文章目录
- 5.1内存模型基础
- 5.2C++中的原子操作和类型
-
- 5.2.1标准原子类型
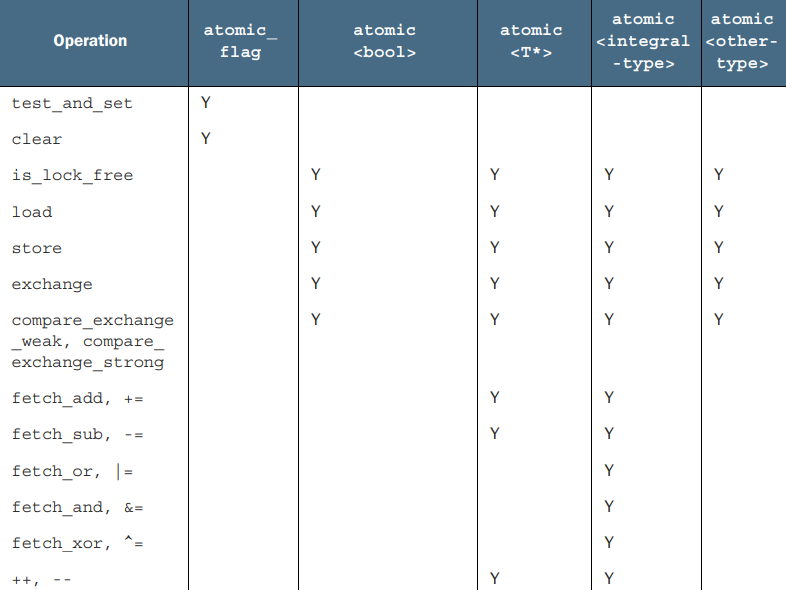
- 5.2.2对std::atomic_flag的操作
- 5.2.3对std::atomic\<bool\>的操作
- 5.2.4对std::atomic\<T*\>:指针运算的操作
- 5.2.5标准原子整型的操作
- [5.2.6 std::atomic<>类模板](#5.2.6 std::atomic<>类模板)
- 5.2.7用于原子操作的非成员函数
- 5.3同步操作和强制顺序
-
- [5.3.1 synchronize -with关系](#5.3.1 synchronize -with关系)
- [5.3.2 happens-before关系](#5.3.2 happens-before关系)
- 5.3.3原子操作的内存排序
- 5.3.4释放序列和同步
- 5.3.5栅栏(Fences)
- [5.3.6 用原子操作对非原子操作进行排序](#5.3.6 用原子操作对非原子操作进行排序)
- 5.3.7对非原子操作排序
5.1内存模型基础
5.1.1对象和内存位置
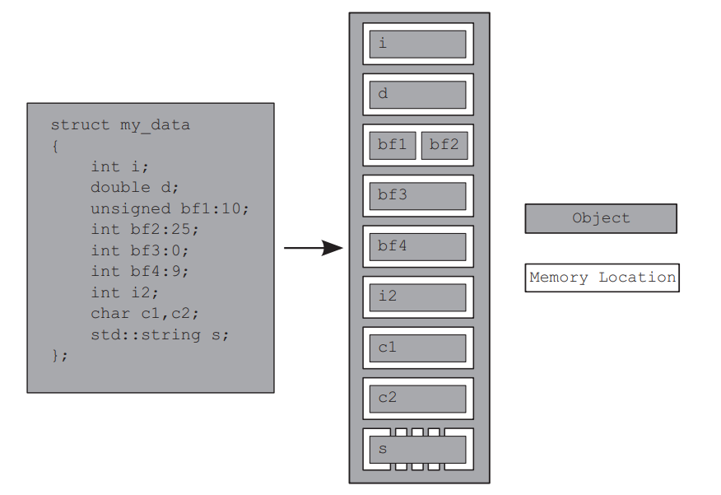
对象的内存表示:C++中每个变量都是对象,都在内存中有对应的位置。无论是简单变量还是复杂数据结构,都会在内存中有自己的空间位置。
基本类型与内存占用:基础数据类型如int或char,无论其值大小如何,都只会占用一个内存位置。这意味着即使它们是数组的一部分,也会单独占用一个内存位置。
并发编程中的内存访问:如果多个线程操作同一内存位置,可能会引发问题,尤其当涉及数据修改时。
- 每个变量都是一个对象,包括成员变量
- 每个对象至少占用一个内存位置
- 基本类型变量,如 int 或 char,恰好占用一个内存位置,无论它们的大小如何,即使- 它们是相邻的或是一个数组的一部分
- 相邻的位字段是同一个内存位置的一部分
下例中,bf3 通常没有自己的内存位置,而 bf4 会有自己的内存位置。bf是bitfield的缩写,即位域,后面的数字表示在内存中占多少位。用竖直方框表示内存地址从低到高的排列
5.1.2对象、内存位置和并发
线程安全与内存位置:
当多个线程访问不同的内存位置时,它们之间不会互相干扰,保持各自独立执行任务。这种情况下,系统线程安全,无需额外的同步措施。
只读共享数据:
如果多个线程同时访问相同的内存位置,但都以只读方式操作,那么也不会出现线程安全问题。只读共享数据不需要特别的保护机制。
修改共享数据的风险:
当多个线程对同一内存位置进行写操作时,就会产生线程安全问题。必须采取适当的同步策略来避免数据不一致或竞态条件的发生。
使用原子操作访问内存位置是避免未定义行为的有效方法之一。虽然它不能完全阻止数据竞争,但可以确保程序在遇到并发问题时仍保持定义行为,提高程序的可靠性,具体在后面介绍。
5.1.3修改顺序
对象修改顺序的一致性是通过程序中的同步机制和内存模型的规则在运行时实现的。
对象修改顺序是由程序中所有线程对该对象的写入操作组成的,从对象的初始化开始。
在任何给定的程序执行中,系统中的所有线程必须对每个对象修改顺序达成一致,但它们不必对不同对象上的操作顺序达成一致。
如果使用原子操作,编译器会负责确保必要的同步,从而维护修改顺序。
5.2C++中的原子操作和类型
原子操作的不可分割性:原子操作是系统中无法被其他线程观察到中间状态的操作,要么完成,要么未完成
5.2.1标准原子类型
可以使用互斥锁来使作表现得像原子操作。标准的原子类型本身可能就是通过这种方式进行模拟的。
通过调用is_lock_free()成员函数,用户可以确定原子类型是否直接使用原子指令执行。
C++17以后,所有原子类型都有一个静态常量成员变量X::is_always_lock_free,表示该原子类型在所有支持的硬件上是否总是lock-free。
如果原子操作本身使用内部锁,可能无法实现预期的性能提升。
ATOMIC_BOOL_LOCK_FREE、ATOMIC_CHAR_LOCK_FREE等宏,指定了对于指定的内置类型及其无符号对应类型的相应原子类型的无锁(lock-free)状态:
0:从来不是无锁的
1:是一个运行时属性
2:总是无锁的
std::atomic_flag是唯一没有提供is_lock_free()成员函数的原子类型。它是一个简单的布尔标志,其操作必须为无锁,这是实现其他原子类型的基础。除了std::atomic_flag外,其余的原子类型都是通过std::atomic类模板的特化来访问的,它们功能更全面,但可能不是无锁的。在大多数流行平台上,预期所有内置类型的原子变体(如std::atomic<int>)都是无锁的,但这并不是必须的。
std::atomic_flag 类型的对象被初始化为clear状态,然后可以被查询和设置(使用 test_and_set() 成员函数)或者被清除(使用 clear() 成员函数)。
除了直接使用 std::atomic<> 类模板,还可以使用下表中的原子类型:
| 类型别名 | 标准特化类型 |
|---|---|
atomic_bool |
std::atomic<bool> |
atomic_char |
std::atomic<char> |
atomic_schar |
std::atomic<signed char> |
atomic_uchar |
std::atomic<unsigned char> |
atomic_int |
std::atomic<int> |
atomic_uint |
std::atomic<unsigned int> |
atomic_short |
std::atomic<short> |
atomic_ushort |
std::atomic<unsigned short> |
atomic_long |
std::atomic<long> |
atomic_ulong |
std::atomic<unsigned long> |
atomic_llong |
std::atomic<long long> |
atomic_ullong |
std::atomic<unsigned long long> |
atomic_char16_t |
std::atomic<char16_t> |
atomic_char32_t |
std::atomic<char32_t> |
atomic_wchar_t |
std::atomic<wchar_t> |
除了基本的原子类型,C++ 标准库还提供了一组对应标准库typedef类型定义的 typedef
| 原子类型别名 | 对应的标准库类型 |
|---|---|
atomic_int_least8_t |
int_least8_t |
atomic_uint_least8_t |
uint_least8_t |
atomic_int_least16_t |
int_least16_t |
atomic_uint_least16_t |
uint_least16_t |
| ... | ... |
标准库原子类型没有提供传统意义上的拷贝或赋值。标准原子类型提供了一些成员函数,如load()和store(),可以直接加载和存储原子变量的值,以及exchange()、compare_exchange_weak()和compare_exchange_strong()等函数,用于实现原子操作的同步和比较。
标准原子类型支持适当的复合赋值运算符,如+=、-=、*=等,用于实现原子变量的赋值操作。并有对应的成员函数fetch_add(), fetch_or()等。
赋值运算符和成员函数的返回值可以是存储的值(对于赋值运算符)或操作前的值(对于命名函数),避免了通常的引用返回方式可能引发的竞态条件问题。
为了从引用中获取存储的值,代码将不得不执行一个单独的读取操作,这允许另一个线程在赋值和读取之间修改该值,从而为数据竞争打开了大门。简单说使用地址引用的时候,在赋值和读取之间,可能会有另外的线程对该变量进行修改,从而引发问题。
std::atomic模板可以用于创建自定义类型的原子变量。std::atomic的操作主要包括load(), store()等,每种操作都有其特定的内存排序选项;内存排序选项决定了原子操作的内存顺序语义,不同的操作类别有不同的允许值。
内存排序选项被分为三类:
- 存储操作:可以具有 memory_order_relaxed、memory_order_release 或 memory_order_seq_cst 顺序;
- 加载操作:可以具有 memory_order_relaxed、memory_order_consume、memory_order_acquire 或 memory_order_seq_cst 顺序;
- 读改写操作:可以具有 memory_order_relaxed、memory_order_consume、memory_order_acquire、memory_order_release、memory_order_acq_rel 或 memory_order_seq_cst 顺序。
如果没有指定内存排序参数,std::atomic将使用最严格的std::memory_order_seq_cst(sequentially consistent,按顺序一致)作为默认排序行为,以确保数据的原子性和可见性。
下面来学习原子类型的通用操作
5.2.2对std::atomic_flag的操作
std::atomic_flag 对象可以处于两种状态之一:设置(set:true)或清除(clear:false)。被故意设计得非常基础,仅作为构建块使用。std::atomic_flag 类型的对象必须使用 ATOMIC_FLAG_INIT 进行初始化。这将标志初始化为清除状态:
cpp
std::atomic_flag f = ATOMIC_FLAG_INIT;它是唯一需要这种特殊初始化处理的原子类型,也是有保证总是无锁(lock-free)的唯一类型。
std::atomic_flag 对象初始化后,只能执行析构函数、clear() 和 test_and_set() 成员函数。clear() 函数是存储操作(涉及到对原子对象状态的改变),不能有 memory_order_acquire 或 memory_order_acq_rel 语义,但 test_and_set() 是一个读、修改、写操作,因此可以应用任何内存排序。与每个原子操作一样,默认情况下两者都是 memory_order_seq_cst。
cpp
f.clear(std::memory_order_release);
bool x = f.test_and_set(); //默认内存排序clear() 函数使用 memory_order_release 内存排序进行调用,这确保了在清除标志之前的所有存储操作对其他线程可见。test_and_set() 函数尝试将标志设置为设置状态,并返回设置之前的值。
原子类型的所有操作都被定义为原子的,拷贝构造或赋值必须首先从一个对象读取值,然后将该值写入另一个对象,它们的组合不可能是原子的。
std::atomic_flag 的功能集有限,非常适合用作自旋锁互斥锁(spinlock mutex)。最初,标志位是清除的,互斥锁是解锁的。要锁定互斥锁,循环调用 test_and_set() 直到旧值为假,表示该线程将值设置为真。解锁互斥锁只需清除标志位:
cpp
class spinlock_mutex{ // 忙等待锁
private:
std::atomic_flag flag; // 原子标志用于表示锁的状态
public:
// 构造函数初始化标志位为未设置(clear)状态,表示锁未被占用
spinlock_mutex() : flag(ATOMIC_FLAG_INIT) {} // 默认false
void lock(){// 尝试获取锁,如果锁已被占用,则忙等待(spin-wait)直到锁可用
while (flag.test_and_set(std::memory_order_acquire)); // 如果成功设置(旧值false),表示锁成功
}
void unlock(){// 释放锁,将标志位清除,表示锁现在可用
flag.clear(std::memory_order_release); //std::memory_order_release 确保在特定操作之前的所有内存写入操作对于后续使用 std::memory_order_acquire、std::memory_order_consume 或 std::memory_order_seq_cst 内存序秩序进行的原子读取操作可见
}
};5.2.3对std::atomic<bool>的操作
std::atomic<bool>是一个比 std::atomic_flag 更具功能的布尔标志。尽管仍然不能进行拷贝构造或拷贝赋值,但可以从一个非原子的 bool 类型构造它,或进行赋值:
cpp
std::atomic<bool> b(true);
b = false;从非原子 bool 类型的赋值,返回一个赋值后的布尔值。这是原子类型的另一个常见模式:它们支持的赋值操作符返回值而不是引用
cpp
std::atomic<bool> flag;
bool condition = true;
// 使用赋值操作符设置flag的值,并获取设置后的值
bool result = flag = condition;// 现在,result变量包含了设置后的flag的值如果返回对原子变量的引用,那么任何依赖于赋值结果的代码将不得不显式加载值,可能会得到另一个线程修改后的结果。
与 std::atomic_flag 使用功能有限的 clear() 函数不同,写入操作(true 、false)是通过调用 store() 来完成的。同样,test_and_set() 被更通用的 exchange() 成员函数取代,它允许用选择的新值替换存储的值,并原子地检索原始值:
cpp
std::atomic<bool> b;
bool x = b.load(std::memory_order_acquire);
b.store(true); // 存储值true到原子变量b
x = b.exchange(false, std::memory_order_acq_rel); // 将b的值交换为false,并返回原始值store() 是一个存储操作, load() 是一个加载操作。exchange() 是一个读修改写操作,但exchange() 并不是 std::atomic<bool> 支持的唯一读修改写操作。
根据当前值存储新值(或不存储):
这个新操作被称为比较交换(compare-exchange),它以 compare_exchange_weak() 和 compare_exchange_strong() 成员函数的形式存在。
它将原子变量的值与提供的期望值进行比较:
相等,则存储提供的期望值
不相等,则将预期值更新为原子变量的值
比较交换函数返回一个布尔值,如果执行了存储操作则为真(因为值相等),否则为假。
对于 compare_exchange_weak(),即使原始值等于期望值,存储操作也可能不成功,这种失败被称为伪失败(spurious failure),因此它通常必须在循环中使用。
这种情况最有可能发生在缺乏单一比较和交换指令的机器上,可能是因为执行操作的线程在必要的指令序列中间被切换出去,而操作系统在其位置安排了另一个线程。也就是两个操作中间可能会有线程操作变量,因此出现即使值相等但存储操作失败。
cpp
bool expected = false;
extern atomic<bool> b; // 在其他地方设置,可能被多个线程修改
while (!b.compare_exchange_weak(expected, true) && !expected);这里有三种情况:
- 情况1 - 首次成功:b 原来是 false,CAS 成功,compare_exchange_weak 返回 true,循环结束。
- 情况2 - 已被设置:b 已是 true,CAS 失败,且 expected 被更新为 true,!expected 为 false,循环结束。
- 情况3 - 伪失败(Spurious Failure):b 是 false 但因硬件原因 CAS 失败,expected 仍为 false,!expected 为 true,继续循环重试。
compare_exchange_strong() 保证只有在值不相等的情况下才返回 false。这可以消除像上面展示的循环的需要。如果存储值的计算很简单,使用 compare_exchange_weak() 可能是有益的,以避免在 compare_exchange_weak() 可能失败的平台上进行双重循环(compare_exchange_strong() 内部实现包含一个循环)。如果存储值很耗时,使用 compare_exchange_strong() 可能是有意义的,以避免在期望值没有变化时重新计算存储值
比较交换函数允许在成功和失败的情况下内存排序语义有所不同
成功:可能希望具有 memory_order_acq_rel 语义
失败:则具有 memory_order_relaxed 语义
失败的比较交换不会执行存储操作,因此它不能具有 memory_order_release 或 memory_order_acq_rel 语义
也不能为失败提供比成功更严格的内存排序
如果没有为失败指定排序,它被假设与成功时相同,只是释放部分被剥离:
memory_order_release 变为 memory_order_relaxed,memory_order_acq_rel 变为 memory_order_acquire。如果两者都没有指定,默认为 memory_order_seq_cst
以下两个对 compare_exchange_weak() 的调用是等效的:
cpp
std::atomic<bool> b;
bool expected;
b.compare_exchange_weak(expected, true, memory_order_acq_rel, memory_order_acquire);
b.compare_exchange_weak(expected, true,memory_order_acq_rel);//memory_order_acquire是,失败默认值,可以不写小结:失败只是读,不能release;成功才写,必须能release。失败顺序必须≤成功顺序,不指定就自动剔除release部分。
5.2.4对std::atomic<T*>:指针运算的操作
std::atomic<T*>与std::atomic<bool> 接口相同,尽管它是在相应的指针类型值上而不是布尔值上操作,具体操作有:
std::atomic的load()函数用于获取当前存储的指针值,返回类型为T*。
std::atomic的store()函数用于设置新的指针值,接受一个T*类型的参数作为新值。
std::atomic的exchange()函数用于交换当前的指针值与给定的新值,返回旧的指针值。
std::atomic<T*> 提供的新操作是指针算术操作。基本操作由 fetch_add() 和 fetch_sub() 成员函数提供,它们对存储的地址进行原子加法和减法, += 和 -= 运算符,以及递增和递减。
fetch_add() 和 fetch_sub() 返回原始值(所以 x.fetch_add(3) 会更新 x 以指向第四个值,但返回指向数组中第一个值的指针)。这个操作也称为exchange-and-add,是原子读修改写操作。
cpp
class Foo{};
Foo some_array[5];
std::atomic<Foo*> p(some_array);
Foo* x = p.fetch_add(2);//fetch_add() 用于将指针 p 增加 2,并返回旧值(指向数组的第一个元素)
assert(x == some_array);
assert(p.load() == &some_array[2]);
x = (p -= 1);//p 将指针减少 1,并返回新值(指向数组的第二个元素)。这些指针算术操作是原子的,确保在多线程环境中指针的更新是安全的
assert(x == &some_array[1]);
assert(p.load() == &some_array[1]);函数形式还允许将内存顺序语义指定为额外的函数调用参数:
cpp
p.fetch_add(3, std::memory_order_release);对于运算符形式来说,指定排序语义是不可能的,因为没有提供信息的方法:因此这些形式总是具有 memory_order_seq_cst 语义。其余的基本原子类型都是一样的:它们都是原子整数类型,并且彼此具有相同的接口。
5.2.5标准原子整型的操作
std::atomic等原子整型类型除了常规的加载、存储、交换等操作外,还提供了一系列的复合赋值操作:支持fetch_add(), fetch_sub(), fetch_and(), fetch_or(), fetch_xor()等操作,以及这些操作的复合赋值形式(+=, -=, &=, |=, ^=),命名函数原子地执行其操作并返回旧值,而复合赋值运算符返回新值。
注意:没有除法、乘法和位移运算符
对于原子整型,我们还可以执行前缀和后缀的增量和减量操作,如++x, x++, --x, x--
5.2.6 std::atomic<>类模板
允许创建自定义类型的原子类型,std::atomic<UDT> 提供与 std::atomic 相同的接口
为了对自定义类型 (UDT) 使用 std::atomic<>,这个类型必须有一个微不足道的拷贝赋值运算符。因此类型不能有虚函数或虚基类,且必须使用编译器生成的拷贝赋值运算符,自定义类型的每个基类和非静态数据成员也必须有一个微不足道的拷贝赋值运算符。这允许编译器使用 memcpy() 或等效操作进行赋值操作.
比较交换操作会进行位比较BITWISE。如果类型提供了具有不同语义的比较操作,或者类型有不参与正常比较的填充位,那么即使值比较相等,这也可能导致比较交换操作失败
数据竞争:编译器它将为所有操作使用一个内部锁。如果允许使用用户提供的拷贝赋值或比较运算符,这可能将受保护数据的引用作为参数传递给用户提供的函数(违背了第 3 章的指导方针)
死锁:如果用户的自定义操作涉及到等待其他锁或资源,而当前线程已经持有一个锁,这可能导致死锁的情况
性能问题:这些限制增加了编译器能够直接为 std::atomic<UDT> 使用原子指令(并使特定实例无锁)的机会。因为它可以将自定义类型视为一组原始字节
cpp
#include <atomic>
#include <iostream>
struct MyClass {
float value;
int flags;
MyClass(float v = 0.0f, int f = 0) : value(v), flags(f) {}//构造函数
bool operator==(const MyClass& other) const {
return value == other.value; // 忽略 flags,这里不是bitwise的比较,所以后面进行比较的时候会出问题
}
};
cpp
int main() {
std::atomic<MyClass> atomicValue;
atomicValue.store(MyClass(1.0f, 0)); // 假设这是从某处获取的旧值
MyClass oldVal(MyClass(1.0f, 1)); // 旧值,flags 为 0
MyClass newVal(MyClass(1.0f, 1)); // 新值,flags 为 1
//新旧值的flag不一样,所以比较结果应该为false
bool success = atomicValue.compare_exchange_strong(oldVal, newVal);
if (!success) {
std::cout << "compare_exchange_strong 操作失败。" << std::endl;
std::cout << "存储的值和旧的值在value上相等,但在表示形式上不相等。" << std::endl;
}
else {std::cout << "compare_exchange_strong 操作成功。" << std::endl; }
}如果自户定义类型(UDT)的大小与 int 或 void* 相同(或更小),大多数常见平台将能够为 std::atomic<UDT> 使用原子指令
一些平台还能够为用户定义类型使用原子指令,这些类型的大小是 int 或 void* 的两倍。这些平台通常支持所谓的双字比较和交换(DWCAS)指令,与 compare_exchange_xxx 函数相对应
数据结构越复杂,就越可能希望对其进行不仅仅是简单赋值和比较的操作。最好使用 std::mutex 来确保数据适用于所需的操作
5.2.7用于原子操作的非成员函数
多数情况下,非成员函数以相应的成员函数命名(将指向原子对象的指针作为第一个参数),但加上了 atomic_ 前缀(如 std::atomic_load())。在有机会指定内存排序时,有两种变体:例如 std::atomic_store(&atomic_var,new_value) 与 std::atomic_store_explicit(&atomic_var,new_value,std::memory_order_release))
cpp
int main() {
std::atomic<int> atomicVar(0); // 初始值为 0
int expected = 0; // 预期值为 0
int newValue = 1; // 我们想要设置的新值为 1
bool success;
// 使用 compare_exchange_weak_explicit 尝试更新 atomicVar 的值
// 成功时使用 memory_order_release 内存顺序,失败时使用 memory_order_relaxed
success = std::atomic_compare_exchange_weak_explicit(&atomicVar,&expected,newValue,std::memory_order_release,std::memory_order_relaxed);
if (success) {std::cout << "atomicVar的值已经成功更新为 " << newValue << std::endl;
} else {std::cout << "compare_exchange_weak操作失败。" << std::endl;}
}std::atomic_flag 上的操作在名称中明确了 flag 部分:std::atomic_flag_test_and_set(),std::atomic_flag_clear()。指定内存排序的额外变体带有 _explicit 后缀:std::atomic_flag_test_and_set_explicit() 和 std::atomic_flag_clear_explicit()。
C++ 标准库还提供了std::shared_ptr<> 实例的原子访问 。这打破了只有原子类型才支持原子操作的原则。但是,C++ 标准委员会认为提供这些额外的函数足够重要。
cpp
std::shared_ptr<my_data> p;
void process_global_data(){
std::shared_ptr<my_data> local = std::atomic_load(&p);
process_data(local);
}
void update_global_data(){
std::shared_ptr<my_data> local(new my_data);
std::atomic_store(&p, local);
}并发TS还提供了 std::experimental::atomic_shared_ptr类型。它被提供为一种单独的类型,因为这样可以允许无锁实现,不会对普通的 std::shared_ptr 实例强加额外的成本。但仍然需要检查它在平台上是否无锁,可以通过 is_lock_free 成员函数来测试。
5.3同步操作和强制顺序
假设有两个线程,其中一个线程正在填充一个数据结构,以便第二个线程读取。第一个线程设置一个标志来表示数据已经准备好,第二个线程在标志被设置之前不会读取数据。
下面代码中如果没有强制的顺序,进行非原子读写访问相同数据是未定义行为,因此为了使这行得通,必须在某个地方有强制的顺序,这里的强制排序来自于对 std::atomic<bool> 变量 data_ready 的操作;内存模型的 happens-before 和 synchronizes-with 关系提供了必要的排序。
cpp
std::vector<int> data;
std::atomic<bool> data_ready(false);
//读取数据
void reader_thread(){
while (!data_ready.load()){
std::cout << "data not ready,waiting..." << "\n";
std::this_thread::sleep_for(std::chrono::milliseconds(1));
}
std::cout << "The answer = " << data[0] << "\n"; // happens after(非原子)
}
//填充一个数据结构
void writer_thread(){
data.push_back(42); // happens before(非原子)
data_ready = true; // 原子状态值,如果是普通布尔值,会导致上面数据还没写好,这里的状态就已经true了
}
int main(){
std::thread reader(reader_thread);
std::thread writer(writer_thread);
reader.join();
writer.join();
}5.3.1 synchronize -with关系
synchronizes-with 关系基本上来自对原子类型的操作。
在适当标记的前提下(默认情况),如果线程 A 存储了一个值,而线程 B 读取了那个值,那么在线程 A 的存储和线程 B 的加载之间存在一个 synchronizes-with 关系。
5.3.2 happens-before关系
happens-before 和 strong-happens-before 指定了哪些操作可以看到其他一些操作的效果。对于单个线程,如果一个操作(A)出现在源代码中另一个操作(B)之前的语句中,那么 A 发生在 B 之前,并且 A strong-happens-before B。
下面代码中,两个操作出现在同一个语句中,通常情况下它们之间没有 happens-before 关系
程序将输出 "1,2" 或 "2,1";
使用内置的逗号运算符,或者一个表达式的结果被用作另一个表达式的参数,那么单个语句内的操作才会有序。
程序将输出 "1,2"
cpp
#include <iostream>
void foo(int a, int b){
std::cout << a << "," << b << std::endl;
}
int get_num(){
static int i = 0;
return ++i;
}
int main(){
foo(get_num(), get_num());
}线程间的 happens-before 关系相对简单,并依赖于 synchronizes-with 关系:它也是一个传递关系:如果 A 在线程间发生在 B 之前,而 B 在线程间发生在 C 之前,那么 A 在线程间发生在 C 之前。
线程间的 strong-happens-before 关系略有不同,但上述描述的两条规则适用。不同之处在于,使用 memory_order_consume 标记的操作参与线程间的 happens-before 关系的建立,但不参与 strong-happens-before 关系。
原子读取操作使用 memory_order_consume 标记,表示该操作依赖于之前某个特定写入的结果。这种依赖关系建立了一个线程间的 happens-before 关系,即写入操作 happens-before 读取操作;但这种可见性并不像其他内存排序选项那样强,只确保了读取操作能够观察到特定写入操作的影响,但不确保所有后续操作都受到先前写入操作的约束。
简单理解:
- happens-before 就像「可靠八卦」
想象三个线程 A、B、C 在聊天:
A 对 B 说:"我先把数据写好了,你去看吧"
B 看到数据后,转头对 C 说:"A 的数据我看见了,没问题"
结论:A 的消息必然能传到 C,这就是传递性:A→B 且 B→C,则 A→C。
技术含义:如果操作 A 在操作 B 之前发生,且 B 在 C 之前发生,那 A 的结果对 C 一定可见。 - strong-happens-before 就是「更严格的八卦」
大部分内存序(如 memory_order_acquire/release)都遵循上述规则,但 memory_order_consume 是个例外。
想象 A 对 B 说悄悄话,但只说了一半:
"这个数据你拿去用,但别告诉 C 是我说的"
技术含义:consume 只保证直接依赖这个数据的操作能看到写入,不保证其他无关操作也受顺序约束。
5.3.3原子操作的内存排序
六种排序选项,代表了三种模型:
- 顺序一致性排序(memory_order_seq_cst)
- 获取-释放排序(memory_order_consume、memory_order_acquire、memory_order_release 和 memory_order_acq_rel)
- 宽松排序(memory_order_relaxed)
这些不同的内存排序模型在不同的 CPU 架构上可能有不同的成本。
顺序一致性排序
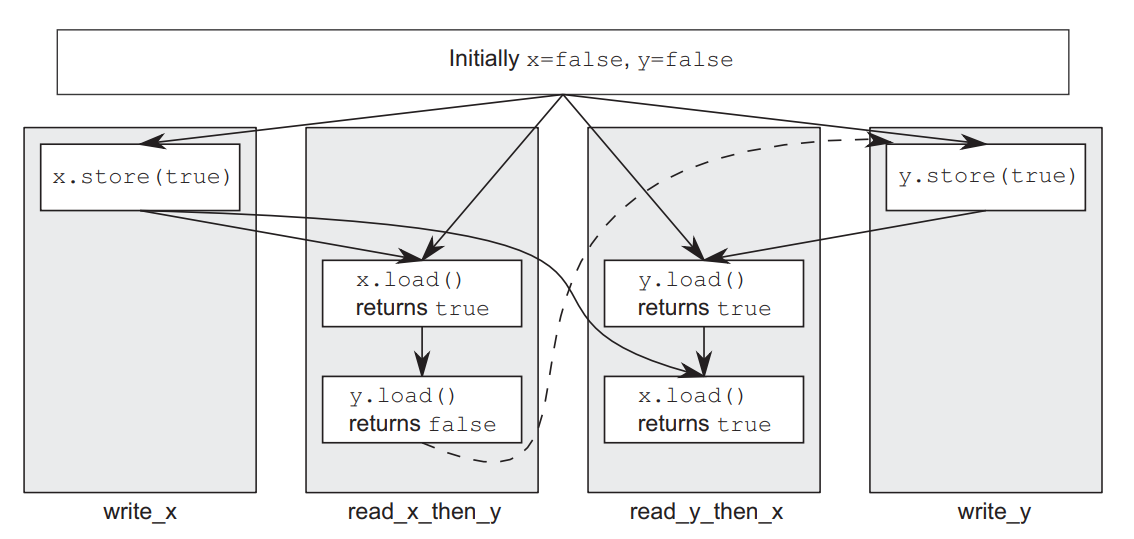
先看最严格的顺序一致性排序,就好像所有这些操作都是由单个线程按某种特定顺序执行的:所有线程必须看到相同的操作顺序。操作不能被重新排序;这种排序最简单,最容易理解,但性能开销最大。
cpp
std::atomic<bool> x, y;
std::atomic<int> z;
void write_x(){
x.store(true, std::memory_order_seq_cst);
}
void write_y(){
y.store(true, std::memory_order_seq_cst);
}
void read_x_then_y(){
while (!x.load(std::memory_order_seq_cst));
if (y.load(std::memory_order_seq_cst))
++z;
}
void read_y_then_x(){
while (!y.load(std::memory_order_seq_cst));
if (x.load(std::memory_order_seq_cst))
++z;
}
int main(){
x = false;
y = false;
z = 0;
std::thread a(write_x);
std::thread b(write_y);
std::thread c(read_x_then_y);
std::thread d(read_y_then_x);
a.join();b.join();c.join();d.join();
assert(z.load() != 0); // 安全!z是1,或2
}所有线程对于以上代码可能看到两种情况:
1.先加载x,再加载y;
2.先加载y,再加载x。
由于使用过的memory_order_seq_cst一致性,因此只会都看到以上两种情况之一。
场景设定
x 和 y 是两个信号灯,初始都是灭的
c 和 d 是两个选手,分别盯着不同的灯
cpp
选手 c:盯着 x 灯,x 一亮马上看 y 灯,如果 y 也亮了就按 +1 按钮
选手 d:盯着 y 灯,y 一亮马上看 x 灯,如果 x 也亮了就按 +1 按钮- 为什么 z 可能是 2?
时间线:x灯亮 → y灯亮 → c看到x亮 → c看到y亮(z=1) → d看到y亮 → d看到x亮(z=2)
两个选手都完美时机地看到了两个灯全亮,各按一次按钮。 - 为什么 z 可能是 1?
时间线:x灯亮 → c看到x亮 → c看y灯(还没亮,放弃) → y灯亮 → d看到y亮 → d看到x亮(z=1)
关键细节:c 在看到 x 亮后,检查 y 的那一瞬间 y 还没亮,所以 c 放弃了。但之后 d 看到两个灯都亮了,按了按钮。
反过来也可能:
y灯亮 → d看到y亮 → d看x灯(还没亮,放弃) → x灯亮 → c看到x亮 → c看到y亮(z=1) - 为何不会 z=0?
因为 seq_cst 保证灯亮之后一定会被人看见。最坏的情况是一个选手反应太快错过了,但另一个选手一定能看到两个灯都亮。
下图显示了:x灯亮 → c看到x亮 → c看y灯(还没亮,放弃) → y灯亮 → d看到y亮 → d看到x亮(z=1)的情况。
非顺序一致性
下面看非顺序一致性的内存排序:
不再有单一全局的事件顺序。这意味着不同线程可能会看到相同操作的不同视图。而且线程之间不必就事件的顺序达成一致。因为不同的CPU缓存和内部缓冲区可以为同一内存持有不同的值;
在没有其他排序约束的情况下,唯一的要求是所有线程对每个独立变量的修改顺序达成一致。对不同变量的操作可以在不同线程上出现不同的顺序。
宽松排序
使用宽松排序执行的原子类型操作不会参与到synchronizes-with关系中
唯一的要求是同一线程对单个原子变量的访问不能被重排序
在没有任何额外同步的情况下,每个变量的修改顺序是使用memory_order_relaxed的线程之间唯一共享的东西
cpp
std::atomic<bool> x, y;
std::atomic<int> z;
void write_x_then_y(){
x.store(true, std::memory_order_relaxed);
y.store(true, std::memory_order_relaxed);
}
void read_y_then_x(){
while (!y.load(std::memory_order_relaxed));
if (x.load(std::memory_order_relaxed)) ++z;
}
int main(){
x = false;y = false;z = 0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();b.join();
assert(z.load() != 0); //z可能为0
}上面代码中变量x和y是不同的,因此对于每个变量上操作产生的值的可见性没有任何顺序保证。relaxed 内存序不保证跨线程的操作顺序可见性。它只保证原子性(操作不可分割)和修改顺序一致性(单个变量的修改历史在所有线程看起来一致),但不建立线程间的 happens-before / synchronizes-with 关系。
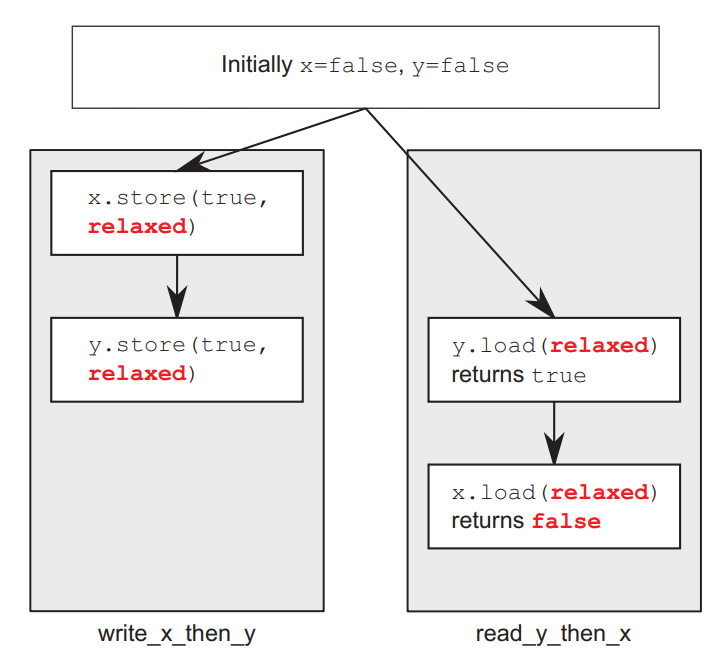
如上图所示,各自线程中的函数有先后关系,但线程之间没有 synchronizes-with 关系,因此read_y_then_x可能看到y.store(true, relaxed)在x.store(true, relaxed)前面。
再看一个复杂点的例子:
cpp
std::atomic<int> x(0), y(0), z(0);
std::atomic<bool> go(false);
unsigned const loop_count = 10;
struct read_values{int x, y, z;};
read_values values1[loop_count];
read_values values2[loop_count];
read_values values3[loop_count];
read_values values4[loop_count];
read_values values5[loop_count];
void increment(std::atomic<int>* var_to_inc, read_values* values){
while (!go) std::this_thread::yield();
for (unsigned i = 0; i < loop_count; ++i){
values[i].x = x.load(std::memory_order_relaxed);
values[i].y = y.load(std::memory_order_relaxed);
values[i].z = z.load(std::memory_order_relaxed);
var_to_inc->store(i + 1, std::memory_order_relaxed);
std::this_thread::yield();
}
}
cpp
void read_vals(read_values* values){
while (!go) std::this_thread::yield();
for (unsigned i = 0; i < loop_count; ++i){
values[i].x = x.load(std::memory_order_relaxed);
values[i].y = y.load(std::memory_order_relaxed);
values[i].z = z.load(std::memory_order_relaxed);
std::this_thread::yield();
}
}
void print(read_values* v){
for (unsigned i = 0; i < loop_count; ++i){
if (i) std::cout << ",";
std::cout << "(" << v[i].x << "," << v[i].y << "," << v[i].z << ")";
}
std::cout << std::endl;
}
int main(){
std::thread t1(increment, &x, values1);
std::thread t2(increment, &y, values2);
std::thread t3(increment, &z, values3);
std::thread t4(read_vals, values4);
std::thread t5(read_vals, values5);
go = true; t5.join();t4.join();t3.join();t2.join();t1.join();
print(values1);print(values2);print(values3);print(values4);print(values5);
}
| 现象 | 说明 |
|---|---|
| 单变量递增序列正确 | 每个变量自身的store(i+1)遵循修改顺序一致性 |
| 跨变量完全无序 | x、y、z的可见性互相独立,没有全局时间戳 |
| 读线程看到"部分更新" | t4先看到x更新,过一会儿才看到y/z更新 |
| 值跳跃 | 线程可能突然看到其他线程的所有历史写入(最终值) |
yield() ≠ 内存屏障 |
线程调度不影响缓存一致性 |
理解宽松排序
想象每个原子变量都是一个小隔间里的人,手里拿着一个记事本。在他的记事本上是一系列值。可以打电话给他,要求他给你一个值,或者可以告诉他写下一个新的值。如果告诉他写下一个新值,他会把它写在列表的最底部。
假设他的列表一开始是5, 10, 23, 3, 1, 和 2。如果向他要一个值,可能会得到其中任何一个。如果是10,下一次问他要时,他可能会再次给出10,或者后面的任何一个值,但不会是5。如果你告诉他写下42,他会把它加到列表的末尾。如果再次向他要一个数字,他会一直给出"42",直到他的列表上有另一个数字。
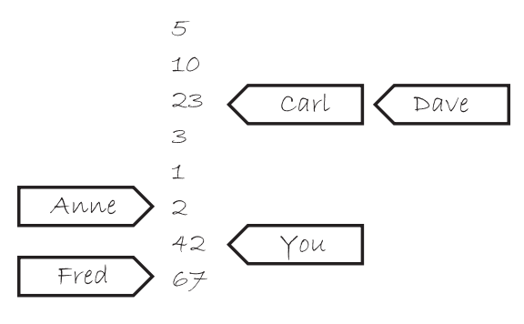
如果有很多这样的男士(原子变量),手里都有电话和记事本。每个原子变量都有自己的修改顺序(记事本上的值列表),但它们之间没有任何关系。如果每个打电话的人(你、Carl、...)都是一个线程,这就是使用memory_order_relaxed进行操作时的情况。
也就是memory_order_relaxed会维持原子变量修改顺序(不会往后,新增的在列表最后),但每个线程看到的值可能不一样。任何时刻都只能有一个人打通电话对值进行修改。
宽松排序很少使用,因为其限制太少,下面来看一种折中的方案。
获取-释放排序
仍然没有总体顺序,但引入了一些同步。
原子加载(load)是获取操作(memory_order_acquire)
原子存储(store)是释放操作(memory_order_release)
以上两个操作是成对出现的,他们之间的协调很有限,只能保证执行acquire的时候能看到release之前发生的事情,但不能保证acquire发生的时候,release已经发生了。在代码中仍需要用while循环进行确认。
原子读-修改-写操作(如fetch_add()或exchange())可以是获取、释放或两者兼有(memory_order_acq_rel)
一个释放操作与读取所写值的获取操作存在synchronizes-with关系
不同线程仍然可以看到不同的顺序,但这些顺序是受限的
重写之前的代码:
cpp
std::atomic<bool> x, y;
std::atomic<int> z;
void write_x(){ x.store(true, std::memory_order_release); }
void write_y(){ y.store(true, std::memory_order_release); }
void read_x_then_y(){
while (!x.load(std::memory_order_acquire));
if (y.load(std::memory_order_acquire)) ++z;
}
void read_y_then_x(){
while (!y.load(std::memory_order_acquire));
if (x.load(std::memory_order_acquire)) ++z;
}
cpp
int main()
{
x = false;
y = false;
z = 0;
//启动两个线程一个写x一个写y
std::thread a(write_x);
std::thread b(write_y);
//该线程先读x再读y
std::thread c(read_x_then_y);
//该线程先读y再读x
std::thread d(read_y_then_x);
a.join();
b.join();
c.join();
d.join();
assert(z.load() != 0); //危险
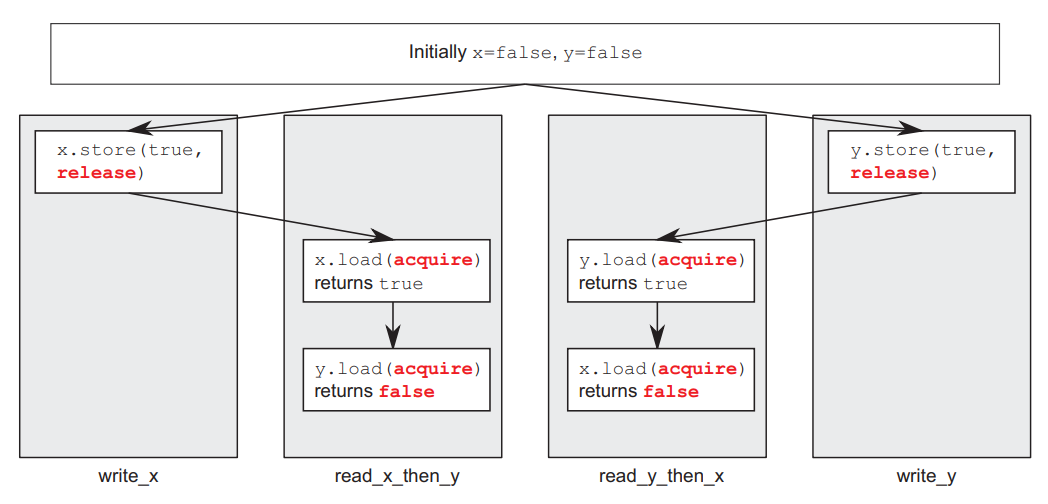
}以上代码只能保证单个变量x或y在release前可以看到各自store的值,但是不能保证x和y写的顺序。如下图所示,程序只能保证x.store(true, std::memory_order_release);到x.load(std::memory_order_acquire)这个部分return true,但可能这个时候y还没有load,因此会返回false。
为了发挥获取-释放排序的好处,需要考虑同一个线程中的两个存储操作,也就是把x和y的store操作放到一个线程里面:
cpp
std::atomic<bool> x, y;
std::atomic<int> z;
void write_x_then_y(){
x.store(true, std::memory_order_relaxed);
y.store(true, std::memory_order_release);
}
void read_y_then_x(){
while (!y.load(std::memory_order_acquire));//这里不能替换为if
if (x.load(std::memory_order_relaxed))
++z;
}
int main(){
x = false;y = false;
z = 0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();b.join();
assert(z.load() != 0); // 安全
}具体原理如下图:
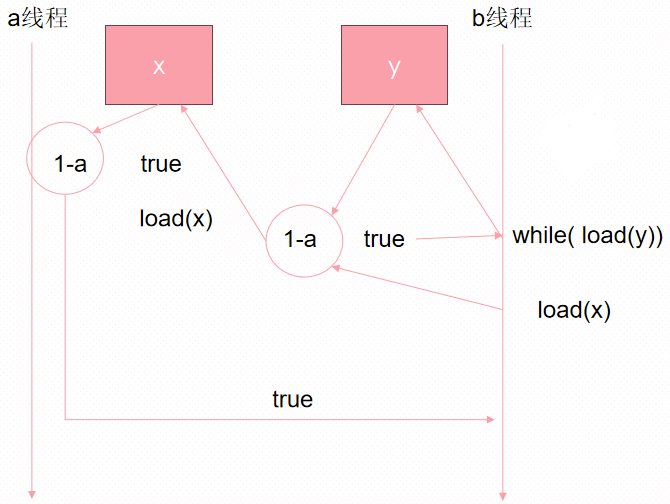
线程a正在运行write_x_then_y,并对隔间x的人说:"请在批次1中代表线程a写入true"
接着线程a又对隔间y的人说:"请在批次1中代表线程a写入true作为最后的写入"
与此同时,线程b正在运行read_y_then_x。线程b一直向隔间y的男士询问带有批次信息的值,直到他说"true"(并得到写入的线程和批次信息)
线程b继续向隔间x的男士询问一个值,但这次他说:"请给我一个值,顺便说一下,我知道线程a的批次1。"
现在隔间x的男士必须查看他的列表,寻找线程a在批次1中的最后记录
通过获取-释放排序实现传递同步
以下代码准备了三个线程:
cpp
std::atomic<int> data[5];
std::atomic<bool> sync1(false), sync2(false);
void thread_1(){
data[0].store(42, std::memory_order_relaxed);
data[1].store(97, std::memory_order_relaxed);
data[2].store(17, std::memory_order_relaxed);
data[3].store(-141, std::memory_order_relaxed);
data[4].store(2003, std::memory_order_relaxed);
sync1.store(true, std::memory_order_release); // 1
}
void thread_2(){
while (!sync1.load(std::memory_order_acquire)); // 2
sync2.store(true, std::memory_order_release); // 3
}
void thread_3(){
while (!sync2.load(std::memory_order_acquire)); // 4
assert(data[0].load(std::memory_order_relaxed) == 42);
assert(data[1].load(std::memory_order_relaxed) == 97);
assert(data[2].load(std::memory_order_relaxed) == 17);
assert(data[3].load(std::memory_order_relaxed) == -141);
assert(data[4].load(std::memory_order_relaxed) == 2003);
}第一个线程修改一些共享变量,并对其中一个做存储-释放操作
第二个线程随后通过加载-获取操作读取受存储-释放操作影响的变量,并对这个变量执行存储-释放操作
第三个线程对这个第二个共享变量执行加载-获取操作。只要加载-获取操作能看到存储-释放操作写入的值,以确保存在synchronizes-with关系。这个第三个线程就能读取第一个线程存储的其他变量的值,即使中间的线程没有触碰它们中的任何一个
代码中标记了执行顺序1-4。
在这种情况下,可以通过在thread_2中使用带有memory_order_acq_rel的读-修改-写操作,将sync1和sync2合并成一个单一的变量。一个选择是使用compare_exchange_strong()来确保只有在看到来自thread_1的存储操作后,值才会被更新。就是吧把上面代码中的2-3两个操作合并为一个。
cpp
std::atomic<int> sync(0);
void thread_1(){
// ...
sync.store(1, std::memory_order_release);
}
void thread_2(){
int expected = 1;
while (!sync.compare_exchange_strong(expected, 2, std::memory_order_acq_rel))
expected = 1;
}
void thread_3(){
while (sync.load(std::memory_order_acquire) < 2);
// ...
}通俗地说,这两段代码都是在解决"三个线程如何排队传递信息"的问题,但用了不同的"暗号系统"。
原代码的思路:接力赛
想象三个选手(线程)传递接力棒:
线程1 写完数据后,把 sync1 这个旗子升起(release),表示"我跑完了"
线程2 瞪大眼睛等着 sync1 旗子(acquire),一看见就升起 sync2 旗子(release),表示"交接完成"
线程3 等着 sync2 旗子(acquire),一看见就开始读数据
关键:sync1 和 sync2 是两个独立的布尔变量,形成了一个传话链条:1→2→3
新代码的思路:状态计数器
现在改用一个整数 sync 当"进度条":
初始状态:0(还没开始)
线程1 写完后,把进度条设为 1(release),表示"阶段一完成"
线程2 用 CAS(比较并交换) 做一个特殊操作:只有当进度条是1时,才把它改成2
这个 CAS 用了 acq_rel(获取并释放)语义,相当于一手接棒,一手传棒
acquire 部分:确认看到线程1的"1"(保证线程1的写入对我可见)
release 部分:把"2"写进去(保证线程3能看到我的修改)
线程3 等着进度条变成 2(acquire),一旦读到≥2,就知道前两棒都跑完了,可以安心读数据
使用获取-释放排序和memory_order_consume进行数据依赖
memory_order_consume很特殊:它为线程间先行发生关系引入了数据依赖性的细微差别,C++17标准明确建议不要使用它,所以前面都没有涉及它。
如果consume操作(B)读取了由存储操作(A)存储的值,并且存储操作(A)带有memory_order_release、memory_order_acq_rel或memory_order_seq_cst标签,并且加载操作(B)带有memory_order_consume标签,那么这个存储操作(A)在依赖排序上先于加载操作(B)
在原子操作加载指向某些数据的指针时。通过在加载时使用memory_order_consume,在之前的存储上使用memory_order_release,可以确保所指向的数据正确同步
cpp
struct X {
int i;
std::string s;
};
std::atomic<X*> p;
std::atomic<int> a;
void create_x() {
X* x = new X;
x->i = 42;
x->s = "hello";
a.store(99, std::memory_order_relaxed); //不引入同步约束。因此在p.load的时候不一定能看见a.store
p.store(x, std::memory_order_release); //后续的load操作将看到此次修改
}
void use_x() {
X* x;
while (!(x = p.load(std::memory_order_consume))) {
std::this_thread::sleep(std::chrono::microseconds(1));
}
assert(x->i == 42); // 安全
assert(x->s == "hello"); // 安全
assert(a.load(std::memory_order_relaxed) == 99); // 危险
}
int main() {
std::thread t1(create_x);
std::thread t2(use_x);
t1.join(); t2.join();
}可以使用std::kill_dependency()来显式地打破依赖链。std::kill_dependency()是一个函数模板,将提供的参数拷贝到返回值中,但在这样做的过程中打破了依赖链。
cpp
int global_data[]={ ... };
std::atomic<int> index;
void f(){
int i=index.load(std::memory_order_consume);
do_something_with(global_data[std::kill_dependency(i)]);//告诉编译器它不需要重新读取数组条目的内容,可以释放i了
}std::memory_order_acquire提供了一种更通用的同步保证,适用于大多数同步场景,而std::memory_order_consume则是一种更特殊的内存顺序,它在特定的数据依赖场景下可以提供优化,但需要开发者更加小心地使用以确保正确性和性能。(不建议用consume)
5.3.4释放序列和同步
如果存储操作被标记为memory_order_release、memory_order_acq_rel或memory_order_seq_cst,加载操作被标记为memory_order_consume、memory_order_acquire或memory_order_seq_cst,并且链中的每个操作都加载了前一个操作写入的值,那么这一连串的操作构成了一个释放序列(有约束)。链中的任何原子读-修改-写操作都可以有任何内存排序(甚至是memory_order_relaxed)
释放序列就是一个"松散的传话链条":
开头必须大声喊(release)
中间可以小声嘀咕(relaxed RMW),只要话传到就行
结尾必须认真听(acquire)
只要满足这个链条,即使中间人很随意,最后一个听话的人也能保证听到第一句话的所有内容。
cpp
std::vector<int> queue_data;//需要保护的共享数据
std::atomic<int> count;//使用atomic<int>来作为共享队列中项目数量的计数器
void populate_queue(){
unsigned const number_of_items = 20;
queue_data.clear();
for (unsigned i = 0; i < number_of_items; ++i){//往queue_data装20个数据
queue_data.push_back(i);
}
count.store(number_of_items, std::memory_order_release);
}
void consume_queue_items(){
while (true){
int item_index;
//希望能同步,上面装完20个数据后才进行操作
if((item_index=count.fetch_sub(1,std::memory_order_acquire))<=0)
{
wait_for_more_items();
continue;
}
process(queue_data[item_index - 1]);
}
}int main(){
std::thread a(populate_queue);
std::thread b(consume_queue_items);
std::thread c(consume_queue_items);
a.join();b.join();c.join();
}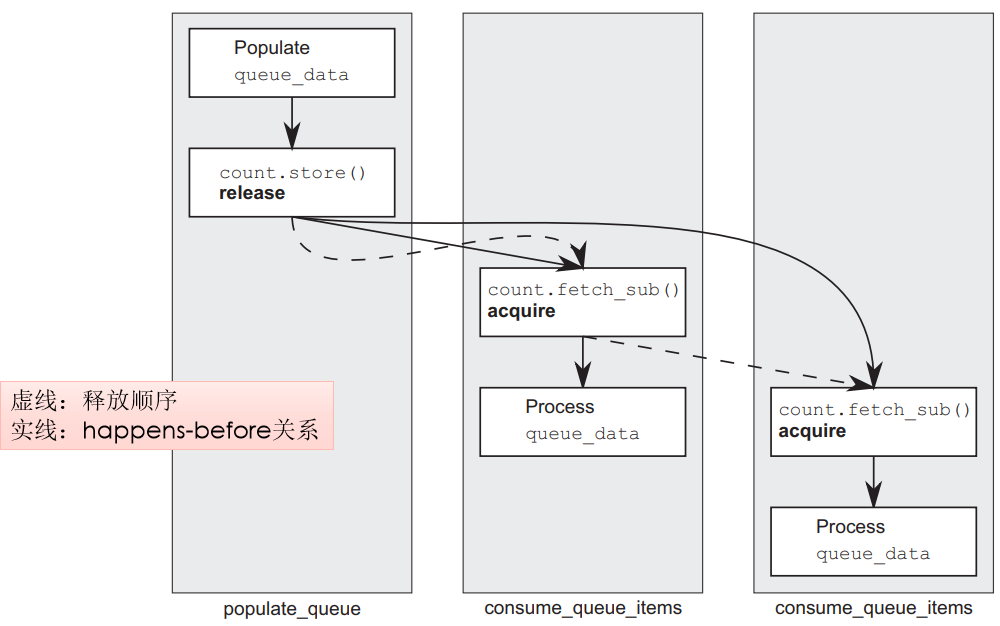
结合图片,可以用一个仓库取货的类比来解释:
- 场景设定
queue_data:仓库里的20个货物(索引0-19)
count:门口电子屏显示"剩余货物数量"(原子计数器)
线程A:送货员(populate)
线程B、C:两个取货员(consume),同时抢货 - 关键操作解析
1.送货员A的工作(左侧populate_queue)
关键点:release 就像打开仓库大门+拉响广播,确保装货动作一定发生在开门之前(代码顺序即执行顺序的保证)
图片中:从 store 画出的实线箭头指向两个消费者的 fetch_sub,表示"happens-before"关系
2.取货员B和C的工作(中间和右侧)
这里的 fetch_sub 是原子的"看-改-写"三步合一:
看:读到当前剩余数量(比如20)
改:内部改成19(但返回给我的是20)
写:把19写回屏幕
item_index - 1 是因为返回的是"第几个",而数组索引从0开始(拿到20对应索引19,即最后一个元素)。 - 图片中的线条含义
实线(happens-before):严格的先后顺序
A装完货 → A更新计数器 → B/C看到计数器 → B/C处理数据
这保证了B和C处理数据时,一定能看到A写入的完整20个数据
虚线(释放顺序):图片中的关键
从A的 store 到B的 fetch_sub 有一条虚线
从B的 fetch_sub 到C的 fetch_sub 也有一条虚线
这表示它们构成了"释放序列"(Release Sequence)
5.3.5栅栏(Fences)
强制执行内存排序约束,而不修改任何数据,通常与使用memory_order_relaxed排序约束的原子操作结合使用。栅栏是全局操作,影响执行栅栏的线程中其他原子操作的顺序。栅栏也通常被称为内存屏障。栅栏限制了宽松操作被重新排序的可能,并引入了新的happens-before和synchronizes-with关系。
如果一个acquire操作看到一个发生在release栅栏之后的存储操作的结果,那么该栅栏将与该获取操作同步;并且,如果一个发生在acquire栅栏之前的加载操作看到了一个release操作的结果,那么该释放操作将与获取栅栏同步。
cpp
std::atomic<bool> x, y;
std::atomic<int> z;
void write_x_then_y(){
x.store(true, std::memory_order_relaxed);
std::atomic_thread_fence(std::memory_order_release);
y.store(true, std::memory_order_relaxed);
}
void read_y_then_x(){
while (!y.load(std::memory_order_relaxed));
std::atomic_thread_fence(std::memory_order_acquire);
if (x.load(std::memory_order_relaxed))
++z;
}
int main(){
x = false;y = false;
z = 0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();b.join();
assert(z.load() != 0);
}栅栏是"无形的墙",它:
不传输数据(不像store/load那样传递值)
只约束顺序(像交通警察,不让车辆乱变道)
成对使用。
| 栅栏类型 | 作用 | 形象比喻 |
|---|---|---|
| Release Fence | 挡住前面的操作,不让它们跑到栅栏后面 | 快递封箱胶带:"箱内物品已齐,封后不再添加" |
| Acquire Fence | 挡住后面的操作,不让它们跑到栅栏前面 | 海关检查站:"先过安检,再看护照" |
以上代码通俗比喻:快递签收
想象两个线程在玩"你拍一我拍一"的远程游戏,但中间隔着一条可能乱序传送物品的魔法通道:
线程A(发货方)的动作:
cpp
x.store(true, relaxed); // ① 把信塞进邮筒(可能还在邮局排队)
std::atomic_thread_fence(release); // ② 🔒release栅栏:封门!
// 作用:确保①的信已经上路,绝对不会跑到③后面
y.store(true, relaxed); // ③ 发电报通知"货已发出"线程B(收货方)的动作:
cpp
while (!y.load(relaxed)); // ④ 不断查电报(可能收到乱序的 earlier 消息)
std::atomic_thread_fence(acquire); // ⑤ 🔓acquire栅栏:拆门!
// 作用:确保⑥的读操作不会被提前到④之前
if (x.load(relaxed)) // ⑥ 去邮筒取信
++z;为什么assert不会失败(z一定不为0)?
如果B看到了电报(y==true),说明B的④看到了A的③
根据规则:acquire操作(④)看到了release栅栏(②)之后的存储(③)→ 栅栏与获取同步
这就像"签收确认":一旦B确认收到了电报(③),邮政系统就保证B一定能看到之前寄出的信(①)
因此x.load()一定能看到x.store(true),z自增,assert通过
如果修改代码顺序
cpp
void write_x_then_y(){
std::atomic_thread_fence(std::memory_order_release);
x.store(true, std::memory_order_relaxed);
y.store(true, std::memory_order_relaxed);
}效果:胶带①前面空空如也,后面跟着信②和电报③。CPU一看:胶带前面没东西要保护,后面这两兄弟(②和③)都是 relaxed,随便排吧!于是信和电报可能乱序发出。
cpp
std::atomic_thread_fence(release); // ① 封箱胶带(但前面是空的!)
x.store(true, relaxed); // ② 把信塞进邮筒
y.store(true, relaxed); // ③ 发电报5.3.6 用原子操作对非原子操作进行排序
如果将上节代码中的x替换为一个普通的非原子型bool,行为将保证是相同的
cpp
bool x = false; // 非atomic
std::atomic<bool> y;
void write_x_then_y(){
x = true; // fence前
std::atomic_thread_fence(std::memory_order_release);
y.store(true, std::memory_order_relaxed); //fence后
}
void read_y_then_x(){
while (!y.load(std::memory_order_relaxed));
std::atomic_thread_fence(std::memory_order_acquire);
if (x) ++z; //fence后
}
int main(){
x = false;y = false;
z = 0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();b.join();
assert(z.load() != 0);
}5.3.7对非原子操作排序
如果一个非原子操作在原子操作之前,并且那个原子操作在另一个线程中的操作之前发生,那么非原子操作也在另一个线程中的那项操作之前发生。这也是C++标准库中更高层同步设施(如互斥锁和条件变量)的基础
cpp
class spinlock_mutex{
private:
std::atomic_flag flag; // 原子标志用于表示锁的状态
public:
// 构造函数初始化标志位为未设置(clear)状态,表示锁未被占用
spinlock_mutex() : flag(ATOMIC_FLAG_INIT) {}
void lock(){// 尝试获取锁,如果锁已被占用,则忙等待(spin-wait)直到锁可用
while (flag.test_and_set(std::memory_order_acquire)); // 如果成功设置(旧值false),表示锁成功;返回 true 表示锁已被其他线程占用,当前线程需要继续循环尝试
}
void unlock(){// 释放锁,将标志位清除,表示锁现在可用
flag.clear(std::memory_order_release);
}
};