2000 年以后,研究者提出了基于统计模型的语音合成方法。与拼接法保留原始录音片段不同,统计合成法将语料库中每个音素的语音片段"总结"成一个称为隐马尔可夫模型(HMM)的统计模型。在前一节中讨论过,HMM 模型可以描述发音的动态过程,因此可以用来合成声音。具体而言,首先用 HMM 模型生成每个音素的声门和声道的参数,再利用声码器(源-滤波模型)从这些参数合成语音。如图 30.9所示,对每个音素("n""i""h""ao")分别建立 HMM 模型,利用这些模型生成声门和声道参数,再通过声码器读取这些参数并合成语音。
统计模型的一个优势在于其可扩展性。通过调整模型参数,合成系统可以改变发音的特性。例如,只需少量训练数据就可以让模型模拟不同人的声音,或调整语音的情感表现。
然而,HMM 学习的是声音的平均特性,无法模拟真实语音中丰富的动态特性。因此,基于HMM 生成的语音通常较为平滑,缺乏真实语音的动态感。
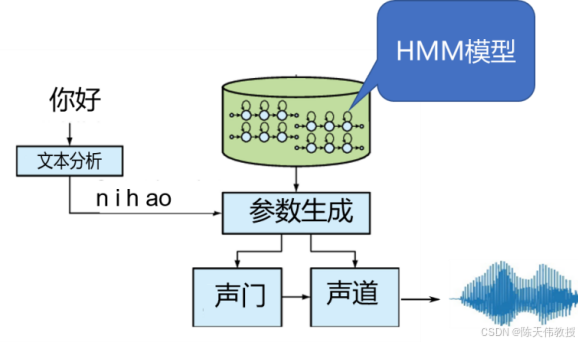
统计合成法示意图