一.写时拷贝
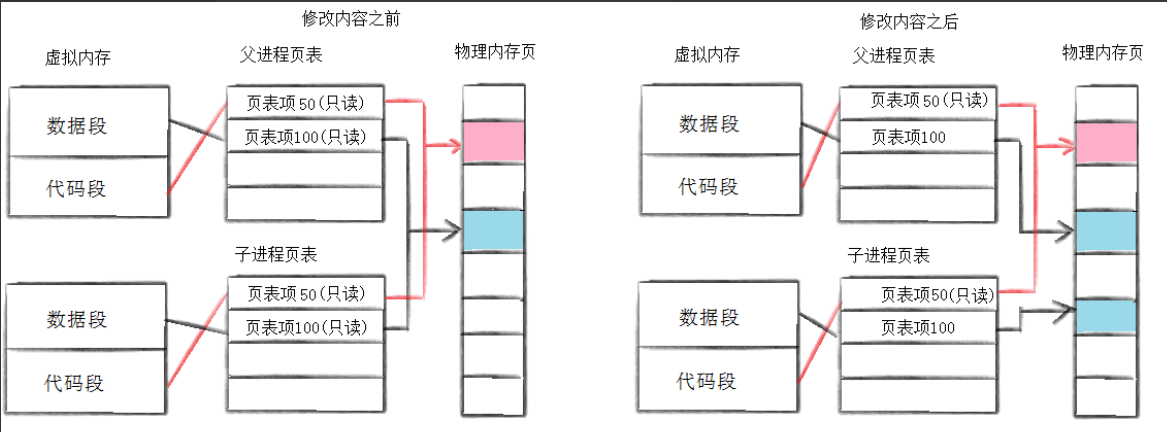
这个就是我们的父进程创建子进程的时候,父子进程的页表指向同一块区域,这里叫做惰性申请,就是为了我们内存空间更好的利用,没有直接给子进程一个新的物理内存,但是我们知道,我们父进程的数据只有你自己的时候肯定是可以修改的啊,这里数据给了只读权限就是为了限制子进程或者父进程修改这俩的同一块数据导致的一些问题,所以是只读权限,当某一个进程尝试着修改数据的时候,此时就会报错,此时操作系统就开始判断,看看你是不是野指针,如果是野指针进行写入的话,就会报运行时错误,如果是进程因为权限无法写入的时候,就会发生写时拷贝,此时就会在拷贝完成后修改我们的权限了,此时我们的进程就完成了独立,通过写时拷贝可以保证进程的独立性了,此时就需要把权限改回来了,所以此时数据的权限就是只读和可修改的权限了。
思考两个问题:

第一个问题就是父进程如果由1MB的数据呢,此时你子进程不一定要修改所有的数据啊,有可能值修改了一点,如果我们直接把数据分开,那么内存不是浪费了吗,如果父进程时100MB呢,你直接分开,那么你不就浪费了内存的资源,而且时间成本也增加了。
第二个问题:举个例子就是,我们a=10;a++;此时我们的a++操作本质就是把10拷贝过来,然后在这个基础上进行++的,不能只开辟空间。
思考一下下面的问题:

不会在物理内存上直接开辟,而是在虚拟内存上先开辟好空间,此时先不建立映射关系,当你用的时候,操作系统一查没有对应的物理空间,但是有虚拟空间,此时操作系统就知道了是自己的工作没有做到位,此时就会给你申请物理内存空间供你写入,再建立映射关系。
二 .fork常规⽤法
⼀个⽗进程希望复制⾃⼰,使⽗⼦进程同时执⾏不同的代码段。例如,⽗进程等待客⼾端请求,
⽣成⼦进程来处理请求。
⼀个进程要执⾏⼀个不同的程序。例如⼦进程从fork返回后,调⽤exec函数。
三.fork调⽤失败的原因
系统中有太多的进程
实际⽤⼾的进程数超过了限制
四.进程终⽌
先思考两个问题。
- 进程终止操作系统要做什么?
进程终⽌的本质是释放系统资源,就是释放进程申请的相关内核数据结构和对应的数据和代码。
2.main() return 0;return 0是什么意思?
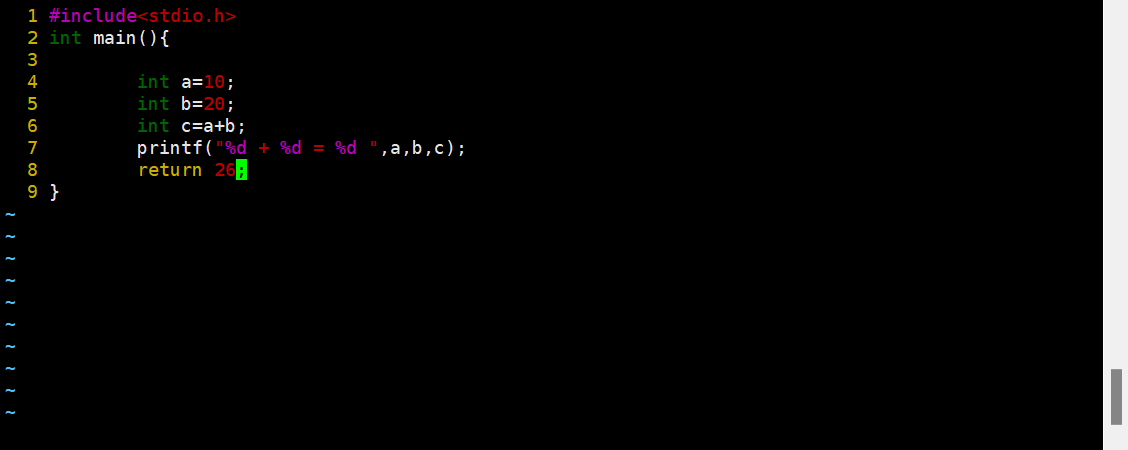
我们来看一下这个代码,这个return 的数据26叫做我们的代码退出码,会被系统获得,用于让系统判断我们的程序是否运行成功,我们怎么查看退出码呢?
我们的操作系统底层把退出吗返回给了一个?的变量中。

我们运行一次是我们的26,为什么第二次是0了啊,因为我们echo命令也是程序啊,这个程序的返回值是0,我们?存放的是最近一次的返回值。

我们来看一下这个什么的错误码吧。
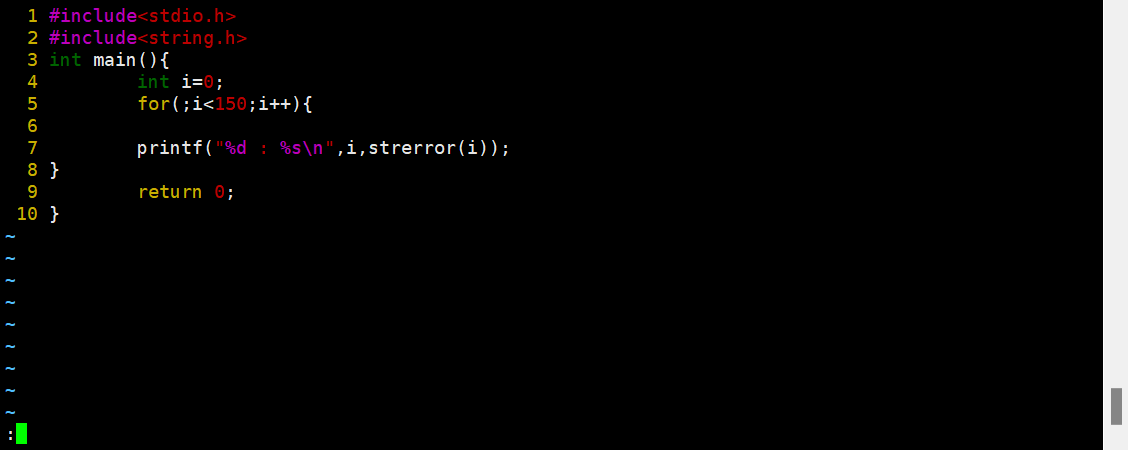
这是我们库中提供的一个方法,作用就是打印我们的错误类型。
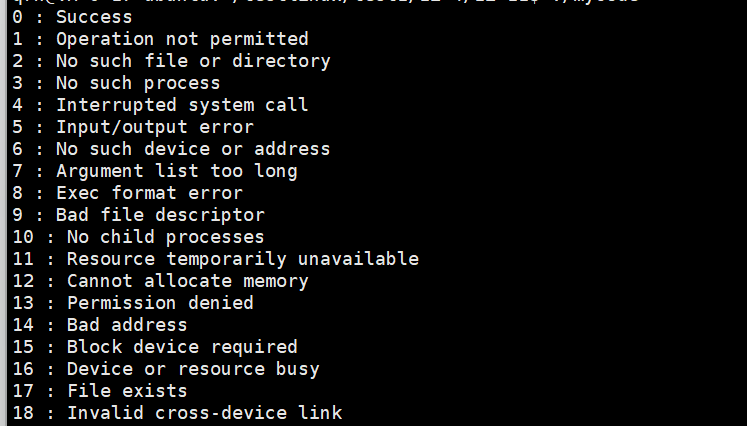
只截了一部分看一下。
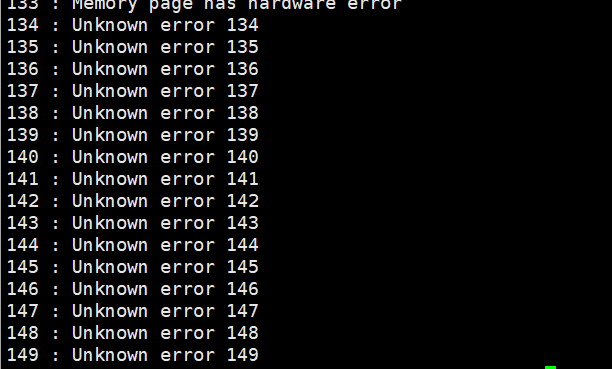
一共134个错误码对应的错误,错误码的作用就是给我们的用户返回错误类型的,让我们知道发生了什么错误。

看到没我们访问一个不存在的文件,返回值是2,正好对应我们的打印的错误信息。
4-1 进程退出场景

进程终止无非这三种情况,代码跑完了,退出码才是有意义的,通过退出码,我们就可以知道是什么类型的错误了,但是如果代码没跑完崩掉了,退出码此时无意义了,崩掉不就是代码异常了吗,操作系统要知道异常的原因,然后通过相应的信号杀掉进程,这个我们下面再详谈,这里先了解一下。
4-2 进程常⻅退出⽅法
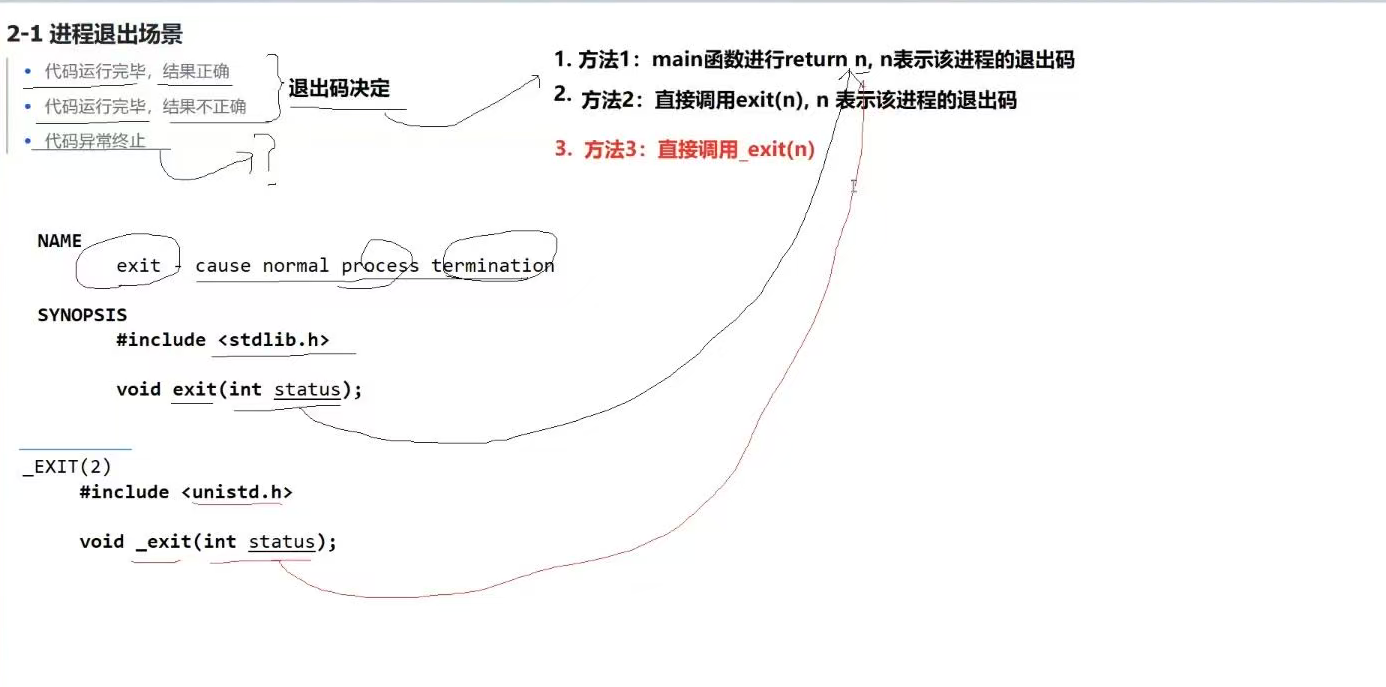
我相信第一个大家是很好理解的,就是main函数通过return进行退出,方法二就是通过调用exit的方法退出,第三个就是直接调用系统的_exit的方法进行退出。
相信大家就有个疑问了,return vs exit 的区别。
我们写个代码看一下。


此时返回的是1,是我们main函数中的返回值。


我们发现只运行了一句话,并且返回值是10,这就很清楚区别了,return是在main函数中结束进程的,其他函数中不结束,但是我们的exit则是在这个语句处直接结束进程并且返回。
我们下面再来看一种情况。


这两种退出方式都能退出进程,都能获取到进程的返回值1,但是这两个退出码有什么区别呢?
我们如果在输出语句中加入\n的话,它俩的区别就不大了,因为直接通过换行来刷新我们的显示屏来得到结果了,但是如果没有\n它俩就有区别了。
下面我们看看结果。
这是exit的。

他能在结束的时候会刷新我们的缓冲区的内容,此时它就会被打印到显示屏上了,但是我们的_exit是C库中的方法,由系统调用,我们此时不会打印任何结果,也就是我们的exit会刷新我们的缓冲区,但是_exit不会刷新。
总结一下就是我们的return和exit在进行结束进程的时候都会刷新我们的缓冲区,但是我们的_exit则不会。
最好结束进程的方法就是使用exit。
那为什么还要讲我们的_exit呢?
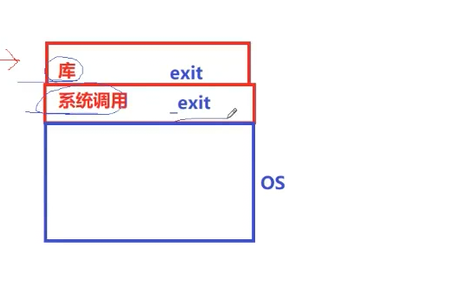
因为我们都知道库和系统调用是上下级的关系,我们终止进程的时候必定要进行系统调用的,而我们的_exit是系统调用的方法,我们的exit就是封装了_exit来实现完成进程终止的。
我们下面简单来认识一下什么叫输出缓冲区,我先来问一个问题,这个输出缓冲区一定不可能在哪里?
一定不可能在操作系统OS中,因为如果在操作系统当中的话,我们的exit都能刷新我们的缓冲区,你的exit又是封装的_exit,那_exit应该也能刷新缓冲区才对啊,所以我们的输出缓冲区只能在我们的库中了。
五.进程等待
5.1 进程等待必要性
之前讲过,⼦进程退出,⽗进程如果不管不顾,就可能造成'僵⼫进程'的问题,进⽽造成内存
泄漏。
另外,进程⼀旦变成僵⼫状态,那就⼑枪不⼊,"杀⼈不眨眼"的kill -9 也⽆能为⼒,因为谁也
没有办法杀死⼀个已经死去的进程。
最后,⽗进程派给⼦进程的任务完成的如何,我们需要知道。如,⼦进程运⾏完成,结果对还是
不对,或者是否正常退出。
⽗进程通过进程等待的⽅式,回收⼦进程资源,获取⼦进程退出信息
我们回顾一下前面说的僵尸状态,就是我们的父进程创建子进程,子进程结束了,它的代码和数据都被释放了,但是它的结构体这个节点还存在,此时如果父进程不管他,此时它就处于僵尸状态,所以说我们要是想解决这个问题,进程等待就是必须的了。
我们再来思考一下,我们的父进程是如何回收子进程的呢?
它是通过调用我们的wait相关的一些函数,我们下面先来学习一个wait,我们了解一下它们的功能。
5.2 进程等待的⽅法
5-2-1 wait⽅法
include <sys/types.h>
include <sys/wait.h>
pid_t wait ( int * status);
返回值:
成功返回被等待进程 pid ,失败返回 -1 。
参数:
输出型参数,获取⼦进程退出状态 , 不关⼼则可以设置成为 NULL
前两个是头文件,pid_t是它的返回值类型。
下面举个例子来理解一下。
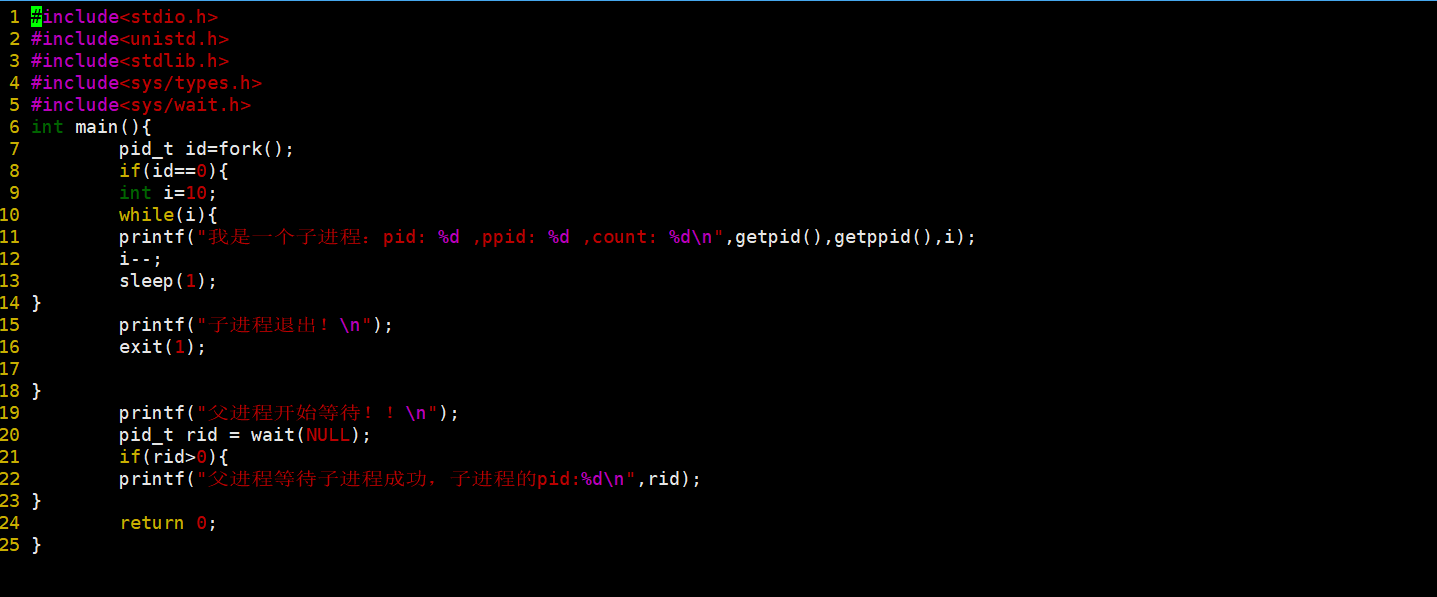
看一下这个代码。
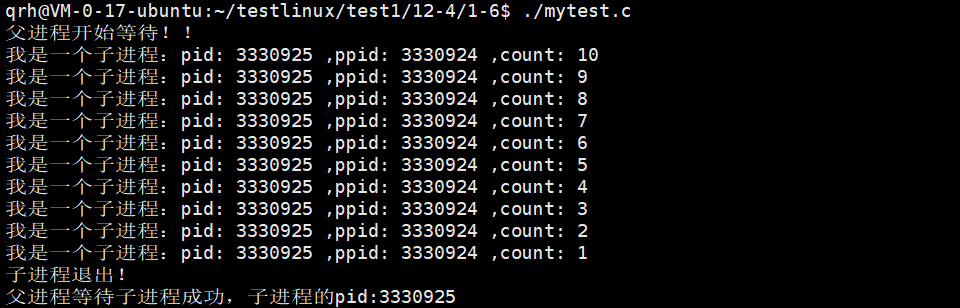
我们可以看到的是,我们的父进程确实通过wait回收子进程了,父进程等待子进程执行完才结束,但是我们并没有看到我们所谓的僵尸这一种状态,下面我们对代码进行修改。
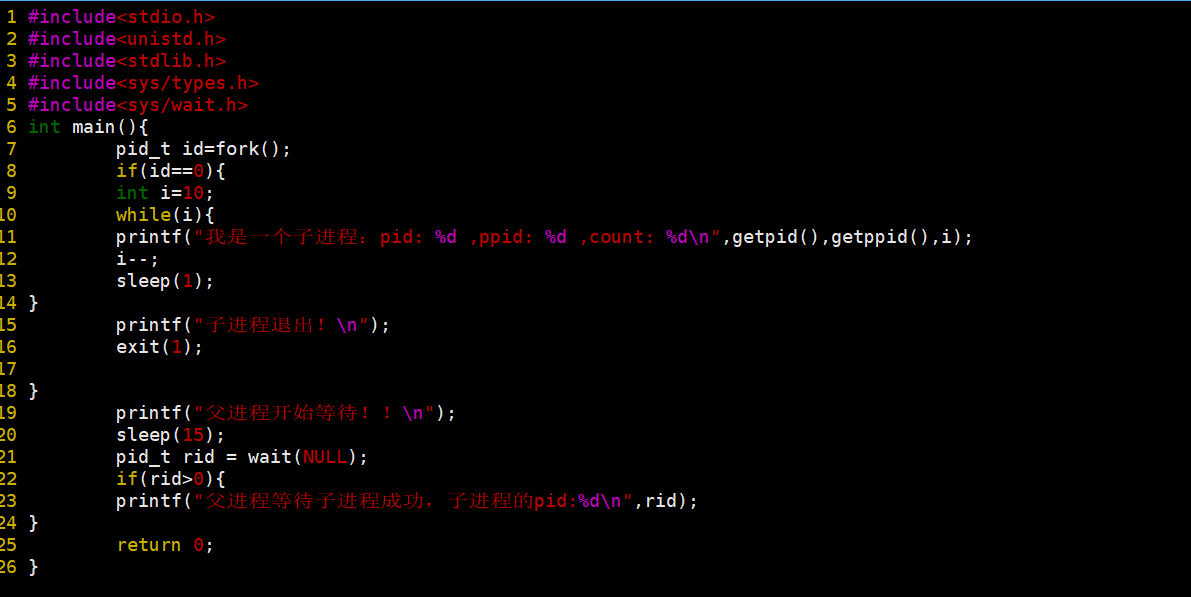
我们再来运行一下。
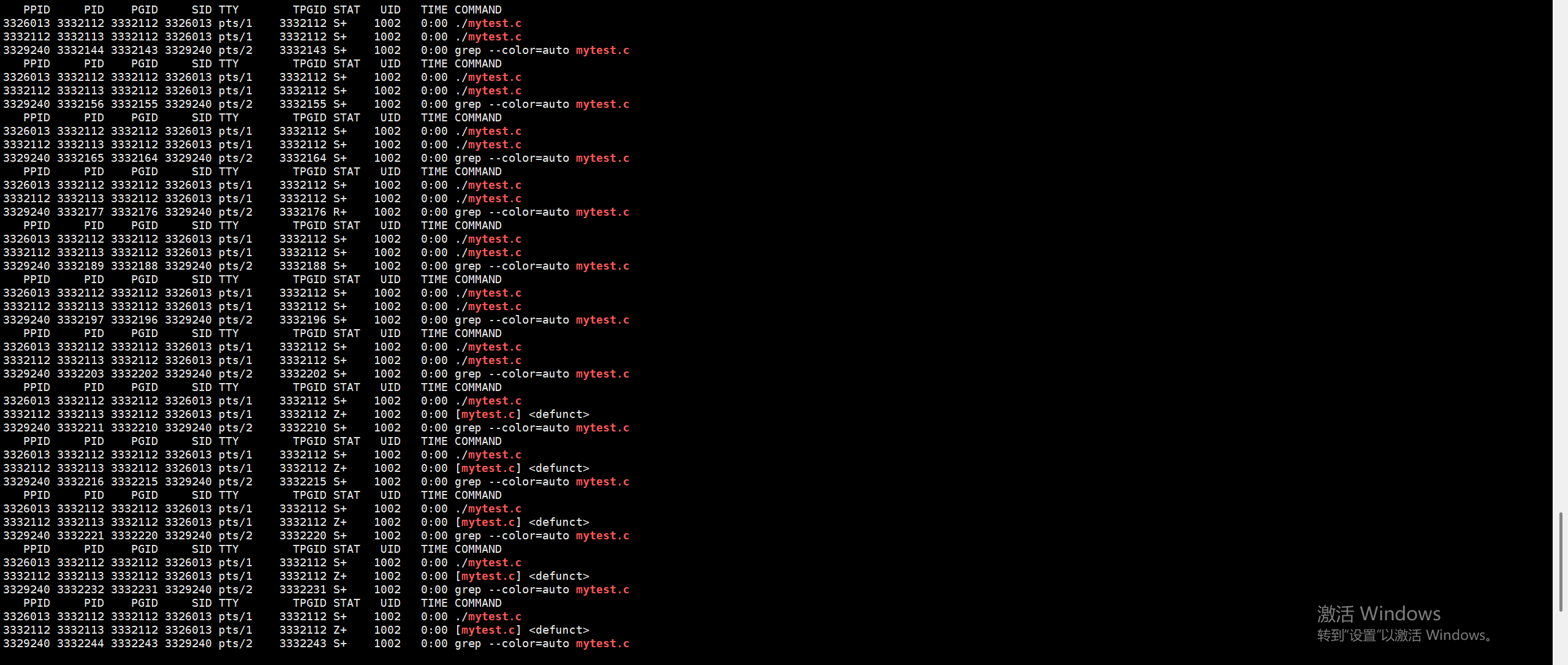
从这张图片我们可以看到在等待的15秒期间确实出现了僵尸状态,这时候就需要我们通过wait来回收了。
我们先简单了解一下这个wait的功能,但是我们日常使用的时候我们一般不用wait来回收,而是使用我们下面的这个waitpid来回收的。
5-2-2 waitpid
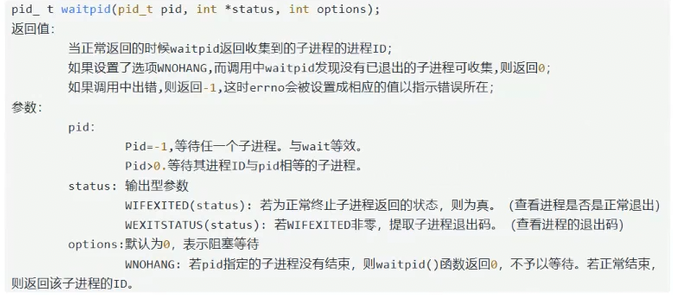
这是一些基本的用法。
我们还是直接来看例子吧。 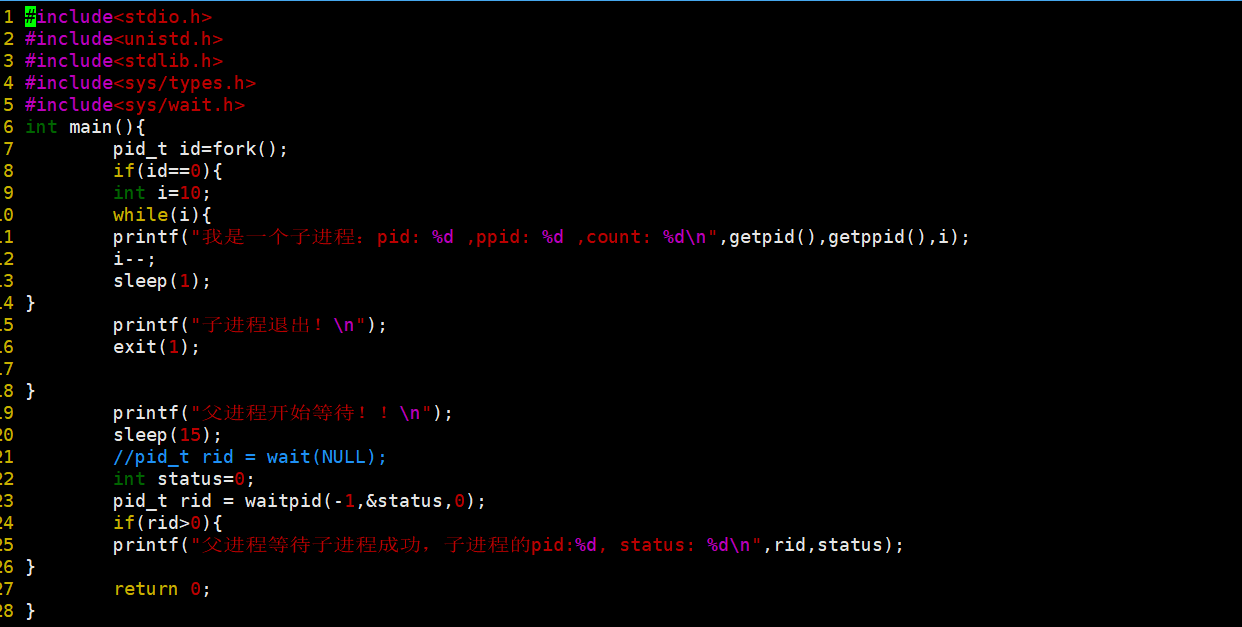
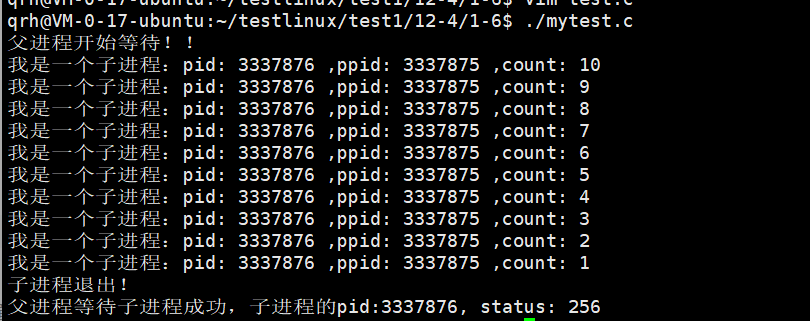
我们看到结果之后就有点疑惑了,我们的status为什么变成256了呢?这是什么情况呢?
我们的status不仅仅是退出码。
我们的int是占4个字节32位的,我们的高16位先不考虑,我们只看低16位。
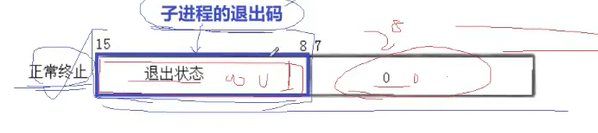
我们低16位的高8位表示的是退出码。

最后气位表示的是信号编号,就是当你被信号所杀的时候,表示这个信号的编号,中间那一位是core dump标志,不用管。
我们的子进程的退出码的范围是0,255,我们例子中的退出码是1,也就是我们的退出状态时00000001,七个0,一个1表示十进制的1,然后带上我们后面的八位,全部都是0,此时就是256了,这才是status的真正的值,那如果我要是就要看真正的退出码呢,那就需要将这个二进制右移八位即可。
就是如图的操作。

发现拿到了真正的退出码了。
你的进程异常了本质就是操作系统给你的进程发送信号了,我们看一下都有什么信号。
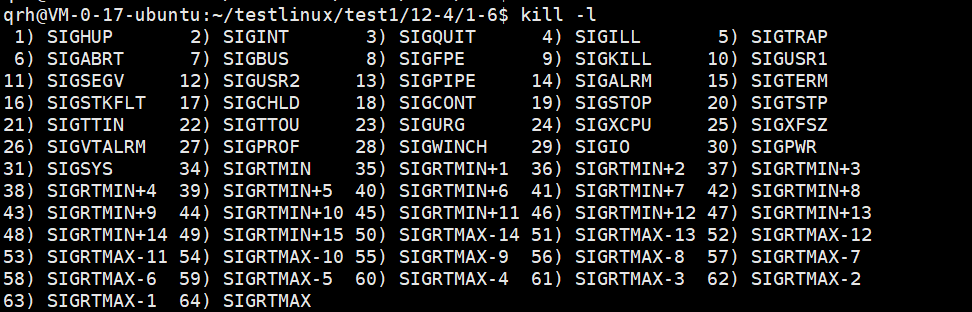

代码正常运行完毕,结果正确,退出信号为0,退出码为0,如果结果不正确,退出信号为0,退出码非0,代码异常终止,退出信号非0,退出码无意义。
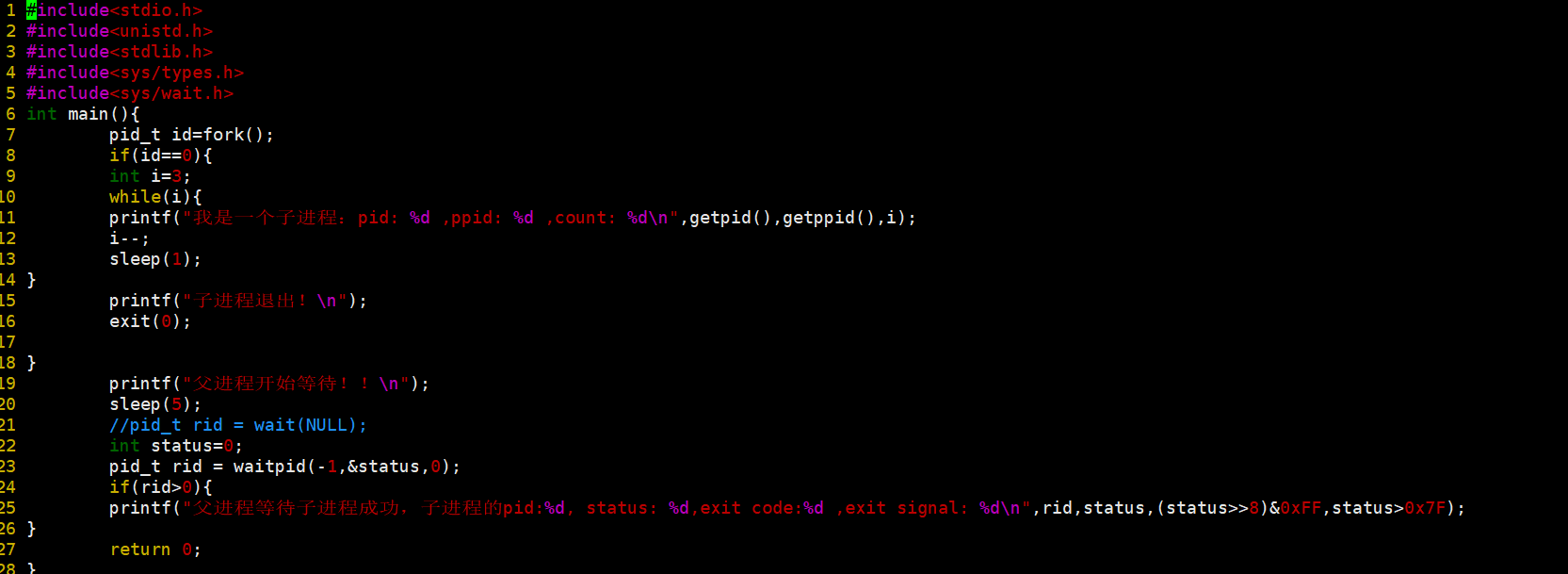

我们可以通过如图拿到我们的退出信号。
我们验证一下。
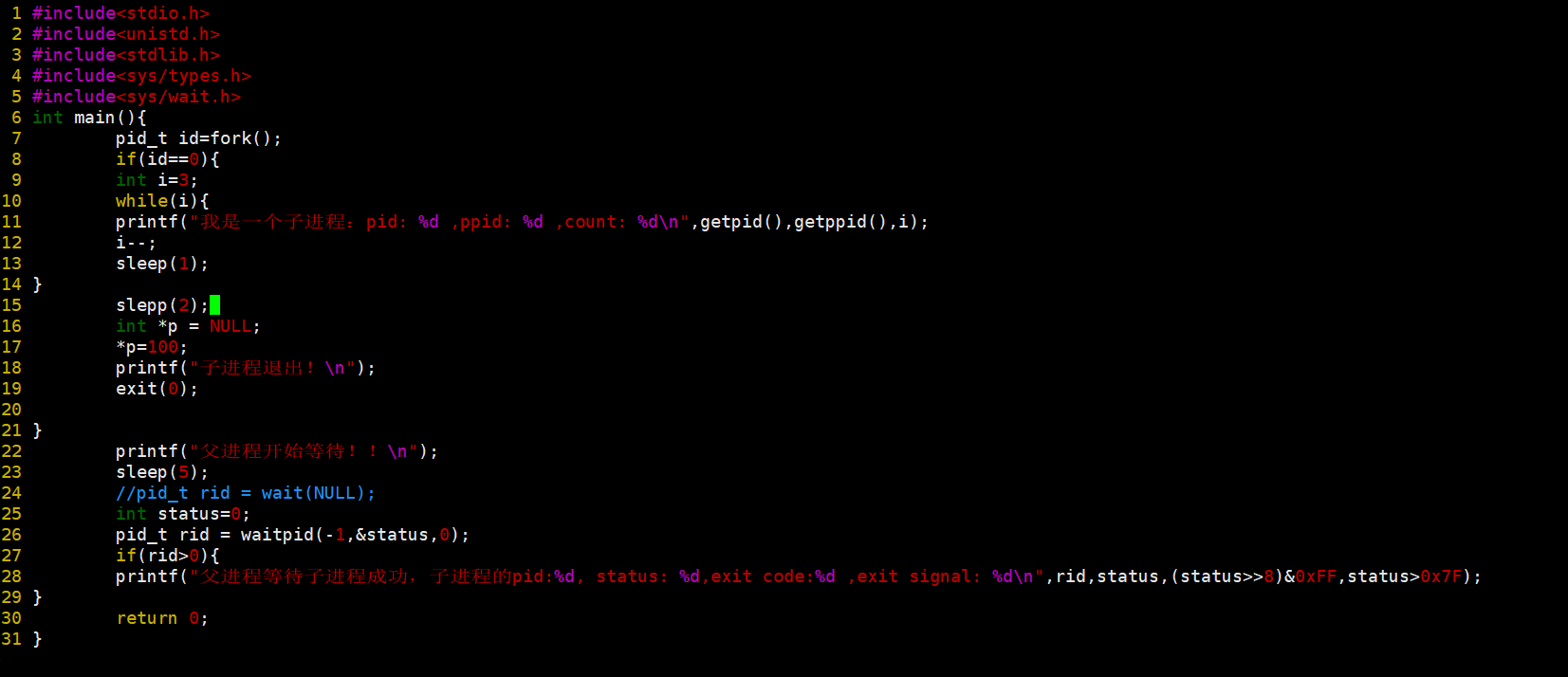
我们故意写一个异常,我们看看退出信号怎么变化。(纠正一下上图的错误,status>0x7F应该是status&0x7F)
刚才时0,现在我们看看是多少。
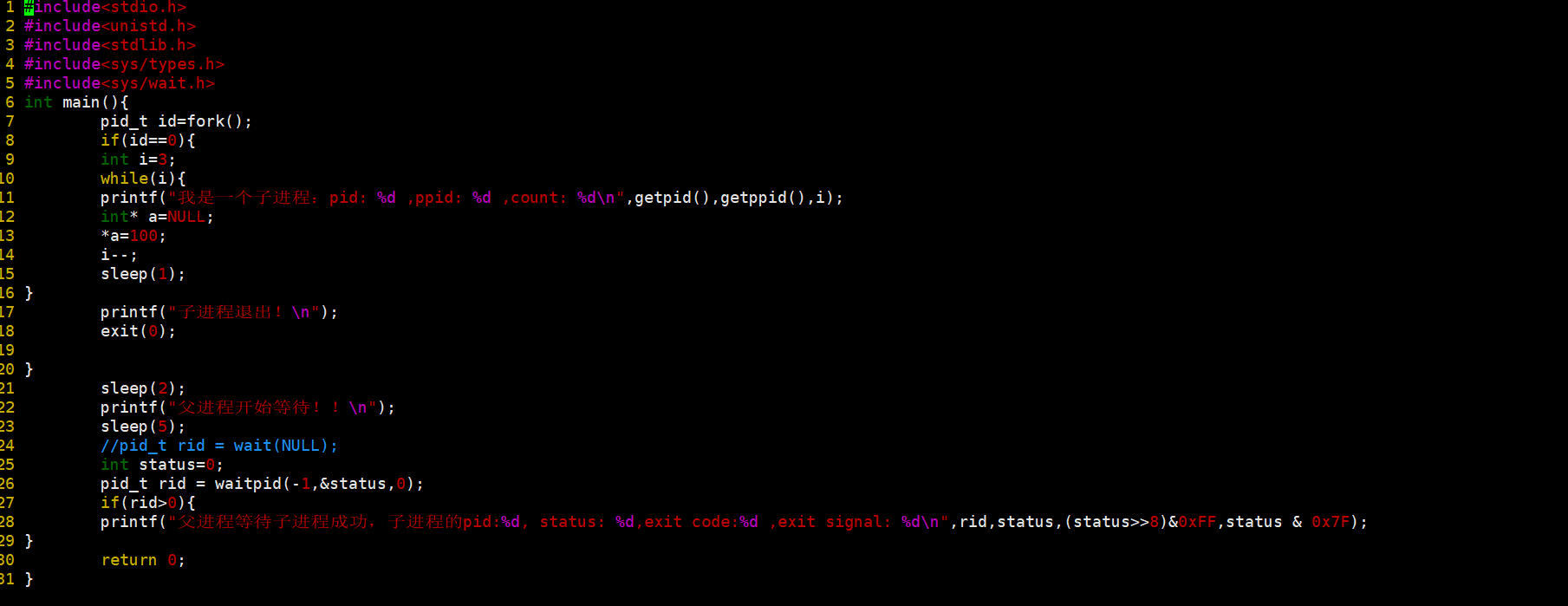
我故意写一个异常,我们再来看一下退出信号的变化。

此时退出信号就变了,这里只是让你们简单了解一下这些异常信号什么的。
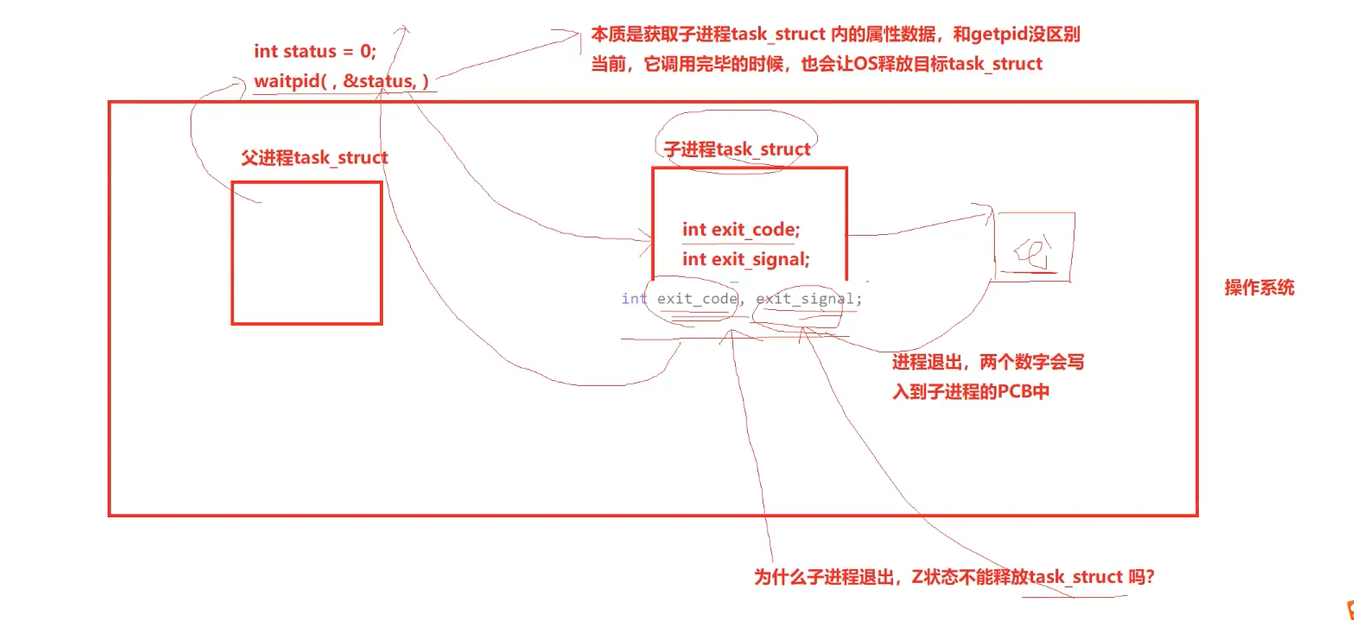
再来理解上图,为什么子进程的PCB不能释放呢?
因为父进程的PCB包含着退出码和退出信号这些信息呢,所以不能释放,它要反映给父进程呢,调用完才会释放。
下面我们介绍两个宏。
WIFEXITED(status): 若为正常终⽌⼦进程返回的状态,则为真。(查看进程 是否是正常退出)
WEXITSTATUS(status): 若WIFEXITED⾮零,提取⼦进程退出码。(查看进程 的退出码)
作用就是如上面所示的作用,下面我们使用一个例子来看一下。
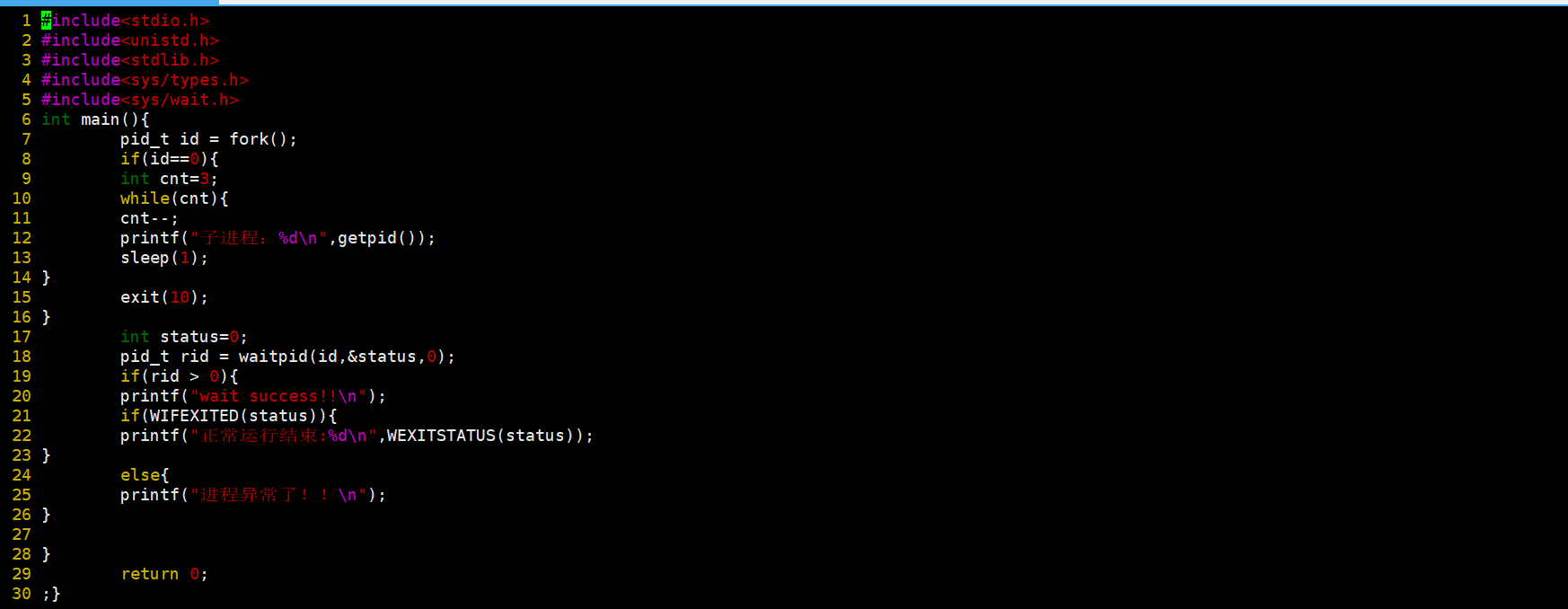
我们使用了这两个宏,一个是判断是否正确退出的,一个是获得退出码的。
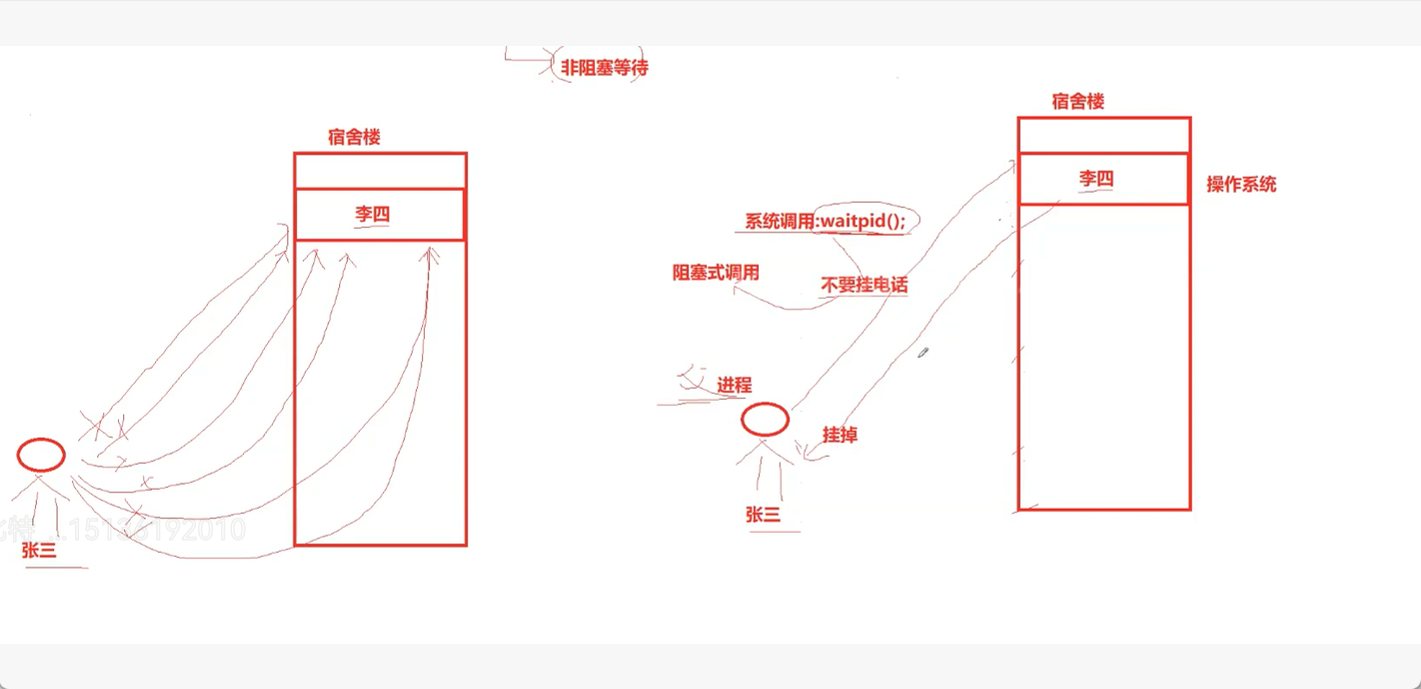
我们来看一下左边是非阻塞调用,就是不断的调用来判断进程是否结束,举个例子吧,就是你去找你朋友玩,你朋友说让你等十分钟,然后你打一次电话,你朋友说马上,你等了一分钟又打了一次,还说马上,你就一直打,一直催直到下来,阻塞调用就是你打个电话不挂断,直到你朋友下来,就是非阻塞就是你可以理解为父进程一直问操作系统结束没,问一次得到一个答案走了,问一次得到一个答案走了,而阻塞就是只在结束的时候直接就来了,中间不过多询问,可以简单这么理解,非阻塞调用就是调用多次waitpid来看子进程的退出状态,而阻塞调用则是只需要调用一次waitpid即可。
下面我们用代码来认识一下这两个等待过程。
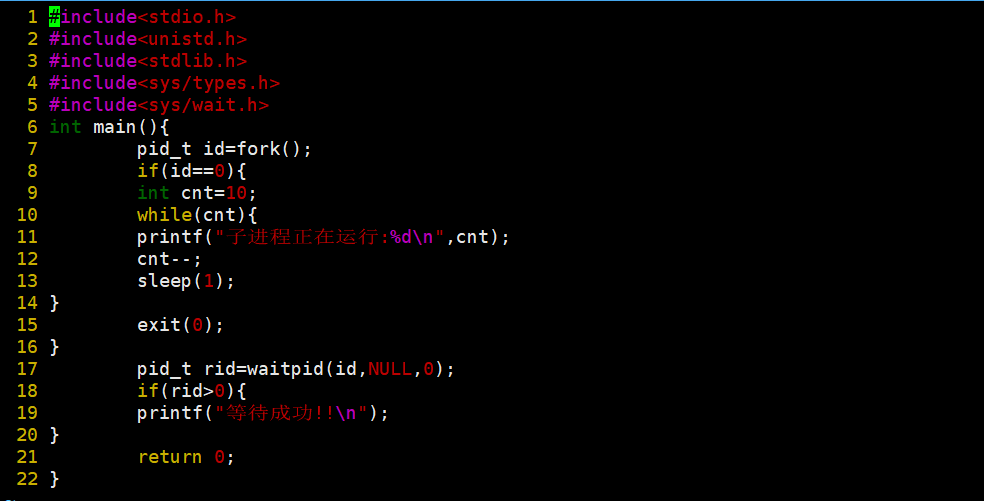
这是我们阻塞等待的过程我们上面经常写到,不过多赘述,下面我们重点来看看非阻塞怎么写。
在写之前我们需要先了解一个东西。
 这是我们非阻塞的规则,当我们的父进程调用waitpid的时候,发现子进程结束了,就返回大于0的一个数,一般都是子进程的pid,如果子进程没有退出就返回0,如果等待失败就返回小于0的数,我们下面来实现一下。
这是我们非阻塞的规则,当我们的父进程调用waitpid的时候,发现子进程结束了,就返回大于0的一个数,一般都是子进程的pid,如果子进程没有退出就返回0,如果等待失败就返回小于0的数,我们下面来实现一下。
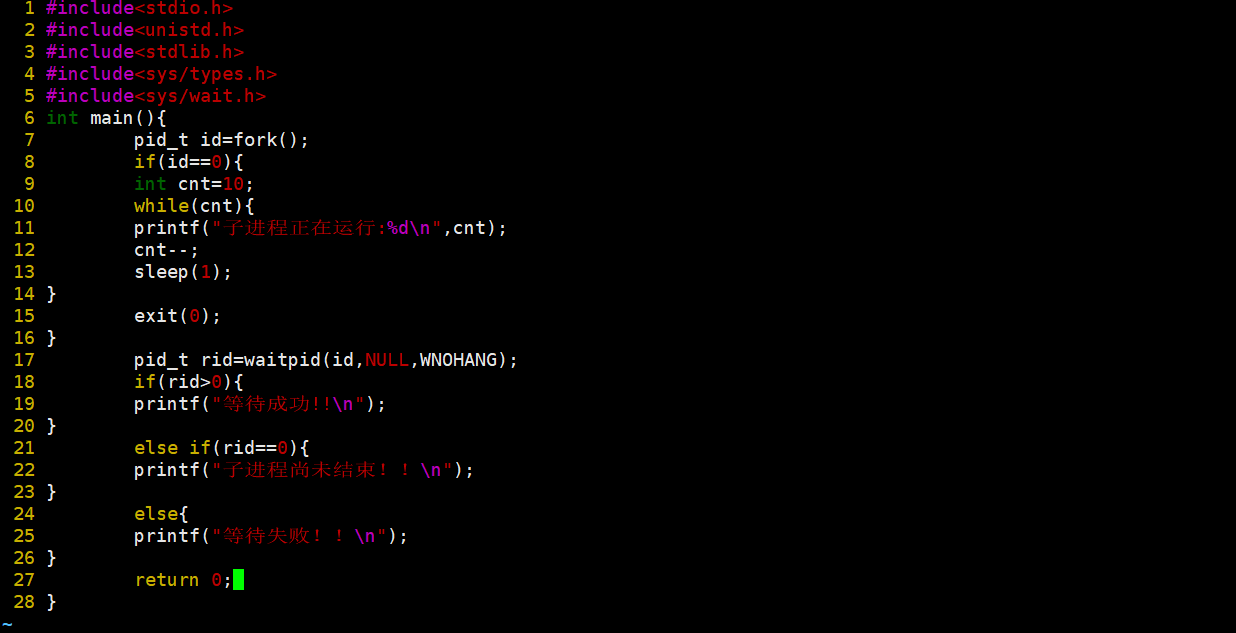 这个主要就要关注两点即可,一点就是这个waitpid的第三个参数,WNOHANG表示的是我们的非阻塞调用,还要就是三个不同的返回值。
这个主要就要关注两点即可,一点就是这个waitpid的第三个参数,WNOHANG表示的是我们的非阻塞调用,还要就是三个不同的返回值。
我们运行一下。
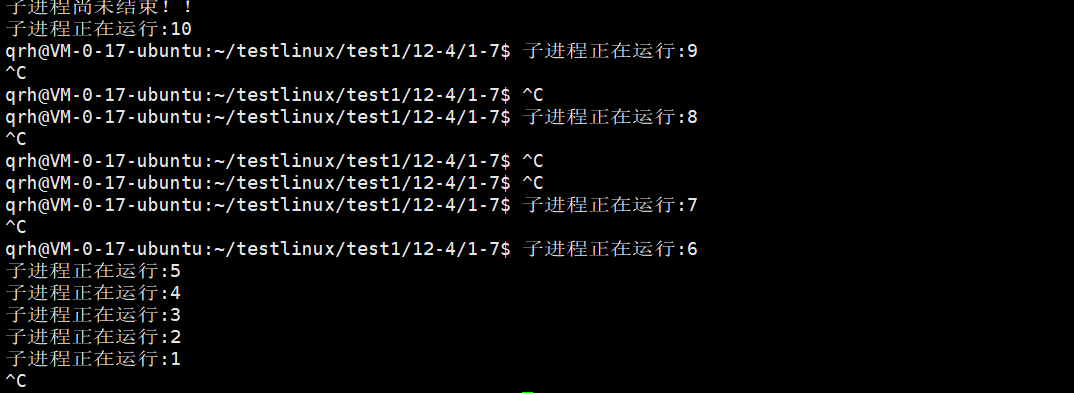
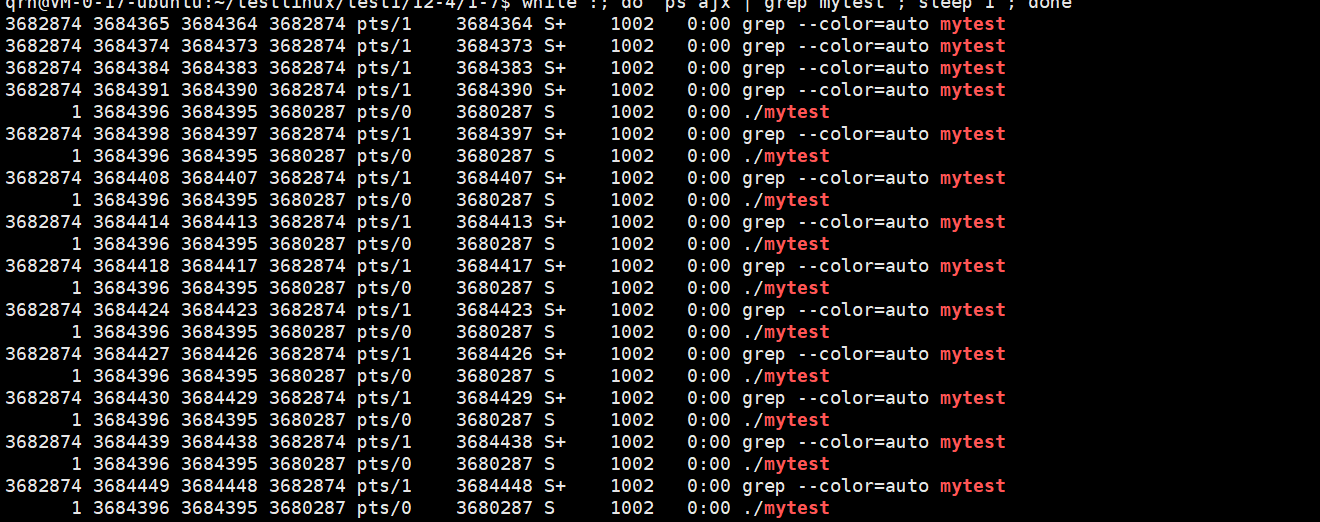 我们观察到图中的信息可能有三个疑问,第一个就是这个为什么父进程先打印了,然后打印的子进程,第二个问题就是Ctrl+c为什么杀不掉进程了呢,第三个问题就是为什么子进程的父进程id变成1了啊。
我们观察到图中的信息可能有三个疑问,第一个就是这个为什么父进程先打印了,然后打印的子进程,第二个问题就是Ctrl+c为什么杀不掉进程了呢,第三个问题就是为什么子进程的父进程id变成1了啊。
下面依次解释这三个问题,第一个问题的原因就是,因为我是非阻塞的,所以我父进程直接就开始运行调用waitpid了,不再等待子进程了,先解释第三个,因为我们的父进程是非阻塞等待,所以直接就运行然后结束了,此时这个子进程没有父进程就变成孤儿进程了,所以此时要被root领养,所以是1,第二个问题就是,此时这个子进程不被终端管理了,你是无法直接通过Ctrl+c杀死它的,之前我们提过一嘴。
下面我们修改一下代码。
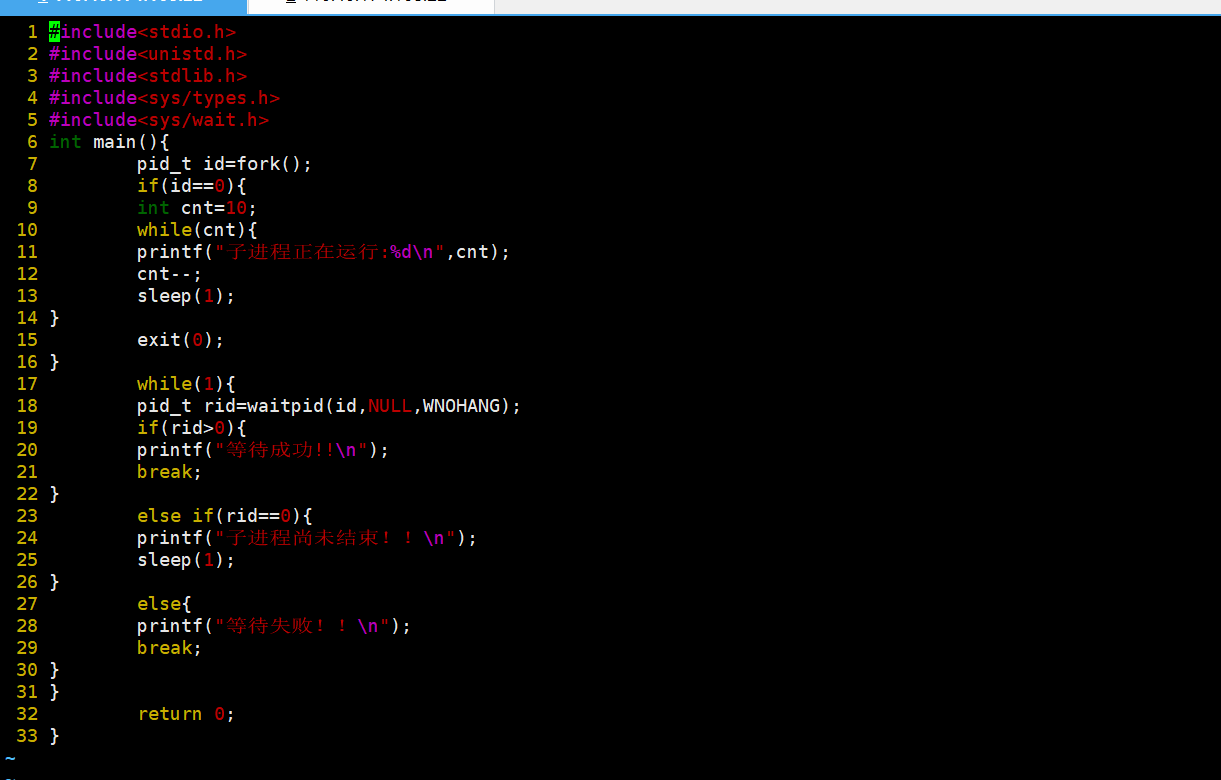 只需要加个循环即可。
只需要加个循环即可。
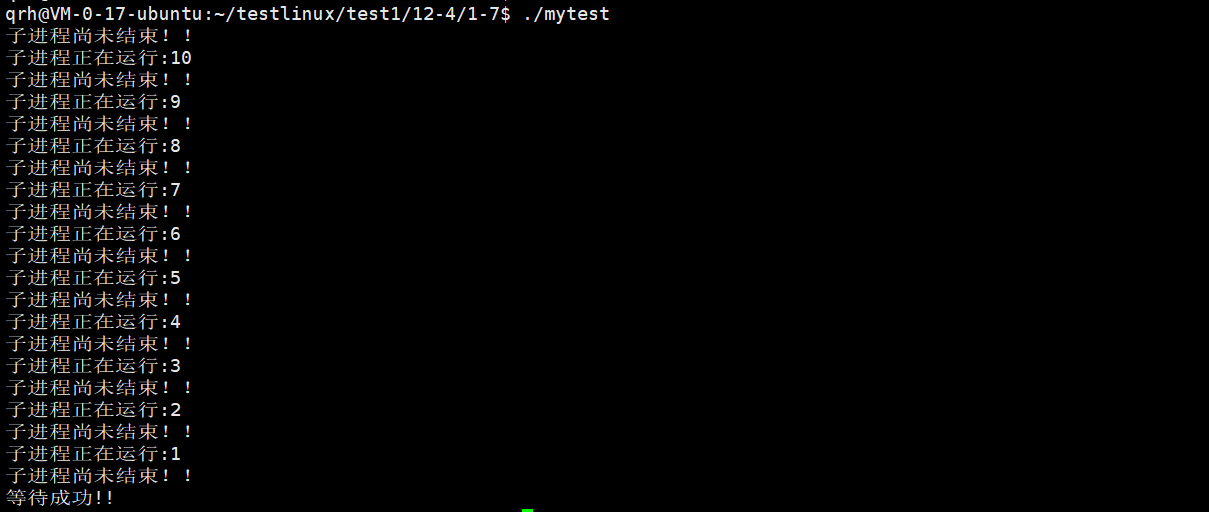 得到了这个现象符合我们的预期。
得到了这个现象符合我们的预期。
非阻塞有什么好处呢?
阻塞调用就是你的子进程不执行完成,我的父进程就不动,但是我的非阻塞运行就是不断调用waitpid吗,等待的间隙我还可以做其他事情啊,所以效率会更高一点点。
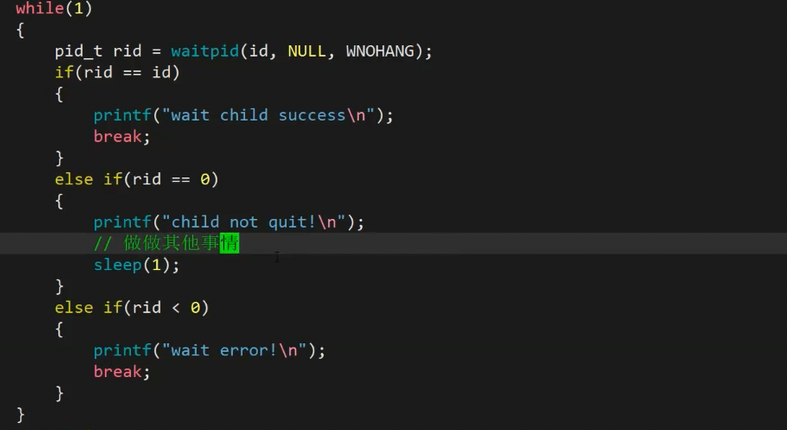
就是这个思路,子进程没有退出可以让父进程做做其他事情。
我们下面通过一个场景来看一下父进程可以干什么。

我们想演示这个场景的话需要这三个文件,首先我们先来了解一下什么十.hpp文件。

简单来说就是.hpp文件就是生命文件加实现文件可以简单的这么理解。
下面我们分别来实现一下这三个函数。
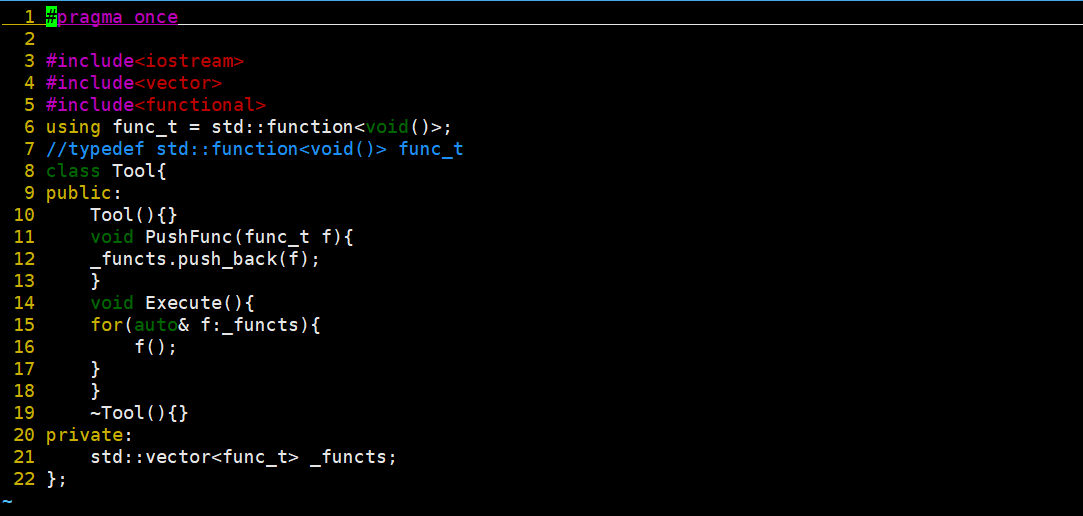
这是我们的Tool文件,首先我们先来看第六行这个东西,想必有点陌生,下面我们来解答一下。
using:类型别名声明(C++11 新特性)
你可以把它理解成 "给某个类型起一个外号",和旧的 typedef 作用类似,但写法更清晰、更灵活。
std::function<void()>:函数包装器
std::function 是 C++11 标准库 <functional> 头文件里的一个函数包装器模板,作用是:
把 "普通函数、Lambda 表达式、类成员函数、仿函数" 等各种可调用对象,包装成一个统一的类型
模板参数 void() 是关键,它表示:void → 这个可调用对象没有返回值 ;() → 这个可调用对象没有参数 。简单说,std::function<void()> 就是 "能装下所有「无参数、无返回值」的可调用对象的容器"。
整句的含义就是给这个包装器起了个别名和typedef std::function<void()> func_t这个的效果是一样的。
using相较于typedef比较明显的一个优势就是这个typedef无法给模板参数的函数或者什么的起别名,但是我们的using则是可以,举个例子。
template<class T>
class A{
}
typedef A<T> aa;这种写法是错误的,因为这个typedef需要明确的类型。
using A<T> aa;这种写法则是正确的。
下面我们再来看看我们Task文件的书写。
这就是模拟写的几个任务。
我们再来实现一下test.c我们的测试文件。
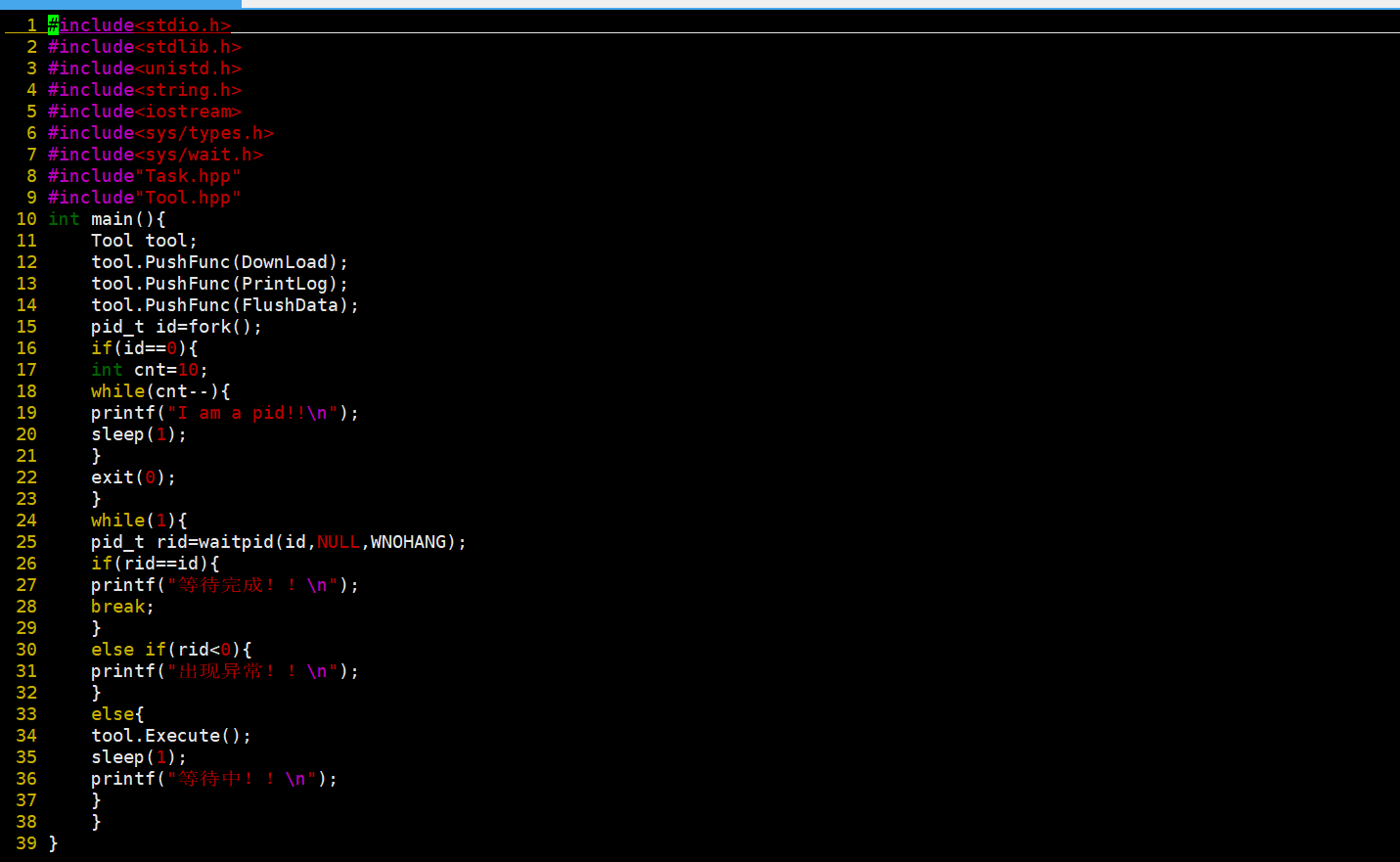
这是我们的测试函数,我们就是通过把这几个函数都插入到我们的vector容器当中,然后只要我们的子进程没有结束,我们就要执行一下我们的这个Execute方法,这个方法的作用就是调用我们的这些方法的。
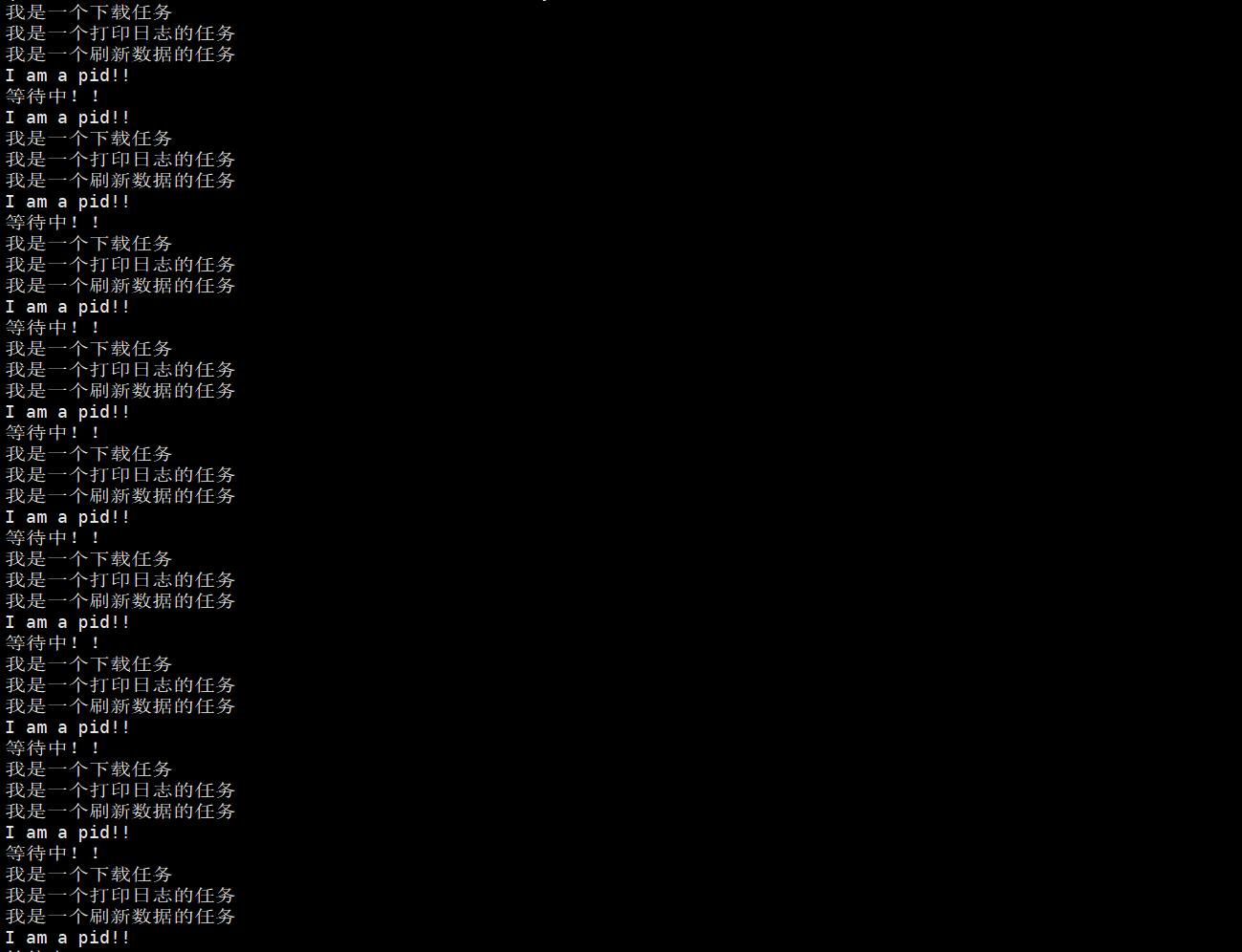
就是这个样子了,我们在等待子进程的过程中,父进程还可以做其他事情,这就是waitpid的优势。
六.进程程序替换
fork() 之后,⽗⼦各⾃执⾏⽗进程代码的⼀部分如果⼦进程就想执⾏⼀个全新的程序呢?进程的程序替换来完成这个功能!程序替换是通过特定的接⼝,加载磁盘上的⼀个全新的程序(代码和数据),加载到调⽤进程的地址空间中!
就是我们原来写的代码,我们的子进程继承我们fork()之后的父进程的代码和数据都是共享给子进程的,但是我们的子进程如果想自己写自己的代码,成为一个独立的代码,不继承父进程的代码和数据呢,就是拥有自己的代码和数据。
6.1 进程替换的原理
⽤fork创建⼦进程后执⾏的是和⽗进程相同的程序(但有可能执⾏不同的代码分⽀),⼦进程往往要调⽤⼀ 种 exec 函数以执⾏另⼀个程序。当进程调⽤⼀种 exec 函数时,该进程的⽤⼾空间代码和数据完全被 新程序替换,从新程序的启动例程开始执⾏。调⽤ exec 并不创建新进程,所以调⽤ exec 前后该进程的 id 并未改变。
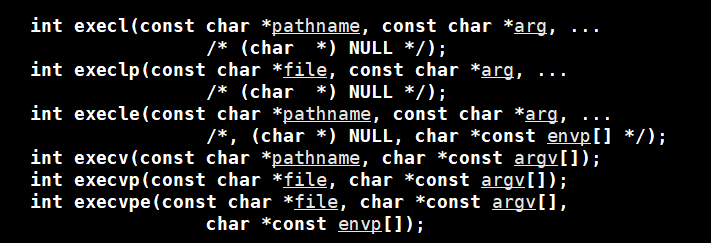
6.2 使用替换
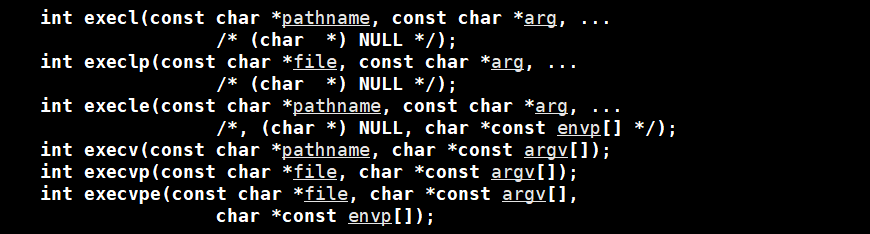
替换函数有如上图的六个。

我们先来使用一下这个函数,这个就是第一个参数就是要传入你想要执行的代码和数据的那个文件的地址,后面的参数就是可变参数模板,我们在之前的c++博客中也有讲到这个东西。
第二个参数传入的是我们的要执行的文件的名称。最后的可变参数我们一般传入的是我们传给程序命令行的选项。
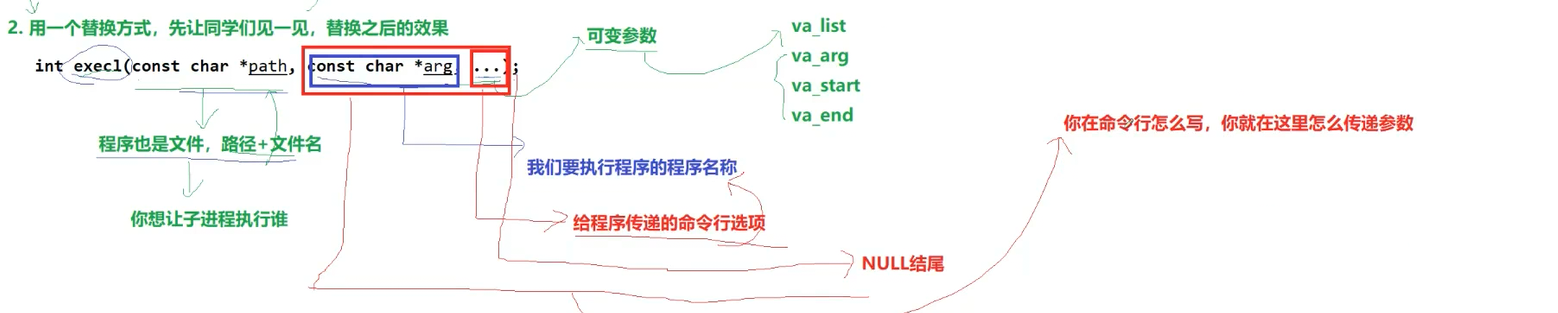
我们简单刨析一下第三个参数吧。
我们直接来看一段代码加上一张图片来理解一下。
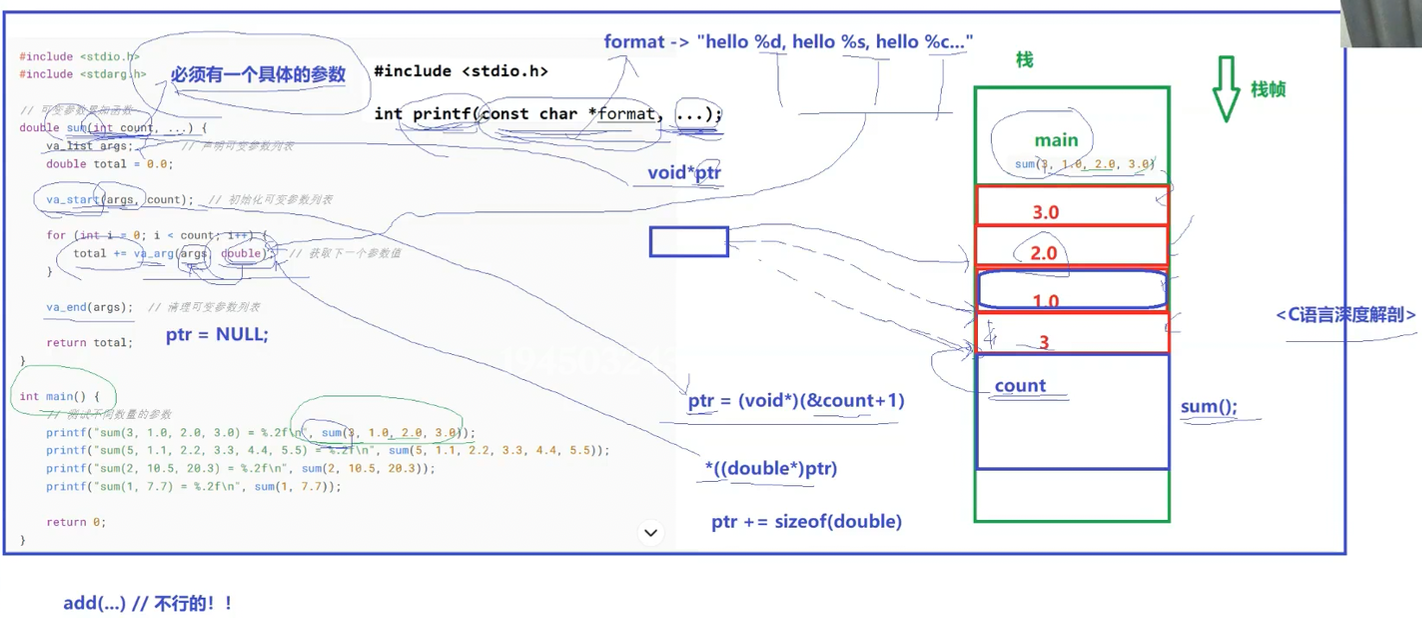
我们简单说一下就行了,首先我们看这个函数

我们代码中的第一行是声明一个可变参数列表的作用,我们调用的这个va_start函数,这个函数的第一个参数就相当于我们定义了一个void* ptr,我们画一下函数栈帧,第二个参数是我们的起始地址,下面我们看一下即可。
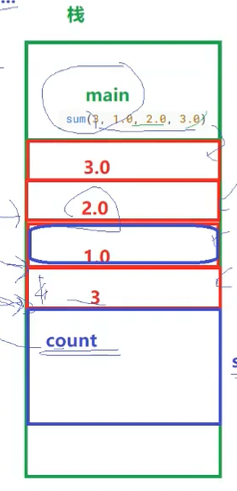
开始我们的ptr指针你可以认为指向空。然后通过ptr=(void*)(&count+1),这样就能指向我们的形参了,所以我们第一个参数一定要是一个确定的形参,不能是函数模板,第一个参数的作用就是让我们能找到我们可变参数模板的形参的。循环中那个函数的作用就是让我们的这些形参都转换为double类型的就是(double)(*ptr)这样的形式,最后一个函数的作用就是让我们的ptr指向NULL的。
我们下面用一个实际的例子来看一下吧。

这是我们写的调用execl的代码,第一个参数是路径,第二个参数是要执行的文件的名称,第三个参数是我们的选项,下面我们来看一下执行完成的结果吧。需要注意的是,选项参数要以NULL结尾。
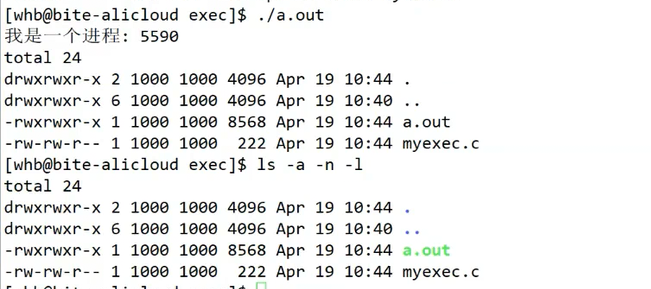
我们发现符合我们的预期,确实执行了这个ls指令,和我们直接执行ls指令的结果是一样的。
为什么我们的最后一条语句并没有执行呢?
因为我们替换了,此时执行的就是ls文件中的内容了,后续内容将不会被执行了。
如果替换失败就会返回-1,是这个替换函数的返回值是-1,但是我们还会执行自己的代码,最后的返回值还是由我们自己代码中返回值决定的,看我们上面的代码,如果替换失败,这个excle函数的返回值是-1,但是我们最终得到的返回值还是10。
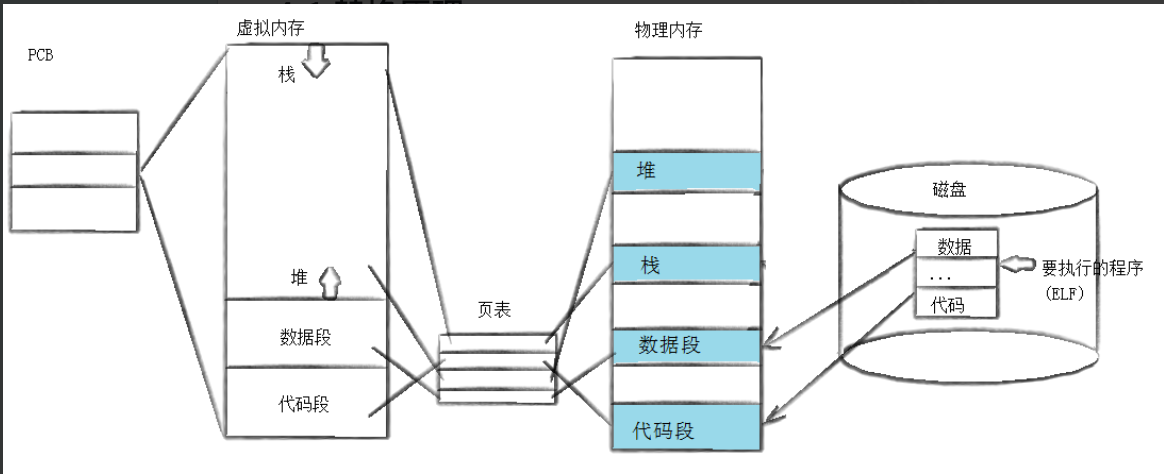
此时我们就想,子进程的代码和数据如果被替换会影响父进程吗?
我们知道,子进程的数据会进行写时拷贝,我们的代码如果被替换,子进程又是继承父进程的代码的,那么父进程不会被影响吗?
但让不会的,因为代码也会执行写时拷贝的。
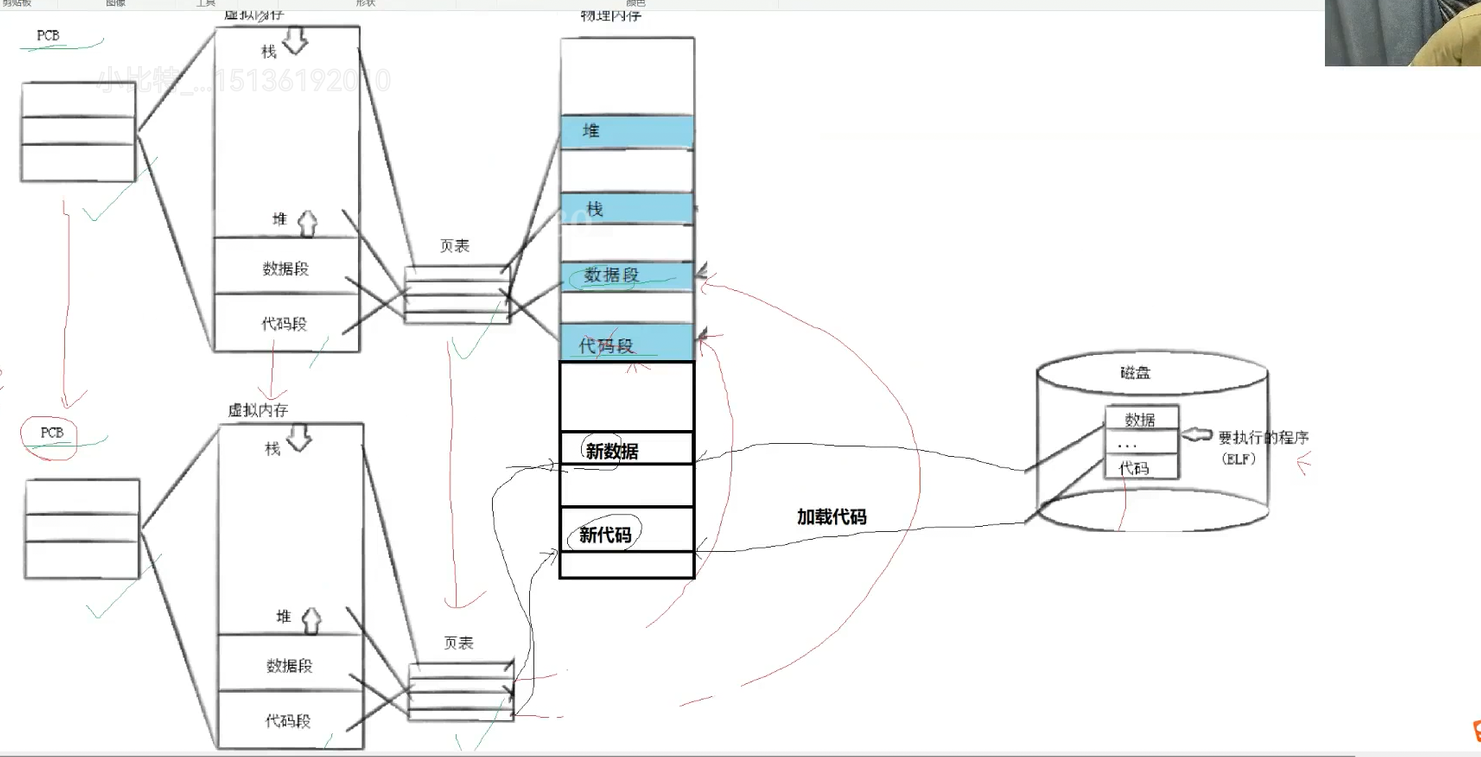
我们看这个图来理解一下,原本我们父子进程共享的都是父进程物理内存中的代码和数据的,但是如果你进行替换的话,此时就会从磁盘中把这个文件的内容加载到内存当中,然后此时你的子进程的页表就会指向新的代码和数据段了。
下面我们把这几个函数的用法都用一下让我们了解一下。
第一个我们使用过了,第三个和第一个的用法是完全相同的,你写入的参数什么的都是相同的,只是形参的逻辑不一样,一个是使用了可变参数模板,一个是用数组。
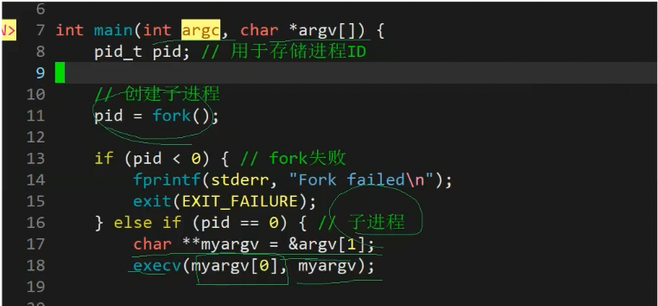
我们来看一下这个代码,这个就是我们使用main函数的两个形参,我们之前也讲过这两个的作用,此时我们写个指令,比如我们生成的这个代码的可执行程序是myload,我们看下图。
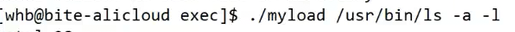
就是这个代码,此时我们的从ls及其之后的内容都会给到我们的argv这个数组中,然后我们通过一个二级指针指向我们的argv【1】的地址,此时我们把这个myargv0给到第一个参数就是我们的地址/usr/bin/ls,此时我们第二个参数就是全部内容了,此时我们就能通过命令行直接指定我们的子进程要执行什么程序了。
我们下面在来看一下第二个。


就是直接输入指令名字,然后系统自己去PATH中找的。
第一个ls表示你要执行谁,第二个ls表示你要怎么执行它,就是ls再加上后面的选项。

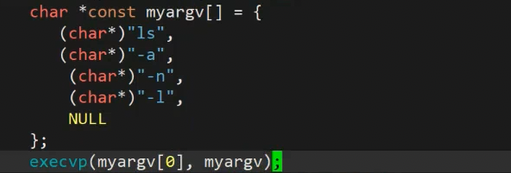
就是这样使用的。
下面我们再来看一个。

第三个参数是传环境变量的。
这个函数的意思就是打印出进程所有的命令行参数和环境变量。
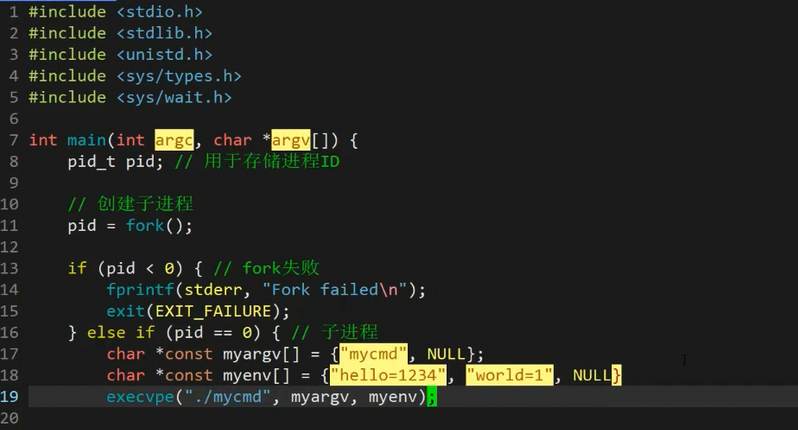
此时我们使用一下上面的函数,就是这样子使用的我们自定义了一些命令行参数和环境变量,此时打印的就是我们的自己的命令行参数和环境变量了,所以我们也可以知道,我们进程的环境变量也是通过exec**e函数来传给我们的main函数中的形参的。

总结一下,如果我们想要使用系统默认的环境变量的话,此时你就可以直接定义一个char **environ 然后把这个传进去就行了,如果你想传入自己的环境变量的话,你就像上面一下自己定义一个然后传进去就行,如果你想传入系统加上默认的话,此时你就可以通过调用putenv这个函数了。
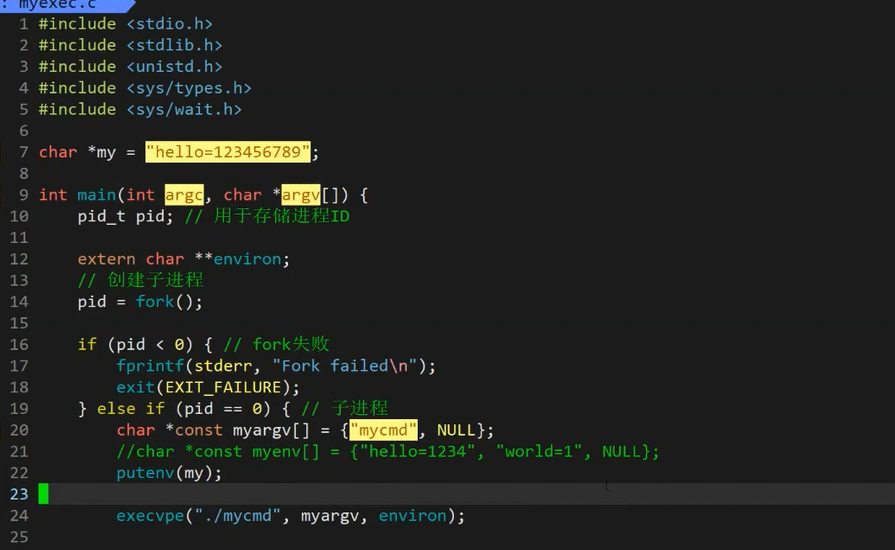
这个是putenv的用法,此时环境变量就是系统默认的加上你putenv的了。
最后一个大家自己用用就行了,这里就不再讲解了。
七.结束语
感谢读到这里的每一位朋友!技术之路漫长,每一次代码的调试、每一个知识点的梳理,都因你的驻足而更有意义。如果文章对你有帮助,欢迎点赞收藏,也期待在评论区和你交流更多技术细节~本期的技术分享就到这里啦!感谢你的耐心观看。文中若有疏漏或更好的优化方案,欢迎随时指出,一起在技术的世界里共同进步!