论文标题: Darwin Gödel Machine: Open-Ended Evolution of Self-Improving Agents
作者: Jenny Zhang ∗ , 1 , 2 ^{*,1,2} ∗,1,2, Shengran Hu ∗ , 1 , 2 , 3 ^{*,1,2,3} ∗,1,2,3, Cong Lu 1 , 2 , 3 ^{1,2,3} 1,2,3, Robert Lange † , 3 ^{†,3} †,3, Jeff Clune † , 1 , 2 , 4 ^{†,1,2,4} †,1,2,4 1 ^{1} 1University of British Columbia, 2 ^{2} 2Vector Institute, 3 ^{3} 3Sakana AI, 4 ^{4} 4Canada CIFAR AI Chair
代码: https://github.com/jennyzzt/dgm
5. 总结
本文提出了一种名为 Darwin Gödel Machine (DGM) 的新型人工智能框架,旨在实现 AI 系统的完全自主进化。DGM 结合了哥德尔机 (Gödel Machine) 的理论愿景------即 AI 能够递归地重写自身代码以提升性能------与达尔文进化论的实证方法。与需要形式化证明每一次修改都有益的理论哥德尔机不同,DGM 通过在沙箱环境中进行实证评估 (empirical validation) 来验证修改的有效性,并通过开放式探索 (open-ended exploration) 维护一个多样化的智能体种群,以避免陷入局部最优。
实验结果表明,DGM 能够在没有人类干预的情况下,显著提升编码智能体的能力。在 SWE-bench Verified 基准测试中,DGM 将基础智能体的解决率从 20.0% 提升至 50.0% ;在 Polyglot 基准测试中,从 14.2% 提升至 30.7%。这一过程不仅发现了更高效的工具使用策略(如更细粒度的文件编辑),还展示了跨模型和跨任务的泛化能力。DGM 代表了向"自我加速" (self-accelerating) AI 系统迈出的重要一步,即 AI 能够利用其现有的智能来创造更强的智能,形成递归式的指数级增长。
1. 思想
当前 AI 系统(尤其是基于 LLM 的 Agent)的发展面临着根本性的结构限制。
-
大问题:
- 现有的 AI 系统大多受限于人类设计的固定架构。它们在预定义的边界内学习(例如通过上下文学习或微调),但无法自主重写其源代码来改变自身的运作逻辑。
- 科学方法的本质是累积的和开放式的,每一个创新都建立在前人的基础上。然而,AI 的每一次架构迭代目前仍严重依赖人类工程师的手工设计,这限制了 AI 进化的速度。
- 经典的 Gödel Machine (Schmidhuber, 2007) 提供了一个理论上的终极方案:一个能够重写自身代码的 AI,只要它能证明重写后的代码比当前代码更好。但在现代深度学习和 LLM 语境下,形式化证明 (formal proof) 几乎是不可能的。
-
小问题:
- 如何在一个不可证明的环境中安全有效地进行自我代码修改?
- 简单的递归自我改进(Recursive Self-Improvement)往往会导致系统陷入局部最优 (local optima),或者在通过狭隘的指标优化时丢失通用能力。
- 如何确保 AI 发现的改进不仅仅是对特定任务的过拟合,而是真正通用的能力提升?
-
核心思想:
- 达尔文式的松弛 (Darwinian Relaxation) : DGM 放宽了哥德尔机对"证明"的要求,转而使用实证证据 (empirical evidence)。即:如果修改后的代码在基准测试集上表现更好,则认为该修改是有益的。
- 基于种群的开放式探索 (Population-based Open-Ended Exploration) : 借鉴进化算法,DGM 不仅仅维护单一的"最佳"智能体,而是维护一个包含所有历史生成的有效智能体的档案 (Archive)。
- 代码作为基因 (Code as Genome): DGM 将智能体的完整实现(Python 代码)视为其基因组。智能体通过读取自身源码、分析运行日志、利用 LLM 提出修改建议并实施修改,从而实现自我进化。
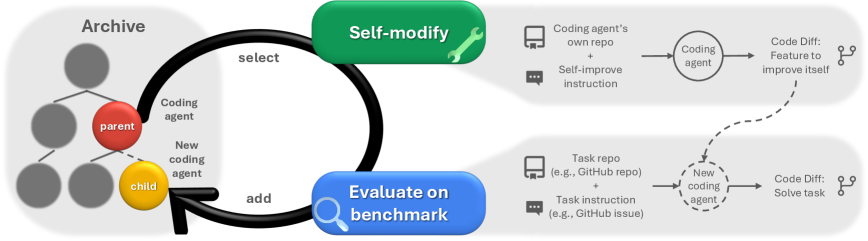
Figure 1: Darwin Gödel Machine 概览。DGM 迭代地构建一个不断增长的智能体档案。通过开放式探索选择档案中的父代智能体进行自我修改,并在下游任务上评估新生成的子代。
2. 方法
DGM 的运作过程是一个持续的循环,包含父代选择、自我修改、评估和档案更新。其核心是一个基于 Python 的编码智能体(Coding Agent),该智能体由冻结权重的 LLM(如 Claude 3.5 Sonnet)驱动,并配备了基本的工具(如 Bash 和文件编辑器)。
2.1 种群与父代选择
DGM 维护一个智能体档案 A t = { a 1 t , a 2 t , ... , a N t } \mathcal{A}^t = \{a_1^t, a_2^t, \dots, a_N^t\} At={a1t,a2t,...,aNt}。为了实现开放式进化,避免过早收敛,系统必须平衡利用 (exploitation) 和 探索 (exploration)。
在每次迭代 t t t,系统从符合条件的候选集 E t \mathcal{E}^t Et 中采样 k k k 个父代智能体。选择概率 p i p_i pi 基于两个因素:智能体的性能得分 α i \alpha_i αi 和其已有的有效子代数量 n i n_i ni(novelty/diversity 的代理指标)。
计算过程如下:
-
性能缩放 : 使用 Sigmoid 函数对性能 α i \alpha_i αi 进行非线性映射,倾向于选择高性能个体:
s i = 1 1 + exp ( − λ ( α i − α 0 ) ) s_i = \frac{1}{1 + \exp(-\lambda (\alpha_i - \alpha_0))} si=1+exp(−λ(αi−α0))1其中 λ \lambda λ 控制锐度, α 0 \alpha_0 α0 是中点。
-
新颖性奖励 (Novelty Bonus) : 惩罚那些已经被过度探索(拥有大量子代)的节点,鼓励探索进化树上的新分支:
h i = 1 1 + n i h_i = \frac{1}{1 + n_i} hi=1+ni1这里 n i n_i ni 是智能体 a i a_i ai 拥有的具备基本功能的子代数量。
-
最终选择概率 :
w i = s i ⋅ h i p i = w i ∑ j ∈ E t w j w_i = s_i \cdot h_i \\ p_i = \frac{w_i}{\sum_{j \in \mathcal{E}^t} w_j} wi=si⋅hipi=∑j∈Etwjwi
关键逻辑 : 这种选择机制确保了系统既关注当前的 SOTA(高 s i s_i si),也不放弃那些虽暂居次席但尚未被充分挖掘潜力的路径(高 h i h_i hi)。这构成了开放式探索的基础。
2.2 自我修改
这是 DGM 最核心的"变异"操作。与传统的遗传算法随机变异不同,DGM 利用 LLM 的推理能力进行定向变异。
过程分解:
- 内省 (Introspection) : 被选中的父代智能体 a i a_i ai 获取其自身的源代码仓库和在基准任务上的详细评估日志。
- 诊断与提案: 使用一个强大的 LLM(如 o1 或 Claude 3.5)分析日志,识别当前实现的弱点(例如:编辑大文件时上下文超限、工具使用错误等),并提出具体的改进功能的 Pull Request 描述。
- 代码重写 : 智能体将该提案视为一个标准的"编码任务",调用自身的工具(即它当前拥有的编辑代码的能力)来修改自己的源码
coding_agent.py或tools/目录。 - 生成子代 : 修改后的代码构成了一个新的智能体 a c h i l d a_{child} achild。
本质: 这是一个元层面的操作。智能体不仅解决外部的编程题,也将"改进自身代码"视为一个编程题。
2.3 实证评估
由于缺乏形式化验证,DGM 依赖严格的测试:
- 编译与基本功能检查: 新智能体必须能通过基本的代码编辑测试(Verified Basic Functionality)。如果连文件都改不了,直接丢弃。
- 基准测试 : 在 SWE-bench Verified 或 Polyglot 的子集上运行新智能体。
- 为了节省计算资源,采用分级评估策略:先在小样本(如 10 个任务)上测试,通过阈值后再在更大样本(如 50-200 个任务)上评估。
- 档案更新 : 只要智能体有效(可运行),它就会被加入档案 A \mathcal{A} A,成为未来进化的潜在跳板。
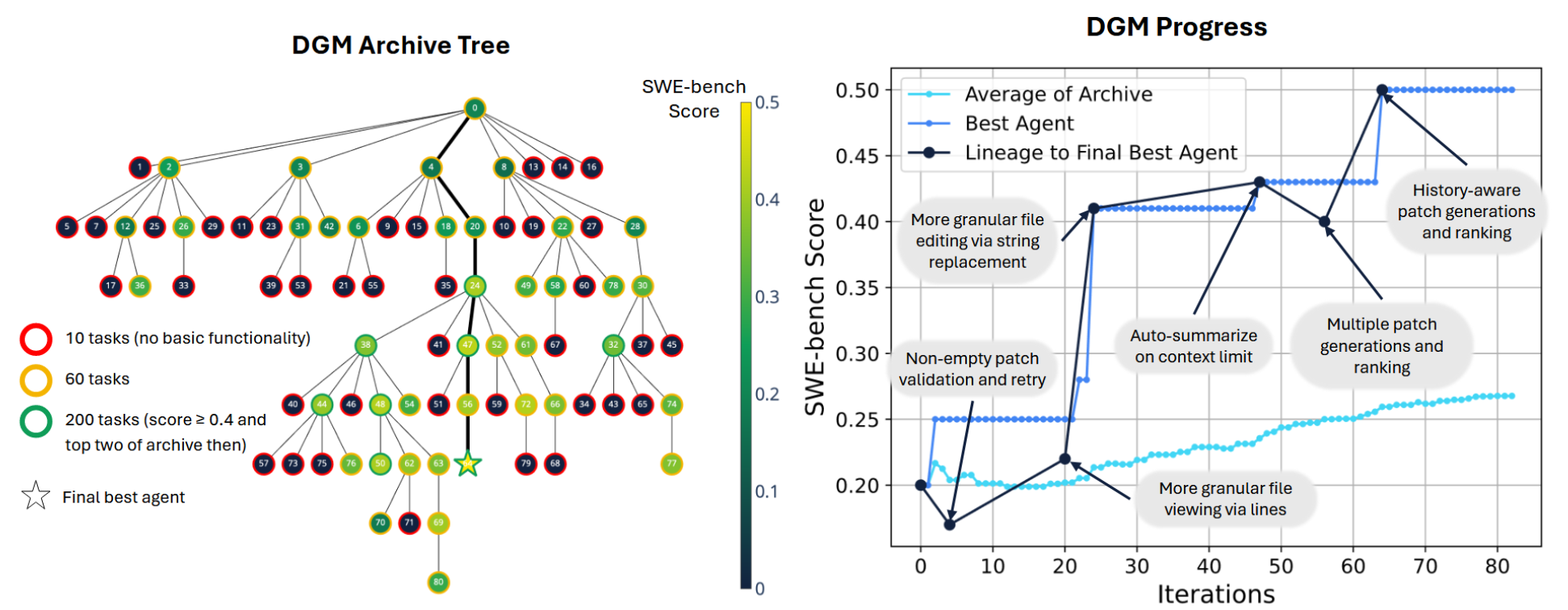
Figure 3: DGM 进化过程的可视化。(左) SWE-bench 上的进化树。颜色代表性能,边框代表评估任务数。可以看到许多创新并非来自当前的最佳节点,而是来自之前的分支。(右) 性能随迭代次数的变化曲线。深蓝色线显示了最终最佳智能体的谱系,注意其中的性能下降点(dips),这表明非单调的改进路径是通往全局最优的必经之路。
3. 优势
DGM 相比于现有的自动化 Agent 设计框架具有显著优势:
- 超越 Prompt Engineering : 许多现有工作(如 OPRO, PromptBreeder)仅优化 Prompt。DGM 直接修改源代码,能够引入新的控制流、新的工具函数、甚至改变与 LLM 的交互模式。
- 克服爬山算法的短视 : 对比基线 (Robeyns et al., 2025) 这种单一智能体递归改进的方法,DGM 的种群档案机制允许它在探索过程中接受暂时的性能下降,从而跨越适应度地形的低谷,找到更优的解决方案(如图 3 所示的 lineage dips)。
- 完全自主性: 整个过程不需要人类干预,不需要手动设计元智能体的 Prompt,实现了端到端的自我进化。
4. 实验
实验主要在两个编码基准上进行:SWE-bench Verified (Python 真实仓库问题) 和 Polyglot (多语言编程题)。
4.1 实验设置
- 基础智能体: 只有简单的 Bash 和全文件 Edit/View 工具。
- LLM: 主要是 Claude 3.5 Sonnet (New)。
- 迭代: 80 次迭代,每次生成 1 个新智能体(并行运行)。
- 评估指标: Pass@1 解决率。
4.2 主要结果
-
性能飞跃:
- SWE-bench Verified : 从初始的 20.0% 提升至 50.0%。
- Polyglot : 从初始的 14.2% 提升至 30.7%。
- 这一结果证明了 DGM 在不改变底层 LLM 权重的情况下,仅通过代码架构进化就能挖掘出巨大的性能潜力。
-
消融研究 (Ablation Study):
- DGM w/o Open-Ended (No Archive): 仅保留最新智能体进行迭代(类似简单的爬山算法)。性能在初期提升后迅速停滞,最终仅达到 23.0% (SWE-bench)。这证明了维护进化历史和多样性的关键作用。
- DGM w/o Self-Improve (Fixed Agent) : 使用固定的元智能体生成新的变体,而不更新元智能体本身。性能达到 39.0%,虽有提升但显著低于完整 DGM,说明递归自我改进(即修改后的智能体能力更强,能更好地修改下一代)是有效的。
-
进化的特征 (Evolved Features) :
DGM 自动"发明"了许多人类工程师常用的高级技巧,且实现方式往往出人意料:
- 细粒度编辑 : 从全文件覆盖进化为基于行号的编辑 (
edit_lines) 或字符串替换 (str_replace),大幅减少了 LLM 的输出负担和错误率。 - 上下文管理: 自动实现了对长输出的截断和摘要机制,防止上下文溢出。
- 多轮尝试与验证: 进化出了在提交前自行运行测试、根据错误信息重试的复杂工作流。
- 解决幻觉 (Hallucination Fixing): 智能体发现 LLM 有时会产生虚假的工具调用文本,于是它修改了结果解析代码,增强了对特定 Token 格式的鲁棒性,甚至移除了可能诱导幻觉的 Log 信息。
- 细粒度编辑 : 从全文件覆盖进化为基于行号的编辑 (
-
泛化能力 (Transferability):
- 跨模型 : 在 Claude 3.5 上进化出的代码架构,直接换用 Claude 3.7 或 o3-mini,性能依然显著优于基线。例如换用 Claude 3.7 后,性能达到 59.5%。
- 跨任务 : 在 SWE-bench (Python) 上进化的智能体,直接用于 Polyglot (多语言),性能从 14.2% 提升至 28.9%。这表明 DGM 学习到的是通用的编程与问题解决能力,而非特定数据集的过拟合 trick。
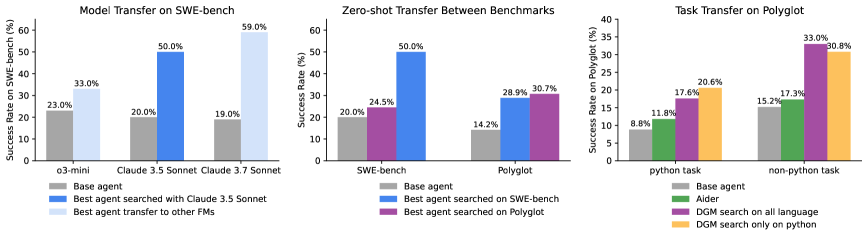
Figure 4: 迁移能力展示。(左) 模型迁移:DGM 发现的架构在不同 LLM 上均有效。(中) 基准迁移:在 SWE-bench 上进化的智能体在 Polyglot 上表现出色,反之亦然。(右) 语言迁移:仅在 Python 任务上训练,在 C++ 等其他语言任务上依然有效。
4.3 局限性与展望
虽然 DGM 取得了显著成果,但作者也坦诚了当前的局限:
- 计算成本: 单次运行需要大量 Token 和时间(SWE-bench 实验约需 2 周和 2.2 万美元 API 成本)。
- 局部最优风险: 尽管有开放式探索,仍可能陷入复杂的局部最优。
- 安全性: 自我修改代码带来了安全隐患。尽管目前使用了沙箱,但在更强大的模型下,需要引入类似于 Constitutional AI 的约束机制进入进化循环。
总而言之,DGM 展示了一条通过代码自进化实现 AI 能力指数级增长的可行路径,验证了在现代 LLM 时代,通过达尔文式的试错与迭代,可以逼近哥德尔机的理想。