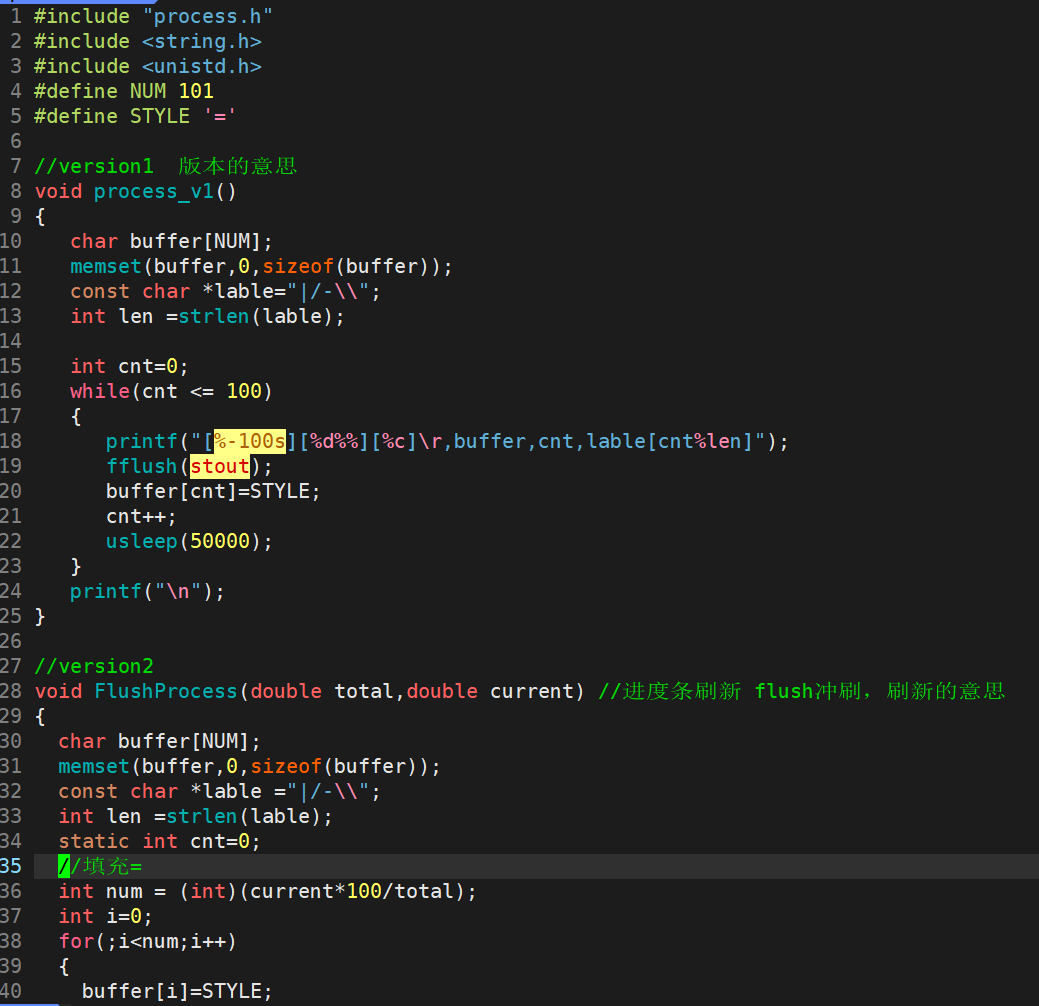
1.回车和换行是一个概念吗?
①回车(Carriage Return,CR)是控制字符,使光标回到当前行的行首位置---- \r
②换行(Line Feed,LF)是控制字符,使光标移动到下一行的同一列位置------ \n
③值得注意的是,在printf中会将\r\n省略写成\n,
2.经典问题------缓冲区
cpp
int main()
{
printf("hello bite!");
sleep(3);
return 0;
}在以上程序执行后,
①为什么看不到字符串输出? 因为没有\n
②字符串在哪里呢? 因为在缓冲区
③可是为什么在缓冲区(本质就是一段内存)就不会输出呢? 这就要看缓冲区的工作原理了
printf("hello Linux!")
↓
内容进入"输出缓冲区"(内存中的一块区域)
↓
缓冲区规则:遇到'\n' 或 缓冲区满 或 程序结束 → 刷新到屏幕↓
这里没有'\n' → 不刷新 → 留在缓冲区
↓
sleep(2) → 程序暂停2秒
↓
2秒后程序结束 → 自动刷新缓冲区 → 显示到屏幕
如果我们不写\n,可以调用函数fflush,这个函数可以让printf的内容直接刷新到显示屏;
cpp
printf("Test3: Linux"); // 没有\n
fflush(stdout); // 强制刷新
sleep(2); // 立即看到输出,然后sleep
printf("\n");
3. stdout是什么
stdout 是标准输出流(Standard Output Stream), stdout 是C语言中预定义的一个文件指针 指向标准输出设备 (通常是终端/屏幕),定义在 <stdio.h> 头文件中。
(1)三个标准流
C程序启动时自动打开三个流:
| 流 | 文件指针 | 默认设备 | 用途 |
|---|---|---|---|
| 标准输入 | stdin |
键盘 | 输入数据 |
| 标准输出 | stdout |
屏幕 | 输出正常信息 |
| 标准错误 | stderr |
屏幕 | 输出错误信息 |
4.倒计时程序
(1)完整程序
cpp
#include <stdio.h>
#include <unistd.h>
int main()
{
int i = 10;
while(i >= 0)
{
// %-2d 确保每个数字都占2个字符宽度
// 这样从10到0都能完全覆盖前一个数字
printf("%-2d\r", i); // 左对齐,占2位
fflush(stdout); // 立即显示
i--;
sleep(1);
}
printf("\n"); // 最后换行,让shell提示符到新行
return 0;
}(2)为什么要-2d
① %-2d 的作用
%d:打印整数
%2d:至少占2个字符宽度,右对齐
%-2d:至少占2个字符宽度,左对齐
② 为什么要用 %-2d?
// 没有宽度控制 printf("%d\r", 10); // "10" printf("%d\r", 9); // "9" ← 只覆盖了"10"的"10"? // 实际显示:"9"(9后面还残留着0) // 有宽度控制 printf("%-2d\r", 10); // "10" printf("%-2d\r", 9); // "9 " ← 用"9 "覆盖"10" // 实际显示:"9"(干净地覆盖)
(3)为什么最后还要 printf("\n")?
①没有 \n 的问题:
// 程序结束时 10 9 8 7 6 5 4 3 2 1 0 ← 光标停在这里 ↑ 光标位置 // 如果此时你输入命令: [gy@VM-4-2-centos ~]$ ./countdown 10 9 8 7 6 5 4 3 2 1 0[gy@VM-4-2-centos ~]$ // 提示符紧跟在0后面,很乱!
②有 \n 的效果:
// 程序结束时 10 9 8 7 6 5 4 3 2 1 0 ← 光标移到下一行行首 // 显示效果: [gy@VM-4-2-centos ~]$ ./countdown 10 9 8 7 6 5 4 3 2 1 0 [gy@VM-4-2-centos ~]$ ← 提示符在新的一行,整齐!
最后编译运行之后就会看到如下现象,

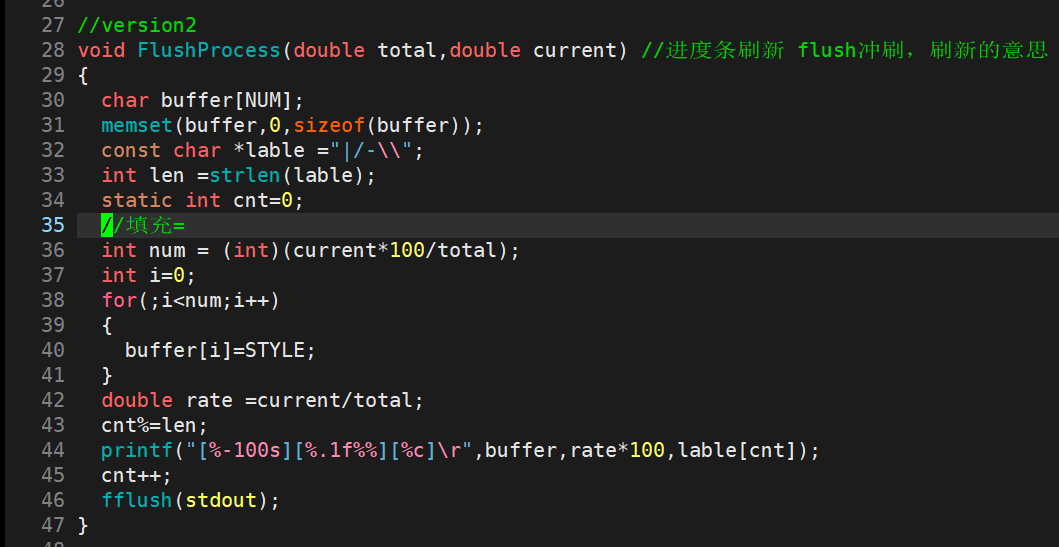
5.进度条(processbar)实现

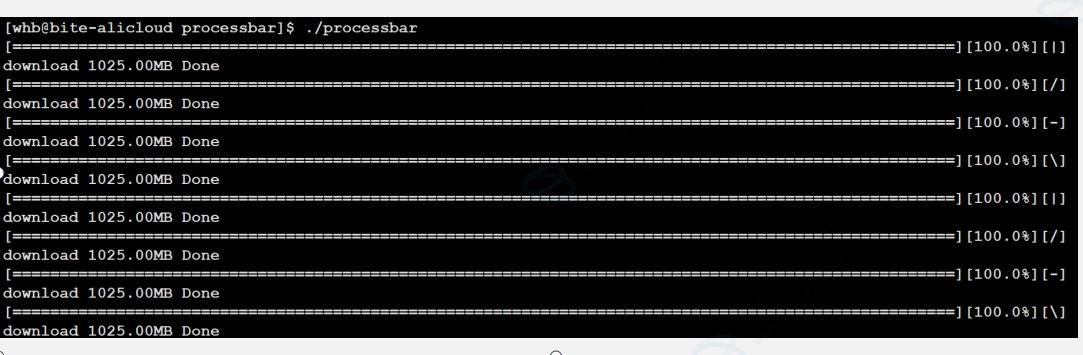
以上是我们今天要实现的进度条,按照download的程度来定义百分比和=的进度,以及|\-/;
(1)usleep和sleep的区别
usleep() 和 sleep() 都是用于暂停程序执行 的函数,但它们在时间精度和使用方式上有重要区别:
主要区别对比
| 特性 | sleep() |
usleep() |
|---|---|---|
| 时间单位 | 秒(seconds) | 微秒(microseconds) |
| 精度 | 秒级(1秒) | 微秒级(0.000001秒) |
| 函数原型 | unsigned int sleep(unsigned int seconds) |
int usleep(useconds_t microseconds) |
| 包含头文件 | <unistd.h> |
<unistd.h> |
| 返回值 | 剩余未休眠的秒数 | 0成功,-1失败(设置errno) |
| 可移植性 | POSIX标准,广泛支持 | 已过时(被nanosleep()取代) |
(2) #pragma once的作用是什么?
防止头文件被重复包含,避免重复定义的编译错误。
(3)完整代码实现