一、HTML核心标签
1. div标签:网页布局的"万能容器"
div标签全称为Division,是HTML中的块级容器标签,核心价值在于"内容分组与区域划分"。它能将网页拆解为独立的功能模块(如头部导航、侧边栏、主体内容区、页脚)。
核心特性与使用逻辑
支持width、height、background、margin、padding等样式属性,能快速自定义区域外观;同时支持嵌套使用,可实现多层级、复杂的页面结构设计,适配从简单网页到大型门户网站的布局需求。
实战代码:div嵌套使用
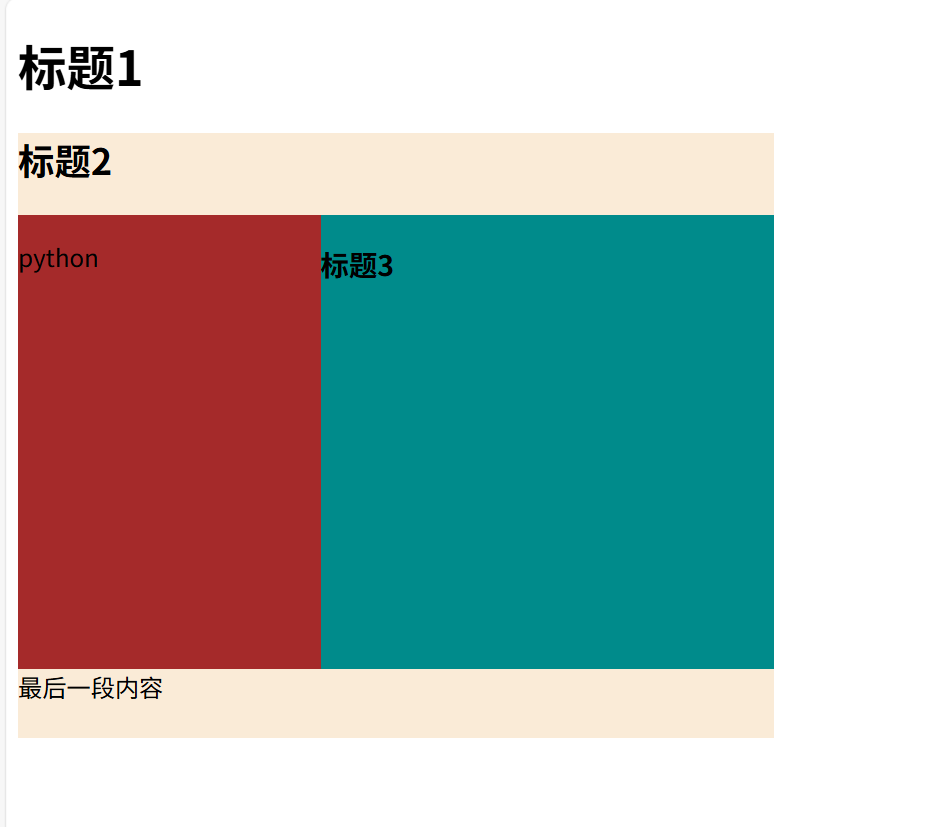
<!DOCTYPE html>
<html lang="zh-cn">
<head>
<meta charset="UTF-8">
<title>标题</title>
</head>
<body>
<h1>标题1</h1>
<div style="background:antiquewhite;width:500px;height:400px">
<h2>标题2</h2>
<div style="background:brown;width:200px;height:300px;float:left">
<p>python</p>
</div>
<div style="background:darkcyan;width:300px;height:300px;float:right">
<h3>标题3</h3>
</div>
<p>最后一段内容</p>
</div>
</body>
</html>演示结果:
2. 表格标签:结构化数据的"展示利器"
表格标签用于展示具有明确行列关系的结构化数据(如成绩表、商品参数、财务报表等),通过组合多个标签形成完整表格,能让数据呈现更清晰、更具可读性。其核心标签包括表格容器、行、单元格、表头、标题等,各司其职构建完整表格结构。
核心标签与属性说明
表格标签需组合使用,各核心标签的功能与关键属性如下:
|-------------|-----------------|---------------------------|
| 标签 | 作用 | 关键属性 |
| <table> | 定义表格容器 | border:设置边框宽度 |
| <tr> | 定义表格行 | 无核心属性,嵌套<td>/<<th> |
| <td> | 定义普通单元格 | 无核心属性 |
| <<th> | 定义表头单元格(默认加粗居中) | colspan:跨列;rowspan:跨行 |
| <caption> | 定义表格标题(默认居中顶部) | 无核心属性 |
实战代码:带合并单元格的完整表格
以下示例实现带表头、标题和跨列合并的学生成绩表,涵盖表格标签的核心用法:
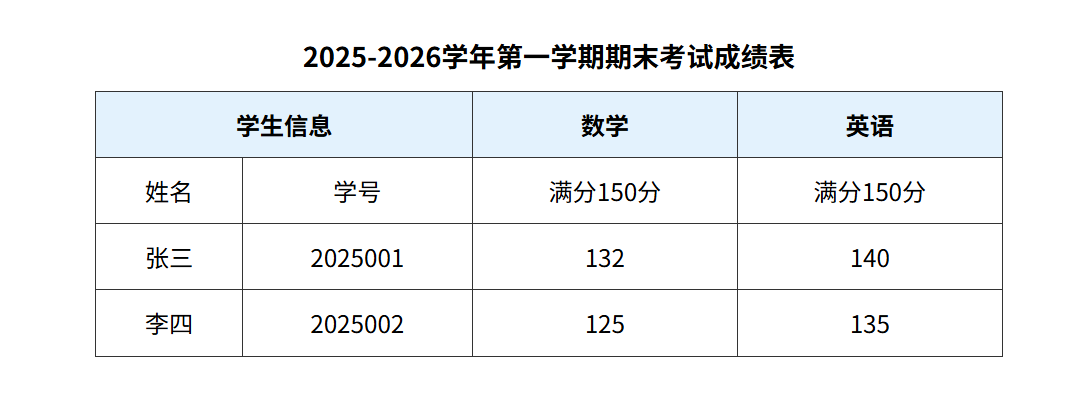
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>表格标签实战示例</title>
<style>
table {
border-collapse: collapse; /* 合并边框,避免双重边框 */
width: 600px;
margin: 30px auto;
}
th, td {
border: 1px solid #333;
padding: 10px;
text-align: center;
}
th {
background-color: #e3f2fd;
}
caption {
font-size: 18px;
font-weight: bold;
margin-bottom: 10px;
}
</style>
</head>
<body>
<table>
<caption>2025-2026学年第一学期期末考试成绩表</caption>
<tr>
<th colspan="2">学生信息</th>
<th>数学</th>
<th>英语</th>
</tr>
<tr>
<td>姓名</td>
<td>学号</td>
<td>满分150分</td>
<td>满分150分</td>
</tr>
<tr>
<td>张三</td>
<td>2025001</td>
<td>132</td>
<td>140</td>
</tr>
<tr>
<td>李四</td>
<td>2025002</td>
<td>125</td>
<td>135</td>
</tr>
</table>
</body>
</html>演示结果:
二、Python爬虫库:解锁网页数据的密钥
1. requests库:轻量级HTTP请求
requests库是基于Python urllib开发的第三方HTTP库,API简洁易用,支持GET/POST请求、会话维持、代理设置、Cookie管理等核心功能,无需复杂的底层封装,能快速实现静态网页(无JavaScript动态渲染)的数据爬取,是爬虫入门的必备工具。
环境准备:安装与验证
通过pip命令安装,推荐使用国内镜像源加速下载,安装后验证版本确保环境正常:
# 安装requests库(清华镜像源)
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple
# 验证安装(查看版本信息)
pip show requestsget()函数:从服务器获取资源
get()函数用于向服务器发送GET请求,核心作用是"获取资源"(如网页源代码、图片、文件、API数据等)。GET请求的参数会拼接在URL末尾,适用于数据查询、资源获取等场景,核心参数包括url(目标地址)、params(查询参数)、headers(请求头)、proxies(代理)。
实战场景1:基础爬取网页源代码
爬取人民邮电出版社官网首页源代码,处理编码避免乱码:
'''get函数'''
import requests
r = requests.get('https://www.ryjiaoyu.com') #获取url网址的内容,返回一个respones对象(获取的网页数据对象)
print(r.text)#显示网页的内容实战场景2:带查询参数的GET请求、添加信息、设置编码
模拟搜索功能,通过params参数传递关键词,自动拼接URL:
'''搜索信息'''
import requests
r = requests.get('https://www.ryjiaoyu.com//search?keyword=python')
print(r.text)
'''添加信息'''
import requests
info ={'keyword':'excel' }
r = requests.get('https://www.bilibili.com/search',params=info)
print(r.url)
print(r.text)
'''设置编码'''
import requests
r = requests.get('https://www.baidu.com')
r.encoding = r.apparent_encoding #自动识别当前网页的编码
print(r.text)实战场景3:UA伪装规避反爬
部分网站会通过User-Agent识别爬虫并拒绝访问,需设置headers模拟浏览器请求:
import requests
# 获取url
url = "https://www.baidu.com/"
# 如果不设置UA 会知道你是python包来访问网页
# UA伪装
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36 Edg/142.0.0.0"
}
# 向url发生请求
r = requests.get(url,headers=head)
r.encoding = r.apparent_encoding #自动识别当前网页的编码
print(r.text)实战场景4:提取网站中的文字信息
import requests
import re
r = requests.get('https://www.ryjiaoyu.com/tag/details/7')
print(r.text)
result = re.findall(r'title="(.+?)">(.+?)</a></h4>',r.text)
for i in range(len(result)):
print('第',i+1,'本书: ',result[i][1])实战场景5:xpath解析
from lxml import etree
# parse 提供解析本地html文件的方法
tree = etree.parse("test.html")
# xpath获取返回的数据类型都是列表形式
# 获取到title对象
print(tree.xpath("/html/head/title/text()"))
print(tree.xpath("/html/body/div/p/text()"))
# 索引定位 这里的索引从1 开始
print(tree.xpath("/html/body/div[1]/p/text()"))
print(tree.xpath("/html/body/div[2]/p/text()"))
print(tree.xpath("/html/body/div[2]/p[2]/text()"))
# 属性定位 class,id
print(tree.xpath("/html/body/div[@class='song']/p[2]/text()"))
# / 表示的是一个层级 // 表示的是多个层级
print(tree.xpath("//div[@class='song']/p[3]/text()"))
# /text() 取直系标签下的文本内容
# //text() 取该标签下的所有文本内容
print(tree.xpath("//div[@class='song']/p[2]/text()")[0])
print(tree.xpath("//div[@class='song']//text()"))
# 取标签内的属性内容 @src、@href、
print(tree.xpath("//div[@class='song']/img/@src"))
print(tree.xpath("//div[@class='tang']/ul/li[3]/a/@href")[0])实战场景6:爬取图片
import fake_useragent
import requests
from lxml import etree
import os
n=0
def count():
global n
n+=1
return n
# 新建一个文件夹用于存储图片
if not os.path.exists("./Picture"):
os.mkdir("./Picture")
head = {
"User-Agent": fake_useragent.UserAgent().random
}
for i in range(1, 3):
url = f'https://10wallpaper.com/List_wallpapers/page/{i}'
# 发送请求
resp = requests.get(url, headers=head)
# 响应回去的返回数据
result = resp.text
tree = etree.HTML(result)
p_list = tree.xpath("//div[@id='pics-list']/p")
for p in p_list:
img_url = p.xpath("./a/img/@src")[0]
img_url2='https://10wallpaper.com'+img_url
print(img_url2)
img_name = count()
print(img_name)
img_resp = requests.get(img_url2, headers=head)
img_content = img_resp.content
with open(f"./Picture/{img_name}.jpg", "wb") as fp:
fp.write(img_resp.content)post()函数:向服务器提交数据
post()函数用于向服务器发送POST请求,核心作用是"提交数据"(如表单提交、用户登录、数据修改、文件上传等)。POST请求的参数不会暴露在URL中,而是放在请求体里,安全性更高,核心参数包括url、data(表单数据)、json(JSON格式数据)、headers。
实战场景:模拟表单提交(修改密码)
以下示例模拟向网站提交修改密码的表单数据,实际场景需结合目标网站的接口规则调整参数:
import requests
d = {'OldPassword':'123python','NewPassword':'123456python','ConfirmPassword':'123456python'}
r = requests.post('https://account.ryjiaoyu.com/change-password', data = d)
print(r.text)
import requests
d = {'Password':'Python123','Email':'15556520641'}
r = requests.post('https://account.ryjiaoyu.com/log-in', data = d)
print(r.text)会话(Session):维持登录状态
HTTP协议是"无状态协议",即每次请求都是独立的,服务器不会保存上一次请求的状态。在爬虫场景中,若需访问登录后的页面(如用户中心、个人数据),需通过requests.Session()创建会话对象,自动保存Cookie信息,维持持续登录状态,实现跨请求的状态保持。
实战场景:登录后访问用户中心
以下示例模拟用户登录,通过会话对象保存Cookie,再访问登录后的用户中心页面:
import requests
s = requests.Session()
data = {'Email': '15156883862','Password': '123python','RememberMe': 'true'}
r1 = s.post('https://account.ryjiaoyu.com/log-in?returnUrl=https%3a%2f%2fwww.ryjiaoyu.com%2f',data=data)
r2 = s.get('https://www.ryjiaoyu.com/user')
print( r2.text)代理服务器:
import requests
proxie = {'http':'http://115.29.199.16:8118'}
r = requests.get('https://www.ryjiaoyu.com/',proxies= proxie)
print(r.text)2. selenium库:动态网页爬取与自动化工具
requests库仅能获取网页原始HTML代码,selenium库通过驱动真实浏览器(Chrome、Edge、Firefox等)模拟用户操作,能获取浏览器渲染后的完整页面内容,适用于动态网页爬取、自动化测试等场景。
环境准备:库安装与驱动配置
selenium的使用需同时安装库文件和对应浏览器的驱动,步骤如下:
# 1. 安装selenium库(指定稳定版本)
pip install selenium==4.11.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
# 2. 下载浏览器驱动
# edge驱动下载地址:https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/?ch=1&form=MA13LH
# chrome驱动下载地址:https://chromedriver.storage.googleapis.com/index.html
# firefox驱动下载地址:https://github.com/mozilla/geckodriver/releases
# 驱动版本需与浏览器版本完全匹配
# 3. 配置驱动路径
# 将驱动文件(chromedriver.exe)放入Python安装目录的Scripts文件夹在浏览器设置中找到浏览器版本
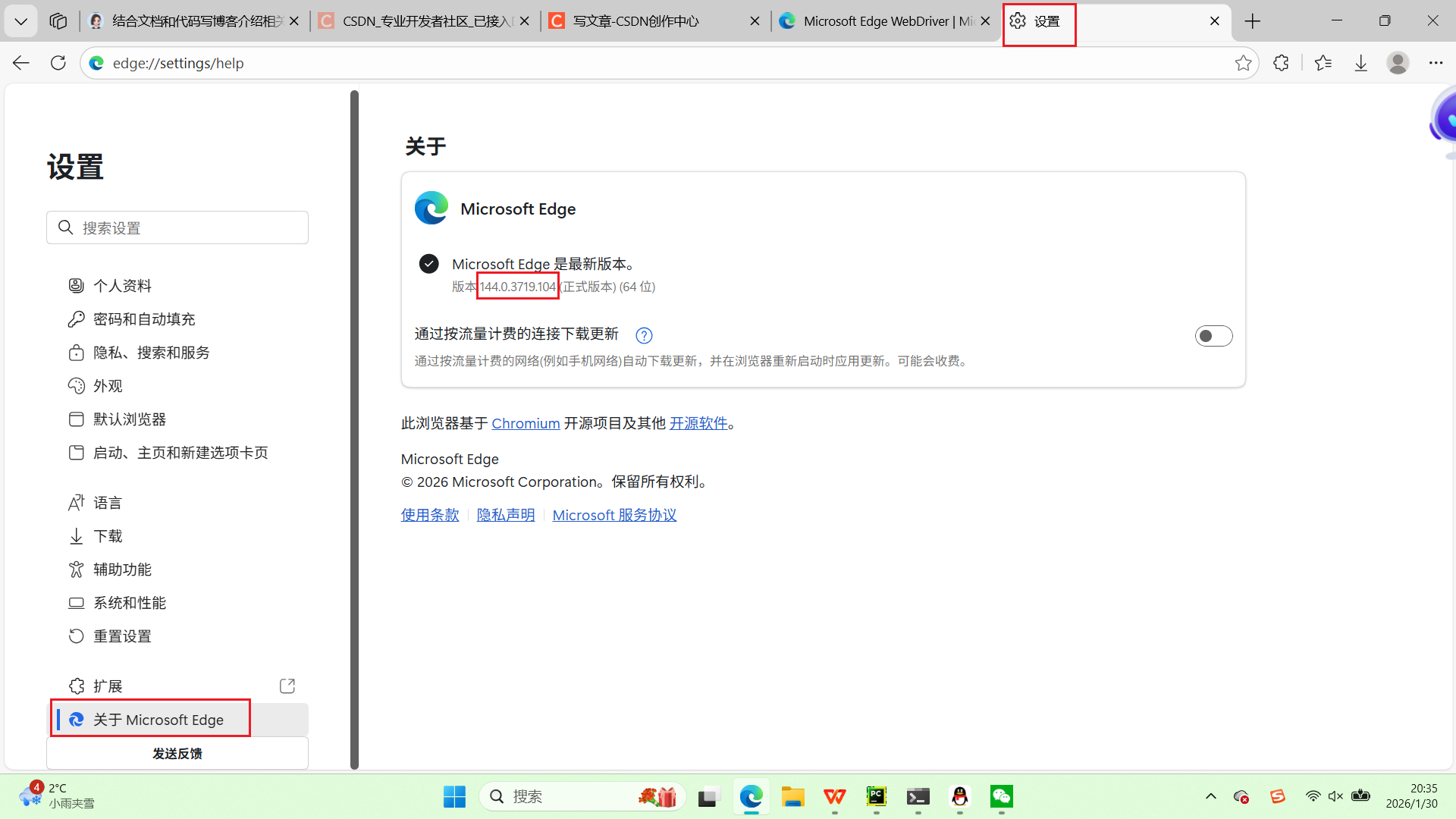
在驱动地址中找到对应的版本下载
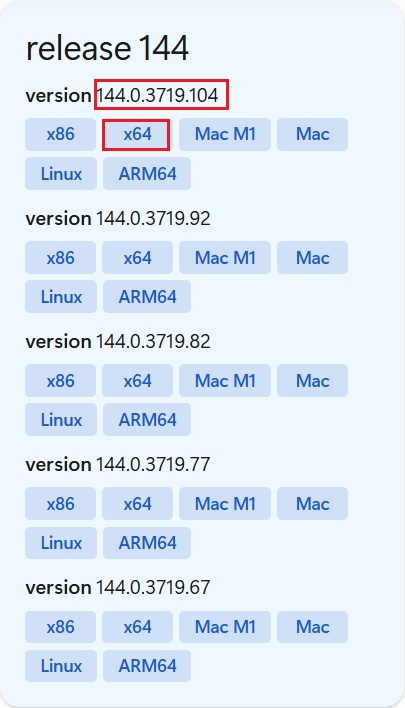
将解压后的exe文件复制到python下载路径的Scripts文件夹中,python路径可以在电脑命令提示符通过where python查找

核心功能与实战示例
selenium支持打开网页、元素定位、输入文字、点击按钮、滚动页面、切换窗口等模拟用户操作,核心方法包括get()(打开网页)、find_element()(定位元素)、send_keys()(输入内容)、click()(点击操作)、execute_script()(执行JavaScript)。
实战场景1:打开网页并获取渲染后源代码
mport re
import time
# pip install selenium==4.11.0 -i https://pypi.mirrors.ustc.edu.cn/simple/
'''打开一个网页'''
from selenium import webdriver #从selenium导入 webdriver (驱动浏览器驱动)
# 导入Edge浏览器的Options类,这个类允许我们配置WebDriver的行为。
from selenium.webdriver.edge.options import Options
# 创建一个Options类的实例,这将用于设置Edge浏览器的启动选项。
edge_options = Options()
# 设置Edge浏览器的文件位置,这样WebDriver知道哪个版本的Edge要启动。
# 这个路径必须指向你的Edge安装目录下的msedge.exe文件。
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
'''①webdriver具备多种不同浏览器的驱动,
browser = webdriver.Firefox()
browser = webdriver.chrome()
browser = webdriver.PhantomJS()
browser= webdriver.Safari()
# '''
# 使用上面创建的Options实例来初始化WebDriver。
# WebDriver是与浏览器交互的主要接口,通过它我们可以模拟用户操作。
driver = webdriver.Edge(options=edge_options)
# 使用get方法让WebDriver打开指定的URL,这里是Bilibili的主页。
driver.get('https://www.ptpress.com.cn/')
# driver.get('https://www.baidu.com/')
# input函数在这里用来暂停脚本的执行,直到用户按下回车键。
# 这样做是为了让用户能够观察到浏览器窗口中的结果
input('dengdai')
time.sleep(1)实战场景2:模拟搜索操作
from selenium import webdriver
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
edge_options = Options()
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)
# 打开B站
driver.get("https://www.bilibili.com/")
# 定位搜索框(通过标签名定位)
search_input = driver.find_element(by=By.TAG_NAME, value="input")
# 输入关键词并按回车搜索
search_input.send_keys("Python爬虫" + Keys.ENTER)
input("按回车关闭...")
driver.quit()实战场景3:在百度识图中上传图片,实现对图片的识别
from selenium import webdriver
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import By
import time
edge_options = Options()
# 将 --headless 参数添加到 WebDriver 的配置中时,它告诉浏览器在"无头"模式下运行。
# 无头模式意味着浏览器在没有图形界面的情况下运行。这对于执行自动化测试或者在服务器上运行爬虫时非常有用,因为它节省了资源,并且运行速度可能更快。
edge_options.add_argument('--headless')
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)
driver.get('https://graph.baidu.com/pcpage/index?tpl_from=pc')
# driver.find_elements(by=By.TAG_NAME,value="input")[1].send_keys(r"E:\爬虫\Picture2\3.jpg")
# 或
input_element = driver.find_element(by=By.NAME,value="file")#定位标签
input_element.send_keys(r"C:\Users\ponyyll\Desktop\Snipaste_2026-01-30_18-38-15.png")
time.sleep(5)
elment = driver.find_element(by=By.CLASS_NAME,value="graph-guess-word") # elements是获取所有标签
print(elment.text)实战场景4:爬取动态加载的图片
import requests
import os
import time
from selenium import webdriver
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import By
# 创建图片保存目录
if not os.path.exists("./图片"):
os.mkdir("./图片")
# 配置浏览器
edge_options = Options()
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)
# 打开百度图片搜索(关键词:迪丽热巴)
driver.get("https://image.baidu.com/search/index?tn=baiduimage&ie=utf-8&word=迪丽热巴")
# 滚动页面3次,加载更多图片
for _ in range(3):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(3) # 等待加载
# 定位所有图片元素
img_elements = driver.find_elements(by=By.XPATH, value="//img[@class='img_7rRSL']")
# 下载图片
for i, img in enumerate(img_elements, 1):
img_url = img.get_attribute("src")
if img_url:
img_data = requests.get(img_url).content
with open(f"./图片/{i}.png", "wb") as f:
f.write(img_data)
print(f"已下载第{i}张图片")
driver.quit()实战场景5:爬取苏宁易购某手机的好评
from selenium import webdriver
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import By
import time
#
edge_options = Options()
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe" ##edge浏览器的地址
driver = webdriver.Edge(options=edge_options)
'''抓取好评'''
driver.get('https://review.suning.com/cluster_cmmdty_review/cluster-38249278-000000012389328846-0000000000-1-good.htm?originalCmmdtyType=general&safp=d488778a.10004.loverRight.166')
hp_file = open('好评.txt','w',encoding='utf8') #文件对象
def get_py_content(file): #只能获取当前这一页的所有评论#get_py_content是定义了一个函数,函数在什么时候会执行?调用的时候
pj_elments_content = driver.find_elements(by= By.CLASS_NAME,value='body-content')#会寻找到所有class名为body-content的标签
for elment in pj_elments_content:#i =0
file.write(elment.text+'\n')
get_py_content(hp_file) #获取当第一页的评论内容
next_elements = driver.find_elements(by= By.XPATH,value='//a[@class="next rv-maidian "]')#xpath,
print(next_elements)#标签元素数据,可以对这个类的数据,有一系列的操作,
while next_elements !=[]:# 是否获取到 下一页的标签,
next_element = next_elements[0]
time.sleep(1)# 以确保页面加载完成后再继续执行后续的操作。
next_element.click()
get_py_content(hp_file)#功能:是获取当前网页的评论数据,并写入到
next_elements = driver.find_elements(by= By.XPATH,value='//*[@class="next rv-maidian "]')
hp_file.close()三、技术选型总结
|-------------|---------------|-----------------------|
| 技术 | 核心用途 | 适用场景 |
| div标签 | 网页布局、内容分组 | 所有网页开发 |
| 表格标签 | 结构化数据展示 | 成绩表、商品参数、报表 |
| requests库 | 静态网页爬取、接口请求 | 无动态渲染的网页、API数据获取 |
| get()函数 | 获取网页/文件资源 | 搜索、数据查询 |
| post()函数 | 提交表单/JSON数据 | 登录、修改信息、数据上传 |
| 会话(Session) | 维持登录状态 | 需登录后访问的页面/接口 |
| selenium库 | 动态网页爬取、模拟用户操作 | JavaScript渲染的网页、自动化测试 |