您好,我是@iFeng的小屋,一枚4年程序猿。
一、爬取目标
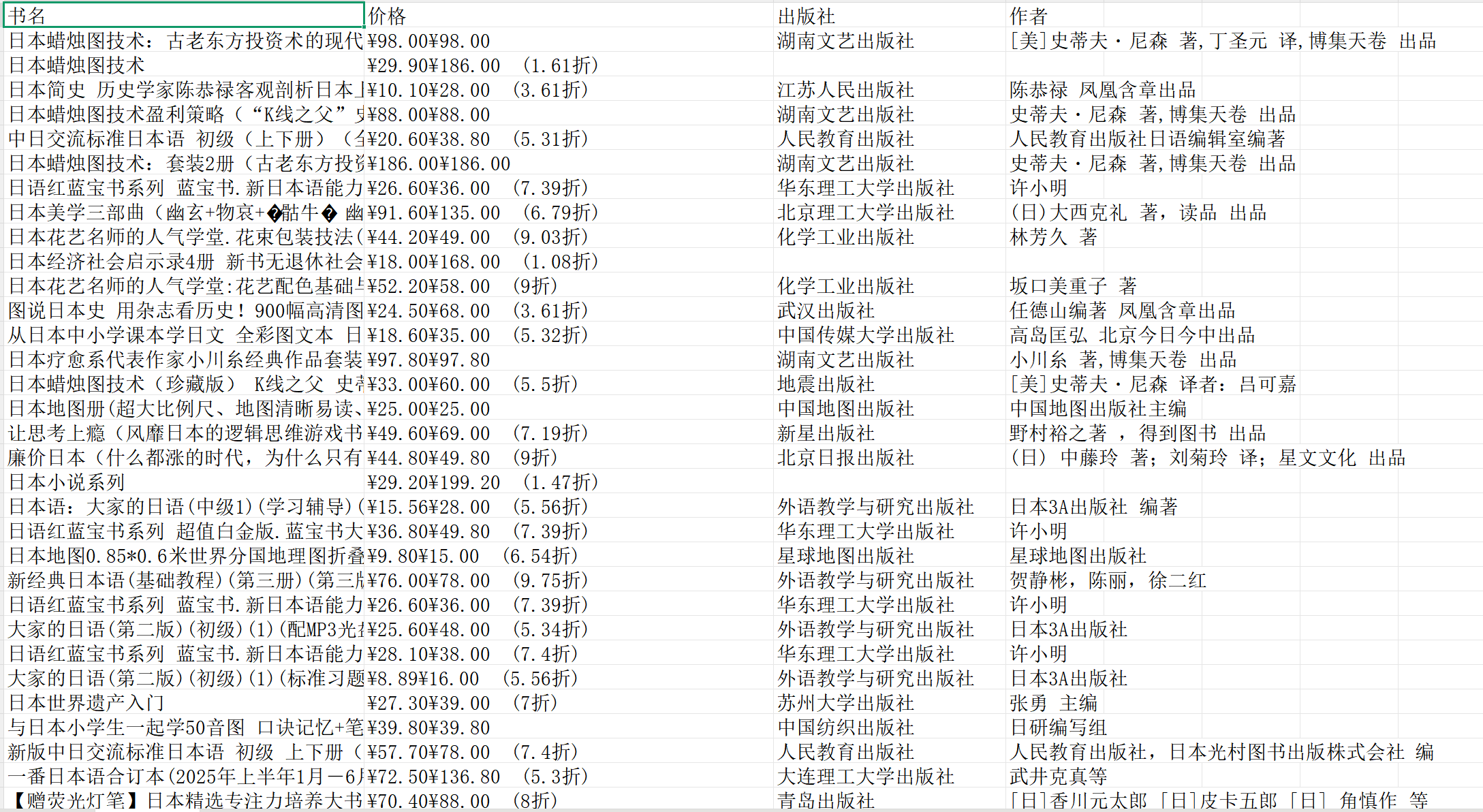
我发现很多对日本文化、历史或文学感兴趣的朋友,或者做出版市场分析的小伙伴,想批量了解市面上相关图书的情况。手动去网站一页页翻,效率太低了。
所以,这次我写了这个当当网图书数据爬虫 。它不仅能根据关键词(比如"日本")批量抓取图书信息,还能自动对价格进行分段统计,用图表直观地展示出来,让你一眼看清市场分布。
目前是源码格式,还没有封装成软件,如果想要软件的我后续开发一个软件版本的。
二、展示爬取结果
三、原理讲解
-
分析当当网搜索页(如"日本"关键词)的链接规律,主要是
page_index参数控制翻页。 -
用
requests库请求页面,用lxml和XPath精准定位并提取每一本书的详细信息。 -
用
pandas把抓到的数据存成表格(CSV格式)。 -
用
正则表达式从价格字符串里把纯数字价格提取出来。 -
根据设定的价格区间(比如10-20万日元、20-30万日元)进行统计,最后用
matplotlib画成一张漂亮的横向条形图。
三、爬虫代码讲解
导入库:
python
import requests
from lxml import etree
import pandas as pd
import re
import matplotlib.pyplot as plt3.1 核心思路与配置
运行需要配置请求头,模拟浏览器访问。其中,Cookie是关键,可以从浏览器开发者工具里获取。
python运行
3.2 关键步骤:抓取列表与翻页
核心是构造翻页URL,并循环抓取,直到满足数量要求。
python
page = 1
while len(book_list) < 1000: # 目标:爬1000条
url = f'http://search.dangdang.com/?key=%C8%D5%B1%BE&act=input&page_index={page}'
response = requests.get(url, headers=headers)
# ... 解析并存储数据
page += 1 # 关键:页码加1,实现翻页3.3 关键步骤:数据清洗与可视化
从原始字符串中提取纯数字价格,并定义区间进行统计绘图。
python
# 1. 用正则表达式从'¥XX.XX¥'这种格式里提取价格数字
price_num = re.findall(r'¥(.*?)¥', price_string)
# 2. 定义价格区间并统计(此处逻辑需在完整源码中完善)
price_ranges = ['10-20万', '20-30万', '30+万']
# 3. 使用matplotlib绘制横向条形图
plt.barh(price_ranges, range_counts) # 绘制图表
plt.title('图书价格区间分布分析')
plt.show()四、如何运行?
-
准备好环境 :安装依赖
pip install requests lxml pandas matplotlib。 -
更新请求头 :将代码中的
headers字典里的Cookie值,替换成你自己浏览器里的最新Cookie。 -
修改关键词(可选) :如果想爬其他主题,把URL里的
%C8%D5%B1%BE(这里是"日本"的编码)换成其他关键词的编码即可。 -
直接运行脚本 :程序会先爬取数据保存为
output_1.csv,然后自动弹出分析图表窗口。
五、说明
需要本文提到的完整可运行Python源码(包含数据清洗和可视化的完整逻辑)的小伙伴,我都放在了与此号同名的公主号里,大家自行获取。
持续分享Python干货中!更多爬虫源码干货,请前往主页查看。