背景
思考为什么要有rag这个技术?
通⽤的基础⼤模型存在一些问题:
1.LLM的知识不是实时的,模型训练好后不具备自动更新知识的能力,会导致部分信息滞后。
2.LLM领域知识是缺乏的,大模型的知识来源于训练数据,这些数据主要来自公开的互联网和开源数据集,无法覆盖特定领域或高度专业化的内部知识。
3.幻觉问题,LLM有时会在回答中生成看似合理但实际上是错误的信息 数据安全性。
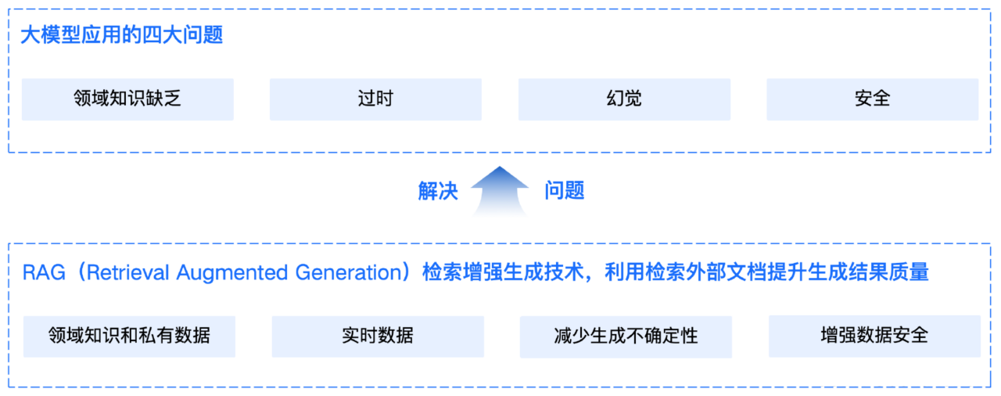
RAG(Retrieval-Augmented Generation)即检索增强生成,为大模型提供了从特定数据源检索到的信息,以此来修正和补充生成的答案。
可以总结为一个公式:RAG = 检索技术 + LLM 提示
rag工作流程图解
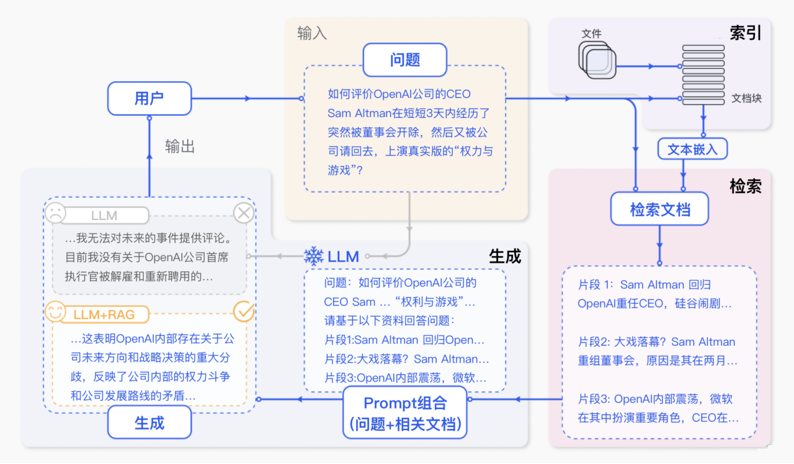
RAG标准流程
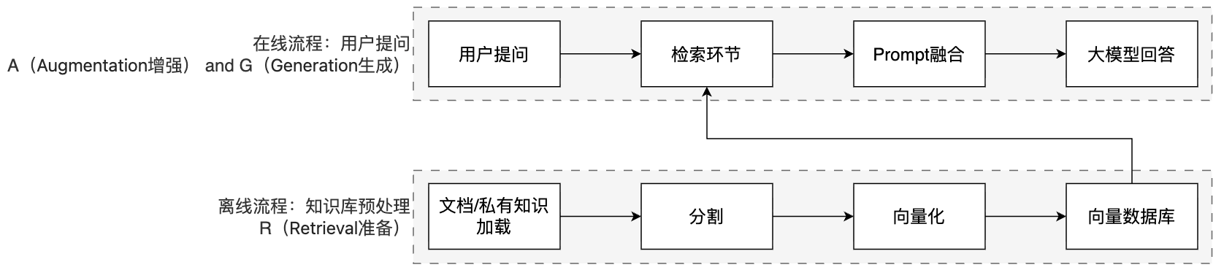
RAG工作分为两条线: 1.离线准备线 / 2.在线服务线
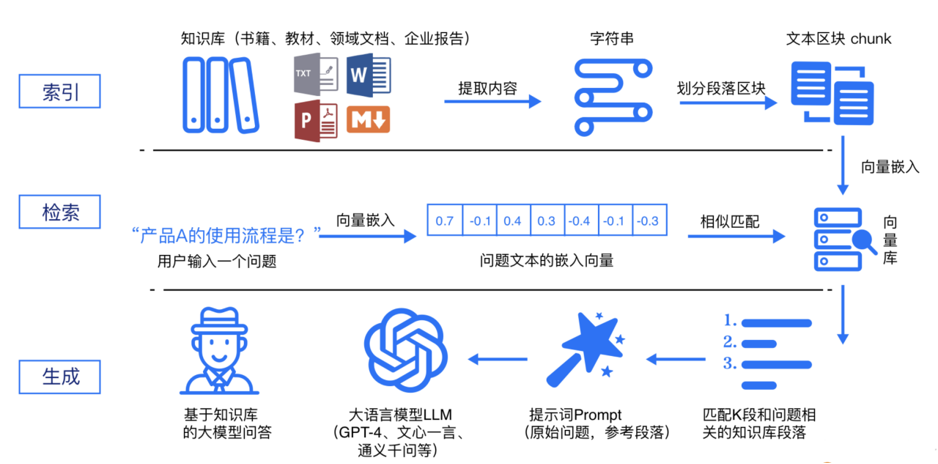
RAG 标准流程由索引(Indexing)、检索(Retriever)和生成(Generation)三个核心阶段组成。
1.索引阶段,通过处理多种来源多种格式的文档提取其中文本,将其切分为标准长度的文本块(chunk),并进行嵌入向量化(embedding),向量存储在向量数据库(vector database)中。 加载文件 内容提取 文本分割 ,形成chunk 文本向量化 存向量数据库
2.检索阶段,用户输入的查询(query)被转化为向量表示,通过相似度匹配从向量数据库中检索出最相关的文本块。 query向量化 在文本向量中匹配出与问句向量相似的top_k个
3.生成阶段,检索到的相关文本与原始查询共同构成提示词(Prompt),输入大语言模型(LLM),生成精确且具备上下文关联的回答。 匹配出的文本作为上下文和问题一起添加到prompt中 提交给LLM生成答案
rag原理
RAG流程中,向量库是一个重要的节点。
1.离线流程:知识和信息 -> 向量嵌入(向量化)-> 存入向量库
2.在线流程:用户的提问 -> 向量嵌入(向量化) -> 在向量库中匹配
向量
向量(Vector)就是文本的 "数学身份证":它把一段文字的语义信息,转换成一串固定长度的数字列表,让计算机能 "看懂" 文字的含义并做相似度计算。
简单来说,就是让计算机更方便的理解不同的文本内容,是否表述的是一个意思。


【扩展】余弦相似度


实战案例
给出核心代码:
python
from langchain ....#导包省略
def print_prompt(prompt):
print("="*20)
print(prompt.to_string())
print("="*20)
return prompt
class RagService(object):
def __init__(self):
self.vector_service = VectorStoreService(
embedding=DashScopeEmbeddings(model=config.embedding_model_name)
)
self.prompt_template = ChatPromptTemplate.from_messages(
[
("system", "以我提供的已知参考资料为主,"
"简洁和专业的回答用户问题。参考资料:{context}。"),
("system", "并且我提供用户的对话历史记录,如下:"),
MessagesPlaceholder("history"),
("user", "请回答用户提问:{input}")
]
)
self.chat_model = ChatTongyi(model=config.chat_model_name)
self.chain = self.__get_chain()
def __get_chain(self):
"""获取最终的执行链"""
retriever = self.vector_service.get_retriever()
def format_document(docs: list[Document]):
if not docs:
return "无相关参考资料"
formatted_str = ""
for doc in docs:
formatted_str += f"文档片段:{doc.page_content}\n文档元数据:{doc.metadata}\n\n"
return formatted_str
def format_for_retriever(value: dict) -> str:
return value["input"]
def format_for_prompt_template(value):
# {input, context, history}
new_value = {}
new_value["input"] = value["input"]["input"]
new_value["context"] = value["context"]
new_value["history"] = value["input"]["history"]
return new_value
chain = (
{
"input": RunnablePassthrough(),
"context": RunnableLambda(format_for_retriever) | retriever | format_document
} | RunnableLambda(format_for_prompt_template) | self.prompt_template | print_prompt | self.chat_model | StrOutputParser()
)
conversation_chain = RunnableWithMessageHistory(
chain,
get_history,
input_messages_key="input",
history_messages_key="history",
)
return conversation_chain
if __name__ == '__main__':
# session id 配置
session_config = {
"configurable": {
"session_id": "user_001",
}
}
res = RagService().chain.invoke({"input": "针织毛衣如何保养?"}, session_config)
print(res)vector_stores.py
python
from langchain_chroma import Chroma
import config_data as config
class VectorStoreService(object):
def __init__(self, embedding):
"""
:param embedding: 嵌入模型的传入
"""
self.embedding = embedding
self.vector_store = Chroma(
collection_name=config.collection_name,
embedding_function=self.embedding,
persist_directory=config.persist_directory,
)
def get_retriever(self):
"""返回向量检索器,方便加入chain"""
return self.vector_store.as_retriever(search_kwargs={"k": config.similarity_threshold})
if __name__ == '__main__':
from langchain_community.embeddings import DashScopeEmbeddings
retriever = VectorStoreService(DashScopeEmbeddings(model="text-embedding-v4")).get_retriever()
res = retriever.invoke("我的体重180斤,尺码推荐")
print(res)knowledge_base.py
python
"""
知识库
"""
import os
import config_data as config
import hashlib
from langchain_chroma import Chroma
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from datetime import datetime
def check_md5(md5_str: str):
"""检查传入的md5字符串是否已经被处理过了
return False(md5未处理过) True(已经处理过,已有记录)
"""
if not os.path.exists(config.md5_path):
# if进入表示文件不存在,那肯定没有处理过这个md5了
open(config.md5_path, 'w', encoding='utf-8').close()
return False
else:
for line in open(config.md5_path, 'r', encoding='utf-8').readlines():
line = line.strip() # 处理字符串前后的空格和回车
if line == md5_str:
return True # 已处理过
return False
def save_md5(md5_str: str):
"""将传入的md5字符串,记录到文件内保存"""
with open(config.md5_path, 'a', encoding="utf-8") as f:
f.write(md5_str + '\n')
def get_string_md5(input_str: str, encoding='utf-8'):
"""将传入的字符串转换为md5字符串"""
# 将字符串转换为bytes字节数组
str_bytes = input_str.encode(encoding=encoding)
# 创建md5对象
md5_obj = hashlib.md5() # 得到md5对象
md5_obj.update(str_bytes) # 更新内容(传入即将要转换的字节数组)
md5_hex = md5_obj.hexdigest() # 得到md5的十六进制字符串
return md5_hex
class KnowledgeBaseService(object):
def __init__(self):
# 如果文件夹不存在则创建,如果存在则跳过
os.makedirs(config.persist_directory, exist_ok=True)
self.chroma = Chroma(
collection_name=config.collection_name, # 数据库的表名
embedding_function=DashScopeEmbeddings(model="text-embedding-v4"),
persist_directory=config.persist_directory, # 数据库本地存储文件夹
) # 向量存储的实例 Chroma向量库对象
self.spliter = RecursiveCharacterTextSplitter(
chunk_size=config.chunk_size, # 分割后的文本段最大长度
chunk_overlap=config.chunk_overlap, # 连续文本段之间的字符重叠数量
separators=config.separators, # 自然段落划分的符号
length_function=len, # 使用Python自带的len函数做长度统计的依据
) # 文本分割器的对象
def upload_by_str(self, data: str, filename):
"""将传入的字符串,进行向量化,存入向量数据库中"""
# 先得到传入字符串的md5值
md5_hex = get_string_md5(data)
if check_md5(md5_hex):
return "[跳过]内容已经存在知识库中"
if len(data) > config.max_split_char_number:
knowledge_chunks: list[str] = self.spliter.split_text(data)
else:
knowledge_chunks = [data]
metadata = {
"source": filename,
# 2025-01-01 10:00:00
"create_time": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
"operator": "小曹",
}
self.chroma.add_texts( # 内容就加载到向量库中了
# iterable -> list \ tuple
knowledge_chunks,
metadatas=[metadata for _ in knowledge_chunks],
)
#
save_md5(md5_hex)
return "[成功]内容已经成功载入向量库"
if __name__ == '__main__':
service = KnowledgeBaseService()
r = service.upload_by_str("周杰轮222", "testfile")
print(r)file_history_store.py
python
def get_history(session_id):
return FileChatMessageHistory(session_id, "./chat_history")
class FileChatMessageHistory(BaseChatMessageHistory):
def __init__(self, session_id, storage_path):
self.session_id = session_id # 会话id
self.storage_path = storage_path # 不同会话id的存储文件,所在的文件夹路径
# 完整的文件路径
self.file_path = os.path.join(self.storage_path, self.session_id)
# 确保文件夹是存在的
os.makedirs(os.path.dirname(self.file_path), exist_ok=True)
def add_messages(self, messages: Sequence[BaseMessage]) -> None:
# Sequence序列 类似list、tuple
all_messages = list(self.messages) # 已有的消息列表
all_messages.extend(messages) # 新的和已有的融合成一个list
# 将数据同步写入到本地文件中
# 类对象写入文件 -> 一堆二进制
# 为了方便,可以将BaseMessage消息转为字典(借助json模块以json字符串写入文件)
# 官方message_to_dict:单个消息对象(BaseMessage类实例) -> 字典
# new_messages = []
# for message in all_messages:
# d = message_to_dict(message)
# new_messages.append(d)
new_messages = [message_to_dict(message) for message in all_messages]
# 将数据写入文件
with open(self.file_path, "w", encoding="utf-8") as f:
json.dump(new_messages, f)
@property # @property装饰器将messages方法变成成员属性用
def messages(self) -> list[BaseMessage]:
# 当前文件内: list[字典]
try:
with open(self.file_path, "r", encoding="utf-8") as f:
messages_data = json.load(f) # 返回值就是:list[字典]
return messages_from_dict(messages_data)
except FileNotFoundError:
return []
def clear(self) -> None:
with open(self.file_path, "w", encoding="utf-8") as f:
json.dump([], f)config_data.py
python
md5_path = "./md5.text"
# Chroma
collection_name = "rag"
persist_directory = "./chroma_db"
# spliter
chunk_size = 1000
chunk_overlap = 100
separators = ["\n\n", "\n", ".", "!", "?", "。", "!", "?", " ", ""]
max_split_char_number = 1000 # 文本分割的阈值
#
similarity_threshold = 1 # 检索返回匹配的文档数量
embedding_model_name = "text-embedding-v4"
chat_model_name = "qwen3-max"
session_config = {
"configurable": {
"session_id": "user_001",
}
}