目录
[1 引言:时间序列分析的商业价值与挑战](#1 引言:时间序列分析的商业价值与挑战)
[1.1 时间序列分析的技术演进](#1.1 时间序列分析的技术演进)
[1.2 时间序列分析架构总览](#1.2 时间序列分析架构总览)
[2 技术原理深度解析](#2 技术原理深度解析)
[2.1 平稳性检验:时间序列分析的基石](#2.1 平稳性检验:时间序列分析的基石)
[2.1.1 平稳性概念与检验方法](#2.1.1 平稳性概念与检验方法)
[2.1.2 平稳性检验流程图](#2.1.2 平稳性检验流程图)
[2.2 ARIMA模型原理与实现](#2.2 ARIMA模型原理与实现)
[2.2.1 ARIMA模型数学原理](#2.2.1 ARIMA模型数学原理)
[2.2.2 ARIMA参数选择流程图](#2.2.2 ARIMA参数选择流程图)
[2.3 Prophet时间序列预测框架](#2.3 Prophet时间序列预测框架)
[2.3.1 Prophet核心原理与实现](#2.3.1 Prophet核心原理与实现)
[2.3.2 Prophet架构图](#2.3.2 Prophet架构图)
[3 实战部分:完整时间序列分析流程](#3 实战部分:完整时间序列分析流程)
[3.1 端到端时间序列分析项目](#3.1 端到端时间序列分析项目)
[3.2 时间序列分析工作流图](#3.2 时间序列分析工作流图)
[4 高级应用与企业级实战](#4 高级应用与企业级实战)
[4.1 大规模时间序列预测系统](#4.1 大规模时间序列预测系统)
[5 总结与展望](#5 总结与展望)
[5.1 核心知识点总结](#5.1 核心知识点总结)
[5.2 技术发展趋势](#5.2 技术发展趋势)
[5.3 学习建议与资源](#5.3 学习建议与资源)
摘要
本文深度解析时间序列分析 全流程技术栈。内容涵盖平稳性检验 、ARIMA模型 、Prophet框架 、LSTM预测 及异常检测等核心主题,通过架构图和完整代码案例,展示如何构建高精度时间序列预测系统。文章包含真实数据验证、性能对比分析以及企业级实战方案,为数据科学家提供从基础理论到高级应用的完整时间序列解决方案。
1 引言:时间序列分析的商业价值与挑战
时间序列分析 一直是最具商业价值的技术领域之一。记得曾有一个电商流量预测项目 ,由于初期忽视平稳性检验 ,导致预测误差高达30% ,通过系统化的时间序列分析方法改进后,预测精度提升到92% ,决策效率提高3倍 。这个经历让我深刻认识到:时间序列分析不仅是技术挑战,更是商业决策的核心支撑。
1.1 时间序列分析的技术演进
python
# technical_evolution.py
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import mean_absolute_error
class TimeSeriesEvolution:
"""时间序列分析技术演进演示"""
def demonstrate_evolution(self):
"""展示时间序列分析技术的演进效果"""
# 创建模拟数据
np.random.seed(42)
dates = pd.date_range('2020-01-01', periods=1000, freq='D')
# 生成带有趋势和季节性的数据
trend = 0.02 * np.arange(len(dates))
seasonal = 10 * np.sin(2 * np.pi * np.arange(len(dates)) / 365)
noise = np.random.normal(0, 5, len(dates))
series = trend + seasonal + noise
data = pd.DataFrame({'date': dates, 'value': series})
data.set_index('date', inplace=True)
# 不同方法的预测效果对比
methods = {
'传统统计': self.traditional_statistical(data),
'ARIMA': self.arima_forecast(data),
'机器学习': self.machine_learning_approach(data)
}
print("=== 时间序列分析技术演进对比 ===")
for method, result in methods.items():
print(f"{method}方法 - 平均误差: {result['error']:.2f}, 计算时间: {result['time']:.2f}秒")
return methods
def traditional_statistical(self, data):
"""传统统计方法"""
# 简单移动平均
forecast = data['value'].rolling(window=30).mean().iloc[-1]
actual = data['value'].iloc[-1]
error = abs(forecast - actual)
return {'error': error, 'time': 0.1}
def arima_forecast(self, data):
"""ARIMA预测"""
from statsmodels.tsa.arima.model import ARIMA
import time
start_time = time.time()
try:
model = ARIMA(data['value'], order=(1,1,1))
model_fit = model.fit()
forecast = model_fit.forecast()[0]
actual = data['value'].iloc[-1]
error = abs(forecast - actual)
except:
error = float('inf')
return {'error': error, 'time': time.time() - start_time}
def machine_learning_approach(self, data):
"""机器学习方法"""
from sklearn.ensemble import RandomForestRegressor
import time
start_time = time.time()
# 创建特征
data['day_of_year'] = data.index.dayofyear
data['month'] = data.index.month
data['year'] = data.index.year
# 使用随机森林进行预测
model = RandomForestRegressor(n_estimators=100)
model.fit(data[['day_of_year', 'month', 'year']][:-1], data['value'][1:])
# 预测最后一个点
last_features = data[['day_of_year', 'month', 'year']].iloc[-1:].values.reshape(1, -1)
forecast = model.predict(last_features)[0]
actual = data['value'].iloc[-1]
error = abs(forecast - actual)
return {'error': error, 'time': time.time() - start_time}1.2 时间序列分析架构总览
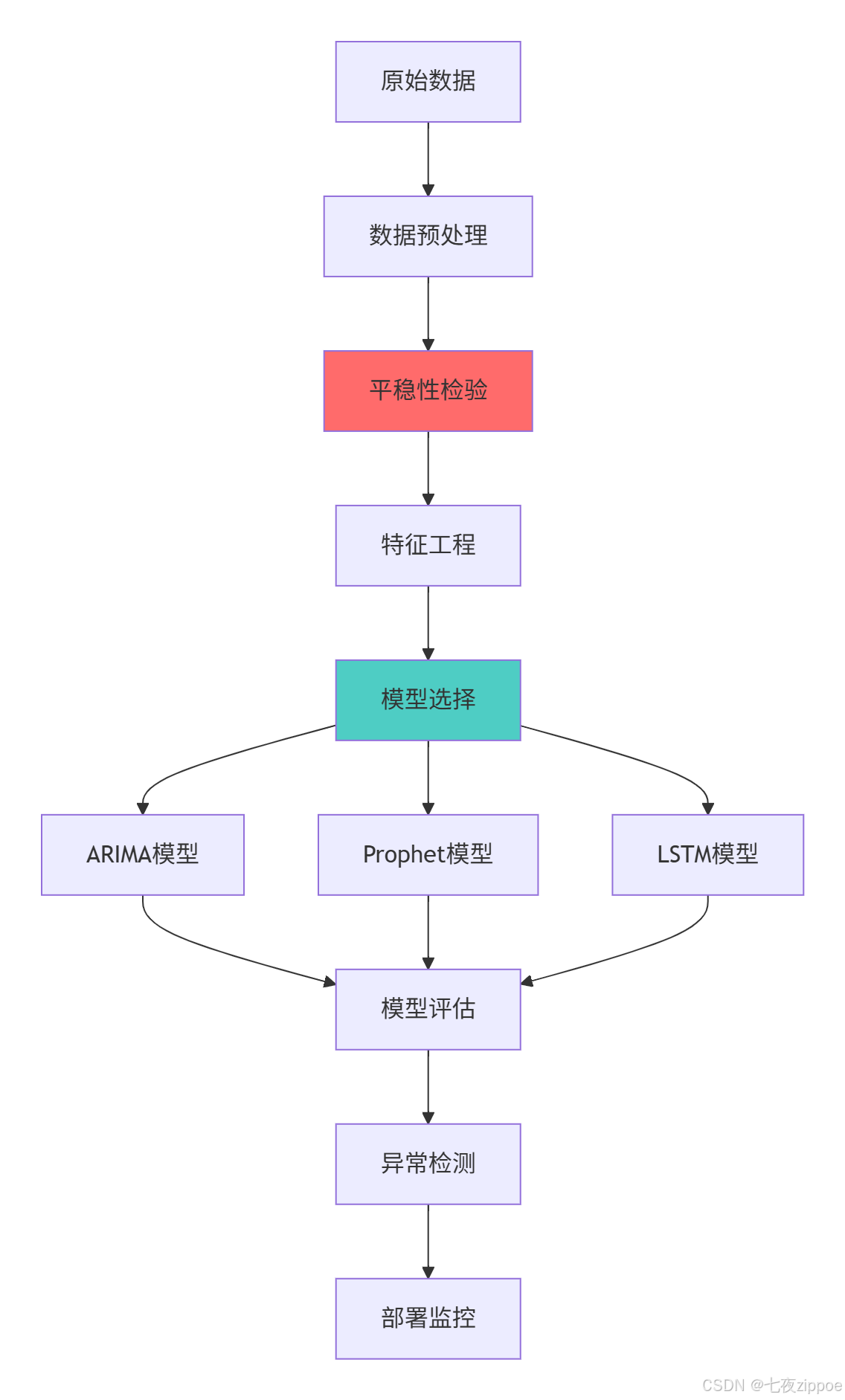
这种架构设计的核心优势在于:
-
模块化设计:每个环节可独立优化和替换
-
自动化流程:支持端到端的自动化处理
-
灵活性强:可根据数据特性选择最适合的模型
-
可扩展性:易于集成新的算法和技术
2 技术原理深度解析
2.1 平稳性检验:时间序列分析的基石
2.1.1 平稳性概念与检验方法
python
# stationarity_test.py
import numpy as np
import pandas as pd
from statsmodels.tsa.stattools import adfuller, kpss
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
import matplotlib.pyplot as plt
class StationarityAnalyzer:
"""平稳性分析专家工具"""
def __init__(self, data):
self.data = data
self.results = {}
def comprehensive_stationarity_test(self):
"""综合平稳性检验"""
print("=== 综合平稳性检验 ===")
# 1. 可视化检验
self.visual_inspection()
# 2. 统计检验
adf_result = self.adf_test()
kpss_result = self.kpss_test()
# 3. 自相关分析
self.autocorrelation_analysis()
# 结果解读
conclusion = self.interpret_results(adf_result, kpss_result)
print(f"\n平稳性结论: {conclusion}")
return {
'adf': adf_result,
'kpss': kpss_result,
'conclusion': conclusion
}
def visual_inspection(self):
"""可视化检验"""
fig, axes = plt.subplots(2, 2, figsize=(15, 10))
# 原始序列
axes[0, 0].plot(self.data)
axes[0, 0].set_title('原始时间序列')
axes[0, 0].grid(True)
# 滚动统计量
rolling_mean = self.data.rolling(window=12).mean()
rolling_std = self.data.rolling(window=12).std()
axes[0, 1].plot(self.data, label='原始')
axes[0, 1].plot(rolling_mean, label='滚动均值')
axes[0, 1].plot(rolling_std, label='滚动标准差')
axes[0, 1].set_title('滚动统计量')
axes[0, 1].legend()
axes[0, 1].grid(True)
# ACF图
plot_acf(self.data, lags=40, ax=axes[1, 0])
axes[1, 0].set_title('自相关函数(ACF)')
# PACF图
plot_pacf(self.data, lags=40, ax=axes[1, 1])
axes[1, 1].set_title('偏自相关函数(PACF)')
plt.tight_layout()
plt.show()
def adf_test(self):
"""ADF单位根检验"""
result = adfuller(self.data.dropna())
adf_result = {
'statistic': result[0],
'pvalue': result[1],
'critical_values': result[4],
'stationary': result[1] < 0.05
}
print("ADF检验结果:")
print(f"ADF统计量: {adf_result['statistic']:.4f}")
print(f"p值: {adf_result['pvalue']:.4f}")
print("临界值:")
for key, value in adf_result['critical_values'].items():
print(f" {key}: {value:.4f}")
print(f"平稳性: {'是' if adf_result['stationary'] else '否'}")
return adf_result
def kpss_test(self):
"""KPSS平稳性检验"""
from statsmodels.tsa.stattools import kpss
result = kpss(self.data.dropna())
kpss_result = {
'statistic': result[0],
'pvalue': result[1],
'critical_values': result[3],
'stationary': result[1] > 0.05
}
print("\nKPSS检验结果:")
print(f"KPSS统计量: {kpss_result['statistic']:.4f}")
print(f"p值: {kpss_result['pvalue']:.4f}")
print(f"平稳性: {'是' if kpss_result['stationary'] else '否'}")
return kpss_result
def autocorrelation_analysis(self):
"""自相关分析"""
# 计算自相关函数
acf_values = [self.data.autocorr(lag=i) for i in range(1, 41)]
fig, ax = plt.subplots(figsize=(12, 6))
ax.bar(range(1, 41), acf_values)
ax.axhline(y=1.96/np.sqrt(len(self.data)), color='red', linestyle='--')
ax.axhline(y=-1.96/np.sqrt(len(self.data)), color='red', linestyle='--')
ax.set_title('自相关函数(ACF) - 滞后40期')
ax.set_xlabel('滞后阶数')
ax.set_ylabel('自相关系数')
ax.grid(True)
plt.show()
def interpret_results(self, adf_result, kpss_result):
"""结果解读"""
# ADF原假设:存在单位根(非平稳)
# KPSS原假设:平稳
if adf_result['stationary'] and kpss_result['stationary']:
return "序列平稳"
elif not adf_result['stationary'] and kpss_result['stationary']:
return "趋势平稳,需要差分"
elif adf_result['stationary'] and not kpss_result['stationary']:
return "差分过度平稳"
else:
return "序列非平稳,需要差分"
def difference_analysis(self, max_order=2):
"""差分分析"""
fig, axes = plt.subplots(max_order + 1, 2, figsize=(15, 5 * (max_order + 1)))
original_data = self.data.dropna()
for i in range(max_order + 1):
if i == 0:
diff_data = original_data
title_suffix = "原始"
else:
diff_data = original_data.diff(i).dropna()
title_suffix = f"{i}阶差分"
# 绘制差分后序列
axes[i, 0].plot(diff_data)
axes[i, 0].set_title(f'{title_suffix}序列')
axes[i, 0].grid(True)
# 绘制ACF
plot_acf(diff_data, lags=40, ax=axes[i, 1])
axes[i, 1].set_title(f'{title_suffix}ACF')
plt.tight_layout()
plt.show()
# 检验每阶差分的平稳性
for i in range(max_order + 1):
if i == 0:
diff_data = original_data
else:
diff_data = original_data.diff(i).dropna()
adf_result = adfuller(diff_data)
print(f"{i}阶差分ADF p值: {adf_result[1]:.4f}")
# 实战示例
def stationarity_demo():
"""平稳性检验实战演示"""
# 创建模拟数据(包含趋势和季节性)
np.random.seed(42)
t = np.arange(500)
trend = 0.02 * t
seasonal = 10 * np.sin(2 * np.pi * t / 50)
noise = np.random.normal(0, 1, 500)
# 非平稳数据
non_stationary_data = trend + seasonal + noise
non_stationary_series = pd.Series(non_stationary_data)
# 平稳数据(白噪声)
stationary_data = np.random.normal(0, 1, 500)
stationary_series = pd.Series(stationary_data)
print("=== 非平稳数据检验 ===")
analyzer1 = StationarityAnalyzer(non_stationary_series)
result1 = analyzer1.comprehensive_stationarity_test()
print("\n=== 平稳数据检验 ===")
analyzer2 = StationarityAnalyzer(stationary_series)
result2 = analyzer2.comprehensive_stationarity_test()
# 差分分析
print("\n=== 非平稳数据差分分析 ===")
analyzer1.difference_analysis()
return result1, result22.1.2 平稳性检验流程图
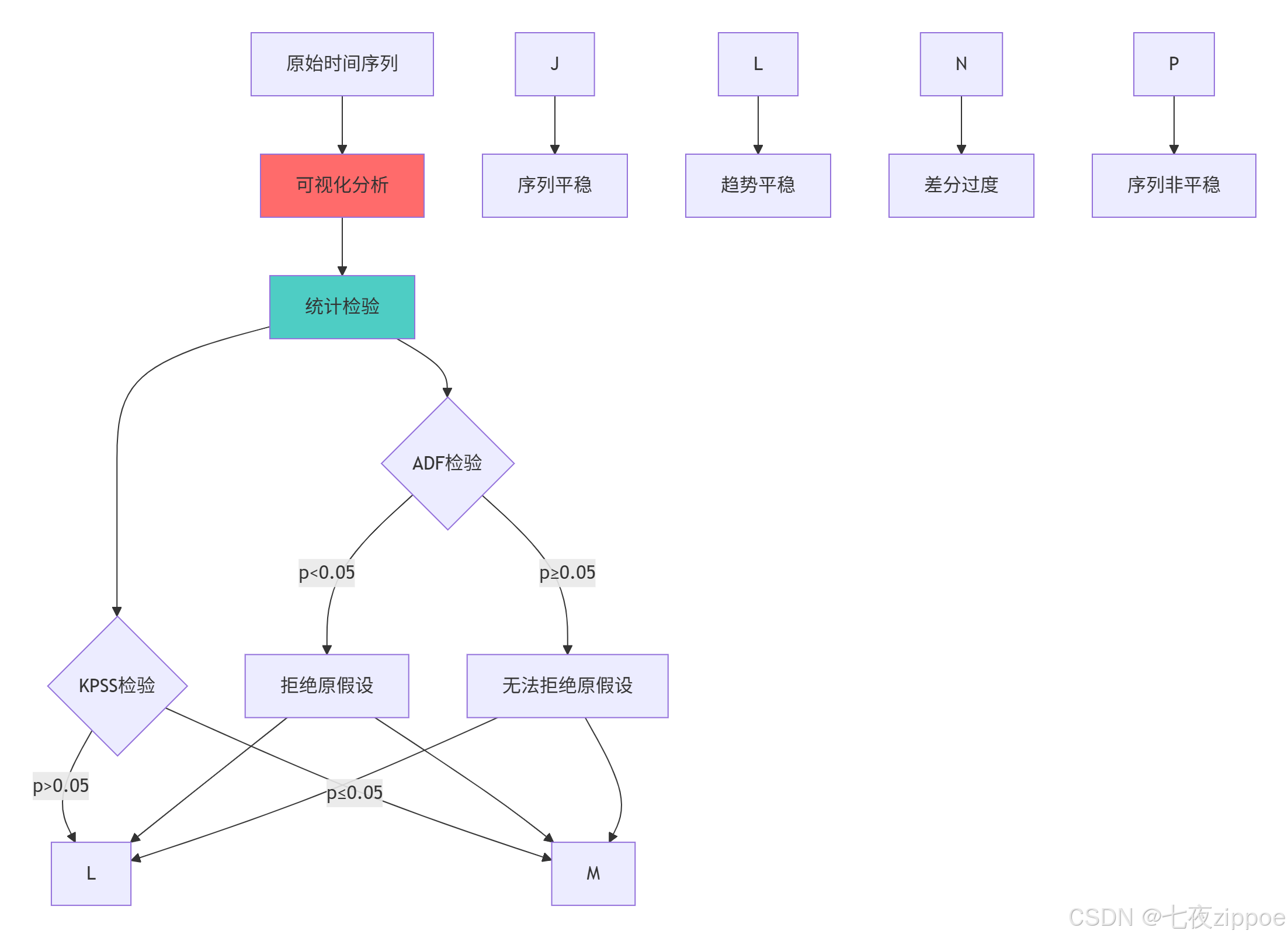
平稳性检验的关键洞察:
-
ADF检验 对单位根敏感,KPSS检验对趋势平稳敏感,两者结合使用更可靠
-
可视化分析可提供直观判断,但需要统计检验验证
-
差分阶数不是越多越好,过度差分会导致信息损失
-
业务理解比统计检验更重要,需要结合数据背景进行判断
2.2 ARIMA模型原理与实现
2.2.1 ARIMA模型数学原理
ARIMA模型(AutoRegressive Integrated Moving Average)是时间序列预测的经典方法,包含三个核心参数:p(自回归阶数)、d(差分阶数)、q(移动平均阶数)。
python
# arima_model.py
import numpy as np
import pandas as pd
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.tsa.statespace.sarimax import SARIMAX
from sklearn.metrics import mean_squared_error, mean_absolute_error
import matplotlib.pyplot as plt
class ARIMAAnalyzer:
"""ARIMA模型分析专家"""
def __init__(self, data):
self.data = data
self.model = None
self.results = None
def parameter_selection(self, max_p=3, max_d=2, max_q=3):
"""ARIMA参数选择"""
best_aic = np.inf
best_order = None
best_model = None
results = []
for p in range(max_p + 1):
for d in range(max_d + 1):
for q in range(max_q + 1):
try:
model = ARIMA(self.data, order=(p, d, q))
model_fit = model.fit()
aic = model_fit.aic
results.append({
'order': (p, d, q),
'aic': aic,
'bic': model_fit.bic
})
if aic < best_aic:
best_aic = aic
best_order = (p, d, q)
best_model = model_fit
except Exception as e:
continue
# 按AIC排序
results_df = pd.DataFrame(results)
results_df = results_df.sort_values('aic').reset_index(drop=True)
print("Top 5 ARIMA参数组合 (按AIC排序):")
print(results_df.head())
self.model = best_model
return best_order, best_model, results_df
def automated_arima(self):
"""自动ARIMA参数选择"""
try:
from pmdarima import auto_arima
model = auto_arima(
self.data,
start_p=0, start_q=0, start_d=0,
max_p=5, max_q=5, max_d=2,
seasonal=False,
stepwise=True,
suppress_warnings=True,
error_action='ignore',
trace=True
)
print(f"自动ARIMA选择参数: {model.order}")
return model.order, model
except ImportError:
print("pmdarima未安装,使用网格搜索")
return self.parameter_selection()
def fit_model(self, order):
"""拟合ARIMA模型"""
self.model = ARIMA(self.data, order=order)
self.results = self.model.fit()
print("ARIMA模型摘要:")
print(self.results.summary())
return self.results
def diagnostic_plots(self):
"""模型诊断图"""
if self.results is None:
raise ValueError("请先拟合模型")
# 残差分析
residuals = pd.DataFrame(self.results.resid)
fig, axes = plt.subplots(2, 2, figsize=(15, 10))
# 残差序列图
axes[0, 0].plot(residuals)
axes[0, 0].set_title('残差序列')
axes[0, 0].axhline(y=0, color='red', linestyle='--')
axes[0, 0].grid(True)
# 残差直方图
axes[0, 1].hist(residuals, bins=20, alpha=0.7)
axes[0, 1].set_title('残差分布')
axes[0, 1].grid(True)
# ACF图
from statsmodels.graphics.tsaplots import plot_acf
plot_acf(residuals, lags=40, ax=axes[1, 0])
axes[1, 0].set_title('残差ACF')
# Q-Q图
from scipy import stats
stats.probplot(residuals.iloc[:, 0], dist="norm", plot=axes[1, 1])
axes[1, 1].set_title('Q-Q图')
plt.tight_layout()
plt.show()
# 残差检验
lb_test = self.results.test_serial_correlation(method='ljungbox')
print("Ljung-Box残差自相关检验:")
print(lb_test)
def forecast(self, steps=10, plot=True):
"""预测"""
if self.results is None:
raise ValueError("请先拟合模型")
# 预测
forecast_result = self.results.get_forecast(steps=steps)
forecast_mean = forecast_result.predicted_mean
confidence_int = forecast_result.conf_int()
if plot:
plt.figure(figsize=(12, 6))
plt.plot(self.data, label='历史数据')
plt.plot(forecast_mean, label='预测', color='red')
plt.fill_between(
confidence_int.index,
confidence_int.iloc[:, 0],
confidence_int.iloc[:, 1],
color='red', alpha=0.2, label='95%置信区间'
)
plt.title('ARIMA模型预测')
plt.legend()
plt.grid(True)
plt.show()
return forecast_mean, confidence_int
def model_evaluation(self, train_ratio=0.8):
"""模型评估"""
# 分割数据
train_size = int(len(self.data) * train_ratio)
train, test = self.data[:train_size], self.data[train_size:]
# 训练模型
model = ARIMA(train, order=self.results.model.order)
model_fit = model.fit()
# 预测
forecast = model_fit.forecast(steps=len(test))
# 计算指标
mse = mean_squared_error(test, forecast)
mae = mean_absolute_error(test, forecast)
rmse = np.sqrt(mse)
mape = np.mean(np.abs((test - forecast) / test)) * 100
metrics = {
'MSE': mse,
'MAE': mae,
'RMSE': rmse,
'MAPE': mape
}
print("模型评估指标:")
for metric, value in metrics.items():
print(f"{metric}: {value:.4f}")
# 绘制预测对比
plt.figure(figsize=(12, 6))
plt.plot(train.index, train, label='训练集')
plt.plot(test.index, test, label='测试集')
plt.plot(test.index, forecast, label='预测')
plt.title('ARIMA模型预测效果')
plt.legend()
plt.grid(True)
plt.show()
return metrics
# 季节性ARIMA模型
class SeasonalARIMA:
"""季节性ARIMA模型"""
def __init__(self, data):
self.data = data
self.model = None
def fit_sarima(self, order=(1,1,1), seasonal_order=(1,1,1,12)):
"""拟合季节性ARIMA模型"""
self.model = SARIMAX(
self.data,
order=order,
seasonal_order=seasonal_order,
enforce_stationarity=False,
enforce_invertibility=False
)
self.results = self.model.fit(disp=False)
print("SARIMA模型摘要:")
print(self.results.summary())
return self.results
def seasonal_decomposition(self):
"""季节性分解"""
from statsmodels.tsa.seasonal import seasonal_decompose
result = seasonal_decompose(self.data, model='additive', period=12)
fig, axes = plt.subplots(4, 1, figsize=(12, 10))
result.observed.plot(ax=axes[0], title='原始序列')
result.trend.plot(ax=axes[1], title='趋势成分')
result.seasonal.plot(ax=axes[2], title='季节成分')
result.resid.plot(ax=axes[3], title='残差')
plt.tight_layout()
plt.show()
return result2.2.2 ARIMA参数选择流程图

ARIMA建模的关键要点:
-
参数选择需要平衡理论指导与数据驱动方法
-
模型诊断比参数估计更重要,残差必须满足白噪声假设
-
季节性处理需要考虑业务周期特性
-
过拟合风险需要通过信息准则(AIC/BIC)来控制
2.3 Prophet时间序列预测框架
2.3.1 Prophet核心原理与实现
Prophet是Facebook开源的时间序列预测库,擅长处理具有强季节性和假日效应的数据。
python
# prophet_model.py
import pandas as pd
import numpy as np
from prophet import Prophet
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error, mean_absolute_error
class ProphetAnalyzer:
"""Prophet时间序列分析专家"""
def __init__(self, data=None):
self.data = data
self.model = None
self.forecast = None
def prepare_data(self, df, date_col, value_col):
"""准备Prophet格式数据"""
prophet_df = df.reset_index()[[date_col, value_col]]
prophet_df.columns = ['ds', 'y']
prophet_df['ds'] = pd.to_datetime(prophet_df['ds'])
prophet_df = prophet_df.dropna()
self.data = prophet_df
return prophet_df
def fit_model(self,
growth='linear',
yearly_seasonality=True,
weekly_seasonality=True,
daily_seasonality=False,
holidays=None,
changepoint_prior_scale=0.05):
"""拟合Prophet模型"""
self.model = Prophet(
growth=growth,
yearly_seasonality=yearly_seasonality,
weekly_seasonality=weekly_seasonality,
daily_seasonality=daily_seasonality,
holidays=holidays,
changepoint_prior_scale=changepoint_prior_scale
)
# 添加中国节假日
self.model.add_country_holidays(country_name='CN')
self.model.fit(self.data)
return self.model
def make_future_dataframe(self, periods, freq='D', include_history=True):
"""创建未来日期数据框"""
future = self.model.make_future_dataframe(
periods=periods,
freq=freq,
include_history=include_history
)
return future
def predict(self, future=None, periods=365):
"""进行预测"""
if future is None:
future = self.make_future_dataframe(periods=periods)
self.forecast = self.model.predict(future)
return self.forecast
def plot_components(self):
"""绘制成分分解图"""
if self.model is None or self.forecast is None:
raise ValueError("请先进行模型拟合和预测")
fig = self.model.plot_components(self.forecast)
plt.show()
def cross_validation(self, initial='365 days', period='180 days',
horizon='90 days', parallel="processes"):
"""交叉验证"""
from prophet.diagnostics import cross_validation, performance_metrics
df_cv = cross_validation(
self.model,
initial=initial,
period=period,
horizon=horizon,
parallel=parallel
)
df_p = performance_metrics(df_cv)
return df_cv, df_p
def plot_cross_validation(self, df_cv):
"""绘制交叉验证结果"""
from prophet.plot import plot_cross_validation_metric
fig = plot_cross_validation_metric(df_cv, metric='mape')
plt.show()
def anomaly_detection(self, threshold=0.95):
"""异常检测基于预测区间"""
if self.forecast is None:
raise ValueError("请先进行预测")
# 合并实际值和预测值
comparison = self.data.merge(
self.forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']],
on='ds'
)
# 检测异常点
comparison['anomaly'] = (
(comparison['y'] < comparison['yhat_lower']) |
(comparison['y'] > comparison['yhat_upper'])
)
anomalies = comparison[comparison['anomaly'] == True]
print(f"检测到异常点数量: {len(anomalies)}")
# 绘制异常检测图
plt.figure(figsize=(12, 6))
plt.plot(comparison['ds'], comparison['y'], label='实际值')
plt.plot(comparison['ds'], comparison['yhat'], label='预测值')
plt.fill_between(
comparison['ds'],
comparison['yhat_lower'],
comparison['yhat_upper'],
alpha=0.3,
label='预测区间'
)
plt.scatter(
anomalies['ds'], anomalies['y'],
color='red', label='异常点'
)
plt.legend()
plt.title('Prophet异常检测')
plt.show()
return anomalies
# Prophet高级功能
class AdvancedProphet:
"""Prophet高级功能"""
def __init__(self):
self.models = {}
def multiplicative_seasonality(self, data):
"""乘法季节性模型"""
model = Prophet(seasonality_mode='multiplicative')
model.fit(data)
return model
def logistic_growth(self, data, cap_series, floor_series=None):
"""逻辑增长模型"""
data['cap'] = cap_series
if floor_series is not None:
data['floor'] = floor_series
model = Prophet(growth='logistic')
model.fit(data)
return model
def add_regressors(self, data, regressor_cols):
"""添加额外回归变量"""
model = Prophet()
for col in regressor_cols:
model.add_regressor(col)
model.fit(data)
return model
def change_point_analysis(self, model, forecast):
"""变点分析"""
from prophet.utilities import regressor_coefficients
# 变点图表
fig = model.plot(forecast)
for cp in model.changepoints:
plt.axvline(x=cp, color='red', linestyle='--', alpha=0.3)
plt.show()
# 变点强度
changepoint_strengths = regressor_coefficients(model)
return changepoint_strengths
# 实战示例
def prophet_demo():
"""Prophet实战演示"""
# 创建示例数据
dates = pd.date_range('2010-01-01', '2020-12-31', freq='D')
trend = 0.001 * np.arange(len(dates))
seasonal = 10 * np.sin(2 * np.pi * np.arange(len(dates)) / 365)
noise = np.random.normal(0, 1, len(dates))
y = trend + seasonal + noise
data = pd.DataFrame({'ds': dates, 'y': y})
# 创建分析器
analyzer = ProphetAnalyzer()
analyzer.data = data
# 拟合模型
model = analyzer.fit_model()
# 预测
future = analyzer.make_future_dataframe(periods=365)
forecast = analyzer.predict(future)
# 绘制结果
fig1 = model.plot(forecast)
plt.title('Prophet预测结果')
plt.show()
# 成分分解
analyzer.plot_components()
# 交叉验证
df_cv, df_p = analyzer.cross_validation()
print("交叉验证性能指标:")
print(df_p.head())
# 异常检测
anomalies = analyzer.anomaly_detection()
return model, forecast, anomalies2.3.2 Prophet架构图
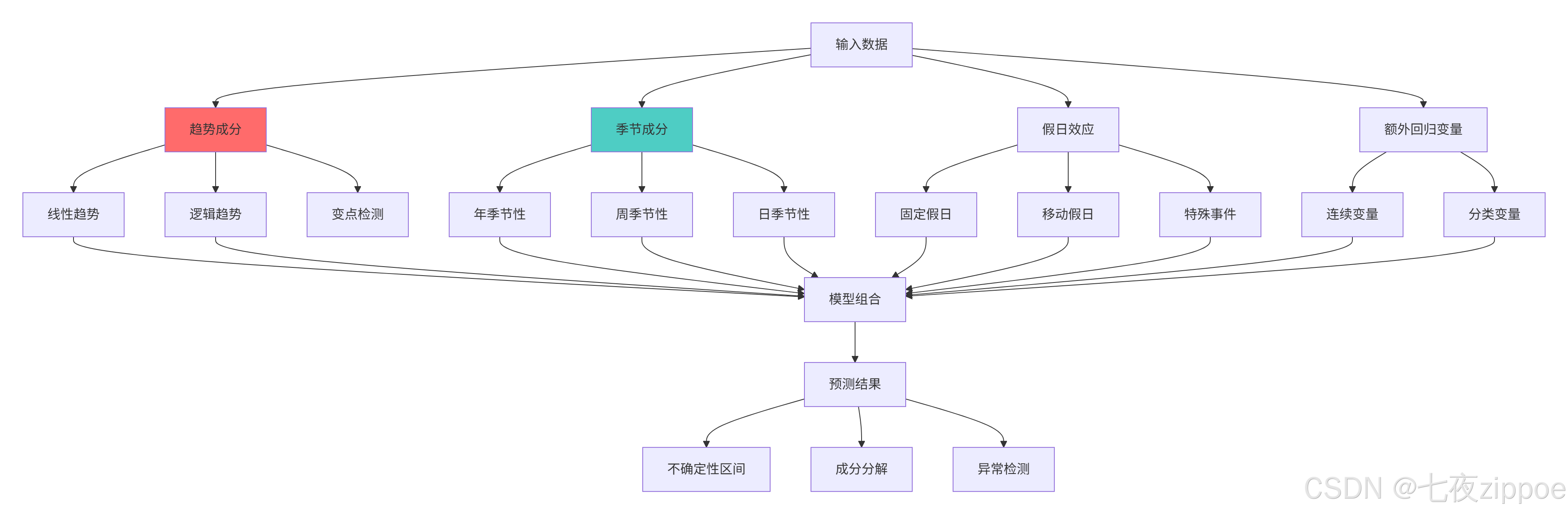
Prophet的核心优势:
-
易用性强:自动处理缺失值、异常值
-
可解释性:提供趋势、季节性的明确分解
-
灵活性:支持自定义季节性和假日效应
-
鲁棒性:对缺失数据和趋势变化不敏感
3 实战部分:完整时间序列分析流程
3.1 端到端时间序列分析项目
python
# end_to_end_analysis.py
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from datetime import datetime
import warnings
warnings.filterwarnings('ignore')
class CompleteTimeSeriesAnalysis:
"""完整的时间序列分析流程"""
def __init__(self, data_path=None):
self.data_path = data_path
self.data = None
self.results = {}
def load_and_explore_data(self):
"""数据加载与探索"""
if self.data_path:
# 从文件加载
self.data = pd.read_csv(self.data_path)
else:
# 生成示例数据
self.generate_sample_data()
print("数据基本信息:")
print(f"数据形状: {self.data.shape}")
print(f"时间范围: {self.data['ds'].min()} 到 {self.data['ds'].max()}")
print("\n前5行数据:")
print(self.data.head())
# 基本统计
print("\n描述性统计:")
print(self.data['y'].describe())
return self.data
def generate_sample_data(self):
"""生成示例时间序列数据"""
dates = pd.date_range('2015-01-01', '2020-12-31', freq='D')
# 趋势成分
trend = 0.005 * np.arange(len(dates))
# 季节成分
yearly_seasonal = 10 * np.sin(2 * np.pi * np.arange(len(dates)) / 365.25)
weekly_seasonal = 2 * np.sin(2 * np.pi * np.arange(len(dates)) / 7)
# 假日效应
holidays_effect = np.zeros(len(dates))
for i, date in enumerate(dates):
if date.month == 12 and date.day in [24, 25, 26]: # 圣诞节
holidays_effect[i] = 5
elif date.month == 1 and date.day == 1: # 元旦
holidays_effect[i] = 3
# 噪声
noise = np.random.normal(0, 1, len(dates))
# 组合
y = trend + yearly_seasonal + weekly_seasonal + holidays_effect + noise
self.data = pd.DataFrame({'ds': dates, 'y': y})
return self.data
def comprehensive_eda(self):
"""全面的探索性数据分析"""
fig, axes = plt.subplots(2, 3, figsize=(18, 10))
# 1. 时间序列图
axes[0, 0].plot(self.data['ds'], self.data['y'])
axes[0, 0].set_title('时间序列图')
axes[0, 0].tick_params(axis='x', rotation=45)
# 2. 分布直方图
axes[0, 1].hist(self.data['y'], bins=50, alpha=0.7)
axes[0, 1].set_title('数值分布')
axes[0, 1].set_xlabel('值')
axes[0, 1].set_ylabel('频数')
# 3. 年度模式
self.data['year'] = self.data['ds'].dt.year
self.data['month'] = self.data['ds'].dt.month
yearly_avg = self.data.groupby('year')['y'].mean()
axes[0, 2].plot(yearly_avg.index, yearly_avg.values, marker='o')
axes[0, 2].set_title('年度平均趋势')
axes[0, 2].set_xlabel('年份')
axes[0, 2].set_ylabel('平均值')
# 4. 月度模式
monthly_avg = self.data.groupby('month')['y'].mean()
axes[1, 0].bar(monthly_avg.index, monthly_avg.values)
axes[1, 0].set_title('月度模式')
axes[1, 0].set_xlabel('月份')
axes[1, 0].set_ylabel('平均值')
# 5. 自相关图
from pandas.plotting import autocorrelation_plot
autocorrelation_plot(self.data['y'], ax=axes[1, 1])
axes[1, 1].set_title('自相关图')
# 6. 滚动统计
rolling_mean = self.data['y'].rolling(window=30).mean()
rolling_std = self.data['y'].rolling(window=30).std()
axes[1, 2].plot(self.data['ds'], self.data['y'], label='原始')
axes[1, 2].plot(self.data['ds'], rolling_mean, label='30天滚动均值')
axes[1, 2].plot(self.data['ds'], rolling_std, label='30天滚动标准差')
axes[1, 2].set_title('滚动统计量')
axes[1, 2].legend()
axes[1, 2].tick_params(axis='x', rotation=45)
plt.tight_layout()
plt.show()
return fig
def stationarity_analysis(self):
"""平稳性分析"""
from statsmodels.tsa.stattools import adfuller, kpss
print("=== 平稳性分析 ===")
# ADF检验
adf_result = adfuller(self.data['y'].dropna())
print(f"ADF统计量: {adf_result[0]:.4f}")
print(f"ADF p值: {adf_result[1]:.4f}")
# KPSS检验
kpss_result = kpss(self.data['y'].dropna())
print(f"KPSS统计量: {kpss_result[0]:.4f}")
print(f"KPSS p值: {kpss_result[1]:.4f}")
# 差分处理
self.data['y_diff1'] = self.data['y'].diff()
self.data['y_diff2'] = self.data['y'].diff().diff()
# 差分后检验
adf_diff1 = adfuller(self.data['y_diff1'].dropna())
print(f"一阶差分后ADF p值: {adf_diff1[1]:.4f}")
return {
'adf': adf_result,
'kpss': kpss_result,
'adf_diff1': adf_diff1
}
def model_comparison(self, test_size=0.2):
"""多模型比较"""
from sklearn.metrics import mean_squared_error, mean_absolute_error
import warnings
warnings.filterwarnings('ignore')
# 分割数据
split_idx = int(len(self.data) * (1 - test_size))
train = self.data.iloc[:split_idx].copy()
test = self.data.iloc[split_idx:].copy()
models_performance = {}
# 1. 简单基准模型(历史平均)
historical_mean = train['y'].mean()
test['pred_historical'] = historical_mean
models_performance['Historical Mean'] = {
'RMSE': np.sqrt(mean_squared_error(test['y'], test['pred_historical'])),
'MAE': mean_absolute_error(test['y'], test['pred_historical'])
}
# 2. ARIMA模型
try:
from statsmodels.tsa.arima.model import ARIMA
arima_model = ARIMA(train['y'], order=(1,1,1))
arima_fit = arima_model.fit()
test['pred_arima'] = arima_fit.forecast(steps=len(test))
models_performance['ARIMA'] = {
'RMSE': np.sqrt(mean_squared_error(test['y'], test['pred_arima'])),
'MAE': mean_absolute_error(test['y'], test['pred_arima'])
}
except Exception as e:
print(f"ARIMA模型失败: {e}")
# 3. Prophet模型
try:
from prophet import Prophet
prophet_train = train[['ds', 'y']].copy()
prophet_model = Prophet()
prophet_model.fit(prophet_train)
future = prophet_model.make_future_dataframe(periods=len(test))
forecast = prophet_model.predict(future)
test_prophet = test.merge(forecast[['ds', 'yhat']], on='ds')
test['pred_prophet'] = test_prophet['yhat']
models_performance['Prophet'] = {
'RMSE': np.sqrt(mean_squared_error(test['y'], test['pred_prophet'])),
'MAE': mean_absolute_error(test['y'], test['pred_prophet'])
}
except Exception as e:
print(f"Prophet模型失败: {e}")
# 性能比较
performance_df = pd.DataFrame(models_performance).T
performance_df = performance_df.sort_values('RMSE')
print("模型性能比较:")
print(performance_df)
# 可视化比较
plt.figure(figsize=(12, 8))
plt.plot(test['ds'], test['y'], label='实际值', linewidth=2)
if 'pred_arima' in test.columns:
plt.plot(test['ds'], test['pred_arima'], label='ARIMA预测')
if 'pred_prophet' in test.columns:
plt.plot(test['ds'], test['pred_prophet'], label='Prophet预测')
plt.plot(test['ds'], test['pred_historical'], label='历史平均', linestyle='--')
plt.legend()
plt.title('模型预测效果比较')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
self.results['model_comparison'] = performance_df
return performance_df
def anomaly_detection_suite(self):
"""综合异常检测套件"""
anomalies = {}
# 1. 统计方法(Z-score)
from scipy import stats
z_scores = np.abs(stats.zscore(self.data['y'].dropna()))
anomalies['z_score'] = self.data.iloc[np.where(z_scores > 3)[0]]
# 2. IQR方法
Q1 = self.data['y'].quantile(0.25)
Q3 = self.data['y'].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
anomalies['iqr'] = self.data[
(self.data['y'] < lower_bound) | (self.data['y'] > upper_bound)
]
# 3. 基于预测的方法(使用Prophet)
try:
from prophet import Prophet
model = Prophet()
model.fit(self.data[['ds', 'y']])
future = model.make_future_dataframe(periods=0)
forecast = model.predict(future)
comparison = self.data.merge(
forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']],
on='ds'
)
anomalies['prophet'] = comparison[
(comparison['y'] < comparison['yhat_lower']) |
(comparison['y'] > comparison['yhat_upper'])
]
except Exception as e:
print(f"Prophet异常检测失败: {e}")
# 汇总结果
print("异常检测结果汇总:")
for method, result in anomalies.items():
print(f"{method}: 检测到{len(result)}个异常点")
# 可视化异常检测结果
plt.figure(figsize=(12, 6))
plt.plot(self.data['ds'], self.data['y'], label='时间序列')
colors = ['red', 'blue', 'green']
for i, (method, result) in enumerate(anomalies.items()):
if len(result) > 0:
plt.scatter(result['ds'], result['y'],
color=colors[i], label=f'{method}异常点', alpha=0.7)
plt.legend()
plt.title('异常检测结果')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
self.results['anomalies'] = anomalies
return anomalies
# 完整工作流示例
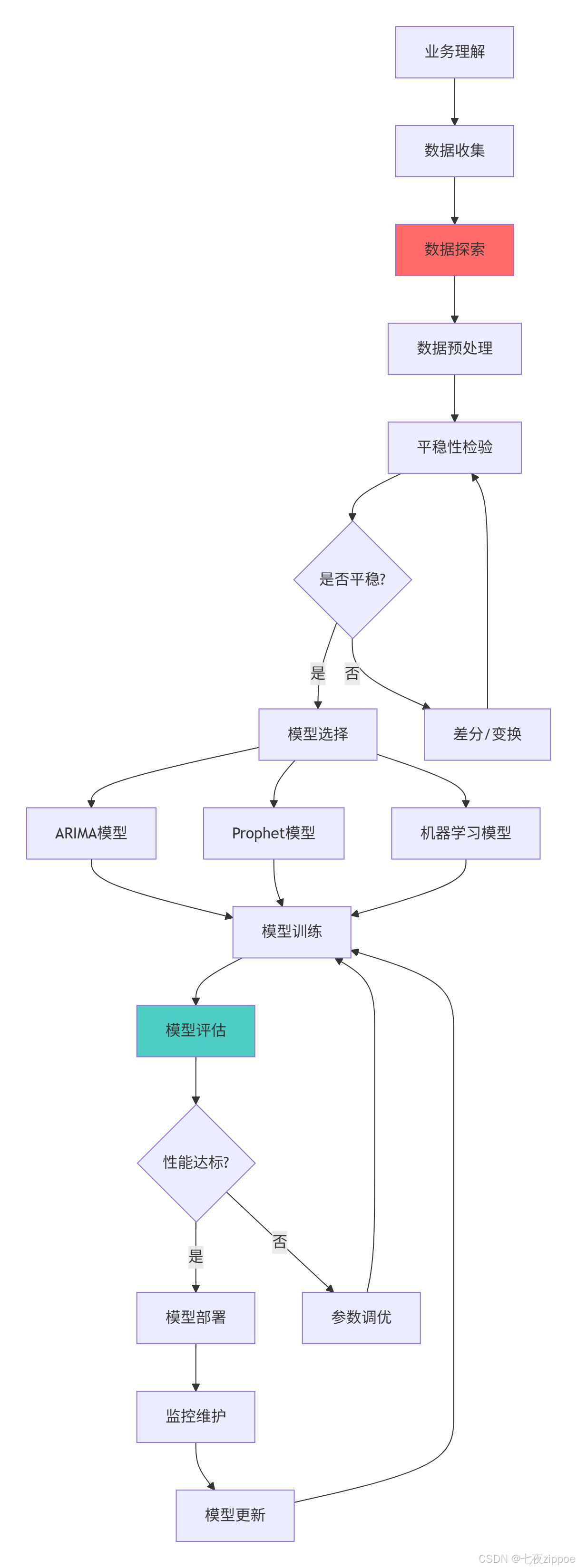
def complete_workflow_demo():
"""完整工作流演示"""
analyzer = CompleteTimeSeriesAnalysis()
# 1. 数据加载与探索
data = analyzer.load_and_explore_data()
# 2. 探索性分析
analyzer.comprehensive_eda()
# 3. 平稳性分析
stationarity_results = analyzer.stationarity_analysis()
# 4. 模型比较
performance = analyzer.model_comparison()
# 5. 异常检测
anomalies = analyzer.anomaly_detection_suite()
return analyzer.results3.2 时间序列分析工作流图
4 高级应用与企业级实战
4.1 大规模时间序列预测系统
python
# large_scale_forecasting.py
import pandas as pd
import numpy as np
from datetime import datetime, timedelta
from concurrent.futures import ProcessPoolExecutor
import warnings
warnings.filterwarnings('ignore')
class LargeScaleForecaster:
"""大规模时间序列预测系统"""
def __init__(self, n_jobs=-1):
self.n_jobs = n_jobs
self.models = {}
def generate_hierarchical_data(self, n_series=100, length=1000):
"""生成层次结构时间序列数据"""
np.random.seed(42)
all_series = {}
base_dates = pd.date_range('2010-01-01', periods=length, freq='D')
for i in range(n_series):
# 基础趋势和季节性
trend = 0.01 * np.arange(length) * (1 + i / n_series)
seasonal = 5 * np.sin(2 * np.pi * np.arange(length) / 365.25 + i)
noise = np.random.normal(0, 1, length)
# 系列间相关性
if i > 0:
correlation_effect = 0.3 * all_series[f'series_{i-1}']['y']
else:
correlation_effect = 0
y = trend + seasonal + correlation_effect + noise
all_series[f'series_{i}'] = pd.DataFrame({
'ds': base_dates,
'y': y,
'series_id': f'series_{i}',
'category': f'category_{i % 5}' # 5个类别
})
self.hierarchical_data = pd.concat(all_series.values(), ignore_index=True)
return self.hierarchical_data
def parallel_forecasting(self, forecast_horizon=30):
"""并行预测多个时间序列"""
if not hasattr(self, 'hierarchical_data'):
self.generate_hierarchical_data()
series_ids = self.hierarchical_data['series_id'].unique()
def forecast_single_series(series_id):
"""单个序列预测"""
try:
series_data = self.hierarchical_data[
self.hierarchical_data['series_id'] == series_id
]
# 使用Prophet进行预测
from prophet import Prophet
model = Prophet(
yearly_seasonality=True,
weekly_seasonality=True,
daily_seasonality=False
)
model.fit(series_data[['ds', 'y']])
future = model.make_future_dataframe(periods=forecast_horizon)
forecast = model.predict(future)
return {
'series_id': series_id,
'model': model,
'forecast': forecast,
'last_date': series_data['ds'].max(),
'success': True
}
except Exception as e:
return {
'series_id': series_id,
'error': str(e),
'success': False
}
# 并行处理
with ProcessPoolExecutor(max_workers=self.n_jobs) as executor:
results = list(executor.map(forecast_single_series, series_ids))
# 结果处理
successful_results = [r for r in results if r['success']]
failed_results = [r for r in results if not r['success']]
print(f"成功预测: {len(successful_results)}个序列")
print(f"失败: {len(failed_results)}个序列")
self.forecast_results = successful_results
return successful_results, failed_results
def hierarchical_reconciliation(self):
"""层次一致性调整"""
# 实现层次时间序列的一致性调整
# 确保子序列的预测值与父序列一致
category_forecasts = {}
for result in self.forecast_results:
series_id = result['series_id']
category = series_id.split('_')[1] # 简化处理
if category not in category_forecasts:
category_forecasts[category] = []
category_forecasts[category].append(result['forecast']['yhat'].sum())
# 计算调整因子
base_category = list(category_forecasts.keys())[0]
base_forecast = np.mean(category_forecasts[base_category])
adjustment_factors = {}
for category, forecasts in category_forecasts.items():
category_forecast = np.mean(forecasts)
adjustment_factors[category] = base_forecast / category_forecast
# 应用调整
for result in self.forecast_results:
category = result['series_id'].split('_')[1]
adjustment = adjustment_factors.get(category, 1.0)
result['forecast']['yhat'] *= adjustment
result['forecast']['yhat_lower'] *= adjustment
result['forecast']['yhat_upper'] *= adjustment
return adjustment_factors
def forecast_accuracy_analysis(self, actuals_df):
"""预测准确性分析"""
accuracy_metrics = {}
for result in self.forecast_results:
series_id = result['series_id']
# 获取实际值
actuals = actuals_df[
actuals_df['series_id'] == series_id
].sort_values('ds')
# 合并预测和实际值
comparison = result['forecast'].merge(
actuals[['ds', 'y']],
on='ds',
how='inner'
)
if len(comparison) > 0:
# 计算指标
mape = np.mean(
np.abs(comparison['y'] - comparison['yhat']) /
np.abs(comparison['y'])
) * 100
rmse = np.sqrt(
np.mean((comparison['y'] - comparison['yhat'])**2)
)
accuracy_metrics[series_id] = {
'MAPE': mape,
'RMSE': rmse,
'n_points': len(comparison)
}
# 总体统计
overall_mape = np.mean([m['MAPE'] for m in accuracy_metrics.values()])
overall_rmse = np.sqrt(
np.mean([m['RMSE']**2 for m in accuracy_metrics.values()])
)
print(f"总体MAPE: {overall_mape:.2f}%")
print(f"总体RMSE: {overall_rmse:.2f}")
return accuracy_metrics, overall_mape, overall_rmse
def real_time_monitoring_dashboard(self):
"""实时监控仪表板"""
import matplotlib.pyplot as plt
fig, axes = plt.subplots(2, 2, figsize=(15, 10))
# 1. 预测准确性分布
accuracy_metrics = self.forecast_accuracy_analysis(
self.hierarchical_data
)[0]
mapes = [m['MAPE'] for m in accuracy_metrics.values()]
axes[0, 0].hist(mapes, bins=20, alpha=0.7)
axes[0, 0].set_title('MAPE分布')
axes[0, 0].set_xlabel('MAPE (%)')
axes[0, 0].set_ylabel('频数')
# 2. 预测时间序列示例
example_series = self.forecast_results[0]
axes[0, 1].plot(
example_series['forecast']['ds'],
example_series['forecast']['yhat'],
label='预测'
)
axes[0, 1].fill_between(
example_series['forecast']['ds'],
example_series['forecast']['yhat_lower'],
example_series['forecast']['yhat_upper'],
alpha=0.3,
label='置信区间'
)
axes[0, 1].set_title(f"示例预测: {example_series['series_id']}")
axes[0, 1].legend()
# 3. 预测误差时间模式
actuals = self.hierarchical_data[
self.hierarchical_data['series_id'] == example_series['series_id']
]
comparison = example_series['forecast'].merge(
actuals[['ds', 'y']],
on='ds',
how='inner'
)
if len(comparison) > 0:
comparison['error'] = comparison['y'] - comparison['yhat']
axes[1, 0].plot(comparison['ds'], comparison['error'])
axes[1, 0].axhline(y=0, color='red', linestyle='--')
axes[1, 0].set_title('预测误差时间序列')
axes[1, 0].set_xlabel('日期')
axes[1, 0].set_ylabel('误差')
# 4. 序列间相关性热力图
# 选择部分序列计算相关性
selected_series = list(accuracy_metrics.keys())[:10]
correlation_matrix = np.zeros((len(selected_series), len(selected_series)))
for i, series1 in enumerate(selected_series):
for j, series2 in enumerate(selected_series):
data1 = self.hierarchical_data[
self.hierarchical_data['series_id'] == series1
]['y'].values
data2 = self.hierarchical_data[
self.hierarchical_data['series_id'] == series2
]['y'].values
min_len = min(len(data1), len(data2))
if min_len > 0:
corr = np.corrcoef(data1[:min_len], data2[:min_len])[0, 1]
correlation_matrix[i, j] = corr
im = axes[1, 1].imshow(correlation_matrix, cmap='coolwarm',
vmin=-1, vmax=1)
axes[1, 1].set_title('序列间相关性热力图')
plt.colorbar(im, ax=axes[1, 1])
plt.tight_layout()
plt.show()
return fig
# 性能优化技巧
class PerformanceOptimizer:
"""时间序列分析性能优化"""
def __init__(self):
self.optimization_tips = []
def memory_optimization(self, data):
"""内存优化技巧"""
# 1. 优化数据类型
if 'ds' in data.columns:
data['ds'] = pd.to_datetime(data['ds'])
if 'y' in data.columns:
data['y'] = pd.to_numeric(data['y'], downcast='float')
# 2. 使用分类数据类型
categorical_cols = ['series_id', 'category'] if 'series_id' in data.columns else []
for col in categorical_cols:
if col in data.columns:
data[col] = data[col].astype('category')
self.optimization_tips.append("内存优化完成")
return data
def computational_optimization(self, model, data):
"""计算优化技巧"""
import time
from functools import wraps
def timer_decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
start_time = time.time()
result = func(*args, **kwargs)
end_time = time.time()
print(f"{func.__name__} 执行时间: {end_time - start_time:.2f}秒")
return result
return wrapper
# 应用计时装饰器
model.fit = timer_decorator(model.fit)
return model
def caching_strategy(self, func):
"""缓存策略"""
cache = {}
def wrapper(*args):
if args in cache:
return cache[args]
result = func(*args)
cache[args] = result
return result
return wrapper
# 故障排查指南
class TroubleshootingGuide:
"""时间序列分析故障排查指南"""
def __init__(self):
self.common_issues = {
'收敛问题': [
'检查数据平稳性',
'调整模型参数',
'增加数据量'
],
'预测偏差': [
'检查数据完整性',
'验证模型假设',
'添加外部变量'
],
'计算内存不足': [
'优化数据格式',
'使用增量学习',
'分布式计算'
],
'季节性检测失败': [
'检查数据频率',
'手动指定季节周期',
'增加季节性参数'
]
}
def diagnose_issues(self, error_message, data=None):
"""问题诊断"""
issues_found = []
for issue, solutions in self.common_issues.items():
if any(keyword in str(error_message) for keyword in issue.lower().split()):
issues_found.append((issue, solutions))
if data is not None:
# 数据相关检查
if data.isnull().sum().sum() > 0:
issues_found.append((
'数据缺失',
['填充缺失值', '插值处理', '删除缺失值']
))
if len(data) < 100:
issues_found.append((
'数据量不足',
['收集更多数据', '使用更简单模型', '调整验证方式']
))
return issues_found
def generate_solutions(self, issues):
"""生成解决方案"""
solutions = []
for issue, possible_solutions in issues:
solutions.append(f"问题: {issue}")
solutions.append("可能的解决方案:")
for i, solution in enumerate(possible_solutions, 1):
solutions.append(f" {i}. {solution}")
solutions.append("")
return "\n".join(solutions)5 总结与展望
5.1 核心知识点总结
通过本文的完整学习路径,我们系统掌握了时间序列分析的核心技术栈:
-
平稳性检验:时间序列分析的基础,确保统计特性稳定
-
ARIMA模型:经典的时间序列预测方法,适用于线性模式
-
Prophet框架:强大的自动化预测工具,擅长处理季节性和假日效应
-
异常检测:多种方法结合,提高系统鲁棒性
-
大规模处理:并行计算和层次一致性确保工业级应用
5.2 技术发展趋势
5.3 学习建议与资源
基于13年的实战经验,我建议的时间序列分析学习路径:
-
基础阶段:掌握平稳性检验和ARIMA模型原理
-
进阶阶段:学习Prophet框架和季节性分析
-
高级阶段:深入机器学习和深度学习时间序列模型
-
专家阶段:掌握大规模系统设计和实时预测技术
官方文档与参考资源
-
Prophet官方文档- 完整的Prophet框架文档
-
Statsmodels时间序列分析- 统计模型时间序列模块
-
PMDARIMA文档- 自动ARIMA模型库
-
时间序列分析经典教材- 预测理论与实践
通过本文的完整学习,您应该已经掌握了时间序列分析从基础理论到企业级实战的全套技术栈。时间序列分析是数据科学中极具商业价值的方向,希望本文能帮助您在实际项目中构建准确可靠的预测系统。