免费版Java学习笔记(28w字)链接:https://www.yuque.com/aoyouaoyou/sgcqr8
免费版Java面试题(20w字)链接:https://www.yuque.com/aoyouaoyou/wh3hto
完整版Java学习笔记200w字,附有代码实现,图解清楚,仅需9.9
完整版Java面试题,150w字,高频面试题,内容详细,仅需9.9
完整版:https://www.xiaohongshu.com/user/profile/63c2d512000000002601232c
祝您新的一年事事马到成功,身体健康,阖家幸福,大展宏图!
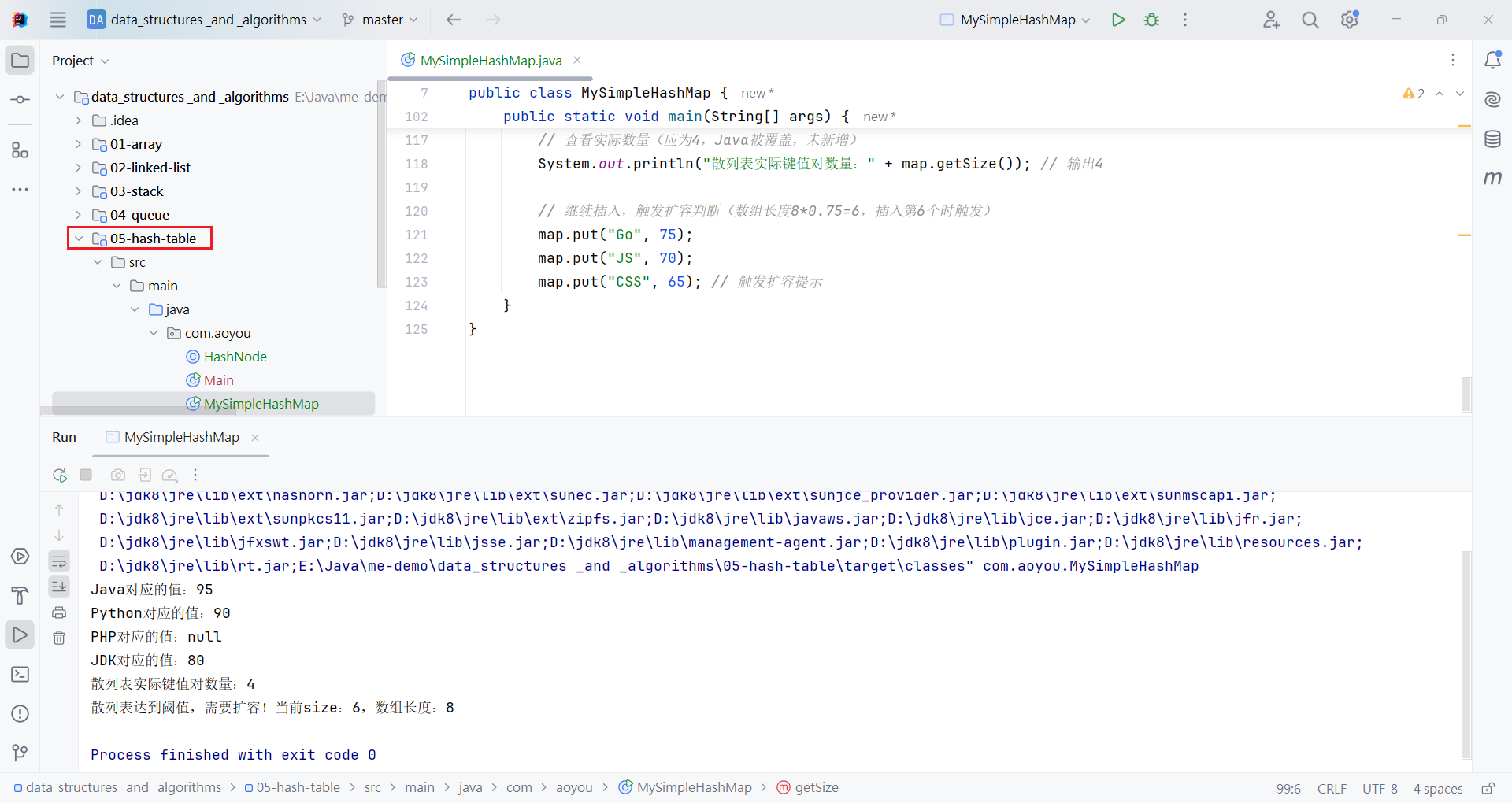
一、散列表概念
1. 定义
散列表(哈希表,Hash Table)是一种通过键(Key) 直接映射值(Value) 的数据结构,实现键值对的高效映射查询,理想情况下时间复杂度接近O(1),是开发中高频使用的非线性结构。
2. 特性
- 底层依托数组实现,数组是散列表的基础存储容器;
- 支持任意类型的Key(以字符串、对象为主),通过哈希函数将Key转换为数组合法下标;
- 价值:将"任意Key"与"数组下标"建立映射,跳过线性遍历,直接定位数据位置。
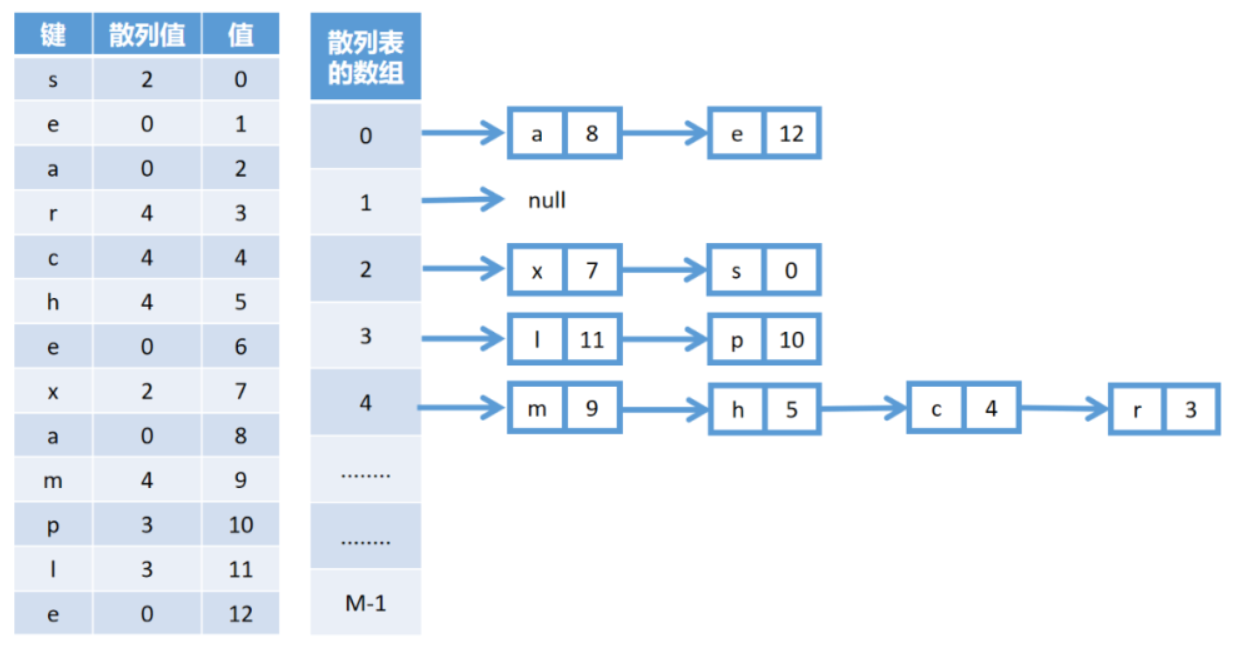
二、散列表存储原理
散列表的是哈希函数 + 数组,通过哈希函数完成Key到数组下标的转换,从而实现Key到Value的快速映射,整体存储逻辑如下:
- 初始化一个固定长度的数组,作为散列表的底层存储;
- 传入键值对时,通过哈希函数对Key进行计算,得到唯一的哈希值;
- 将哈希值转换为数组合法下标(如取模运算),把键值对存储到该下标位置;
- 查询时,对目标Key重复上述哈希计算,直接定位数组下标,获取对应Value。
此处为语雀内容卡片,点击链接查看:https://www.yuque.com/aoyouaoyou/pbz18g/na6onlixdvgsfttp
1. 哈希函数(Hash Function)
定义
将任意长度、任意类型 的Key,通过散列算法转换为固定类型、固定长度的哈希值,再通过后续运算得到数组下标,是散列表的。
要求
- 确定性:同一Key多次计算,必须得到相同哈希值;
- 高效性:计算过程简单,时间复杂度接近O(1);
- 均匀性:哈希值分布均匀,尽可能减少哈希冲突。
常见哈希函数
- 基础哈希:Java中Object的
hashCode()(返回int型哈希值); - 经典算法:CRC16/CRC32、MurmurHash、Times33、SipHash;
- 简单转换公式(Java示例):
数组下标 = Math.abs(Key.hashCode()) % 数组长度,保证下标在[0, 数组长度-1]范围内。
基础哈希计算示例
// 计算Key为"Java"、"Python"的数组下标,数组长度为16
int index1 = Math.abs("Java".hashCode()) % 16;
int index2 = Math.abs("Python".hashCode()) % 16;
System.out.println("Java对应的数组下标:" + index1); // 输出具体数字,如9
System.out.println("Python对应的数组下标:" + index2); // 输出具体数字,如52. 传统Hash与一致性Hash
- 传统Hash:上述基础哈希方式,数组长度固定时查询高效,但数组扩容/缩容后,所有Key需重新计算下标(重新Hash),不适合动态扩展场景;
- 一致性Hash:解决传统Hash的扩展问题,将哈希值映射到环形空间,数组节点也映射到环上,Key按哈希值找到最近的节点存储,扩容时仅需重新映射部分Key,适合分布式缓存(如Redis集群)。
三、哈希冲突(Hash Collision)
1. 定义
由于数组长度有限,不同Key通过哈希函数计算后,得到相同的数组下标,多个键值对需要存储到同一数组位置的情况,称为哈希冲突(哈希碰撞),是散列表无法避免的问题,只能尽可能减少和解决。
2. 两种解决方法
方法1:开放寻址法
原理
当目标数组下标已被占用时,按固定规则寻找下一个空闲位置(如线性探测:下标+1、+2...直到找到空闲位置;二次探测:下标+1²、-1²、+2²...),所有键值对均直接存储在数组中,无额外结构。
特点
- 优点:实现简单,无需额外内存存储指针,CPU缓存命中率高;
- 缺点:冲突越多,探测次数越多,查询效率越低;数组利用率低,易出现"堆积"现象;
- 应用:Java的
ThreadLocal、ConcurrentHashMap的部分实现。
此处为语雀内容卡片,点击链接查看:https://www.yuque.com/aoyouaoyou/pbz18g/ny4mh92yfk6bhk5b
此处为语雀内容卡片,点击链接查看:https://www.yuque.com/aoyouaoyou/pbz18g/sgfga1rcgn0255xx
方法2:链表法(拉链法)
原理
数组的每个下标位置,不仅存储一个键值对,还是一个单链表的头节点 ;当发生哈希冲突时,新的键值对直接作为新节点插入到该链表中 (头插/尾插),链表节点存储Key、Value和后继指针next。
特点
- 优点:解决冲突简单,无需探测空闲位置;数组利用率高,冲突节点仅在链表中追加;
- 缺点:每个链表节点需存储指针,有额外内存开销;链表过长时,查询效率会下降;
- 应用:Java的
HashMap(JDK1.7)、Redis字典、大部分编程语言的散列表实现。
链表法节点结构定义
/**
* 链表法的节点:存储Key、Value,以及后继指针(解决哈希冲突)
*/
public class HashNode {
String key; // 键
Integer value; // 值
HashNode next; // 后继指针,指向同一下标的下一个节点
public HashNode(String key, Integer value) {
this.key = key;
this.value = value;
this.next = null;
}
}3. JDK1.8对链表法的优化
当链表中节点数量超过8个 ,且数组长度大于等于64 时,HashMap会将单链表转换为红黑树 ;当节点数量小于6个时,再从红黑树转回链表。
- 原因:单链表的查询时间复杂度为O(m)(m为链表节点数),红黑树的查询时间复杂度为O(logm),大幅提升多冲突场景下的查询效率;
- 阈值:8是基于泊松分布计算的结果,实际开发中链表节点数达到8的概率极低,兼顾效率和实现复杂度。
四、散列表操作
散列表的操作是写操作(put/插入) 和读操作(get/查询) ,基于链表法实现时,需处理"无冲突"和"有冲突"两种情况,同时包含扩容判断 和键覆盖逻辑。
代码实现(自定义简易HashMap,链表法解决冲突,含put/get/扩容判断)
/**
* 自定义简易散列表(HashMap):链表法解决哈希冲突,模拟JDK1.7逻辑
* 底层:数组 + 单链表,支持put(插入/覆盖)、get(查询),含负载因子和扩容判断
*/
public class MySimpleHashMap {
// 1. 散列表底层数组:存储链表头节点
private HashNode[] table;
// 2. 散列表中实际存储的键值对数量
private int size;
// 3. 负载因子(阈值):默认0.75f,触发扩容的参数
private static final float LOAD_FACTOR = 0.75f;
// 4. 数组初始容量:默认取2的n次方(JDK规定,保证哈希分布均匀),此处设为8
private static final int INIT_CAPACITY = 8;
// 构造方法:初始化散列表
public MySimpleHashMap() {
this.table = new HashNode[INIT_CAPACITY];
this.size = 0;
}
// 方法1:计算Key对应的数组下标(哈希函数+取模)
private int getIndex(String key) {
if (key == null) {
throw new NullPointerException("Key不能为空!");
}
// 哈希计算:hashCode() + 取绝对值 + 取模数组长度
return Math.abs(key.hashCode()) % table.length;
}
// 方法2:写操作(put):插入/覆盖键值对,含扩容判断
public void put(String key, Integer value) {
// 步骤1:判断是否需要扩容(当前数量 >= 数组长度 * 负载因子)
if (size >= table.length * LOAD_FACTOR) {
System.out.println("散列表达到阈值,需要扩容!当前size:" + size + ",数组长度:" + table.length);
// 此处仅打印扩容提示,实际扩容需实现「创建新数组+重新Hash所有键值对」
// resize();
return;
}
// 步骤2:计算数组下标
int index = getIndex(key);
HashNode head = table[index];
// 情况1:该下标无节点(无哈希冲突),直接创建新节点作为头节点
if (head == null) {
table[index] = new HashNode(key, value);
size++;
return;
}
// 情况2:该下标有节点(有哈希冲突),遍历链表
HashNode cur = head;
while (cur != null) {
// 子情况1:链表中存在相同Key,执行值覆盖
if (cur.key.equals(key)) {
cur.value = value;
return;
}
// 子情况2:遍历到链表尾,未找到相同Key,尾插法添加新节点
if (cur.next == null) {
cur.next = new HashNode(key, value);
size++;
return;
}
// 继续遍历链表
cur = cur.next;
}
}
// 方法3:读操作(get):通过Key查询Value,无则返回null
public Integer get(String key) {
// 步骤1:计算数组下标
int index = getIndex(key);
HashNode head = table[index];
// 情况1:该下标无节点,直接返回null
if (head == null) {
return null;
}
// 情况2:该下标有节点,遍历链表查找Key
HashNode cur = head;
while (cur != null) {
if (cur.key.equals(key)) {
return cur.value; // 找到Key,返回对应Value
}
cur = cur.next;
}
// 遍历完链表未找到Key,返回null
return null;
}
// 辅助方法:获取散列表中实际键值对数量
public int getSize() {
return size;
}
// 测试主方法
public static void main(String[] args) {
MySimpleHashMap map = new MySimpleHashMap();
// 插入键值对(含正常插入、哈希冲突、值覆盖)
map.put("Java", 100);
map.put("Python", 90);
map.put("C++", 85);
map.put("Java", 95); // 覆盖原Java的100为95
map.put("JDK", 80); // 大概率与Java哈希冲突,插入到同一链表
// 查询操作
System.out.println("Java对应的值:" + map.get("Java")); // 输出95
System.out.println("Python对应的值:" + map.get("Python"));// 输出90
System.out.println("PHP对应的值:" + map.get("PHP")); // 输出null
System.out.println("JDK对应的值:" + map.get("JDK")); // 输出80
// 查看实际数量(应为4,Java被覆盖,未新增)
System.out.println("散列表实际键值对数量:" + map.getSize()); // 输出4
// 继续插入,触发扩容判断(数组长度8*0.75=6,插入第6个时触发)
map.put("Go", 75);
map.put("JS", 70);
map.put("CSS", 65); // 触发扩容提示
}
}
操作细节
写操作(put)步骤
- 扩容判断:先检查当前键值对数量是否达到「数组长度×负载因子」,达到则先扩容;
- 哈希计算:对Key计算数组下标;
- 无冲突:下标位置无节点,直接创建新节点作为头节点;
- 有冲突 :遍历链表,若存在相同Key则值覆盖 ,否则尾插法添加新节点;
- 更新数量 :新节点插入后,散列表实际数量
size++。
读操作(get)步骤
- 哈希计算:对目标Key计算数组下标;
- 无冲突:下标位置无节点,直接返回null;
- 有冲突:遍历链表,找到相同Key则返回对应Value,遍历完未找到则返回null。
五、散列表扩容(resize)
1. 扩容原因
散列表基于数组实现,当键值对数量增多,哈希冲突概率会大幅提升,若链表过长(或红黑树节点过多),会导致查询/插入效率下降,因此需要通过扩容降低散列表的饱和度,重新分布键值对,减少冲突。
2. 扩容影响因素
- Capacity:散列表底层数组的当前长度(容量);
- LoadFactor(负载因子):散列表的饱和度阈值,默认0.75f(JDK规定),是时间和空间的平衡值(负载因子过小,数组利用率低;过大,冲突概率高);
- 扩容触发条件 :
散列表实际数量(size) >= Capacity × LoadFactor。
3. 扩容步骤(JDK1.7/1.8通用步骤)
- 创建新数组 :新建一个空数组,长度为原数组的2倍(保证2的n次方,使哈希分布更均匀);
- 重新Hash :遍历原数组的所有节点(包括数组直接节点和链表/红黑树节点),对每个节点的Key重新计算数组下标(基于新数组长度);
- 迁移节点:将原节点重新存储到新数组的对应下标位置;
- 替换数组:将散列表的底层数组引用,指向新数组,原数组被GC回收;
- 重置参数 :更新散列表的容量为新数组长度,实际数量
size保持不变。
4. JDK1.7与1.8扩容差异
- JDK1.7 :链表采用头插法 迁移节点,导致原链表顺序反转 ,高并发场景下可能形成循环链表,引发死循环;
- JDK1.8 :链表采用尾插法迁移节点,保持原链表顺序,解决了死循环问题;同时红黑树迁移后,若节点数小于6,会转回链表。
此处为语雀内容卡片,点击链接查看:https://www.yuque.com/aoyouaoyou/pw1w5m/raxmeqxck9p1x2se
六、散列表时间复杂度
散列表的时间复杂度与哈希冲突程度 、是否触发扩容强相关,操作时间复杂度如下(m为单链表节点数,n为散列表总键值对数):
|------------|-----------|------------|-------|
| 操作类型 | 理想情况(无冲突) | 有哈希冲突(链表法) | 触发扩容时 |
| 写操作(put) | O(1) | O(m) | O(n) |
| 读操作(get) | O(1) | O(m) | - |
| 哈希冲突处理 | - | O(m)(链表遍历) | - |
| 扩容(resize) | - | - | O(n) |
结论:理想情况下所有操作均为O(1);实际开发中,哈希函数设计良好时,m极小(接近1),因此时间复杂度仍接近O(1);JDK1.8红黑树优化后,冲突场景下复杂度降为O(logm)。
七、散列表优缺点
优点
- 查询/插入/删除高效:理想情况下时间复杂度接近O(1),远优于数组、链表的线性遍历;
- 键值对映射直观:直接通过Key定位Value,无需额外索引,开发使用便捷;
- 存储灵活:Key支持多种类型(字符串、对象等),Value可存储任意数据。
缺点
- 无法避免哈希冲突:只能通过哈希函数和解决方法尽可能减少,冲突过多会降低效率;
- 元素无序:键值对按哈希值分布在数组中,无固定顺序,无法直接按顺序遍历;
- 扩容开销大:扩容时需重新Hash并迁移所有节点,时间复杂度O(n),低频但耗时;
- 内存利用率问题:开放寻址法易浪费数组空间,链表法需额外存储指针,红黑树实现复杂。
八、散列表经典应用
散列表是工业级开发中最常用的数据结构之一,从编程语言底层到中间件、分布式系统均有广泛应用,应用如下:
1. 编程语言内置容器
- Java:
HashMap、HashTable、ConcurrentHashMap(线程安全)、LinkedHashMap(有序散列表); - Python:
dict(字典,底层为散列表); - C++:
unordered_map,均基于散列表实现,提供高效的键值对操作。
2. 中间件
- Redis字典 :Redis的数据结构之一,整个Redis数据库、Hash类型均基于字典实现,采用链表法解决哈希冲突,支持动态扩容;
- Memcached:分布式缓存,底层通过散列表存储键值对,实现高速缓存查询。
3. 经典衍生结构/算法
(1)布隆过滤器(Bloom Filter)
- 原理:基于二进制向量 + 多个独立哈希函数,将元素映射到二进制向量的多个位置并置1;查询时,若所有位置均为1则元素"可能存在",若有一个为0则"一定不存在";
- 特点:空间效率和查询效率极高,存在假阳性(无法完全确定元素存在),无假阴性;
- 应用:Redis缓存穿透防护、海量数据去重、爬虫URL去重。
此处为语雀内容卡片,点击链接查看:https://www.yuque.com/aoyouaoyou/pbz18g/km0xppm9cgndcwqz
(2)位图(Bitmap)
- 原理:用1个bit位标记一个元素的状态(0/1),Key为元素值,Value为bit位状态,底层基于数组实现(数组每个元素占多个bit);
- 特点:极致节省内存(1个int占32bit,可标记32个元素);
- 应用:海量数据去重、排序、统计(如统计用户登录状态、海量整数去重)。
4. 业务开发场景
- 缓存系统:本地缓存、分布式缓存,通过Key快速查询缓存数据;
- 数据索引:数据库索引(如MySQL的哈希索引),快速定位数据行;
- 配置中心:存储系统配置的键值对,快速查询和更新配置。
九、总结
- 散列表是键值对映射 的数据结构,底层基于数组 实现,是哈希函数,理想时间复杂度接近O(1);
- 哈希冲突无法避免,主流解决方法为开放寻址法 (适合小数据量)和链表法 (适合大数据量),JDK1.8将长链表优化为红黑树,提升冲突场景效率;
- 扩容是散列表的重要机制,触发条件为
size >= 容量×负载因子,JDK1.8通过尾插法解决了1.7的扩容死循环问题; - 散列表的平衡是负载因子,默认0.75f兼顾时间和空间效率,是工业级实现的标准值;
- 散列表是编程语言容器、Redis、缓存系统的底层基础,衍生出布隆过滤器、位图等高效结构,是开发中必备的数据结构。