python
**import pandas as pd
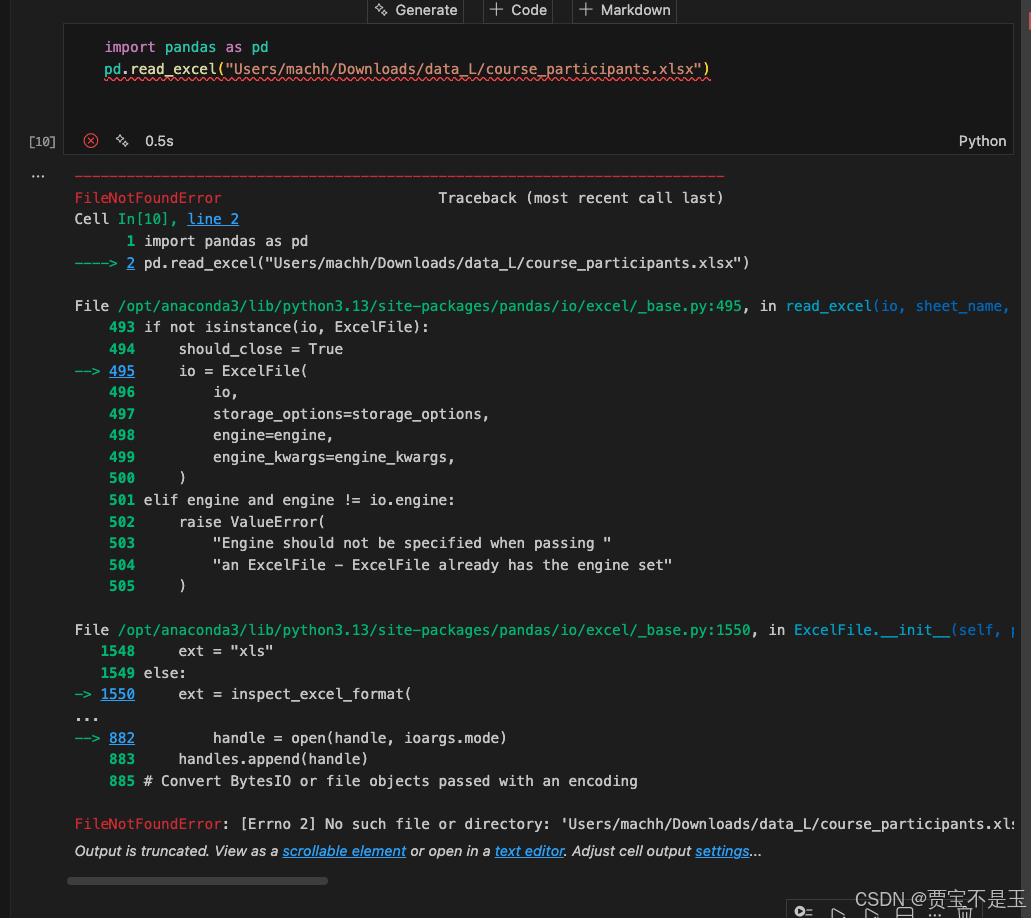
pd.read_excel("Users/machh/Downloads/data_L/course_participants.xlsx")错误在哪里
核心问题修正与关键说明
- 路径错误(最核心问题)
路径 Users/machh/... 缺少根目录前缀 /,属于相对路径,Python 会从当前运行脚本的目录开始查找,而非系统根目录,导致文件找不到。
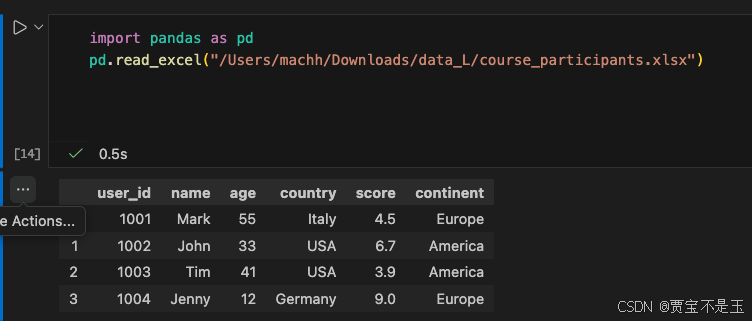
正确绝对路径:/Users/machh/Downloads/data_L/course_participants.xlsx(macOS/Linux 系统)。 - 未赋值 DataFrame 对象
pd.read_excel() 执行后会返回DataFrame 类型的数据集对象,必须将其赋值给变量(如 df),否则无法对数据进行后续操作(筛选、分析、可视化等)。 - 跨系统路径兼容说明
macOS/Linux:路径分隔符为 /,绝对路径以 / 开头(如上述代码);
Windows:路径分隔符为 \(需转义为 \),绝对路径以盘符开头(如 C:\Users\machh\...)。 - 必加异常处理
添加 try-except 可以捕获文件不存在、路径错误、Excel 文件损坏等常见问题,避免程序直接崩溃,同时给出明确的错误提示。
实用技巧
- 查看当前工作目录(确认相对路径的基准目录)
python
import os
print("当前工作目录:", os.getcwd()) # 若用相对路径,文件需放在此目录下- 读取 Excel 指定 sheet
python
df = pd.read_excel(file_path, sheet_name="Sheet1") # sheet_name可传数字(0=第一个sheet)- 处理大型 Excel 文件(提升读取速度,减少内存占用):
python
df = pd.read_excel(file_path, usecols=[0,1,3]) # 只读取指定列运行结果预期
若路径正确、文件正常,会输出:
数据前 5 行的内容(快速验证数据结构);
数据的基本信息(列名、非空值数量、数据类型等),示例如下:
python
数据读取成功,前5行内容:
学员ID 课程名称 报名时间 学习进度
0 1 Python 2026-01-01 100.0
1 2 Python 2026-01-02 80.0
2 3 SQL 2026-01-01 90.0
3 4 Python 2026-01-03 70.0
4 5 SQL 2026-01-02 100.0
数据基本信息:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 100 entries, 0 to 99
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 学员ID 100 non-null int64
1 课程名称 100 non-null object
2 报名时间 100 non-null datetime64[ns]
3 学习进度 98 non-null float64
dtypes: datetime64[ns](1), float64(1), int64(1), object(1)
memory usage: 3.2+ KB