完整提取流程总览
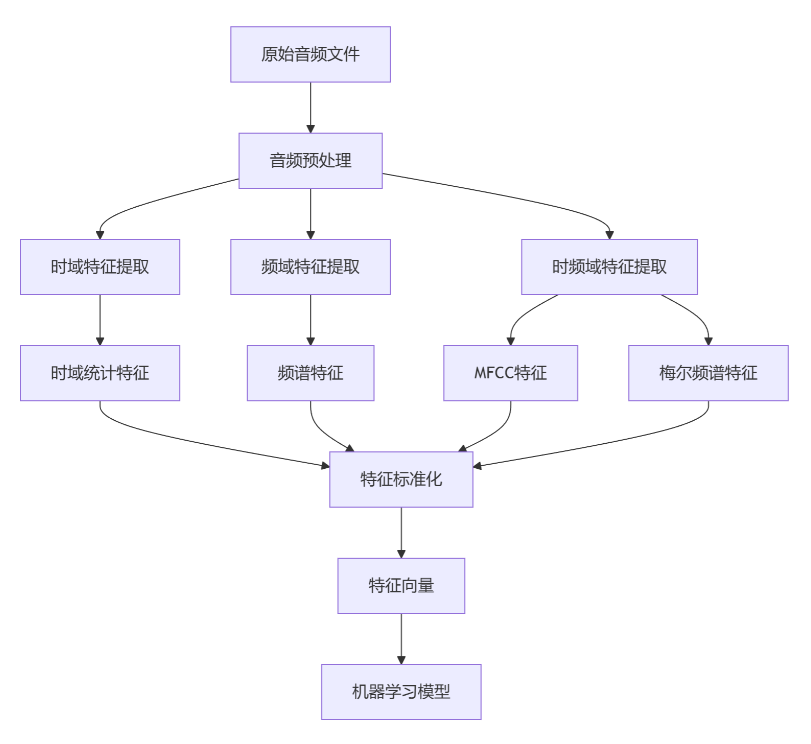
1.音频预处理步骤
步骤1: 加载与重采样
python
def load_and_resample(audio_path, target_sr=22050):
"""加载音频并统一采样率"""
# 加载音频
audio, original_sr = librosa.load(audio_path, sr=None)
# 重采样到目标频率
if original_sr != target_sr:
audio = librosa.resample(audio, orig_sr=original_sr, target_sr=target_sr)
return audio, target_sr步骤2: 音频标准化
python
def standardize_audio(audio, target_duration=1.0):
"""音频长度标准化"""
target_length = int(target_duration * 22050) # 1秒
if len(audio) < target_length:
# 零填充
padding = target_length - len(audio)
audio = np.pad(audio, (0, padding), mode='constant')
elif len(audio) > target_length:
# 截断
audio = audio[:target_length]
# 振幅归一化
audio = audio / (np.max(np.abs(audio)) + 1e-8) # 防止除零
return audio2.时域特征提取方法
步骤3: 提取时域统计特征
python
def extract_time_domain_features(audio):
"""提取时域统计特征"""
features = {}
# 1. 基本统计量
features['mean'] = np.mean(audio)
features['std'] = np.std(audio)
features['max'] = np.max(audio)
features['min'] = np.min(audio)
features['range'] = features['max'] - features['min']
# 2. 高阶统计量
features['skewness'] = scipy.stats.skew(audio) # 偏度
features['kurtosis'] = scipy.stats.kurtosis(audio) # 峰度
# 3. 能量相关特征
features['rms'] = np.sqrt(np.mean(audio**2)) # 均方根
features['energy'] = np.sum(audio**2) # 总能量
# 4. 过零率
zero_crossings = np.where(np.diff(np.signbit(audio)))[0]
features['zero_crossing_rate'] = len(zero_crossings) / len(audio)
return features3 频域特征提取方法
步骤4: 频域转换与特征提取
python
def extract_frequency_domain_features(audio, sr=22050):
"""提取频域特征"""
features = {}
# 1. 傅里叶变换
fft = np.fft.fft(audio)
magnitude_spectrum = np.abs(fft)[:len(fft)//2] # 取正频率
frequency_bins = np.fft.fftfreq(len(audio), 1/sr)[:len(audio)//2]
# 2. 频谱质心
features['spectral_centroid'] = np.sum(frequency_bins * magnitude_spectrum) / np.sum(magnitude_spectrum)
# 3. 频谱带宽
centroid = features['spectral_centroid']
features['spectral_bandwidth'] = np.sqrt(
np.sum((frequency_bins - centroid)**2 * magnitude_spectrum) / np.sum(magnitude_spectrum)
)
# 4. 频谱滚降点
total_energy = np.sum(magnitude_spectrum)
cumulative_energy = np.cumsum(magnitude_spectrum)
rolloff_idx = np.where(cumulative_energy >= 0.85 * total_energy)[0]
features['spectral_rolloff'] = frequency_bins[rolloff_idx[0]] if len(rolloff_idx) > 0 else 0
# 5. 频谱通量
if hasattr(extract_frequency_domain_features, 'prev_spectrum'):
spectral_flux = np.sum((magnitude_spectrum - extract_frequency_domain_features.prev_spectrum)**2)
features['spectral_flux'] = spectral_flux
extract_frequency_domain_features.prev_spectrum = magnitude_spectrum
return features4 时频域特征提取方法(核心)
步骤5: MFCC特征提取
python
def extract_mfcc_features(audio, sr=22050, n_mfcc=20):
"""提取梅尔频率倒谱系数"""
# 1. 短时傅里叶变换
stft = np.abs(librosa.stft(audio, n_fft=2048, hop_length=512))
# 2. 梅尔滤波器组
mel_filter = librosa.filters.mel(sr=sr, n_fft=2048, n_mels=128)
# 3. 梅尔频谱
mel_spectrum = np.dot(mel_filter, stft)
# 4. 对数压缩
log_mel_spectrum = librosa.power_to_db(mel_spectrum, ref=np.max)
# 5. 离散余弦变换
mfccs = librosa.feature.mfcc(
y=audio, sr=sr, n_mfcc=n_mfcc,
n_fft=2048, hop_length=512, n_mels=128
)
return mfccs步骤6: 计算MFCC统计特征
python
def calculate_mfcc_statistics(mfccs, delta_order=2):
"""计算MFCC统计特征"""
features = []
# 1. 均值特征
mfcc_mean = np.mean(mfccs, axis=1)
features.extend(mfcc_mean)
# 2. 标准差特征
mfcc_std = np.std(mfccs, axis=1)
features.extend(mfcc_std)
# 3. 一阶差分
if delta_order >= 1:
mfcc_delta = librosa.feature.delta(mfccs)
mfcc_delta_mean = np.mean(mfcc_delta, axis=1)
features.extend(mfcc_delta_mean)
# 4. 二阶差分
if delta_order >= 2:
mfcc_delta2 = librosa.feature.delta(mfccs, order=2)
mfcc_delta2_mean = np.mean(mfcc_delta2, axis=1)
features.extend(mfcc_delta2_mean)
return np.array(features)5 特征整合与标准化
步骤7: 特征组合
python
def combine_all_features(audio, sr=22050):
"""整合所有特征"""
# 1. 时域特征
time_features = extract_time_domain_features(audio)
# 2. 频域特征
freq_features = extract_frequency_domain_features(audio, sr)
# 3. MFCC特征
mfccs_20 = extract_mfcc_features(audio, sr, n_mfcc=20)
mfcc_stats_80 = calculate_mfcc_statistics(mfccs_20, delta_order=2)
mfccs_13 = extract_mfcc_features(audio, sr, n_mfcc=13)
mfcc_stats_39 = calculate_mfcc_statistics(mfccs_13, delta_order=1)
# 4. 特征组合
combined_features = {
'time_features': np.array(list(time_features.values())),
'freq_features': np.array(list(freq_features.values())),
'mfcc_80': mfcc_stats_80,
'mfcc_39': mfcc_stats_39
}
return combined_features步骤8: 特征标准化
python
def standardize_features(features_dict, scaler=None):
"""特征标准化"""
standardized_features = {}
for feature_name, feature_array in features_dict.items():
if scaler is None:
# 标准化到[0,1]范围
min_val = np.min(feature_array)
max_val = np.max(feature_array)
if max_val - min_val > 0:
standardized = (feature_array - min_val) / (max_val - min_val)
else:
standardized = feature_array
else:
# 使用预训练的scaler
standardized = scaler.transform(feature_array.reshape(1, -1))[0]
standardized_features[feature_name] = standardized
return standardized_features特征提取完整示例
python
def extract_audio_features_complete(audio_path, target_duration=1.0):
"""完整的音频特征提取流程"""
# 步骤1: 音频预处理
print("步骤1: 音频预处理...")
audio, sr = load_and_resample(audio_path)
audio = standardize_audio(audio, target_duration)
# 步骤2: 时域特征提取
print("步骤2: 时域特征提取...")
time_features = extract_time_domain_features(audio)
# 步骤3: 频域特征提取
print("步骤3: 频域特征提取...")
freq_features = extract_frequency_domain_features(audio, sr)
# 步骤4: MFCC特征提取
print("步骤4: MFCC特征提取...")
mfccs_20 = extract_mfcc_features(audio, sr, n_mfcc=20)
mfcc_stats_80 = calculate_mfcc_statistics(mfccs_20, delta_order=2)
mfccs_13 = extract_mfcc_features(audio, sr, n_mfcc=13)
mfcc_stats_39 = calculate_mfcc_statistics(mfccs_13, delta_order=1)
# 步骤5: 特征整合
print("步骤5: 特征整合...")
all_features = {
'time_features': np.array(list(time_features.values())),
'freq_features': np.array(list(freq_features.values())),
'mfcc_80': mfcc_stats_80,
'mfcc_39': mfcc_stats_39
}
# 步骤6: 特征标准化
print("步骤6: 特征标准化...")
standardized_features = standardize_features(all_features)
print("✓ 特征提取完成!")
print(f" 时域特征: {len(time_features)}维")
print(f" 频域特征: {len(freq_features)}维")
print(f" MFCC-80维特征: {len(mfcc_stats_80)}维")
print(f" MFCC-39维特征: {len(mfcc_stats_39)}维")
return standardized_features