YOLO的早期发展
YOLOv1版本: 在当时主流目标检测模型都使用两阶段的方法:滑动窗口生成候选再进行分类和回归,YOLOv1提出了一次前向传播 输出所有检测结果,无候选框生成的单阶段目标检测方法,具体来说是将图像分成S×S的网格,然后每个网格预测2个预测框。
YOLOv2版本: YOLOv1 的训练过程存在梯度不稳定、收敛慢、对初始化敏感 的问题,且容易出现过拟合,导致模型泛化能力受限--->YOLOv2 在所有卷积层后都添加了BN 层,移除了原有的 Dropout,训练收敛速度提升3 倍以上,泛化能力提升较大。
YOLOv1直接回归预测框的效果较差--->YOLOv2 不再直接回归框的绝对坐标,而是回归预测框相对于 Anchor 的偏移量,大幅降低学习难度。Anchor 生成方式 :不再手动设定,而是用k-means 聚类对训练集的真实框(GT)聚类,得到 5 个最优 Anchor。(注:训练集是带标签的)
YOLOv2为了让模型适应不同尺度的特征,通过每训练10 个批次 ,随机选择一个尺寸作为下一批次的输入,这种多尺度训练能让用户推理时可根据需求选择尺寸。
YOLOv3版本: YOLOv1/v2 仅用单一尺度特征图 做预测--->YOLOv3使用FPN的上采样融合技术,输出 3 个尺度的特征图(步长分别为 32、16、8),对应不同大小的目标检测。
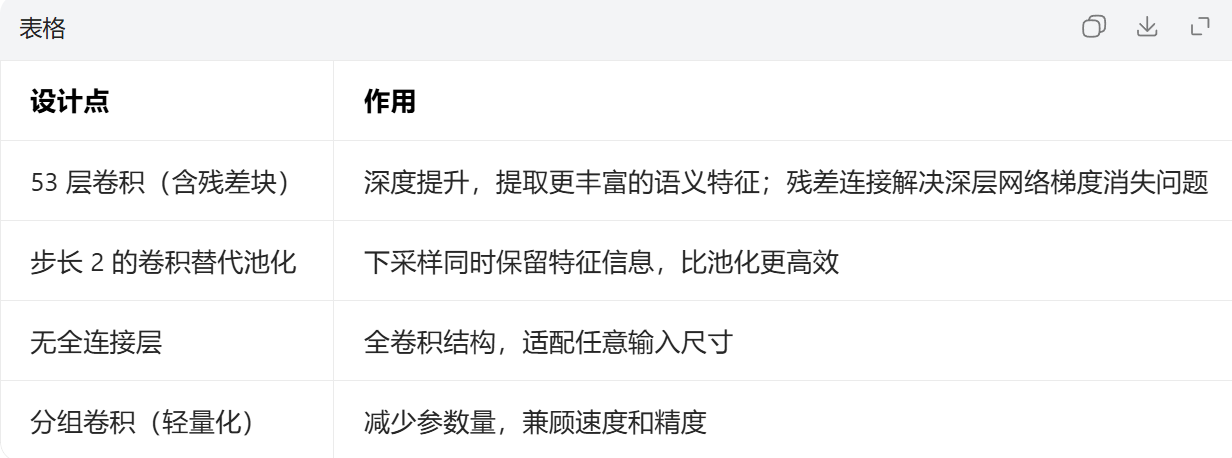
YOLOv2使用Darknet-19作为骨干网络,网络深度不足,语义特征提取能力弱--->YOLOv3设计了Darknet-53作为骨干网络,尽管速度略降,但是精度稳定提升,且支持了多标签分类,是真正实现了让YOLO能用的关键版本。
YOLO的中期发展
注:由于YOLOv4和YOLOv5发布时间非常将近,两者都采用 "SPP + PAN" 的特征融合组合,然而前者还是C语言,而后者是基于 PyTorch 框架,因此我们直接来看2020年6月发布的YOLOv5。
YOLOv5: 相较于YOLOv3版本纯残差块堆叠的Darknet-53,YOLOv5升级为了CSPDarknet53,核心改动是CSP 残差块(CSPResidual Block):将输入拆分为两部分,一部分走残差分支,一部分直接短路,最后拼接融合,大大减少了计算量。
C3模块详细介绍: 输入特征图(假设维度为 [B, C, H, W],B = 批次,C = 通道数,H/W = 高 / 宽)首先被按通道维度拆分为主分支和短路分支,各占一半的通道数, 主分支会经过 n 个残差块(Bottleneck)后和短路分支进行特征融合(Concat),最终经过一个1*1卷积层输出。
YOLOv3 仅用 FPN 做 "自上而下" 融合,浅层位置信息无法传递到深层--->
YOLOv5的骨干网络输出3个尺度特征 → SPPF增强深层特征 → FPN(自上而下)融合 → PAN(自下而上)融合 → 预测头
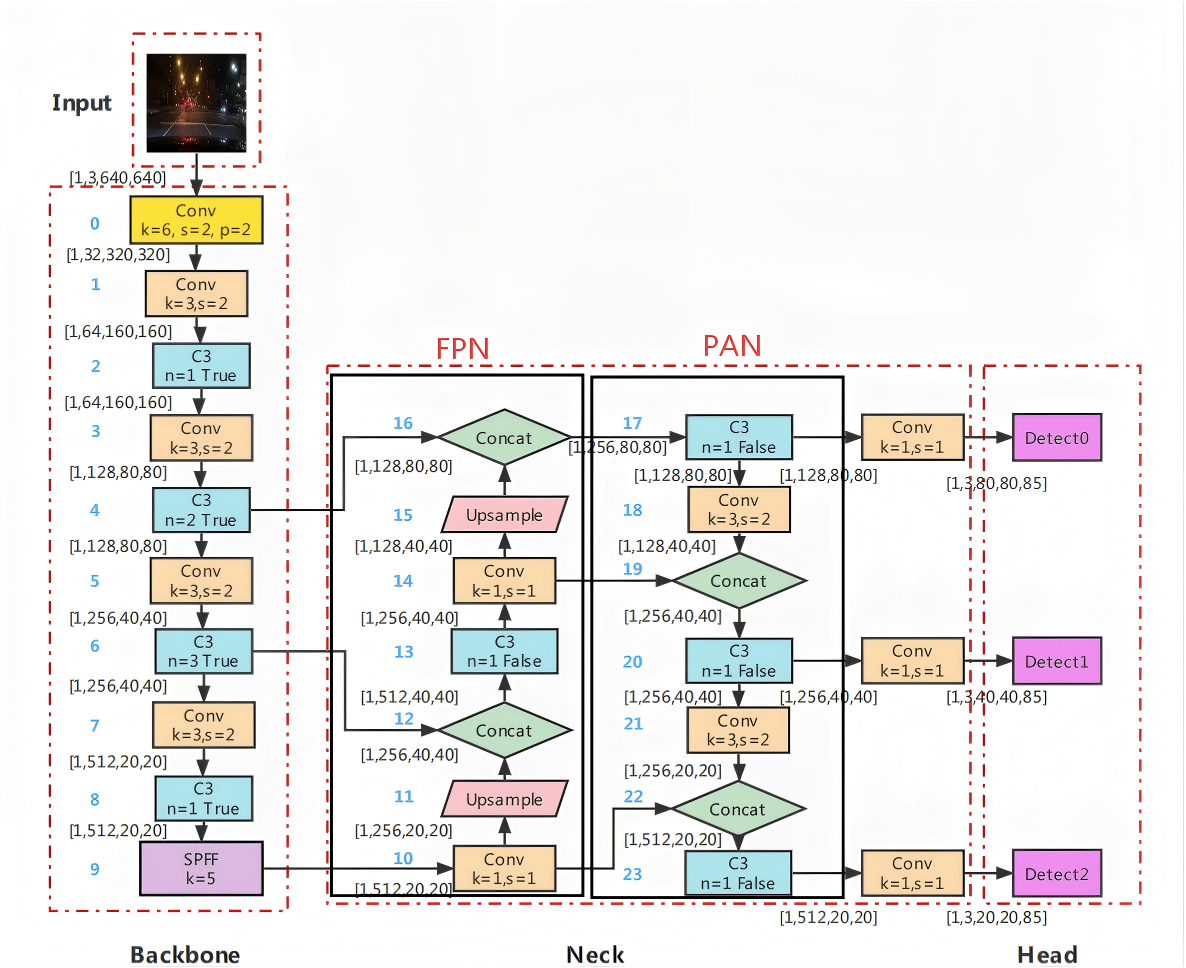
SPPF通过多次池化叠加,形成多尺度感受野,可同时捕捉小、中、大目标的特征,流程如下:
- 输入特征图先经过一次 5×5 最大池化;
- 输出结果再经过一次 5×5 最大池化;
- 若需要,可再经过一次 5×5 最大池化;
- 将原始特征、第一次池化、第二次池化、第三次池化的结果按通道拼接(Concat);
- 最后通过 1×1 卷积整合通道数,输出增强后的特征。
除了网络结构的改善,YOLOv5还提供了以下的方法提升模型性能和使用效果:
引入 Mosaic、MixUp、CutMix 等增强策略,自动对图像进行拼接、裁剪、颜色扰动;
采用 CIoU / DIoU Loss等损失,同时优化边界框回归和置信度损失;
支持自动锚框聚类、自动学习率调整、混合精度训练(FP16)、多尺度训练;
通过深度 / 宽度系数衍生出 nano/s/m/l/x 等多个版本;(yaml文件可直接修改)
基于 PyTorch 框架,提供一键训练 / 推理 / 导出脚本,支持 ONNX/TensorRT/OpenVINO 等格式。
YOLOv8于2023年1月发布,依然是 Backbone → Neck → Head 三段式结构,但相较于YOLOv5版本有了精度速度双提升。
YOLOv8:
主干网络依旧是CSPDarknet,相较于YOLOv5版本的C3模块,YOLOv8采用了更先进的C2f模块,核心区别是C3 是 "两路融合",C2f 是 "多路堆叠融合",特征更密、梯度更顺。
C2f 模块详细介绍: 输入特征图(假设维度为 [B, C, H, W])
首先通过 1×1 卷积将通道数调整为 C',随后按通道维度拆分为主分支 和短路分支 (各占 C'/2 通道数);主分支会依次经过 n 个串联的残差块(Bottleneck),且每个残差块的输出都会被保留 ,最终将「短路分支 + 原始主分支输入 + 所有残差块的输出」按通道维度拼接(Concat),再通过 1×1 卷积层整合通道数并输出,输出维度仍为 [B, C, H, W]。
C2f 的计算量略高于 C3,但特征表达能力提升远大于计算量增加,实现了精度的飞跃
Head部分也有了革命性的改进:从 Anchor-Based → Anchor-Free
YOLOv8的预测头是直接预测中心点和宽高,输出少、计算少、后处理极快
此外YOLOv8的预测头通过解耦实现任务互不干扰,可单独优化且收敛更快:
- 分类头:独立分支,只预测类别概率
- 回归头:独立分支,只预测框坐标
YOLOv5(Anchor-Based)的冗余计算,核心来自 Anchor 的 "预设 + 匹配 + 筛选" 全流程,
Anchor-Free直接预测目标的「中心点 + 宽高缩放」,无需预设 Anchor,输出维度简化为:[B, (4+1+NC), H, W](每个网格仅预测 1 组值),且无需 Anchor 匹配 / NMS 的大量筛选计算,实现了速度的飞跃
引入 DFL(Distribution Focal Loss):
- 对边界框坐标做分布建模(离散成 16 个 bin),用 softmax 输出概率分布,再加权求和得到连续坐标
- 优势:框回归更鲁棒、精度更高,尤其对小目标和密集场景
- 劣势:有一定的计算量,牺牲了速度
YOLOv8可以直接回归而YOLOV1不行的原因:
首先肯定是网络架构天差地别,其次是损失函数设计。
YOLOv1 用 MSE 损失直接回归坐标和置信度:
- 对宽高的 MSE 损失:大目标的宽高误差(如 ±10 像素)相对占比小,小目标的 ±10 像素误差是致命的,损失函数无法兼顾;
- 置信度损失:将 "是否包含目标" 和 "IoU" 混在一起,模型难以优化。
而 YOLOv8 用 DFL+CIoU Loss预测中心点偏移和宽高缩放:
- DFL:将坐标建模为概率分布,用 softmax 输出,对小目标的坐标误差更敏感;
- CIoU:同时考虑 IoU、长宽比、中心距离,回归更精准。
此外YOLOv8 采用 "预热(Warmup)+ 余弦衰减 + 自适应重启":前 5 个 epoch 小学习率预热(避免梯度爆炸),中期余弦衰减(稳定收敛),后期小幅重启(跳出局部最优)------ 训练收敛速度提升 20%,最终精度更高。
YOLO的近期发展
YOLOV11于2024年9月发布,在 "精度、速度、轻量化、多任务适配" 上做了精准的工程化优化
YOLO2026于2026 年1 月 14 日 ,随 Ultralytics 框架 v8.4.0 版本在 GitHub 正式发布,模型权重与代码全面开放,针对边缘部署进行了优化,具有端到端无 NMS 推理功能。
相较于YOLOV8,这两个版本在网络上个主要改进在于两点:C3K2模块和C2PSA模块
C3K2模块
C3K2 是 C3 模块的优化版,核心是将 3×3 卷积替换为 2×2 卷积(K2),在降低计算量的同时保持特征提取能力;
官方代码 modules\block.py
C2f 模块(YOLOv8)- 第 288-320 行
class C2f(nn.Module):
def init(self, c1: int, c2: int, n: int = 1, shortcut: bool = False, g: int = 1, e: float = 0.5):
super().init()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x: torch.Tensor) -> torch.Tensor:
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y-1) for m in self.m)
return self.cv2(torch.cat(y, 1))
C3k2 模块(YOLOv11)- 第 1069-1107 行
class C3k2(C2f):
def init(
self,
c1: int,
c2: int,
n: int = 1,
c3k: bool = False, # 新增参数
e: float = 0.5,
attn: bool = False, # 新增参数
g: int = 1,
shortcut: bool = True,
):
super().init(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(
nn.Sequential(
Bottleneck(self.c, self.c, shortcut, g),
PSABlock(self.c, attn_ratio=0.5, num_heads=max(self.c // 64, 1)),
)
if attn
else C3k(self.c, self.c, 2, shortcut, g)
if c3k
else Bottleneck(self.c, self.c, shortcut, g)
for _ in range(n)
)
C3k 模块 - 第 1109-1128 行
class C3k(C3):#可自定义卷积核k的大小
def init(self, c1: int, c2: int, n: int = 1, shortcut: bool = True, g: int = 1, e: float = 0.5, k: int = 3):
super().init(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))
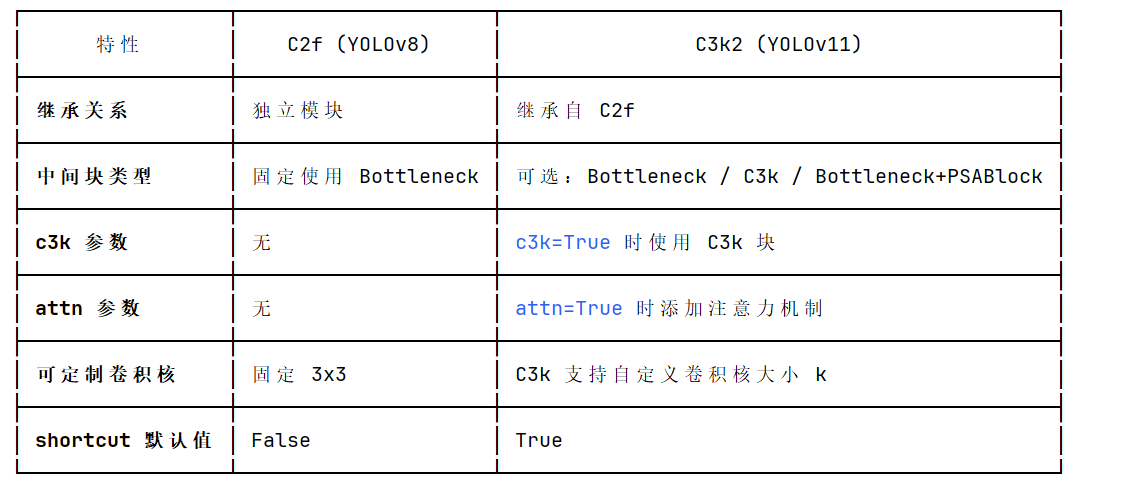
注:C3K2的注意力机制是YOLO26版本加入的,因此YOLOv11官方版本默认是False,不使用
相当于对于YOLOV11的C3K2模块只有两种模式:
c3k=False (使用 Bottleneck)完全等价于使用YOLOv8的C2f模块
输入 → cv1 → chunk成2份
├─ 直接通过
└─ Bottleneck(3x3) → Bottleneck(3x3) → ...
→ concat → cv2 → 输出
-
特点:轻量、计算效率高
-
适用:浅层、需要快速处理的位置
c3k=True (使用 C3k,默认卷积核3×3大小)
输入 → cv1 → chunk成2份
├─ 直接通过
└─ C3k模块
├─ cv1分支 → Bottleneck(k) → Bottleneck(k) → ...
└─ cv2分支 → 直接通过
→ concat → cv2 → 输出
-
特点:更大的感受野、更强的特征提取
-
适用:深层、需要语义信息的位置
YOLOv26: 只有最后一层 P5/32-large 使用了 attn=True,因为加上 PSABlock 注意力机制 能捕捉全局语义信息,增强大目标检测
C2PSA模块
class C2PSA(nn.Module):
"""C2PSA: C2f + PSA (Position-Sensitive Attention)"""def init(self, c1: int, c2: int, n: int = 1, e: float = 0.5):
super().init()
assert c1 == c2
self.c = int(c1 * e) # 隐藏通道数
self.cv1 = Conv(c1, 2 * self.c, 1, 1) # 1x1卷积,通道翻倍
self.cv2 = Conv(2 * self.c, c1, 1) # 1x1卷积,恢复通道# 🔑 核心:堆叠 n 个 PSABlock
self.m = nn.Sequential(
*(PSABlock(self.c, attn_ratio=0.5, num_heads=self.c // 64) for _ in range(n))
)def forward(self, x):
a, b = self.cv1(x).split((self.c, self.c), dim=1) # 分成两路
b = self.m(b) # b 路经过 PSA 注意力
return self.cv2(torch.cat((a, b), 1)) # 拼接后输出class PSABlock(nn.Module):
"""Position-Sensitive Attention Block"""
def init(self, c: int, attn_ratio: float = 0.5, num_heads: int = 4):
super().init()
🔑 多头自注意力
self.attn = Attention(c, attn_ratio=attn_ratio, num_heads=num_heads)
🔑 前馈网络
self.ffn = nn.Sequential(
Conv(c, c * 2, 1), # 扩展
Conv(c * 2, c, 1, act=False) # 压缩
)
self.add = shortcut
def forward(self, x):
x = x + self.attn(x) # 残差 + 注意力
x = x + self.ffn(x) # 残差 + FFN
return x
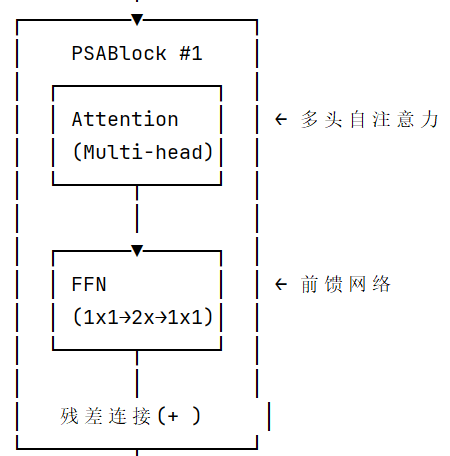
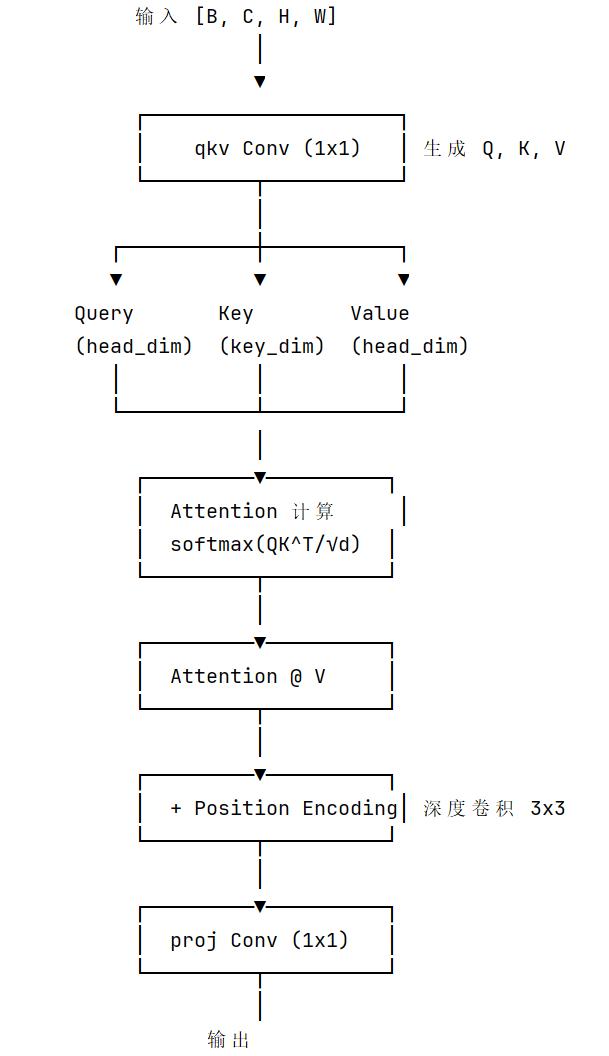
左边是PSABlock,右边是注意力机制
C2PSA = C2f 结构 + PSA 注意力机制
核心创新:
-
双分支设计:一路保留原始特征(a分支),一路进行注意力增强(b分支)
-
PSA 堆叠:可以堆叠多个 PSABlock,逐步增强特征
-
位置敏感:通过深度卷积保留空间位置信息
-
高效平衡:只在最深层 P5 使用一次,避免过大的计算开销
作用:增强模型对全局上下文的理解,特别有助于大目标检测和复杂场景的理解。
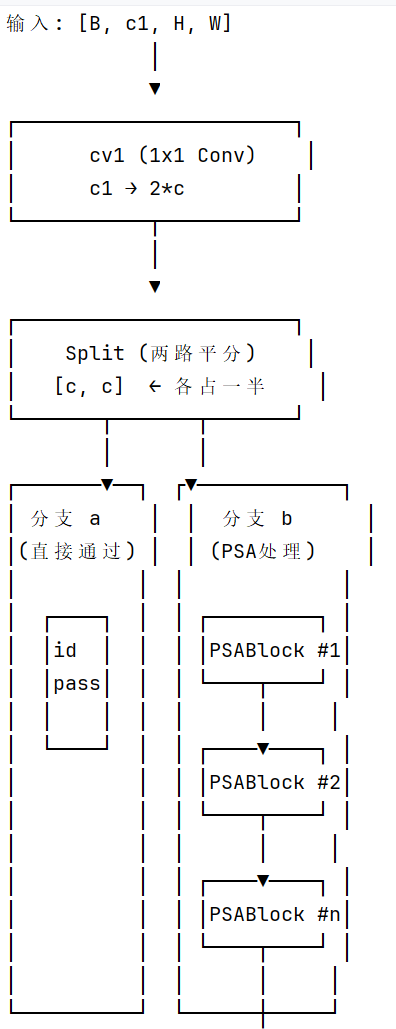
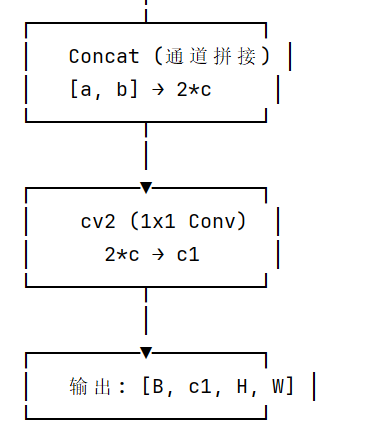
两个模块都不改变输入输出的空间尺寸和通道数,它们的作用是增强特征表达:
-
SPPF: 多尺度局部特征融合
-
C2PSA: 全局上下文建模(注意力)
-
YOLOv26 的改进: SPPF 加入残差连接
def init(self, c1: int, c2: int, k: int = 5, n: int = 3, shortcut: bool = False):
c1: 输入通道
c2: 输出通道
k: 池化核大小(默认5)
n: 池化迭代次数(默认3)
shortcut: 是否用残差连接(默认False)
YOLO26的其他改进
移除了DFL模块
reg_max: 1 # 控制DFL (Distribution Focal Loss) 的分布区间数量,用于边界框回归。取1则相当于移除了DFL,直接减少了计算量
无需NMS的端到端
nn\modules\head.py
end2end: True # whether to use end-to-end mode|----------------------------------------------------------------------------|----------------------------------------------------------------------------|
| YOLO26以前的模式 | YOLO26 |
| 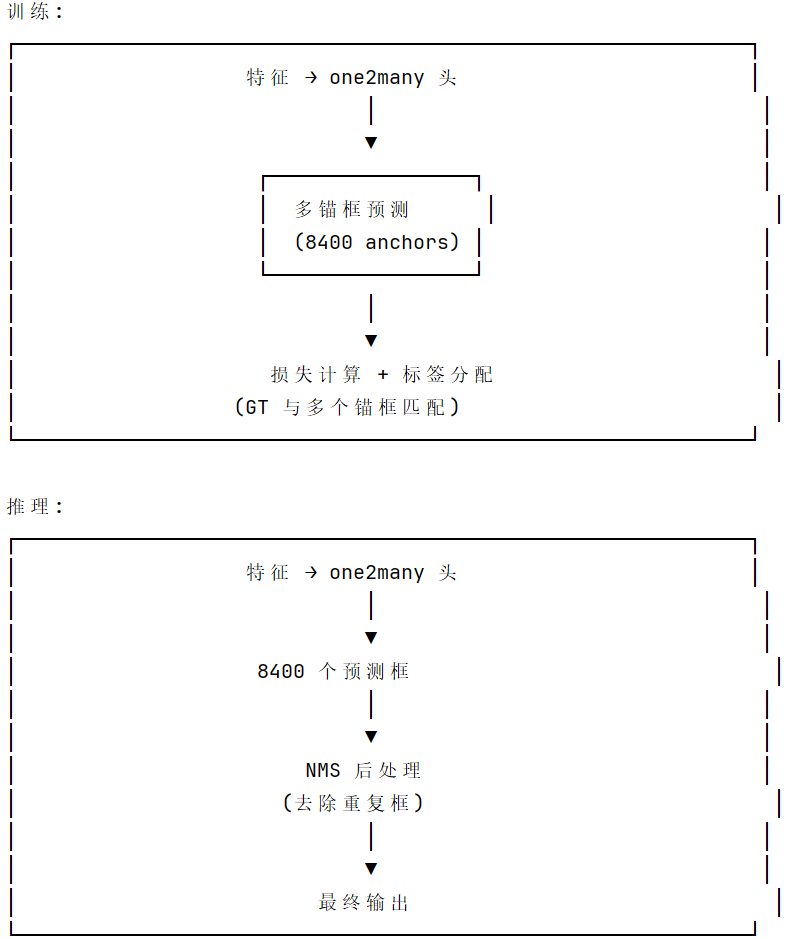 |
|  |
|
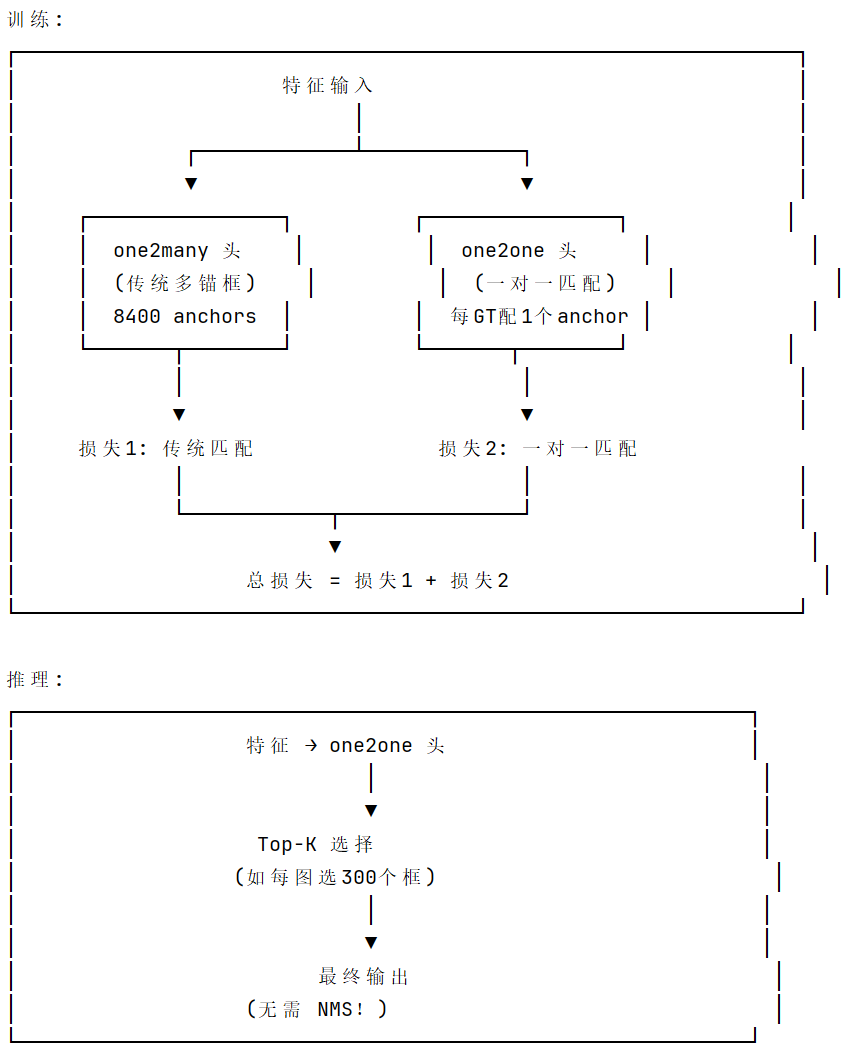
YOLOv26 通过 one2one 头实现一对一监督训练,让模型学会"每个位置只预测一个目标",从而推理时可以用 Top-K 直接输出,无需 NMS,实现真正的端到端目标检测。Top-K 就是从所有预测框中,选择置信度最高的 K 个框。
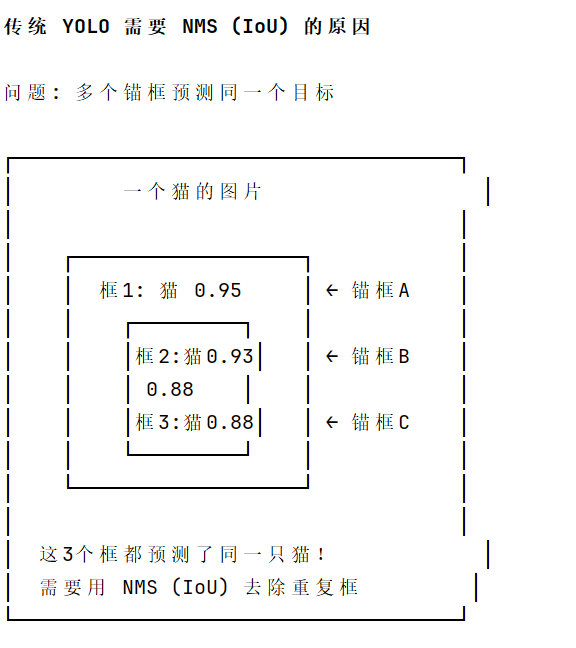
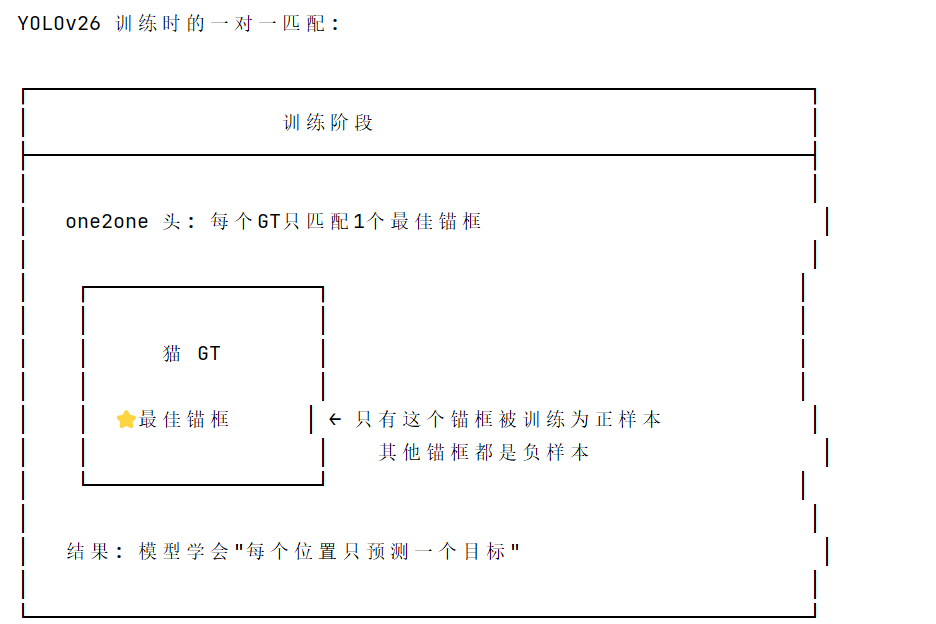
由于训练时一对一监督,模型自然地倾向于: 每个目标位置只有一个高置信度预测 不会有大量重复框 , 因此直接 Top-K 选择即可,无需 NMS 去重
改进了损失函数并使用了MuSGD优化器
class E2EDetectLoss:
def init(self, model):
🔑 核心:创建两个损失函数,使用不同的 tal_topk
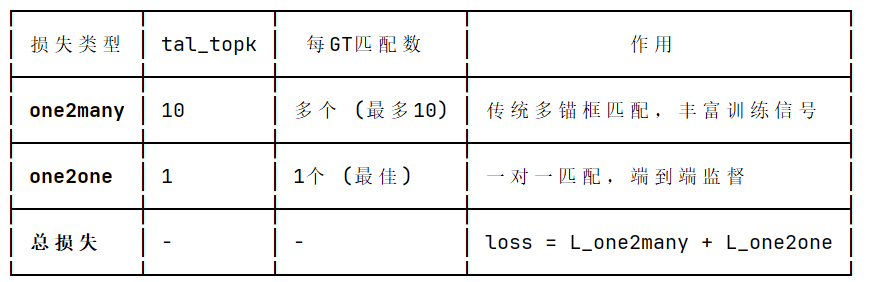
self.one2many = v8DetectionLoss(model, tal_topk=10) # 多对一
self.one2one = v8DetectionLoss(model, tal_topk=1) # 一对一
def call(self, preds, batch):
one2many = preds"one2many"
loss_one2many = self.one2many(one2many, batch)
one2one = preds"one2one"
loss_one2one = self.one2one(one2one, batch)
🔑 双损失相加
return loss_one2many0 + loss_one2one0, loss_one2many1 + loss_one2one1
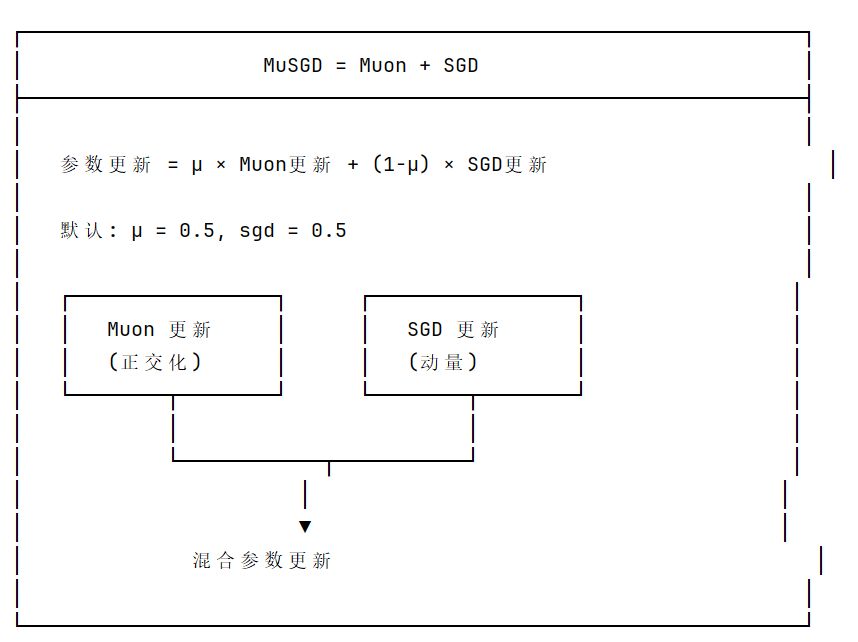
自动优化器切换
trainer.py 中的逻辑
name, lr, momentum = ("MuSGD", 0.01, 0.9) if iterations > 10000 else ("AdamW", lr_fit, 0.9)