跳表是怎么实现的?
跳表是一链表改造而来,是一种小区链表,能够快速查询元素
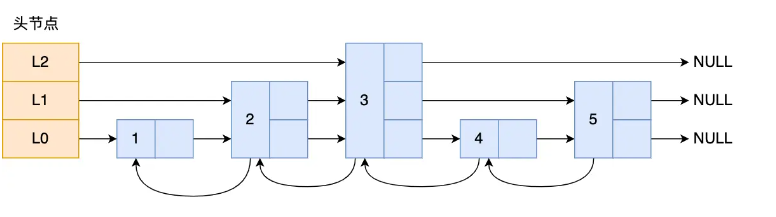
头节点有3个指针L0、L1、L2
L0系统有5个节点:1、2、3、4、5
L1系统有3个节点:2、3、5
L2系统有1个节点:3
eg:我想查找4,就可以从L2系统查到3再查到4,只需要操作两次
如果在很大的数据 下跳表就会在系统层级上跳来跳去实现查询,时间复杂度就为O(logN)
跳表实现多系统(层级):
这里需要看跳表的源码
cpp
typedef struct zskiplistNode {
//Zset 对象的元素值
sds ele;
//元素权重值
double score;
//后向指针
struct zskiplistNode *backward;
//节点的level数组,保存每层上的前向指针和跨度
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;redis中zset存储sds类型的key和double类型的score,并且每一个节点都有一个前驱指针( struct zskiplistNode *backward),能够很方便的实现倒叙
这里sds类型它是 Redis 专门设计、用于替代 C 语言原生字符串(
char*)的自定义字符串类型并且可以 自动扩容,按需分配,兼顾效率和内存
多层级 就是依赖zskiplistLevel,可以存储每一个系统相邻节点之间的跨度,还有一个后继指针(truct zskiplistNode *forward)

而且层高是根据0,1之间生成一个随机数,若小于0.25(概率小于25%),就会添加一层,两个相邻的元素之间没有层高比例,层数最大是64
#跳表是怎么设置层高的?
层高是根据**0,1之间生成一个随机数,若小于0.25(概率小于25%),就会添加一层**,两个相邻的元素之间没有层高比例,层数最大是64
Redis为什么用跳表而不是用B+树?
因为Redis中跳表场景适用度更高
跳表是适用于内存优化(redis)
B+树使用于磁盘优化(减少I/O次数,mysql)
1、内存与磁盘的设计初衷(最重要的原因):
B+树是为了磁盘I/O优化的: B+树的设计核心是降低树的高度,从而减少磁盘I/O次数。
**Redis 是纯内存操作:**在内存中,没有"磁盘 I/O"的瓶颈。内存中指针跳转的速度非常快。跳表虽然比 B+ 树高(层数多),但因此在内存中多几次指针跳转的长度非常小。,B+ 树为了减少高度而设计的复杂页管理机制,在内存场景下稀疏且笨重。
2、实现复杂度与代码维护:
跳表(Skip List):本质上是"楼梯链表"。其插入、删除逻辑主要是修改指针,代码实现非常简洁(几行C代码)。
B+树:插入和删除可能会引发节点的分割(Split)和合并(Merge),甚至需要对整棵树进行重平衡。实现一个健壮、高效的B+树非常复杂,代码量大而难以调试。
结论: Redis 作者 Antirez 非常看重代码的可执行性和简洁性,跳表以相邻的代码复杂度达到了同等级别的性能 O(log N)。
3、写入性能与重平衡代价:
**B+树的读取读写:**当插入导致数据页分裂时,需要移动大量数据或改变树的结构,这会产生读写读写。
跳表的局部性: 跳表的插入和删除操作是局部的。一个节点只需要修改相对节点的指针,并根据概率随机生成层高。它不需要像红黑树或B+树那样进行全局的旋转或复杂的结构调整
redis选择跳表不选B+树就是因为:
1.内存场景下,B+树的I/O优势无法发挥
2.zset的操作(增、删),跳表能以较低的复杂度实现同等甚至更优的性能
3.高频更新场景中,跳表的的实现简单性、性能稳定性更加符合redis的要求