一句话总结
这篇报告提出 ERNIE 5.0 :从零开始统一训练文本、图像、视频、音频的自回归基础模型,核心创新是 统一 Next-Group-of-Tokens 目标 + 模态无关的超稀疏 MoE 路由 + 弹性训练,并配套可扩展的 RL 与训练基础设施,最终在多模态理解与生成上取得均衡且强劲的表现。
1. 背景与问题
现有多模态模型通常以"文本为中心",多模态生成往往靠外挂式解码器或后期融合。这会导致:
- 理解与生成割裂 :理解强,生成弱或反之。
- 模态能力跷跷板 :加强某一模态会牺牲另一模态。
- 扩展不优雅 :需要为每个模态设计专用组件和目标。
作者的核心目标是: 让多模态理解与生成都在一个统一自回归范式里完成 ,并且可在不同算力条件下灵活部署。
2. 整体架构:统一自回归 + 超稀疏 MoE
ERNIE 5.0 在模型层面做了三件关键事:
- 统一序列化 :文本、图像、视频、音频都映射到共享 token 序列。
- 统一目标 :所有模态都用 Next-Group-of-Tokens Prediction 训练。
- 统一路由 :MoE 路由不依赖模态标签,完全由 token 表示决定。
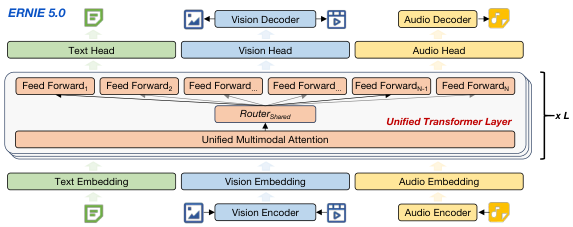
图解:整体架构示意。文本、视觉、音频 token 统一进入同一自回归骨干;MoE 专家池共享,路由不区分模态。
3. 统一自回归目标:Next-Group-of-Tokens
传统文本是 Next-Token Prediction,而图像/视频/音频是"分组 token 预测":
- 文本:标准 NTP,辅以 Multi-Token Prediction (MTP)。
- 视觉:Next-Frame-and-Scale Prediction (NFSP)。
- 音频:Next-Codec Prediction (NCP)。
这样所有模态都被纳入统一的 autoregressive 训练目标,从根上避免"不同模态训练目标不一致"的问题。
4. 模态无关 MoE:共享专家、自动分化
路由层不看模态,只看 token 的表达。结果是:
- 专家出现 自发的模态专化 。
- 不同模态在深层出现更强的语义重叠。
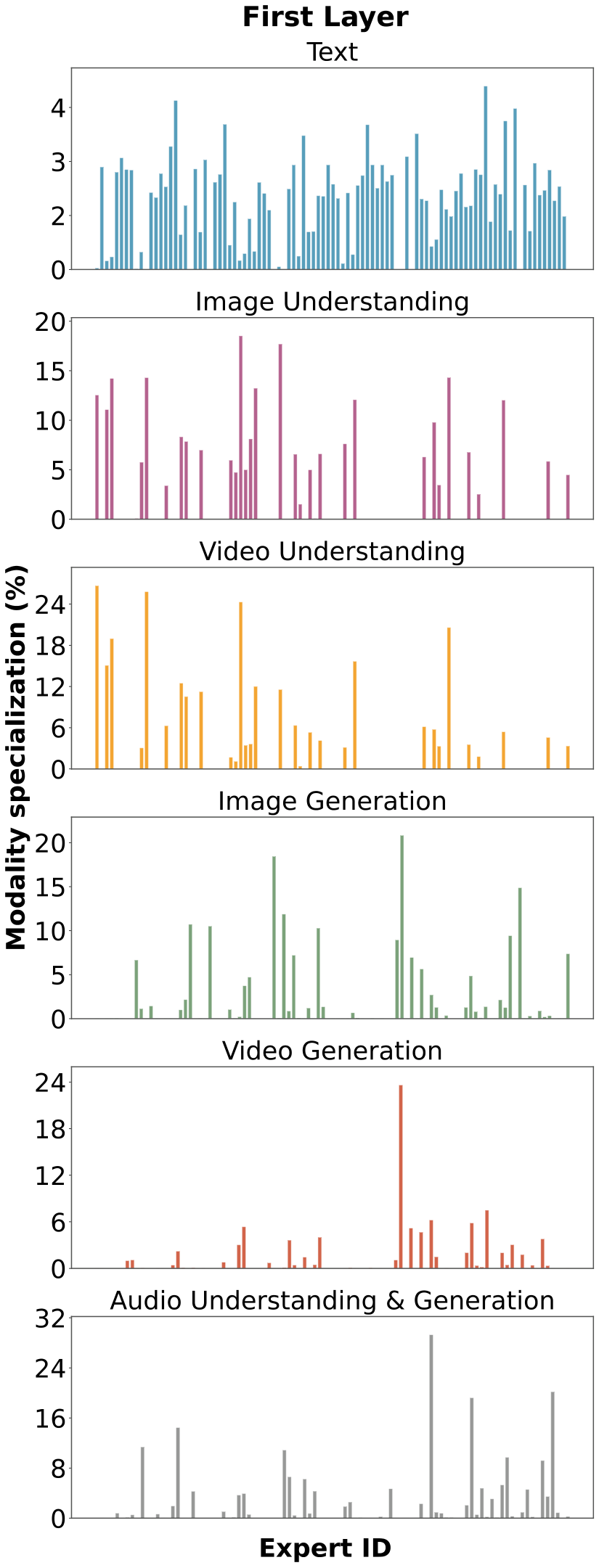
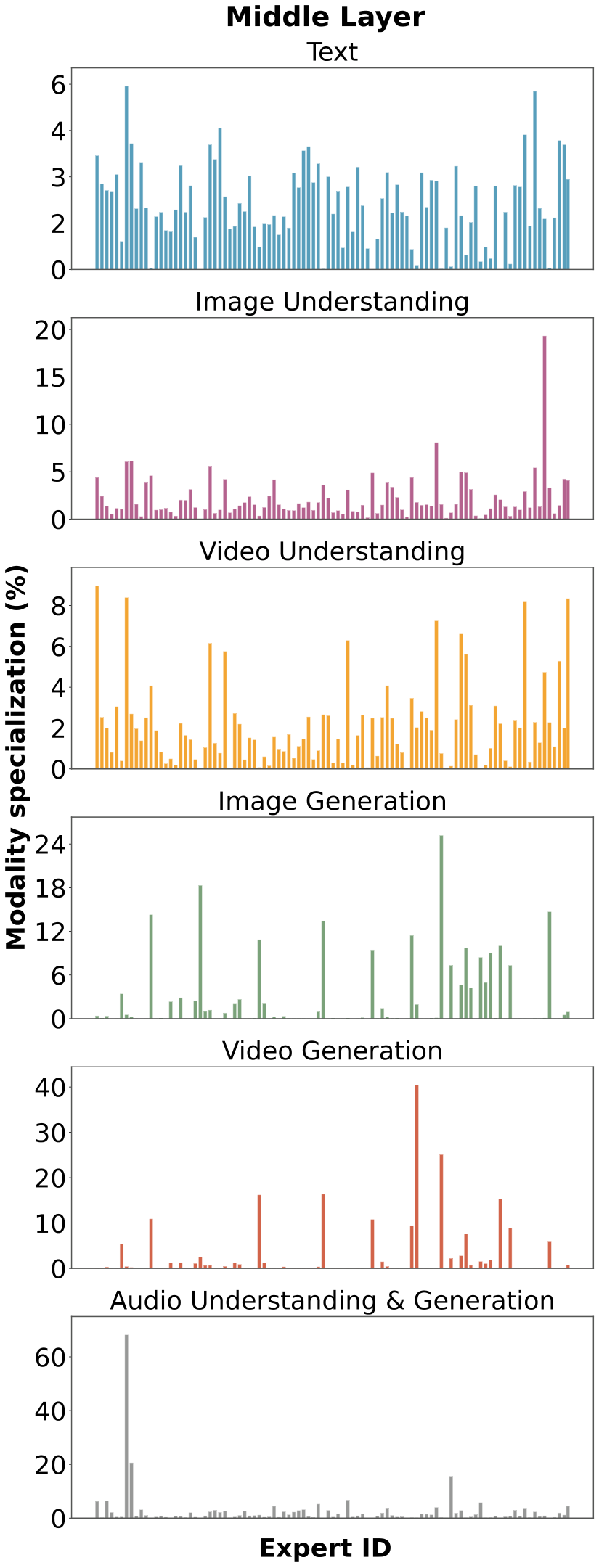
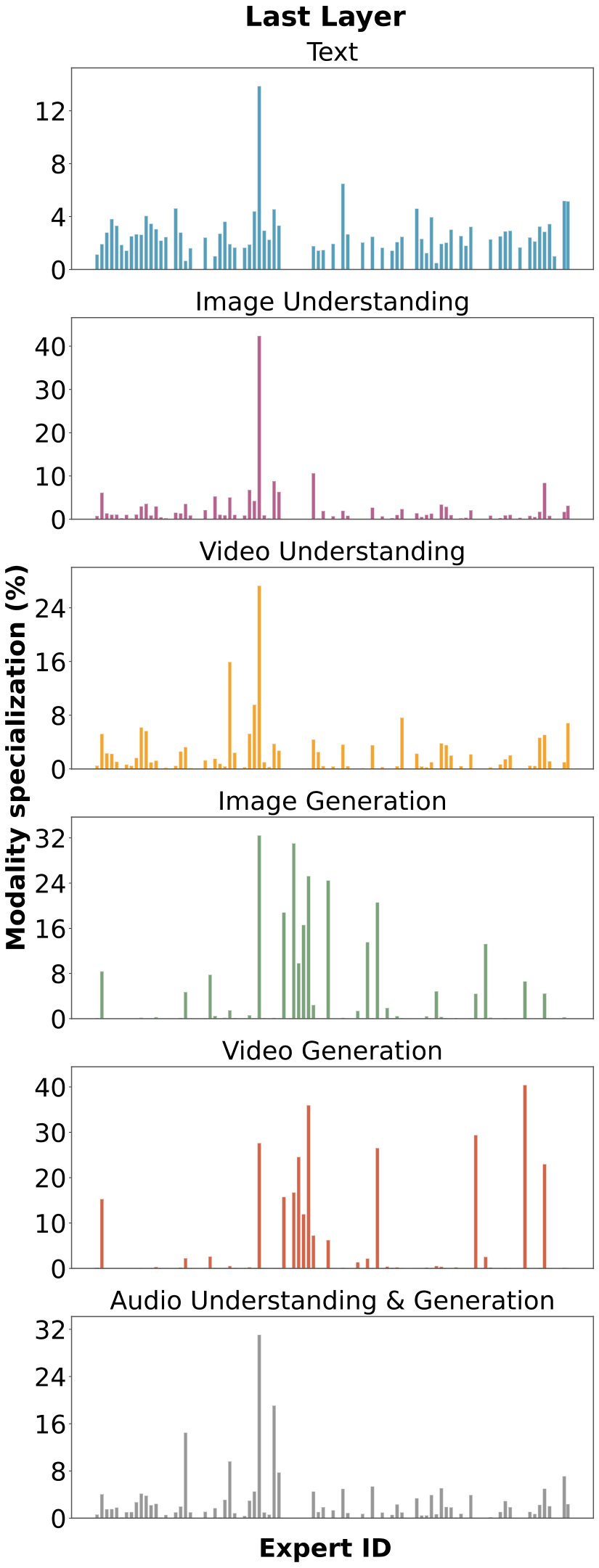
图解:不同层专家激活分布。可以看到非均匀激活,专家在模态上自然分化。
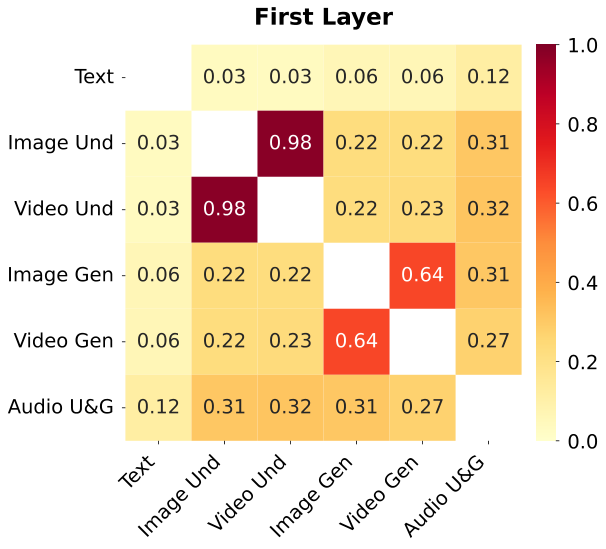
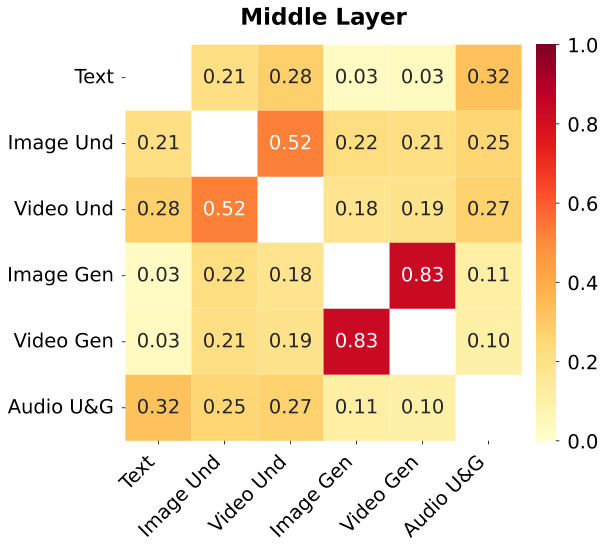
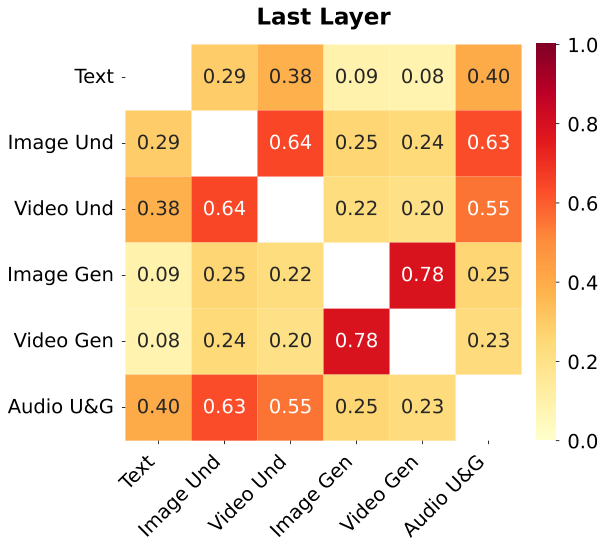
图解:不同模态 top-25% 激活专家的 IoU 重叠。深层跨模态重叠增强,表明语义逐步统一。
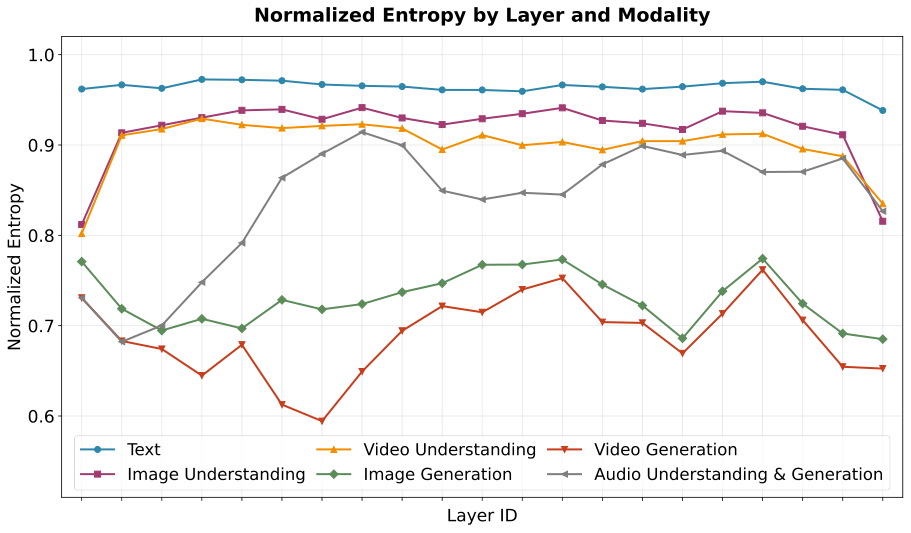
图解:各层专家负载均衡度(NE)。
N E = − ∑ i = 1 N p i log ( p i ) log N NE=\frac{-\sum_{i=1}^{N} p_i \log(p_i)}{\log N} NE=logN−∑i=1Npilog(pi)
NE 越高说明越均匀。
5. 弹性训练:一次预训练得到多种规模
传统"训练后压缩"代价高。作者提出 Elastic Training ,一次训练得到多尺寸子模型。
弹性维度:
- Depth :随机跳层。
- Width :随机减少专家数量。
- Sparsity :随机降低路由 top- k k k。
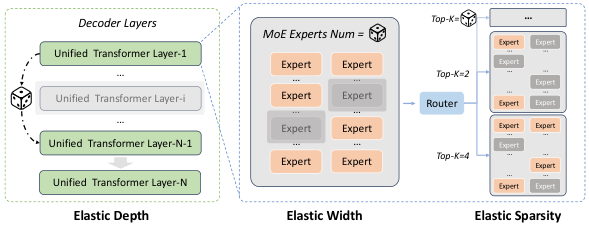
图解:弹性训练框架,三条轴同时采样,形成 Once-For-All 超网络。
关键结论:
- 仅激活 53.7% 参数、总参数 35.8% 时,性能仍接近满模。
- top- k k k 降到 25% 时,解码速度提升超过 15%。
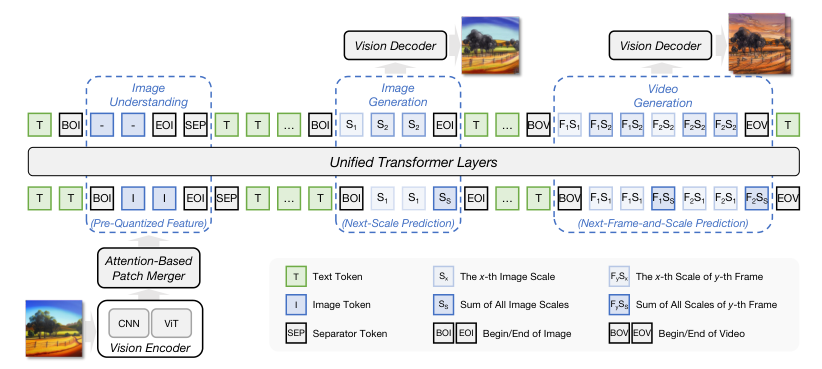
图解:视觉理解与生成统一架构,理解走双路径表征,生成走 NFSP。
6. 视觉与音频:理解 + 生成统一建模
6.1 视觉
- 理解 :CNN + ViT 双路径融合,再做 Attention Patch Merger。
- 生成 :NFSP,图像是单帧视频,多尺度递进生成。
6.2 音频
- 理解 :残差向量量化 (RVQ),多层代码 embedding 相加。
- 生成 :NCP,逐层预测 codec token。
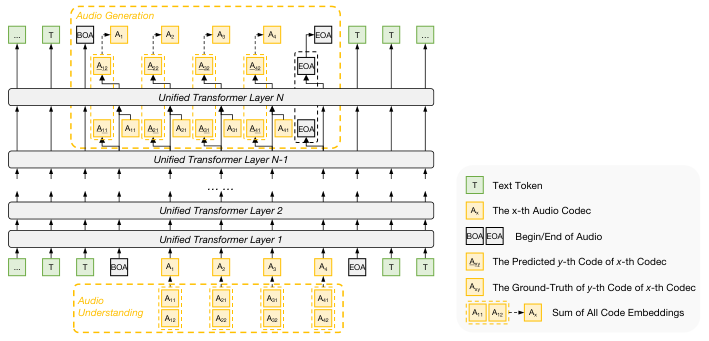
图解:音频理解与生成架构。理解走多层残差嵌入加和,生成走 NCP 分层预测。
7. 预训练与基础设施
为支撑万亿级超稀疏 MoE,需要系统级优化:
- 混合并行 :TP + PP + EP + ZeRO + Context Parallel。
- FP8 混精度 :显著降低显存峰值。
- FlashMask :对异构注意力掩码加速。
结果:训练在稳定性与吞吐上兼顾,支持多模态统一训练。
8. Post-Training:SFT + 统一多模态 RL
RL 训练对 MoE + 多模态极其不稳定,作者提出:
- Unbiased Replay Buffer (U-RB) :避免长尾 rollout 阻塞。
- MISC :多粒度重要性裁剪,避免熵崩塌。
- WPSM :对"已学会样本"做掩码,强化难题学习。
- AHRL :难题注入 hint,让 RL 从"提示"过渡到自探索。
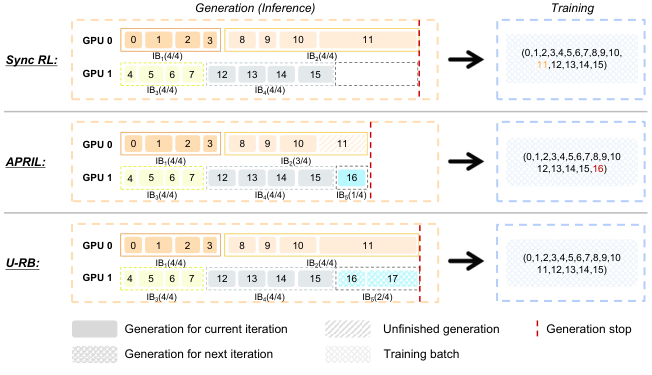
图解:U-RB 机制,保持数据顺序并避免长尾拖慢训练。
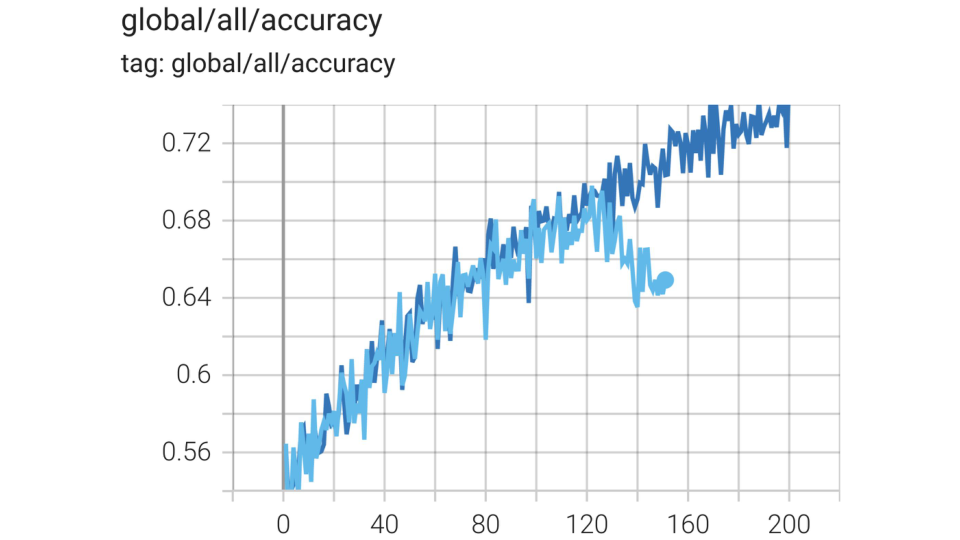
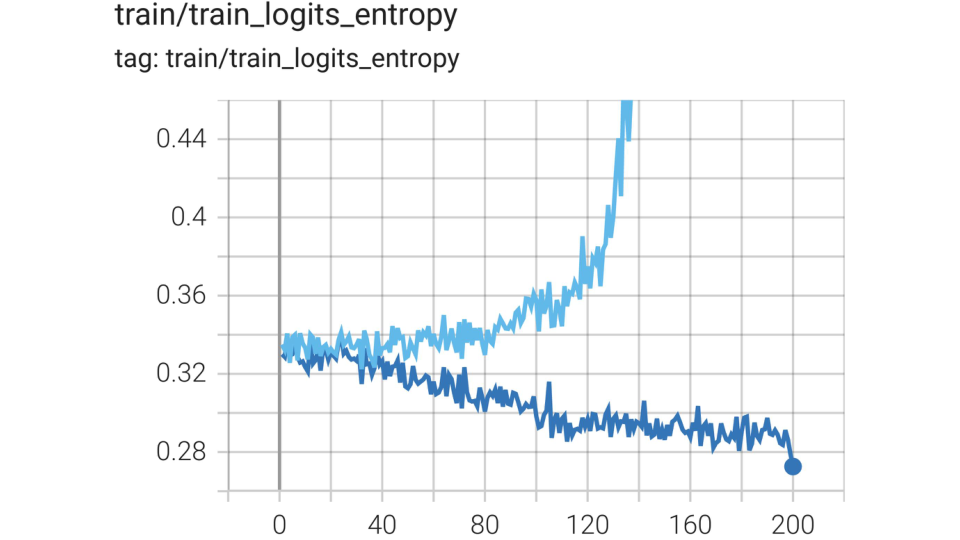
图解:MISC 稳定 RL 训练,避免早期熵崩塌。

图解:AHRL 引入"思考骨架"逐步降低提示比率,提升难题学习效率。
9. 实验结果要点(跨模态全面)
- 文本 :在知识、推理、代码、指令跟随等任务上与顶尖模型接近或领先。
- 视觉 :在 VQA、文档理解、推理、视频理解等多类任务保持强竞争力。
- 音频 :ASR、语音对话、音频理解、TTS 均表现稳定。
核心结论: 统一训练没有牺牲单模态能力,反而在多模态融合和一致性上更强。
10. 结论与启示
ERNIE 5.0 给出一个非常清晰的技术路径:
- 统一自回归范式 是多模态理解与生成真正融合的关键。
- 模态无关 MoE 路由 可以让专家自发形成分工,减少人工设计负担。
- 弹性训练 是"训练一次、多场景部署"的可行路径。
- RL 在超大多模态 MoE 上仍是难点,但系统化工程 + 算法改造可行。