参考文:Cao B, Xia Y, Ding Y, et al. Predictive Dynamic FusionJ. arXiv preprint arXiv:2406.04802, 2024.2406.04802 Predictive Dynamic Fusion
整体架构
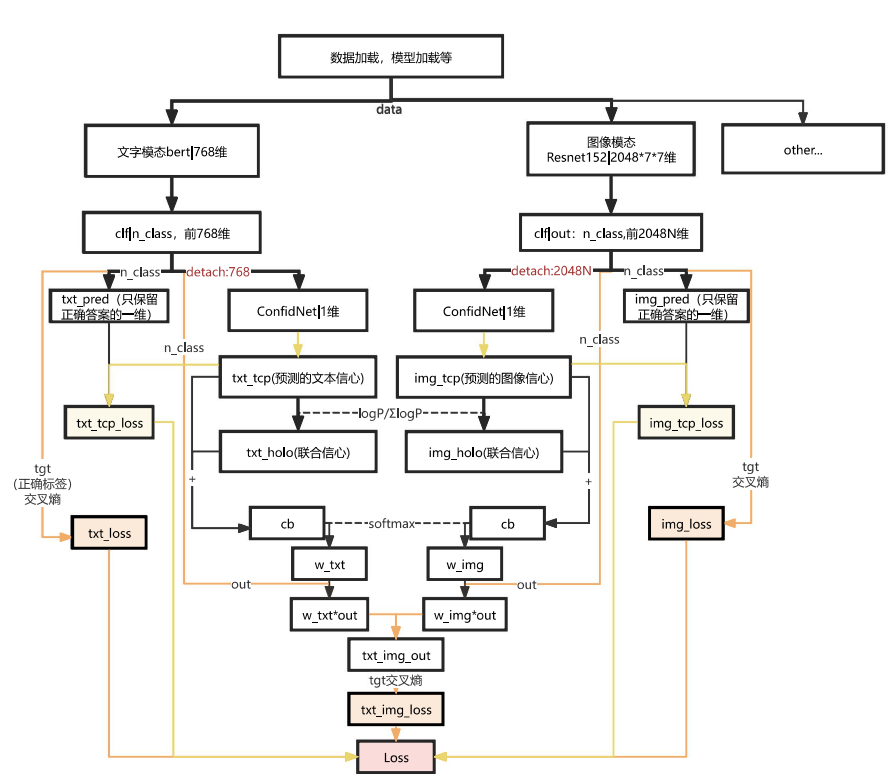
花了点时间照着项目代码的结构画了这个流程图;每种颜色区分了loss反向传播的路线,红色的detach切断了两条loss的交叉。
大概模型结构可以分为:1、文字模型;2、图像模型;3、融合部分。
"单模态分类 + 置信度预测 + 置信度驱动动态融合"的多模态情绪识别框架。
一、数据加载与整体框架初始化
在模型训练开始阶段,首先进行数据加载与模型初始化。训练数据由文本信息、图像信息以及对应的情绪标签组成,形成多模态输入样本。系统通过数据加载模块将文本数据和图像数据分别读取并构建为批次数据,同时完成模型结构、优化器以及相关训练组件的初始化。随后,输入数据被分发到各个模态分支中进行特征提取与后续处理,从而构建完整的多模态情绪识别训练流程。
| 组件 | 存储内容 | 内存占用 | 详细解释存储的内容 |
|---|---|---|---|
| Model(模型) | 参数(Parameters) | 大 | 存储神经网络的所有可学习参数,例如各层的 weight 和 bias 。例如全连接层的 weight ∈ R^(out×in)、卷积核参数、BERT中的注意力权重等。这些参数在训练过程中通过梯度下降不断更新,是模型学习知识的核心。 |
| Activation(激活值) | 前向传播输出 | 很大 | 在前向传播时,每一层都会产生中间输出(activation),例如卷积层输出特征图、Transformer隐藏层表示等。这些中间结果需要被 保存到计算图中,以便在反向传播时计算梯度,因此在训练时会占用大量显存,特别是深层网络或大 batch 时。 |
| Gradient(梯度) | dL/dW | 大 | 反向传播过程中计算得到的 损失函数对每个参数的偏导数 。例如 ∂Loss/∂weight。这些梯度会暂存在每个参数的 .grad 属性中,并被优化器用于更新参数。梯度的大小通常与参数大小相同,因此也占用较大内存。 |
| Optimizer(优化器) | momentum / 状态变量 | 很大 | 优化器需要为每个参数保存额外状态。例如 Adam优化器 会为每个参数维护两个变量:一阶矩估计 m(梯度动量)和二阶矩估计 v(梯度平方的指数平均)。因此优化器状态通常会占用 约2倍参数大小的额外内存。 |
| DataLoader(数据加载器) | batch 数据 | 小 | 在每次迭代时加载当前 batch 的输入数据,例如 图像张量、文本token、标签等。DataLoader本身不长期保存整个数据集,只是按需读取并生成 batch,因此占用内存较小,主要存储当前 batch 的数据和少量缓存。 |
| Scheduler(学习率调度器) | 学习率状态 | 极小 | 保存当前训练轮数(epoch 或 step)、当前学习率值以及一些调度参数。例如在 ReduceLROnPlateau 中还会记录验证集性能变化,用于判断何时降低学习率。这些信息只包含少量标量或配置参数,因此占用内存极小。 |
| Loss(损失) | 标量或小张量 | 极小 | 存储当前 batch 计算得到的 损失值 ,通常是一个标量(例如 tensor(0.83))。此外在计算过程中会生成一个小型计算图节点,用于反向传播梯度。由于数据量非常小,因此内存占用可以忽略。 |
二、文本模态特征提取
文本模态采用预训练语言模型作为特征提取器,通过BERT编码器对输入文本进行语义表示学习。输入文本首先经过分词与编码处理后输入BERT模型,通过其多层Transformer结构提取深层语义特征,最终得到维度为768的文本特征向量。
项目代码具体使用的是BERT-base-uncased 是自然语言处理领域的经典预训练模型,采用 12 层 Transformer 编码器、隐藏层维度 768、12 个自注意力头,总参数量约 1.1 亿(~110M),模型大小约 104MB。
参数构成主要包括以下几部分:
| 组件 | 规格 | 说明 |
|---|---|---|
| 隐藏层维度 | 768 | 每个词的向量表示维度 |
| Transformer层数 | 12 | 深层双向编码器 |
| 注意力头数 | 12 | 并行注意力机制 |
| 词汇表大小 | 30,522 | 覆盖广泛的英文词汇 |
三、图像模态特征提取
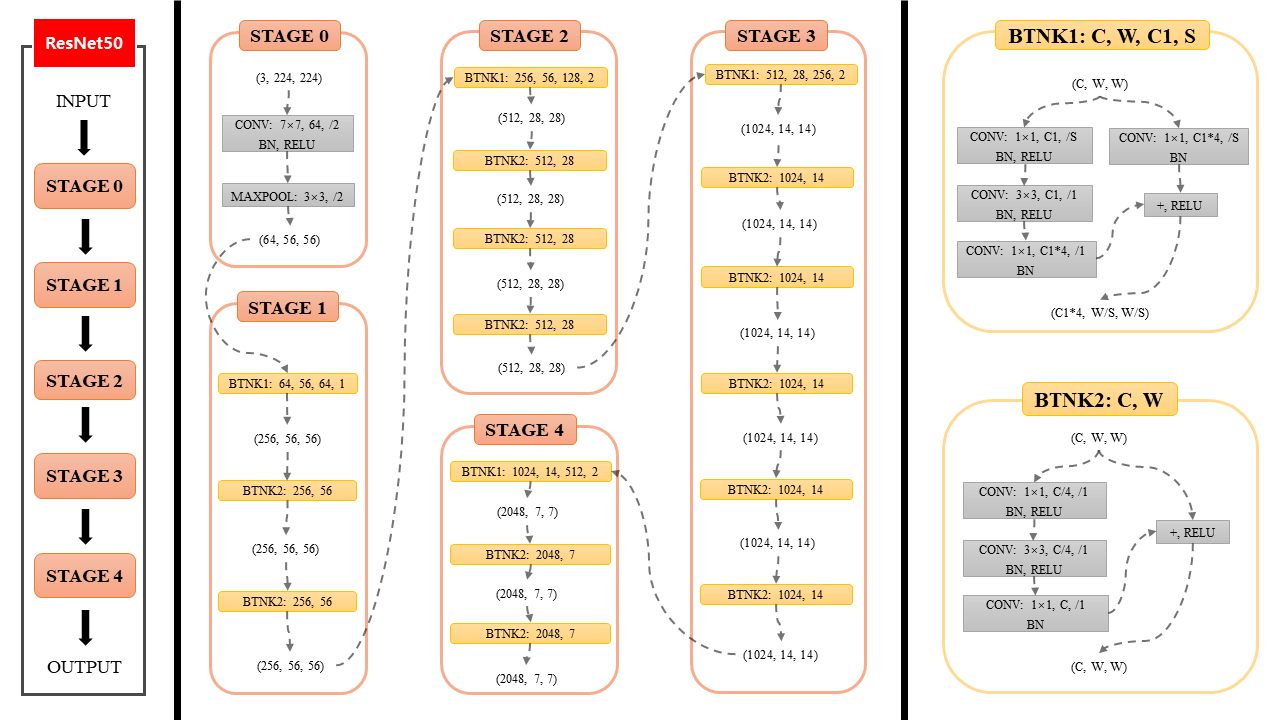
图像模态通过深度卷积神经网络进行视觉特征提取。本模型采用ResNet152作为图像编码器,将输入图像经过多层残差卷积结构进行特征提取,最终输出维度为2048×7×7;2048×7×7 的高层视觉特征图。项目的image_encoder通过全局平均池化等操作可以进一步得到2048维的图像语义表示,该表示能够捕捉图像中的情绪相关视觉线索。只找到了resnet50的图,但是大差不差:
三、融合部分
(1)单模态分类预测CLF
在获得文本与图像特征表示之后,模型为每个模态分别构建独立的分类器CLF,用于进行单模态情绪预测。文本特征向量输入到文本分类层中,通过全连接层映射到情绪类别空间,输出维度为n_class 的预测概率向量。图像模态同样通过全连接分类层将2048维图像特征映射到相同的类别空间,得到图像模态的情绪预测结果。
class BertClf(nn.Module):
def __init__(self, args):
super(BertClf, self).__init__()
self.args = args
self.enc = BertEncoder(args)
self.clf = nn.Linear(args.hidden_sz, args.n_classes)
self.clf.apply(self.enc.bert.init_bert_weights)
def forward(self, txt, mask, segment):
x = self.enc(txt, mask, segment)
return self.clf(x), x(2)置信度预测与计算(ConfidenceNet)
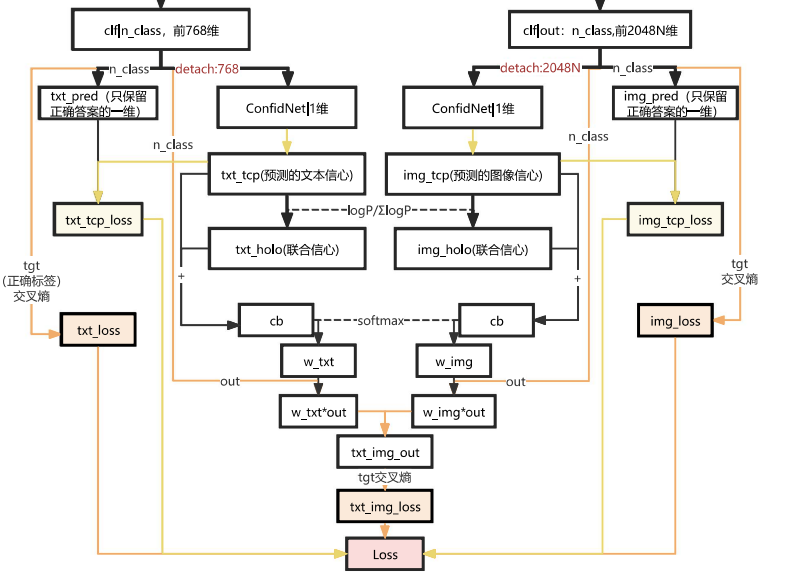
为了评估不同模态预测结果的可靠程度,模型为每个模态引入独立的置信度预测网络(ConfidenceNet)。该网络以对应模态的特征向量作为输入,通过若干全连接层预测该模态当前样本的置信度值,即模型对该模态预测结果可信程度的估计。在实现过程中,输入特征在进入置信度网络前通过detach操作与主网络的梯度传播路径分离(使用了detach函数),从而避免置信度预测过程对原始特征学习产生干扰。
为了训练置信度预测网络,需要构建真实置信度信号。模型通过提取单模态分类预测结果中对应真实标签类别的预测概率,将其作为该模态的真实置信度目标值。置信度网络输出的预测值与真实置信度之间通过均方误差损失进行优化。模型进一步对文本模态和图像模态的置信度进行联合建模,通过对数概率归一化等方式得到统一尺度的联合置信度表示,使不同模态的置信度能够在同一空间内进行比较和融合。
网络以已知正确结果维度的预测值为基准,计算信心程度的损失(在forward函数里实现的),这样可以让模型在预测出结果偏离正确结果时,更没有信心,反之。打个比方就是题目越会写越有自信,不会写的时候就没自信。
在获得各模态置信度之后,模型通过融合权重计算模块生成每个模态在当前样本中的贡献权重。具体而言,将文本模态和图像模态的联合置信度输入到权重计算函数中,并通过Softmax函数进行归一化处理,从而得到文本模态权重𝑤_𝑡𝑥𝑡与图像模态权重𝑤_𝑖𝑚𝑔。该机制能够根据不同样本的情境特征自适应调整各模态的重要程度,使模型在文本信息更可靠时增强文本贡献,而在视觉信息更明显时提升图像权重。
计算流程可以看图;
class MultimodalLateFusionClf_pdf(nn.Module):
def __init__(self, args):
super(MultimodalLateFusionClf_pdf, self).__init__()
self.args = args
self.txtclf = BertClf(args)
self.imgclf= ImageClf(args)
self.ConfidNet_txt = nn.Sequential(
nn.Linear(768, 768*2),
nn.Linear(768*2, 768),
nn.Linear(768, 1),
nn.Sigmoid()
)
self.ConfidNet_img = nn.Sequential(
nn.Linear(6144, 6144*2),
nn.Linear(6144*2, 6144),
nn.Linear(6144, 1),
nn.Sigmoid()
)
def forward(self, txt, mask, segment, img,choice):
txt_out,txt_f = self.txtclf(txt, mask, segment)
img_out,img_f = self.imgclf(img)
if self.args.df:
# pdf train
if choice=='pdf_train':
txt_f_cp = txt_f.clone().detach()
img_f_cp = img_f.clone().detach()
txt_tcp = self.ConfidNet_txt(txt_f_cp)
img_tcp = self.ConfidNet_img(img_f_cp)
txt_holo = torch.log(img_tcp)/(torch.log(txt_tcp*img_tcp)+1e-8)
img_holo = torch.log(txt_tcp)/(torch.log(txt_tcp*img_tcp)+1e-8)
cb_txt = txt_tcp.detach() + txt_holo.detach()
cb_img = img_tcp.detach() + img_holo.detach()
w_all = torch.stack((cb_txt,cb_img),1)
softmax = nn.Softmax(1)
w_all = softmax(w_all)
w_txt = w_all[:,0]
w_img = w_all[:,1]
txt_img_out = w_txt.detach()*txt_out+w_img.detach()*img_out
return txt_img_out, txt_out, img_out, txt_tcp, img_tcp