前言 :
在上一篇博客中,我们化身"数据炼金术师",将杂乱无章的原始数据清洗、编码、缩放,打磨成了晶莹剔透的"特征宝石"。现在,这些宝石已经整齐地摆放在实验台上,等待着被赋予生命。
本篇是"机器学习实战四部曲"的第三篇,我们将进入最核心的环节:模型训练与评估 。
很多初学者有一个误区:认为选一个最贵的算法(比如深度神经网络),跑一遍代码,任务就完成了。大错特错!
真正的机器学习工程,80% 的精力花在如何科学地评估模型、诊断问题以及微调参数上。 如果评估方法错了,你所谓的"高精度"可能只是自欺欺人。今天,我们就来拆解这套科学的验证体系,并深入几个经典算法的内核。
文章目录
-
-
- [1. 为什么要切分数据?](#1. 为什么要切分数据?)
- [2. 代码实现:`train_test_split`](#2. 代码实现:
train_test_split)
- [🌲 二、经典算法巡礼:从逻辑回归到随机森林](#🌲 二、经典算法巡礼:从逻辑回归到随机森林)
-
- [1. 逻辑回归 (Logistic Regression) ------ 分类界的"基准线"](#1. 逻辑回归 (Logistic Regression) —— 分类界的“基准线”)
- [2. 决策树 (Decision Tree) ------ 模拟人类决策](#2. 决策树 (Decision Tree) —— 模拟人类决策)
- [3. 随机森林 (Random Forest) ------ 集体的智慧](#3. 随机森林 (Random Forest) —— 集体的智慧)
- [📏 三、评估指标:准确率是个"骗子"?](#📏 三、评估指标:准确率是个“骗子”?)
-
- [1. 准确率陷阱](#1. 准确率陷阱)
- [2. 四大金刚指标](#2. 四大金刚指标)
- [3. 代码实战:全方位体检](#3. 代码实战:全方位体检)
- [🎛️ 四、超参数调优:寻找模型的"甜蜜点"](#🎛️ 四、超参数调优:寻找模型的“甜蜜点”)
- [📉 五、学习曲线:诊断模型的"健康状况"](#📉 五、学习曲线:诊断模型的“健康状况”)
- [🔮 下一篇预告:迈向巅峰------集成学习与实战项目](#🔮 下一篇预告:迈向巅峰——集成学习与实战项目)
-
🧪 一、黄金法则:训练集与测试集的分离
在开始训练之前,我们必须确立一条不可逾越的红线:永远不要用考试卷来复习功课。
1. 为什么要切分数据?
如果我们用所有数据来训练模型,然后又在同一批数据上测试它,模型很可能会"死记硬背"下每一个样本的细节(包括噪声和异常值)。这在机器学习中称为过拟合 (Overfitting)。
- 训练集 (Training Set):课本。模型通过学习它来掌握规律(通常占 70%-80%)。
- 测试集 (Test Set):考卷。完全 unseen(未见过的)数据,用来检验模型是否真的学会了举一反三(通常占 20%-30%)。
2. 代码实现:train_test_split
Scikit-learn 提供了极其便捷的工具来完成这一步。
python
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
# 1. 生成一些模拟的分类数据 (1000个样本,20个特征)
X, y = make_classification(n_samples=1000, n_features=20, random_state=42)
# 2. 切分数据
# test_size=0.2 表示 20% 做测试集
# random_state=42 保证每次运行结果一致,方便复现
# stratify=y 表示分层采样,保证训练集和测试集中各类别的比例一致(非常重要!)
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=0.2,
random_state=42,
stratify=y
)
print(f"训练集样本数: {X_train.shape[0]}")
print(f"测试集样本数: {X_test.shape[0]}")💡 专家提示 :
如果你的数据中正负样本比例严重失衡(例如 99% 是正常用户,1% 是欺诈用户),务必使用
stratify=y参数。否则,测试集中可能一个欺诈样本都没有,导致评估完全失效。

🌲 二、经典算法巡礼:从逻辑回归到随机森林
虽然深度学习很火,但在结构化数据(表格数据)领域,传统机器学习算法依然是王者。我们重点介绍三个最具代表性的算法。
1. 逻辑回归 (Logistic Regression) ------ 分类界的"基准线"
不要被名字里的"回归"误导,它是一个分类算法。
- 原理 :在线性回归的基础上,加了一个 Sigmoid 函数 ,把输出值压缩到 (0, 1) 之间,代表属于某一类的概率。
- 优点:计算快、可解释性强(能看出哪个特征权重高)、不易过拟合。
- 适用:作为 baseline(基准模型),或者需要解释"为什么"的场景(如信贷审批)。
2. 决策树 (Decision Tree) ------ 模拟人类决策
- 原理 :像流程图一样,通过一系列"如果是...那么..."的问题(节点分裂),最终得出结论(叶子节点)。
- 根节点:收入 > 5000 吗?
- 左分支:是 -> 年龄 < 30 吗?
- 右分支:否 -> 拒绝贷款。
- 优点:直观易懂,无需数据缩放,能处理非线性关系。
- 缺点:极易过拟合(树长得太深,把特例都记住了)。
3. 随机森林 (Random Forest) ------ 集体的智慧
- 原理 :集成学习 (Ensemble Learning) 的代表。它构建几十甚至上百棵决策树,每棵树只看到部分数据和部分特征。最后,通过"投票"决定结果。
- 核心思想:三个臭皮匠,顶个诸葛亮。单棵树可能犯错,但一百棵树同时犯错的概率极低。
- 优点:精度极高、抗过拟合能力强、对异常值不敏感。是目前表格数据竞赛中的常客。
python
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
# 初始化三个模型
lr = LogisticRegression()
dt = DecisionTreeClassifier(random_state=42)
rf = RandomForestClassifier(n_estimators=100, random_state=42) # 100棵树
# 训练
lr.fit(X_train, y_train)
dt.fit(X_train, y_train)
rf.fit(X_train, y_train)
print("三个模型训练完成!")
📏 三、评估指标:准确率是个"骗子"?
模型训练好了,怎么知道它好不好?
新手最爱用 准确率 (Accuracy) :预测对的样本数 / 总样本数。
但在很多场景下,准确率会骗人!
1. 准确率陷阱
假设我们要检测癌症,1000 个人里只有 1 个患者。
如果模型是个"懒汉",它全部预测为"健康"。
- 准确率 = 999/1000 = 99.9%。看起来棒极了!
- 但实际上,它漏掉了唯一的患者,召回率 (Recall) 为 0。这在医疗上是致命的。
2. 四大金刚指标
我们需要更细致的维度,这就引入了混淆矩阵 (Confusion Matrix):
| 预测正例 (Positive) | 预测负例 (Negative) | |
|---|---|---|
| 真实正例 | TP (真阳性) | FN (假阴性 - 漏报) |
| 真实负例 | FP (假阳性 - 误报) | TN (真阴性) |
基于此,衍生出核心指标:
- 精确率 (Precision) :预测为正例的里面,有多少是真的?
- 公式 : T P / ( T P + F P ) TP / (TP + FP) TP/(TP+FP)
- 场景:垃圾邮件检测。宁可漏掉一封垃圾邮件,也不能把重要邮件误判为垃圾(FP 代价大)。
- 召回率 (Recall) :所有真实的正例里,找回来了多少?
- 公式 : T P / ( T P + F N ) TP / (TP + FN) TP/(TP+FN)
- 场景:地震预测、癌症筛查。宁可误报,也不能漏报(FN 代价大)。
- F1-Score :精确率和召回率的调和平均数。当两者需要平衡时使用。
- 公式 : 2 × ( P r e c i s i o n × R e c a l l ) / ( P r e c i s i o n + R e c a l l ) 2 \times (Precision \times Recall) / (Precision + Recall) 2×(Precision×Recall)/(Precision+Recall)
3. 代码实战:全方位体检
python
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, classification_report, confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
# 使用随机森林进行预测
y_pred = rf.predict(X_test)
# 计算各项指标
acc = accuracy_score(y_test, y_pred)
prec = precision_score(y_test, y_pred)
rec = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
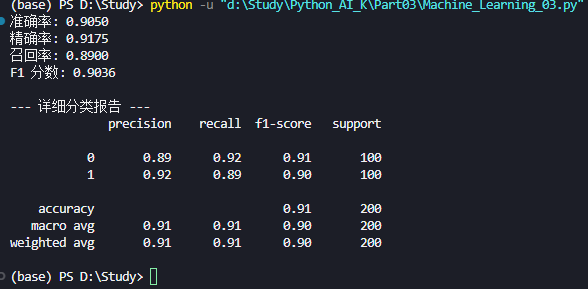
print(f"准确率: {acc:.4f}")
print(f"精确率: {prec:.4f}")
print(f"召回率: {rec:.4f}")
print(f"F1 分数: {f1:.4f}")
print("\n--- 详细分类报告 ---")
# 直接打印每个类别的指标
print(classification_report(y_test, y_pred))
# 绘制混淆矩阵
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.title('混淆矩阵')
plt.ylabel('真实标签')
plt.xlabel('预测标签')
plt.show()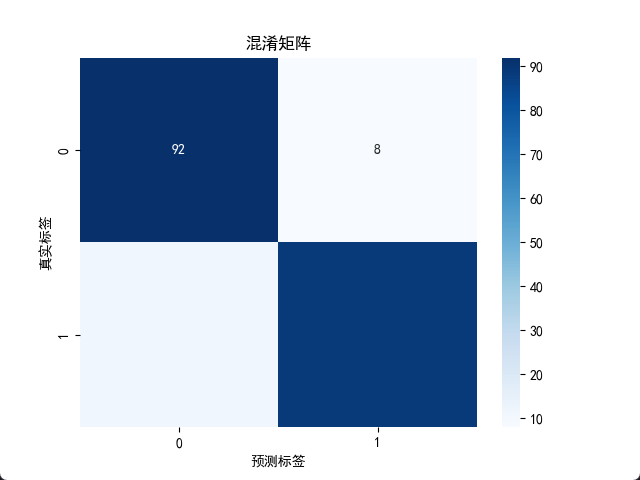
🎛️ 四、超参数调优:寻找模型的"甜蜜点"
模型内部有两类参数:
- 模型参数 :算法自己学出来的(如线性回归的权重 w w w)。
- 超参数 (Hyperparameters) :我们在训练前手动设定的(如随机森林的树的数量
n_estimators、决策树的最大深度max_depth)。
超参数设不好,模型性能天差地别。怎么找最好的组合?
- 笨办法:人工一个个试(累死且不全)。
- 聪明办法 :网格搜索 (Grid Search)。
网格搜索原理
它会把所有可能的参数组合列成一个表格(网格),然后自动遍历每一种组合,利用交叉验证 (Cross Validation) 来评估,最后选出得分最高的那组。
python
from sklearn.model_selection import GridSearchCV
# 1. 定义我们要尝试的参数网格
param_grid = {
'n_estimators': [50, 100, 200], # 树的数量
'max_depth': [None, 10, 20], # 树的最大深度
'min_samples_split': [2, 5] # 内部节点再划分所需最小样本数
}
# 2. 初始化网格搜索对象
# cv=5 表示 5 折交叉验证:把训练集分成 5 份,轮流做验证,结果更稳
grid_search = GridSearchCV(
estimator=RandomForestClassifier(random_state=42),
param_grid=param_grid,
cv=5,
scoring='f1', # 我们优化的目标是 F1 分数
n_jobs=-1, # 使用所有 CPU 核心加速
verbose=1 # 显示进度
)
# 3. 开始搜索 (这步比较耗时)
grid_search.fit(X_train, y_train)
# 4. 输出最佳结果
print("最佳参数组合:", grid_search.best_params_)
print("最佳交叉验证得分:", grid_search.best_score_)
# 5. 使用最佳模型在测试集上验证
best_model = grid_search.best_estimator_
final_score = best_model.score(X_test, y_test)
print(f"测试集最终得分: {final_score:.4f}")
通过这一步,我们不再是"拍脑袋"定参数,而是用数据驱动的方式找到了当前数据集下的最优解。
📉 五、学习曲线:诊断模型的"健康状况"
调优结束后,如果效果还是不理想,该怎么办?这时候需要画出学习曲线 (Learning Curve) 来诊断病因。
- 现象 A :训练集得分高,验证集得分低,且随着数据量增加,两者差距依然很大。
- 诊断 :过拟合 (High Variance)。
- 药方:增加正则化、减少特征、增加更多训练数据、降低模型复杂度。
- 现象 B :训练集和验证集得分都很低,且两者靠得很近。
- 诊断 :欠拟合 (High Bias)。
- 药方:增加模型复杂度、增加新特征、减少正则化。
python
from sklearn.model_selection import learning_curve
import numpy as np
train_sizes, train_scores, val_scores = learning_curve(
best_model, X_train, y_train,
cv=5,
scoring='f1',
train_sizes=np.linspace(0.1, 1.0, 10),
n_jobs=-1
)
# 计算均值和标准差
train_mean = np.mean(train_scores, axis=1)
val_mean = np.mean(val_scores, axis=1)
plt.plot(train_sizes, train_mean, 'o-', color='blue', label='训练集得分')
plt.plot(train_sizes, val_mean, 'o-', color='green', label='交叉验证得分')
plt.xlabel('训练样本数量')
plt.ylabel('F1 分数')
plt.title('学习曲线')
plt.legend()
plt.grid(True)
plt.show()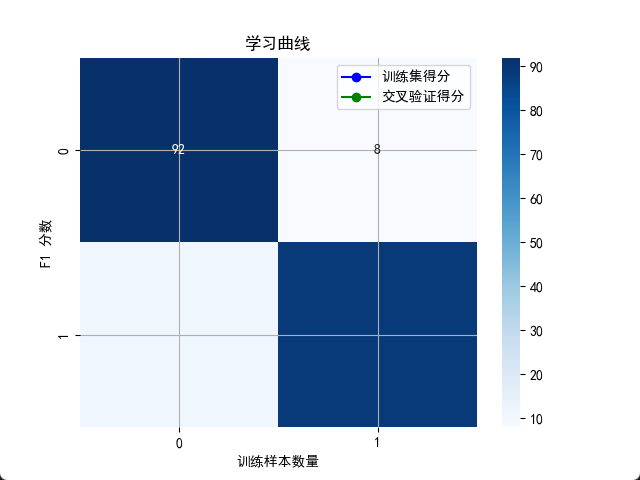
看着这张图,你就能像医生看 X 光片一样,清晰地判断模型是"太胖了"(过拟合)还是"太瘦了"(欠拟合),从而对症下药。
🔮 下一篇预告:迈向巅峰------集成学习与实战项目
至此,我们已经掌握了机器学习的完整闭环:
- 数据预处理:清洗、编码、缩放。
- 模型训练:逻辑回归、决策树、随机森林。
- 科学评估:混淆矩阵、F1 分数、交叉验证。
- 参数调优:网格搜索、学习曲线诊断。
但这还不是终点。在工业界和顶级竞赛中,高手们往往不满足于单个模型的表现。
在**第四篇(终章)**博客中,我们将:
- 进阶集成策略 :除了随机森林,还有更强大的 Gradient Boosting (GBDT, XGBoost, LightGBM) 和 Stacking 融合技术,它们是如何通过"接力赛"的方式不断修正错误的?
- 全流程实战:我们将把这些知识串联起来,完成一个完整的端到端项目(例如:房价预测或客户流失分析),从数据加载到模型部署,输出一份可落地的解决方案。
- 避坑指南:总结新手最容易犯的 5 个致命错误。
准备好了吗?让我们收官之作中,见证从"熟练工"到"架构师"的最后一步跨越!
毒 vs 误报病毒),你应该优先优化哪个指标?你会如何调整模型的阈值来实现这一点?