一、问题现象
开启 Kerberos 后,Hue 使用 Spark SQL(Spark Thrift Server)访问出现:
Thrift exception; retrying: Bad status: 3 (b'GSS initiate failed')- 页面侧表现为 Spark SQL 连接失败/执行失败
bash
[root@dev1 hue]# tail -f runcpserver.log
[23/Jan/2026 14:42:52 +0800] api WARNING Oozie application is not enabled: Model class oozie.models.Job doesn't declare an explicit app_label and isn't in an application in INSTALLED_APPS.
[23/Jan/2026 14:42:52 +0800] settings INFO Welcome to Hue 4.11.0
[23/Jan/2026 14:42:54 +0800] apps INFO AXES: BEGIN LOG
[23/Jan/2026 14:42:54 +0800] apps INFO AXES: Using django-axes version 5.13.0
[23/Jan/2026 14:42:54 +0800] apps INFO AXES: blocking by IP only.
[23/Jan/2026 14:42:55 +0800] api WARNING Oozie application is not enabled: Model class oozie.models.Job doesn't declare an explicit app_label and isn't in an application in INSTALLED_APPS.
[23/Jan/2026 14:42:55 +0800] middleware INFO Unloading MimeTypeJSFileFixStreamingMiddleware
[23/Jan/2026 14:42:55 +0800] middleware INFO Unloading HueRemoteUserMiddleware
[23/Jan/2026 14:42:55 +0800] middleware INFO Unloading SpnegoMiddleware
[23/Jan/2026 14:42:55 +0800] middleware INFO Unloading ProxyMiddleware
[23/Jan/2026 14:43:00 +0800] backend INFO Augmenting users with class: <class 'desktop.auth.backend.DefaultUserAugmentor'>
[23/Jan/2026 14:43:00 +0800] access INFO 192.168.3.2 admin - "POST /jobbrowser/jobs/ HTTP/1.1" returned in 14ms 200 12
[23/Jan/2026 14:43:04 +0800] oozie_batch WARNING Oozie application is not enabled: Model class oozie.models.Job doesn't declare an explicit app_label and isn't in an application in INSTALLED_APPS.
[23/Jan/2026 14:43:04 +0800] hive_server2_lib INFO sparksql: server_host=dev3, use_sasl=True, mechanism=GSSAPI, kerberos_principal_short_name=hive, impersonation_enabled=True, auth_username=hue
[23/Jan/2026 14:43:04 +0800] hive_server2_lib INFO Opening sparksql thrift session for user admin
[23/Jan/2026 14:43:04 +0800] thrift_util INFO Thrift exception; retrying: Bad status: 3 (b'GSS initiate failed')
[23/Jan/2026 14:43:04 +0800] thrift_util INFO Thrift exception; retrying: Bad status: 3 (b'GSS initiate failed')
[23/Jan/2026 14:43:04 +0800] thrift_util INFO Thrift saw a transport exception: Bad status: 3 (b'GSS initiate failed')
[23/Jan/2026 14:43:04 +0800] access INFO 192.168.3.2 admin - "POST /api/editor/autocomplete/ HTTP/1.1" returned in 72ms 200 167
[23/Jan/2026 14:43:08 +0800] models INFO Sample user found with username "hue" and User ID: 1100713
[23/Jan/2026 14:43:08 +0800] models INFO Home directory already exists for user: hue
[23/Jan/2026 14:43:08 +0800] access INFO 192.168.3.2 admin - "GET /hue/editor/ HTTP/1.1" returned in 899ms 200 240424
[23/Jan/2026 14:43:08 +0800] access INFO 192.168.3.2 admin - "GET /static/desktop/css/roboto.895233d7bf84.css HTTP/1.1" returned in 16ms 200 -
[23/Jan/2026 14:43:08 +0800] access INFO 192.168.3.2 admin - "GET /static/desktop/ext/css/cui/bootstrap-responsive2.e47b2a557fdc.css HTTP/1.1" returned in 17ms 200 -
[23/Jan/2026 14:43:08 +0800] access INFO 192.168.3.2 admin - "GET /static/desktop/ext/css/font-awesome.min.bf0c425cdb73.css HTTP/1.1" returned in 13ms 200 -
[23/Jan/2026 14:43:08 +0800] access INFO 192.168.3.2 admin - "GET /static/desktop/ext/css/cui/cui.5bfb0d381388.css HTTP/1.1" returned in 11ms 200 -
[23/Jan/2026 14:43:08 +0800] access INFO 192.168.3.2 admin - "GET /static/desktop/ext/css/cui/bootstrap2.f77764366b1f.css HTTP/1.1" returned in 19ms 200 -
[23/Jan/2026 14:43:08 +0800] access INFO 192.168.3.2 admin - "GET /static/desktop/css/hue.ffaca3f0bc26.css HTTP/1.1" returned in 5ms 200 -
[23/Jan/2026 14:43:08 +0800] access INFO 192.168.3.2 admin - "GET /static/desktop/css/jquery-ui.1929861c8e8d.css HTTP/1.1" returned in 16ms 200 -
[23/Jan/2026 14:43:08 +0800] access INFO 192.168.3.2 admin - "GET /static/desktop/css/home.9208eafcb331.css HTTP/1.1" returned 
现象关键点
Spark SQL 的目标端是
dev3:10016,但 Hue 发起 GSSAPI 的身份仍是hive/...,这类组合通常会直>接导致GSS initiate failed。
二、配置层面的两种尝试
一开始的方向是"让 Hue 访问 Hive 用 Hive principal,访问 Spark SQL 用 Spark principal",但配置层面怎么做都不生效。
1、方案一:在 spark 强行指定 spark principal/短名
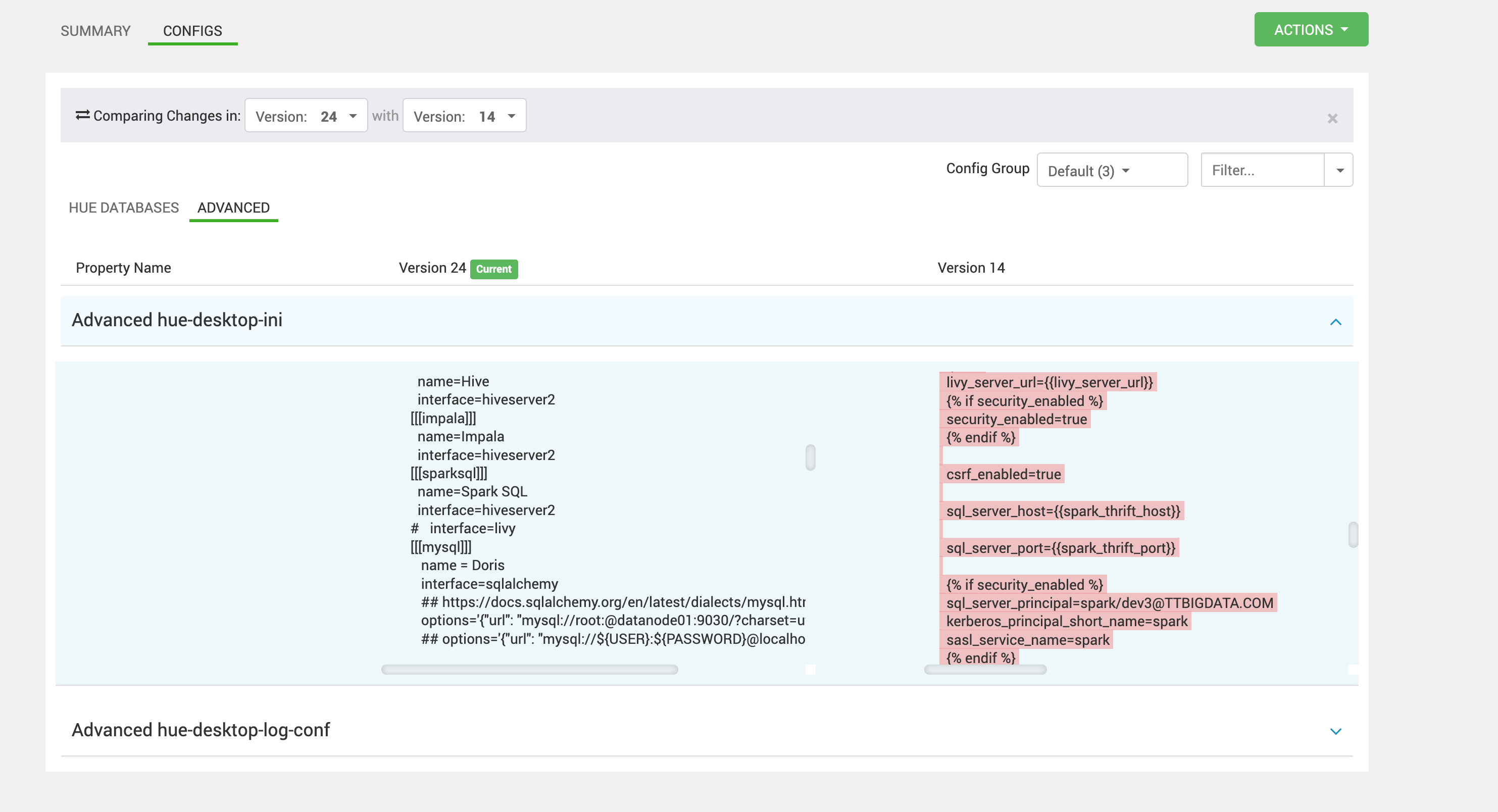
bash
[spark]
livy_server_url={{livy_server_url}}
{% if security_enabled %}
security_enabled=true
{% endif %}
csrf_enabled=true
sql_server_host={{spark_thrift_host}}
sql_server_port={{spark_thrift_port}}
{% if security_enabled %}
sql_server_principal=spark/dev3@TTBIGDATA.COM
kerberos_principal_short_name=spark
sasl_service_name=spark
{% endif %}
use_sasl=true结果:重启 Hue 后依旧不生效。
2、方案二:Notebook interpreters options 强行覆盖
bash
[notebook]
[[interpreters]]
[[[hive]]]
name=Hive
interface=hiveserver2
[[[impala]]]
name=Impala
interface=hiveserver2
[[[sparksql]]]
name=Spark SQL
interface=hiveserver2
options='{"server_host":"dev3","server_port":"10016","use_sasl":true,"mechanism":"GSSAPI","transportMode":"binary","sasl_service_name":"spark","kerberos_principal_short_name":"spark","principal":"spark/dev3@TTBIGDATA.COM"}'结果:同样不行。
为什么"配置看起来正确,但就是不生效"
从 Hue 的实现逻辑来看,Spark SQL(sparksql)并不是完全独立的一套 HS2 配置,它是复用 HiveServer2 的连接参数,然后在 dbms.py
中做二次覆写。
如果覆写逻辑只覆盖了 host/port/use_sasl,但没有覆盖 principal,最终进入 Thrift SASL/GSSAPI 的身份仍会沿用 Hive 的
principal。
三、打开 DEBUG 并定位到源码
为确认"最终生效"的 Query Server 参数来源,先把 Hue 日志调成 DEBUG:
bash
[root@dev1 conf]# cat log.conf
##########################################
# To change the log leve, edit the `level' field.
# Choices are: DEBUG, INFO, WARNING, ERROR, CRITICAL
#
# The logrotation limit is set at 5MB per file for a total of 5 copies.
# I.e. 25MB for each set of logs.
##########################################
[handler_logfile]
level=DEBUG
class=handlers.RotatingFileHandler
formatter=default
args=('%LOG_DIR%/%PROC_NAME%.log', 'a', 5000000, 5)
##########################################
# Please do not change the settings below
##########################################
[logger_root]
handlers=logfile,errorlog
[logger_access]
handlers=accesslog
qualname=access
[logger_django_auth_ldap]
handlers=accesslog
qualname=django_auth_ldap
[logger_kazoo_client]
level=INFO
handlers=errorlog
qualname=kazoo.client
[logger_djangosaml2]
level=INFO
handlers=errorlog
qualname=djangosaml2
[logger_django_db]
level=DEBUG
handlers=errorlog
qualname=django.db.backends
[logger_boto]
level=ERROR
handlers=errorlog
qualname=boto
[logger_hive_server2_lib]
level=DEBUG
handlers=logfile,errorlog
qualname=hive_server2_lib
propagate=0
[logger_beeswax]
level=DEBUG
handlers=logfile,errorlog
qualname=beeswax
propagate=0
[logger_desktop_lib_thrift_util]
level=DEBUG
handlers=logfile,errorlog
qualname=desktop.lib.thrift_util
propagate=0
[logger_desktop_lib_thrift_sasl]
level=DEBUG
handlers=logfile,errorlog
qualname=desktop.lib.thrift_sasl
propagate=0
[logger_thrift_util]
level=DEBUG
handlers=logfile,errorlog
qualname=thrift_util
propagate=0
# The logrotation limit is set at 5MB per file for a total of 5 copies.
# I.e. 25MB for each set of logs.
[handler_accesslog]
class=handlers.RotatingFileHandler
level=DEBUG
propagate=True
formatter=access
args=('%LOG_DIR%/access.log', 'a', 5000000, 5)
# All errors go into error.log
[handler_errorlog]
class=handlers.RotatingFileHandler
level=ERROR
formatter=default
args=('%LOG_DIR%/error.log', 'a', 5000000, 5)
[formatter_default]
class=desktop.log.formatter.Formatter
format=[%(asctime)s] %(module)-12s %(levelname)-8s %(message)s
datefmt=%d/%b/%Y %H:%M:%S %z
[formatter_access]
class=desktop.log.formatter.Formatter
format=[%(asctime)s] %(levelname)-8s %(message)s
datefmt=%d/%b/%Y %H:%M:%S %z
[loggers]
keys=root,access,django_auth_ldap,kazoo_client,djangosaml2,django_db,boto,hive_server2_lib,beeswax,desktop_lib_thrift_util,desktop_lib_thrift_sasl,thrift_util
[handlers]
keys=logfile,accesslog,errorlog
[formatters]
keys=default,access然后在日志中抓到了关键输出:Query via ini sparksql 后,Query Server 的 principal 仍为 Hive。
最终在 dbms.py 里找到了组装 Query Server 的逻辑:
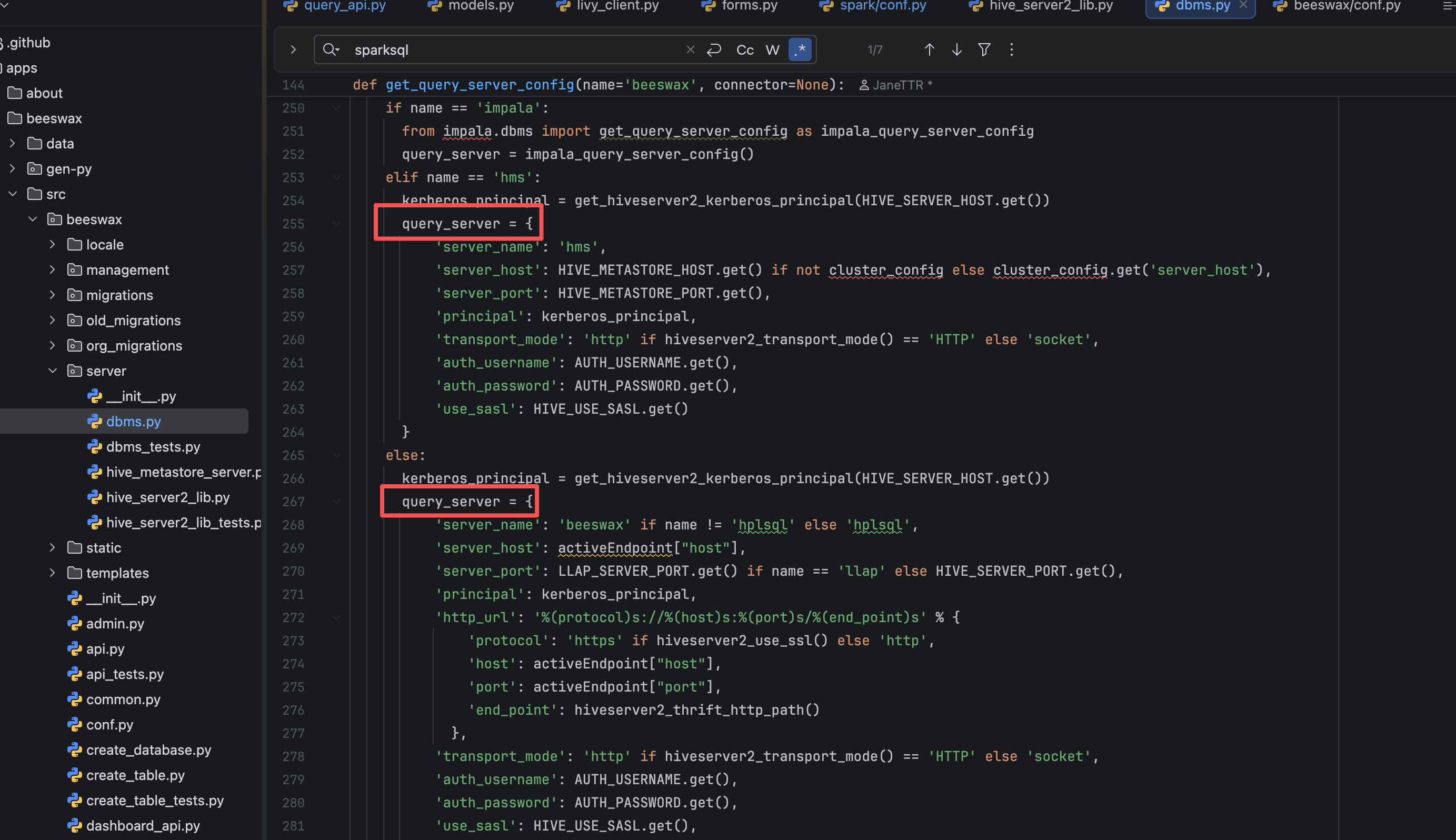
python
def get_query_server_config(name='beeswax', connector=None):
if connector and has_connectors(): # TODO: Give empty connector when no connector in use
LOG.debug("Query via connector %s" % name)
query_server = get_query_server_config_via_connector(connector)
else:
LOG.debug("Query via ini %s" % name)
if name == "llap":
activeEndpoint = cache.get('llap')
if activeEndpoint is None:
if HIVE_DISCOVERY_LLAP.get():
LOG.debug("Checking zookeeper for discovering Hive LLAP server endpoint")
zk = KazooClient(hosts=libzookeeper_conf.ENSEMBLE.get(), read_only=True)
zk.start()
if HIVE_DISCOVERY_LLAP_HA.get():
znode = "{0}/instances".format(HIVE_DISCOVERY_LLAP_ZNODE.get())
LOG.debug("Setting up Hive LLAP HA with the following node {0}".format(znode))
if zk.exists(znode):
hiveservers = zk.get_children(znode)
if not hiveservers:
raise PopupException(_('There is no running Hive LLAP server available'))
LOG.info("Available Hive LLAP servers: {0}".format(hiveservers))
for server in hiveservers:
llap_servers = json.loads(zk.get("{0}/{1}".format(znode, server))[0])["internal"][0]
if llap_servers["api"] == "activeEndpoint":
LOG.info("Selecting Hive LLAP server: {0}".format(llap_servers))
cache.set(
"llap",
json.dumps({
"host": llap_servers["addresses"][0]["host"],
"port": llap_servers["addresses"][0]["port"]
}),
CACHE_TIMEOUT.get()
)
else:
LOG.error("Hive LLAP endpoint not found, reverting to config values")
cache.set("llap", json.dumps({"host": HIVE_SERVER_HOST.get(), "port": HIVE_HTTP_THRIFT_PORT.get()}), CACHE_TIMEOUT.get())
else:
znode = "{0}".format(HIVE_DISCOVERY_LLAP_ZNODE.get())
LOG.debug("Setting up Hive LLAP with the following node {0}".format(znode))
if zk.exists(znode):
hiveservers = zk.get_children(znode)
for server in hiveservers:
cache.set(
"llap",
json.dumps({
"host": server.split(';')[0].split('=')[1].split(":")[0],
"port": server.split(';')[0].split('=')[1].split(":")[1]
})
)
zk.stop()
else:
LOG.debug("Zookeeper discovery not enabled, reverting to config values")
cache.set("llap", json.dumps({"host": LLAP_SERVER_HOST.get(), "port": LLAP_SERVER_THRIFT_PORT.get()}), CACHE_TIMEOUT.get())
activeEndpoint = json.loads(cache.get("llap"))
elif name != 'hms' and name != 'impala':
activeEndpoint = cache.get("hiveserver2")
if activeEndpoint is None:
if HIVE_DISCOVERY_HS2.get():
hiveservers = get_zk_hs2()
LOG.debug("Available Hive Servers: {0}".format(hiveservers))
if not hiveservers:
LOG.error('There are no running Hive server available')
raise PopupException(_('There are no running Hive server available'))
server_to_use = 0
LOG.debug("Selected Hive server {0}: {1}".format(server_to_use, hiveservers[server_to_use]))
cache.set(
"hiveserver2",
json.dumps({
"host": hiveservers[server_to_use].split(";")[0].split("=")[1].split(":")[0],
"port": hiveservers[server_to_use].split(";")[0].split("=")[1].split(":")[1]
})
)
else:
cache.set("hiveserver2", json.dumps({"host": HIVE_SERVER_HOST.get(), "port": HIVE_HTTP_THRIFT_PORT.get()}))
else:
# Setting hs2 cache in-case there is no HS2 discovery
cache.set("hiveserver2", json.dumps({"host": HIVE_SERVER_HOST.get(), "port": HIVE_HTTP_THRIFT_PORT.get()}))
if HIVE_DISCOVERY_HS2.get():
# Replace ActiveEndpoint if the current HS2 is down
hiveservers = get_zk_hs2()
if hiveservers:
server_to_use = 0
hs2_host_name = hiveservers[server_to_use].split(";")[0].split("=")[1].split(":")[0]
hs2_in_active_endpoint = hs2_host_name in activeEndpoint
LOG.debug("Is the current HS2 active {0}".format(hs2_in_active_endpoint))
if not hs2_in_active_endpoint:
LOG.error(
'Current HiveServer is down, working to connect with the next available HiveServer from Zookeeper')
reset_ha()
server_to_use = 0
LOG.debug("Selected HiveServer {0}: {1}".format(server_to_use, hiveservers[server_to_use]))
cache.set(
"hiveserver2",
json.dumps({
"host": hiveservers[server_to_use].split(";")[0].split("=")[1].split(":")[0],
"port": hiveservers[server_to_use].split(";")[0].split("=")[1].split(":")[1]
})
)
else:
LOG.error('Currently there are no HiveServer2 running')
raise PopupException(_('Currently there are no HiveServer2 running'))
activeEndpoint = json.loads(cache.get("hiveserver2"))
if name == 'impala':
from impala.dbms import get_query_server_config as impala_query_server_config
query_server = impala_query_server_config()
elif name == 'hms':
kerberos_principal = get_hiveserver2_kerberos_principal(HIVE_SERVER_HOST.get())
query_server = {
'server_name': 'hms',
'server_host': HIVE_METASTORE_HOST.get() if not cluster_config else cluster_config.get('server_host'),
'server_port': HIVE_METASTORE_PORT.get(),
'principal': kerberos_principal,
'transport_mode': 'http' if hiveserver2_transport_mode() == 'HTTP' else 'socket',
'auth_username': AUTH_USERNAME.get(),
'auth_password': AUTH_PASSWORD.get(),
'use_sasl': HIVE_USE_SASL.get()
}
else:
kerberos_principal = get_hiveserver2_kerberos_principal(HIVE_SERVER_HOST.get())
query_server = {
'server_name': 'beeswax' if name != 'hplsql' else 'hplsql',
'server_host': activeEndpoint["host"],
'server_port': LLAP_SERVER_PORT.get() if name == 'llap' else HIVE_SERVER_PORT.get(),
'principal': kerberos_principal,
'http_url': '%(protocol)s://%(host)s:%(port)s/%(end_point)s' % {
'protocol': 'https' if hiveserver2_use_ssl() else 'http',
'host': activeEndpoint["host"],
'port': activeEndpoint["port"],
'end_point': hiveserver2_thrift_http_path()
},
'transport_mode': 'http' if hiveserver2_transport_mode() == 'HTTP' else 'socket',
'auth_username': AUTH_USERNAME.get(),
'auth_password': AUTH_PASSWORD.get(),
'use_sasl': HIVE_USE_SASL.get(),
'close_sessions': CLOSE_SESSIONS.get(),
'has_session_pool': has_session_pool(),
'max_number_of_sessions': MAX_NUMBER_OF_SESSIONS.get()
}
if name == 'sparksql': # Extends Hive as very similar
from spark.conf import SQL_SERVER_HOST as SPARK_SERVER_HOST, SQL_SERVER_PORT as SPARK_SERVER_PORT, USE_SASL as SPARK_USE_SASL, SQL_SERVER_PRINCIPAL as SPARK_PRINCIPAL
query_server.update({
'server_name': 'sparksql',
'server_host': SPARK_SERVER_HOST.get(),
'server_port': SPARK_SERVER_PORT.get(),
'use_sasl': SPARK_USE_SASL.get()
})
if not query_server.get('dialect'):
query_server['dialect'] = query_server['server_name']
debug_query_server = query_server.copy()
debug_query_server['auth_password_used'] = bool(debug_query_server.pop('auth_password', None))
LOG.debug("Query Server: %s" % debug_query_server)
return query_server根因结论
sparksql复用 Hive 的query_server,但覆写时只改了server_host/server_port/use_sasl,没有把principal从 Hive 改成Spark。
因此无论 ini 配置怎么写,最终进入 GSSAPI 的身份仍是 Hive,触发
GSS initiate failed。
四、解决方案
处理办法可参考
22207:解决办法
五、验证结果
改完源码并重启 Hue 后,再次点击刷新,日志显示 sparksql 的 principal 已经切换成 spark:
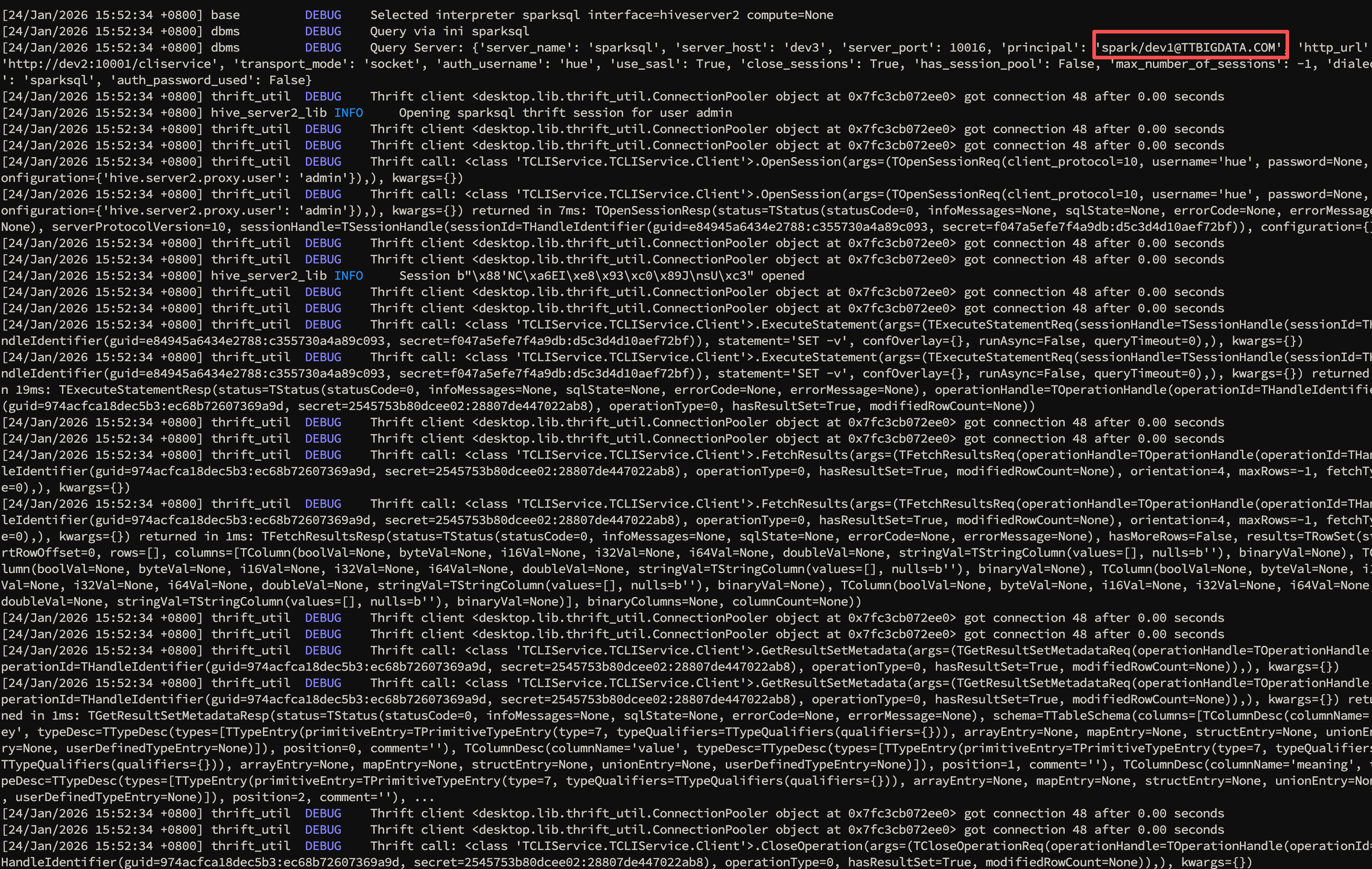
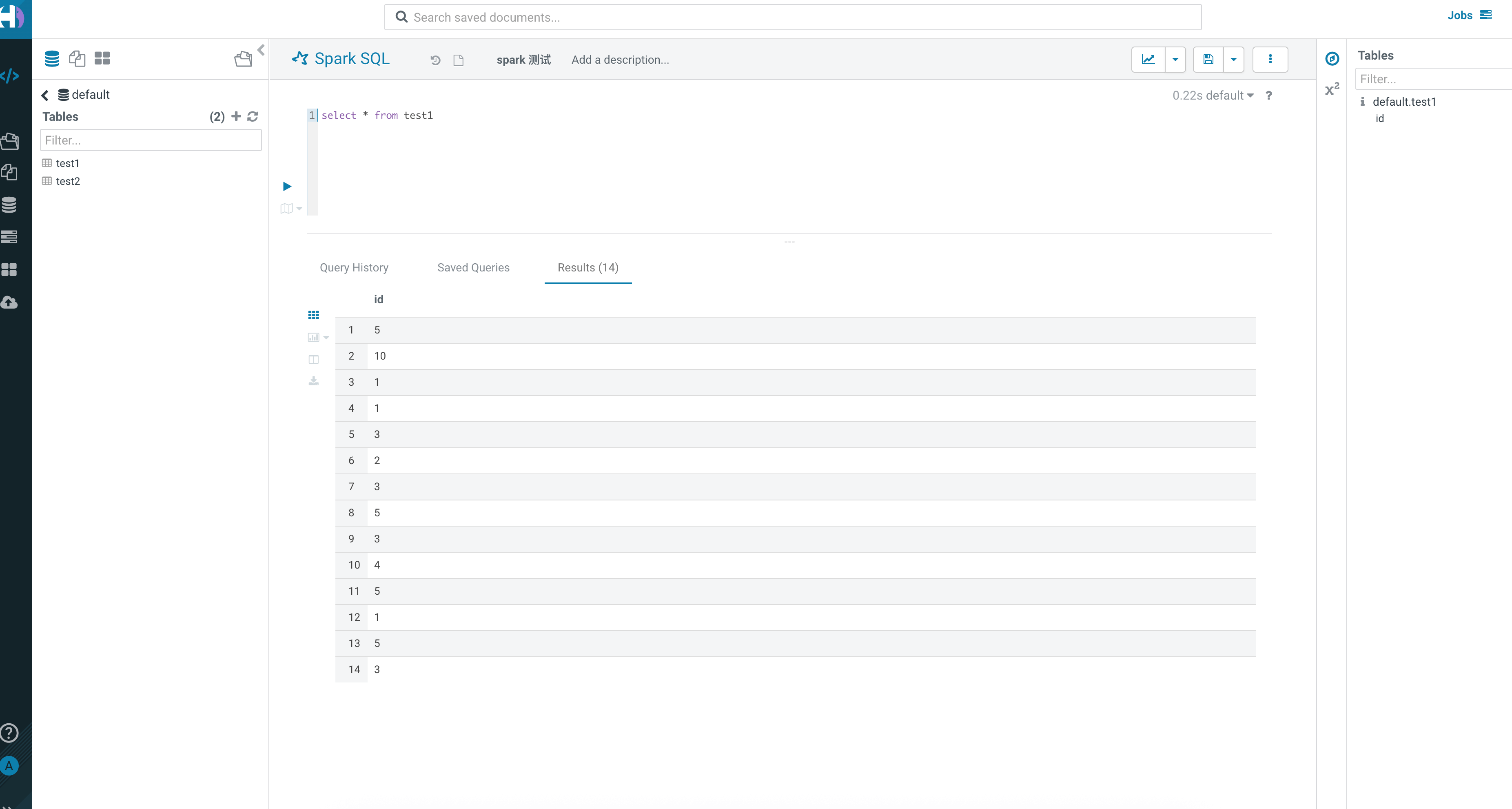
Spark SQL 查询可以正常执行:
验证要点
以 Hue DEBUG 日志为准:
Query Server输出中principal必须是spark/<host>@REALM,且 host/port 指向 Spark ThriftServer。
两者一致后,GSSAPI 才会以正确服务身份完成握手。