《智能的理论》全书转至目录****
不同AGI的研究路线对比简化版:《AGI(具身智能)路线对比》,欢迎各位参与讨论、批评或建议。
一.从被动视觉到主动视觉
1.计算视觉理论(被动视觉)
在七十年代中期,美国麻省理工学院的Marr综合信息处理、心理学以及神经生理学的研究成果,从信息科学的角度提出了第一个较为完整的计算机视觉理论框架,即计算视觉理论。该理论将视觉描述为从二维图像中对图像进行重塑,经过一系列的处理和转换,并最终形成三维图像的过程(9-19:物体识别)。
然而,该理论存在三点问题。第一,图像是真实世界中三维物体的二维投影,从三维到二维的过程中必然存在信息丢失。并且几何特征、光照、物体材料表面性质、物体的颜色、摄像机参数等多种转换因素决定了这个转换的过程。因此,由物体的二维图像投影反推其三维结构时,若缺乏考虑足够多的转换因素,三维重建的信息损失会将更为严重;第二,视觉计算理论中的信息流通路是自下而上单一方向的,对高层知识的引导和反馈缺乏足够的重视,与人类视觉系统有目的的、主动的认知过程相距甚远(刘琼,秦世引和李志成,2010);第三,产生这些通用的、精确的三维模型往往需要太高的代价,这与大脑处理能力的有限性矛盾。随着时间的推移,计算视觉理论研究遇到了越来越多的困难,人们不得不对Marr理论进行反思。
2.主动视觉(厉阳春,2008;刘成君和戴汝为,2015)
主动视觉的思想来源于人工智能领域对"感知-动作"的研究,在主动视觉框架中,视觉系统体现了视觉行为及其所支持动作的紧密结合。与以往的被动视觉相比,使个体从以往的观察者成为行动者,从被动接受者成为主动行为者,从孤立的视觉研究到人类整体的认知行为中的视觉研究。
人类的主动视觉行为是为了完成任务的前提下,在记忆与注意的共同引导下,通过行为驱动视觉感知。具体的说,行为驱动视觉感知是:主动控制身体的参数来协调所需要处理的任务和视觉信号的关系,这些参数包括身体的位置、注意点、晶状体和瞳孔的聚焦等。比如,如果目标物太远看不清晰或者存在遮挡使物体分类存在不确定因素,可以通过调整身体位置解决,同时调整身体位置观察也可以更直接的解决物体三维构造识别的问题,又如通过调整注意和注视点观察兴趣或目标。
主动视觉的特点如下:
(a)视觉是主动的,生物视觉的研究表明,感知不仅是对外界刺激的被动反映,而更应是有目的、有选择地主动搜索感兴趣信息的过程,即视觉必须服务于特定的目的的;
(b)视觉是有选择性,如果以前的被动视觉局限于将输入的视觉数据映射到一个其他层次上的表达的话(如图像分类、图像分割),那么主动视觉还包括对时空信息的选择性地获得。这种选择性表现在两个方面,一是空间选择,通过控制动作(身体或注视点)对准场景中与任务相关的部分;二是分辨率选择,对分布于不同空间范围和时间段上的信号采用不同的分辨率有选择性地感知(眼睛分为中央凹视觉和外周视觉,中央凹视觉的分辨率最高,外周的相对较低)。虽然主动视觉的选择性限制了获取信息量的大小,但多次的注视弥补了这种不足。
(c)"感知-动作"过程,视觉与动作是一个协调交互的过程。
二.主动视觉中的注意(刘琼梅和谌艳春,2009)
为了解决输入信息量大而大脑处理能力有限的矛盾,人类视觉系统除了采用非均匀采样外(中央凹与外周视觉分辨率的区别),另一种重要机制就是视觉注意。通过注意机制,选择场景中感兴趣的区域,从一个区域转向另一个区域,从而将场景理解问题分解成一系列对信息处理要求不高的局部的视觉分析问题。
既然视觉注意就是对场景的选择。那么,很自然会提到以下两个问题:一是选择的依据,即根据什么来选择场景;二是选择的对象,即视觉注意选择的是空间某个区域还是某个目标?
1.视觉注意选择的依据
视觉选择的依据有两类:
一是自下而上基于特征的信息,它包括图像的动态和静态特征。静态特征指的是图像的颜色、纹理、亮度等,而动态特征指的是目标的运动特征。自下而上的视觉注意相对简单,并且有很多计算模型。Itti等人(Itti,Koch和Niebur 1998)提出的自下而上模型如图1所示。具体分为4个步骤,(a)该模型利用生物的"中央-外周"机制提取多尺度的低级特征,形成各个尺度的颜色、灰度和方位3个显著性特征描述;(b)分别在不同尺度上对3种特征进行线性组合,形成不同尺度的显著性地图(当某个位置的特征与周围位置的特征差别越大时,显著越高,越容易吸引注意);(c)一个赢者通吃网络(WTA)用于将注意力集中于当前最显著的图像区域,并提取该位置的信息同时抑制其他位置的信息;(d)提取完信息后,返回抑制(预览效应,9-15:视觉注意)抑制了当前所注意的位置,使得注意力能移至下一个最显著的位置。
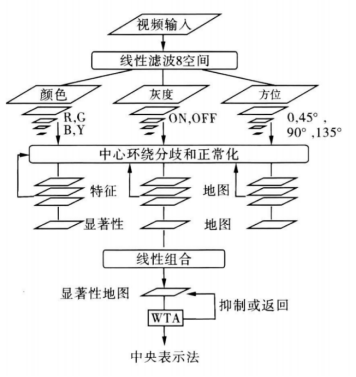
图1
二是自上而下基于任务或目标的信息。如人在行走的过程中只需注意两个点,即远方的一个点(用于控制行走的方向)和近处路面上的一个点(用于检测障碍物的存在)。如果在行走的过程中没有特殊情况出现,人的"注意点"就在这两个点之间交替。
2.视觉注意选择的对象
目前有两种观点:一种是基于空间的注意,一种是基于对象的注意(9-15:视觉注意)。这两种注意选择机制并不是相互排斥互不相容的。相反,它们可以相互补充,用于不同的时机,前者可用于前注意阶段和注意阶段,而后者只用于注意阶段。
三."感知-动作"过程(赵怀永和吴灵丹,2007)
视觉在人类与环境交互的过程中发挥着重要的作用:表征世界和控制动作。在以往的很长一段时间里,视觉都被作为被动的过程来研究,视觉的目的仅仅是从视网膜输入中得到一个真实的外部视觉表征(表征世界)。这在一定程度上孤立了视觉,将其与人的其它认知和行为功能分隔开来。眼动和行动间的紧密而一致的联结表明,人类是通过眼动主动地选择并获取当前任务所需要的信息,并将这些信息用于任务和运动。主动视觉的研究正是强调眼睛如何运动,以从环境中提取信息以及如何加工被提取的信息,来支持个体的行动并完成任务(控制动作)。
1.场景表征与眼动
对于场景中其他不被注视的视觉表征能否被保持?一项研究对此进行了考察。在该研究实验中,被试需要在虚拟环境中从仓库区逐一地取出材料到工作区去复制一个玩具模型(当被试注视工作区时被试看不到仓库区,反之亦然)。被试在两种条件下完成实验,一是仓库区材料位置无变化,二是仓库区材料位置随机变化。在材料位置变化的条件下,每当被试取到材料,注视点跳出仓库区时,仓库区内的材料的摆放位置就会随机地被改变。实验发现,在被试取材料时,约有20%的概率注视点会直接跳到仓库区下一个需要的材料上或者该材料在仓库区变化之前的原位置上。而且,在引入材料位置变化后,被试在仓库区用于搜索材料的注视的次数显著增多。注视次数的增加可以解释为被试记住了所需材料在仓库区的位置,而当材料的位置被改变时,被试不得不进行眼动来重新搜索所需的材料。由此可以认为,被试在注视仓库区的过程中形成了对材料布局的表征,而且当被试下一次到仓库区取材料时,此表征指导了被试的眼动。
2.场景信息的稳定性
虽然在动作任务中,人类的眼睛会快速地跳转到特定区域来获得任务所需的信息。但是,这并不是说每次注视都会生成一个全新的视景表征。从上述论述可见,在注视之间和任务相关的视景信息能够被保持下来。人类在体验着一个稳定的视觉世界,而不是一系列的短暂的视景片断。另一方面,稳定的视觉场景表征也表明了,主动视觉并不意味着人类对视景信息的贫乏(场景信息是稳定存在于大脑中)。相比被动视觉(直接从视觉中构建整个场景表征),主动视觉并不是消耗大量认知资源来获得并保持一个高质量的视觉场景表征,而是更经济地在时间的扩展中通过眼动来获得当前所需的视觉信息。
3.眼动和动作的协调
一项研究考察了个体泡茶时的眼动,并因此将视觉的动作控制功能细分为四种形式:(a)将注视点定位到要用的物体上;(b)指导手或手中物体到新位置;(c)引导一物体趋近另一物体;(d)检查某操作的状态。在做三明治和用手操作物体的研究中也报告了注视的上述功能。
个体行走和驾驶汽车时的眼动如何对个体运动进行控制?在一项的研究中,被试需要踩着路面上画好的脚印行走一段距离。通过对眼动记录的分析发现,视觉以前馈的方式控制个体的行走,即被试并非注视当前的要踩到的脚印,而是注视当前脚步前面的大约第二个脚印。另外,对个体驾驶汽车的研究同样发现,当将要驶入弯道时,个体在转动方向盘之前总是注视弯道的内侧边缘,即弯道的内切点。因此,研究者认为弯道的内切点与汽车前进方向的相对角度提供了弯道的弯曲度信息,驾驶员利用此信息来控制行驶方向。
一些体育项目通常对个体的动作控制要求很高,而其中个体的眼动反映了视觉对动作的预测控制。例如在打板球时,击球手需要在球发出之后的短暂时间内根据球的飞行来计算合适的击球位置和时间。研究发现,击球手总是先注视着球的发出,然后进行预测性的眼跳去注视预计的球在地面上的反弹点。在球投出后的几百毫秒内,击球手从球的飞行轨迹中得到足够的信息去预测球在地面的反弹点,从而得到球随后的飞行轨迹的准确信息来击球。
4.调谐结构
获取的视觉信息和其所控制的动作行为并不是独立的,而是一个协调交互的过程。调谐结构是指眼动和身体各部分的动作的协调,使特定的视觉信息适时地"注入"正在实施的动作当中。研究显示了视动任务中眼、头和手的有节奏的相互协调运动。在上述"复制玩具模型"的实验中,被试从仓库区逐个取出材料放到工作区来复制出玩具模型。在此过程中,被试的手、注视点和头的朝向总是在仓库区和工作区之间有节奏地来回往复,而且眼动总是最先发生,然后依次是头动、手动。眼动和手动间的协调非常紧密,在某些情况下手动甚至会被推迟,以待眼睛完成对玩具模型的注视又可以指导手动。身体的调谐结构使眼、手和头有节奏地相互协调来完成任务。
5."感知-动作"之间的映射连接
在学习新异视觉-运动的任务(一项未执行过的或不熟悉的需要视觉配合的动作任务)中,眼和手的如何协调?在一项实验中,被试的任务是用双手旋转、拉伸或挤压一个控制器以控制电脑鼠标去点击屏幕上连续出现的目标物。结果发现,在被试学习过程中眼动和手动的协调可以分为三个阶段。在初始的探索阶段,被试的目标物击中率很低,鼠标位置变化很大,注视点追随鼠标的移动。在随后的技能掌握阶段,被试的目标物击中率迅速提高,眼睛开始提前注视所预测的鼠标位置。在最后的技能完善阶段,被试的目标击中率继续逐步提升。该研究表明,在探索阶段,被试试图建立一种基本的手动与眼动指令的映射规则。在此过程中,被试可能建立起了两种连接:一是手部动作指令与动作结果视觉信息之间的连接(即怎么样的动作会得到怎么样的结果(结果通过视觉表现出来)),二是眼动指令和手部动作指令之间的连接。简单点说,即怎么样的动作预测了什么样的结果,然后由眼动引导了这个动作。当被试熟练地掌握了动作技能之后,这种映射规则就已建立并完善了。
6.自动化
在泡茶这一日常熟练任务中,眼动总是在身体动作之前发生以指导动作执行,然而这种眼动并没有被个体意识到。因此,研究者认为如果一个任务的执行形成了自动化,那么不只是动作执行本身而是整个负责任务执行的控制系统都形成了自动化,包括个体的眼动。由于个体在泡茶任务前"眼动-手段"就已经形成自动化,所以个体几乎不会意识到视觉对任务执行的监控。