Banana Slides 深度解析(2):AI Core 架构设计与 Prompt 工程实践
开发生成式 AI 应用的核心挑战在于稳定性 与可控性。大语言模型 (LLM) 具有固有的随机性,如何使其输出符合严格的业务逻辑和数据格式要求,是系统设计的关键。
在 Banana Slides 中,AIService 模块承担了这一核心职责。本文将深入分析其架构设计、Prompt 工程策略以及如何确结构化数据的稳定产出。
1. 核心架构与入口设计
AI 模块的入口类为 backend/services/ai_service.py 中的 AIService。该类不仅封装了所有与 LLM 的交互逻辑,还通过设计模式实现了模型提供商的解耦。
1.1 入口类:AIService
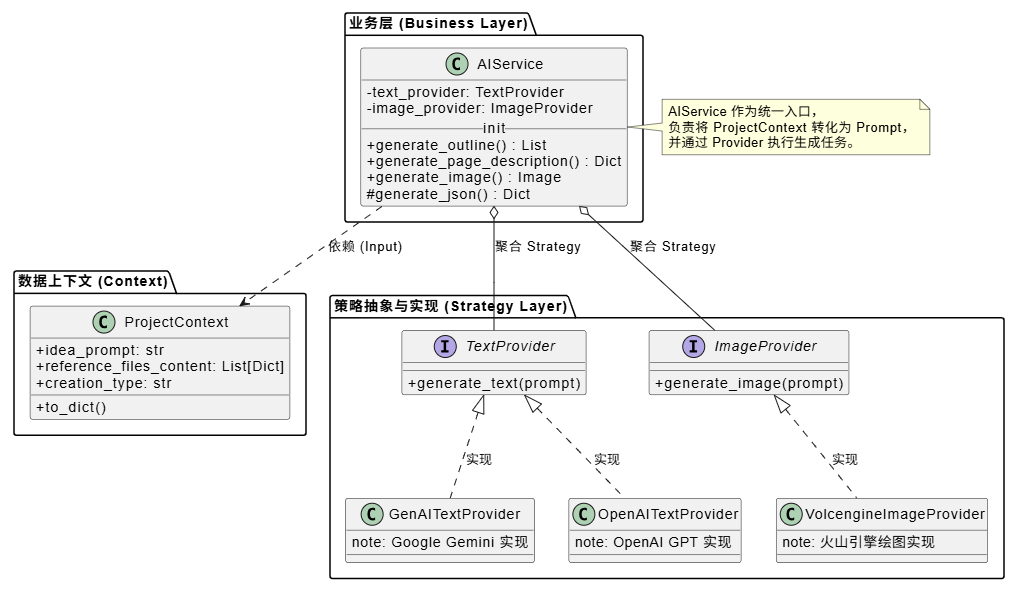
AIService 采用了策略模式 (Strategy Pattern) 进行设计。它定义了统一的业务接口(如 generate_outline, generate_image),而将具体的模型调用逻辑委托给 TextProvider 和 ImageProvider 接口的实现类。这种设计使得系统能够灵活切换底层模型(如从 OpenAI 切换至 Google Gemini 或本地模型),而无需修改上层业务代码。
关键代码结构如下:
python
# backend/services/ai_service.py
class AIService:
"""
AI 服务核心类。
负责协调 Prompt 构建、模型调用及结果解析,对外提供统一的业务接口。
"""
def __init__(self, text_provider: TextProvider = None, image_provider: ImageProvider = None):
# 策略模式应用:依赖注入具体的 Provider 实现
# 若未指定,则根据配置工厂方法获取默认 Provider
self.text_provider = text_provider or get_text_provider(model=self.text_model)
self.image_provider = image_provider or get_image_provider(model=self.image_model)
def generate_outline(self, project_context, language=None):
# 标准流程:构建 Prompt -> 调用模型 -> 解析清洗结果
prompt = get_outline_generation_prompt(
project_context.idea_prompt,
project_context.reference_files_content,
language
)
return self.generate_json(prompt)AIService 作为一个协调者 (Coordinator) ,其核心职责是标准化的:从 prompts.py 获取提示词模板,调用 Provider 执行生成,并对返回结果进行清洗和格式化校验。
1.2 关键类间关系 (PlantUML)
以下类图展示了 AIService 与周边组件的协作关系:
2. 关键业务流程解析
以生成 PPT 大纲 (Outline) 为例,这是一个将非结构化用户需求转化为结构化 JSON 数据的过程。为了保证流程的健壮性,系统在 Prompt 构建和结果解析阶段都做了大量工程化处理。
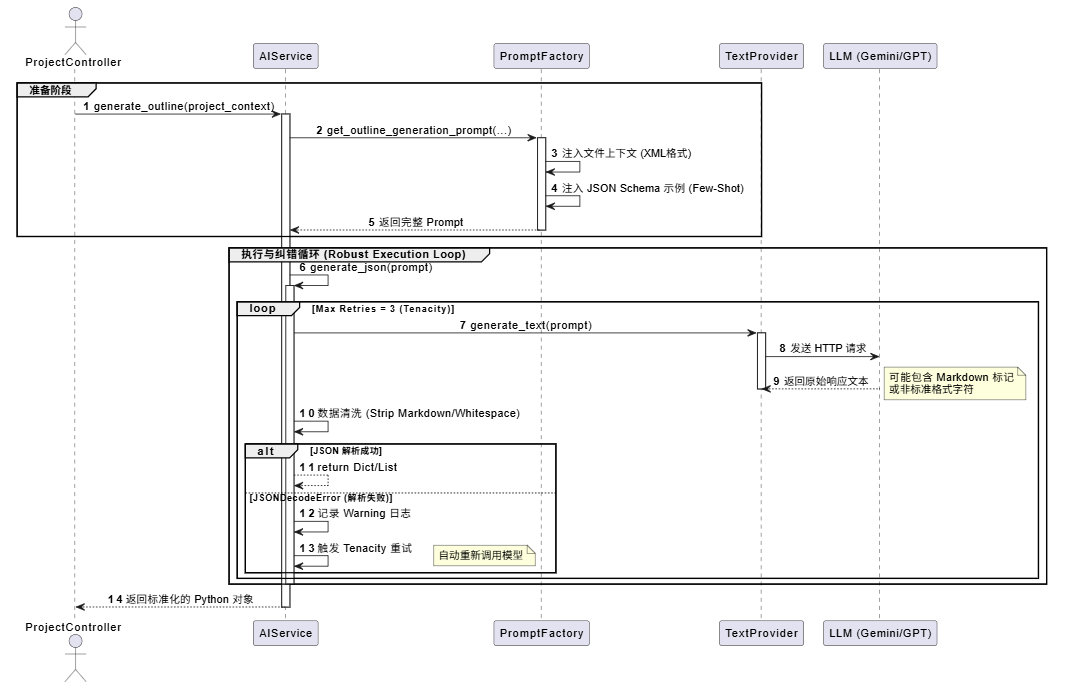
2.1 流程时序图 (Sequence Diagram)
下图展示了从 Controller 发起请求到最终获取结构化数据的完整时序,重点展示了 generate_json 方法中的重试机制 。
3. 实现关键点分析
Banana Slides 在 AI 工程化方面有几个值得深入分析的实践点:
3.1 策略模式实现模型解耦
系统通过定义 TextProvider 和 ImageProvider 抽象基类,屏蔽了不同模型 API 的差异。例如,Google Gemini 支持原生多模态输入,而 OpenAI 早期版本需要将图片转换为 Base64 编码。这些底层实现的差异被完全封装在具体的 Provider 类中,AIService 层无需关注具体实现细节,从而保证了业务逻辑的稳定性。
3.2 鲁棒的 JSON 处理管道
LLM 在输出 JSON 时常会出现格式问题(如包含 Markdown 代码块标记、末尾多余逗号或缺少闭合括号)。Banana Slides 在 generate_json 方法中构建了一个防御性的处理管道:
- 正则清洗 :使用正则表达式自动移除
```json等 Markdown 标记,提取有效的 JSON 字符串片段。 - 重试机制 :引入
tenacity库,对json.JSONDecodeError进行捕获并自动重试。这能够有效应对 LLM 的偶发性生成错误,显著提高了系统成功率。
3.3 上下文注入 (Context Injection)
LLM 是无状态的 (Stateless),为了使其在生成过程中保持对项目整体的认知,系统引入了 ProjectContext 类。
该类聚合了项目的关键信息(用户初始创意、参考文档内容、当前大纲结构等)。在每次请求时,系统会将这些上下文信息动态注入到 Prompt 中。对于参考文档,系统将其解析为 XML 格式嵌入 Prompt,使模型能够基于特定知识库进行生成,模拟了 RAG (Retrieval-Augmented Generation) 的效果。
3.4 Prompt 工程:One-Shot/Few-Shot 策略
在 backend/services/prompts.py 中,我们可以看到大量的 Prompt 模板。系统并没有试图用自然语言详尽描述复杂的 JSON Schema,而是采用了 Few-Shot Prompting 策略,直接提供标准的 JSON 示例。
例如:
text
Examples:
[
{"title": "Introduction", "points": ["Brief history", "Core definition"]},
{"title": "Analysis", "points": ["Data A", "Data B"]}
]这种做法利用了 LLM 强大的上下文模仿能力,相比纯粹的指令描述,能够得到格式更准确、结构更稳定的输出。
4. 总结
Banana Slides 的 AI 核心设计展示了如何通过严谨的软件工程手段弥补大模型的不确定性。其核心设计理念包括:
- 架构解耦:通过策略模式隔离模型依赖。
- 容错设计:通过重试机制和数据清洗应对随机错误。
- 提示工程:通过 Few-Shot 和上下文注入提高生成质量。
这些实践表明,在构建 AI 应用时,稳定的工程架构与算法模型本身同等重要。通过合理的架构设计,可以将不可控的概率性生成转化为可控的确定性业务流程。