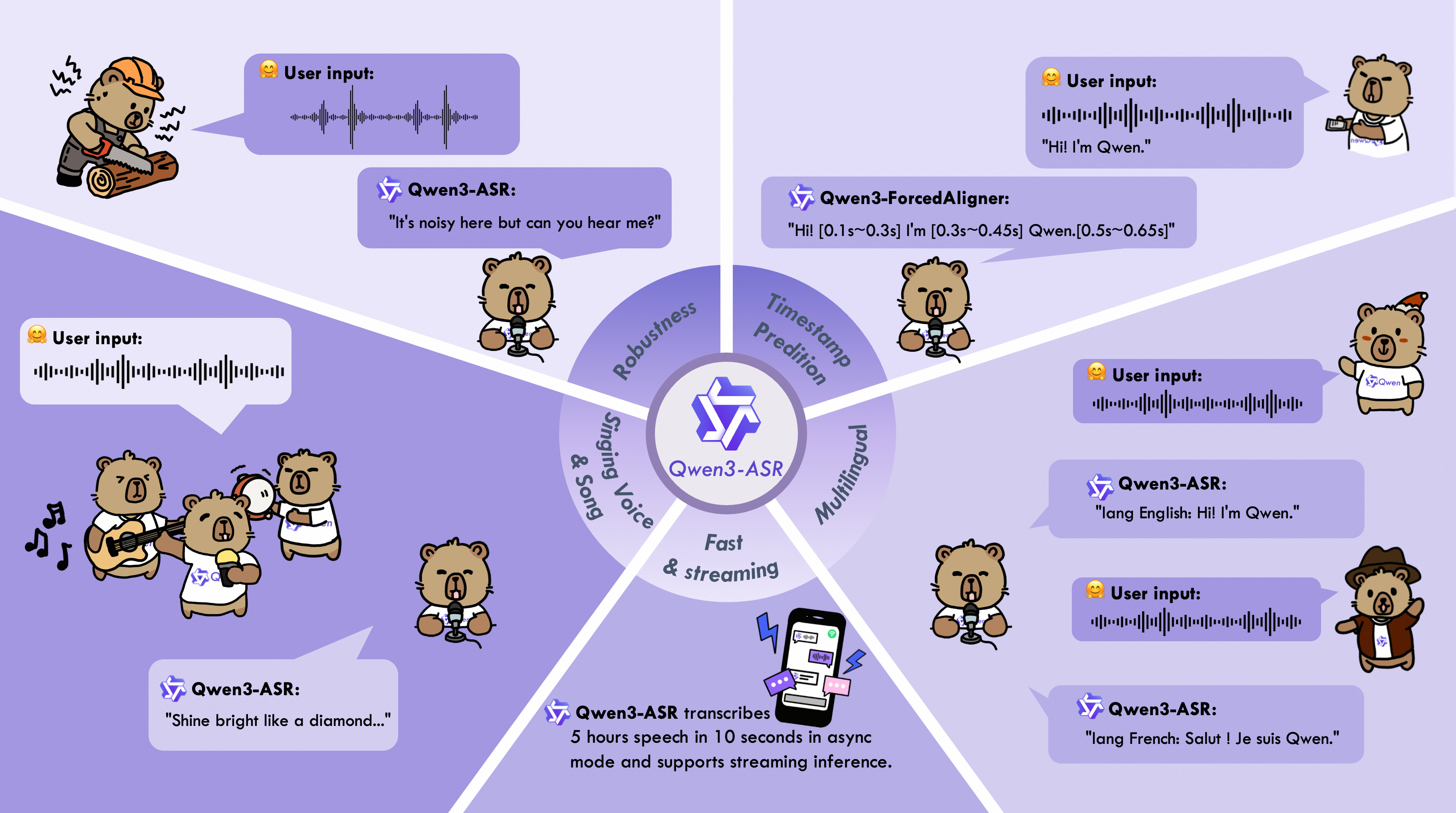
Qwen3-ASR系列包含Qwen3-ASR-1.7B和Qwen3-ASR-0.6B两款模型,支持52种语言与方言的语种识别及语音转写。二者均基于大规模语音训练数据及基座模型Qwen3-Omni强大的音频理解能力构建。实验表明,1.7B版本在开源ASR模型中达到最优性能,并可媲美最强的商业专有API。主要特性如下:
-
全能识别:Qwen3-ASR-1.7B和Qwen3-ASR-0.6B支持30种语言及22种汉语方言的语种识别与语音转写,同时涵盖多国英语口音识别。
-
又快又准:该系列模型在复杂声学环境和挑战性文本场景下仍保持高质量、高鲁棒性的识别效果。Qwen3-ASR-1.7B在开源及内部测试集上均取得领先性能,0.6B版本则在精度与效率间取得平衡,在128并发下实现2000倍吞吐量。二者均支持单模型流式/非流式统一推理,并具备长音频转录能力。
-
创新强对齐方案:我们推出Qwen3-ForcedAligner-0.6B,支持11种语言的语音内容在5分钟内任意单元的时间戳预测。评估显示其时间戳精度超越现有端到端强制对齐模型。
-
完整推理工具链:除开源Qwen3-ASR系列架构及权重外,我们还发布了功能强大的全特性推理框架,支持基于vLLM的批量推理、异步服务、流式推理、时间戳预测等功能。
模型架构
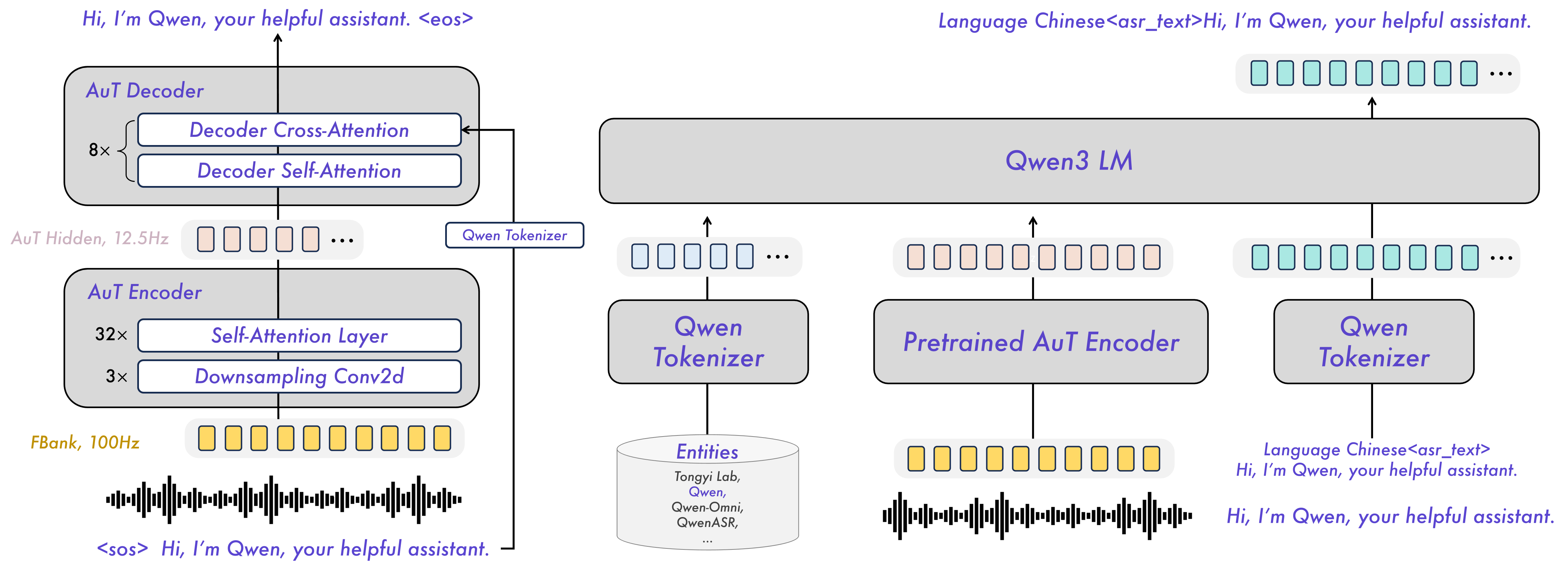
已发布模型说明与下载
以下是Qwen3-ASR系列模型的介绍与下载信息,请根据需求选择下载对应模型。
| 模型 | 支持语言 | 支持方言 | 推理模式 | 音频类型 |
|---|---|---|---|---|
| Qwen3-ASR-1.7B & Qwen3-ASR-0.6B | 中文(zh)、英文(en)、粤语(yue)、阿拉伯语(ar)、德语(de)、法语(fr)、西班牙语(es)、葡萄牙语(pt)、印尼语(id)、意大利语(it)、韩语(ko)、俄语(ru)、泰语(th)、越南语(vi)、日语(ja)、土耳其语(tr)、印地语(hi)、马来语(ms)、荷兰语(nl)、瑞典语(sv)、丹麦语(da)、芬兰语(fi)、波兰语(pl)、捷克语(cs)、菲律宾语(fil)、波斯语(fa)、希腊语(el)、匈牙利语(hu)、马其顿语(mk)、罗马尼亚语(ro) | 安徽话、东北话、福建话、甘肃话、贵州话、河北话、河南话、湖北话、湖南话、江西话、宁夏话、山东话、陕西话、山西话、四川话、天津话、云南话、浙江话、粤语(港式口音)、粤语(广式口音)、吴语、闽南语 | 离线/流式 | 人声、歌声、带背景音乐歌曲 |
| Qwen3-ForcedAligner-0.6B | 中文、英文、粤语、法语、德语、意大利语、日语、韩语、葡萄牙语、俄语、西班牙语 | -- | NAR | 人声 |
使用qwen-asr包或vLLM加载模型时,会根据模型名称自动下载模型权重。若运行环境不允许执行时下载权重,可使用以下命令将模型权重提前下载至本地目录:
bash
# Download through ModelScope (recommended for users in Mainland China)
pip install -U modelscope
modelscope download --model Qwen/Qwen3-ASR-1.7B --local_dir ./Qwen3-ASR-1.7B
modelscope download --model Qwen/Qwen3-ASR-0.6B --local_dir ./Qwen3-ASR-0.6B
modelscope download --model Qwen/Qwen3-ForcedAligner-0.6B --local_dir ./Qwen3-ForcedAligner-0.6B
# Download through Hugging Face
pip install -U "huggingface_hub[cli]"
huggingface-cli download Qwen/Qwen3-ASR-1.7B --local-dir ./Qwen3-ASR-1.7B
huggingface-cli download Qwen/Qwen3-ASR-0.6B --local-dir ./Qwen3-ASR-0.6B
huggingface-cli download Qwen/Qwen3-ForcedAligner-0.6B --local-dir ./Qwen3-ForcedAligner-0.6B快速开始
环境配置
使用Qwen3-ASR最简单的方式是从PyPI安装qwen-asr Python包。该操作会自动安装运行所需的依赖项,并支持加载所有已发布的Qwen3-ASR模型。若需进一步简化环境配置,您也可以使用我们官方的Docker镜像。qwen-asr包提供两种后端实现:transformers后端和vLLM后端,不同后端的使用方法请参阅Python包使用说明。为避免与现有软件包产生依赖冲突,建议在全新的隔离环境中进行安装。可通过以下命令创建纯净的Python 3.12环境:
bash
conda create -n qwen3-asr python=3.12 -y
conda activate qwen3-asr运行以下命令以获取支持transformers-backend的最小安装:
bash
pip install -U qwen-asr要启用vLLM后端以获得更快的推理和流式支持,请运行:
bash
pip install -U qwen-asr[vllm]如果您想在本地开发或修改代码,请以可编辑模式从源代码安装:
bash
git clone https://github.com/QwenLM/Qwen3-ASR.git
cd Qwen3-ASR
pip install -e .
# support vLLM backend
# pip install -e ".[vllm]"此外,我们推荐使用FlashAttention 2来降低GPU内存占用并加速推理速度,尤其适用于长输入和大批量处理场景。
bash
pip install -U flash-attn --no-build-isolation如果你的机器内存少于96GB且拥有大量CPU核心,请运行:
bash
MAX_JOBS=4 pip install -U flash-attn --no-build-isolation此外,您需要确保硬件支持FlashAttention 2。更多详情请查阅FlashAttention官方仓库文档。请注意,只有当模型以torch.float16或torch.bfloat16格式加载时,才能使用FlashAttention 2。
Python 包使用指南
快速推理
qwen-asr 包提供两种后端引擎:transformers 后端 和 vLLM 后端 。您可以将音频输入以本地路径、URL链接、base64编码数据或(np.ndarray, sr)元组形式传入,并执行批量推理。要快速体验Qwen3-ASR,可使用Qwen3ASRModel.from_pretrained(...)加载transformers后端,示例代码如下:
python
import torch
from qwen_asr import Qwen3ASRModel
model = Qwen3ASRModel.from_pretrained(
"Qwen/Qwen3-ASR-1.7B",
dtype=torch.bfloat16,
device_map="cuda:0",
# attn_implementation="flash_attention_2",
max_inference_batch_size=32, # Batch size limit for inference. -1 means unlimited. Smaller values can help avoid OOM.
max_new_tokens=256, # Maximum number of tokens to generate. Set a larger value for long audio input.
)
results = model.transcribe(
audio="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-ASR-Repo/asr_en.wav",
language=None, # set "English" to force the language
)
print(results[0].language)
print(results[0].text)如果想返回时间戳,请传递 forced_aligner 及其初始化参数。以下是带时间戳输出的批量推理示例:
python
import torch
from qwen_asr import Qwen3ASRModel
model = Qwen3ASRModel.from_pretrained(
"Qwen/Qwen3-ASR-1.7B",
dtype=torch.bfloat16,
device_map="cuda:0",
# attn_implementation="flash_attention_2",
max_inference_batch_size=32, # Batch size limit for inference. -1 means unlimited. Smaller values can help avoid OOM.
max_new_tokens=256, # Maximum number of tokens to generate. Set a larger value for long audio input.
forced_aligner="Qwen/Qwen3-ForcedAligner-0.6B",
forced_aligner_kwargs=dict(
dtype=torch.bfloat16,
device_map="cuda:0",
# attn_implementation="flash_attention_2",
),
)
results = model.transcribe(
audio=[
"https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-ASR-Repo/asr_zh.wav",
"https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-ASR-Repo/asr_en.wav",
],
language=["Chinese", "English"], # can also be set to None for automatic language detection
return_time_stamps=True,
)
for r in results:
print(r.language, r.text, r.time_stamps[0])如需更详细的使用示例,请参考transformers后端的示例代码。
vLLM 后端
若想获得Qwen3-ASR最快的推理速度,我们强烈推荐使用vLLM后端,通过Qwen3ASRModel.LLM(...)初始化模型。下方提供示例代码。注意必须通过pip install -U qwen-asr[vllm]安装。如需模型输出时间戳,建议通过pip install -U flash-attn --no-build-isolation安装FlashAttention来加速强制对齐模型的推理。请务必将代码包裹在if __name__ == '__main__':下,以避免vLLM故障排除指南中描述的spawn错误。
python
import torch
from qwen_asr import Qwen3ASRModel
if __name__ == '__main__':
model = Qwen3ASRModel.LLM(
model="Qwen/Qwen3-ASR-1.7B",
gpu_memory_utilization=0.7,
max_inference_batch_size=128, # Batch size limit for inference. -1 means unlimited. Smaller values can help avoid OOM.
max_new_tokens=4096, # Maximum number of tokens to generate. Set a larger value for long audio input.
forced_aligner="Qwen/Qwen3-ForcedAligner-0.6B",
forced_aligner_kwargs=dict(
dtype=torch.bfloat16,
device_map="cuda:0",
# attn_implementation="flash_attention_2",
),
)
results = model.transcribe(
audio=[
"https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-ASR-Repo/asr_zh.wav",
"https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-ASR-Repo/asr_en.wav",
],
language=["Chinese", "English"], # can also be set to None for automatic language detection
return_time_stamps=True,
)
for r in results:
print(r.language, r.text, r.time_stamps[0])如需更详细的使用示例,请参考vLLM后端的示例代码。此外,您可以通过qwen-asr-serve命令启动vLLM服务器,该命令是vllm serve的封装器。您可以传入任何vllm serve支持的参数,例如:
bash
qwen-asr-serve Qwen/Qwen3-ASR-1.7B --gpu-memory-utilization 0.8 --host 0.0.0.0 --port 8000并通过以下方式向服务器发送请求:
python
import requests
url = "http://localhost:8000/v1/chat/completions"
headers = {"Content-Type": "application/json"}
data = {
"messages": [
{
"role": "user",
"content": [
{
"type": "audio_url",
"audio_url": {
"url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-ASR-Repo/asr_en.wav"
},
}
],
}
]
}
response = requests.post(url, headers=headers, json=data, timeout=300)
response.raise_for_status()
content = response.json()['choices'][0]['message']['content']
print(content)
# parse ASR output if you want
from qwen_asr import parse_asr_output
language, text = parse_asr_output(content)
print(language)
print(text)流式推理
Qwen3-ASR 全面支持流式推理。目前流式推理仅在使用 vLLM 后端时可用。请注意,流式推理不支持批量推理或返回时间戳。具体实现请参考示例代码。您也可以通过指南启动流式网页演示,体验 Qwen3-ASR 的流式转录能力。
强制对齐器使用
Qwen3-ForcedAligner-0.6B 可对齐文本-语音对并返回词级或字级时间戳。以下是直接使用强制对齐器的示例:
python
import torch
from qwen_asr import Qwen3ForcedAligner
model = Qwen3ForcedAligner.from_pretrained(
"Qwen/Qwen3-ForcedAligner-0.6B",
dtype=torch.bfloat16,
device_map="cuda:0",
# attn_implementation="flash_attention_2",
)
results = model.align(
audio="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-ASR-Repo/asr_zh.wav",
text="甚至出现交易几乎停滞的情况。",
language="Chinese",
)
print(results[0])
print(results[0][0].text, results[0][0].start_time, results[0][0].end_time)此外,强制对齐器支持本地路径/URL/base64数据/(np.ndarray, sr)输入和批量推理。详情请参阅示例代码。
启动本地Web UI演示
Gradio演示
要启动Qwen3-ASR的Web UI gradio演示,请先安装qwen-asr包,然后运行qwen-asr-demo。使用以下命令获取帮助信息:
bash
qwen-asr-demo --help要启动演示,可以使用以下命令:
bash
# Transformers backend
qwen-asr-demo \
--asr-checkpoint Qwen/Qwen3-ASR-1.7B \
--backend transformers \
--cuda-visible-devices 0 \
--ip 0.0.0.0 --port 8000
# Transformers backend + Forced Aligner (enable timestamps)
qwen-asr-demo \
--asr-checkpoint Qwen/Qwen3-ASR-1.7B \
--aligner-checkpoint Qwen/Qwen3-ForcedAligner-0.6B \
--backend transformers \
--cuda-visible-devices 0 \
--backend-kwargs '{"device_map":"cuda:0","dtype":"bfloat16","max_inference_batch_size":8,"max_new_tokens":256}' \
--aligner-kwargs '{"device_map":"cuda:0","dtype":"bfloat16"}' \
--ip 0.0.0.0 --port 8000
# vLLM backend + Forced Aligner (enable timestamps)
qwen-asr-demo \
--asr-checkpoint Qwen/Qwen3-ASR-1.7B \
--aligner-checkpoint Qwen/Qwen3-ForcedAligner-0.6B \
--backend vllm \
--cuda-visible-devices 0 \
--backend-kwargs '{"gpu_memory_utilization":0.7,"max_inference_batch_size":8,"max_new_tokens":2048}' \
--aligner-kwargs '{"device_map":"cuda:0","dtype":"bfloat16"}' \
--ip 0.0.0.0 --port 8000然后打开 http://<你的IP>:8000,或通过 VS Code 等工具的端口转发功能访问。
后端说明
本演示支持两种后端:transformers 和 vLLM。所有后端特定的初始化参数都应通过 --backend-kwargs 以 JSON 字典形式传入。若未提供参数,演示将采用合理的默认值。
bash
# Example: override transformers init args without flash attention
--backend-kwargs '{"device_map":"cuda:0","dtype":"bfloat16"}'
# Example: override vLLM init args with 65% GPU memory
--backend-kwargs '{"gpu_memory_utilization":0.65}'CUDA设备说明
由于vLLM不支持cuda:0风格的设备选择方式,本演示通过--cuda-visible-devices参数设置CUDA_VISIBLE_DEVICES环境变量来选择GPU设备。
bash
# Use GPU 0
--cuda-visible-devices 0
# Use GPU 1
--cuda-visible-devices 1时间戳说明
时间戳仅在提供 --aligner-checkpoint 参数时可用。若未使用强制对齐器启动演示,时间戳界面将自动隐藏。
bash
# No forced aligner
qwen-asr-demo --asr-checkpoint Qwen/Qwen3-ASR-1.7B
# With forced aligner
qwen-asr-demo \
--asr-checkpoint Qwen/Qwen3-ASR-1.7B \
--aligner-checkpoint Qwen/Qwen3-ForcedAligner-0.6BHTTPS 注意事项
为避免部署服务器后出现浏览器麦克风权限问题,建议/要求通过 HTTPS 运行 gradio 服务(尤其是在远程访问或现代浏览器/网关环境下)。使用 --ssl-certfile 和 --ssl-keyfile 参数启用 HTTPS。首先生成私钥和自签名证书(有效期为 365 天):
bash
openssl req -x509 -newkey rsa:2048 \
-keyout key.pem -out cert.pem \
-days 365 -nodes \
-subj "/CN=localhost"然后使用 HTTPS 运行演示:
bash
qwen-asr-demo \
--asr-checkpoint Qwen/Qwen3-ASR-1.7B \
--backend transformers \
--cuda-visible-devices 0 \
--ip 0.0.0.0 --port 8000 \
--ssl-certfile cert.pem \
--ssl-keyfile key.pem \
--no-ssl-verify然后打开 https://<你的IP>:8000 即可使用。如果浏览器显示安全警告,这是自签名证书的正常现象。生产环境请使用正规证书。
流式演示
为体验Qwen3-ASR在网页界面中的流式转录能力,我们提供了一个基于Flask的最小化流式演示。该演示通过浏览器采集麦克风音频,将其重采样至16,000Hz,并持续将PCM音频块推送至模型。运行以下命令启动演示:
bash
qwen-asr-demo-streaming \
--asr-model-path Qwen/Qwen3-ASR-1.7B \
--host 0.0.0.0 \
--port 8000 \
--gpu-memory-utilization 0.9然后打开 http://<你的IP>:8000,或通过 VS Code 等工具的端口转发访问。
使用 vLLM 部署
vLLM 官方为 Qwen3-ASR 提供了高效推理的 day-0 模型支持。
安装
您可以通过 vLLM nightly 轮或 docker 镜像运行 Qwen3-ASR。要安装 vLLM 的 nightly 版本,我们推荐使用 uv 作为环境管理器
bash
uv venv
source .venv/bin/activate
uv pip install -U vllm --pre \
--extra-index-url https://wheels.vllm.ai/nightly/cu129 \
--extra-index-url https://download.pytorch.org/whl/cu129 \
--index-strategy unsafe-best-match
uv pip install "vllm[audio]" # For additional audio dependencies在线服务
您可以通过运行以下命令,轻松使用vLLM部署Qwen3-ASR模型:
bash
vllm serve Qwen/Qwen3-ASR-1.7B模型服务器成功部署后,您可以通过多种方式与其交互。
使用 OpenAI SDK
python
import base64
import httpx
from openai import OpenAI
# Initialize client
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="EMPTY"
)
# Create multimodal chat completion request
response = client.chat.completions.create(
model="Qwen/Qwen3-ASR-1.7B",
messages=[
{
"role": "user",
"content": [
{
"type": "audio_url",
"audio_url": {
{"url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-ASR-Repo/asr_en.wav"}
}
}
]
}
],
)
print(response.choices[0].message.content)该模型还支持通过OpenAI转录API在vLLM上运行。
python
import httpx
from openai import OpenAI
# Initialize client
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="EMPTY"
)
audio_url = "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-ASR-Repo/asr_en.wav"
audio_file = httpx.get(audio_url).content
transcription = client.audio.transcriptions.create(
model="Qwen/Qwen3-ASR-1.7B",
file=audio_file,
)
print(transcription.text)使用 cURL
bash
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"messages": [
{"role": "user", "content": [
{"type": "audio_url", "audio_url": {"url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-ASR-Repo/asr_en.wav"}}
]}
]
}'离线推理
查看以下示例,了解如何使用vLLM与Qwen3-ASR进行离线推理
python
from vllm import LLM, SamplingParams
from vllm.assets.audio import AudioAsset
import base64
import requests
# Initialize the LLM
llm = LLM(
model="Qwen/Qwen3-ASR-1.7B"
)
# Load audio
audio_asset = AudioAsset("winning_call")
# Create conversation with audio content
conversation = [
{
"role": "user",
"content": [
{
"type": "audio_url",
"audio_url": {"url": audio_asset.url}
}
]
}
]
sampling_params = SamplingParams(temperature=0.01, max_tokens=256)
# Run inference using .chat()
outputs = llm.chat(conversation, sampling_params=sampling_params)
print(outputs[0].outputs[0].text)Docker
为方便使用我们的qwen-asr Python包,我们提供了预构建的Docker镜像:qwenllm/qwen3-asr。您只需安装GPU驱动并下载模型文件即可运行代码。请按照NVIDIA容器工具包安装指南确保Docker能访问您的GPU。若您位于中国大陆且访问Docker Hub困难,可使用镜像仓库加速拉取。
首先拉取镜像并启动容器:
bash
LOCAL_WORKDIR=/path/to/your/workspace
HOST_PORT=8000
CONTAINER_PORT=80
docker run --gpus all --name qwen3-asr \
-v /var/run/docker.sock:/var/run/docker.sock -p $HOST_PORT:$CONTAINER_PORT \
--mount type=bind,source=$LOCAL_WORKDIR,target=/data/shared/Qwen3-ASR \
--shm-size=4gb \
-it qwenllm/qwen3-asr:latest运行命令后,您将进入容器的bash shell。您的本地工作空间(请将 /path/to/your/workspace替换为实际路径 )将被挂载到容器内的/data/shared/Qwen3-ASR目录。主机的8000端口会映射到容器内的80端口,因此您可以通过http://<主机IP>:8000访问容器内运行的服务。请注意,容器内的服务必须绑定到0.0.0.0(而非127.0.0.1)才能使端口转发生效。
若退出容器,您可以通过以下命令重新启动并再次进入:
bash
docker start qwen3-asr
docker exec -it qwen3-asr bash要完全移除容器,请运行:
bash
docker rm -f qwen3-asr