我们之前讲了Redis中数据对象的存储,大家就好奇了,我既然知道这些对象存储的底层原理,那么整体在Redis中是怎么存储的呢?Redis作为内存存储,前面提到过我们放在Redis中的数据都是以键值对形式存储的,本次我们会学习Redis底层结构到底长什么样?
一.内存存储
在Redis中,redisDb代表Redis数据库结构,而我们之前讲的各种操作对象是存储在dict数据结构里的,下面是redisDb的结构代码:
cpp
typedef struct redisDb {
dict *dict; // 主字典,存储所有键值对
dict *expires; // 过期时间字典,存储key的过期时间
dict *blocking_keys; // 阻塞键字典(BLPOP等命令使用)
dict *ready_keys; // 就绪键字典
dict *watched_keys; // 监视键字典(事务WATCH使用)
int id; // 数据库ID(0-15)
long long avg_ttl; // 平均TTL(用于统计)
list *defrag_later; // 稍后碎片整理的键列表
} redisDb;在该结构中,我们需要重点关注其中两个字段: dict和expires;
2.1dict结构
我们先重点关注一i下dict结构,它代表我们存入的key-value存储,我们平常添加数据,就是往dict里添加。可以看到,dic就是我们前面介绍的Hash对象结构:
cs
typedef struct dict {
dictType *type;
void *privdata;
dicht ht[2];
long rehashidx; /* rehashing */
unsigned long iterators; /* */
} dict;下面这张图更加生动的说明了redis中底层数据存储是什么样的:redisDb即为数据库对象,指向了数据字典,字典里包含了我们平常存储的k-v数据,k是字符串对象,value支持任意Redis对象,这些对象我们前面有介绍。
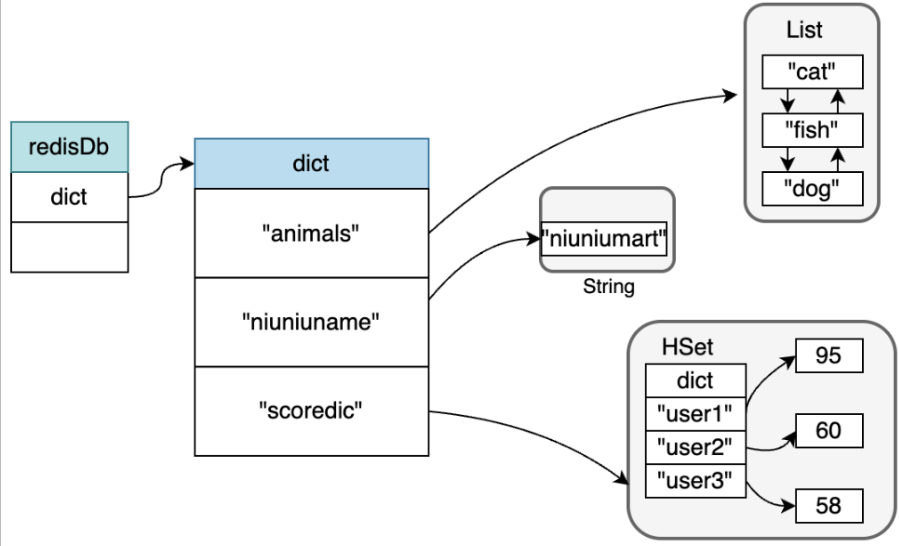
当时我学到这的时候,有一个疑问,Redis中redisDb有一个dict字段用于存入key-value;而这个字段里有一个dictht ht2代表两个hashtable,其中我们最常用的是h0,那么我在使用hash对象的时候会使用到hashtable,如果我再加一个hash对象不是又需要用到新的hashtable,可是一个数据库不是只有一个dict,而这个dict只对应唯一dictht ht2,那怎么办。后面查询资料才知道是我的误解,我混淆了两个不同层次的哈希表:
1. 数据库层面的哈希表(redisDb中的dict)
redisDb.dict是用来存储整个数据库所有键值对的dict.ht[0]和dict.ht[1]是用于渐进式rehash的- 这里存的是:key(字符串)→ value(可以是string、list、hash、set等任意类型)
2. Hash对象内部的哈希表
- 当value的类型是hash时,这个hash对象内部有自己独立的dict结构
- 每个hash对象都有自己的
dict,也有自己的ht[0]和ht[1]
cs
redisDb
└── dict (数据库级别的字典)
└── ht[0] / ht[1] (用于渐进式rehash)
├── key: "user:1" → value: Hash对象
│ └── dict (这个hash对象自己的字典)
│ └── ht[0] / ht[1]
│ ├── "name" → "张三"
│ ├── "age" → "25"
│ └── "city" → "北京"
│
├── key: "user:2" → value: Hash对象
│ └── dict (另一个独立的字典)
│ └── ht[0] / ht[1]
│ ├── "name" → "李四"
│ └── "age" → "30"
│
└── key: "counter" → value: String对象
└── "100"- redisDb中的dict:管理所有Redis键,每个键对应一个value对象
- Hash对象中的dict:每个hash对象内部都有独立的dict,用于存储该hash的field-value对
所以我添加多个hash对象不会冲突,因为每个hash对象都包含自己独立的dict结构。这是一种嵌套的设计,外层dict管理键空间,内层dict(在hash对象中)管理hash的字段。
接下来我们需要知道如何添加数据呢?
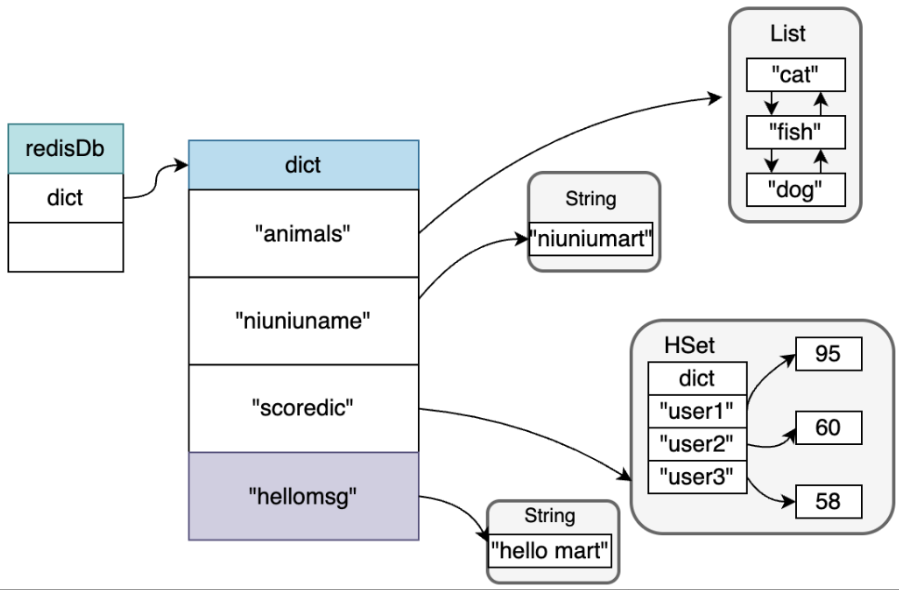
即将键值对,添加到dict结构字典中去,Key必须为String对象,Value为任何类型的对象都可以。比如,如果我们使用命令:SEThellomsg"hellomart",键空间会变成如下结构。
2.2 expires
我们有介绍过,Redis数据都可以设置过期键,这样到了一定的时间,这些对象就会自动过期并回收。那么过期键,又是存储在哪里的呢?过期键是存在expires字典上。
假设上面例子的Key,都设置了过期时间,那么结构如下:
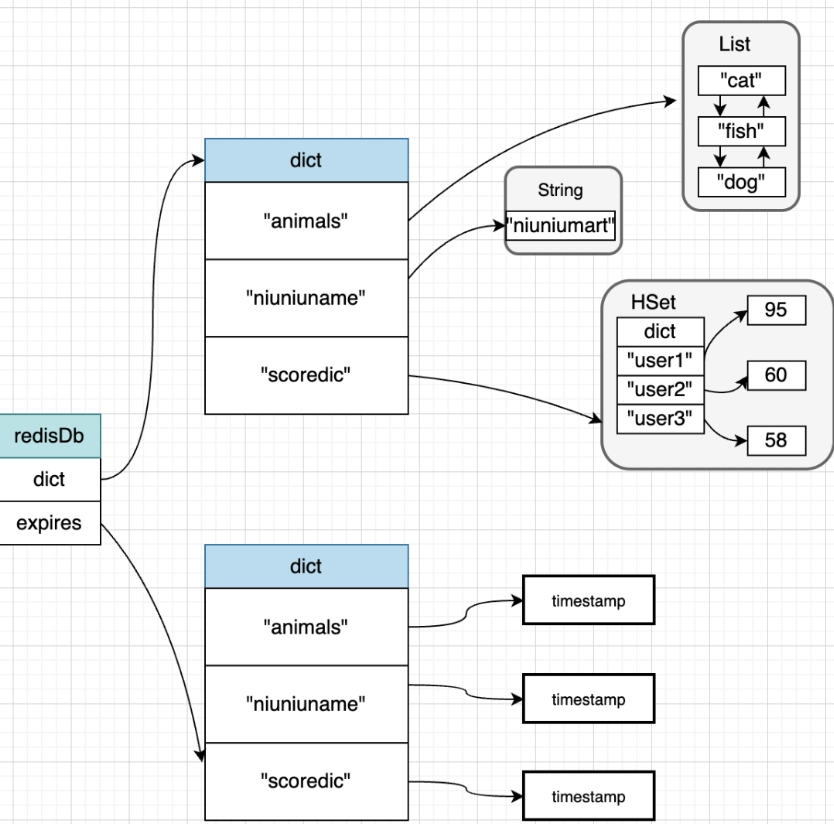
注意,这里的dict中和expires中Key对象,实际都是存储的String对象指针,意思是内存中有一片地址存储这些字符串,而dict和expires中的key实际存储的都是指向内存相应字符串的地址。所以并不是会重复占用内容,Redis对内存的使用都是很珍惜的。
除此之外,redis中如果key设置了ttl,会立马进入到过期字典,要先判断是否过期,再决定是否返回值。而键过期之后不会立即删除,一般会采取三种清楚策略,分别是定时,定期或者惰性删除。Redis主要是定期和惰性删除。
二. 单线程
Redis是一个能高效处理请求的组件,一般而言,对于这种组件我们需要了解它的并发模型是什么样的;而对于Redis,核心处理逻辑Redis一直是单线程的,其它辅助模块也会有一些多线程,比如UNLINK。总之,Redis采用Reactor模式的网络模型,对于一个客户端的请求,主线程负责一个完整的处理过程。
那么为什么Redis会选择单线程呢?
从Redis的定位来看,一般来说Redis的执行会很快,所以执行本身不应该成为瓶颈,而瓶颈通常在网络I/O部分,所以处理逻辑多线程并不会有太大的收益。因为Redis主要是键值存储,其操作主要涉及内存读取/写入和网络通信,而这些操作通常不需要大量的CPU计算,因此多线程带来的CPU并行处理优势并不明显,甚至可能增加线程切换开销。
同时,Redis本身秉持简洁高效的理念,代码的简单性、可维护性是Redis一直以来的追求,引入多线程带来的复杂性远比想象的要大,而且多线程本身也会引入额外成本,下面我们分析一下:
1.多线程引入的复杂性是极大的
首先,多线程引入之后,Redis原来的顺序执行特性就不复存在,为了支持事务的原子性、隔离性,Redis就不得不引入一些很复杂的实现;其次,Redis的数据结构,可以说是极其高效,在单线程模式下做了很多特性的优化,如果引入多线程,那么所有底层数据结构都要改造为线程安全,这会是极其复杂的工作;而且,多线程模式也使得程序调试更加复杂和麻烦,会带来额外的开发成本及运营成本,也更容易犯错
2.多线程带来额外的成本
除了引入复杂度,多线程还会带来额外的成本。包括:
- 上下文切换成本,多线程调度需要切换线程上下文,这个操作先存储当前线程的本地数据、程序指针等,然后载入另一个线程数据,这种内核操作的成本不可忽视。
- 同步机制的开销,一些公共资源,在单线程模式下直接访问就行了,多线程需要通过加锁等方式去进行同步,这也是不可忽视的CPU开销;
- 一个线程本身也占据内存大小,对Redis这种内存数据库而言,内存非常珍贵,多线程本身带来的内存使用的成本也需要谨慎决策。
所以综合来看,多线程其实会带来非常多的成本,如果将处理模块改为多线程,即使在性能上,可能也很难有一个很高的预期,毕竟Redis单线程的处理,已经够快了。
既然我们选择了单线程,为什么单线程能够这么快呢?
我们前面说到,Redis核心的请求处理是单线程,通常来说,单线程的处理能力要比多线程差很多,但是Redis却能使用单线程模型达到每秒数万级别的处理能力,一般业界认知就是Redis的性能是能达到10多w的。这是为什么呢?其实,这是Redis多方面极致设计的一个综合结果。
几个关键点:
- Redis的大部分操作在内存上完成,内存操作本身就特别快;
- 第二,Redis追求极致,选择了很多高效的数据结构,并做了非常多的优化,比如ziplist,hash,跳表,有时候一种对象底层有几种实现以应对不同场景。
- 第三,Redis采用了多路复用机制,使其在网络I0操作中能并发处理大量的客户端请求,实现高吞吐量。
前面两点很好理解,我们这边着重来讲第三点多路复用机制。要理解多路复用机制,我们要先理解为什么要多路复用,没有多路复用情况下,哪些环节可能发生阻塞,Redis是单线程模型,一旦发生阻塞,整体服务都慢会下来。
首先,我们知道Redis是完全在内存中处理数据,所以我们最应该考虑的瓶颈是I/O,我们下面通过分析一次请求,来看一下,一个单线程在一次完整的处理中,哪些地方可能拖慢整个流程。
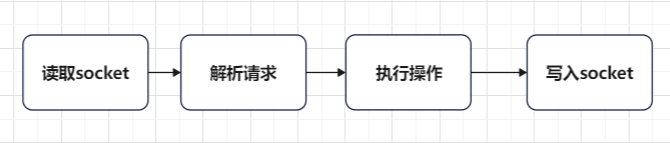
Redis的服务端在启动的时候,已经bind了端口,并且用listen操作监听客户端请求,此时客户端就可以发起连接请求。此时,客户端发起一次处理请求,比如,客户端发来一个GET请求,服务端需要哪些事情:
1.客户端请求到来时候,使用accept建立连接
2.调用recv从套接字中读取请求
3.解析客户端发送请求,拿到参数
4.处理请求,这里是Get,那么Redis就是通过Key获取对应的数据5.最后将数据通过send发送给客户端
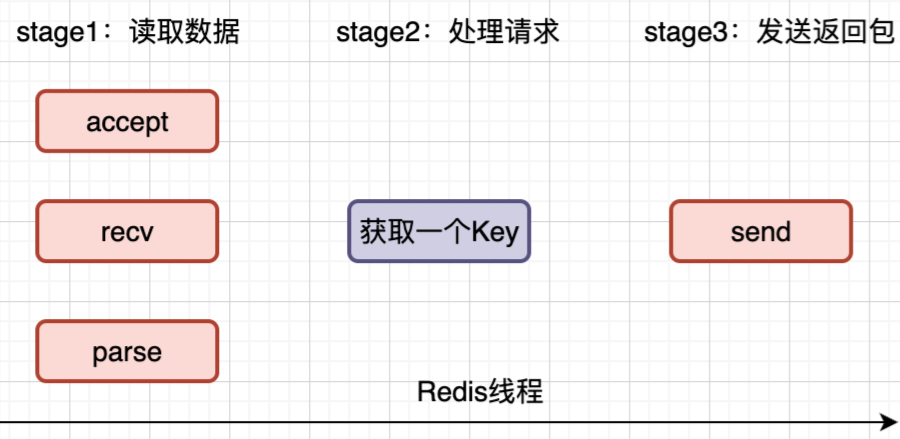
我们要知道,套接字是默认阻塞模式的,这里阻塞可能会发生在两个地方。个是accept,比如accept建立时间过长,另一个是recv时客户端一直没有发送数据。此时,Redis服务就会阻塞在那里。Redis本身定位就是单线程,发生这种阻塞会将整个服务都卡住。所以不能让这两个操作阻塞,这里Redis将套接字设置为非阻塞式的,这样accept和recv都可以非阻塞调用。
非阻塞调用下,如果没数据,不会阻塞在那里,而是让你返回做其它事情。这样可以解决卡死的问题。但我们也需要一种机制,能回过头来看看这些操作是否已经就绪。
最简单的思路,我们可以通过一个循环来不断轮询,但这种方式显然低效。好在各个操作系统实现了一种机制,叫I/O多路复用。
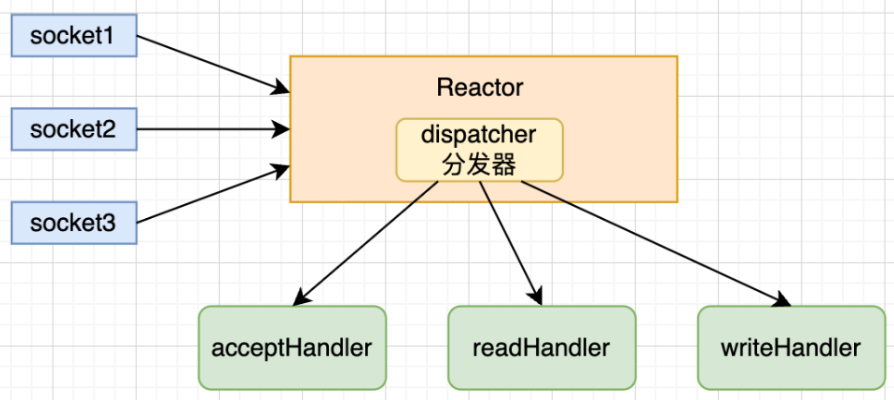
什么叫I/O多路复用,简单理解来说,就是有I/O操作触发的时候,就会产生通知,收到通知,再去处理通知对应的事件,针对I/O多路复用,Redis做了一层包装,叫Reactor模型。
如下图,本质就是监听各种事件,当事件发生时,将事件分发给不同的处理器。
声明: 本篇笔记仅为学习时整理的笔记以及疑问解决点,无其他任何商业用途,如有侵权联系即删。