背景
Apache Datafusion Comet 是苹果公司开源的加速Spark运行的向量化项目。
本项目采用了 Spark插件化 + Protobuf + Arrow + DataFusion 架构形式
其中
- Spark插件是 利用 SparkPlugin 插件,其中分为 DriverPlugin 和 ExecutorPlugin ,这两个插件在driver和 Executor启动的时候就会调用
- Protobuf 是用来序列化 spark对应的表达式以及计划,用来传递给 native 引擎去执行,利用了 体积小,速度快的特性
- Arrow 是用来 spark 和 native 引擎进行高效的数据交换(native执行的结果或者spark执行的数据结果),主要在JNI中利用Arrow IPC 列式存储以及零拷贝等特点进行进程间数据交换
- DataFusion 主要是利用Rust native以及Arrow内存格式实现的向量化执行引擎,Spark中主要offload对应的算子到该引擎中去执行
本文基于 datafusion comet 截止到2026年1月13号的main分支的最新代码(对应的commit为 eef5f28a0727d9aef043fa2b87d6747ff68b827a)
主要分析 Rust Native CometNativeExec怎么生成对应的RDDColumnarBatch
Native父类CometNativeExec
CometNativeExec 是所有Native物理计划的父类,也是生层RDDColumnarBatch的地方,
abstract class CometNativeExec extends CometExec
...
abstract class CometExec extends CometPlan {
/** The original Spark operator from which this Comet operator is converted from */
def originalPlan: SparkPlan
/** Comet always support columnar execution */
override def supportsColumnar: Boolean = true
override def output: Seq[Attribute] = originalPlan.output
override def doExecute(): RDD[InternalRow] =
ColumnarToRowExec(this).doExecute()
...由以上得知,Native物理计划是支持列执行的,根据Spark Datafusion Comet 向量化--ApplyColumnarRulesAndInsertTransitions规则所说,所以会执行doExecuteColumnar方法:
override def doExecuteColumnar(): RDD[ColumnarBatch] = {
serializedPlanOpt.plan match {
case None =>
// This is in the middle of a native execution, it should not be executed directly.
throw new CometRuntimeException(
s"CometNativeExec should not be executed directly without a serialized plan: $this")
case Some(serializedPlan) =>
// Switch to use Decimal128 regardless of precision, since Arrow native execution
// doesn't support Decimal32 and Decimal64 yet.
SQLConf.get.setConfString(CometConf.COMET_USE_DECIMAL_128.key, "true")
val serializedPlanCopy = serializedPlan
// TODO: support native metrics for all operators.
val nativeMetrics = CometMetricNode.fromCometPlan(this)
// Go over all the native scans, in order to see if they need encryption options.
// For each relation in a CometNativeScan generate a hadoopConf,
// for each file path in a relation associate with hadoopConf
// This is done per native plan, so only count scans until a comet input is reached.
val encryptionOptions =
mutable.ArrayBuffer.empty[(Broadcast[SerializableConfiguration], Seq[String])]
foreachUntilCometInput(this) {
case scan: CometNativeScanExec =>
// This creates a hadoopConf that brings in any SQLConf "spark.hadoop.*" configs and
// per-relation configs since different tables might have different decryption
// properties.
val hadoopConf = scan.relation.sparkSession.sessionState
.newHadoopConfWithOptions(scan.relation.options)
val encryptionEnabled = CometParquetUtils.encryptionEnabled(hadoopConf)
if (encryptionEnabled) {
// hadoopConf isn't serializable, so we have to do a broadcasted config.
val broadcastedConf =
scan.relation.sparkSession.sparkContext
.broadcast(new SerializableConfiguration(hadoopConf))
val optsTuple: (Broadcast[SerializableConfiguration], Seq[String]) =
(broadcastedConf, scan.relation.inputFiles.toSeq)
encryptionOptions += optsTuple
}
case _ => // no-op
}
assert(
encryptionOptions.size <= 1,
"We expect one native scan that requires encryption reading in a Comet plan," +
" since we will broadcast one hadoopConf.")
// If this assumption changes in the future, you can look at the commit history of #2447
// to see how there used to be a map of relations to broadcasted confs in case multiple
// relations in a single plan. The example that came up was UNION. See discussion at:
// https://github.com/apache/datafusion-comet/pull/2447#discussion_r2406118264
val (broadcastedHadoopConfForEncryption, encryptedFilePaths) =
encryptionOptions.headOption match {
case Some((conf, paths)) => (Some(conf), paths)
case None => (None, Seq.empty)
}
...- 如果没有序列化的计划,则直接报异常
- 如果存在序列化的计划,则作如下操作:
-
创建
CometMetricNode -
从父到子依次遍历native scan(仅限于CometNativeScanExec),如果 有加密配置,则广播该配置,便于后续读取parquet文件的时候进行解密,并且要求最多只能有一个加密的
Scan计划 -
从父到子依次遍历收集输入节点(当且仅当是连续的Comet的物理计划)
val sparkPlans = ArrayBuffer.empty[SparkPlan] foreachUntilCometInput(this)(sparkPlans += _) ... def foreachUntilCometInput(plan: SparkPlan)(func: SparkPlan => Unit): Unit = { plan match { case _: CometNativeScanExec | _: CometScanExec | _: CometBatchScanExec | _: CometIcebergNativeScanExec | _: CometCsvNativeScanExec | _: ShuffleQueryStageExec | _: AQEShuffleReadExec | _: CometShuffleExchangeExec | _: CometUnionExec | _: CometTakeOrderedAndProjectExec | _: CometCoalesceExec | _: ReusedExchangeExec | _: CometBroadcastExchangeExec | _: BroadcastQueryStageExec | _: CometSparkToColumnarExec | _: CometLocalTableScanExec => func(plan) case _: CometPlan => // Other Comet operators, continue to traverse the tree. plan.children.foreach(foreachUntilCometInput(_)(func)) case _ => // no op } }这些都是向量化执行的潜入输入节点,而且父节点在列表的最开始
-
收集输入的RDD
- 对于非广播算子的输入,则直接执行
executeColumnar方法获得RDD[ColumnarBatch] - 对于广播罐子的输入,则直接执行
executeColumnar获得CometBatchRDD,也是一种RDD[ColumnarBatch]
- 对于非广播算子的输入,则直接执行
-
如果没有输入,则调用
createCometExecIter方法组装成CometExecRDD -
如果存在输入,则调用
createCometExecIter方法组装成ZippedPartitionsRDD,ZippedPartitionsRDD会以收集到的输入作为输入def createCometExecIter( inputs: Seq[Iterator[ColumnarBatch]], numParts: Int, partitionIndex: Int): CometExecIterator = { val it = new CometExecIterator( CometExec.newIterId, inputs, output.length, serializedPlanCopy, nativeMetrics, numParts, partitionIndex, broadcastedHadoopConfForEncryption, encryptedFilePaths) setSubqueries(it.id, this) Option(TaskContext.get()).foreach { context => context.addTaskCompletionListener[Unit] { _ => it.close() cleanSubqueries(it.id, this) } } it }这个
CometExecIterator就是之前Spark Datafusion Comet 向量化Rust Native--创建Datafusion计划中提到的CometExecIterator。
-
Native物理计划调用链
对于每个计划,得到对应的输入节点RDD(调用 executeColumnar方法),而从作为整个当前Native算子的输入,从而调用CometExecIterator对应的方法去执行,
而该方法的执行依赖于Rust Native的执行(依赖Arrow C 数据接口获取执行的ColumnarBatch结果),
此处传给Rust的就是:
private val cometBatchIterators = inputs.map { iterator =>
new CometBatchIterator(iterator, nativeUtil)
}.toArray此处的CometBatchIterator会在Rust端中以JNI的方式调用JVM相关的方法获取对应的ColumnarBatch数据:
如Rust中ScanExec:
fn allocate_and_fetch_batch(
env: &mut jni::JNIEnv,
iter: &JObject,
num_cols: usize,
) -> Result<(i32, Vec<i64>, Vec<i64>), CometError> {
let mut array_addrs = Vec::with_capacity(num_cols);
let mut schema_addrs = Vec::with_capacity(num_cols);
for _ in 0..num_cols {
let arrow_array = Rc::new(FFI_ArrowArray::empty());
let arrow_schema = Rc::new(FFI_ArrowSchema::empty());
let (array_ptr, schema_ptr) = (
Rc::into_raw(arrow_array) as i64,
Rc::into_raw(arrow_schema) as i64,
);
array_addrs.push(array_ptr);
schema_addrs.push(schema_ptr);
}
// Prepare the java array parameters
let long_array_addrs = env.new_long_array(num_cols as jsize)?;
let long_schema_addrs = env.new_long_array(num_cols as jsize)?;
env.set_long_array_region(&long_array_addrs, 0, &array_addrs)?;
env.set_long_array_region(&long_schema_addrs, 0, &schema_addrs)?;
let array_obj = JObject::from(long_array_addrs);
let schema_obj = JObject::from(long_schema_addrs);
let array_obj = JValueGen::Object(array_obj.as_ref());
let schema_obj = JValueGen::Object(schema_obj.as_ref());
let num_rows: i32 = unsafe {
jni_call!(env,comet_batch_iterator(iter).next(array_obj, schema_obj) -> i32)?
};
// we already checked for end of results on call to has_next() so should always
// have a valid row count when calling next()
assert!(num_rows != -1);
Ok((num_rows, array_addrs, schema_addrs))
}其中 jni_call!(env,comet_batch_iterator(iter).next(array_obj, schema_obj) -> i32)?就是Rust通过JNI调用JVM的CometBatchIterator的next方法
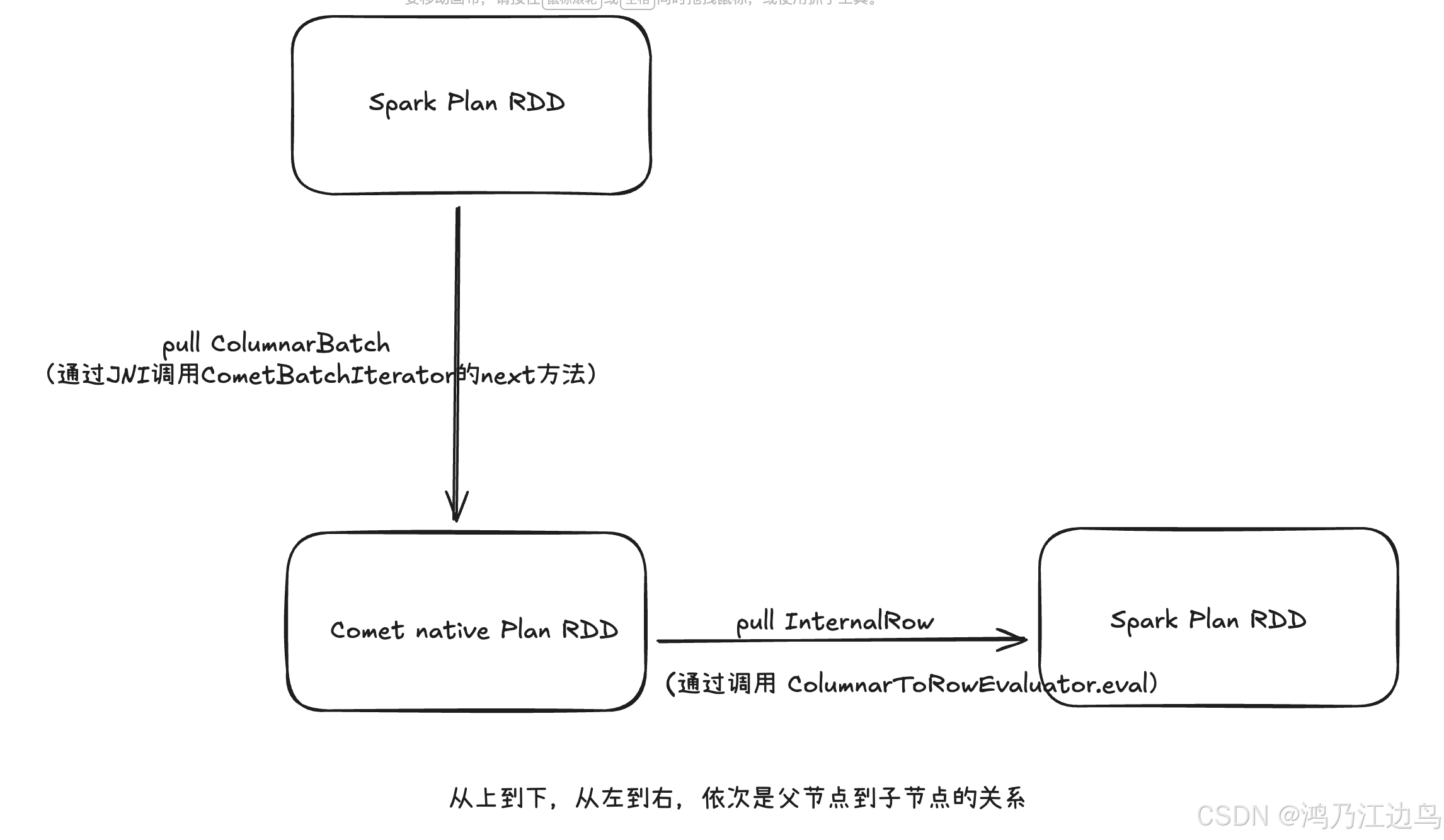
注意:在调用 输入节点的 executeColumnar 方法时就会依次调用子节点(非comet物理计划)对应的方法(要么executeColumnar/要么execute)