张世洲¹,吕学强¹,邢英慧¹*,吴启瑞¹,徐迪²,赵晨¹,张艳宁¹
¹西北工业大学,中国
²华为,中国
https://arxiv.org/pdf/2512.22973
摘要
当前的增量目标检测(Incremental Object Detection, IOD)方法主要依赖于Faster R-CNN或DETR系列检测器;然而,这些方法无法适配实时YOLO检测框架。本文首先识别出导致基于YOLO的增量检测器发生灾难性遗忘的三类主要知识冲突:前景-背景混淆、参数干扰以及知识蒸馏错位。随后,我们提出了YOLO-IOD,一种构建于预训练YOLO-World模型之上的实时增量目标检测框架,通过分阶段参数高效微调实现增量学习。具体而言,YOLO-IOD包含三个核心组件:1)冲突感知伪标签精炼(Conflict-Aware Pseudo-Label Refinement, CPR),通过利用伪标签的置信度水平并识别与未来任务相关的潜在目标来缓解前景-背景混淆;2)基于重要性的卷积核选择(Importance-based Kernel Selection, IKS),在当前学习阶段识别并更新与当前任务相关的关键卷积核;3)跨阶段非对称知识蒸馏(Cross-Stage Asymmetric Knowledge Distillation, CAKD),通过将学生目标检测器的特征分别送入前一阶段和当前阶段教师检测器的检测头,实现现有类别与新引入类别之间的非对称蒸馏,从而解决知识蒸馏错位冲突。我们进一步提出了LoCo COCO,一个消除阶段间数据泄露的更贴近实际的基准测试集。在传统COCO和LoCo COCO基准上的实验表明,YOLO-IOD在最小化遗忘的同时实现了卓越性能。
引言
增量目标检测(IOD)的目标是在连续学习新任务的过程中持续获取新目标类别,同时保留过去已学习类别的知识。尽管近期工作(Mo等,2024;Liu等,2023)在IOD领域取得了显著进展,但大多数现有方法均构建于Faster R-CNN(Ren等,2015)或DETR(Carion等,2020)等检测器之上。当这些方法应用于实时YOLO系列检测器(Redmon等,2016)时,它们通常会遭遇泛化性能的显著下降,并难以保持先前类别的知识,这主要源于任务间的知识冲突。
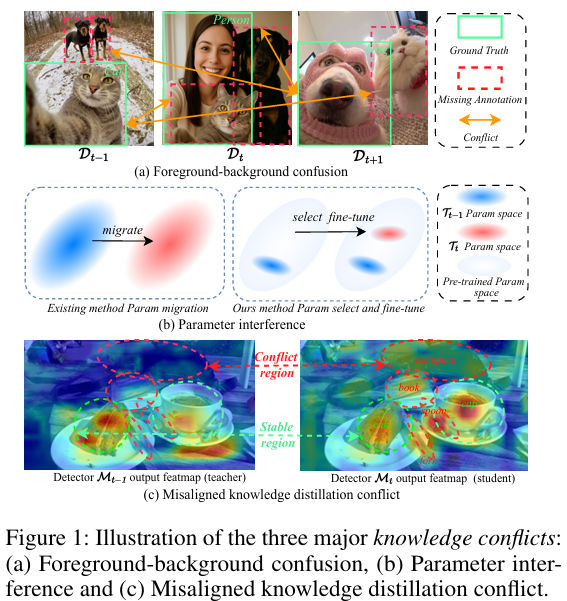
在本工作中,我们首先将基于YOLO的增量检测器中遗忘现象的根本原因识别为三类主要知识冲突(如图1所示):1)前景-背景混淆:在训练过程中,属于先前任务和未来任务的未标注目标被错误分类为背景。该问题对YOLO检测器尤为关键,因其依赖Mosaic和MixUp等激进的数据增强技术,而这些技术假设标注准确。在IOD设置下,伪标签产生的噪声会被这些增强技术放大,从而损害模型性能。2)参数干扰:不同任务通常依赖模型中相交的参数子集。针对新任务的更新会改变这些共享参数,从而可能破坏先前习得的表征,导致早期任务知识的灾难性遗忘。3)知识蒸馏错位冲突:教师模型与学生模型针对不匹配的类别分布进行优化,违反了标准知识蒸馏中两个模型共享一致学习目标的核心假设。以空间网格进行密集预测著称的YOLO系列检测器受此问题影响尤为显著。
为克服上述挑战,我们提出了YOLO-IOD,一种构建于预训练YOLO-World(Cheng等,2024)模型之上的实时IOD框架,并在每个增量学习阶段执行参数高效微调。YOLO-IOD包含三个旨在解决上述知识冲突的主要模块:1)冲突感知伪标签精炼(CPR),通过两种策略缓解前景-背景混淆:增强伪标签损失(通过基于置信度和不确定性的加权提升伪标签监督的可靠性)和聚类未知伪标签(通过执行开放词汇目标检测和特征空间聚类识别未来任务的潜在目标);2)基于重要性的卷积核选择(IKS),基于Fisher信息的差异重要性估计,仅选择并微调与当前任务相关的重要卷积核,从而缓解参数干扰;3)跨阶段非对称知识蒸馏(CAKD),通过将跨阶段学生特征送入旧教师检测器和当前教师检测器的检测头,实现跨新旧类别的非对称蒸馏,从而解决知识蒸馏错位冲突。
此外,当前的IOD基准测试集并未针对实际应用进行定制,它们任意划分类别而忽视类别的自然共现性,并允许图像在增量阶段间重复出现。在实际场景中,某些类别(如汽车和行人)经常共同出现,而其他类别(如汽车和船只)则不会。阶段间图像重叠必须被严格禁止以避免数据泄露。这引发了对当前基准上观测到的性能是否能有效迁移到实际应用的质疑,特别是对于依赖伪标签的近期IOD方法。因此,我们提出了LoCo COCO,一个新颖的基准测试集,旨在消除阶段间图像重叠并遵循类别共现统计规律,为IOD提供更公平、更贴近实际的评估基准。
我们的贡献可总结如下:
• 我们提出了YOLO-IOD,一个集成化的实时IOD框架,并指出了三类遗忘原因:前景-背景混淆、参数干扰和知识蒸馏错位冲突。
• YOLO-IOD包含三个创新模块以减轻遗忘,特别强调双教师CAKD模块。该模块通过将目标学生检测器的特征送入前一阶段和当前阶段教师检测器的检测头,解决了知识蒸馏错位挑战。
• 我们提出了LoCo COCO,一个实用的基准测试集,通过移除阶段间图像重叠并考虑类别共现性,实现对增量目标检测更公平的评估。
• 在传统COCO和LoCo COCO基准上多种设置下的大量实验表明,我们的方法在保持实时推理速度的同时始终达到最先进性能。
相关工作
增量学习
增量学习使模型能够在不遗忘先前知识的情况下获取新信息(Schlimmer和Granger Jr,1986;Li和Hoiem,2017)。方法包括:基于回放的方法,通过重放或生成先前任务的样本(Rebuffi等,2017;Lopez-Paz和Ranzato,2017;Shin等,2017);基于正则化的方法,通过约束重要参数以保持稳定性(Kirkpatrick等,2017;Luo等,2025;Yang等,2023;Wu等,2025);基于架构的方法,为任务分配特定子网络(Von Oswald等,2019;Rypeść等,2024);以及知识蒸馏,通过教师-学生学习从过去任务转移信息(Tao等,2020;Chen和Chang,2023;Asadi等,2023)。近期,基于基础模型的持续学习也引起了广泛关注,包括L2P(Wang等,2022)、CODA-Prompt(Smith等,2023)和VPT-NSP2^{2}2(Lu等,2024)等方法。
增量目标检测
与分类相比,IOD涉及更复杂的场景和更大挑战,因其需要同时定位和分类目标。在IOD中,蒸馏特别有效,这得益于检测框架中丰富的特征表示和多层次监督信号。ERD(Feng、Wang和Yuan,2022)引入了弹性响应蒸馏以自适应地转移知识。BPF(Mo等,2024)通过双教师模型桥接过去-未来知识,CL-DETR(Liu等,2023)在DETR架构内应用蒸馏,强调来自旧模型的可靠预测。然而,这些方法通过仅选择与新标签不重叠的旧任务输出作为蒸馏目标来处理知识蒸馏问题。该策略不适用于YOLO风格的密集预测。此外,该方法只能从教师模型中蒸馏部分知识,无法完全解决底层冲突。我们提出的CAKD通过使用检测头抑制无关特征的响应,提供跨阶段非对称知识蒸馏。
预备知识与基准测试
问题定义
在IOD中,任务按顺序到达:T={T1,T2,...,Tt,...,Tn}\mathcal{T} = \{\mathcal{T}_1, \mathcal{T}_2, \ldots, \mathcal{T}_t, \ldots, \mathcal{T}_n\}T={T1,T2,...,Tt,...,Tn}。每个任务Tt\mathcal{T}_tTt旨在学习特定的目标类别集合Ct\mathcal{C}_tCt,且Ci∩Cj=∅\mathcal{C}_i \cap \mathcal{C}_j = \emptysetCi∩Cj=∅,∀i≠j\forall i \neq j∀i=j。对于每个任务Tt\mathcal{T}_tTt,提供一个数据集:Dt={(Xti,Yti)}i=1Nt\mathcal{D}_t = \{(\mathcal{X}_t^i, \mathcal{Y}t^i)\}{i=1}^{N_t}Dt={(Xti,Yti)}i=1Nt,其中Xti\mathcal{X}_t^iXti表示第iii张图像,Yti\mathcal{Y}_t^iYti是其对应标注。重要的是,数据集Dt\mathcal{D}tDt仅对类别Ct\mathcal{C}tCt中的目标进行标注。即,属于C1:t−1∪Ct+1:n\mathcal{C}{1:t-1} \cup \mathcal{C}{t+1:n}C1:t−1∪Ct+1:n的目标即使出现在图像中也不会被标注。在任务Tt\mathcal{T}_tTt的训练过程中,仅可访问Dt\mathcal{D}_tDt。IOD的目标是在每个阶段训练一个目标检测器MtM_tMt,使其能够正确检测当前任务类别Ct\mathcal{C}tCt和所有已见类别C1:t−1\mathcal{C}{1:t-1}C1:t−1中的目标。
YOLO-World
开放词汇目标检测(Open-Vocabulary Object Detection, OVOD)使检测器能够通过文本输入引导识别任意类别。近期方法如GLIP(Li等,2022)、Grounding DINO(Liu等,2024)和YOLO-World(Cheng等,2024)在大规模视觉-语言数据上学习区域-文本对齐。我们的方法基于预训练的YOLO-World模型。图像由视觉编码器fvf_vfv处理,类别文本由文本编码器ftf_tft处理,特征通过RepVL-PAN融合:V,P=fRepVL(fv(I),ft(T))\mathbf{V}, \mathbf{P} = f_{\text{RepVL}}(f_v(I), f_t(T))V,P=fRepVL(fv(I),ft(T)),其中V={ek}k=1K\mathbf{V} = \{\mathbf{e}k\}{k=1}^KV={ek}k=1K是区域级视觉嵌入,P={pj}j=1C\mathbf{P} = \{\mathbf{p}j\}{j=1}^CP={pj}j=1C是文本原型。分类得分计算为:sk,j=η⋅(Norm(ek),Norm(pj))+ζs_{k,j} = \eta \cdot (\text{Norm}(\mathbf{e}_k), \text{Norm}(\mathbf{p}_j)) + \zetask,j=η⋅(Norm(ek),Norm(pj))+ζ。
LoCo COCO基准测试集
在先前的IOD基准测试中,每个阶段ttt通常从完整数据集中选择包含类别Ct\mathcal{C}_tCt目标的所有图像。现实世界图像经常包含来自各类别的目标,意味着单张图像将在多个训练阶段中被使用。根据统计,在20+20的4阶段设置中,每张图像平均出现在1.84个阶段中。这种重叠挑战了持续学习的基础前提,并通过允许检测器在重复使用的训练图像上生成伪标签人为地夸大了基于伪标签方法的有效性。
为解决此问题,我们引入了一种新的数据划分协议,命名为低共现COCO(Low Co-occurrence COCO, LoCo COCO)。我们首先构建一个类别共现矩阵A∈RN×N\mathbf{A} \in \mathbb{R}^{N \times N}A∈RN×N,其中Aij\mathbf{A}{ij}Aij表示类别cic_ici和cjc_jcj共同出现的图像数量。该矩阵定义了一个无向加权图G=(V,E)\mathcal{G} = (\mathcal{V}, \mathcal{E})G=(V,E),节点代表类别,边权重由Aij\mathbf{A}{ij}Aij给出。随后,我们在G\mathcal{G}G上执行图聚类,将类别集合C={c1,c2,...,cn}\mathcal{C} = \{c_1, c_2, \ldots, c_n\}C={c1,c2,...,cn}划分为nnn个不相交的子集用于nnn个阶段。这确保了频繁共现的类别被分配到同一任务中,最小化任务间图像重叠。在上述类别划分后,仍存在一部分重叠图像包含来自多个阶段的类别。对于每张跨越多个候选类别集的重叠图像III,我们将其随机分配给其中一个候选任务。该策略确保每张图像仅出现在一个阶段中,消除了阶段间任何数据泄露。我们提出的LoCo COCO基准测试集更符合现实世界的IOD场景,并消除了基于伪标签的IOD方法中的评估偏差。
方法
整体框架
所提出的YOLO-IOD以预训练的YOLO-World作为基础模型。如图2所示,YOLO-IOD通过分阶段部分微调执行增量学习,其中参数更新由基于重要性的卷积核选择引导。整体架构包含三个组件。在图2左上部分,冲突感知伪标签精炼(CPR)通过增强伪标签损失生成高质量的旧任务监督以缓解先前任务的前景-背景混淆,同时通过聚类未知伪标签处理未来任务潜在的前景-背景混淆。在图2左下部分,基于重要性的卷积核选择(IKS)确定在每个增量阶段需更新的卷积核,保留先前任务的关键知识同时允许对新类别进行部分微调。最后,跨阶段非对称知识蒸馏(CAKD)实现两种不同的知识蒸馏损失。第一种涉及将旧检测器Mt−1M_{t-1}Mt−1与目标检测器MtM_{t}Mt进行比较,方法是将它们各自的密集特征送入旧检测器Mt−1M_{t-1}Mt−1的检测头。第二种涉及将当前检测器MstM_{st}Mst(在当前阶段数据集Dt\mathcal{D}{t}Dt上训练的检测器,该数据集仅对类别Ct\mathcal{C}{t}Ct进行标注)与目标检测器MtM_{t}Mt进行比较,方法是利用当前检测器检测头内的密集特征。
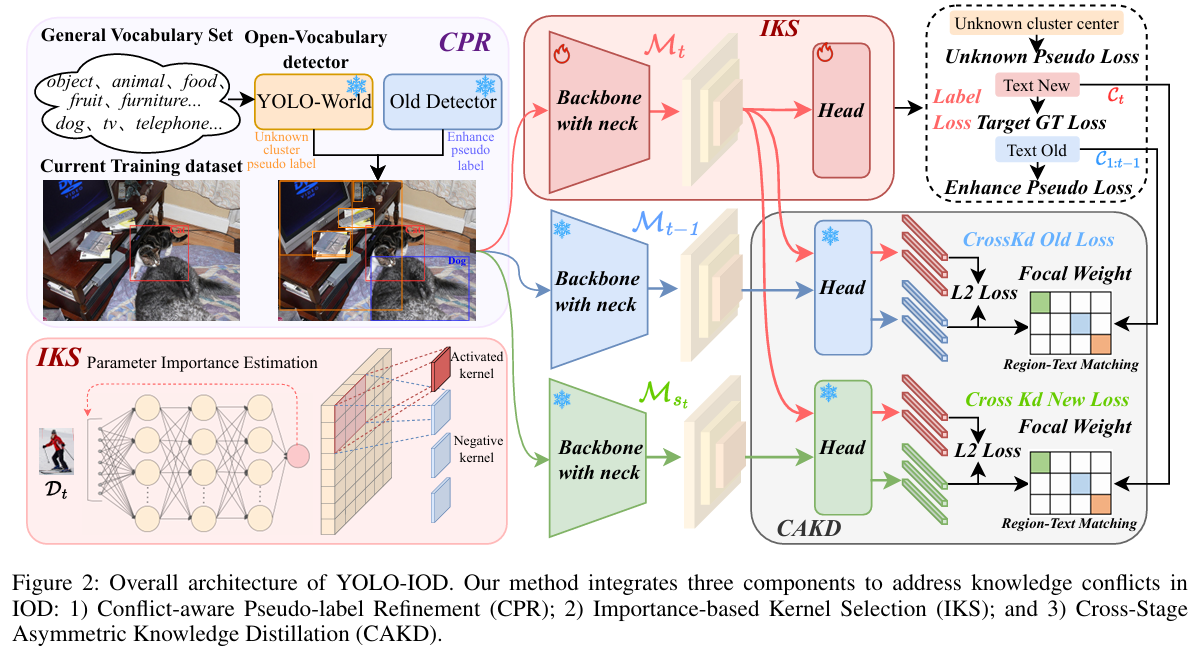
增强伪标签损失。IOD中的传统伪标签方法依赖置信度阈值选择可靠的伪标签,这引入了基于置信度的选择偏差。该偏差导致低置信度类别在训练过程中逐渐被忽略。此外,高于阈值的伪标签被统一处理而不考虑其实际可靠性,导致监督信号不一致。
为解决此问题,我们提出了增强伪标签损失,将每个伪标签的置信度得分sss视为软监督目标,结合置信度感知加权与熵正则化:
Lpseudocls=−∣s−pt∣γlog(pt)+λ⋅(1−s)δ⋅H(y^), \mathcal{L}_{pseudo}^{cls} = -|s - p_t|^{\gamma} \log(p_t) + \lambda \cdot (1 - s)^{\delta} \cdot H(\hat{y}), Lpseudocls=−∣s−pt∣γlog(pt)+λ⋅(1−s)δ⋅H(y^),
其中ptp_tpt表示伪标签类别预测的概率,H(y^)H(\hat{y})H(y^)表示预测类别分布的熵。第一项通过类focal方案实现置信度对齐监督,第二项应用与置信度得分成反比的自适应熵正则化。该设计充分利用了广泛置信度范围内的伪标签。低置信度伪标签提供软监督,并通过式(1)中的第二项进一步正则化以保留预测中的不确定性,而高置信度标签根据其可靠性提供更稳定的监督。
聚类未知伪标签。对于未来任务类别的缺失标注,我们提出了聚类未知伪标签方法。我们构建一个通用词汇集VgenV_{gen}Vgen,包含由大语言模型总结的500个常见目标类别和50个抽象超类别。在每个增量阶段,我们使用VgenV_{gen}Vgen应用YOLO-World识别所有前景目标(排除具有真实标注的目标)。令F\mathcal{F}F表示这些由YOLO-World预测的未标注前景目标集合,CF⊆Vgen\mathcal{C}{\mathcal{F}} \subseteq V{gen}CF⊆Vgen表示F\mathcal{F}F中目标的类别标签集合。为将这些预测转换为稳定的未知监督同时最小化与未来任务的冲突,我们在CF\mathcal{C}_{\mathcal{F}}CF的文本特征表示ft(⋅)f_t(\cdot)ft(⋅)上执行频率加权K-Means聚类,其中每个类别的权重对应其在F\mathcal{F}F中的出现频率。所得聚类中心定义了一组未知超类别U={u1,u2,...,uK}\mathcal{U} = \{u_1, u_2, \ldots, u_K\}U={u1,u2,...,uK}。随后,我们将F\mathcal{F}F中每个标签替换为其分配的超类别U\mathcal{U}U,并在训练过程中将其文本嵌入替换为对应的聚类中心。该方法将由未标注未来任务类别引起的知识冲突转化为从未知超类别中发现和学习新类别的过程。
基于重要性的卷积核选择
我们利用基于重要性的参数选择机制以缓解YOLO-IOD中的参数冲突。具体而言,我们在每个增量任务中仅选择并微调重要卷积核,最小化对整体参数分布的干扰。为避免破坏先前任务的关键知识,我们通过从当前任务特定重要性中减去历史重要性来计算差异重要性。
参数重要性估计。我们采用Fisher信息量化参数重要性,但在卷积核粒度上定义以保留归纳结构并避免随任务增加而产生的存储成本。给定一个包含dkd_kdk个标量参数的卷积核wk={wjk}j=1dk\mathbf{w}^k = \{w_j^k\}_{j=1}^{d_k}wk={wjk}j=1dk,其基于Fisher的重要性可计算为:
It(wk)=∑j=1dk(1Nt∑n=1Nt(∂logp(yn∣xn;θ)∂wjk)2), \mathbf{I}{t}(\mathbf{w}^{k}) = \sum{j=1}^{d_{k}} \left( \frac{1}{N_{t}} \sum_{n=1}^{N_{t}} \left( \frac{\partial \log p(y_{n} \mid x_{n}; \theta)}{\partial w_{j}^{k}} \right)^{2} \right), It(wk)=j=1∑dk Nt1n=1∑Nt(∂wjk∂logp(yn∣xn;θ))2 ,
其中(xn,yn)(x_{n}, y_{n})(xn,yn)是来自任务Tt\mathcal{T}_{t}Tt的训练样本,θ\thetaθ表示模型参数。为避免与先前学习任务的干扰,我们计算差异重要性,其中ρ\rhoρ表示加权因子:
ΔIt(wk)=It(wk)−ρ∑i=1t−1Ii(wk). \Delta \mathbf{I}{t}(\mathbf{w}^{k}) = \mathbf{I}{t}(\mathbf{w}^{k}) - \rho \sum_{i=1}^{t-1} \mathbf{I}_{i}(\mathbf{w}^{k}). ΔIt(wk)=It(wk)−ρi=1∑t−1Ii(wk).
随后,我们选择按ΔIt(wk)\Delta \mathbf{I}_t(\mathbf{w}^k)ΔIt(wk)排名前KKK的卷积核在任务Tt\mathcal{T}_tTt中进行微调,其余卷积核保持冻结。
跨阶段非对称知识蒸馏
如图2所示,我们的CAKD模块采用双教师框架,其中目标检测器MtM_tMt作为学生。第一位教师是旧检测器Mt−1M_{t-1}Mt−1,专用于先前学习的类别C1:t−1\mathcal{C}{1:t-1}C1:t−1,主要关注C1:t−1\mathcal{C}{1:t-1}C1:t−1的前景特征,其检测头抑制无关特征的响应。第二位教师是当前检测器MstM_{st}Mst,其特征聚焦于当前阶段类别同时抑制其他类别特征。这种跨阶段非对称知识蒸馏设计使目标检测器MtM_{t}Mt能够避免任务间的错位监督和特征干扰,同时最大限度地蒸馏并整合新旧类别的知识。
蒸馏过程通过将学生neck特征FstudentneckF_{student}^{neck}Fstudentneck送入教师检测头来操作,生成跨阶段后检测头特征。检测头包含分类和回归组件:回归头为每个anchor输出边界框位置,而分类头产生图像编码,经区域-文本匹配与文本嵌入结合以产生分类logits。
我们在特征图上全局应用蒸馏损失。为抑制噪声或背景区域并聚焦于最具信息量和可靠性的预测,我们为每个空间位置ppp引入focal权重wfocal(p)=maxjlogtteacher(p,j)w_{\text{focal}}(p) = \max_j \log t_{\text{teacher}}(p, j)wfocal(p)=maxjlogtteacher(p,j),基于教师的最大置信度强调前景可能性高的区域。
分类蒸馏损失测量教师和学生在每个位置的区域级特征嵌入之间的L2L_{2}L2距离,并由focal因子加权:
Lcls_kd=∑p∥Eteacher(p)−Estudent_cross(p)∥22⋅wfocal(p), \mathcal{L}{cls\kd} = \sum{p} \|\mathbf{E}{\text{teacher}}(p) - \mathbf{E}{\text{student\cross}}(p)\|{2}^{2} \cdot w{\text{focal}}(p), Lcls_kd=p∑∥Eteacher(p)−Estudent_cross(p)∥22⋅wfocal(p),
其中Eteacher(p)\mathbf{E}{\text{teacher}}(p)Eteacher(p)和Estudent_cross(p)\mathbf{E}{\text{student\cross}}(p)Estudent_cross(p)分别表示教师和学生模型在位置ppp的区域级特征嵌入。类似地,回归蒸馏损失在特征图所有位置上操作,背景抑制效果通过wfocal(p)w{\text{focal}}(p)wfocal(p)实现:
Lreg_kd=∑pLIoU(Btea(p),Bstu_cross(p))⋅wfocal(p), \mathcal{L}{reg\kd} = \sum{p} \mathcal{L}{\text{IoU}}(\mathrm{B}{\text{tea}}(p), \mathrm{B}{\text{stu\cross}}(p)) \cdot w{\text{focal}}(p), Lreg_kd=p∑LIoU(Btea(p),Bstu_cross(p))⋅wfocal(p),
其中Bstu_cross(p)\mathrm{B}_{\text{stu\cross}}(p)Bstu_cross(p)和Btea(p)\mathrm{B}{\text{tea}}(p)Btea(p)分别是学生和教师模型在位置ppp的边界框。整体蒸馏目标是这两部分的加权和:
LCAKD=αLcls_kd+βLreg_kd. \mathcal{L}{\text{CAKD}} = \alpha \mathcal{L}{cls\kd} + \beta \mathcal{L}{reg\_kd}. LCAKD=αLcls_kd+βLreg_kd.
实验
实验设置
数据集与评估指标。为评估我们的方法,我们使用MS COCO 2017(Lin等,2014)数据集及先前研究(Mo等,2024;Kim等,2024)建立的协议。我们还在提出的LoCo COCO基准测试集上进行评估以提供更贴近实际的评估。我们使用标准COCO指标:IoU阈值0.5-0.95下的mAP、mAP@0.5和mAP@0.75。我们还报告与联合训练相比的AbsGap(绝对mAP差距)和RelGap(相对mAP差距)以量化灾难性遗忘。
实现细节。我们的方法在YOLO-World (X)上实现。我们在4块RTX 3090 GPU上使用批量大小16,学习率设置为2×10−52 \times 10^{-5}2×10−5(骨干网络)和2×10−42 \times 10^{-4}2×10−4(neck和head)。训练使用AdamW(Loshchilov和Hutter,2017)优化器进行20个epoch,Mosaic增强在第10个epoch后禁用。在IKS模块中,所选卷积核比例KKK在基础阶段设为20%,在增量阶段设为12%。
与最先进方法的比较
我们在COCO数据集的单阶段和多阶段IOD设置下评估我们的方法。我们将YOLO-IOD与近期最先进方法进行比较,包括两阶段检测器(BPF、RGR)、基于DETR的方法(CL-DETR、SDDR(Kim等,2024)、DCA(Zhang等,2025))以及构建于开放词汇模型之上的方法(TLR(Zhang等,2024)、GCD(Wang、Wang和Lin,2025))。此外,我们在YOLO-World架构上复现了经典的基于响应的蒸馏方法ERD和近期的生成回放方法RGR以进行进一步比较。
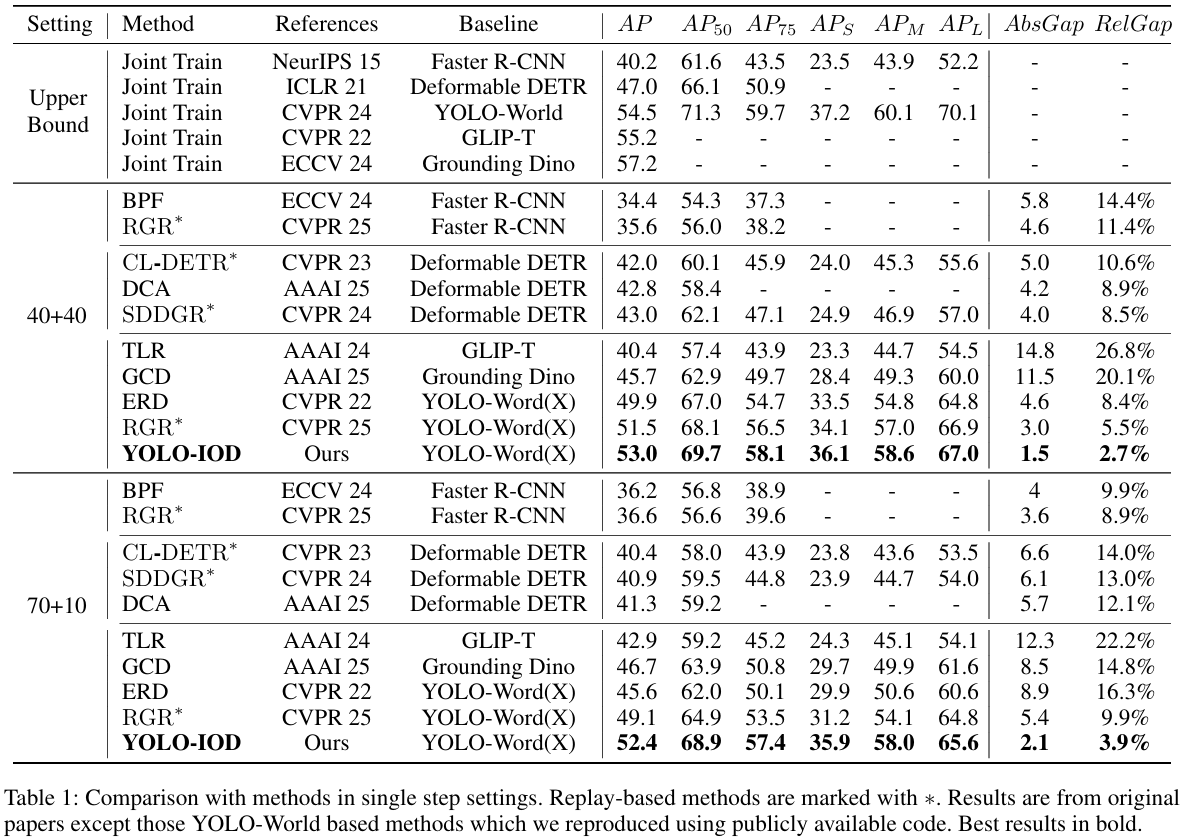
单阶段增量设置。我们首先在40+40和70+10设置下评估性能,其中分别添加40和10个类别。如表1所示,YOLO-IOD在先前方法上实现了一致的性能提升。具体而言,在40+40配置下,我们的方法以1.5的AP超越先前最佳方法RGR,AbsGap仅为1.5,并将相对性能差距从5.5%显著降低至2.7%。在70+10设置下,YOLO-IOD以3.3%的AP超越RGR,与上界相比达到极低的3.9% RelGap,同时在所有指标上保持强劲性能。值得注意的是,RGR是一种基于生成回放的方法,而我们的方法完全不需要回放。
多阶段增量设置。为更好地反映新类别持续引入的真实场景,我们扩展了多阶段评估(40-10、40-20)至更长的20-20和10-10设置,分别每阶段增量添加20或10个类别直至学习全部80个类别。这些更长配置对于评估真实部署场景中的增量检测器尤为重要。如表2所示,我们的方法在这些长期设置中始终达到最佳性能,相对于RGR的AP提升从3.3%增至6.3%。值得注意的是,在具有8个增量阶段的挑战性10-10设置下,YOLO-IOD展现出卓越性能,在最终阶段仅达到8.8%的RelGap,大幅超越RGR(20.3% RelGap)和CL-DETR(48.1% RelGap)。结果表明,YOLO-IOD通过充分解决知识冲突,可成功适配需要持续适应新兴目标类别的真实场景。
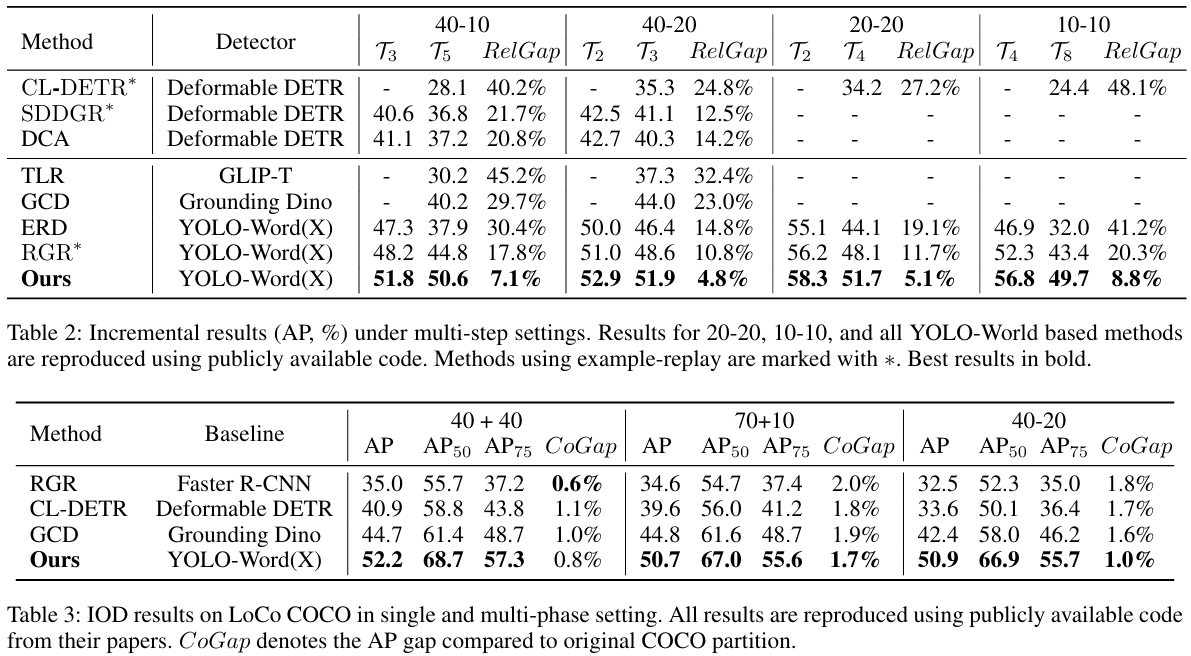
在LoCo COCO上的评估
我们在更贴近实际的LoCo COCO基准测试集上评估近期方法和我们的YOLO-IOD,如表3所示。与原始COCO基准测试集相比,所有方法在LoCo COCO上均经历0.6%至2.0%的AP下降,这表明先前增量设置中数据泄露的影响。尽管如此,YOLO-IOD在所有增量场景中始终实现强劲性能,即使在移除阶段间图像重叠的情况下也展现出鲁棒性。具体而言,YOLO-IOD在40+40、70+10和40+20设置下分别以7.5、5.9和8.5的AP超越先前最佳方法GCD。这些结果既凸显了YOLO-IOD在实际持续检测中的实用价值,也证明了LoCo COCO作为IOD实用评估基准的必要性。
消融实验
主要组件有效性。如表4所示,我们逐步添加模块以展示它们在70-10和40-10设置下的独立贡献。从标准伪标签基线开始(在70-10上达到48.4% AP,在40-10上达到44.3%),添加CPR将性能显著提升至50.3%和47.3%,证明其在缓解前景-背景混淆方面的有效性。加入IKS进一步将结果提升至70-10的51.5% AP和40-10的49.1%,凸显选择性参数更新的价值。值得注意的是,当单独应用CAKD时,AP从70-10的48.4%升至50.8%,从40-10的44.3%升至49.2%,展示其强大的蒸馏能力。当CAKD与先前模块结合时,可获得进一步增益,将AP从70-10的51.5%提升至52.4%,从40-10的49.1%提升至50.6%。这些结果证实CPR、IKS和CAKD三个组件协同工作,各自贡献显著性能提升并共同解决基础知识冲突。因此,完整的YOLO-IOD框架实现了卓越结果。
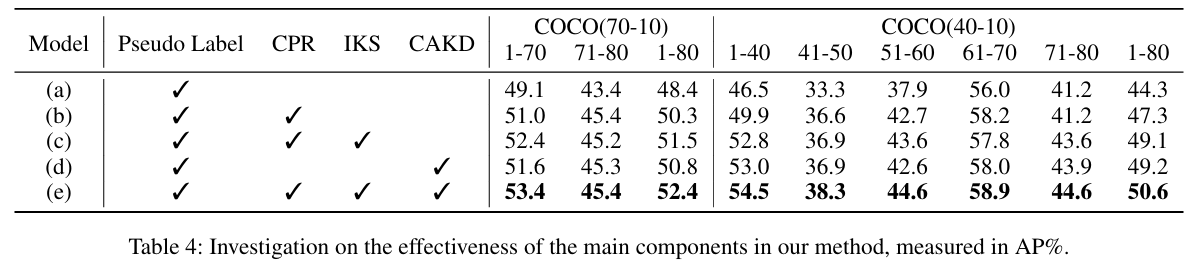
CAKD消融研究。如图3所示,我们比较了三种CAKD变体:仅使用旧教师检测器、仅使用当前教师检测器以及完整的双教师。在早期阶段,仅当前变体通过促进对新类别的快速适应表现更好。随着任务累积,仅旧变体在保留先前知识方面变得更有效,反映了从可塑性到稳定性的转变。完整的CAKD始终达到最佳结果,验证了结合两种知识源的非对称蒸馏优势。
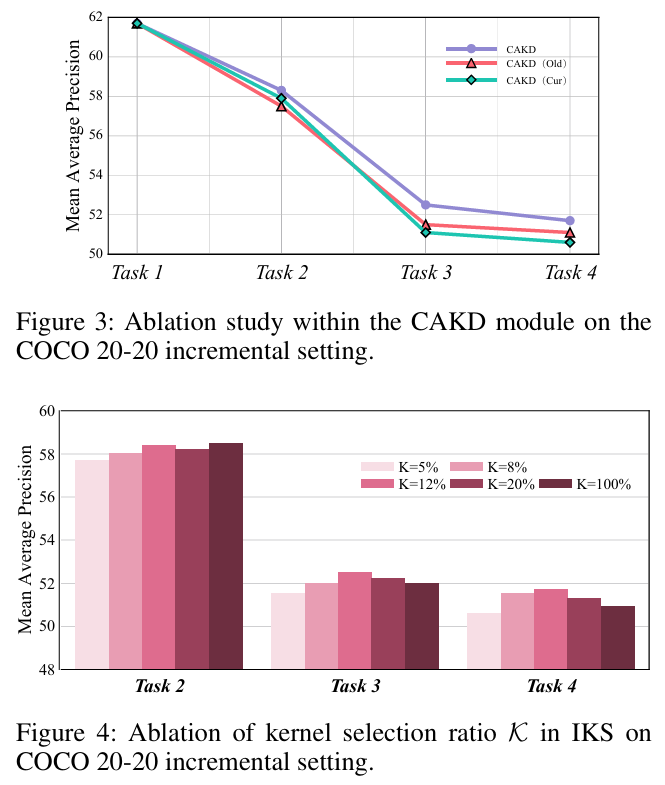
IKS卷积核选择比例K\mathcal{K}K的影响。如图4所示,较小比例(如5%)限制模型适应能力,而较大比例(如20%)因过度更新参数导致遗忘。我们观察到当设置K=12%\mathcal{K} = 12\%K=12%时达到最优权衡,凸显了在IOD中调节待更新参数量的重要性。
结论
本研究提出了YOLO-IOD,一种新颖的实时IOD框架,利用预训练的YOLO-World模型。通过有效解决前景-背景混淆、参数干扰和知识蒸馏错位挑战,部署三个精心设计的模块:冲突感知伪标签精炼、基于重要性的卷积核选择和跨阶段非对称知识蒸馏,YOLO-IOD在保留先前知识与获取检测新类别目标能力之间实现了最优平衡。此外,我们提出了LoCo COCO基准测试集,成功缓解数据泄露并将类别划分与真实世界共现性对齐。YOLO-IOD在传统COCO基准测试集和LoCo COCO基准测试集的多种单阶段和多阶段设置下均展现出卓越性能。
致谢
本工作部分受中国国家自然科学基金(NSFC)资助(项目号62576282、62476223);部分受中国国家重点研发计划资助(项目号2024YFF1306501、2024YFB4303700);部分受陕西省科技创新能力支撑计划资助(项目号2024ZC-KJXX-043);部分受STI2030重大项目资助(项目号2022ZD0208805);部分受陕西省自然科学基础研究计划资助(2024JC-DXWT-07)。