负荷预测综述🚀
这种先看了两篇综述,一个是风电功率预测的一个是光伏的,然后供给侧看完了,接下来看需求侧的,直接看负荷预测,最后写一个高比例可再生能源调度相关的综述论文,写综述之前先了解一下情况,每个领域的,然后再涉及框架,然后再搜论文这样。这次看的是一篇英国和土耳其作者合作的综述论文。
读后感:感觉其实也就是一篇普通的综述中规中矩,没有什么特别亮眼的优点,结构我觉得也不是非常清晰,一般吧,入门了解了解背景是ok的。
文章目录
- 负荷预测综述🚀
- 题目
- 摘要
-
- [1. 引言](#1. 引言)
- [2. 方法论](#2. 方法论)
- [3. 电力消耗的负荷预测(LF)](#3. 电力消耗的负荷预测(LF))
- [4. 基于不同数据集的深度学习短期负荷预测(DL-based STLF)](#4. 基于不同数据集的深度学习短期负荷预测(DL-based STLF))
- [5. 基于深度学习的 STLF 问题常用技术](#5. 基于深度学习的 STLF 问题常用技术)
-
- [5.1. 循环神经网络(RNNs)](#5.1. 循环神经网络(RNNs))
- [5.2. LSTM 网络](#5.2. LSTM 网络)
- [5.3. GRU 网络](#5.3. GRU 网络)
- [5.4. 卷积神经网络(CNNs)](#5.4. 卷积神经网络(CNNs))
- [5.5. 自动编码器(Autoencoders)](#5.5. 自动编码器(Autoencoders))
- [6. 在线负荷预测模型](#6. 在线负荷预测模型)
- [7. 不确定性感知负荷预测模型](#7. 不确定性感知负荷预测模型)
- [8. 基于深度学习的 STLF 研究的实践依据](#8. 基于深度学习的 STLF 研究的实践依据)
- [9. 讨论、进一步建议与局限性](#9. 讨论、进一步建议与局限性)
-
- [9.1. 深度学习模型中的灵敏度](#9.1. 深度学习模型中的灵敏度)
- [9.2. 处理深度学习模型中的不确定性](#9.2. 处理深度学习模型中的不确定性)
- [9.3. 利用多智能体系统和物联网创新 STLF](#9.3. 利用多智能体系统和物联网创新 STLF)
- [9.4. 用于增强分析的数据集均匀性](#9.4. 用于增强分析的数据集均匀性)
- [9.5. 整合可再生能源与进化算法](#9.5. 整合可再生能源与进化算法)
- [9.6. 为能源决策者提供准确的 STLF 见解](#9.6. 为能源决策者提供准确的 STLF 见解)
- [10. 结论](#10. 结论)
https://www.sciencedirect.com/science/article/pii/S1364032123008894

题目
- A comprehensive review on deep learning approaches for short-term load forecasting
短期负荷预测中深度学习方法的全面综述
摘要
-
The balance between supplied and demanded power is a crucial issue in the economic dispatching of electricity energy.
供需电力之间的平衡是电能经济调度的关键问题。 -
With the emergence of renewable sources and data-driven approaches, demand-side or demand response (DR) programs have been applied to maintain this balance as accurately as possible.
随着可再生能源和数据驱动方法的出现,需求侧或需求响应(DR)项目已被应用于尽可能准确地维持这种平衡。 -
Short-term load forecasting (STLF) has a decisive impact on the success, sustainability, and performance of those programs.
短期负荷预测(STLF)对这些项目的成功、可持续性和绩效具有决定性影响。 -
Forecasting customers' consumption over short or long time horizons allows distribution companies to establish new policies or modify strategies in terms of energy management, infrastructure planning, and budgeting.
对客户在短期或长期时间范围内的消耗进行预测,使配电公司能够制定新政策,或在能源管理、基础设施规划和预算方面修改策略。 -
Deep learning (DL)-based approaches for STLF have been referenced for a long time, considering factors such as accuracy, various performance measures, volatility, and adverse effects of uncertainties in load demand.
考虑到准确性、各种性能衡量标准、波动性以及负荷需求中不确定性的不利影响,基于深度学习(DL)的 STLF 方法长期以来一直被引用。 -
Hence, in this review, DL-based studies for the STLF problem have been considered.
因此,在本综述中,考虑了针对 STLF 问题的基于深度学习的研究。 -
The studies have been classified by several titles, such as the provided method and main ideas, dataset specifications, uncertain-aware approaches, online solutions, and practical extensions to DR programs.
这些研究已按多个标题进行分类,例如所提供的方法和主要思想、数据集规范、不确定性感知方法、在线解决方案以及对 DR 项目的实际扩展。 -
The main contribution of this review is the ongoing exploration of STLF with DL models to reveal the research direction of the load forecasting problem in terms of the future-oriented integration of the key concepts of online, robustness, and feasibility.
本综述的主要贡献是持续探索使用深度学习模型进行短期负荷预测,以揭示负荷预测问题在在线、鲁棒性和可行性等关键概念的面向未来集成方面的研究方向。
1. 引言
-
The pursuit of economical, efficient, reliable, and safe energy sources integrated into autonomous heterogeneous power grids has led to the development of the smart grid (SG) concept.
对集成到自主异构电网中的经济、高效、可靠且安全能源的追求,促使了智能电网(SG)概念的发展。 -
This concept provides a versatile platform for implementing intelligent solutions from various perspectives, including human-centric approaches, technological compliance, technical harmony, and environmental friendliness.
这一概念为从多角度实施智能解决方案提供了一个多功能平台,包括以人为本的方法、技术合规性、技术和谐性以及环境友好性。 -
The distribution networks have become increasingly decentralised due to the rapid and growing penetration of microgrid networks powered by renewables.
由于可再生能源驱动的微网网络迅速且日益增长的渗透,配电网络已变得越来越去中心化。 -
The digital revolution has introduced new technologies into our daily lives, shaping and influencing our preferences and individual standards.
数字革命将新技术引入我们的日常生活,塑造并影响着我们的偏好和个人标准。 -
In this context, electricity consumption data of residents has become a crucial tool for managing and regulating SG networks through demand response (DR) programs.
在此背景下,居民用电数据已成为通过需求响应(DR)计划管理和调节智能电网的关键工具。 -
DR refers to the strategies employed in the electricity market to manage and balance the supply and demand of electricity during different periods, including real-time 1.
需求响应(DR)是指电力市场中用于管理和平衡不同时段(包括实时)电力供需的策略 1。 -
Based on each consumption profile, DR includes policies to encourage consumers to voluntarily reduce or shift their electricity consumption during specified periods.
基于每种消耗概况,需求响应包括鼓励消费者在指定时段自愿减少或转移用电量的政策。 -
However, the full deployment of data-meter devices and their maintenance and online operation can be costly or unfeasible.
然而,数据计量设备的全面部署及其维护和在线运行可能成本高昂或难以实现。 -
Accurate residential load forecasting (LF) has, therefore, become a popular research topic for both small and large-scale DR programs.
因此,准确的住宅负荷预测(LF)已成为小型和大型需求响应计划的热门研究课题。 -
LF can be divided into two main categories based on the time horizon of the data.
根据数据的时间跨度,负荷预测可分为两大类。 -
Short-term load forecasting (STLF) involves predicting electricity demand in the relatively short-term, typically a few minutes, hours, or days ahead, while long-term LF relates to predictions up to 20 years ahead 2.
短期负荷预测(STLF)涉及对相对短期内(通常为未来几分钟、几小时或几天)电力需求的预测,而长期负荷预测则涉及长达 20 年的预测 2。 -
LF minimises the risk of energy supply and demand imbalances.
负荷预测(LF)最大限度地降低了能源供需失衡的风险。 -
With the help of LF, a feasible and reliable energy management framework can be established with DR and demand-side programs.
借助负荷预测,可以结合需求响应和需求侧项目建立一个可行且可靠的能源管理框架。 -
Such a decision-making framework offers advantages for both power suppliers and end-users while aligning with government commitments and regulations.
这种决策框架在符合政府承诺和监管要求的同时,为供电商和终端用户都带来了优势。 -
Therefore, LF plays a significant role in the implementation of each micro decision-making-based component of the SG.
因此,负荷预测在智能电网中每个基于微观决策的组件实施中起着重要作用。 -
The primary challenge in achieving accurate LF results is the complexity of grid operations.
实现准确负荷预测(LF)结果的主要挑战在于电网运行的复杂性。 -
Various factors, including user preferences, variations in the quality and quantity of appliance types, the prevalence of renewables, and fluctuating prices, contribute to this complexity.
各种因素,包括用户偏好、电器类型质量和数量的变化、可再生能源的普及以及价格波动,都导致了这种复杂性。 -
Among these factors, fluctuations in prices and supplied power from alternative sources are particularly significant.
在这些因素中,价格波动和替代能源供应电力的波动尤为显著。 -
Unidirectional grids without price regulation applications lack interaction between customers and utilities, preventing end-users from reacting to price variations 3.
缺乏价格调节应用的单向电网由于缺少用户与公用事业公司之间的互动,导致终端用户无法对价格变化做出反应 3。 -
However, with tariff-based regulations and the growing preference for bidirectional renewable energy-based microgrids, end-users can now interact with energy suppliers, paving the way for dynamic pricing concepts in the energy market.
然而,随着基于关税的监管以及对基于可再生能源的双向微电网的日益青睐,终端用户现在可以与能源供应商互动,为能源市场中的动态定价概念铺平了道路。 -
This transformation has been facilitated by smart meter-based time-ahead LF or survey-based passive LF techniques.
这种转型得到了基于智能电表的提前量负荷预测或基于调查的被动负荷预测技术的推动。 -
The literature reflects a focus on improving and proposing new concepts for energy management.
文献反映出研究重点在于改进和提出能源管理的新概念。 -
The outcomes of these studies can be directly linked to financial benefits for both utility companies (suppliers) and end-users in terms of reducing operation and energy costs, respectively.
这些研究成果可以直接转化为公用事业公司(供应商)和终端用户的经济利益,即分别降低运营成本和能源支出。 -
Deep learning (DL)-based LF techniques have gained prominence due to the constraints in electrical energy production and consumption cycles.
由于电能生产和消费周期的约束,基于深度学习(DL)的负荷预测技术已脱颖而出。 -
In this context, data-driven LF solutions offer distinct advantages for managing load demand (LD) and the supply of renewable energy sources (RESs).
在此背景下,数据驱动的负荷预测解决方案在管理负荷需求(LD)和可再生能源(RESs)供应方面具有显著优势。 -
Data-driven techniques can be applied on the supply side to integrate renewables.
数据驱动技术可应用于供应侧以整合可再生能源。 -
This integration is facilitated through the mutual interaction of customers and utilities.
这种整合是通过用户与公用事业公司的相互作用实现的。 -
By analysing consumption patterns, energy sources can be installed closer to the points of consumption.
通过分析消费模式,能源设备可以安装在更靠近消费点的地方。 -
The use of renewable resources can proportionally reduce the environmental impact of conventional resources.
使用可再生资源可以按比例减少传统资源对环境的影响。 -
Diversifying energy sources enhances energy security by reducing exposure to fluctuations in fuel prices and supply disruptions.
能源多样化通过减少受燃料价格波动和供应中断的影响,增强了能源安全性。 -
Therefore, machine learning (ML) and DL-based neural network (NN) approaches can be used to coordinate renewable energy production and adjust grid operations in real-time to maintain stability.
因此,机器学习(ML)和基于深度学习的神经网络(NN)方法可用于协调可再生能源生产并实时调整电网运行以维持稳定性。 -
On the supply side, the main concern is that a large quantity of electrical energy must be consumed immediately after generation.
在供应侧,主要关注点是大量的电能必须在发电后立即消耗。 -
Renewable-powered microgrids have mitigated this constraint to some extent.
由可再生能源驱动的微电网在一定程度上缓解了这一约束。 -
The demand side remains volatile and unpredictable, as evident in load profiles.
正如负荷曲线所示,需求侧仍然具有波动性和不可预测性。 -
The primary non-linear relationships in LD profiles can be attributed to occupancy behaviours, seasonal variables, energy costs, geographical conditions, etc.
负荷需求曲线中的主要非线性关系可归因于占用行为、季节变量、能源成本、地理条件等。 -
Therefore, LF models must possess self-adaptability, repeatability, and robustness to handle contingencies 4.
因此,负荷预测模型必须具备自适应性、可重复性和鲁棒性,以处理突发事件 4。 -
Given the volatile nature of residential LD, an LF model should be adaptable to preference-based trends, repeatable for forward predictions, robust against uncertainties, and validated for expected accuracy.
考虑到住宅负荷需求的波动性,负荷预测模型应能适应基于偏好的趋势,在远期预测中具有可重复性,对不确定性具有鲁棒性,并经过预期准确性的验证。 -
In this regard, DL approaches offer reasonable and profitable solutions, despite the unpredictable nature of the load profiling problem, thanks to their substantial non-linear mapping capabilities.
在这方面,尽管负荷特征描述问题具有不可预测性,但深度学习方法凭借其强大的非线性映射能力,提供了合理且有利可图的解决方案。 -
The main types of DL methods for LF problems include recurrent neural network (RNN), variants of RNN such as long short term memory (LSTM) networks or gated recurrent unit (GRU), and convolutional neural networks (CNN) 5.
用于负荷预测问题的主要深度学习方法包括循环神经网络(RNN)、RNN 的变体(如长短期记忆网络 LSTM 或门控循环单元 GRU)以及卷积神经网络(CNN) 5。 -
In addition to these individual techniques, combinations of approaches have been proposed.
除了这些单一技术外,研究者还提出了多种方法的组合。 -
In this context, hybrid and ensemble LF models have been developed to enhance the performance of NN models.
在此背景下,为了增强神经网络模型的性能,开发了混合和集成负荷预测模型。 -
A hybrid LF model combines two or more models to solve a specific problem, leveraging the strengths of each model to produce a more accurate solution.
混合负荷预测模型结合了两个或多个模型来解决特定问题,利用每个模型的优势来产生更准确的解决方案。 -
For example, a hybrid LF model might combine a time series model, such as an autoregressive integrated moving average (ARIMA), with another NN model to capture both linear and non-linear dynamics in the data.
例如,混合负荷预测模型可能会将时间序列模型(如差分整合移动平均自回归模型 ARIMA)与另一个神经网络模型结合,以捕获数据中的线性和非线性动态。 -
An ensemble LF model involves training multiple models on the same data and combining their predictions through a single output to produce more robust forecasts.
集成负荷预测模型涉及在相同数据上训练多个模型,并通过单一输出结合它们的预测,从而产生更具鲁棒性的预测。 -
Ensemble models can be used to reduce the variance or bias of predictions and improve overall forecast accuracy.
集成模型可用于减少预测的方差或偏差,并提高整体预测准确性。 -
In the context of an LF problem, an ensemble model may involve training multiple decision trees or sub-models and combining their predictions through a voting mechanism or by averaging their predictions.
在负荷预测问题的背景下,集成模型可能涉及训练多个决策树或子模型,并通过投票机制或平均预测值来结合其预测结果。 -
Considering the related review papers, the concepts of DL or LF can be specified with respect to the scope of the work.
考虑到相关的综述论文,深度学习或负荷预测的概念可以根据工作范围进行具体界定。 -
In this manner, DL-based studies can be reviewed with or without limitations on the referred techniques or time range.
通过这种方式,基于深度学习的研究可以在有或没有技术及时间范围限制的情况下进行综述。 -
LF can be considered as a sub-item of a study on electrical power systems applications or as an independent subject within its own internal classification.
负荷预测可以被视为电力系统应用研究的一个子项,也可以作为其内部分类中的独立学科。 -
Besides, LF can also be addressed by load types (LTs), forecast horizon, and time range.
此外,负荷预测还可以根据负荷类型(LTs)、预测时间尺度和时间范围进行研究。 -
In this regard, the reviews can be classified into classes. These classes are the DL concept with special LTs for forecasting, DL applications to the electric power systems, deep forecasting models, and a special form of DL-based LF problem.
在这方面,综述可以分为以下几类:针对特定负荷类型的深度学习概念、深度学习在电力系统中的应用、深度预测模型,以及特定形式的基于深度学习的负荷预测问题。 -
Considering the first class, review research is conducted by focusing on the RNNs technique as well as touching on some other ML techniques for residential-type LF 6.
考虑到第一类,综述研究重点关注 RNN 技术,同时也涉及了用于住宅型负荷预测的其他一些机器学习技术 6。 -
In this manner, the works on DL-type LSTM, CNN, and RNNs, as well as other approaches based on ML and statistical tools, are surveyed, and their results are analysed for building LF 7.
通过这种方式,研究人员调查了关于 LSTM、CNN 和 RNN 等深度学习类型,以及基于机器学习和统计工具的其他方法的工作,并分析了它们在建筑负荷预测中的结果 7。 -
Using the same data type, the pros and cons-based review analysis is performed 8,9.
利用相同的数据类型,研究者进行了基于优缺点的综述分析 8,9。 -
At the second class of reviews, DL-based papers subjected to the applications of electric power systems are examined.
在第二类综述中,研究了涉及电力系统应用的深度学习论文。 -
In these reviews, DL-based LF can be a small part of the study, and LF is generally not surveyed in detail 10--13.
在这些综述中,基于深度学习的负荷预测可能只是研究的一小部分,通常不会对其进行详细调查 10--13。 -
Another class includes the research focused on deep forecasting models.
另一类包括专注于深度预测模型的研究。 -
These studies consider the modelling, tuning, and applications stages of DL techniques and provide detailed investigations on the stages of determining the dynamics and parameter values within the model as well as performance indices 14--16.
这些研究考虑了深度学习建模、调优和应用阶段,并详细调查了确定模型内部动态和参数值的阶段以及性能指标 14--16。 -
The last class of the related reviews aims to search LF-based papers in terms of the forecast horizon and DL techniques.
最后一类相关综述旨在从预测时间尺度和深度学习技术的角度搜索基于负荷预测的论文。 -
The concept of LF with a specific horizon or LF covering all horizon types is selected.
选择了特定时间尺度或涵盖所有时间尺度类型的负荷预测概念。 -
Besides, single or a group of DL techniques are selected.
此外,还选择了单一或一组深度学习技术。 -
In this regard, hybrid DL models based on nature-inspired meta-heuristic techniques for STLF are investigated 17.
在这方面,研究了基于受自然启发元启发式技术的短期负荷预测(STLF)混合深度学习模型 17。 -
Another paper deals with DL techniques for the general LF problem 18.
另一篇论文涉及了用于一般负荷预测问题的深度学习技术 18。 -
Following the survey between 2015--2020, a conceptual DL learning model is proposed, which promises to reduce computational time in LF.
在对 2015-2020 年间的调查之后,提出了一种概念性的深度学习模型,有望减少负荷预测中的计算时间。 -
Deep and shallow learning techniques associated with all horizon-type LF are dealt with to analyse the application suitability of the techniques 19.
研究了与所有时间尺度类型负荷预测相关的深度和浅层学习技术,以分析这些技术的应用适用性 19。 -
Following the same learning scope, a review is performed for STLF models by 20.
遵循相同的学习范围,文献 20 对短期负荷预测模型进行了综述。 -
This paper mainly focuses on the performance analysis of STLF techniques and includes a limited number of studies.
该论文主要侧重于短期负荷预测技术的性能分析,且包含的研究数量有限。 -
Based on the above analysis, it is evident that there are several research gaps in the field of STLF-DL.
基于上述分析,显而易见在短期负荷预测-深度学习(STLF-DL)领域存在若干研究空白。 -
While the literature contains a plethora of sources, there is a scarcity of reviews tailored to meet the future needs of this field.
虽然文献资源极其丰富,但缺乏专门为满足该领域未来需求而定制的综述。 -
Furthermore, the future directions outlined in existing review papers often focus on specific models and dataset specifications.
此外,现有综述论文中概述的未来方向往往集中于特定模型和数据集规范。 -
In this review, we have addressed a specialised problem to anticipate the evolving demands related to expanding datasets, end-user preferences, and energy market requirements.
在本综述中,我们解决了一个专门问题,以预测与不断扩大的数据集、终端用户偏好和能源市场需求相关的演变需求。 -
Therefore, the customised problem of DL-based STLF has been selected as a focal point.
因此,基于深度学习的短期负荷预测(STLF)这一定制化问题被选为焦点。 -
Additionally, the future direction of this problem is designed to encompass the upcoming requirements, including online capabilities, uncertainty awareness, and practical implementability.
此外,该问题的未来方向旨在涵盖即将到来的要求,包括在线能力、不确定性感知和实际可操作性。 -
This review also encompasses all-time papers related to DL-based STLF and offers key insights into future directions.
本综述还涵盖了与基于深度学习的 STLF 相关的历年论文,并提供了关于未来方向的关键见解。 -
Power systems in almost every country have recently been privatised, and electricity is now bought and sold in the energy market 2.
几乎所有国家的电力系统近期都已私有化,电力现在能源市场上进行买卖 2。 -
In this context, the stability of energy prices can only be ensured by a realistic indicator known as STLF.
在此背景下,能源价格的稳定性只能通过一个被称为 STLF 的现实指标来确保。 -
Consequently, STLF has become a critical element in regulating market prices, allowing for trade-off negotiations between the increasing operational competition brought about by the SG concept and users' demand for convenient and cost-effective solutions.
因此,STLF 已成为调节市场价格的关键要素,允许在智能电网(SG)概念带来的日益激烈的运营竞争与用户对便捷且具成本效益的解决方案的需求之间进行权衡谈判。 -
Despite the vast potential of STLF to meet the needs of both market parties by offering economical and comfortable solutions to the LF problem, it poses challenges due to various factors that complicate accurate electricity consumption prediction.
尽管 STLF 通过为负荷预测问题提供经济且舒适的解决方案,在满足市场双方需求方面具有巨大潜力,但由于各种因素使准确的电力消耗预测变得复杂,它也带来了挑战。 -
These factors encompass temporal variability with daily, weekly, and seasonal patterns, sensitivity to weather conditions (including temperature, humidity, wind speed, and radiation levels), rapid load fluctuations resulting from real-time failures like equipment malfunctions, unplanned outages, and performance degradation due to intermittent renewable sources, price dynamics, uncertainty factors, dataset quality, modelling limitations, and the growing number and diversity of domestic loads 21.
这些因素包括具有日、周和季节模式的时间变异性;对天气条件(包括温度、湿度、风速和辐射水平)的敏感性;由设备故障、计划外停电等实时故障导致的快速负荷波动;由于间歇性可再生能源导致的性能下降;价格动态;不确定性因素;数据集质量;建模限制;以及国内负荷数量和多样性的增加 21。 -
When considering these factors, the impact of weather conditions on forecasting quality, as well as rapid load fluctuations, are noteworthy.
在考虑这些因素时,天气条件对预测质量的影响以及快速的负荷波动值得关注。 -
Weather conditions significantly affect the accuracy of predictions, and rapid load fluctuations result from real-time failures and intermittent renewables.
天气条件显著影响预测的准确性,而快速负荷波动则源于实时故障和间歇性可再生能源。 -
Price dynamics and uncertainty factors encompass unexpected occurrences within the systems, making them vital for informed decision-making and experience accumulation.
价格动态和不确定性因素涵盖了系统内的突发事件,使它们对于明智的决策和经验积累至关重要。 -
Ensuring high-quality, well-granulated historical data for the dataset is crucial for understanding consumer behaviour.
确保数据集拥有高质量、细粒度的历史数据,对于理解消费者行为至关重要。 -
Finally, modelling limitations, while simplifying forecasting models for ease of interpretation and computation, need to be carefully considered 22.
最后,虽然为了易于解释和计算而简化了预测模型,但建模限制仍需仔细考虑 22。 -
Addressing these limitations is essential in the face of the various factors influencing electricity consumption.
面对影响电力消耗的各种因素,解决这些限制至关重要。 -
Given the aforementioned challenges, effectively addressing the complexities of the STLF problem demands robust and adaptive forecasting models 23.
鉴于上述挑战,有效解决 STLF 问题的复杂性需要鲁棒且自适应的预测模型 23。 -
In this context, DL approaches present a viable solution to meet the modelling requirements of STLF.
在此背景下,深度学习方法为满足 STLF 的建模需求提供了一个可行的解决方案。 -
DL methods have consistently proven their mettle as robust and adaptive forecasting models, particularly when dealing with extensive time series datasets.
深度学习方法已一贯证明其作为鲁棒且自适应预测模型的实力,特别是在处理大规模时间序列数据集时。 -
Nevertheless, it is crucial to acknowledge that DL methodologies are not universally applicable, and their suitability should be assessed based on the specific demands of the LF problem.
尽管如此,承认深度学习方法并非万能至关重要,应根据负荷预测问题的具体需求评估其适用性。 -
These considerations may encompass the availability of data, computational complexity, and interpretive aspects relevant to the application.
这些考虑因素可能包括数据的可用性、计算复杂度以及与应用相关的解释性方面。 -
It is often beneficial to explore a spectrum of modelling approaches, which could include traditional statistical methods and ML algorithms, when tackling forecasting tasks.
在处理预测任务时,探索一系列建模方法(可能包括传统统计方法和机器学习算法)通常是有益的。 -
Additionally, classical metrics or customised metrics reflecting user or regional behaviours and occupancies can be readily incorporated into DL-based methods 24
此外,反映用户或区域行为及占用情况的经典指标或定制指标可以很容易地整合到基于深度学习的方法中 24。 -
Another crucial factor to consider is the compatibility of DL-based solutions with the increasing decentralisation of distribution networks, prompted by the rapid proliferation of RESs.
另一个需要考虑的关键因素是基于深度学习的解决方案与配电网络日益去中心化(由可再生能源的快速扩散引起)的兼容性。 -
This matter can be assessed by examining grid monitoring and control, as well as the integration of distributed energy resources.
这一问题可以通过检查电网监测与控制,以及分布式能源的整合来评估。 -
These factors have significantly heightened the complexity of LF models.
这些因素显著提高了负荷预测模型的复杂性。 -
Therefore, the extensive mapping capabilities of DL-based models stand out as a prominent solution to meet the urgent requirement for rapid price determination within short-time horizons
因此,基于深度学习模型的广泛映射能力作为一种卓越的解决方案脱颖而出,以满足在短时间内快速确定价格的迫切要求。 -
Last but certainly not least, it is vital to acknowledge that preferences and individual standards are continuously evolving 25,26.
最后但同样重要的一点是,必须承认偏好和个人标准是在不断演变的 25,26。 -
The DL-based STLF concept possesses the substantial capability to incorporate new or modified cause-and-effect relationships into the model.
基于深度学习的 STLF 概念具有将新的或修改后的因果关系整合到模型中的强大能力。 -
This approach can be exemplified by focusing on factors such as future engineering, consumer segmentation, the integration of recent survey data, and the feedback mechanism.
这种方法可以通过关注诸如特征工程(原文误为 future engineering)、消费者细分、近期调查数据的整合以及反馈机制等因素来体现。 -
Regarding future engineering, the model is enriched by including information on energy-efficient appliances, shifts in lighting and temperature preferences, and occupancy patterns of end-users.
关于特征工程,通过包含节能设备信息、照明和温度偏好的转变以及终端用户的占用模式,模型得到了丰富。 -
Furthermore, consumer segmentation enables a more personalised forecast by categorising consumers into distinct groups with unique preferences.
此外,消费者细分通过将消费者分类为具有独特偏好的不同群体,实现了更个性化的预测。 -
Additionally, survey data provides valuable insights to enhance forecast accuracy by capturing recent preferences and standards.
此外,调查数据通过捕捉近期的偏好和标准,为提高预测准确性提供了宝贵的见解。 -
Finally, the feedback mechanism, achievable through an online-iterative based optimisation procedure allows for adjustments to the internal dynamics of the LF model.
最后,通过基于在线迭代的优化程序实现的反馈机制,允许对负荷预测模型的内部动态进行调整。 -
This concept is particularly relevant for the model architecture of forward-looking real-time applications that consider online and uncertainty dynamics.
这一概念对于考虑在线和不确定性动态的前瞻性实时应用的模型架构尤为相关。 -
Building upon the discussions in the preceding section, it is evident that achieving the required accuracy in addressing the LF problem necessitates a short-term dataset horizon and a flexible modelling approach.
基于前一节的讨论,显而易见,要在解决负荷预测问题时达到所需的准确性,需要短期的训练数据集范围和灵活的建模方法。 -
The model should possess a robust capability to map both predicted and random variations in energy market parameters and effectively integrate RESs.
模型应具备强大的能力,以映射能源市场参数中预测的和随机的变化,并有效整合可再生能源(RESs)。 -
*To tackle this challenge, we propose the hypothesis that ''DL-based models for STLF are essential for the dynamic and feasible operation of the energy market''. *
为了应对这一挑战,我们提出了这样一个假设:"基于深度学习的 STLF 模型对于能源市场的动态且可行运行至关重要"。 -
Precisely predicting STLF from an energy market operator dataset is a formidable task due to the considerable uncertainty and volatility in demand, coupled with a relatively short prediction interval.
由于需求存在巨大的不确定性和波动性,加之预测间隔相对较短,从能源市场运营商的数据集中精确预测 STLF 是一项艰巨的任务。 -
ML-based models rooted in DL concepts have often been explored to address these complexities, leading to a substantial body of literature dedicated to STLF.
植根于深度学习概念的机器学习模型经常被探索用于解决这些复杂性,从而产生了大量致力于 STLF 的文献。 -
Additionally, outlining the future directions of DL-STLF requires an innovative perspective and the synthesis of background information.
此外,概述 DL-STLF 的未来方向需要创新的视角和背景信息的综合。 -
In this study, we introduce DL-based STLF models and conduct a comprehensive review.
在本研究中,我们介绍了基于深度学习的 STLF 模型并进行了全面综述。 -
To our knowledge, prior research has not thoroughly explored the diverse facets of the STLF problem, including problem types, modelling forms, and future solutions.
据我们所知,先前的研究尚未透彻探讨 STLF 问题的各个方面,包括问题类型、建模形式和未来的解决方案。 -
This review provides a detailed analysis of relevant studies, highlighting emerging trends and encompassing online DL-based STLF models, uncertainty-aware models, practical evidence, and dataset details.
本综述对相关研究进行了详细分析,强调了新兴趋势,并涵盖了在线深度学习 STLF 模型、不确定性感知模型、实践证据和数据集细节。 -
We propose a forward-looking concept to address future directions in online, robust, and implementable aspects.
我们提出了一个前瞻性概念,以解决在线、鲁棒和可实施方面的未来方向。 -
This research paper primarily focuses on the examination of studies related to STLF problems using DL approaches, covering various aspects such as techniques proposed, key ideas in reviewed papers, dataset origins and types, uncertainty awareness, online methodologies, and practical evidence in DR applications.
本研究论文主要侧重于考察使用深度学习方法解决 STLF 问题的相关研究,涵盖了所提出的技术、综述论文中的核心思想、数据集来源和类型、不确定性感知、在线方法论以及需求响应(DR)应用中的实践证据等各个方面。 -
The paper classifies the concept into categories like online models, uncertainty-aware perspective, and practical evidence context to provide a comprehensive solution for DL-based STLF.
本文将该概念分为在线模型、不确定性感知视角和实践证据背景等类别,为基于深度学习的 STLF 提供全面的解决方案。 -
Within the framework of the SG concept, it aims to generate precise input data for DR applications and offers references for future LF or DR studies.
在智能电网(SG)概念的框架内,其旨在为需求响应(DR)应用生成精确的输入数据,并为未来的负荷预测(LF)或需求响应研究提供参考。 -
The ultimate goal is to provide a unified direction for future research on DL-based STLF, with key contributions including a detailed analysis of relevant studies, dataset descriptions, explanations of commonly referenced techniques, and the highlighting of important concepts for future research in the field.
最终目标是为基于深度学习的 STLF 的未来研究提供统一的方向,主要贡献包括对相关研究的详细分析、数据集描述、常用技术的解释,以及对该领域未来研究重要概念的强调。 -
The rest of this review is organised as follows.
本综述的其余部分安排如下。 -
Section 2 explains the methodology employed in this review.
第 2 节解释了本综述采用的方法论。 -
Section 3 introduces the LF problem for electricity consumption.
第 3 节介绍了电力消耗的负荷预测(LF)问题。 -
Section 4 provides a summary of DL-based studies for STLF problems, accompanied by detailed tables.
第 4 节总结了针对 STLF 问题的深度学习研究,并辅以详细表格。 -
Section 5 includes concise information about frequently referenced techniques.
第 5 节包含了关于常用技术的简明信息。 -
Sections 6 and 7 delve into notable online approaches and uncertainty awareness, respectively.
第 6 节和第 7 节分别深入探讨了值得关注的在线方法和不确定性感知。 -
Section 8 scrutinises the practical evidence of DL-based STLF.
第 8 节详细审查了基于深度学习的 STLF 的实践证据。 -
Section 9 offers comprehensive discussions regarding future directions, recommendations, and limitations.
第 9 节提供了关于未来方向、建议和局限性的全面讨论。 -
Finally, Section 10 concludes the review.
最后,第 10 节对本综述进行了总结。
2. 方法论
- The methodology, illustrated in Fig. 1, comprises the following steps: Scoping and Pooling, Analysis, Classification, and Pool Refinement; Filtering and Abstraction; Identification of Future Research Trends and Discussions.
如图 1 所示,该方法论包含以下步骤:范围界定与汇总、分析、分类与汇总优化;筛选与抽象;以及未来研究趋势的确定与讨论。
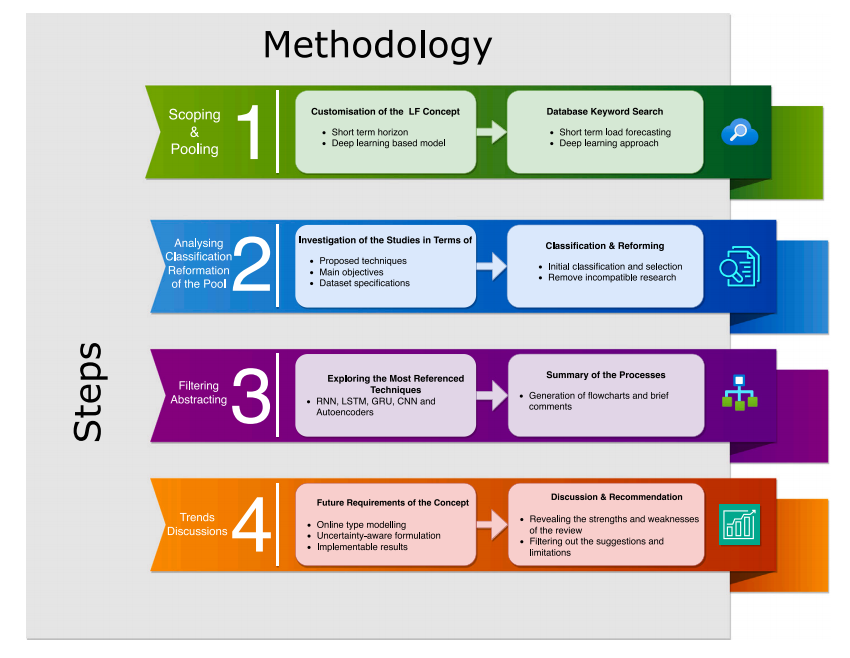
图片内容翻译
- 范围界定与汇总
-
Customisation of the LF Concept: Short term horizon, Deep learning based model
负荷预测(LF)概念定制:短期时间尺度、基于深度学习的模型 -
Database Keyword Search: Short term load forecasting, Deep learning approach
数据库关键词搜索:短期负荷预测、深度学习方法
- 样本池分析、分类与重组
-
Investigation of the Studies in Terms of: Proposed techniques, Main objectives, Dataset specifications
研究调查内容:提出的技术、主要目标、数据集规范 -
Classification & Reforming: Initial classification and selection, Remove incompatible research
分类与重组:初步分类与筛选、剔除不相容的研究
- 过滤与抽象化
-
Exploring the Most Referenced Techniques: RNN, LSTM, GRU, CNN and Autoencoders
探索最常被引用的技术:RNN, LSTM, GRU, CNN 和自动编码器 -
Summary of the Processes: Generation of flowcharts and brief comments
流程总结:生成流程图并进行简要评价
- 趋势与讨论
-
Future Requirements of the Concept: Online type modelling, Uncertainty-aware formulation, Implementable results
该概念的未来需求:在线型建模、不确定性感知公式化、可实施的结果 -
Discussion & Recommendation: Revealing the strengths and weaknesses of the review, Filtering out the suggestions and limitations
讨论与建议:揭示综述的优缺点、筛选建议与局限性
-
These steps are elaborated as follows:
这些步骤详细阐述如下: -
Step 1: Scoping and pooling. The specific problem definition for the LF problem, as well as the determination of the solution model type, has been carried out.
步骤 1:范围界定与汇总。已完成负荷预测(LF)问题的具体定义,并确定了解决方案的模型类型。 -
The STLF concept is identified as a specialised form of the LF problem, given its potential to effectively address end-user energy usage patterns.
鉴于短期负荷预测(STLF)在有效处理终端用户能源使用模式方面的潜力,它被确定为负荷预测问题的一种专门形式。 -
STLF has gained significance due to the increasing number of parameters driven by higher expectations for economical and comfortable solutions.
由于对经济和舒适解决方案的更高预期驱动了参数数量的增加,STLF 的重要性日益凸显。 -
Therefore, DL-based models have emerged as the most preferred techniques, owing to their substantial capacity to map input--output relationships and make visible user behaviours related to electricity demand.
因此,基于深度学习(DL)的模型已成为最受青睐的技术,这归功于它们在映射输入输出关系以及使与电力需求相关的用户行为可视化方面的强大能力。 -
In this context, a literature survey has been conducted using the keywords ''STLF'' and ''DL''.
在此背景下,使用关键词"STLF"和"DL"进行了文献调研。 -
Studies that include both of these keywords were searched using academic search engines (Web of Science and Google Scholar). The details of this step are provided in Section 3.
利用学术搜索引擎(Web of Science 和 Google Scholar)搜索了同时包含这两个关键词的研究。该步骤的详细信息见第 3 节。 -
Step 2: Analysing, classification and reformation of the pool. The studies have been categorised based on the proposed techniques and primary objectives, as well as dataset specifications.
步骤 2:分析、分类与汇总重构。研究已根据提出的技术、主要目标以及数据集规范进行了分类。 -
The details of these classifications can be found in Tables 1 and 2. The primary aim of this categorisation is to highlight the variations in requirements that can guide future research directions for the specified problem.
这些分类的详细信息见表 1 和表 2。此类分类的主要目的是突出需求的多样性,从而为该特定问题的未来研究方向提供指导。 -
Additionally, a separate dataset review has been conducted, considering different LTs, origins, and sample rate (SR).
此外,还考虑到不同的负荷类型(LTs)、来源和采样率(SR),进行了独立的数据集审查。 -
By simultaneously examining the contents of these tables, prospective researchers can easily establish connections between proposed techniques and objectives, facilitating the exploration of future ideas. The specifics of this step are provided in Sections 3 and 4.
通过同时查看这些表格的内容,潜在的研究人员可以轻松地在所提技术与目标之间建立联系,从而促进对未来构思的探索。该步骤的具体细节见第 3 节和第 4 节。 -
Step 3: Filtering and abstracting. In light of the review, the most frequently referenced DL-based modelling techniques are identified as RNN, LSTM, GRU, CNN, and autoencoders.
步骤 3:筛选与抽象。根据综述情况,最常被引用的基于深度学习的建模技术被确定为 RNN、LSTM、GRU、CNN 和自动编码器。 -
These techniques are briefly explained using flowcharts and their characteristic features. Further details on Step 3 can be found in Section 5.
本文使用流程图及其特征属性对这些技术进行了简要解释。关于步骤 3 的更多细节见第 5 节。 -
Step 4: Identification of the future research trends and discussions. Future requirements of the DL-based STLF problem are defined by three critical aspects: online-type modelling, uncertainty awareness, and implementability.
步骤 4:确定未来研究趋势与讨论。基于深度学习的 STLF 问题的未来需求由三个关键方面定义:在线型建模、不确定性感知和可实施性。 -
The shared perspectives on these concerns enhance the feasibility of future efforts to meet the performance demands of the modern SG concept.
对这些关注点的共同见解增强了未来努力实现现代智能电网(SG)概念性能需求的可行性。 -
There is a limited body of literature that addresses the performance of individual or combined objectives within these areas. A detailed analysis of these specifics is presented in Sections 6, 7, and 8.
目前涉及这些领域内单一或组合目标性能的文献有限。第 6、7 和 8 节对这些细节进行了详细分析。 -
Furthermore, a comprehensive discussion of the review, encompassing key ideas and additional perspectives, can be found in Section 9.
此外,包含核心思想和额外视角的综述全面讨论见第 9 节。
3. 电力消耗的负荷预测(LF)
-
LF leverages local patterns in the LD of end-user groups, presenting a challenging problem due to the unpredictable behaviours of occupants and the influence of exogenous parameters on electricity consumption, such as weather conditions, local or nationwide human activities, festivals, and more.
负荷预测(LF)利用终端用户群体负荷需求(LD)的局部模式,由于占入者不可预测的行为以及天气条件、地方或全国性人类活动、节日等外部参数对电力消耗的影响,这成为一个极具挑战性的问题。 -
The scope of LF is categorised into four segments: very short-term forecasting, short-term forecasting, mid-term forecasting, and long-term forecasting 51.
负荷预测的范围分为四个部分:超短期预测、短期预测、中期预测和长期预测 51。 -
Each category encompasses different time spans, ranging from a few minutes to one hour, one hour to one week, several months, and several years, respectively.
每个类别涵盖不同的时间跨度,分别从几分钟到一小时、一小时到一周、几个月以及几年不等。 -
Among these categories, STLF has gained popularity due to the proliferation of internet of things (IoT) applications based on smart meter data, the increasing granularity of data for data-driven techniques, and the ease of establishing data relevance with conditional factors 97.
在这些类别中,由于基于智能电表数据的物联网(IoT)应用的普及、数据驱动技术所需的数据粒度不断增加,以及易于建立数据与条件因子的相关性,短期负荷预测(STLF)受到了广泛关注 97。 -
STLF serves as a key input for operational decisions in unit commitment and source coordination to minimise transmission costs 64.
STLF 是机组组合和能源协调运行决策的关键输入,旨在最大限度地降低输电成本 64。 -
Consequently, STLF plays a pivotal role in enhancing the efficiency of the power supply side, ensuring grid safety, establishing common ground for complex pricing strategies in the energy market, and addressing challenges stemming from the increased integration of RESs 115,116.
因此,STLF 在提高供电侧效率、确保电网安全、为能源市场复杂的定价策略建立共同基础,以及应对因可再生能源(RESs)整合增加而带来的挑战方面发挥着关键作用 115,116。 -
Moreover, STLF serves as a point of reference for DR applications to adapt to price changes or instant regulations in the electricity market.
此外,STLF 还作为需求响应(DR)应用的参考点,以适应电力市场的价格变化或即时监管。 -
Regulatory actions can be achieved through load curtailment and load shifting. However, repricing is typically determined through tariff adjustment procedures.
监管行动可以通过负荷削减和负荷转移来实现。然而,重新定价通常是通过关税调整程序确定的。 -
LF is also assessed from the perspective of economical electricity dispatching, as accurately estimating future demand is crucial for meeting demand while minimising costs.
负荷预测也从经济电力调度角度进行评估,因为准确估计未来需求对于在降低成本的同时满足需求至关重要。 -
In this context, challenges arise in terms of LF accuracy, price dynamics, the intermittent characteristics of energy renewables, and various operational constraints, as highlighted in studies like 121,122.
在此背景下,正如研究 121,122 所强调的,挑战出现在负荷预测准确性、价格动态、可再生能源的间歇性特征以及各种运行约束方面。 -
Achieving adequate accuracy in LF is an ongoing research focus, with efforts aimed at improving accuracy through factors such as climate dynamics, addressing uncertainties in demand, and employing risk assessment approaches for unexpected events.
在负荷预测中实现足够的准确性是一个持续的研究重点,研究工作旨在通过气候动态等因素提高准确性,解决需求中的不确定性,并对突发事件采用风险评估方法。 -
Dispatching decisions are predominantly influenced by price fluctuations in the available supplied power.
调度决策主要受可用供应电力价格波动的影响。 -
To ensure a fair and competitive energy market, reliability is a crucial parameter that can be better assessed through improved LF performance.
为了确保公平且具有竞争力的能源市场,可靠性是一个关键参数,可以通过提高负荷预测性能来更好地评估。 -
Moreover, considering the increasing integration of renewables into the grid, these sources produce intermittent and variable energy.
此外,考虑到可再生能源在电网中的整合日益增加,这些能源产生的是间歇性和多变的能量。 -
Therefore, accurate LF prediction is vital for operators to balance unexpected deficits and ensure demand reliability.
因此,准确的负荷预测对于运营商平衡意外缺口并确保需求可靠性至关重要。 -
Finally, operational constraints, including generator capacity, voltage-frequency stability, and transmission limits can also be incorporated into the economical dispatching of energy using LF concepts.
最后,包括发电机容量、电压频率稳定性和输电限制在内的运行约束,也可以利用负荷预测概念纳入能源经济调度中。 -
These constraints have practical applications in optimising DR programs based on LF.
这些约束在优化基于负荷预测的需求响应计划中具有实际应用价值。 -
LF involves heavily varying non-linear dynamics due to the unpredictable nature of human-based activities or micro-climate variables.
由于人类活动或微气候变量的不可预测性,负荷预测涉及剧烈变化的非线性动态。 -
The methods used to address these challenges need to capture both short- and long-term dependencies, which are influenced by human behaviours, natural dynamics, and weather-related factors.
用于解决这些挑战的方法需要捕捉受人类行为、自然动态和天气相关因素影响的短期和长期依赖关系。 -
STLF has been tackled using three primary methods: mathematical algorithms, single artificial intelligence algorithms, and combinatorial algorithms 100.
STLF 主要通过三种方法解决:数学算法、单一人工智能算法和组合算法 100。 -
Mathematical algorithms encompass regression-based models, interpolations, serial methods, statistical techniques, and fuzzy-logic approaches. The majority of these models have been designed with a linear approach.
数学算法包括基于回归的模型、插值法、序列法、统计技术和模糊逻辑方法。这些模型中的大多数是采用线性方法设计的。 -
However, linear or affine-linear methods exhibit poor performance when dealing with demand profiles that exhibit random and volatile patterns.
然而,在处理具有随机和波动模式的需求曲线时,线性或仿射线性方法的表现较差。 -
Non-linear models outperform linear approaches but may struggle to capture the volatility in demand patterns.
非线性模型优于线性方法,但在捕获需求模式的波动性方面可能会遇到困难。 -
Intelligent algorithms, including ML methods, have been proposed, such as artificial neural networks (ANNs), RNNs, LSTMs, GRUs, support vector regression (SVR), BMN, decision and regression trees, random forest (RF), k-nearest neighbours (k-NNs), linear regression, Gaussian processes ensemble, clustering, hybrid algorithms, k-means, fuzzy c-means algorithms, deep belief networks (DBNs), extreme learning machines, principal component regression, adaptive neuro-fuzzy inference systems, GBM, CNNs, and autoencoders.
已经提出了包括机器学习(ML)方法在内的智能算法,如人工神经网络(ANNs)、循环神经网络(RNNs)、长短期记忆网络(LSTMs)、门控循环单元(GRUs)、支持向量回归(SVR)、玻尔兹曼机(BMN)、决策树和回归树、随机森林(RF)、k-最近邻(k-NNs)、线性回归、高斯过程集成、聚类、混合算法、k-均值、模糊 C-均值算法、深度信念网络(DBNs)、极限学习机、主成分回归、自适应神经模糊推理系统、梯度提升机(GBM)、卷积神经网络(CNNs)和自动编码器。 -
These ML-based models possess a robust mapping ability for STLF, but they may be susceptible to increased forecasting errors caused by sudden deviations in seasonal or occupancy-related parameters 75.
这些基于机器学习的模型对 STLF 具有强大的映射能力,但它们可能容易受到季节或占用相关参数突然偏差引起的预测误差增加的影响 75。 -
To address these deficiencies, combinatorial approaches, categorised as hybrid or ensemble models, have been proposed.
为了弥补这些不足,研究者提出了分为混合模型或集成模型的组合方法。 -
Hybrid models that split the task into two sub-tasks can reduce forecasting errors when dealing with aggregated loads but may fall short in capturing long-term dependencies in residential demand loads 98.
将任务拆分为两个子任务的混合模型在处理聚合负荷时可以减少预测误差,但在捕捉住宅需求负荷的长期依赖关系方面可能力有不逮 98。 -
Additionally, ensemble forecasting strategies involve basic models combined through multiple learning algorithms. The output of each model is weighted according to the correlation degree to enhance accuracy.
此外,集成预测策略涉及通过多种学习算法组合基础模型。根据相关程度对每个模型的输出进行加权,以提高准确性。 -
In the literature, both static and dynamic ensemble learning approaches have been proposed for electricity LF, utilising combinations of LSTM, GRU, and temporal convolutional networks (TCNs) techniques 94.
在文献中,已经提出了用于电力负荷预测的静态和动态集成学习方法,利用了 LSTM、GRU 和时间卷积网络(TCNs)技术的组合 94。
4. 基于不同数据集的深度学习短期负荷预测(DL-based STLF)
-
DL is a subfield of ML that utilises ANNs with multiple layers to learn and represent complex mappings between input and output data 123,124.
深度学习(DL)是机器学习(ML)的一个子领域,它利用多层人工神经网络(ANNs)来学习和表示输入与输出数据之间的复杂映射关系 123,124。 -
The DL approach gained significant momentum shortly after the introduction of MLP and the development of back-propagation algorithms in the 1980s and 1990s 10.
在 20 世纪 80 和 90 年代引入多层感知器(MLP)和反向传播算法发展后不久,深度学习方法获得了显著的发展动力 10。 -
DL techniques address the vanishing gradient problem more effectively compared to shallow models.
与浅层模型相比,深度学习技术能更有效地解决梯度消失问题。 -
Consequently, DL-based models exhibit superior capabilities in handling complex functions with high accuracy 6.
因此,基于深度学习的模型在以高精度处理复杂函数方面表现出卓越的能力 6。 -
The DL perspective has also recently gained momentum due to the unprecedented availability of extensive datasets and advanced algorithms 10,123.
由于海量数据集的前所未有的可用性和先进算法的出现,深度学习视角近期再次获得强劲动力 10,123。 -
DL methods construct linear or non-linear functions to reduce the correlation between the input data and output response as closely as possible through multi-layer network models.
深度学习方法通过多层网络模型构建线性或非线性函数,以尽可能减小输入数据与输出响应之间的相关性误差。 -
Hence, the ML techniques mentioned in the previous two sections have been transformed into DL models by augmenting the mapping layers.
因此,前两节中提到的机器学习技术通过增加映射层,已转化为深度学习模型。 -
Considering the LF problem, DL approaches require building complex networks which present superior advantages over classical techniques for multi-point scenarios in the profile.
考虑到负荷预测(LF)问题,深度学习方法需要构建复杂的网络,这在处理负荷曲线中的多点场景时比传统技术具有显著优势。 -
However, they also have disadvantages in terms of computational burden and restrictions to deterministic point forecasting 69.
然而,它们在计算负担以及局限于确定性点预测方面也存在缺点 69。 -
Despite dealing with the pros and cons of DL approaches for LF, their immense capability to capture short- and long-term dependencies on input data and have tractable options for computational issues make them even more preferable than shallow learning models.
尽管需要权衡深度学习方法在负荷预测中的优缺点,但其捕捉输入数据短期和长期依赖关系的巨大能力,以及解决计算问题的可行方案,使其比浅层学习模型更受欢迎。 -
The influential factors on electricity consumption can be classified as date-related, atmospheric, and economic factors 29.
影响电力消耗的因素可分为日期相关因素、大气因素和经济因素 29。 -
Moreover, specifying the precision of the prediction can be directly related to the feasible identifications of each decisive or descriptive variable in the load profile, as well as the learning type of the DL models.
此外,预测精度的确定与负荷曲线中每个决定性或描述性变量的可行识别,以及深度学习模型的学习类型直接相关。 -
DL models have frequently been referenced in the literature for the LF problem.
在关于负荷预测问题的文献中,深度学习模型被频繁引用。 -
Table 1 reviews the studies on the DL-based STLF problem in terms of the proposed techniques and the main ideas of the corresponding studies.
表 1 从提出的技术和相应研究的核心思想方面,综述了基于深度学习的短期负荷预测问题的研究。
| Ref. | Year | 提出的技术 (Proposed technique(s)) | 主要目标 (Main objective) |
|---|---|---|---|
| 27 | 2016 | DBN model with multiple layers of restricted Boltzmann machine network (RBM) 具有多层受限玻尔兹曼机网络 (RBM) 的深度信念网络 (DBN) 模型 | To compare and evaluate the performance of the proposed model with feedforward multi-layer perception (MLP) NN model. 将所提模型与前馈多层感知器 (MLP) 神经网络模型进行性能比较和评估。 |
| 28 | 2017 | RNNs 循环神经网络 (RNNs) | To exploit the potential of DL approach in LF. 挖掘深度学习方法在负荷预测 (LF) 中的潜力。 |
| 29 | 2018 | Deep feedforward network and probability density forecasting methods based on quantile regression and kernel density estimation 基于分位数回归和核密度估计的深度前馈网络及概率密度预测方法 | To conduct the comparative analysis in terms of the performance evaluations of the proposed method and other competitive methods. 对所提方法与其他竞争方法进行性能评估和比较分析。 |
| 30 | 2018 | Combination of LSTM and feed forward NN methods LSTM 与前馈神经网络方法的组合 | To search the best learning factor in the patterns of consumption trends on the day types. 搜索不同日期类型消费趋势模式中的最佳学习因子。 |
| 31 | 2018 | Feedforward and deep RNNs 前馈和深度 RNNs | To demonstrate the applicability of deep NNs for the aim of appliance-level STLF. 证明深度神经网络在电器级短期负荷预测 (STLF) 中的适用性。 |
| 32 | 2018 | Deep NN based model by combination of CNNs and variation autoencoders 基于 CNN 与变分自动编码器组合的深度神经网络模型 | To search rich feature extraction case in order to build generalised appliance-level LF by proposing deep NN based energy disaggregation structure. 通过提出基于深度神经网络的能源分解结构,搜索丰富的特征提取案例,以构建通用的电器级负荷预测。 |
| 33 | 2018 | Adapted DL algorithms of denoising autoencoder, RNN and rectangle type network 改进的去噪自动编码器、RNN 和矩形类型网络深度学习算法 | To address the high uncertainty in households' demand for STLF, a model is provided based on a feedforward ANN, along with a preprocessing stage employing energy disaggregation techniques. 针对家庭 STLF 的高不确定性,提供了一个基于前馈人工神经网络 (ANN) 且采用能源分解预处理技术的模型。 |
| 34 | 2018 | Deep NN with MLP 带有 MLP 的深度神经网络 | To find optimal operation procedure of the residential appliances using DL. 利用深度学习寻找住宅电器的最佳运行程序。 |
| 35 | 2018 | DL-based load profile clustering framework with convolutional autoencoder 带有卷积自动编码器的基于深度学习的负荷分布聚类框架 | To incorporate daily and seasonal variations into the cluster framework with reduced data dimensionality. 在数据降维的聚类框架中纳入每日和季节性变化。 |
| 36 | 2018 | Temporal ensemble learning model with kernel regression, SVR and other NN approaches. 结合核回归、SVR 和其他神经网络方法的时序集成学习模型 | To compensate the lack of multivariate data in the dataset by proposing ensemble approach based on temporal features. 通过提出基于时序特征的集成方法,弥补数据集中多元数据的缺乏。 |
| 37 | 2019 | LSTM with multi-input multi-output 多输入多输出 LSTM | To address non-linearity and other ill-defined dependencies in the data, they employ a novel prediction framework that is entirely driven by historical data, eliminating the need for information about dataset characteristics. 采用完全由历史数据驱动的新型预测框架来解决数据中的非线性和其他定义不良的依赖关系,从而消除对数据集特征信息的依赖。 |
| 38 | 2019 | Supervised based DL models with one-step secant backpropagation ANN and Fletcher-Broyden-Shanno-Goldfarb quasi-Newton network 基于一步割线反向传播 ANN 和拟牛顿网络的有监督深度学习模型 | To overcome the design challenges for district level electricity distribution by DL forecasting model. 通过深度学习预测模型克服地区级电力分配的设计挑战。 |
| 39 | 2019 | DL forecasting by probability density functions 通过概率密度函数进行的深度学习预测 | To consider the influencing factors on the electric consumption in a DL forecasting model. 在深度学习预测模型中考虑用电量的影响因素。 |
| 3 | 2019 | Multiple-inputs multiple-outputs deep RNNs 多输入多输出深度 RNNs | To consider relationship between price and load, and proposes two DL forecast models to utilise further to the new DR programs. 考虑价格与负荷之间的关系,并提出两个深度学习预测模型以进一步利用新的需求响应 (DR) 计划。 |
| 40 | 2019 | Ensemble model with gradient boosting (GB) regression, MLP and LSTM 带有梯度提升 (GB) 回归、MLP 和 LSTM 的集成模型 | To present stacked multi-learning ensemble model for near real-time residential energy demand forecasting. 提出用于近实时住宅能源需求预测的堆叠多学习集成模型。 |
| 41 | 2019 | Probabilistic LF approach with multitask Bayesian DL 采用多任务贝叶斯深度学习的概率负荷预测方法 | Given the uncertainty and volatile nature of residential load, they have developed a Bayesian DL model with a high level of reliability and stability. 针对住宅负荷的不确定性和波动性,开发了具有高可靠性和稳定性的贝叶斯深度学习模型。 |
| 42 | 2019 | Probabilistic baseline estimation framework with DL-based optimal clustering stage 带有深度学习优化聚类阶段的概率基准估计框架 | To improve the prediction process by considering the large number of daily patterns with DL-based clustering approach. 通过采用基于深度学习的聚类方法考虑大量的每日模式,从而改进预测过程。 |
| 43 | 2019 | CNN with recurrence plots which encode time series data into images 将时间序列数据编码为图像的带有递归图的 CNN | To propose a DL-based LF solution for DR applications targeting single residential loads, which typically exhibit higher volatility compared to aggregated loads. 为针对单个住宅负荷(通常波动性高于聚合负荷)的需求响应应用提出基于深度学习的负荷预测方案。 |
| 44 | 2019 | RNN with differentiable architecture search 带有可微分架构搜索的 RNN | To show the merit of the proposed RNN with optimised hyper parameters. 展示具有优化超参数的所提 RNN 的优点。 |
| 45 | 2019 | Hybrid ensemble deep belief learning approach with k-NN classification method 结合 k-NN 分类方法的混合集成深度信念学习方法 | To propose an ensemble model that leverages the high generalisation, adaptability, and non-linear mapping capabilities of DL. 提出一种利用深度学习的高泛化性、适应性和非线性映射能力的集成模型。 |
| 46 | 2019 | DBN model with Gauss-Bernoulli restricted BMN 带有 Gauss-Bernoulli 受限 RBM 的深度信念网络模型 | To enhance the effectiveness of the DBN-based LF by customising the RBM technique and incorporating optimisation procedures to fine-tune the network parameters. 通过定制 RBM 技术并纳入优化程序微调网络参数,增强基于 DBN 的负荷预测有效性。 |
| 47 | 2019 | LSTM 长短期记忆网络 (LSTM) | To improve performance and incorporate weather-based variables into the proposed LF model for assessing discomfort index. 提高性能并在所提负荷预测模型中纳入基于天气的变量以评估不适指数。 |
| 48 | 2019 | Stacked bidirectional LSTM 堆叠双向 LSTM | To incorporate meteorological data, a significant source of uncertainty, into the proposed model. 在所提模型中纳入气象数据(这一重要的不确定性来源)。 |
| 49 | 2019 | Deep NN-CNN 深度神经网络-卷积神经网络 (Deep NN-CNN) | To provide integrated approach with adequate accuracy to pre-process and analyse the consumption. 提供具有足够准确性的集成方法来预处理和分析消费数据。 |
| 50 | 2020 | RNN-LSTM 循环神经网络-长短期记忆网络 (RNN-LSTM) | To facilitate a comparative analysis, the study first discloses the input-output relationship of STLF data and offers a suitable model. Subsequently, it identifies the most appropriate combination of feature sets and an efficient encoding mechanism. 为方便对比分析,该研究揭示了 STLF 数据的输入输出关系并提供合适模型。随后识别了特征集与编码机制的最佳组合。 |
| 21 | 2020 | LSTM, CNN, GRU and stacked autoencoder LSTM, CNN, GRU 和堆叠自动编码器 | To test the performance of competitive DL techniques by a real case study. 通过真实案例研究测试竞争性深度学习技术的性能。 |
| 51 | 2020 | Video pixel networks based one-dimensional CNNs with LSTM or GRU techniques 基于一维 CNN 与 LSTM 或 GRU 技术的视频像素网络 | To obtain superior performance by apply point estimation instead of confidence interval estimation for the time series forecast. 通过对时间序列预测应用点估计而非置信区间估计,获得更优的性能。 |
| 52 | 2020 | Sequence to sequence and a two dimensional CNNs 序列到序列 (Seq2Seq) 和二维 CNNs | To obtain adequate prediction accuracy under poor information case. 在信息贫乏的情况下获得足够的预测准确度。 |
| 53 | 2020 | Multi-objective DBN with empirical mode decomposition 带有经验模态分解的多目标 DBN | To introduce a LF model that offers superior accuracy and greater generalisation ability compared to similar competitive methods. 引入一种比类似竞争方法具有更高精度和更强泛化能力的负荷预测模型。 |
| 54 | 2020 | Supervised ML forecasting models by Gaussian kernel regression with random feature expansion and nonparametric based k-NN 结合随机特征扩展的高斯核回归与非参数 k-NN 的有监督机器学习预测模型 | To introduce novel LD forecast models with enhanced predictive potential for speed and accuracy. 引入具有增强预测潜力、速度和准确性的新型负荷需求预测模型。 |
| 55 | 2020 | Quantile regression CNN 分位数回归 CNN | To demonstrate the effectiveness of the proposed model in comparison to other competitive approaches. 证明所提模型与其他竞争方法相比的有效性。 |
| 5 | 2020 | CNN for probabilistic LF 用于概率负荷预测的 CNN | To obtain more reliable and sharper load probability distributions by probabilistic LF models. 通过概率负荷预测模型获得更可靠、更清晰的负荷概率分布。 |
| 56 | 2020 | Hybrid forecast model including modified mutual information, factored conditional restricted BMN, and genetic wind driven optimisation techniques 结合改进互信息、因子条件受限 RBM 和遗传风驱动优化技术的混合预测模型 | To propose adaptive DL approach for LF. 提出一种用于负荷预测的自适应深度学习方法。 |
| 57 | 2020 | Cluster-based aggregate forecasting 基于聚类的聚合预测 | To offer random clustering baselines to get higher accuracy in load prediction. 提供随机聚类基准以在负荷预测中获得更高的准确度。 |
| 58 | 2020 | Hybrid model of empirical mode decomposition and GRU 经验模态分解与 GRU 的混合模型 | To enhance the forecasting performance, a hybrid procedure that incorporates the decomposing process instead of using LSTM directly is proposed. 提出一种纳入分解过程而非直接使用 LSTM 的混合程序以增强预测性能。 |
| 59 | 2020 | LSTM 长短期记忆网络 (LSTM) | To show the effectiveness of LSTM against the traditional networks. 展示 LSTM 相对于传统网络的有效性。 |
| 60 | 2020 | Blended decision tree, k-NN, feedforward NN, and deep feedforward NN 混合决策树、k-NN、前馈神经网络和深度前馈神经网络 | To consider various factors, including date, exact time, climate variables, and artificial predictive variables using the proposed mixed model. 使用所提混合模型考虑日期、时间、气候和人工预测变量等多种因素。 |
| 61 | 2020 | LSTM and deep feedforward NN LSTM 和深度前馈神经网络 | To capture both members' interdependencies by LSTM and climate factors on LF by deep feedforward NN. 通过深度前馈神经网络捕捉 LSTM 成员间的相互依赖关系以及气候因素对负荷预测的影响。 |
| 62 | 2020 | DL-based electricity demand forecasting model by sequence to sequence regression technique 采用序列到序列 (Seq2Seq) 回归技术的基于深度学习的电力需求预测模型 | To include input ranking feature selection analysis with RReliefF algorithm. 包含使用 RReliefF 算法的输入排名特征选择分析。 |
| 63 | 2020 | LSTM 长短期记忆网络 (LSTM) | To propose priority based framework for economical utilisation of household devices. 提出一种基于优先级的家用设备经济利用框架。 |
| 64 | 2020 | TCN 时间卷积网络 (TCN) | To present precocious accuracy in LF problem by extracting the auxiliary input from the residential consumption components by the proposed framework. 通过所提框架从住宅消费组件中提取辅助输入,展现负荷预测的精度。 |
| 65 | 2020 | LSTM-GRU 长短期记忆网络-门控循环单元 (LSTM-GRU) | To develop time series forecasting model by some RNN types for the agriculture load. 为农业负荷开发基于某些 RNN 类型的序列预测模型。 |
| 66 | 2020 | Combination of LSTM k-means clustering LSTM 与 k-means 聚类的组合 | To uncover similarities in consumption patterns that enable the forecasting model to effectively mitigate the overfitting issue. 揭示消费模式的相似性,使预测模型能有效缓解过拟合问题。 |
| 67 | 2020 | RNN 循环神经网络 (RNN) | To propose an incentive based DR program together with DL-based forecasting model 提出一个基于激励的需求响应计划以及深度学习预测模型。 |
| 68 | 2021 | Online adaptive RNN 在线自适应 RNN | To achieve higher accuracy than the stand-alone offline LSTM network and some online algorithms. They employ an adaptation mechanism that allows them to capture newly arriving data. 实现比离线单机 LSTM 网络和某些在线算法更高的准确度。他们采用一种自适应机制来捕捉新到达的数据。 |
| 69 | 2021 | Hybrid interval forecasting model combining k-NN optimised by genetic algorithm (GA), DBN and self-adaptive kernel density estimation techniques 结合经遗传算法 (GA) 优化的 k-NN、深度信念网络和自适应核密度估计技术的混合区间预测模型 | To demonstrate the success of the proposed interval forecasting model in terms of accuracy and flexibility, without compromising the simplicity of the forecasting process. 证明所提区间预测模型在准确性和灵活性方面的成功,且不牺牲预测过程的简便性。 |
| 70 | 2021 | Trilinear deep residual network with self-adaptive dropout method based on hierarchical clustering and Gaussian noise. 基于分层聚类和高斯噪声的带有自适应 dropout 方法的三线性深度残差网络 | To propose a robust model that mitigates the issues of vanishing and exploding gradients, along with addressing overfitting, while simultaneously achieving improved forecasting accuracy. 提出一种稳健模型,缓解梯度消失和爆炸问题,同时解决过拟合,并提高预测准确度。 |
| 71 | 2021 | The algorithms of concrete dropouts, deep ensembles, Bayesian NNs, deep Gaussian processes, and functional neural processes 混凝土 Dropout、深度集成、贝叶斯神经网络、深度高斯过程和泛函神经过程算法 | To explore the probabilistic extensions and performance potential of DL algorithms. 探索深度学习算法的概率扩展和性能潜力。 |
| 72 | 2021 | k-means CNN-LSTM forecast model with clustering approach 带有聚类方法的 k-means CNN-LSTM 预测模型 | To obtain reliable energy consumption data for an academic building for DR application. 为学术建筑的需求响应应用获取可靠的能耗数据。 |
| 73 | 2021 | Non-linear fully connected feed-forward ANN by autoencoder with localised stochastic sensitivity 带有局部随机灵敏度的基于自动编码器的非线性全连接前馈神经网络 | To propose a DL model aimed at enhancing prediction accuracy and reliability by minimising the error, which is represented by the training error and stochastic sensitivity. 提出一种旨在通过最小化误差(由训练误差和随机灵敏度表示)来提高预测精度和可靠性的深度学习模型。 |
| 74 | 2021 | Bidirectional LSTM based sequence to sequence regression approach 基于双向 LSTM 的序列到序列回归方法 | To evaluate the proposed model against other competitive techniques for both public holidays and normal days in terms of accuracy and the availability of limited data. 在准确性和有限数据可用性方面,针对其他竞争技术评估所提模型在公共假期和普通日期的表现。 |
| 75 | 2021 | Ensemble learning model using multi-modal multi-objective evolutionary algorithm and random vector functional link network based ensemble learning 使用多模态多目标进化算法和随机向量函数链路网络的集成学习模型 | To discover additional trade-off multimodal solutions by harnessing the mapping capabilities of the proposed ensemble learning approach in the context of STLF problems. 在短期负荷预测背景下,通过利用集成学习的映射能力发现额外的权衡多模态解决方案。 |
| 76 | 2021 | Asynchronous deep reinforcement learning (RL) based model with deterministic policy gradient 带有确定性策略梯度的异步深度强化学习 (RL) 模型 | To address the high temporal correlation and convergence instability issues of STLF using a deep RL model. 使用深度强化学习模型解决短期负荷预测的高时间相关性和收敛不稳定性问题。 |
| 77 | 2021 | Deep RNN 深度循环神经网络 (Deep RNN) | To increase the forecasting accuracy and performance under the uncertain model dynamics. 提高不确定模型动态下的预测准确性和性能。 |
| 78 | 2021 | CNN 卷积神经网络 (CNN) | To enhance the model's ability to capture non-linear relationships, a feature selection process is proposed. 提出一种特征选择过程以增强模型捕获非线性关系的能力。 |
| 79 | 2021 | RNN, vanilla LSTM, stacked LSTM, bidirectional LSTM and GRU RNN, Vanilla LSTM, 堆叠 LSTM, 双向 LSTM 和 GRU | To evaluate the performance of LF by comparing RNN, three variants of the LSTM model, and GRU. 通过比较 RNN、三种 LSTM 变体和 GRU 来评估负荷预测性能。 |
| 80 | 2021 | Deep RL 深度强化学习 (Deep RL) | To consider using a pre-trained dataset instead of a random one when proposing LF results to optimise DR applications. 在提出负荷预测结果以优化需求响应应用时,考虑使用预训练数据集而非随机数据集。 |
| 81 | 2021 | Hybrid network consisted the layers of autoencoder LSTM, bidirectional LSTM, and stack of LSTM 由自动编码器、双向 LSTM 和堆叠 LSTM 组成的混合网络 | To demonstrate the superiority of the proposed hybrid model when tested with the dataset collected from a residential home, as compared to previous similar studies. 证明所提混合模型在住宅家庭数据集测试中优于以往类似研究。 |
| 82 | 2021 | Comparative analysis with linear regression, tree-based regression, linear support vector machine (SVM), quadratic SVM, cubic SVM and RNN 线性回归、树基回归、线性 SVM、二次 SVM、三次 SVM 和 RNN 的对比分析 | To evaluate the performance of various ML and DL-based residential LF models. 评估各种机器学习和深度学习住宅负荷预测模型的性能。 |
| 83 | 2021 | A prioritised experience replay automated RL 优先级经验回放自动化强化学习 | To provide a coupled approach with multi period forecasting and DR program. 提供一种耦合多周期预测和需求响应计划的方法。 |
| 84 | 2021 | Past vector similarity 过去向量相似性 | To forecast the load at the finer granularity by extracting the exact load patterns of the occupants regarding to their routine and socio-economic values. 通过提取住户日常习惯和社会经济价值的精确负荷模式,进行更细粒度的负荷预测。 |
| 85 | 2021 | CNN with squeeze-and-excitation modules 带有挤压和激励模块 (Squeeze-and-Excitation) 的 CNN | To represent the strong relationship between climates variable and residential volatile LD by the proposed model. 展现气候变量与住宅波动负荷需求之间的强相关性。 |
| 86 | 2021 | RNN with LSTM 带有 LSTM 的循环神经网络 | To assess the predictive performance of the proposed model in comparison to other models that use the same dataset. 在使用相同数据集的情况下,将所提模型的预测性能与其他模型进行比较。 |
| 87 | 2021 | Residential LF framework combined by k-means clustering algorithm and federated learning 结合 k-means 聚类算法和联邦学习的住宅负荷预测框架 | To establish a cooperative training procedure by utilising fine-grained monitored consumption data. 利用细粒度监控的消费数据建立合作训练程序。 |
| 88 | 2021 | Separate use of LSTM and GRU 单独使用 LSTM 和 GRU | To show that the accuracy performance of STLF better than the longer focused forecasting models. 展示短期负荷预测的准确性性能优于长周期关注的预测模型。 |
| 89 | 2021 | Deep forward NN by automated selecting the best Box-Jenkins models 通过自动选择最佳 Box-Jenkins 模型的深度前馈神经网络 | To obtain higher accuracy than the shallow networks. 获得比浅层网络更高的准确度。 |
| 90 | 2021 | CNN sequence to sequence model with an attention mechanism based on a multi-task learning method 基于多任务学习方法的带有注意机制的 CNN 序列到序列模型 | To demonstrate the superior accuracy performance of the proposed model. 证明所提模型优异的准确性能。 |
| 91 | 2022 | Backward-eliminated exhaustive ensemble model for future selection method, and the LF techniques of k-NN, CNN, RNN and SVR. 用于特征选择的后向消除穷举集成模型及 k-NN, CNN, RNN, SVR 技术 | To obtain higher accuracy by proposing backward-eliminated exhaustive approach for feature selection technique. 通过提出用于特征选择技术的后向消除穷举法来获得更高的准确度。 |
| 92 | 2022 | LSTM by mix-up and transfer learning techniques 通过 mix-up 和迁移学习技术的 LSTM | To propose reliable model by considering the lack of sufficient historical data on the consumption which reduces the accuracy. 通过考虑减少准确性的历史消费数据缺乏问题,提出可靠模型。 |
| 93 | 2022 | LSTM, federated stochastic gradient descent and federated averaging. LSTM, 联邦随机梯度下降和联邦平均 | To train a single federated learning based model when dealing with multiple smart meters, eliminating the need to share local data. 在处理多个智能电表时训练单一的联邦学习模型,消除共享本地数据的需求。 |
| 94 | 2022 | Ensemble model with LSTM, GRU, and TCN 带有 LSTM, GRU 和 TCN 的集成模型 | To demonstrate that the proposed ensemble models achieve better performance than the traditional individual models. 证明所提集成模型比传统的单一模型达到更好的性能。 |
| 95 | 2022 | CNN based on wavelet and varying mode decomposition 基于小波和变模态分解的 CNN | To extract more detailed spectral and temporal information in order to enhance the forecasting performance, especially when exogenous data are 提取更详细的光谱和时间信息以增强预测性能。 |
| 96 | 2022 | Federated learning model with ANN architecture 带有 ANN 架构的联邦学习模型 | To address privacy and security requirements for residential LF through the smart meter data with dynamic power demand. 通过具有动态电力需求的智能电表数据解决住宅负荷预测的隐私和安全要求。 |
| 97 | 2022 | Consecutive applications of STLF network with a layer of GRUs and STLF network constructed by stacking several TCNs 带有门控循环单元层和通过堆叠多个 TCN 构建的 STLF 网络的连续应用 | To enhance the DL-based elastic model while maintaining good performance under varying conditions, including changes in accommodation, temperature, humidity, and wind speed. 在包括住宿、温度、湿度和风速变化在内的各种条件下,增强深度学习弹性模型。 |
| 98 | 2022 | Hybrid model including the CNN and an attention-based sequence to sequence network. 包含 CNN 和注意机制序列到序列网络的混合模型 | To improve the forecasting performance by capturing the long-term spatial and temporal features of the data. 通过捕捉数据的长期空间和时间特征来提高预测性能。 |
| 99 | 2022 | Two stage encoder-decoder architecture based on receptive field based dilated causal convolutional and bidirectional LSTM networks. 基于感受野扩张因果卷积和双向 LSTM 网络的阶段性编解码架构 | To increase the STLF performance by encoder-decoder configuration. 通过编解码器配置提高短期负荷预测性能。 |
| 100 | 2022 | LSTM with back propagation NN and XGBoost 带有反向传播神经网络和 XGBoost 的 LSTM | To find a moderate solution to the contradiction between forecasting accuracy and calculation speed. 寻找预测准确性与计算速度之间矛盾的适中解决方案。 |
| 101 | 2022 | A dynamic ANN model motivated by meta-learning 受元学习启发的动态神经网络模型 | To introduce a fine-tuning approach for predicting highly non-stationary points and implementing a robust forecasting procedure. 引入一种微调方法来预测高度非平稳点并实施稳健的预测程序。 |
| 102 | 2022 | Ensemble structure based on LSTM and XGBoost 基于 LSTM 和 XGBoost 的集成结构 | To propose a more accurate and scalable model while mitigating some of the limitations of current approaches. 提出一种更准确、可扩展的模型,同时减轻当前方法的局限性。 |
| 103 | 2022 | Bidirectional LSTM 双向 LSTM | To propose seasonal segmentation to achieve relatively higher accuracy in the forecasting procedure by taking into consideration the seasonal factors specific to the dataset of the geographical territory. 提出季节性细分,通过考虑特定地理区域的季节因素实现更高的准确度。 |
| 4 | 2022 | A self-adaptive DL model with particle swarm optimisation (PSO) 带有粒子群算法 (PSO) 的自适应深度学习模型 | To improve the accuracy, robustness, repeatability and self-adaptive capability in load prediction. 提高负荷预测在不良预测中的准确性、稳健性、重复性和自适应能力。 |
| 104 | 2022 | Ensemble model with XGBoost and light-gradient boosting machine (GBM), RF regression and stacking regressor 带有 XGBoost, LightGBM, 随机森林回归和堆叠回归器的集成模型 | To analyse the correlation between various variables in the dataset and testing the model performance for most influential variables. 分析数据集中各变量的相关性,并测试模型对最具影响力变量的性能。 |
| 105 | 2022 | A multi-channel bidirectional nested LSTM framework 多通道双向嵌套 LSTM 框架 | To improve the prediction accuracy by following multiple sub-signals processing approach. 通过遵循多子信号处理方法来提高预测准确性。 |
| 106 | 2022 | XGBoost 极致梯度提升 (XGBoost) | To determine the occurrence range of peak load considering the load, weather and time factors. 考虑负荷、天气和时间因素,确定峰值负荷的发生范围。 |
| 107 | 2022 | Autoencoder based LSTM 基于自动编码器的 LSTM | To propose a dual-channel structure in the encoder part for extracting different levels of time series data. Additionally, they suggest a three-channel output structure in the decoder part to enhance the model's representation ability. 在编码器部分提出双通道结构以提取不同水平的时序数据;在解码器部分提出三通道结构。 |
| 108 | 2022 | Hybrid model called as variational autoencoder bidirectional LSTM 变分自动编码器双向 LSTM 混合模型 | To present the effectiveness of the proposed method over the classical models. 展示所提方法优于经典模型的有效性。 |
| 109 | 2022 | Hybrid model with integrated GA bidirectional GRU 带有集成遗传算法的双向 GRU 混合模型 | To present more stable and reliable model than the models developed by the classical methods. 展示比经典方法开发的模型更稳定、更可靠的性能。 |
| 110 | 2022 | ML models of SVR, RF, XGBoost, light-GBM, adaptive boosting, bidirectional LSTM, GRU, and a DL regression model. SVR, RF, XGBoost, LightGBM, 适应性提升, 双向 LSTM, GRU 和深度学习回归模型 | To specify best features and searching for nest ML model for predicting the hourly demand. 指定最佳特征并寻找最佳机器学习模型来预测每小时需求。 |
| 111 | 2022 | Hybrid structure with empirical mode decomposition, one-dimensional CNN, TCN, a self-attention mechanism, and a LSTM 带有经验模态分解、一维 CNN、时间卷积网络 (TCN)、自注意机制和 LSTM 的混合结构 | To propose hybrid model having more stable and accurate prediction for STLF problem. 为短期负荷预测问题提出更稳定、准确的混合模型。 |
| 112 | 2022 | ML approach with deep ANN and decision tree-based prediction 带有深度神经网络和基于决策树预测的机器学习方法 | To show that the ML algorithms and regression analysis have adequate accuracy for LF. 展示机器学习算法和回归分析在负荷预测中具有足够的准确性。 |
| 113 | 2022 | Hybrid structure with CNN, LSTM and MLP 带有 CNN, LSTM 和 MLP 的混合结构 | To propose a solution that offers both adequate accuracy and robustness for LF problems. 为负荷预测问题提出一个兼具准确性和稳健性的解决方案。 |
| 114 | 2022 | Joint structure with multi-feature fusion, self-attention mechanism, convolutional graph network 带有多特征融合、自注意机制、卷积图网络的联合结构 | To obtain better prediction performance than some of the benchmark models. 获得比某些基准模型更好的预测性能。 |
-
This table provides a broad perspective for prospective research on DL-based STLF problems.
该表为基于深度学习的 STLF 问题的未来研究提供了广泛的视角。 -
It summarises the related studies in the literature in terms of the connection between the adopted techniques and potential contributions to the literature.
它根据所采用的技术与对文献的潜在贡献之间的联系,总结了文献中的相关研究。 -
In this manner, the proposed techniques have been specified along with the main objectives of the study to clarify the potential of these studies.
通过这种方式,明确了所提出的技术以及研究的主要目标,从而阐明了这些研究的潜力。 -
Hence, new research on the proposed solution techniques can be initiated easily, as well as potential comparative analyses may be dealt with.
因此,可以轻松开展针对所提解决方案技术的新研究,并进行潜在的对比分析。 -
Table 2 presents the specifications of the dataset from the paper referenced by the keywords of DL and STLF.
表 2 展示了通过"深度学习"和"短期负荷预测"关键词引用的论文中的数据集规范。 -
In Table 2, LT, reference (Ref) studies, dataset origin, data SR and the specific dataset are given, respectively.
在表 2 中,分别给出了负荷类型(LT)、参考文献(Ref)、数据集来源、数据采样率(SR)以及特定数据集。
| LT (负荷类型) | Ref. (引用) | Origin (来源) | SR (分辨率) | Dataset (数据集) |
|---|---|---|---|---|
| Residential load 住宅负荷 | 32,33,40,105 | UK 英国 | 1 h | Domestic appliance-level electricity (UK-DALE) dataset 英国国内设备级用电 (UK-DALE) 数据集 |
| 67,100 | Austin/USA 美国奥斯汀 | 1 h | Pecan street inc dataport dataset Pecan Street Inc. 数据港数据集 | |
| 92 | California/USA 美国加州 | 1 h | OpenEI-National renewable energy laboratory dataset OpenEI-国家可再生能源实验室数据集 | |
| 68,93 | London/UK 英国伦敦 | 1 h | London hydro dataset 伦敦水利数据集 | |
| 42,96 | London/UK 英国伦敦 | 30 m | Low carbon London project dataset 低碳伦敦项目数据集 | |
| 31 | USA 美国 | 1 h & 1-5-30 m | UMass trace repository/Smart datasets* 麻省大学追踪库/Smart 数据集* | |
| 95 | Morocco 摩洛哥 | 1 h | Moroccan buildings' electricity consumption dataset 摩洛哥建筑耗电量数据集 | |
| 97 | France & Belgium 法国和比利时 | 1 & 10 m | The individual household electric power consumption and the appliances energy prediction (AEP) datasets 个人家庭用电量与电器能量预测 (AEP) 数据集 | |
| 99 | Lahore/Pakistan 巴基斯坦拉合尔 | 15 m | Lahore electric supply company dataset 拉合尔供电公司数据集 | |
| 43,58,77,86 | California/USA 美国加州 | 1 m - 1 h | UCI ML repository dataset (UCI public dataset) UCI 机器学习库数据集 (UCI 公开数据集) | |
| 34 | USA 美国 | 1 m | UMass smart home dataset 麻省大学智能家居数据集 | |
| 98 | California/USA 美国加州 | 1 h | Individual household electric power consumption dataset 个人家庭用电量数据集 | |
| 74 | Pakistan 巴基斯坦 | 1 d | FESCO dataset FESCO 数据集 | |
| 64 | Canada 加拿大 | 1 m | AMPds2 dataset AMPds2 数据集 | |
| 41 | Ireland & Australia 爱尔兰和澳大利亚 | 30 m | The Irish commission for energy regulation and Australian SG city project datasets 爱尔兰能源监管委员会与澳大利亚智能电网城市项目数据集 | |
| 81 | Paris/France 法国巴黎 | 1 d | The individual household electric power consumption (IHEPC) Dataset 个人家庭用电量 (IHEPC) 数据集 | |
| 63 | Alaska/USA 美国阿拉斯加 | 1 h | Open energy data initiative (OEDI) dataset 开放能源数据倡议 (OEDI) 数据集 | |
| 87 | Sydney/Australian 澳大利亚悉尼 | 1 h | Australian "SG, Smart City" customer trial dataset 澳大利亚"智能电网,智能城市"客户试验数据集 | |
| 66 | Ireland 爱尔兰 | 30 m | Smart metering data on the electricity customer behaviour trials initiated by the commission for energy regulation in Ireland 爱尔兰能源监管委员会发起的电力客户行为试验智能计量数据 | |
| 84 | New South Wales/Australia and Eskilstuna/Sweden 澳大利亚新南威尔士与瑞典埃斯基尔斯蒂纳 | 1 h | Specific 特定数据集 | |
| 82 | Tallinn/Estonia 爱沙尼亚塔林 | 1 m | Specific 特定数据集 | |
| 117 | Tomsk/Russia 俄罗斯托木斯克 | 1 d | Specific 特定数据集 | |
| 29,50 | Jiangsu/China 中国江苏 | 1 m - 1 h | Specific 特定数据集 | |
| 28 | New England-Ireland/UK 新英格兰-爱尔兰/英国 | 1 h | Specific 特定数据集 | |
| Operator load 运营商负荷 | 94 | Algeria 阿尔及利亚 | 5 m | Bejaia concession of Algerian electricity and gas distribution company (SADEG) dataset 阿尔及利亚电力和天然气分配公司 (SADEG) 贝贾亚特许经营数据集 |
| 3,56 | USA 美国 | 5 m | PJM electricity market dataset PJM 电力市场数据集 | |
| 51 | Istanbul/Turkey 土耳其伊斯坦布尔 | 1 h | CK Bogazici Elektrik dataset CK Bogazici Elektrik 数据集 | |
| 101 | Belgium 比利时 | 1 h | Elia: Belgian transmission system operator dataset Elia:比利时输电系统运营商数据集 | |
| 44,53,75 | Tasmania-Queensland-New South Wales/Australia 澳大利亚塔斯马尼亚-昆士兰-新南威尔士 | 30-60 m | Australian energy market operator (AEMO) 澳大利亚能源市场运营商 (AEMO) | |
| 45 | Eastern China & Eastern Australia 中国东部和澳大利亚东部 | 15 m | Ausgrid dataset Ausgrid 数据集 | |
| 47,62 | Delhi 德里 | 1 h | Tata power Delhi distribution limited dataset 塔塔电力德里分配有限公司数据集 | |
| 3,5,21,70,76,89,111 | New England/USA 美国新英格兰 | 1 h | Independent System Operator-New England (ISO-NE) dataset 新英格兰独立系统运营商 (ISO-NE) 数据集 | |
| 55,85 | USA 美国 | 1 h | Global energy forecasting competition (GEFCom) 2014 dataset 2014 年全球能源预测竞赛 (GEFCom) 数据集 | |
| 76 | USA 美国 | 1 h | Global energy forecasting competition (GEFCom) 2017 dataset 2017 年全球能源预测竞赛 (GEFCom) 数据集 | |
| 73 | France, Germany, Romania, and Spain 法国、德国、罗马尼亚和西班牙 | 1 h | ENTSO-E data portal ENTSO-E 数据门户 | |
| 37 | Chandigarh/India 印度钱迪加尔 | 1 d | UT Chandigarh dataset 钱迪加尔直辖区数据集 | |
| 107 | Canada 加拿大 | 1 h | Alberta electric system operator 艾伯塔省电力系统运营商 | |
| 27 | Macedonia 马其顿 | 1 h | Electricity transmission system operator of Macedonia (MEPSO) dataset 马其顿输电系统运营商 (MEPSO) 数据集 | |
| 109 | Bangladesh 孟加拉国 | 30 m | Bangladesh power system network dataset 孟加拉国电力系统网络数据集 | |
| 46 | Tianjin/China 中国天津 | 15 m | China Tianjin power grid 中国天津电网 | |
| 86 | Maine/USA 美国缅因州 | 1 h | Electricity data - U.S. energy information administration (EIA) 用电数据 - 美国能源信息署 (EIA) | |
| 36 | Los Angeles-USA 美国洛杉矶 | 15 m | Los Angeles department of water and power (LADWP) dataset 洛杉矶水电局 (LADWP) 数据集 | |
| 88 | France 法国 | 1 h | Dataset on the daily electricity load of France 法国每日电力负荷数据集 | |
| 48 | Scotland 苏格兰 | 1 h | Dataset of distribution networks of Scotland 苏格兰配电网数据集 | |
| 91 | Czech Republic 捷克共和国 | 30 m | Czech Republic electricity load dataset 捷克共和国电力负荷数据集 | |
| 110 | Panama 巴拿马 | 1 h | Panama's power system dataset 巴拿马电力系统数据集 | |
| 112 | Ontario/Canada 加拿大安大略省 | 1 h | Independent electricity system operator (IESO) 独立电力系统运营商 (IESO) | |
| 113 | Mayotte 马约特 | 30 m | Electricity of Mayotte (EDM) dataset 马约特电力 (EDM) 数据集 | |
| 113 | Panama 巴拿马 | 1 h | Panama Electricity LF from Kaggle dataset 来自 Kaggle 的巴拿马电力负荷预测数据集 | |
| 114 | China 中国 | 1 h | Shandong data open network in China - Grid bus load dataset 中国山东数据开放网络 - 电网母线负荷数据集 | |
| 61,80 | Toronto-Ontario/Canada 加拿大安大略省多伦多 | 1 h-5 m | Independent electricity system operator (IESO) dataset 独立电力系统运营商 (IESO) 数据集 | |
| 108 | Tabriz/Iran 伊朗大不里士 | 1 h | Distribution network of Tabriz city dataset 大不里士市配电网数据集 | |
| 71 | Germany 德国 | 1 h | Specific 特定数据集 | |
| 59 | Tien Giang/Vietnam 越南前江 | 1 d | Specific 特定数据集 | |
| 118 | Zhejiang/China and New Zealand 中国浙江和新西兰 | 1 h | Specific 特定数据集 | |
| 106 | Shanghai/China 中国上海 | 30 m | Specific 特定数据集 | |
| 103 | Madhya Pradesh/India 印度中央邦 | 15 m | Specific 特定数据集 | |
| 102 | Spain 西班牙 | 10 m | Specific 特定数据集 | |
| 69 | Australia 澳大利亚 | 30 m | Specific 特定数据集 | |
| 83 | China 中国 | 1 h | Specific 特定数据集 | |
| Other loads 其他负荷 | 90 | China 中国 | 1 h | Integrated energy microgrid dataset on industrial loads 工业负荷综合能源微网数据集 |
| 65 | India 印度 | 30 m | MERC Interim Report, AMR dataset (agriculture load) MERC 中期报告,AMR 数据集(农业负荷) | |
| 4 | Bristol/England 英国布里斯托 | 1 h | Campus building dataset 校园建筑数据集 | |
| 119 | South Korea 韩国 | 1 h | Korea electric power corporation (KEPCO) dataset on industrial load 韩国电力公司 (KEPCO) 工业负荷数据集 | |
| 78 | Zurich/Switzerland 瑞士苏黎世 | 1 h | The building data genome project dataset on public buildings 公共建筑数据基因组项目数据集 | |
| 30 | Japan 日本 | 30 m | Power company dataset on industrial load 电力公司工业负荷数据集 | |
| 120 | China 中国 | 30 m | Carbon culture platform dataset on public buildings 公共建筑碳文化平台数据集 | |
| 72 | Bombay/India 印度孟买 | 15 m | Laboratory SEI. academic building dataset SEI 实验室学术建筑数据集 | |
| 52 | Shandong/China 中国山东 | 1 d | Specific 特定数据集 |
-
LT defines the types of load such as residential, operator or aggregated, industrial, agriculture or public buildings loads.
LT 定义了负荷类型,如住宅、运营商或聚合、工业、农业或公共建筑负荷。 -
In this manner, operator data is logged as mixed types of data by utility companies in aggregated form.
在这种方式下,运营商数据是由公用事业公司以聚合形式记录的混合类型数据。 -
Besides, the origin shows the country in which the data is collected.
此外,来源(Origin)显示了收集数据的国家。 -
SR is the granularity of the data at the corresponding study, and the time resolution may be various for the dataset origin.
SR 是相应研究中的数据粒度,其时间分辨率可能因数据集来源而异。 -
For SR, the time periods of minute, hour and day are abbreviated as m, h and d, respectively.
对于采样率,分钟、小时和天的时间段分别缩写为 m、h 和 d。 -
Finally, the dataset specifies the type and specific source of the collected data.
最后,数据集指定了所收集数据的类型和具体来源。 -
The dataset may be taken from data metering centres which are given in Table 2 or the data is obtained by the authors. For the second case, the dataset part of the figure is typed as specific.
数据集可能取自表 2 中给出的数据计量中心,或者是作者自行获取的。对于第二种情况,图中的数据集部分被标注为"特定(specific)"。
5. 基于深度学习的 STLF 问题常用技术
-
DL techniques in Table 1 can be viewed as evolved or extended versions of ANNs.
表 1 中的深度学习(DL)技术可以看作是人工神经网络(ANNs)的进化或扩展版本。 -
Therefore, it can be said that DL-based models are multi-layered NNs, where input signals pass through multiple layers of neurons to generate an output.
因此,可以说基于深度学习的模型是多层神经网络,其中输入信号通过多个神经元层以产生输出。 -
The distinctive feature of DL is the depth of the networks, signifying they consist of a significant number of hidden layers.
深度学习的显著特征是网络的深度,这意味着它们由大量的隐藏层组成。 -
These layers can extract progressively complex features from the input data, enabling the network to learn and classify patterns with higher accuracy.
这些层可以从输入数据中逐步提取复杂的特征,使网络能够以更高的准确性学习和分类模式。 -
Moreover, DL techniques may include specific architectures optimised for processing images and sequential data, respectively.
此外,深度学习技术还包括分别针对处理图像和序列数据而优化的特定架构。 -
Based on the information presented in Table 1, one can identify the most frequently referenced techniques as follows: RNNs, variants of RNNs such as LSTM and GRU, CNNs, and autoencoders.
根据表 1 中提供的信息,可以识别出最常被引用的技术如下:循环神经网络(RNNs)、RNN 的变体(如 LSTM 和 GRU)、卷积神经网络(CNNs)以及自动编码器。 -
The frequency of occurrence of these techniques is calculated by considering the references reviewed in the manuscript. LSTM, CNN, RNN, GRU, and autoencoders have respective shares of 32%, 17%, 10%, 9%, and 8%.
这些技术的出现频率是结合本文综述的参考文献计算得出的。LSTM、CNN、RNN、GRU 和自动编码器的占比分别为 32%、17%、10%、9% 和 8%。 -
These techniques were developed to address the limitations of previous approaches or to tackle different types of problems.
开发这些技术是为了解决先前方法的局限性或应对不同类型的问题。 -
Various factors are taken into account during the application process, making it impractical and unfair to provide a general comparative analysis.
在应用过程中需要考虑各种因素,因此提供通用的比较分析是不切实际且不公平的。 -
Nevertheless, these techniques can be compared based on key criteria, such as their ability to handle sequential data, modelling complexity, computational efficiency, and training time.
尽管如此,这些技术仍可以根据关键标准进行比较,例如处理序列数据的能力、建模复杂度、计算效率和训练时间。 -
The comparative results are presented in Table 3. Additionally, we offer a brief summary of these techniques in the following subsections.
比较结果见表 3。此外,我们在接下来的小节中提供了这些技术的简要总结。
| Benchmarks (基准指标) | The pros and cons of the techniques (技术的优缺点) |
|---|---|
| Handling sequential data 处理序列数据 | RNN is convenient for handling sequential data 127. LSTM and GRU are suitable for sequential data, with LSTM being effective in mitigating the vanishing gradient problem 128. CNN is primarily designed for spatial data, characterised by multidimensional arrays, rather than sequential data 129. Autoencoders can also be utilised for processing sequential data arrays 130,131. RNN 方便处理序列数据 127。LSTM 和 GRU 适用于序列数据,其中 LSTM 在缓解梯度消失问题方面非常有效 128。CNN 主要针对空间数据设计,其特征是多维数组而非序列数据 129。自动编码器也可用于处理序列数据阵列 130,131。 |
| Modelling complexity 建模复杂度 | Simple RNNs are less complex than LSTM and GRU 132. The LSTM concept includes three gates, while GRUs have fewer parameters since they merge the input and forget gates into the update gate 132. Hence, it can be inferred that GRU is simpler than LSTM as it includes fewer gating structures. Moreover, CNNs and autoencoders have different architectures compared to the RNN family, which makes it challenging to compare them directly. CNN architecture is built with numerous layers, each serving specific functions 133. Due to limitations in their architecture, CNNs may benefit from optimisation algorithms to mitigate overfitting or issues with local minima 133. The complexity of CNN modelling depends on the number of layers and extensions. Autoencoders, on the other hand, are a special form of feedforward architecture with encoder, decoder, and latent space, and they can also be utilised in convolutional or recurrent forms 123. The complexity of autoencoders can be specified by the number of latent features 134. 简单 RNN 的复杂度低于 LSTM 和 GRU 132。LSTM 概念包含三个门,而 GRU 参数较少,因为它将输入门和遗忘门合并为更新门 132。因此,可以推断 GRU 比 LSTM 更简单,因为它包含较少的门控结构。此外,与 RNN 系列相比,CNN 和自动编码器具有不同的架构,这使得直接比较它们具有挑战性。CNN 架构由许多层构建,每层服务于特定功能 133。由于架构的限制,CNN 可能会从优化算法中受益,以缓解过拟合或局部最小值问题 133。CNN 建模的复杂度取决于层数和扩展。另一方面,自动编码器是具有编码器、解码器和潜空间的一种特殊形式的前馈架构,它们也可以以卷积或循环形式利用 123。自动编码器的复杂度可以通过潜在特征的数量来指定 134。 |
| Computational efficiency 计算效率 | Computational efficiency depends heavily on some special factors of model size, data type, batch size, hardware etc. Considering the same conditions, GRUs are computationally more efficient than LSTM 135. In a general manner, GRU gives better performance than LSTM for low-complex cases, and LSTM performs better in relatively higher-complex strings 136. Also, RNN family is executable on embedded platforms 137. For general comparative analysis, CNNs are computationally intensive 138,139. Autoencoders have advantageous for computational point of view as they can deal large dataset by dimensionality reduction algorithms 131. 计算效率在很大程度上取决于模型大小、数据类型、批次大小、硬件等特殊因素。在相同条件下,GRU 的计算效率高于 LSTM 135。通常情况下,GRU 在低复杂度案例中的表现优于 LSTM,而 LSTM 在相对高复杂度的字符串中表现更好 136。此外,RNN 系列可以在嵌入式平台上执行 137。对于一般性对比分析,CNN 的计算量很大 138,139。从计算角度来看,自动编码器具有优势,因为它们可以通过降维算法处理大型数据集 131。 |
| Training time 训练时间 | Due to the exploding and the vanishing gradient problem, training of simple modellings may be longer compared to LSTM which is proposed to tackle with the gradient problem. GRUs are faster than LSTMs 135. Training time for CNN is depended on layer numbers, as well as the weights 140. Besides, weight sharing feature reduces the number of trainable parameters, as well as it avoids the overfitting 139. For autoencoders, data feeding through the layers may impose bottleneck 141. Besides, the size of the training-set can be optimised 142. 由于梯度爆炸和消失问题,简单模型的训练时间可能比旨在解决梯度问题的 LSTM 更长。GRU 的速度比 LSTM 快 135。CNN 的训练时间取决于层数以及权重 140。此外,权值共享特性减少了可训练参数的数量,并避免了过拟合 139。对于自动编码器,通过各层的数据传输可能会造成瓶颈 141。此外,训练集的大小可以进行优化 142。 |
- For more in-depth information, readers can refer to the Refs 125,126.
欲了解更深入的信息,读者可参考参考文献 125,126。
5.1. 循环神经网络(RNNs)
-
RNN is a type of ANN designed for processing sequential data, such as speech, text, and time series 123,143.
RNN 是一种旨在处理序列数据(如语音、文本和时间序列)的人工神经网络(ANN) 123,143。 -
Unlike traditional feedforward NNs, which process input data as a fixed-length vector, RNNs process input data as a sequence, where each time step in the sequence is connected to the previous time step.
与将输入数据处理为固定长度向量的传统前馈神经网络不同,RNN 将输入数据处理为一个序列,其中序列中的每个时间步都与前一个时间步相连。 -
The basic idea behind an RNN is to use a hidden state vector to capture the information from previous time steps, which is then used to make predictions at each time step.
RNN 的基本思想是利用隐藏状态向量来捕获来自先前时间步的信息,然后将其用于在每个时间步进行预测。 -
The hidden state vector is updated based on the current input and the previous hidden state at each time step.
隐藏状态向量在每个时间步根据当前输入和前一个隐藏状态进行更新。 -
This allows the network to capture the long-term dependencies in sequential data, making it well-suited for tasks such as language modelling, speech recognition, and time series forecasting.
这使得网络能够捕获序列数据中的长期依赖关系,使其非常适合语言建模、语音识别和时间序列预测等任务。 -
In terms of structure, an RNN is composed of a series of interconnected neurons, where each neuron is connected to the neurons in the previous and next time steps.
在结构方面,RNN 由一系列相互连接的神经元组成,其中每个神经元都与前一个和后一个时间步的神经元相连。 -
The weights of the connections between neurons are shared across all time steps, allowing the network to learn patterns in the data that persist over a long period of time.
神经元之间连接的权重在所有时间步中是共享的,这使得网络能够学习数据中长期存在的模式。 -
A typical RNN flowchart includes an input layer, one or more hidden layers, and an output layer, as illustrated in Fig. 2.
典型的 RNN 流程图包括一个输入层、一个或多个隐藏层以及一个输出层,如图 2 所示。
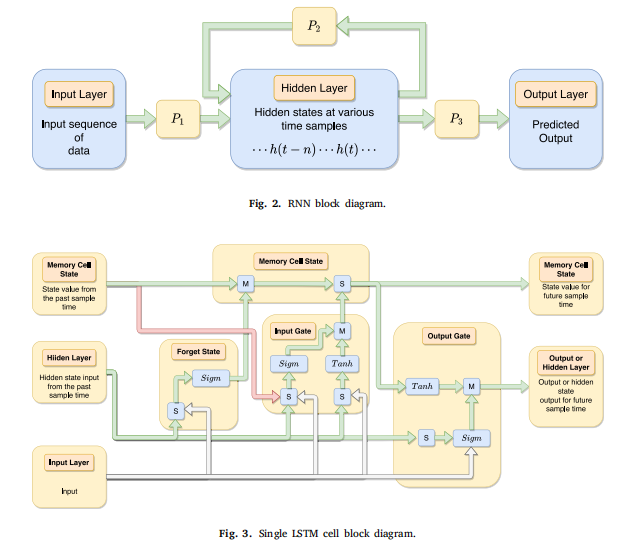
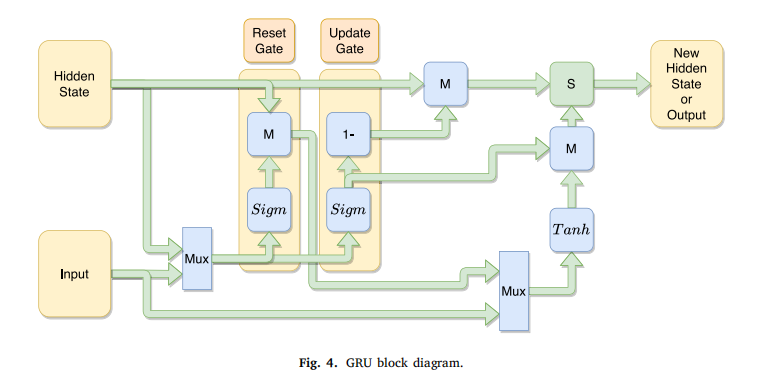
-
The input layer takes the data for a given time step and passes it to the hidden layer.
输入层接收给定时间步的数据并将其传递给隐藏层。 -
The hidden layer consists of a set of neurons, each with its own set of weights and biases.
隐藏层由一组神经元组成,每个神经元都有自己的一组权重和偏置。 -
The hidden layer processes the input and generates an output, which is then fed back into the hidden layer as the hidden state for the next time step.
隐藏层处理输入并生成输出,该输出随后作为下一个时间步的隐藏状态反馈到隐藏层中。 -
This hidden state captures information from previous time steps, which is used to make predictions at each time step. The output layer takes the outputs from the hidden layer and generates the final prediction.
该隐藏状态捕获了来自先前时间步的信息,用于在每个时间步进行预测。输出层接收来自隐藏层的输出并生成最终预测。 -
The weights (𝑃1, 𝑃2, and 𝑃3) and biases of the network are learned through training, where the network is exposed to a series of inputs and their corresponding outputs, and the weights and biases are adjusted to minimise the error between the network's predictions and the actual outputs.
网络的权重( P 1 P_1 P1, P 2 P_2 P2 和 P 3 P_3 P3)及偏置是通过训练学习的。在训练过程中,网络接触一系列输入及其对应的输出,并调整权重和偏置以最小化网络预测与实际输出之间的误差。 -
RNNs are well-suited for processing sequential data and have been utilised in LF to model the temporal dependencies in the data.
RNN 非常适合处理序列数据,并已在负荷预测(LF)中用于模拟数据中的时间依赖性。 -
Several variants of RNNs have been developed in recent years, including simple RNN, LSTM network, GRU network, bidirectional RNN, and CNN-LSTM network.
近年来开发了多种 RNN 变体,包括简单 RNN、LSTM 网络、GRU 网络、双向 RNN 和 CNN-LSTM 网络。 -
Each of these variants has its own strengths and weaknesses, and the choice of which one to use will depend on the specific problem at hand and the type of data being employed.
这些变体各有优缺点,选择哪一种取决于手头的具体问题和所使用的数据类型。 -
When considering the DL-based STLF problem, LSTM, GRU, and CNN-LSTM are frequently referenced.
在考虑基于深度学习的 STLF 问题时,LSTM、GRU 和 CNN-LSTM 是被频繁引用的模型。 -
In addressing the design decisions for RNNs, it is crucial to consider two key aspects: sequential processing and the vanishing gradient issue.
在处理 RNN 的设计决策时,考虑两个关键方面至关重要:序列处理和梯度消失问题。 -
Real-world data sources often exhibit temporal dependencies. RNNs capture these temporal patterns through sequential processing, achieved by employing recurrent connections with hidden states.
现实世界的数据源通常表现出时间依赖性。RNN 通过序列处理捕获这些时间模式,这是通过采用带有隐藏状态的循环连接来实现的。 -
Additionally, the vanishing gradient problem is closely linked to these recurrent connections within the model.
此外,梯度消失问题与模型内部的这些循环连接密切相关。 -
As a result, weak recurrent connections can limit the network's capacity to capture long-term dependencies, leading to challenges associated with the vanishing gradient problem.
结果,微弱的循环连接会限制网络捕获长期依赖关系的能力,从而导致与梯度消失问题相关的挑战。
5.2. LSTM 网络
-
LSTM networks were first introduced in 144. LSTM is an advanced variant of RNN that is specifically designed to overcome the vanishing gradient problem common in traditional RNNs.
LSTM 网络最早在 144 中引入。LSTM 是 RNN 的一种高级变体,专门设计用于克服传统 RNN 中常见的梯度消失问题。 -
In traditional RNNs, gradients used to update the model parameters during training can become very small over time, making it difficult to train the model effectively 145.
在传统 RNN 中,用于在训练期间更新模型参数的梯度会随着时间的推移变得非常小,导致难以有效地训练模型 145。 -
LSTM networks can efficiently extract the underlying complicated temporal connections using gates and memory cells, illustrated in Fig. 3.
LSTM 网络能够利用门(gates)和记忆单元(memory cells)高效地提取潜在的复杂时间连接,如图 3 所示。 -
In Fig. 3, 𝑆𝑖𝑔𝑚 and 𝑇𝑎𝑛ℎ stand for the sigmoid and hyperbolic tangent functions, respectively. Additionally, consecutive 𝑆 and 𝑀 indicate summation and multiplication, respectively.
在图 3 中, S i g m Sigm Sigm 和 T a n h Tanh Tanh 分别代表 S 型激活函数(sigmoid)和双曲正切函数。此外,连续的 S S S 和 M M M 分别表示加法和乘法。 -
LSTM networks accomplish the temporal pattern connections by using a type of memory cell designed to keep information over a long period of time.
LSTM 网络通过使用一种旨在长期保存信息的记忆单元来实现时间模式的连接。 -
The memory cell is surrounded by gates that control the flow of information into and out of the cell.
记忆单元被多个"门"包围,这些门控制着信息进入和离开单元的流动。 -
Due to their remarkable ability to capture long-term dependencies in long sequences of data, they are used in a variety of applications, including natural language processing, speech recognition, and LF.
由于其在长序列数据中捕捉长期依赖关系的卓越能力,它们被广泛应用于包括自然语言处理、语音识别和负荷预测(LF)在内的各种领域。 -
They use memory cells and gates to keep information over a long period and improve the model's ability to learn from long sequences of data.
它们利用记忆单元和门控机制长期保存信息,并提高了模型从长序列数据中学习的能力。 -
As seen from the block diagram of a single unit in Fig. 3, the LSTM network has typical components of an input layer, memory cell, input gate, forget gate, output gate, hidden state, and output layer.
从图 3 的单个单元框图可以看出,LSTM 网络具有典型的组成部分:输入层、记忆单元、输入门、遗忘门、输出门、隐藏状态和输出层。 -
The input layer takes in the data the network will process, which is usually a sequence of values, such as time series data.
输入层接收网络将要处理的数据,这通常是一系列数值,例如时间序列数据。 -
The memory cell is surrounded by three gates: the input gate, the forget gate, and the output gate. The memory cell is the core component of the LSTM network, as it keeps the information from one time step to the next by carrying it over a long period of time.
记忆单元由三个门包围:输入门、遗忘门和输出门。记忆单元是 LSTM 网络的核心组件,它通过长期携带信息将信息从一个时间步传递到下一个时间步。 -
The input gate controls the flow of information into the memory cell by determining what information should be added to the cell's state based on the current input and the previous cell state.
输入门通过根据当前输入和前一时刻单元状态确定哪些信息应添加到单元状态中,从而控制流入记忆单元的信息流。 -
Similarly, the forget gate controls the flow of information out of the memory cell by determining what information should be forgotten based on the current input and the previous cell state.
类似地,遗忘门通过根据当前输入和前一时刻单元状态确定哪些信息应该被遗忘,从而控制流出记忆单元的信息流。 -
The output gate is the third gate and controls the flow of information out of the memory cell and into the final output of the LSTM network. It determines what information should be output based on the current input and the previous cell state.
输出门是第三个门,控制从记忆单元流向 LSTM 网络最终输出的信息。它根据当前输入和前一时刻单元状态确定应输出哪些信息。 -
In this regard, the hidden state is also the output of the memory cell after it has been processed by the input, forget, and output gates. The hidden state is used as the input for the next time step in the sequence.
在这方面,隐藏状态也是记忆单元经过输入门、遗忘门和输出门处理后的输出。隐藏状态被用作序列中下一个时间步的输入。 -
Finally, the output layer takes the hidden state from the memory cell and produces the final output of the LSTM network, which can be used for prediction or classification tasks.
最后,输出层接收来自记忆单元的隐藏状态,并产生 LSTM 网络最终的输出,可用于预测或分类任务。 -
For the design decision of LSTM sequential processing, memory cells, and complexity should be considered.
对于 LSTM 的设计决策,应考虑序列处理、记忆单元和复杂度。 -
LSTMs are mainly designed for forecasting problems with sequential data. Hence, the order of the input is important to capture the temporal patterns.
LSTM 主要设计用于处理序列数据的预测问题。因此,输入的顺序对于捕获时间模式至关重要。 -
LSTMs include memory cells gating mechanisms and the design decision should be made by the capacity of the information capturing over long sequences due to the requirements to avoid the vanishing gradient problem.
LSTM 包含记忆单元门控机制,设计决策应取决于在长序列上捕捉信息的能力,以满足避免梯度消失问题的要求。 -
Also, LSTMs have relatively higher capacity to involve the long-term dependencies. But this capacity increasing costs to higher computational burden.
此外,LSTM 具有相对较高的处理长期依赖关系的能力。但这种能力的提升是以更高的计算负担为代价的。
5.3. GRU 网络
-
GRU network is another variation of RNNs that has been frequently used in LF to capture both short-term and long-term dependencies in the data 146.
GRU 网络是 RNN 的另一种变体,经常被用于负荷预测(LF)中,以捕捉数据中的短期和长期依赖关系 146。 -
As seen from Fig. 4, GRU consists of the update and reset gates. The update gate decides how much information from the previous sample time should be passed on to the current step, while the reset gate specifies how much of the previous information should be forgotten.
如图 4 所示,GRU 由更新门和重置门组成。更新门决定了来自前一采样时刻的信息有多少应传递到当前步骤,而重置门则规定了前一时刻的信息有多少应被遗忘。 -
These gates are implemented using sigmoid activation functions, which produce values between 0 and 1.
这些门是通过 S 型激活函数(sigmoid)实现的,它会产生 0 到 1 之间的数值。 -
The output of the GRU at each sample is determined by a combination of the previous state and the input at the current time.
GRU 在每个采样点的输出是由前一状态和当前时刻输入的组合所决定的。 -
The state information is stored in the hidden units and updated at each time sample based on the input and the gate values.
状态信息存储在隐藏单元中,并根据输入和门控值在每个时间采样点进行更新。 -
In this regard, the critical advantage of GRUs over traditional RNNs is that they are able to effectively balance the trade-off between retaining old information and incorporating new information, allowing them to model long-term dependencies in sequential data more effectively.
在这方面,GRU 相比传统 RNN 的关键优势在于,它们能够有效地平衡保留旧信息与整合新信息之间的权衡,从而使它们能更有效地对序列数据中的长期依赖关系进行建模。 -
This has made GRUs popular choice for a wide range of sequence modelling tasks, as well as LF problems.
这使得 GRU 成为各种序列建模任务以及负荷预测问题的热门选择。 -
GRU and LSTM are two types of RNNs designed to address the problem of vanishing gradients, which can occur when training RNNs on long sequences.
GRU 和 LSTM 是两种旨在解决梯度消失问题的 RNN,梯度消失通常发生在对长序列进行 RNN 训练时。 -
GRU networks have been introduced as a simplified version of LSTM networks. They have two gates to control the flow of information through the network instead of three gates in LSTMs.
GRU 网络作为 LSTM 网络的简化版本被引入。它们拥有两个门来控制网络中的信息流,而 LSTM 则有三个门。 -
Also, GRU networks use a single memory unit to store information, while LSTMs use two memory units.
此外,GRU 网络使用单个记忆单元来存储信息,而 LSTM 使用两个记忆单元。 -
Hence, they require relatively fewer parameters to be tuned and less training time compared to LSTMs.
因此,与 LSTM 相比,它们需要调整的参数相对较少,训练时间也更短。 -
GRUs are simpler alternatives to LSTMs. They incorporate only update-reset gates and have a more straightforward construction.
GRU 是 LSTM 更简单的替代方案。它们仅包含更新-重置门,并且结构更加直观。 -
This simplified form emerges as the primary design decision factor for GRUs, with the aim of balancing forecasting performance and computational burden for shorter sequenced forecasting problems.
这种简化形式成为 GRU 的主要设计决策因素,其目的是在处理较短序列预测问题时,平衡预测性能与计算负担。 -
Furthermore, when compared to LSTM cells, GRUs have less complex memory cells, making them a suitable option.
此外,与 LSTM 单元相比,GRU 的记忆单元复杂程度较低,使其成为一个合适的选择。
5.4. 卷积神经网络(CNNs)
-
CNNs are a type of deep NN commonly employed for image recognition and computer vision tasks 147,148.
卷积神经网络(CNNs)是一种常用于图像识别和计算机视觉任务的深度神经网络 147,148。 -
CNNs are designed to handle time series data and have been used to capture local patterns within time series data.
CNN 被设计用于处理时间序列数据,并已被用于捕捉时间序列数据中的局部模式。 -
A block diagram of a CNN is provided in Fig. 5. As observed in the diagram, a CNN consists of a series of convolution layers that extract features from the input image, followed by one or more fully connected layers that make predictions based on the extracted features.
图 5 提供了 CNN 的框图。如图中所示,CNN 由一系列用于从输入图像中提取特征的卷积层组成,随后是一个或多个根据提取出的特征进行预测的全连接层。
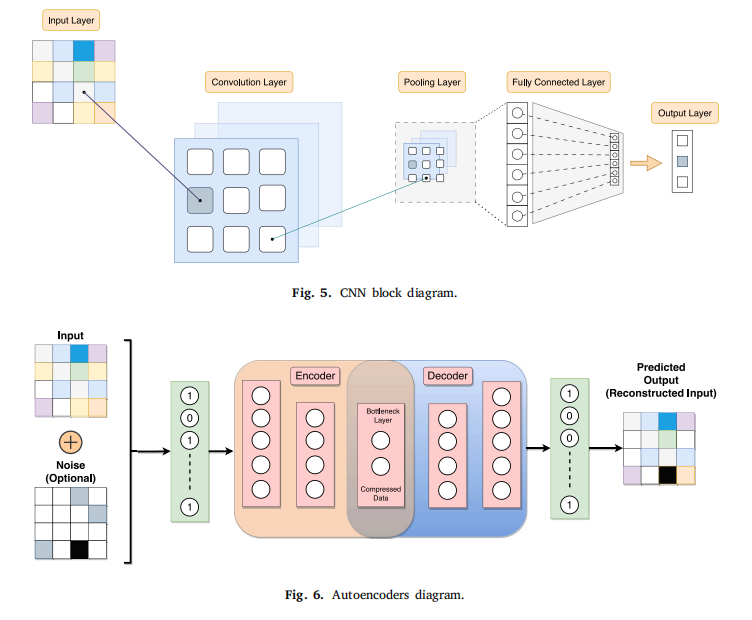
-
The input image undergoes convolution with a set of filters to generate a set of output feature maps.
输入图像通过一组滤波器进行卷积运算,以生成一组输出特征图。 -
Each filter is a small matrix of weights slid over the image, computing a dot product at each position to create a single value in the output feature map.
每个滤波器都是一个在图像上滑动的小权重矩阵,通过在每个位置计算点积,在输出特征图中创建一个数值。 -
These filters are typically learned through back-propagation during training, and the values in the feature maps represent learned visual features, such as edges or corners, which are useful for identifying objects in the image.
这些滤波器通常在训练期间通过反向传播学习得到,特征图中的数值代表了学习到的视觉特征(如边缘或拐角),这对于识别图像中的对象非常有用。 -
After each convolution layer, a non-linear activation function, such as rectified linear unit, is applied to the output feature maps to introduce non-linearity into the network.
在每个卷积层之后,会将非线性激活函数(如修正线性单元 ReLU)应用于输出特征图,从而为网络引入非线性。 -
The feature maps are then typically down-sampled using pooling layers, reducing the spatial size of the features and enhancing the network's computational efficiency.
特征图随后通常使用池化层进行下采样,以减小特征的空间尺寸并提高网络的计算效率。 -
Finally, one or more fully connected layers are added to the end of the network to make predictions based on the learned features.
最后,在网络末端添加一个或多个全连接层,根据学习到的特征做出预测。 -
These layers are similar to those in a traditional NN and may use techniques such as dropout or batch normalisation to improve generalisation and prevent overfitting.
这些层类似于传统神经网络中的层,可能会使用随机失活(dropout)或批归一化(batch normalisation)等技术来提高泛化能力并防止过拟合。 -
CNNs have significant differences from GRU or LSTM networks.
CNN 与 GRU 或 LSTM 网络有着显著的区别。 -
CNNs use convolutional layers to extract features from input data, while GRU or LSTM networks use recurrent connections to maintain the memory of the input.
CNN 使用卷积层从输入数据中提取特征,而 GRU 或 LSTM 网络则使用循环连接来保持对输入的记忆。 -
CNNs process data in a spatially local manner by applying filters to small sub-regions of the input data. In contrast, GRU operates on data in a temporally local manner by using recurrent connections to maintain a memory of previous inputs over time.
CNN 通过将滤波器应用于输入数据的微小局部区域,以空间局部的方式处理数据。相比之下,GRU 通过使用循环连接随时间保持对先前输入的记忆,以时间局部的方式处理数据。 -
Therefore, CNN networks are well suited for processing visual data such as images and video, while GRU or LSTM networks are used for sequence data processing tasks.
因此,CNN 网络非常适合处理图像和视频等视觉数据,而 GRU 或 LSTM 网络则用于序列数据处理任务。 -
When considering the design decision factors of CNNs, it is essential to take into account the roles of convolutional layers, translation invariance, and pooling layers.
在考虑 CNN 的设计决策因素时,必须考虑卷积层、平移不变性以及池化层的作用。 -
Convolutional layers serve to detect partial patterns within the input spatial data, enabling the network to learn features ranging from low-level local details to high-level dimensional details.
卷积层用于检测输入空间数据中的局部模式,使网络能够学习从低层局部细节到高层维度细节的特征。 -
The concept of translation invariance means that CNNs recognise features regardless of the object's position in the data.
平移不变性的概念意味着,无论对象在数据中的位置如何,CNN 都能识别出特征。 -
This simplifies the learning process by focusing on local features instead of requiring extensive feature engineering.
这通过专注于局部特征而不是需要大量的特征工程,简化了学习过程。 -
To reduce the spatial dimension and facilitate down-sampling, CNNs incorporate pooling layers, which aid in managing computational complexity.
为了减小空间维度并促进下采样,CNN 引入了池化层,这有助于管理计算复杂度。
5.5. 自动编码器(Autoencoders)
-
Autoencoders are one of the most important ML models. They transform input data into a more compact and informative representation in the form of a vector set, which can be utilised for downstream tasks such as classification, clustering, or forecasting 149.
自动编码器(Autoencoders)是最重要的机器学习模型之一。它们将输入数据转换成向量集形式的更紧凑且更具信息量的表示,可用于分类、聚类或预测等下游任务 149。 -
Encoding involves mapping raw input data to a lower-dimensional space by capturing the most notable features of the input.
编码过程涉及通过捕捉输入中最显著的特征,将原始输入数据映射到低维空间。 -
This process is achieved through a series of non-linear transformations that reconstruct the input data into a sequence of hidden representations.
这一过程通过一系列非线性变换实现,将输入数据重构为一系列隐藏表示。 -
These depiction relations are learned from data using gradient descent and backpropagation algorithms.
这些描述关系是利用梯度下降和反向传播算法从数据中学习得到的。 -
Autoencoders are often designed with an unsupervised learning approach where the goal is to learn a low-dimensional representation of the input data without any explicit supervision or labels.
自动编码器通常采用无监督学习方法设计,其目标是在没有任何明确监督或标签的情况下,学习输入数据的低维表示。 -
As shown in Fig. 6, autoencoders include basically two blocks which are the encoder and the decoder.
如图 6 所示,自动编码器基本包含两个模块:编码器(encoder)和解码器(decoder)。 -
The encoder network takes an input data sample and maps it to a lower-dimensional latent representation.
编码器网络接收输入数据样本,并将其映射到低维的潜在表示(latent representation)。 -
The size of this representation is typically much smaller than the input size, which allows the network to learn a compressed form of the input data.
这种表示的尺寸通常远小于输入尺寸,从而允许网络学习输入数据的压缩形式。 -
Then, the encoder network can be composed of one or more layers of neurons and can be implemented using a variety of NN architectures, such as fully connected layers or convolutional layers.
编码器网络可以由一层或多层神经元组成,并可以使用多种神经网络架构来实现,如全连接层或卷积层。 -
However, the decoder network takes the compressed inherent representation produced by the encoder network and maps it back to a reconstructed output that is the same size as the input.
然而,解码器网络接收由编码器网络产生的压缩内在表示,并将其映射回与输入尺寸相同的重构输出。 -
So, it can be said that the decoder is typically a mirror image of the encoder in terms of the number of layers and the architecture type.
因此可以说,就层数和架构类型而言,解码器通常是编码器的镜像。 -
Besides, the connections and weights are in reverse form to each other.
此外,两者的连接和权重互为逆形式。 -
Considering the training process, the objective of the autoencoders is to minimise the difference between the original input and the predicted output.
考虑到训练过程,自动编码器的目标是最小化原始输入与预测输出之间的差异。 -
This is typically done using a function defined by the metrics of mean squared error or cross-entropy loss.
这通常使用由均方误差(MSE)或交叉熵损失指标定义的函数来完成。 -
Autoencoders can be trained in an unsupervised manner. Hence, they can learn to extract useful features from input data without requiring explicit labels.
自动编码器可以以无监督方式进行训练。因此,它们可以学着从输入数据中提取有用特征,而不需要明确的标签。 -
Once trained, the encoder network can be used to extract features from new data samples, which can be especially used for an LF problem.
一旦完成训练,编码器网络即可用于从新数据样本中提取特征,这在负荷预测(LF)问题中尤为有用。 -
Autoencoders can be efficiently used for unsupervised learning tasks, such as dimensionality reduction, feature extraction, anomaly detection etc.
自动编码器可以高效地用于无监督学习任务,如降维、特征提取、异常检测等。 -
Besides, CNN, GRU or LSTM networks are primarily used for supervised learning tasks, such as classification, regression, and sequence modelling etc.
相比之下,CNN、GRU 或 LSTM 网络主要用于有监督学习任务,如分类、回归和序列建模等。 -
Briefly, it can be said that autoencoders do not require labelled data for training which differentiates them from other competitive network models.
简而言之,自动编码器不需要标签数据进行训练,这使其区别于其他具有竞争力的网络模型。 -
Considering the performance of each technique, autoencoders can be effective in learning useful representations of high-dimensional data.
考虑到每种技术的性能,自动编码器在学习高维数据的有用表示方面非常有效。 -
However, they may not perform well such as other network architectures on specific supervised learning tasks, especially those involving sequential or image data, where RNNs, GRUs, LSTMs, and CNNs have shown superior performance.
然而,在特定的有监督学习任务中,特别是在涉及序列或图像数据时,它们的表现可能不如其他网络架构,而 RNN、GRU、LSTM 和 CNN 在这些领域表现出了卓越的性能。 -
For LF problems, autoencoders can be preferred for LF models with feature extraction and data pre-processing to improve the accuracy of forecasting.
对于负荷预测问题,自动编码器可首选用于具有特征提取和数据预处理功能的预测模型,以提高预测准确性。 -
Also, they can be trained using an unsupervised learning approach, which provides immense help to model performance as this form of learning does not require labelled data.
此外,它们可以使用无监督学习方法进行训练,由于这种学习形式不需要标签数据,因此对提升模型性能有巨大帮助。 -
In this regard, in cases where limited training data is available, autoencoders can be designed with transfer learning mode, which enables them to be pre-trained on a related task and then fine-tuned on the LF problem.
在这方面,在训练数据有限的情况下,可以将自动编码器设计为迁移学习模式,使其能够在相关任务上进行预训练,然后在负荷预测问题上进行微调。 -
Moreover, autoencoders are relatively successful in anomaly detection and predicting unusual events, such as power outages or equipment failures.
此外,自动编码器在异常检测和预测异常事件(如停电或设备故障)方面相对成功。 -
However, autoencoders can suffer from overfitting when the size of the input data is large or the network architecture is complex.
然而,当输入数据量大或网络架构复杂时,自动编码器可能会遭受过拟合。 -
This can lead to poor generalisation performance on new data. Also, training autoencoders can be computationally expensive, particularly for large datasets or complex network architectures.
这可能导致在新数据上的泛化性能较差。此外,训练自动编码器的计算成本可能很高,特别是对于大型数据集或复杂的网络架构。 -
Additionally, the design of autoencoders does not have a precise algorithm to determine the optimal architecture for a given task, which can be time-consuming and required expertise.
此外,自动编码器的设计没有精确的算法来确定给定任务的最佳架构,这可能非常耗时且需要专业知识。 -
When considering design decisions for autoencoders, several key points should be taken into account, including the architecture, the bottleneck layer, and the use of variational autoencoders.
在考虑自动编码器的设计决策时,应考虑几个关键点,包括架构、瓶颈层(bottleneck layer)以及变分自动编码器(VAE)的使用。 -
Autoencoders consist of two internal networks that work in an integrated manner, allowing them to effectively learn features.
自动编码器由两个以集成方式工作的内部网络组成,使其能够有效地学习特征。 -
The encoder network maps input data to a compressed latent image, and the decoder network reconstructs the data from this image.
编码器网络将输入数据映射到压缩的潜在图像,解码器网络从该图像中重构数据。 -
This structure results in the designing of a bottleneck layer in the middle of the model, which serves to reduce the dimension of the latent representation.
这种结构导致在模型中间设计了一个瓶颈层,其作用是降低潜在表示的维度。 -
Consequently, important features of the network can be captured in a more compact representation at this layer.
因此,网络的重要特征可以在该层以更紧凑的表示形式被捕捉。 -
Furthermore, variational autoencoders introduce a probabilistic element to the model, enabling the generation of new data samples for purposes such as data generation and anomaly detection.
此外,变分自动编码器向模型引入了概率元素,能够生成新的数据样本,用于数据生成和异常检测等目的。
6. 在线负荷预测模型
-
Classical NN approaches utilise offline learning and miss the chance to learn from newly arriving data.
经典的神经网络(NN)方法利用离线学习,失去了从新到达的数据中学习的机会。 -
They handle all data in the training procedure, and the resulting model serves to forecast future demands without adapting the inner parameters 68.
它们在训练过程中处理所有数据,生成的模型用于预测未来需求,而不会调整内部参数 68。 -
On the other hand, online ML-based approaches have the potential to embrace variations in the data stream and adapt to the model by reiterating the procedure with available data 68.
另一方面,基于在线机器学习(ML)的方法有潜力吸收数据流中的变化,并通过利用可用数据重复学习过程来适应模型 68。 -
Considering the DL-based STLF concept, one of the future direction is developing online learning type of NN LF models.
考虑到基于深度学习的 STLF 概念,未来的研究方向之一是开发在线学习型的神经网络负荷预测模型。 -
Online LF techniques are utilised to predict future electricity or energy demand in real-time or near real-time.
在线负荷预测技术用于实时或近实时地预测未来的电力或能源需求。 -
Online measuring of continuously generated datasets enable precise LF which paves the way for the efficient power distribution programs to compete with the imbalances and energy shortage scenarios 150.
对持续生成的数据集进行在线测量可实现精确的负荷预测,这为高效的配电方案应对不平衡和能源短缺场景铺平了道路 150。 -
The basic online-type LF techniques include time series analysis, ML with statistical models, hybrid models, online learning algorithms, online data sources, probabilistic forecasting, and deep RL 150.
基本的在线型负荷预测技术包括时间序列分析、带统计模型的机器学习、混合模型、在线学习算法、在线数据源、概率预测和深度强化学习(RL) 150。 -
When searching for these techniques within the context of STLF, the literature is not extensive. Therefore, the STLF perspective has been broadened to encompass general horizon LF.
在 STLF 背景下搜索这些技术时,相关文献并不广泛。因此,STLF 的视角已被扩大到涵盖一般时间尺度的负荷预测。 -
Online-based LF techniques are reviewed to provide an analysis of the advantages and disadvantages of these techniques and to project their applicability to the LF concept.
对基于在线的负荷预测技术进行了综述,以分析这些技术的优缺点,并预测其在负荷预测概念中的适用性。 -
In this context, online-type LF studies are presented in Table 4 in terms of the basic concepts and key findings.
在此背景下,表 4 从基本概念和关键发现方面展示了在线型负荷预测的研究。
| Ref. | Year | Basic concept (基本概念) | Key findings on online LF (在线负荷预测的关键发现) |
|---|---|---|---|
| 157 | 2014 | Autonomous kernel based online ANN model and its application to building cooling load prediction 基于自主核的在线人工神经网络模型及其在建筑冷负荷预测中的应用 | Autonomous kernel-based NN model is proposed for noisy data regression prediction without requiring external update of the model parameters. 提出了一种基于自主核的神经网络模型,用于噪声数据回归预测,无需外部更新模型参数。 |
| 158 | 2015 | RF model for STLF 用于短期负荷预测(STLF)的随机森林(RF)模型 | Providing design scheme of online type RF techniques considering the day-ahead learning procedure for long range forecast. 提供了考虑日前学习程序的在线随机森林技术设计方案,用于长程预测。 |
| 159 | 2018 | Kernel extreme learning machine and Cholesky decomposition for STLF 用于 STLF 的核极限学习机与 Cholesky 分解 | Taking into account the parameter updating of the growing dataset to overcome both of the short-term irregularity in power load and variation in weather conditions. 考虑到不断增长的数据集的参数更新,以克服电力负荷的短期不规则性和天气条件的波动。 |
| 150 | 2018 | Online SVR model for STLF 用于 STLF 的在线支持向量回归(SVR)模型 | Presenting design details of online SVR and giving discussions on the pros and cons of the proposed method with the tree-based ensemble methods. 展示了在线 SVR 的设计细节,并讨论了所提方法与基于树的集成方法的优缺点。 |
| 156 | 2020 | Hybrid DL scheduling algorithm for STLF online learning system with CNN-LSTM model 基于 CNN-LSTM 模型的 STLF 在线学习系统混合深度学习(DL)调度算法 | Enhancing and accelerating the learning performance in a multi-client auto-metering dataset. Presenting the design of the learning system for edge-cloud computing. 增强并加速了多客户端自动计量数据集的学习性能。展示了面向边缘云计算的学习系统设计。 |
| 153 | 2020 | In an IoT environment, supervised ML algorithms are considered for online STLF, and the Gaussian process regression ML algorithm emerges as the best-fitting LF algorithm for the provided setup 在物联网(IoT)环境下,探讨了用于在线 STLF 的有监督机器学习算法,其中高斯过程回归被证明是该设置下的最佳预测算法 | An online LF architecture is proposed for use in an IoT-based online home energy management system, along with a basic circuitry design for real-time data logging onto the cloud. 提出了一种用于基于物联网的在线家庭能源管理系统的在线预测架构,以及用于云端实时数据记录的基础电路设计。 |
| 160 | 2021 | Ensemble STLF method based on passive aggressive regression algorithm 基于被动攻击回归算法的集成 STLF 方法 | Answers the question "How can we efficiently integrate the online learning concept into the existing LF models to obtain better accuracy?" Developing an online ensemble model for LF applications. 回答了"如何有效地将在线学习概念整合到现有的预测模型中以获得更好的准确性?"。开发了用于负荷预测应用的在线集成模型。 |
| 68 | 2021 | Online Adaptive RNNs for STLF 用于 STLF 的在线自适应循环神经网络(RNNs) | Building a foundational learner model using RNNs to capture temporal dependencies, alongside a tuning module to adapt the NN's hyperparameters to newly arriving patterns. Comparing the accuracy performance of the proposed model with online models such as MLP, linear regression, passive-aggressive algorithm, online bagging, and k-NN. 构建了一个使用 RNN 捕捉时间依赖的基础学习器模型,以及一个调整模块以使神经网络超参数适应新到达的模式。将所提模型的准确性能与 MLP、线性回归、被动攻击算法、在线 Bagging 和 k-NN 等在线模型进行了比较。 |
| 152 | 2021 | A sliding-window type online learning algorithm with deep echo-state network for STLF 具有深度回声状态网络的滑动窗口型在线学习算法用于 STLF | An online learning scheme is implemented to enhance edge computation capabilities and capture dynamic changes in LD. The results of long-term experiments demonstrate promising reductions in computational burden and improvements in accuracy for real-world residential load data. 实施了一种在线学习方案,以增强边缘计算能力并捕捉负荷需求的动态变化。长期实验结果表明,该方案能有效降低计算负担并提高真实住宅负荷数据的预测准确性。 |
| 161 | 2021 | DL-based sequential encoder-stacked decoder model for STLF 基于深度学习的序列编码器-堆叠解码器 STLF 模型 | Presenting an online training method for sequence data based on transfer learning. Comparative analysis is provided between the hidden Markov model and RNNs. 提出了一种基于迁移学习的序列数据在线训练方法。提供了隐马尔可夫模型与 RNN 之间的对比分析。 |
| 162 | 2021 | Adaptive online ensemble learning with RNN and ARIMA for STLF 结合 RNN 和 ARIMA 的 STLF 自适应在线集成学习 | Combining approach with ARIMA and RNN for STLF in drift concept. Online adaptive RNN to capture time dependencies in the dataset. Considering the overall LF error, online ARIMA-RNN ensemble performs better than standalone online adaptive RNN or ARIMA. 在漂移概念下结合 ARIMA 和 RNN 进行 STLF。利用在线自适应 RNN 捕捉数据集中的时间依赖性。考虑到整体预测误差,在线 ARIMA-RNN 集成的表现优于独立的在线自适应 RNN 或 ARIMA。 |
| 154 | 2021 | Hidden Markov model based online learning algorithm for adaptive probabilistic LF 基于隐马尔可夫模型的自适应概率负荷预测在线学习算法 | Adapting LF model parameters to the changes in the consumption patterns and load uncertainties. Providing online learning techniques for probabilistic LF model to update the model parameters. Presenting efficient implementation of online learning for adaptive probabilistic LF. 使预测模型参数适应消费模式的变化和负荷不确定性。为概率预测模型提供在线学习技术以更新参数。展示了自适应概率预测在线学习的高效实现。 |
| 163 | 2022 | Two-stage online learning-based STLF model called as for RAnger-Based online learning approach 名为 RAnger-Based 的两阶段在线学习 STLF 模型 | To further improve the performance of the online learning-based stacking ensemble model, an online learning approach is proposed for better capturing the rapid changes or variability in building energy consumption trends. 为了进一步提高基于在线学习的堆叠集成模型的性能,提出了一种在线学习方法,以更好地捕捉建筑能耗趋势的快速变化或波动。 |
| 164 | 2022 | A physical-based multiple linear regression model for cooling LF 用于冷负荷预测的基于物理的多元线性回归模型 | Online type model promises the better characteristics in terms of small training samples, generalisation ability, and interpret ability. Together utilisation of online training & calibration improves the performance by mean percentage absolute error compared to the offline models. 在线模型在小训练样本、泛化能力和可解释性方面表现出更好的特性。结合在线训练和校准,与离线模型相比,该模型显著降低了平均绝对百分比误差。 |
| 165 | 2022 | Hybrid tree-based ensemble learning model including GBM, extreme GB, Cubist, and RF for daily peak LF 用于日峰值预测的包含 GBM、XGBoost、Cubist 和 RF 的混合树集成学习模型 | Utilising the Boruta algorithm to select all admissible features to build online learning model, and online model is trained on these variables using time-series cross-validation. 利用 Boruta 算法选择所有容许特征以构建在线学习模型,并使用时间序列交叉验证在这些变量上训练在线模型。 |
| 151 | 2022 | Time-delay NN model for STLF 用于 STLF 的时延神经网络模型 | Time-delay embedding theory is utilised for the LF to confirm interpretability of the model. Proposing hour-ahead LF by online training and testing approach. Proposed algorithm is suitable for IoT-based networks with smaller dataset. 利用时延嵌入理论进行预测,以确认模型的可解释性。提出通过在线训练和测试方法进行日前预测。所提算法适用于数据集较小的物联网。 |
| 155 | 2023 | Adaptive DL-based STLF framework by integrating transformer and domain knowledge 整合 Transformer 和领域知识的自适应深度学习 STLF 框架 | Considering the data collection performance due to inadequate deployment of the data meters, as well as data privacy issues, it is aimed to offer adaptive based model for time-series forecasting. 考虑到由于数据计量器部署不足导致的数据收集性能以及数据隐私问题,旨在为时间序列预测提供自适应模型。 |
| 166 | 2023 | Online-offline DL method for residential STLF 用于住宅 STLF 的在线-离线深度学习方法 | Proposing a simple structure for effective online training, as well as remarkable performance to learn the temporal dynamics. Following the feasibility analysis of applying online and offline learning scheme with historical and real-time dataset for LF. 提出了一种用于高效在线训练的简单结构,在学习时间动态方面具有显著性能。随后对将在线和离线学习方案应用于预测的历史和实时数据集进行了可行性分析。 |
-
This table clarifies the fundamental models used to address various types of LF problems and briefly highlights the favourable results achieved.
该表阐明了用于解决各类负荷预测问题的基础模型,并简要强调了所取得的良好结果。 -
When considering Table 4, certain issues can be specifically evaluated.
在参考表 4 时,可以对某些问题进行专门评估。 -
For example, DL algorithms such as convolution or feed-forward NNs calculate the output based solely on the current input, without considering the temporal patterns of the data 68.
例如,卷积或前馈神经网络等深度学习算法仅根据当前输入计算输出,而不考虑数据的时间模式 68。 -
However, RNNs introduce forward mapping models based on both current and historical inputs.
然而,RNN 引入了基于当前和历史输入的正向映射模型。 -
The concept of continuous learning and adapting to new patterns is studied in the context of online learning RNN 68.
在线学习 RNN 的背景下研究了持续学习和适应新模式的概念 68。 -
This model has the capacity for continuous learning from newly arriving data, adapting itself by updating RNN weights to accommodate new patterns or changes in data type.
该模型具有从新到达的数据中持续学习的能力,通过更新 RNN 权重来适应新模式或数据类型的变化,从而实现自我调节。 -
Its performance has been compared to other online and offline algorithms.
其性能已与其他在线和离线算法进行了对比。 -
The efficient integration of the online learning concept into LF models is discussed, and an application of an online ensemble-type model is presented 151.
讨论了将在线学习概念有效整合到负荷预测模型中的方法,并展示了一个在线集成型模型的应用 151。 -
In the context of real-time data-driven models, a sliding-window online algorithm based on deep networks has been proposed 152.
在实时数据驱动模型的背景下,提出了一种基于深度网络的滑动窗口在线算法 152。 -
The computational ability under volatile online parameters has been tested through an extensive long-term experimental procedure.
通过广泛的长期实验过程,测试了在波动的在线参数下的计算能力。 -
This perspective is also relevant in an IoT environment. An online-type implementation of LF architecture has been introduced in Refs. 153, 154.
这一观点在物联网(IoT)环境下也具有相关性。文献 153, 154 介绍了一种在线型负荷预测架构的实现。 -
In this approach, issues related to data collection efficiency, caused by the inefficiencies in data meters, are addressed through online and transfer learning techniques using adaptive-based models with time-series data 155.
在这种方法中,通过在线和迁移学习技术,利用基于自适应的时间序列数据模型,解决了由数据仪表效率低下引起的数据收集效率相关问题 155。 -
Furthermore, learning performance has been enhanced through a deep hybrid model featuring a CNN-LSTM network 156.
此外,通过一个具有 CNN-LSTM 网络的深度混合模型增强了学习性能 156。 -
Probabilistic LF is also discussed within the context of adaptive online learning, taking into consideration changing consumption patterns and model parameters 157.
概率负荷预测也在自适应在线学习的背景下进行了讨论,同时考虑了不断变化的消耗模式和模型参数 157。
7. 不确定性感知负荷预测模型
-
LF is a process for estimating future demand based on recent data in national (deregulated) or liberalised energy markets.
负荷预测(LF)是在国家(放松管制)或自由化能源市场中,基于近期数据估算未来需求的过程。 -
The load data obtained from those markets are uncertain and non-linear in nature, necessitating the use of DL methodologies.
从这些市场获得的负荷数据本质上具有不确定性和非线性,因此有必要使用深度学习(DL)方法。 -
DL-based LF helps provide more robust solutions within the energy management framework in terms of cost, efficiency, and reliability 167.
基于深度学习的负荷预测有助于在成本、效率和可靠性方面,为能源管理框架提供更稳健的解决方案 167。 -
Rigorous STLF is essential to recognise the absolute deficit in the balance of energy supply and demand.
严谨的短期负荷预测(STLF)对于识别能源供需平衡中的绝对缺口至关重要。 -
Considering the concept of liberalised power grids, rigorous STLF can also be used as an argument for a price forecasting model to make optimal decisions for system operators, energy suppliers, and end-users 27.
考虑到自由化电网的概念,严谨的 STLF 也可以作为价格预测模型的依据,帮助系统运营商、能源供应商和终端用户做出最佳决策 27。 -
Network-based estimation procedures may experience decreased performance due to uncertainty in real power consumption, primarily because of incomplete metering infrastructure deployment.
由于实际功耗的不确定性(主要是因为计量基础设施部署不完整),基于网络的估算程序可能会出现性能下降。 -
Additionally, inherent issues in NNs, such as overfitting, vanishing gradients, and exploding gradients, can gradually diminish the robustness of forecasting models.
此外,神经网络(NN)固有的问题,如过拟合、梯度消失和梯度爆炸,会逐渐削弱预测模型的稳健性。 -
As a result, DL models with classical or customised NN techniques have been utilised in the literature to enhance performance in dealing with uncertainties.
因此,文献中利用了具有经典或定制神经网络技术的深度学习模型,以增强处理不确定性的性能。 -
Besides the focus on the DL-based STLF concept in this research, the literature is not rich in this area. Therefore, the search scope is expanded to include ML-based robust LF models in order to gather innovative ideas for improving the robustness of STLF.
除了本研究关注的基于深度学习的 STLF 概念外,该领域的文献并不丰富。因此,搜索范围扩大到包括基于机器学习(ML)的稳健负荷预测模型,以收集提高 STLF 稳健性的创新想法。 -
In this context, Table 5 is prepared to present the fundamental concepts and key findings related to uncertainty considerations in each of the referenced papers.
在此背景下,表 5 展示了每篇参考文献中与不确定性考虑相关的基本概念和关键发现。 -
Considering Table 5, studies related to uncertainty in the LF problem encompass both deterministic and probabilistic models.
参考表 5,负荷预测问题中与不确定性相关的研究包括确定性模型和概率性模型。 -
Table 5. Uncertainty-aware LF studies in terms of basic concept and key findings.
表 5. 不确定性感知负荷预测(LF)研究的基本概念与关键发现。
| Ref. | Year | Basic concept (基本概念) | Key findings on uncertainty (关于不确定性的关键发现) |
|---|---|---|---|
| 169 | 2014 | PSO-based lower-upper bound estimation method for LF 基于粒子群算法(PSO)的负荷预测上下限估计方法 | A PSO-based method is proposed for lower-upper bound estimation in LF, as well as a PSO-based probabilistic optimisation formulation to tune the NN parameters, which allows for the formation of prediction intervals for uncertainty quantification. 提出了一种基于 PSO 的负荷预测上下限估计方法,以及一种用于调整神经网络参数的 PSO 概率优化公式,从而能够构建预测区间以进行不确定性量化。 |
| 171 | 2018 | LF model by combination of generalised extreme learning machine, wavelet processing and bootstrapping techniques 结合广义极限学习机、小波处理和自助法(Bootstrapping)技术的负荷预测模型 | The uncertainty formulations for the LF model and data noise are provided using a probabilistic approach. 采用概率方法提供了负荷预测模型和数据噪声的不确定性公式。 |
| 172 | 2018 | Hybrid model with empirical mode decomposition, DBN and ensemble technique for short-term cooling LF 结合经验模态分解、深度信念网络(DBN)和集成技术的短期冷负荷预测混合模型 | In the synthesis of a robust model, statistical analysis is conducted to identify imperfections in the model, and necessary modifications are introduced to the formulation using ensemble techniques. 在构建稳健模型时,通过统计分析识别模型缺陷,并利用集成技术对公式进行必要修正。 |
| 173 | 2018 | Quantile regression forest enhanced by recursive feature elimination model for LF 通过递归特征消除模型增强的分位数回归森林负荷预测 | The merits of probabilistic forecasting under uncertain parameters are highlighted. The level of quantile forecasting is considered in the model to include the uncertain patterns in the load. 强调了不确定参数下概率预测的优点。模型中考虑了分位数预测水平,以纳入负荷中的不确定模式。 |
| 42 | 2019 | DL-based clustering method for STLF 基于深度学习(DL)的短期负荷预测(STLF)聚类方法 | A probabilistic estimation framework is proposed to quantify the electricity consumption responsiveness at the household level by considering the confidence level demand uncertainty. 提出了一种概率估计框架,通过考虑置信水平需求的不确定性,来量化家庭层面的用电响应能力。 |
| 174 | 2019 | Probabilistic model for peak LF 用于峰值负荷预测的概率模型 | The focus is on addressing uncertainties in different weather conditions and peak load using a probabilistic LF approach. The uncertainty occurred in the magnitude and occurrence pattern of the peak load is considered by the probabilistic model. 重点在于使用概率负荷预测方法解决不同天气条件和峰值负荷下的不确定性。概率模型考虑了峰值负荷大小和发生模式中出现的不确定性。 |
| 175 | 2019 | DL-based ensemble probabilistic model 基于深度学习的集成概率模型 | The probabilistic LF framework provides customer classification and multitask representation learning approach to make better uncertainty quantification of individual customers. The framework includes combination of deep ensemble learning and multitask representation to improve the performance for data analysis. 概率预测框架提供了客户分类和多任务表示学习方法,以便更好地量化单个客户的不确定性。该框架结合了深度集成学习和多任务表示,提高了数据分析性能。 |
| 176 | 2020 | STLF model by RL technique with Q-learning based dynamic model selection 基于强化学习(RL)技术及 Q-learning 动态模型选择的 STLF 模型 | Parameterised uncertainty of the deterministic LF, and optimising the uncertainty indicator by minimising the pinball loss with GA. 对确定性负荷预测的不确定性进行参数化,并通过遗传算法(GA)最小化 Pinball 损失来优化不确定性指标。 |
| 5 | 2020 | DL-based CNN network for probabilistic STLF 用于概率 STLF 的基于深度学习的 CNN 网络 | The study provides solution for adaption of the probabilistic LF concept to the CNNs which considers the uncertain cases in the decision variables. A long range discretisation method is presented to define load probability distributions which enables the segmentation of the load using in training procedure. 该研究提供了将概率预测概念应用于 CNN 的解决方案,考虑了决策变量中的不确定情况。提出了一种长程离散化方法来定义负荷概率分布,从而在训练过程中实现负荷分割。 |
| 41 | 2020 | Multitask Bayesian DL network for residential probabilistic LF 用于住宅概率负荷预测的多任务贝叶斯深度学习网络 | Multitask learning probabilistic LF is proposed to quantify simultaneously the mutual uncertainties over specific end-user groups, as well as separating the uncertainty pattern for each group. 提出多任务学习概率负荷预测,以同时量化特定终端用户群体的相互不确定性,并分离每个群体的不确定性模式。 |
| 170 | 2020 | DL-based hybrid model with RNNs and clustering techniques for STLF 基于深度学习的结合 RNN 和聚类技术的 STLF 混合模型 | Detailed analysis of future selection and hyper-parameter fine-tuning mechanisms for the LF accuracy and robustness are given. Proposed model performs well to the variational cases of building type, building operation, seasonal patterns etc. 详细分析了特征选择和超参数微调机制对预测准确性和稳健性的影响。所提模型在建筑类型、建筑运行、季节模式等各种变化情况下表现良好。 |
| 76 | 2021 | Asynchronous deep reinforcement deterministic policy gradient model with adaptive early forecasting method and reward incentive mechanism for STLF 具有自适应早期预测方法和奖励激励机制的异步深度强化确定性策略梯度 STLF 模型 | Robustness analysis for the proposed model is tested by experimental studies. Dataset is divided into two cases which include different training sets and test sets to verify the robustness of the proposed model. 通过实验研究对所提模型进行了稳健性分析。将数据集分为两种情况,包括不同的训练集和测试集,以验证模型的稳健性。 |
| 177 | 2021 | Theory-guided deep-learning LF 理论引导的深度学习负荷预测 | Presenting model has the capacity of training procedure by random disturbance originated by weather and load inaccuracies. 展示的模型具备处理由天气和负荷不准确引起的随机干扰的训练能力。 |
| 178 | 2021 | The deep mixture network for residential STLF model with CNN, GRU, and fully-connected neural layers 用于住宅 STLF 的包含 CNN、GRU 和全连接神经层的深度混合网络模型 | Providing a deep mixture model to capture inherent intermittent uncertainty of the residential load profiles. Uncertainty awareness performance of the model is obtained for single household load, as well as aggregated loads. 提供深度混合模型以捕捉住宅负荷分布中固有的间歇性不确定性。获得了单户负荷及聚合负荷的模型不确定性感知性能。 |
| 69 | 2021 | DBN STLF model by non-dominated sorting GA and k-NN 基于非支配排序遗传算法和 k-NN 的 DBN STLF 模型 | k-NN algorithm is optimised by non-dominated sorting GA, and compared to the other LF models, remarkable improvements are obtained in convergence speed and robustness. Proposed model performs credible robust results that are insensitive to the sample size and train-to-test ratio. 通过非支配排序遗传算法优化 k-NN 算法,与其他模型相比,在收敛速度和稳健性方面取得了显著进步。所提模型表现出可靠的稳健结果,对样本大小和训练测试比不敏感。 |
| 168 | 2022 | End-to-end DL framework of dual-stage attention based quantile LSTM network for STLF 基于双阶段注意力的分位数 LSTM 网络端到端深度学习 STLF 框架 | Pinball loss is adopted as the loss function to better capture load uncertainties. The proposed model promises robust performance against changing variable conditions by adaptively increasing the correlation level of features and reducing the impact of irrelevant variables. 采用 Pinball 损失作为损失函数以更好地捕捉负荷不确定性。所提模型通过自适应增加特征相关水平并减少无关变量的影响,保证了在变量条件变化下的稳健性能。 |
-
Probabilistic models are primarily referenced for representing uncertain dynamics, providing essential background information for robust LF models.
概率模型主要用于表示不确定的动态过程,为稳健的负荷预测模型提供必要的背景信息。 -
Additionally, studies combining online optimisation procedures and statistical approaches offer a promising foundation for robust LF models.
此外,结合在线优化程序和统计方法的研究为稳健的负荷预测模型奠定了有前景的基础。 -
This approach not only allows for iterative parameter updates but also incorporates representations of random variables at specified confidence levels.
这种方法不仅允许迭代更新参数,还纳入了在特定置信水平下的随机变量表示。 -
On the other hand, this concept should be further developed to introduce new patterns that better capture the volatile nature of STLF and to streamline the complexity of the training process.
另一方面,这一概念应进一步发展,以引入能更好捕捉 STLF 波动特性的新模式,并简化训练过程的复杂性。 -
In Table 5, various single or hybrid ML techniques, including LSTM, CNN, RNN, RL, and GRU, are referenced in both probabilistic and deterministic robust LF modelling.
在表 5 中,各种单一或混合机器学习技术(包括 LSTM、CNN、RNN、RL 和 GRU)在概率性和确定性稳健负荷预测建模中均被提及。 -
Furthermore, many papers explore specific LF models supported by concepts such as parameter adaptation, reward incentive mechanisms, clustering, and wavelet processing.
此外,许多论文探索了由参数自适应、奖励激励机制、聚类和小波处理等概念支持的特定负荷预测模型。 -
Optimisation algorithms like PSO, GA, and k-NN are employed for fine-tuning the model parameters.
粒子群优化(PSO)、遗传算法(GA)和 k-最近邻(k-NN)等优化算法被用于微调模型参数。 -
These key findings on the representation of uncertainty in model or exogenous parameters offer valuable insights for future research.
这些关于模型或外部参数中不确定性表示的关键发现,为未来的研究提供了宝贵的见解。 -
Probabilistic LF approaches hold significant potential for representing parametric uncertainty, as exemplified in modelling peak load uncertainty in terms of occurrence and magnitude 168 and load probability distribution 5.
概率性负荷预测方法在表示参数不确定性方面具有巨大潜力,例如对峰值负荷发生时间和强度的不确定性建模 168 以及负荷概率分布建模 5。 -
Additionally, optimisation techniques such as GA and PSO are proposed for hyper-parameter optimisation and assessing prediction uncertainty levels during training 69,169.
此外,提出了遗传算法(GA)和粒子群算法(PSO)等优化技术,用于超参数优化以及评估训练期间的预测不确定性水平 69,169。 -
The optimisation procedures also enhance the convergence rate of the LF model 69.
优化程序还提高了负荷预测模型的收敛速度 69。 -
Considering Table 5, various DL-based robust LF models have been developed using techniques such as adaptive and reward incentive methods, ensemble probabilistic learning, CNN, RNN, GRU, and clustering.
参考表 5,已经利用自适应和奖励激励方法、集成概率学习、CNN、RNN、GRU 和聚类等技术开发了各种基于深度学习的稳健负荷预测模型。 -
In this context, the application of deep RNN techniques aims to enhance LF accuracy and performance under uncertain modelling dynamics 170.
在此背景下,深度 RNN 技术的应用旨在提高不确定建模动态下的负荷预测准确性和性能 170。 -
Additionally, deep RL, which combines the non-linear fitting capabilities of DL with the decision-making abilities of RL, has provided effective solutions to optimisation problems involving both certain and uncertain dynamics.
此外,深度强化学习(Deep RL)结合了深度学习的非线性拟合能力和强化学习的决策能力,为涉及确定性和不确定性动态的优化问题提供了有效的解决方案。 -
For example, a robust framework using an asynchronous deep RL based model is presented in 76.
例如,76 提出了一个使用基于异步深度强化学习模型的稳健框架。 -
This research has conducted multiple comparative experiments to achieve robust LF results.
该研究进行了多次对比实验,以获得稳健的负荷预测结果。 -
Moreover, probabilistic forecasting techniques have the potential to represent the high level of uncertainty in real-time LD with great accuracy.
此外,概率预测技术有潜力以极高的准确度表示实时负荷需求(LD)中的高度不确定性。 -
Regarding the probabilistic concept, the utilisation of CNN, combined with load range discretisation for LF, is proposed 5.
关于概率概念,5 提出了将 CNN 与负荷范围离散化相结合的方法用于负荷预测。 -
This method results in more precise load probability estimates, which are beneficial for decision-making processes in DR applications and provide a significant advantage in feature extraction.
该方法可以获得更精确的负荷概率估计,这有利于需求响应(DR)应用中的决策过程,并在特征提取方面具有显著优势。 -
Furthermore, in pursuit of higher levels of stability and reliability against the uncertain and volatile nature of residential load data, a probabilistic LF model with a multitask Bayesian DL approach is presented 41.
此外,为了针对住宅负荷数据的不确定和波动特性追求更高水平的稳定性和可靠性,41 提出了一种采用多任务贝叶斯深度学习方法的概率性负荷预测模型。 -
Another robust probabilistic baseline estimation framework is provided for quantifying consumer responsiveness to estimate pricing inputs 42.
42 提供了另一个稳健的概率基准估计框架,用于量化消费者响应度以估算定价输入。 -
Clustering approaches have also been employed in STLF to analyse time-series data and identify both certain and uncertain patterns based on different time scales.
聚类方法也被应用于 STLF 中,以分析时间序列数据并识别基于不同时间尺度的确定性和不确定性模式。
8. 基于深度学习的 STLF 研究的实践依据
-
Recently, DL-based STLF studies achieve significance due to their practical justifications in improving the forecasting accuracy, model efficiency, and reliability of electricity grid operations 11.
近年来,基于深度学习的短期负荷预测(STLF)研究由于其在提高预测准确性、模型效率和电网运行可靠性方面的实践依据而具有重要意义 11。 -
Besides, LF should be combined with short-term DR programs that manipulate actual energy demands.
此外,负荷预测(LF)应与操纵实际能源需求的短期需求响应(DR)计划相结合。 -
DR programs aim to reduce electricity demand and maintain a balance between supply and demand by incentivising the shifting of energy usage to off-peak periods.
需求响应计划旨在通过激励能源使用向非高峰时段转移,从而减少电力需求并维持供需平衡。 -
These programs save significant energy and relieve strain on the power grid by aligning with LD. Also, they can leverage LF to encourage consumers to adjust their electricity usage in real-time 179.
这些计划通过与负荷需求(LD)保持一致,节省了大量能源并减轻了电网压力。此外,它们可以利用负荷预测来鼓励消费者实时调整其用电量 179。 -
In this regard, the practical and effective implementation of DR programs coupled with LF promise the benefits of data integration, customer engagement for participation, smart automation concept and fair competitive market regulations.
在这方面,需求响应计划与负荷预测相结合的实际有效实施,有望带来数据集成、客户参与、智能自动化概念和公平竞争的市场监管等益处。 -
Considering utility-based planning and management strategies for electricity generation and distribution, accurate LF has a significant impact on the effectiveness of DR programs.
考虑到基于公用事业的发电和配电规划与管理策略,准确的负荷预测对需求响应计划的有效性有着重大影响。 -
Therefore, LF models should incorporate a wide range of data sources, including historical energy usage patterns, weather forecasts, occupancy data, and other specific factors relevant to the particular problem.
因此,负荷预测模型应纳入广泛的数据源,包括历史能源使用模式、天气预报、占用数据以及与特定问题相关的其他特定因素。 -
Moreover, these models should possess the theoretical and practical capabilities necessary to provide near-real-time predictions.
此外,这些模型应具备提供近实时预测所需的理论和实践能力。 -
In this context, one study introduced a deep RL based forecasting model to enhance the accuracy of predicting RES outputs and loads, with the DR program designed around the predicted load 83.
在此背景下,一项研究引入了基于深度强化学习(RL)的预测模型,以提高预测可再生能源(RES)输出和负荷的准确性,并围绕预测负荷设计了需求响应计划 83。 -
Another study integrated a DL-based approach for daily energy demand prediction into a home energy management system, allowing for a reduction in overall appliance energy costs through linear programming 34.
另一项研究将基于深度学习的每日能源需求预测方法集成到家庭能源管理系统中,通过线性规划降低了家电的总能源成本 34。 -
Another study presented a deep RL approach for designing DR procedures, considering tariff structures based on LF, to provide a more economically efficient energy utilisation strategy for end-users 80.
另一项研究提出了一种用于设计需求响应程序的深度强化学习方法,考虑了基于负荷预测的关税结构,从而为终端用户提供更具经济效益的能源利用策略 80。 -
In a separate effort, a DR management system was designed using a time-of-use-based approach, along with an LSTM-based LF model to predict household appliance energy consumption 63.
在另一项工作中,设计了一个基于分时电价方法的需求响应管理系统,并结合基于 LSTM 的负荷预测模型来预测家用电器的能耗 63。 -
Furthermore, an incentive-based DR program, incorporating customised DL and RL, was proposed, considering LF procedures, electricity prices, and photovoltaic power output 67.
此外,提出了一项基于激励的需求响应计划,结合了定制的深度学习和强化学习,并考虑了负荷预测程序、电价和光伏发电输出 67。 -
Experimental results demonstrated a 17% reduction in peak electricity demand, mitigating supply--demand imbalances through the proposed approach.
实验结果表明,通过该方法,峰值电力需求减少了 17%,缓解了供需失衡。 -
Highlighting the importance of accurate LF for the design of more robust and cost-effective DR strategies, a combined DL-based LSTM LF model was proposed to address multi-timescale electricity consumption behaviour for household residents 100.
强调准确负荷预测对于设计更稳健且具成本效益的需求响应策略的重要性,提出了一种基于深度学习的组合 LSTM 负荷预测模型,以应对家庭居民的多时间尺度用电行为 100。 -
Dealing with precise LF and economic analysis, differentiating between over-forecasting and under-forecasting, have been examined using both hybrid and single LF methods 61.
在使用混合和单一负荷预测方法时,已经对精确负荷预测和经济分析(区分过度预测和预测不足)进行了研究 61。 -
Results indicate that hybrid deep NN-based models outperform other methods, emphasising their significant contribution to the success of DR programs.
结果表明,基于混合深度神经网络的模型优于其他方法,强调了它们对需求响应计划成功的重大贡献。 -
Dynamic pricing or tariff-based approaches are also associated with DL-based STLF problems.
动态定价或基于关税的方法也与基于深度学习的 STLF 问题相关。 -
This concept also plays a crucial role in DR or general energy management strategies. Hence, the literature also contains examples of pricing notions in the related problem.
这一概念在需求响应或一般能源管理策略中也发挥着至关重要作用。因此,文献中也包含了相关问题中定价概念的实例。 -
To emphasise the important role of STLF in power system planning, a multi-scale CNN-LSTM hybrid NN STLF model is presented to reveal the correlation between electricity price and load 180.
为强调 STLF 在电力系统规划中的重要作用,提出了一种多尺度 CNN-LSTM 混合神经网络 STLF 模型,以揭示电价与负荷之间的相关性 180。 -
The relationship between price and LF is also mentioned by proposing multiple-inputs, multiple-outputs deep RNNs models 3.
通过提出多输入多输出深度 RNN 模型,也提到了价格与负荷预测之间的关系 3。 -
The dynamic time-of-use tariff procedure is dealt with by a clustering-based residential load estimation process 42.
通过基于聚类的住宅负荷估算过程来处理动态分时电价程序 42。 -
In this study, the aim is to discuss some basic requirements for DR applications with time-varying pricing schedules.
本研究旨在讨论具有时变价格计划的需求响应应用的一些基本要求。 -
Finally, we will discuss shallow NN models for the LF problem, providing valuable insights for DR applications. These models can be converted into DL format by appropriately adjusting the hidden layers.
最后,我们将讨论负荷预测问题的浅层神经网络模型,为需求响应应用提供宝贵见解。通过适当调整隐藏层,这些模型可以转换为深度学习格式。 -
For example, the optimal program for energy demand is realised for a single household by using ML algorithms to forecast power generation and load aggregation 181.
例如,通过使用机器学习算法预测发电量和负荷聚合,实现了单个家庭能源需求的最佳方案 181。 -
In this model, the output of the forecasting model is used as input for the optimal scheduling procedure.
在该模型中,预测模型的输出被用作最佳调度程序的输入。 -
Another DR study is conducted using forecasting LD data obtained through a new prosumer microgrid criterion with hybrid ML techniques 182.
另一项需求响应研究使用了通过混合机器学习技术在新型产消者微网准则下获得的负荷需求预测数据 182。 -
Unlike other DR studies that consider pre-defined load patterns without using any LF methods, this study shows that the adopted approach leads to more realistic results.
与考虑预定义负荷模式而不使用任何负荷预测方法的其他需求响应研究不同,本研究表明,所采用的方法能够产生更现实的结果。 -
By utilising the IoT concept, compact studies with LF and DR have also been realised.
通过利用物联网(IoT)概念,已经实现了负荷预测与需求响应的紧凑研究。 -
Decision trees and k-NN algorithms are proposed for STLF and price forecasting in a DR program 183.
在需求响应计划中,提出了决策树和 k-NN 算法用于 STLF 和价格预测 183。 -
The non-intrusive load monitoring method is proposed to identify the active LD, as well as adapt them to the appliance usage patterns 184.
提出了非侵入式负荷监控方法来识别活跃的负荷需求,并使其适应电器使用模式 184。 -
This study helps predict household loads in fewer minutes, which is of significant practical interest for DR applications.
这项研究有助于在几分钟内预测家庭负荷,这对于需求响应应用具有重大的实践意义。 -
A multi-agent RL-based model with a DR application is provided by using current load and all-day load prediction to shift higher demand to the period of low demand 185.
通过使用当前负荷和全天负荷预测,提供了一个具有需求响应应用的基于多智能体强化学习的模型,以将较高的需求转移到低需求时段 185。 -
A framework for customer baseline load estimation for the day of a DR program is realised through load pattern forecasting 186.
通过负荷模式预测,实现了一个用于需求响应计划实施日客户基准负荷估算的框架 186。 -
LF is executed using unsupervised learning-based data mining approaches with self-organising maps and k-means clustering.
利用基于无监督学习的数据挖掘方法(包括自组织映射和 k-均值聚类)执行负荷预测。 -
An efficient energy management system was developed using hundreds of digital passive infrared occupancy sensors to detect data anomalies 187.
利用数百个数字被动红外占用传感器开发了一个高效的能源管理系统,以检测数据异常 187。 -
This setup utilises an LSTM network for day-ahead energy consumption forecasting, particularly for potential DR applications.
该装置利用 LSTM 网络进行日前能耗预测,特别是针对潜在的需求响应应用。 -
Real-time training of RNNs using a parallel processing ANN approach is formulated for STLF 188.
针对 STLF 制定了使用并行处理人工神经网络方法的 RNN 实时训练方案 188。 -
A comparative analysis is proposed to show the suitability of GA and PSO to train the NN model for real-time LF 189.
提出了一项对比分析,以展示遗传算法(GA)和粒子群算法(PSO)在训练实时负荷预测神经网络模型方面的适用性 189。 -
Real-time anomaly detection for STLF is presented as a dynamic regression model 190.
STLF 的实时异常检测以动态回归模型形式呈现 190。 -
Moreover, a unified ML-based training data generator concept with a look-back optimiser, which simultaneously performs electrical LF and unsupervised anomaly detection in real-time, is provided 191.
此外,提供了一个统一的基于机器学习的训练数据生成器概念,配备回顾优化器,可同时实时执行电力负荷预测和无监督异常检测 191。 -
Real-time short-term residential load consumption problems are handled by RNN-LSTM techniques to offer a DR scheme to reduce peak LD 192.
通过 RNN-LSTM 技术处理实时短期住宅负荷消耗问题,以提供旨在减少峰值负荷需求的需求响应方案 192。
9. 讨论、进一步建议与局限性
-
To enhance the feasibility, reliability, and robustness of DL-based STLF solutions, it is essential to focus on performance indicators such as sensitivity, uncertainty bands, and dataset uniformity.
为了增强基于深度学习(DL)的短期负荷预测(STLF)解决方案的可行性、可靠性和稳健性,必须关注灵敏度、不确定带和数据集均匀性等性能指标。 -
Additionally, extending the forecasting problem to include renewables managed by DR applications can introduce innovation by utilising real-time data for feedback mechanisms.
此外,将预测问题扩展到包括由需求响应(DR)应用管理的可再生能源,可以通过利用实时数据进行反馈机制来引入创新。 -
This approach establishes a closed-loop model, potentially accelerating convergence toward predefined success criteria.
这种方法建立了一个闭环模型,有可能加速向预定义成功标准的收敛。 -
Furthermore, when considering internal parameter optimisation within DL models, the incorporation of evolutionary algorithms can lead to more accurate and robust forecasts.
此外,在考虑深度学习模型内部参数优化时,结合进化算法可以实现更准确、更稳健的预测。 -
In light of these considerations, the following suggestions are proposed.
基于这些考虑,提出了以下建议。
9.1. 深度学习模型中的灵敏度
-
Balancing sensitivity in DL models is crucial for addressing STLF challenges through feature selection, data smoothing, and model complexity considerations.
通过特征选择、数据平滑和模型复杂度考量来平衡深度学习模型的灵敏度,对于应对 STLF 挑战至关重要。 -
In DL models, sensitivity refers to the responsiveness and flexibility of predictions when faced with variations in input data or parameters.
在深度学习模型中,灵敏度是指预测在面对输入数据或参数变化时的响应能力和灵活性。 -
Highly sensitive models may produce unreliable predictions in response to minor deviations in the input data.
高度敏感的模型可能会针对输入数据的轻微偏差产生不可靠的预测。 -
To address the STLF problem, various strategies and techniques can be employed to determine the optimal level of sensitivity.
为了解决 STLF 问题,可以采用各种策略和技术来确定最佳灵敏度水平。 -
For instance, one approach involves the meticulous selection of input features that are less susceptible to noise or data fluctuations.
例如,一种方法涉及细致地选择对噪声或数据波动较不敏感的输入特征。 -
Instead of relying solely on static data, incorporating factors such as temperature or occupancy trends within daily or even hourly averages can be considered.
与其仅仅依赖静态数据,不如考虑将温度或占用趋势等因素纳入每日甚至每小时的平均值中。 -
Furthermore, features can be normalised or scaled to emphasise relevant patterns.
此外,可以对特征进行归一化或缩放以强调相关模式。 -
In addition, data-smoothing techniques like moving, exponential, or kernel smoothing can be introduced to reduce noise in the data, thereby making the model more sensitive.
此外,可以引入移动平滑、指数平滑或核平滑等数据平滑技术来减少数据中的噪声,从而使模型更具敏感性(且稳健)。 -
Although certain approaches... may introduce complexity, they prove valuable in regulating sensitivity.
虽然某些方法(如通过混合模型捕获短期和长期趋势、将多个模型组合成集成框架、包含不确定性估计滤波器等)可能会增加复杂性,但事实证明它们在调节灵敏度方面非常有价值。 -
Implementing cross-validation to identify and fine-tune the model makes predictions less sensitive to fluctuations in load data.
实施交叉验证以识别和微调模型,使预测对负荷数据的波动不那么敏感。 -
On the other hand, the careful tuning of hyperparameters, as well as the judicious determination of the number of hidden layers, strikes a fine balance between model complexity and sensitivity.
另一方面,仔细调整超参数以及明智地确定隐藏层数量,可以在模型复杂度和灵敏度之间达到良好的平衡。
9.2. 处理深度学习模型中的不确定性
-
Addressing uncertainty in DL models through probabilistic forecasting, online feedback loops, and ensemble techniques enhances accuracy and robustness for STLF.
通过概率预测、在线反馈回路和集成技术解决深度学习(DL)模型中的不确定性,可以增强短期负荷预测(STLF)的准确性和稳健性。 -
The uncertainty in DL models can arise from inherent randomness or variability in the observed data and a lack of knowledge about certain modelling dynamics.
深度学习模型中的不确定性可能源于观测数据中固有的随机性或变异性,以及对某些建模动态的认知匮乏。 -
Attempting to achieve complete modelling or eliminate data fluctuations is inconclusive.
试图实现完全建模或消除数据波动是徒劳的(无定论的)。 -
Therefore, the aim is to develop models that can handle uncertainty by considering parameters with changing trends to provide more accurate predictions.
因此,目标是开发能够通过考虑具有变化趋势的参数来处理不确定性的模型,从而提供更准确的预测。 -
To accomplish this, the proposal includes an online feedback prediction loop that continuously monitors forecasting performance to update the model's parameters.
为了实现这一目标,该方案包含一个在线反馈预测回路,持续监控预测性能以更新模型参数。 -
This approach can also eliminate the influence arising from data logging external variables.
这种方法还可以消除因外部变量数据记录而产生的影响。 -
The uncertainty-aware framework incorporates specific techniques, such as probabilistic LF, which provides a range of possible values, and quantifying uncertainties using NNs, hybrid or ensemble modelling.
该不确定性感知框架纳入了特定技术,例如提供可能值范围的概率负荷预测(LF),以及使用神经网络(NNs)、混合或集成建模来量化不确定性。 -
DL approaches gain robustness through probabilistic forecasting, as they provide a range of values rather than a single point estimate.
深度学习方法通过概率预测获得稳健性,因为它们提供的是一个数值范围而非单点估计。 -
Therefore, it is possible to integrate the probable distribution of values into the model's mapping mechanism.
因此,可以将值的概率分布整合到模型的映射机制中。 -
By using Bayesian NNs, the weights are treated as random variables with probability distributions, and prediction intervals can be extracted at specified confidence levels.
通过使用贝叶斯神经网络(Bayesian NNs),权重被视为具有概率分布的随机变量,并可以在指定的置信水平下提取预测区间。 -
Furthermore, hybrid and ensemble models can combine LF methods and leverage the strengths of each component to provide more accurate and robust predictions.
此外,混合和集成模型可以结合多种预测方法,并利用各组件的优势来提供更准确和稳健的预测。 -
Therefore, the techniques proposed here for achieving a more certain DL-based STLF model can be applied in future studies, as they capture distinct aspects of LD characteristics.
因此,本文提出的旨在实现更确定性的深度学习 STLF 模型的技术可以应用于未来的研究,因为它们捕捉到了负荷需求(LD)特征的不同方面。
9.3. 利用多智能体系统和物联网创新 STLF
-
Expanding the capabilities of STLF through the integration of multi-agent systems and the IoT for real-time DR applications promises to revolutionise LF models and ensure heightened accuracy and coordination.
通过整合多智能体系统(MAS)和物联网(IoT)来扩展短期负荷预测(STLF)的能力,有望彻底改变负荷预测模型,并确保更高的准确性和协调性。 -
Building upon the discussion in Section 8, the primary focus is on real-time implementations of DR applications for short-term energy management.
基于第 8 节的讨论,主要焦点在于用于短期能源管理的需量响应(DR)应用的实时实现。 -
Furthermore, DL-based LF models can take on new, innovative forms by incorporating valuable theoretical and practical approaches, as well as groundbreaking ideas.
此外,基于深度学习(DL)的负荷预测模型可以通过结合有价值的理论和实践方法以及突破性的想法,呈现出全新的创新形式。 -
The scope of this concept can be broadened by harnessing the power of multi-agent systems and the IoT.
通过利用多智能体系统和物联网的力量,这一概念的范畴可以得到进一步拓宽。 -
The multi-agent approach is centred around systems in which multiple autonomous agents interact with each other and their environment.
多智能体方法的核心在于多个自治智能体之间及其与环境之间相互作用的系统。 -
On the other hand, IoT pertains to the interconnection of physical objects, devices, and systems that collect and exchange data for autonomous operation.
另一方面,物联网涉及物理对象、设备和系统的互连,它们收集并交换数据以实现自主运行。 -
A fundamental distinction between multi-agent systems and the IoT concept lies in the fact that ''IoT focuses on connecting physical devices for data sensing, while multi-agent systems focus on distributed decision-making among autonomous agents''.
多智能体系统与物联网概念的一个根本区别在于:"物联网侧重于连接物理设备以进行数据感知,而多智能体系统侧重于自治智能体之间的分布式决策"。 -
IoT and multi-agent systems significantly enhance the capabilities of LF models in terms of accuracy and reliability.
物联网和多智能体系统在准确性和可靠性方面显著增强了负荷预测模型的能力。 -
Sensing and metering IoT devices provide real-time data on consumption, grid balance conditions, unexpected events, and equipment monitoring.
感测和计量的物联网设备提供了关于能耗、电网平衡状况、突发事件以及设备监控的实时数据。 -
Furthermore, multi-agent systems enable better coordination and utilisation of resources, facilitate load management actions (such as load shifting or shedding), decentralise decision-making, and ensure secure communication among the agents.
此外,多智能体系统能够实现更好的资源协调与利用,促进负荷管理行动(如移峰或削峰),实现决策去中心化,并确保智能体之间的安全通信。
9.4. 用于增强分析的数据集均匀性
-
The performance of data-driven multi-layer models hinges on dataset uniformity and necessitates decoupling mutual effects among various LTs to design efficient DR applications.
数据驱动的多层模型的性能取决于数据集的统一性,并且需要解耦各种负荷类型(LTs)之间的相互影响,以设计高效的需量响应(DR)应用。 -
In the literature, the majority of datasets are obtained from operator-based loads, which encompass a mixed form of energy demand patterns.
在现有文献中,大多数数据集源自运营商负荷,这些负荷包含混合形式的能源需求模式。 -
These patterns include various end-user types, such as residential, industrial, EV charging stations, and public buildings.
这些模式包括各种终端用户类型,如住宅、工业、电动汽车(EV)充电站和公共建筑。 -
Furthermore, some shared components of these LTs, like heating-ventilation-air conditioning or private charging units, significantly contribute to the total LD.
此外,这些负荷类型中的一些共有组件,如供暖通风空调(HVAC)或私人充电单元,对总负荷需求(LD)有显著贡献。 -
Therefore, it is essential to decouple the mutual effects of these factors from each LT to enable feasible analysis.
因此,必须从每种负荷类型中解耦这些因素的相互影响,以实现可行的分析。 -
This approach allows for the ideal design of DR applications.
这种方法有助于实现需量响应应用的理想设计。 -
This situation raises the question of how to separate the basic LTs and distinguish the significant common sub-classes of loads.
这种情况引出了一个问题:如何分离基础负荷类型并区分重要的共有负荷子类。 -
The answer to this question requires expanding the dataset's scope to include factors such as energy demand, occupancy patterns for different regional family types, social preference surveys, weather-based dynamics, and more.
这一问题的答案在于扩大数据集的范围,纳入能源需求、不同地区家庭类型的占用模式、社会偏好调查、基于天气的动态因素等。 -
With such a comprehensive dataset, forecasting models can establish extensive mapping networks between input and output characteristics, enabling the implementation of versatile DR-based programs.
通过如此全面的数据集,预测模型可以在输入和输出特征之间建立广泛的映射网络,从而实现多样化的需量响应计划。
9.5. 整合可再生能源与进化算法
-
Combining DR with renewables and harnessing evolutionary algorithms promises to reduce load variability and enhance the accuracy and robustness of the STLF models.
将需量响应(DR)与可再生能源(RESs)相结合,并利用进化算法,有望减少负荷波动性,并增强短期负荷预测(STLF)模型的准确性和稳健性。 -
The sudden time-based variability in LD can be mitigated by utilising RESs in conjunction with DR applications.
通过将可再生能源与需量响应应用结合使用,可以缓解负荷需求(LD)在时间维度上的突发波动。 -
DR programs can influence end-users' usage habits by offering profitable incentives.
需量响应计划可以通过提供经济激励来影响终端用户的用电习惯。 -
As a result, the volatility of demand can be maintained at a reasonable level.
结果是,需求的波动性可以维持在合理的水平。 -
Therefore, incorporating DR applications and renewables into the feedback dynamics of the LF problem reduces the magnitude of the challenge.
因此,将需量响应应用和可再生能源纳入负荷预测问题的反馈动态中,可以降低预测任务的难度。 -
Evolutionary algorithms also improve the performance of STLF models in terms of accuracy and robustness.
进化算法同样在准确性和稳健性方面提升了 STLF 模型的性能。 -
They can optimise future subsets of the search range, as well as various combinations of hyperparameters using feature selection criteria based on mutual information and forecasting scores.
它们可以基于互信息和预测评分的特征选择准则,优化搜索范围的未来子集以及超参数的各种组合。 -
Evolutionary algorithms have an immense capacity to overcome trapping on a local minima.
进化算法具有克服陷入局部最优解(Local Minima)的巨大潜力。 -
They provide candidate solutions in the vicinity of local minima to search for the global solution.
它们在局部最优解附近提供候选方案,以寻找全局最优解。 -
When considering GAs, this process can be primarily managed by mutation operators that introduce random changes into the candidate solutions.
在考虑遗传算法(GAs)时,这一过程主要由变异算子管理,通过向候选方案引入随机变化来实现。 -
Therefore, it is proposed as a future direction to use GAs with multiple mutation operators 24.
因此,未来的一个研究方向是使用带有多种变异算子的遗传算法 24。 -
In each iteration, a specific mutation operator is chosen and applied to the optimal hyperparameter search problem.
在每次迭代中,选择并应用特定的变异算子来处理最优超参数搜索问题。 -
This increases the randomness level of the solution, directly enhancing the convergence rate of the parameters to the global optimal points.
这增加了方案的随机化水平,直接提高了参数向全局最优点收敛的速度。
9.6. 为能源决策者提供准确的 STLF 见解
-
Accurate STLF provides critical insights for informed decision-making in the energy sector, leading to optimised energy operations, enhanced grid stability, increased profitability, and reduced operational costs.
准确的短期负荷预测(STLF)为能源领域的明智决策提供了关键见解,从而实现了能源运行的优化、电网稳定性的增强、盈利能力的提升以及运营成本的降低。 -
Considering the valuable insights and benefits of LF, the players of the sector can be informed for making the right decisions on the operation procedures for some key factors.
考虑到负荷预测(LF)带来的宝贵见解和效益,行业参与者可以据此针对一些关键因素的运行流程做出正确决策。 -
Those factors can be listed as optimised energy production and consumption, enhanced grid stability and more profitable trading and reducing the operational costs.
这些因素包括:优化的能源生产与消费、增强的电网稳定性、更具盈利性的交易以及运营成本的缩减。 -
Those factors can be subjected to the above-mentioned discussions for technical issues, as well as they can lead to the sector through the data drive decision making environment.
这些因素既可以作为上述技术问题的讨论对象,也可以通过数据驱动的决策环境引领整个行业的发展。
10. 结论
-
In this review, recent studies on STLF using DL were compiled. These studies were categorised based on their proposed techniques, primary objectives, and the datasets they employed.
在本综述中,汇编了近期使用深度学习进行 STLF 的研究。这些研究根据其提出的技术、主要目标和所使用的数据集进行了分类。 -
In conclusion, DL-based STLF has emerged as a popular research direction in the search for more accurate and high-performance solutions for LF.
总之,基于深度学习的 STLF 已成为寻求更准确、高性能负荷预测解决方案的热门研究方向。 -
Improved LF can directly contribute to the economic welfare of the SG concept. Obtaining more reliable and faster STLF solutions can lead to the widespread adoption of DR applications in grid operations.
改进的负荷预测可以直接促进智能电网(SG)概念的经济福利。获得更可靠、更快速的 STLF 解决方案可以促进需求响应应用在电网运行中的广泛采用。 -
Therefore, this review facilitates individuals seeking an understanding of the background of DL-based STLF problems and furnishes them with a succinct comparative analysis of the merits and drawbacks of the proposed techniques.
因此,本综述为寻求了解基于深度学习的 STLF 问题背景的人士提供了便利,并为他们提供了关于所提技术优缺点的简洁对比分析。