在进行深度学习之前,我们需要了解一下对于机器学习和深度学习来说,它们的处理方法有哪些不同。
1. 特征工程
- ML :依赖手动特征工程。数据科学家需要通过领域知识提取、选择和转换特征,例如计算新特征(如年龄分组)、编码分类变量(one-hot encoding)、处理缺失值(均值填充)。模型(如决策树、SVM)无法自动学习复杂特征,因此预处理至关重要。
- DL :特征工程部分自动化。神经网络(如CNN、RNN)可以从原始数据中自动学习特征表示,无需过多手动干预。例如,CNN可直接处理图像像素,RNN处理序列数据。预处理更注重数据增强(如图像旋转、文本分词)以提高模型泛化。
2. 数据规模和质量要求
- ML:适用于中小规模数据集(数千至数万样本)。对数据质量敏感,需要平衡类别分布(处理不平衡数据)、去除噪声。预处理包括标准化(z-score)、归一化(min-max)以适应模型假设。
- DL:需要大规模数据集(数十万至数百万样本)以避免过拟合。数据质量仍重要,但模型对噪声更鲁棒。预处理强调批量处理,如批量归一化(Batch Normalization)、数据管道(DataLoader in PyTorch/TensorFlow)以高效加载和增强数据。
3. 预处理复杂度
- ML:预处理相对简单,聚焦于统计方法和规则-based转换。工具如pandas、scikit-learn用于清洗、分割数据集(train/val/test)。
- DL:预处理更复杂,涉及多模态数据(如图像、文本、时间序列)。需要特定格式化,如将文本转换为嵌入向量(Word2Vec、BERT)、图像resize/crop。使用框架如TensorFlow/Keras或PyTorch进行端到端管道,包括数据加载器和变换。
如果想把深度学习引入到网络中,最必要的一步是在数据集预处理中进行标准化(standardization)或归一化(normalization)。目前的项目主要使用传统机器学习模型(如LogisticRegression、RandomForest),这些模型大部分对特征尺度相对不敏感,因此未应用缩放。
但是,深度学习模型(如神经网络)对特征尺度敏感,标准化可加速收敛并提高性能。如果需要适配DL,建议在数据分割后对数值特征(如Age、Fare)应用StandardScaler或MinMaxScaler。
python
# 标准化数值特征(为深度学习准备)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_val_scaled = scaler.transform(X_val)
print("标准化完成。")大家可以用上一篇文章中的机器学习模型进行测试,进行标准化后几乎对结果没有影响
标准化前
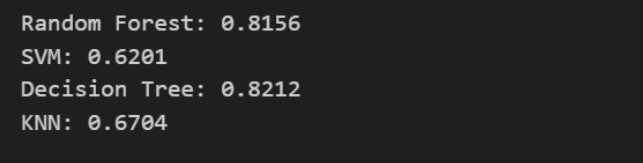
标准化后

下面构建一个简单的MLP网络来进行测试
MLP
python
# 深度学习模型实现
import torch
import torch.nn as nn
import torch.optim as optim
# 转换为tensor
X_train_tensor = torch.tensor(X_train_scaled, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train.values, dtype=torch.float32).unsqueeze(1)
X_val_tensor = torch.tensor(X_val_scaled, dtype=torch.float32)
y_val_tensor = torch.tensor(y_val.values, dtype=torch.float32).unsqueeze(1)
# 定义MLP模型
class MLP(nn.Module):
def __init__(self, input_size):
super(MLP, self).__init__()
self.fc1 = nn.Linear(input_size, 64)
self.fc2 = nn.Linear(64, 32)
self.fc3 = nn.Linear(32, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.sigmoid(self.fc3(x))
return x
model = MLP(X_train_scaled.shape[1])
# 损失函数和优化器
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
epochs = 100
for epoch in range(epochs):
model.train()
optimizer.zero_grad()
outputs = model(X_train_tensor)
loss = criterion(outputs, y_train_tensor)
loss.backward()
optimizer.step()
# 预测
model.eval()
with torch.no_grad():
y_pred_prob = model(X_val_tensor)
y_pred = (y_pred_prob > 0.5).float()
# 计算准确率
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_val, y_pred.numpy().flatten())
print(f"深度学习模型验证集准确率: {accuracy:.4f}")代码中使用了一个简单的多层感知机(MLP)模型,包括两个隐藏层(64和32个神经元),使用ReLU激活和Sigmoid输出。模型在标准化数据上训练100个epoch,使用Adam优化器和BCELoss损失函数。模型输出如下:

可以发现,对于这样一个简单问题,深度学习效果并不比机器学习好。主要是由于该数据集比较小(只有891个样本)不能发挥深度学习在大规模数据中的优势。
当然,类似于机器学习,深度学习也有很多参数可以调整了提升模型效果,而且远比机器学习要复杂的多。包括但不限于:
-
网络结构:
- 隐藏层数(当前2层)。
- 每层神经元数(fc1: 64, fc2: 32)。
- 激活函数(fc1和fc2: ReLU, fc3: Sigmoid)。
-
训练参数:
- epochs (当前100)。
- 学习率 (lr=0.001)。
- 优化器 (Adam)。
- 损失函数 (BCELoss)。
-
其他:
- 添加dropout、batch normalization等正则化。
- 批大小 (batch_size)。
因此,如何高效对深度学习网络进行调参也是非常重要的。
改进网络
python
# 改进的深度学习模型(添加dropout和batch normalization)
import torch
import torch.nn as nn
import torch.optim as optim
# 转换为tensor(复用之前的)
X_train_tensor = torch.tensor(X_train_scaled, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train.values, dtype=torch.float32).unsqueeze(1)
X_val_tensor = torch.tensor(X_val_scaled, dtype=torch.float32)
y_val_tensor = torch.tensor(y_val.values, dtype=torch.float32).unsqueeze(1)
# 定义改进的MLP模型
class ImprovedMLP(nn.Module):
def __init__(self, input_size):
super(ImprovedMLP, self).__init__()
self.fc1 = nn.Linear(input_size, 128)
self.bn1 = nn.BatchNorm1d(128)
self.dropout1 = nn.Dropout(0.3)
self.fc2 = nn.Linear(128, 64)
self.bn2 = nn.BatchNorm1d(64)
self.dropout2 = nn.Dropout(0.3)
self.fc3 = nn.Linear(64, 32)
self.bn3 = nn.BatchNorm1d(32)
self.dropout3 = nn.Dropout(0.3)
self.fc4 = nn.Linear(32, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.dropout1(torch.relu(self.bn1(self.fc1(x))))
x = self.dropout2(torch.relu(self.bn2(self.fc2(x))))
x = self.dropout3(torch.relu(self.bn3(self.fc3(x))))
x = self.sigmoid(self.fc4(x))
return x
model = ImprovedMLP(X_train_scaled.shape[1])
# 损失函数和优化器(调整学习率)
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=0.0005)
# 训练模型
epochs = 50
for epoch in range(epochs):
model.train()
optimizer.zero_grad()
outputs = model(X_train_tensor)
loss = criterion(outputs, y_train_tensor)
loss.backward()
optimizer.step()
# 预测
model.eval()
with torch.no_grad():
y_pred_prob = model(X_val_tensor)
y_pred = (y_pred_prob > 0.5).float()
# 计算准确率
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_val, y_pred.numpy().flatten())
print(f"改进深度学习模型验证集准确率: {accuracy:.4f}")
可以看到,改进了如下内容
- 输入层:7个特征(经标准化后)。
- 隐藏层1:128个神经元 + Batch Normalization + Dropout(0.3) + ReLU激活。
- 隐藏层2:64个神经元 + Batch Normalization + Dropout(0.3) + ReLU激活。
- 隐藏层3:32个神经元 + Batch Normalization + Dropout(0.3) + ReLU激活。
- 输出层:1个神经元 + Sigmoid激活(用于二分类概率输出)。
总共4个全连接层,使用Batch Normalization防止过拟合,Dropout(0.3)随机丢弃30%神经元以增强泛化。激活函数为ReLU(隐藏层)和Sigmoid(输出层)。这有助于处理小数据集并提升性能。
但值得注意的是,如果大家将epoch从50调整到100再调整到200,会发现模型准确率逐渐下降 ,这是因为epoch增加时,模型在训练集上学习更多,但可能导致过拟合(overfitting),即模型记住训练数据噪声,而非泛化到验证集。泰坦尼克数据集小(约800样本),易过拟合。
所以,可以添加早停,监控验证损失,当损失不再下降时停止训练。