如果说人工智能是当下科技领域的 "顶流",那深度学习绝对是撑起这份热度的核心技术支柱。作为机器学习的重要分支,深度学习凭借模拟人脑的神经网络结构,在图像识别、语音交互、自然语言处理等领域屡创奇迹,甚至催生了 ChatGPT 这样的千亿参数级大模型。今天,我们就从基础概念出发,一步步拆解深度学习的核心逻辑,帮你轻松入门这门前沿技术。
一、深度学习是什么?核心逻辑一目了然
深度学习是机器学习领域中一个新的研究方向
它的关键特点的是:
- 用多层神经网络搭建模型,通过输入层、隐藏层、输出层的信号传递实现特征学习;
- 依赖反向传播算法优化网络参数,不断缩小预测误差;
- 擅长处理图像、语音等非结构化数据,能从海量信息中挖掘深层规律。
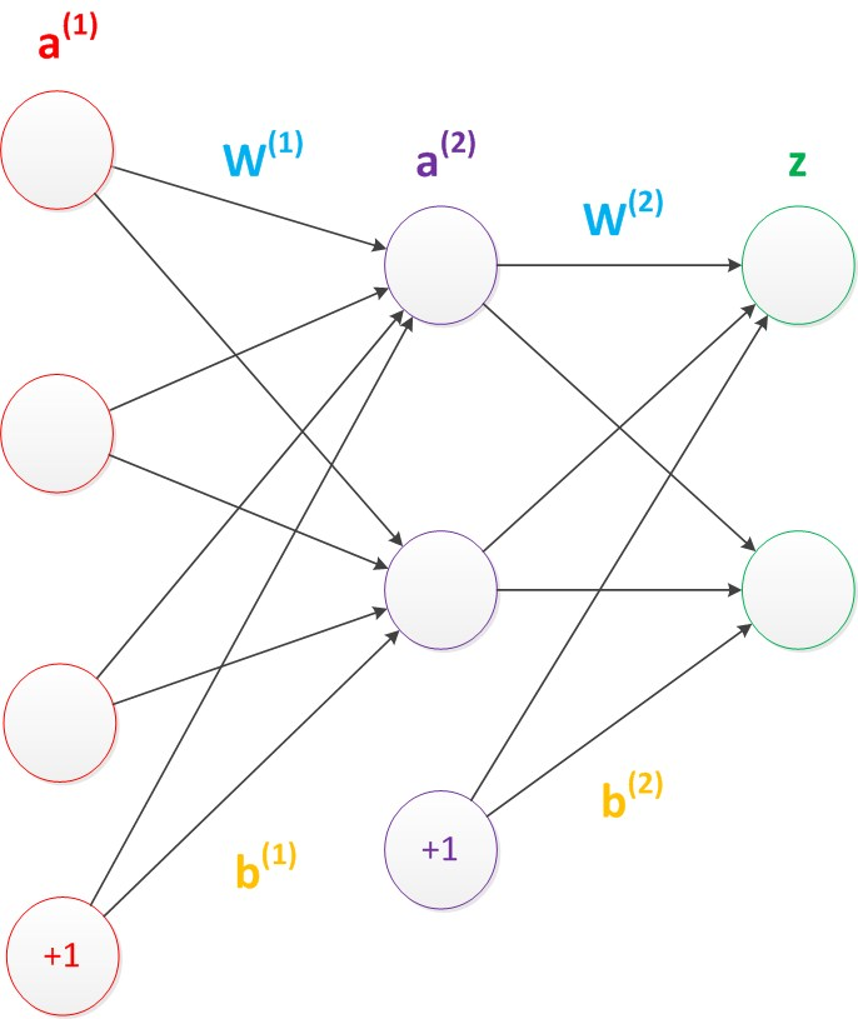
二、神经网络构造:从感知器到多层架构
神经网络是深度学习的 "骨架",理解它的构造就能抓住技术核心。
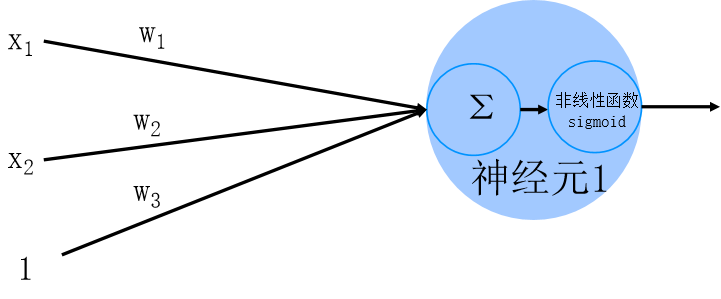
1. 基础单元:神经元与权重
每个神经元就像一个简单的计算节点,接收多个输入信号(x1、x2、...xn),每个输入都对应一个权重(w1、w2、...wn)------ 权重相当于信号的 "重要性系数",决定了该输入对输出的影响程度。

输入信号经过加权求和后,会通过激活函数(如 sigmoid)进行非线性转换,最终输出结果。激活函数是关键,它让神经网络能处理非线性问题,避免沦为简单的线性模型。
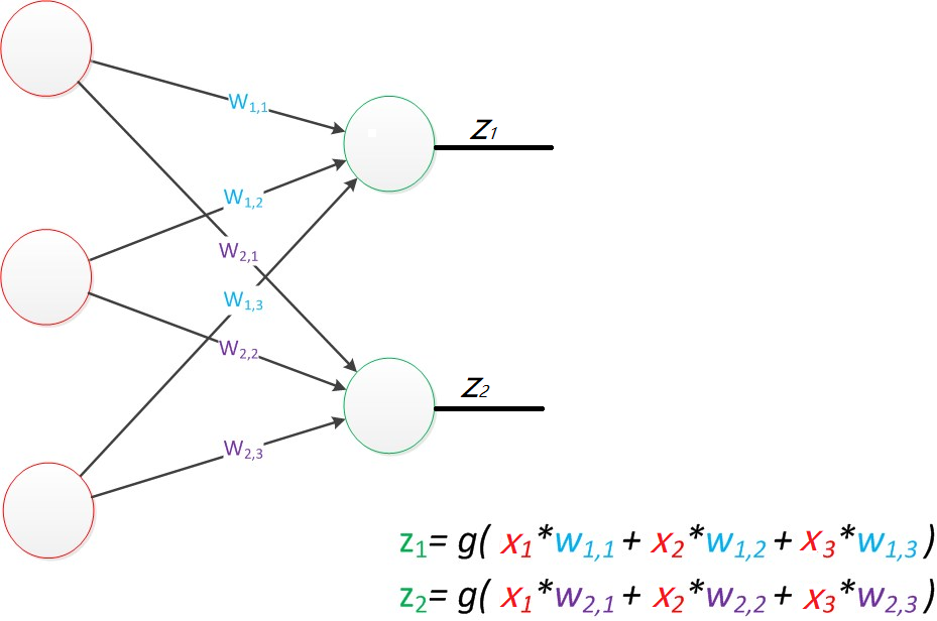
2. 基础架构:感知器与多层感知器
- 感知器:由输入层和输出层组成的两层神经网络,只能处理线性可分的数据(比如用直线划分两类点),局限性较大;
公式是线性方程组,因为可以用矩阵乘法来表达这两个公式
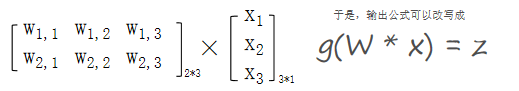
- 多层感知器(MLP) :在输入层和输出层之间增加了隐藏层,这是神经网络能处理非线性问题的核心。隐藏层可以有多层,层数越多,模型的特征提取能力越强(这也是 "深度" 学习的由来)。
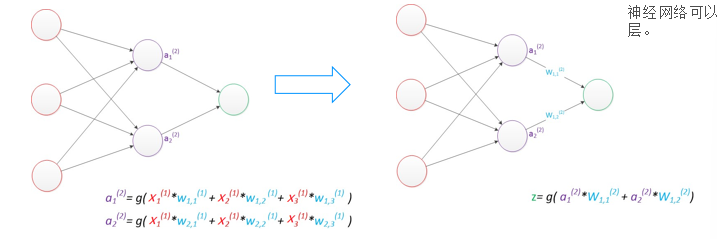
此外,神经网络中还存在偏置节点(默认值为 1),它能调整模型的输出基准,避免因输入全为 0 导致网络失效,通常不会在结构图中明确画出。
三、模型训练:从损失函数到反向传播
搭建好神经网络后,核心是通过训练让模型 "学会" 规律,这一过程的核心是 "最小化误差"。
1. 损失函数:衡量预测与真实的差距
损失函数(Loss Function)是量化预测值()与真实值(y)误差的工具,误差越小说明模型效果越好。常用的损失函数包括:
- 均方差损失(MSE):适合回归任务,计算预测值与真实值的平方差平均值;
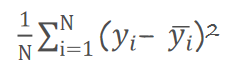
- 交叉熵损失:适合分类任务,尤其多分类场景,通过概率归一化后取对数,放大错误预测的损失;
- 0-1 损失函数、平均绝对差损失等:根据具体任务选择。
以多分类为例,模型输出会通过归一化转换为 0-1 之间的概率,若输入 "猫" 的图片,对应 "猫" 类别的概率越接近 1,交叉熵损失越小,模型预测越准确。
2. 正则化:防止过拟合的关键
过拟合是模型训练的 "天敌"------ 指模型在训练数据上表现极好,但在新数据上误差很大。正则化通过惩罚过大的权重参数(),避免模型过度依赖个别特征,常用的有两种:
- L1 正则化:对权重绝对值求和(
),会让部分权重变为 0,实现特征筛选;
- L2 正则化:对权重平方求和(
形象来说,正则化就像 "约束模型不要太较真",避免它死记硬背训练数据,而是学习通用规律。
3. 梯度下降与反向传播:优化权重的核心算法
模型训练的本质是调整权重(w)以最小化损失函数,这就需要梯度下降和反向传播的配合:
- 梯度:损失函数对所有权重的偏导数构成的向量,指明了损失函数变化最快的方向;
- 梯度下降:沿着梯度的反方向调整权重,步长(学习率)决定调整幅度 ------ 步长太大容易震荡,太小则训练过慢;
- 反向传播(BP):从输出层的损失值出发,反向计算每一层权重对损失的影响,将梯度传递到输入层,完成全网络权重的更新。
整个训练过程就是 "正向传播计算损失→反向传播调整权重" 的循环,直到损失值小于预设阈值,模型达到最优。
四、深度学习的核心:数据与参数规模
深度学习的性能离不开两大要素:海量数据和大规模参数。以 ChatGPT 为例,它基于 8000 亿个单词的语料库训练,包含 1750 亿个参数 ------ 正是这样的 "数据 + 参数" 规模,让模型能捕捉复杂的语言规律,实现流畅的人机交互。
但这并不意味着入门必须依赖千亿级数据,对于初学者来说,掌握核心逻辑后,用小规模数据集(如 MNIST 手写数字数据集)搭建简单神经网络,就能直观感受深度学习的工作原理。
总结
深度学习的核心逻辑并不复杂:用多层神经网络模拟人脑,通过权重传递信号,靠损失函数判断误差,借梯度下降和反向传播优化参数,再用正则化避免过拟合。从感知器到千亿参数大模型,本质都是这一逻辑的延伸与升级。
如果你是技术入门者,建议从搭建简单的多层感知器开始,亲手实践数据预处理、模型搭建、训练优化的全流程,就能逐步打通深度学习的 "任督二脉"。