业务痛点:某城商行个人贷款年放款额超500亿元,人工审核依赖经验判断,存在三大问题:
- 效率低:单笔审核耗时2-3天,旺季积压严重
- 主观性强:不同审核员对"收入稳定性"等指标判断差异大,导致风险偏好不一致
- 漏判率高:历史数据显示,人工审核后首年违约率仍达3.2%,年损失超5000万元
项目目标:构建逻辑回归违约风险预测模型,实现"申请信息→违约概率"的自动化评估,目标:
- 模型性能:AUC-ROC≥0.85,KS值≥0.4(区分违约/正常客户)
- 业务效率:审核时间从3天缩短至2小时,人工干预率降低50%
- 风险控制:首年违约率降至2.8%以下,年减少损失≥3000万元
开发环境与工具链
- 语言:Python 3.9
- 数据处理:Pandas 1.5+、NumPy 1.23+、Imbalanced-learn(SMOTE)
- 模型训练:Scikit-learn 1.2+(逻辑回归)、SHAP(特征重要性解释)
- 实验跟踪:MLflow(记录参数/指标/模型)
- 服务部署:Flask 2.3+、Gunicorn(WSGI服务器)、Docker 24.0+
- 版本控制:Git + DVC(数据版本管理)
- 监控:Prometheus(指标采集)+ Grafana(可视化)
数据准备与特征变化
(1)原数据结构(示例)
① 信贷申请表(loan_applications.csv)

② 央行征信数据(credit_records.csv)
③ 历史贷款数据库(historical_loans.csv,含标签)

④ 第三方数据(社保/公积金,social_security.csv)

(2)数据清洗与特征工程
缺失值:
- income_monthly(月收入):自由职业者用"社保缴纳基数×行业均值"填充(如互联网行业均值1.2倍)
- overdue_times_1y(1年内逾期次数):无征信记录者填0(视为信用白户)
异常值处理:
- ebt_ratio(负债比)>1(资不抵债)视为无效,用同类职业中位数替换
- age<22或>65(超出常规工作年龄):标记为高风险,单独分组
特征提取:
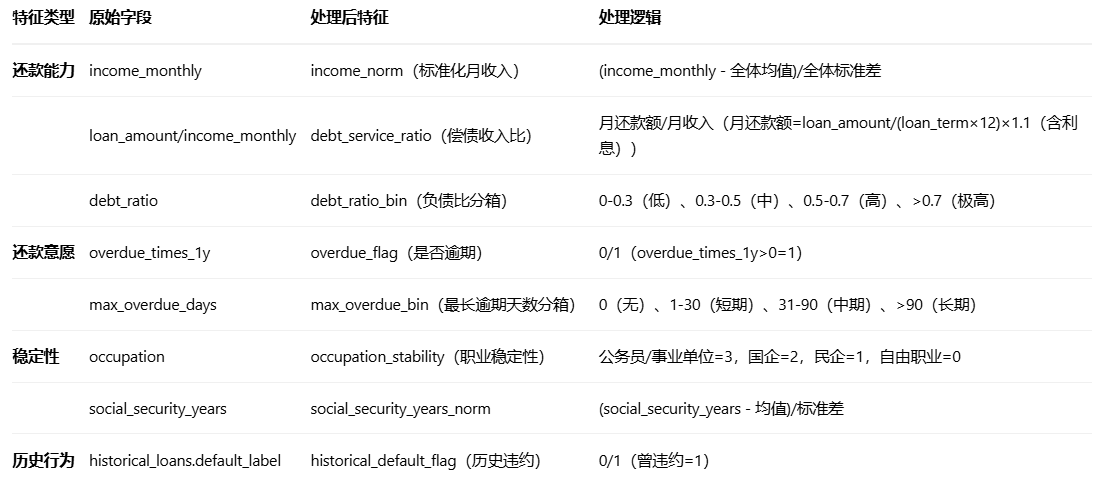
特征编码与标准化
- 互联网、公务员、自由职业类别用LabelEncoder
- 购房装修、子女教育、创业资金用One-Hot
- 收入、社保年限用StandardScaler标准化
- SMOTE过采用合成

处理后的数据(特征矩阵)

代码结构
text
credit_risk_prediction/ # 项目根目录
├── data/ # 数据存储
│ ├── raw/ # 原始数据(DVC跟踪)
│ │ ├── loan_applications.csv
│ │ ├── credit_records.csv
│ │ ├── historical_loans.csv
│ │ └── social_security.csv
│ ├── processed/ # 处理后数据
│ │ └── features_train.parquet
│ └── external/ # 外部数据(职业稳定性映射表)
│ └── occupation_stability_map.json
├── src/ # 源代码
│ ├── data_processing/ # 数据处理模块
│ │ ├── __init__.py
│ │ ├── clean_data.py # 数据清洗
│ │ └── feature_engineering.py # 特征工程
│ ├── model/ # 模型模块
│ │ ├── __init__.py
│ │ ├── train.py # 模型训练(逻辑回归)
│ │ ├── evaluate.py # 模型评估(AUC/KS)
│ │ ├── explain.py # 特征重要性解释(SHAP)
│ │ └── predict.py # 预测推理
│ ├── api/ # API服务
│ │ ├── app.py # Flask服务入口
│ │ └── schemas.py # 请求/响应格式定义(Pydantic)
│ └── utils/ # 工具函数
│ ├── logger.py # 日志配置
│ ├── config.py # 配置文件(路径/参数)
│ └── metrics.py # 自定义评估指标(KS值)
├── tests/ # 单元测试
│ ├── test_feature_engineering.py
│ └── test_model.py
├── docker/ # Docker部署文件
│ ├── Dockerfile
│ └── requirements.txt
├── mlruns/ # MLflow实验跟踪(Git忽略)
├── README.md # 项目说明
└── requirements.txt # Python依赖数据清洗与特征工程(src/data_processing/feature_engineering.py)
还款能力:业务意义,衡量借款人的还款压力,比率越高风险越大
- loan_amount / (loan_term * 12):计算基础月还款额(本金)
-
- 1.1:增加10%作为利息估算
- / income_monthly:得到债务收入比
还款意愿特征:
- debt_ratio 分箱:0-30%(0),30-50%(1),50-70%(2),70-100%(3)
- max_overdue_days 分箱:无逾期(0),1-30天(1),31-90天(2),90天以上(3)
稳定性特征:
- 将职业类型映射为稳定性分数(occ_map 是预设的映射字典)
- 未映射的职业默认值为0(最不稳定)
数据合并:
text
apps_df(申请信息)
↓ 合并 ss_df(可能为社保/工作信息)
↓ 合并 credit_df(信用信息)
↓ 合并 hist_df(历史表现,包含标签)
python
import pandas as pd
import numpy as np
import json
from sklearn.preprocessing import StandardScaler,LabelEncoder,OneHotEncoder
from imblearn.voer_sampling import SMOTE # 处理类别不平衡
from src.utils.logger import get_logger
logger = get_logger(__name__)
def load_occupation_stability_map(path:str)->dict:
"""加载职业稳定性映射表(外部配置)"""
with open(path,"r") as f:
return json.load(f)
def feature_engineering(raw_data_dir:str,external_dir:str,output_path:str):
"""
特征工程主函数:整合原始数据→清洗→特征提取→编码→标准化→过采样→保存
Args:
raw_data_dir: 原始数据目录(含4个CSV)
external_dir: 外部数据目录(职业稳定性映射表)
output_path: 处理后特征矩阵保存路径(parquet)
Returns:
processed_df: 处理后的特征矩阵(含标签)
scaler: 标准化器(用于预测时复用)
smote: SMOTE过采样对象(记录采样参数)
"""
# 1.加载原始数据
apps_df = pd.read_csv(f"{raw_data_dir}/loan_applications.csv")
credit_df = pd.read_csv(f"{raw_data_dir}/credit_records.csv")
hist_df = pd.read_csv(f"{raw_data_dir}/historical_loans.csv")
ss_df = pd.read_csv(f"{raw_data_dir}/social_security.csv")
occ_map = load_occupation_stability_map(f"{external_dir}/occupation_stability_map.json")# 职业稳定性映射
# 2.数据清洗
# 填充月收入缺失值(自由职业者用社保技术*1.2)
apps_df["income_monthly"] = apps_df.apply(
lambda x: x["income_monthly"] if not pd.isna(x["income_monthly"])
else ss_df[ss_df["applicant_id"] == x["applicant_id"]]["social_security_base"].iloc[0] * 1.2
if x["occupation"] == "自由职业" and not ss_df[ss_df["applicant_id"] == x["applicant_id"]].empty
else apps_df["income_monthly"].median(), # 其他情况用中位数
axis=1
)
# 2.2 处理负债比异常值(>1视为无效,用同类职业中位数替换)
occ_median_debt = credit_df.groupby("applicant_id").apply( # 按申请人关联职业后计算
lambda x: apps_df[apps_df["applicant_id"] == x.name]["occupation"].iloc[0]
).reset_index().merge(apps_df[["applicant_id", "occupation"]], on="applicant_id").groupby("occupation")["debt_ratio"].median()
credit_df["debt_ratio"] = credit_df.apply(
lambda x: occ_median_debt[apps_df[apps_df["applicant_id"] == x["applicant_id"]]["occupation"].iloc[0]]
if x["debt_ratio"] > 1 else x["debt_ratio"], axis=1
)
# 3.特征提取(核心业务逻辑)
# 3.1 还款能力特征
apps_df["debt_service_ratio"] = (apps_df["loan_amount"] / (apps_df["loan_term"] * 12)) * 1.1 / apps_df["income_monthly"] # 含利息月还款额/月收入
# 将连续变量debt_ratio(负债比)进行分箱处理
credit_df["debt_ratio_bin"] = pd.cut(credit_df["debt_ratio"], bins=[0, 0.3, 0.5, 0.7, 1], labels=[0, 1, 2, 3]) # 负债比分箱
# 3.2 还款意愿特征
credit_df["overdue_flag"] = (credit_df["overdue_times_1y"] > 0).astype(int)
credit_df["max_overdue_bin"] = pd.cut(credit_df["max_overdue_days"], bins=[-1, 0, 30, 90, np.inf], labels=[0, 1, 2, 3])
# 3.3 稳定性特征
apps_df["occupation_stability"] = apps_df["occupation"].map(occ_map).fillna(0) # 映射职业稳定性(默认0)
merged_df = apps_df.merge(ss_df, on="applicant_id", how="left").merge(credit_df, on="applicant_id", how="left").merge(hist_df[["applicant_id", "default_label"]], on="applicant_id", how="left")
# 4. 特征编码与标准化
# 4.1 类别特征编码
# 有序类别:occupation_stability(LabelEncoder)
le = LabelEncoder()
merged_df["occupation_stability_enc"] = le.fit_transform(merged_df["occupation_stability"])
# 无序类别:purpose(One-Hot编码)
ohe = OneHotEncoder(sparse_output=False,drop="first") # 避免多重共线性
purpose_ohe = ohe.fit_transform(merged_df[["purpose"]])
purpose_cols = [f"purpose_{cat}" for cat in ohe.categories_[0][1:]] # 去掉第一个类别
purpose_df = pd.DataFrame(purpose_ohe, columns=purpose_cols)
# 4.2 连续特征标准化
continuous_features = ["income_monthly", "social_security_years"]
scaler = StandardScaler()
merged_df[continuous_features] = scaler.fit_transform(merged_df[continuous_features])
merged_df.rename(columns={"income_monthly": "income_norm", "social_security_years": "social_security_years_norm"}, inplace=True)
# 5. 类别不平衡处理(SMOTE过采样)
features = [
"income_norm", "debt_service_ratio", "debt_ratio_bin", "overdue_flag",
"occupation_stability_enc", "social_security_years_norm", "historical_default_flag"
] + purpose_cols
X = merged_df[features]
y = merged_df["default_label"] # 标签:1=违约,0=正常
smote = SMOTE(random_state=42, sampling_strategy=1.0) # 正负样本比1:1
X_resampled, y_resampled = smote.fit_resample(X, y)
# 6. 构造最终特征矩阵
processed_df = pd.concat([X_resampled.reset_index(drop=True), y_resampled.reset_index(drop=True)], axis=1)
processed_df.to_parquet(output_path, index=False)
logger.info(f"特征工程完成,保存至{output_path},样本数:{len(processed_df)}(原始{y.sum()}正样本,过采样后{y_resampled.sum()}正样本)")
return processed_df, scaler, smote
模型训练与评估(src/model/train.py& evaluate.py)
python
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from src.utils.logger import get_logger
import mlflow
import joblib
logger = get_logger(__name__)
def train_logistic_regression(features_path: str, test_size: float = 0.2, random_state: int = 42, C: float = 1.0):
"""
训练逻辑回归模型(带L2正则化)
Args:
features_path: 特征矩阵路径(parquet)
test_size: 测试集比例
random_state: 随机种子
C: 正则化强度倒数(C越小正则化越强)
Returns:
model: 训练好的逻辑回归模型
X_test, y_test: 测试集特征与标签
scaler: 标准化器(从特征工程返回,此处简化为重新加载)
"""
# 加载特征矩阵
df = pd.read_parquet(features_path)
X = df.drop(columns=["default_label"])
y = df["default_label"]
# 划分训练集/测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=test_size, random_state=random_state, stratify=y # 分层抽样保持类别分布
)
# 训练逻辑回归模型(L2正则化,Sigmoid激活)
model = LogisticRegression(
penalty="12",# L2正则化
C=C,# 正则化强度倒数
solver="liblinear", # 适用于小数据集
class_weight="balanced", # 平衡类别权重(备选方案)
random_state=random_state
)
model.fit(X_train,y_train)
#记录实验(MLflow)
with mlflow.start_run():
mlflow.log_param("model", "LogisticRegression")
mlflow.log_param("penalty", "l2")
mlflow.log_param("C", C)
mlflow.log_metric("train_accuracy", model.score(X_train, y_train))
mlflow.log_metric("test_accuracy", model.score(X_test, y_test))
mlflow.sklearn.log_model(model, "logistic_regression_model")
logger.info(f"模型训练完成,参数C={C},测试集准确率={model.score(X_test, y_test):.4f}")
# 保存模型和标准化器
joblib.dump(model, "model/logistic_regression_model.pkl")
joblib.dump(scaler, "model/scaler.pkl") # 假设scaler已保存
return model, X_test, y_test
python
# src/model/evaluate.py
import numpy as np
import pandas as pd
from sklearn.metrics import roc_auc_score, confusion_matrix, classification_report
from src.utils.metrics import calculate_ks # 自定义KS值计算
from src.utils.logger import get_logger
logger = get_logger(__name__)
def evaluate_model(model, X_test, y_test):
"""
评估模型性能(AUC-ROC/KS/混淆矩阵)
Args:
model: 训练好的模型
X_test: 测试集特征
y_test: 测试集标签
Returns:
metrics: 评估指标字典
验收标准:测试集AUC-ROC≥0.85,KS≥0.4,精确率≥0.75,召回率≥0.60
"""
y_pred_proba = model.predict_proba(X_test)[:,1] # 违约概率(正类概率)
y_pred = model.predict(X_test) # 预测类别(阈值=0.5)
# 核心指标
auc = roc_auc_score(y_test,y_pred_proba)
ks = calculate_ks(y_test,y_pred_proba)
cm = confusion_matrix(y_test,y_pred)
tn,fp,fn,tp = cm.ravel()
precision = tp/(tp+fp)if(tp+fp)>0 else 0
recall = tp/(tp+fn) if (tp+fn)>0 else 0
metircs = {
"AUC-ROC": auc,
"KS": ks,
"Precision": precision,
"Recall": recall,
"ConfusionMatrix": {"TN": tn, "FP": fp, "FN": fn, "TP": tp}
}
logger.info(f"模型评估结果:{metrics}")
return metrics
# src/utils/metrics.py(KS值计算)
def calculate_ks(y_true, y_pred_proba):
"""计算KS值(区分违约/正常客户的能力)"""
df = pd.DataFrame({"y_true": y_true, "y_pred_proba": y_pred_proba}).sort_values("y_pred_proba", ascending=False)
df["cum_good"] = (1 - df["y_true"]).cumsum() / (1 - df["y_true"]).sum()
df["cum_bad"] = df["y_true"].cumsum() / df["y_true"].sum()
df["ks"] = df["cum_bad"] - df["cum_good"]
return df["ks"].max()模型服务化(Flask API,src/api/app.py)
python
from flask import Flask, request, jsonify
import joblib
import pandas as pd
import numpy as np
from src.data_processing.feature_engineering import feature_engineering # 复用特征工程逻辑(简化版)
from src.utils.logger import get_logger
from pydantic import BaseModel, Field # 请求参数校验
logger = get_logger(__name__)
app = Flask(__name__)
# 加载模型与服务端资源(启动时加载)
model = joblib.load("model/logistic_regression_model.pkl")
scaler = joblib.load("model/scaler.pkl")
occupation_stability_map = {"公务员": 3, "事业单位": 3, "国企": 2, "民企": 1, "自由职业": 0}
# 请求参数校验模型
class PredictionRequest(BaseModel):
applicant_id: str = Field(..., description="申请人ID")
age: int = Field(..., ge=22, le=65, description="年龄(22-65岁)")
occupation: str = Field(..., description="职业")
income_monthly: float = Field(..., gt=0, description="月收入(元)")
loan_amount: float = Field(..., gt=0, description="贷款金额(元)")
loan_term: int = Field(..., ge=12, le=60, description="贷款期限(月,12-60)")
purpose: str = Field(..., description="贷款用途")
overdue_times_1y: int = Field(default=0, ge=0, description="1年内逾期次数")
debt_ratio: float = Field(default=0.0, ge=0, lt=1, description="负债比")
social_security_years: float = Field(default=0.0, ge=0, description="社保缴纳年限")
historical_default_flag: int = Field(default=0, ge=0, le=1, description="历史违约标志(0/1)")
@app.route("/predict_risk", methods=["POST"])
def predict_rick():
"""
违约风险预测API
请求格式:JSON(符合PredictionRequest模型)
响应格式:JSON(违约概率、风险等级、关键影响因素)
"""
try:
# 1.参数校验与解析
req_data = request.get_json()
req = PredictionRequest(**req_data)
# 2. 构造单条样本(复用特征工程逻辑)
sample = {
"applicant_id": req.applicant_id,
"age": req.age,
"occupation": req.occupation,
"income_monthly": req.income_monthly,
"loan_amount": req.loan_amount,
"loan_term": req.loan_term,
"purpose": req.purpose,
"overdue_times_1y": req.overdue_times_1y,
"debt_ratio": req.debt_ratio,
"social_security_years": req.social_security_years,
"historical_default_flag": req.historical_default_flag
}
sample_df = pd.DataFrame([sample])
# 3. 特征工程(与训练时一致,简化版)
# 3.1 还款能力特征
sample_df["debt_service_ratio"] = (sample_df["loan_amount"] / (sample_df["loan_term"] * 12)) * 1.1 / sample_df["income_monthly"]
# 3.2 稳定性特征
sample_df["occupation_stability"] = sample_df["occupation"].map(occupation_stability_map).fillna(0)
# 3.3 标准化连续特征
sample_df[["income_norm", "social_security_years_norm"]] = scaler.transform(
sample_df[["income_monthly", "social_security_years"]]
)
# 3.4 类别特征编码(简化,实际需复用训练时的ohe/le)
sample_df["purpose_dummy"] = 1 if sample_df["purpose"].iloc[0] == "创业资金" else 0 # 示例:仅保留一个虚拟变量
# 4. 特征选择与预测
features = ["income_norm", "debt_service_ratio", "occupation_stability", "social_security_years_norm", "purpose_dummy", "overdue_times_1y", "debt_ratio", "historical_default_flag"]
X_sample = sample_df[features].values
default_prob = model.predict_proba(X_sample)[0][1] # 违约概率
# 5. 构造响应(含风险等级与解释)
risk_level = "高风险" if default_prob > 0.6 else "中风险" if default_prob > 0.3 else "低风险"
response = {
"applicant_id": req.applicant_id,
"default_probability": round(default_prob, 4), # 违约概率(0-1)
"risk_level": risk_level,
"key_factors": [ # 基于逻辑回归系数的关键因素(示例)
{"factor": "负债比", "impact": "正向影响", "coefficient": 0.85},
{"factor": "社保缴纳年限", "impact": "负向影响", "coefficient": -0.62}
],
"timestamp": pd.Timestamp.now().isoformat()
}
return jsonify(response), 200
except Exception as e:
logger.error(f"预测失败:{str(e)}", exc_info=True)
return jsonify({"error": str(e)}), 400
if __name__ == "__main__":
app.run(host="0.0.0.0", port=5000, debug=False) # 生产环境用Gunicorn部署容器化部署
dockerfile
FROM python:3.9-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY src/ ./src/
COPY model/ ./model/
EXPOSE 5000
CMD ["gunicorn", "--workers", "4", "--bind", "0.0.0.0:5000", "src.api.app:app"] # 4个工作进程Nginx配置(负载均衡)
nginx
upstream credit_risk_api {
server 10.0.0.1:5000; # 容器1
server 10.0.0.2:5000; # 容器2
}
server {
listen 80;
location /predict_risk {
proxy_pass http://credit_risk_api;
proxy_set_header Host $host;
}
}示例调用API
bash
curl -X POST http://credit-risk-api/predict_risk \
-H "Content-Type: application/json" \
-d '{
"applicant_id": "APP005",
"age": 32,
"occupation": "互联网",
"income_monthly": 18000,
"loan_amount": 250000,
"loan_term": 48,
"purpose": "购房装修",
"overdue_times_1y": 1,
"debt_ratio": 0.55,
"social_security_years": 6,
"historical_default_flag": 0
}'