目录
[4.1 基数排序](#4.1 基数排序)
[4.1.1 CPU代码](#4.1.1 CPU代码)
[4.1.2 GPU代码](#4.1.2 GPU代码)
[4.2 合并列表](#4.2 合并列表)
[4.2.1 CPU代码](#4.2.1 CPU代码)
[4.2.2 GPU代码](#4.2.2 GPU代码)
[4.2.2.1 并行合并](#4.2.2.1 并行合并)
CUDA C/C++ 中的函数修饰符:
变量声明:
__shared__:是一个关键的限定符,用于声明共享内存(Shared Memory)__constant__: 是一个限定符,用于声明存储在常量内存(Constant Memory)中的变量cudaMalloc:是 CUDA 运行时 API 中用于在 GPU 设备内存(全局内存)中分配内存的函数,类似于 CPU 端的malloc函数,但分配的是 GPU 显存,允许程序在 GPU 上进行并行计算__managed__:用于声明统一内存(Unified Memory)变量
函数声明:
__global__:用于声明 CUDA 内核函数(Kernel),该函数在 GPU 上执行__host__:用于声明函数仅在主机(CPU)上运行-
__device__: 用于声明在 GPU 设备上执行的函数,且只能从设备端代码(如核函数或其他__device__函数)调用 -
__host__ __device__:实现同一函数在主机和设备端的双重编译,可以在主机和设备上都被调用
调用内核:
cpp
kernel_function<<<num_blocks, num_threads>>>(param1, param2, ...)参数num_threads表示内核函数的线程数量。在这个例子中,线程数目即循环迭代的次数。内核调用的下一部分是参数传递。我们可以使用寄存器或者常量内存进行参数传递。如果使用寄存器传参,每个线程用一个寄存器来传递一个参数。
线程块:
num_blocks是内核函数调用中的第一个参数,如果将这个参数从1改成2,就是告诉GPU硬件,将启动之前线程数量的2倍线程。例如:
cpp
some_kernel_func<<<2,128>>>(a,b,c)这将会调用名为some_kernel_func的GPU函数2*128次,每次都是不同的线程。
cpp
// 设备端函数,计算平方
__device__ float square(float x) {
return x * x;
}
// 核函数调用设备函数
__global__ void kernel(float* input, float* output, int n) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < n) {
output[idx] = square(input[idx]); // 调用 __device__ 函数
}
}线程网格:
cpp
dim3 threads_rect(32,4);
dim3 blocks_rect(1,4);每个线程块的X轴方向上开启了32个线程,Y轴方向上开启了4个线程;在线程网格上,X轴方向上有一个线程块,Y轴方向有4个线程块。之后,我们可以通过以下代码来启动内核:
cpp
some_kernel_func<<<blocks_rec,threads_rec>>>(a,b,c)4.1 基数排序
基数排序通过从最低有效位到最高有效位一一进行比较,对数值排序。对于一个32位的整型数,使用一个基数位,无论数据集有多大,整个排序需要迭代32次。按照比特位依次比较。
例子:{122,10,1,2,9}
它们二进制分别为:
122:01111010
10 :00001010
1 :00000001
2 :00000010
9 :00001001
**第一轮:**最低有效位为0的元素放一起,为1的放一起

**第二轮:**比较的有效位往左移动一位

第三轮:

第四轮:

第五轮:

第六轮:

第七轮:

第8轮:

...
直到第32轮
4.1.1 CPU代码
为了建立列表,我们需要N+2N个内存单元。我们可以将比特位为0的数从列表头开始存放,比特数为1的从列表尾开始存放。我们使用两个单独的列表。
cpp
__host__ void cpu_sort(u32 * const data, const u32 num_elements)
{
static u32 cpu_tmp_0[NUM_ELEME];
static u32 cpu_tmp_1[NUM_ELEME];
for (u32 bit=0;bit<32;bit++)
{
u32 base_cnt_0=0;
u32 base_cnt_1=0;
for(u32 i=0;i<num_elements;i++)
{
const u32 d = data[i];
const u32 bit_mask=(1<<bit);
if ((d&bit_mask)<0)
{
cpu_tmp_1[base_cnt_1]=d;
base_cnt_1++;
}
else
{
cpu_tmp_0[base_cnt_0]=d;
base_cnt_0++;
}
}
for(u32 i=0;i<base_cnt_0;i++)
{
data[i]=cpu_tmp_0[i];
}
for(u32 i=0;i<base_cnt_1;i++)
{
data[base_cnt_0+i]=cpu_tmp_1[i];
}
}
}4.1.2 GPU代码
GPU代码需要考虑多线程。
cpp
__device__ void radix_sort(u32 * const sort_tmp,
const u32 num_lists,
const u32 num_elements,
const u32 tid,
u32 * const sort_tmp_0,
u32 * const sort_tmp_1)
{
for (u32 bit=0;bit<32;bit++)
{
u32 base_cnt_0=0;
u32 base_cnt_1=0;
for (u32 i=0;i<num_elements;i+num_lists)
{
const u32 elem = sort_tmp[i+tid];
const u32 bit_mask = (1<<bit);
if ((elem&bit_mask)>0)
{
sort_tmp_1[base_cnt_1+tid]=elem;
base_cnt_1+num_lists;
}
else
{
sort_tmp_0[base_cnt_0+tid]=elem;
base_cnt_0+num_lists;
}
}
for(u32 i=0;i<base_cnt_0;i+num_lists)
{
sort_tmp[i+tid]=sort_tmp_0[i+tid];
}
for(u32 i=0;i<base_cnt_1;i+num_lists)
{
sort_tmp[base_cnt_0+i+tid]=sort_tmp_1[i+tid];
}
}
__syncthreads();
}
此时,GPU内核是以一个设备函数的形式编写的。设备函数是只能被GPU内核调用的函数。它相当于C语言函数声明之前添加一个"static",或者C++中的"private"。
该GPU版本的代码通过将num_lists个线程产生num_lists个独立的排好序的列表。 在代码中的内循环有变化,串行代码,每次循环+1,在并行代码中,每次循环增加num_lists。这个数表示基数排序所产生的独立列表的数目,它等于内核函数每个每个线程块启动的线程数。为了避免存储冲突,它的理想值应该是线程束的大小32。
优化之后的代码如下:
cpp
__device__ void radix_sort(u32 * const sort_tmp,
const u32 num_lists,
const u32 num_elements,
const u32 tid,
u32 * const sort_tmp_0,
u32 * const sort_tmp_1)
{
for (u32 bit=0;bit<32;bit++)
{
u32 base_cnt_0=0;
u32 base_cnt_1=0;
for (u32 i=0;i<num_elements;i+num_lists)
{
const u32 elem = sort_tmp[i+tid];
const u32 bit_mask = (1<<bit);
if ((elem&bit_mask)>0)
{
sort_tmp_1[base_cnt_1+tid]=elem;
base_cnt_1+=num_lists;
}
else
{
sort_tmp_0[base_cnt_0+tid]=elem;
base_cnt_0+=num_lists;
}
}
for(u32 i=0;i<base_cnt_0;i+num_lists)
{
sort_tmp[i+tid]=sort_tmp_0[i+tid];
}
for(u32 i=0;i<base_cnt_1;i+num_lists)
{
sort_tmp[base_cnt_0+i+tid]=sort_tmp_1[i+tid];
}
}
__syncthreads();
}
不需要将0列表和1列表分开 ,0列表可以通过重复利用原始列表空间进行创建。掩码实际上是跟bit的单次迭代相关的常量,它是伴随循环索引i的一个常量,因此可以将它移到循环的外面,以下是 稍作优化后的代码:
cpp
__device__ void radix_sort(u32 * const sort_tmp,
const u32 num_lists,
const u32 num_elements,
const u32 tid,
u32 * const sort_tmp_1)
{
for (u32 bit=0;bit<32;bit++)
{
const u32 bit_mask = (1<<bit);
u32 base_cnt_0=0;
u32 base_cnt_1=0;
for (u32 i=0;i<num_elements;i+num_lists)
{
const u32 elem = sort_tmp[i+tid];
if ((elem&bit_mask)>0)
{
sort_tmp_1[base_cnt_1+tid]=elem;
base_cnt_1+=num_lists;
}
else
{
sort_tmp[base_cnt_0+tid]=elem;
base_cnt_0+=num_lists;
}
}
for(u32 i=0;i<base_cnt_1;i+num_lists)
{
sort_tmp[base_cnt_0+i+tid]=sort_tmp_1[i+tid];
}
}
__syncthreads();
}
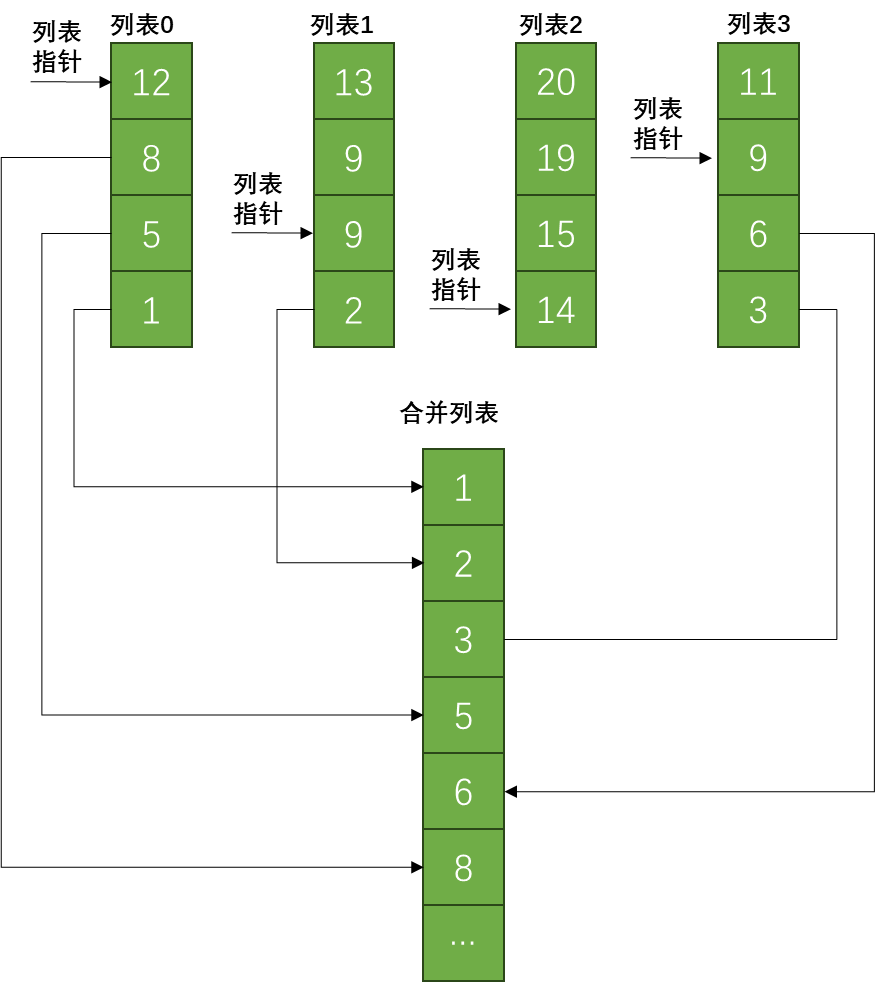
4.2 合并列表
合并排好序的列表是并行编程中一个比较常用的方法。
4.2.1 CPU代码
假定需要从num_lists个列表中选取数据,我们需要跟踪当前在各个列表中的位置,用list_indexes数组来表示 。 由于数组的数量可能很小,我们使用栈,将数据声明为本地变量,但是对于GPU内核而言,这是一个不好的选择,因为根据GPU的不同,栈可能分配到缓慢的全局内存上,而共享内存可能是GPU上的最优选择。
首先,将索引值全部设置为0,然后对所有元素进行迭代,使用find_min函数得到结果值划分到结果中。
find_min函数从num_lists个数值中找到最小的那一个数。对每一个列表都用到了一个索引进行维护。如果函数找到一个值比当前min_val小,将min_val更新为新找到的值。扫描完所有的列表,最小值对应的列表索引加一,并返回得到的最小值。
cpp
void merge_array(const u32 * const src_array,
u32 * const dest_array,
const u32 num_lists,
const num_elements)
{
const u32 num_elements_per_list = (num_elements/num_lists);
u32 list_indexes[MAX_NUM_LISTS];
for(u32 list=0;list<num_lists;list++)
{
list_indexes[list]=0;
}
for(u32 i=0;i<num_elements;i++)
{
dest_array[i]=find_min(srs_array,
list_indexes,
num_lists,
num_elements_per_list);
}
}
u32 find_min(const u32 * const src_array,
u32 * const list_indexes,
const u32 num_lists,
const u32 num_elements_per_list)
{
u32 min_val = 0xFFFFFFFF;
u32 min_idx = 0;
for (u32 i=0;i<num_lists;i++)
{
if(list_indexes[i]<num_elements_per_list)
{
const u32 src_index=i+(list_indexes[i]*num_lists];
const u32 data = src_data[src_index];
if (data<min_val)
{
min_val = data;
min_idx = i;
}
}
}
list_indexes[min_idx]++;
return min_val;
}4.2.2 GPU代码
顶层函数如下:
cpp
__global__ void gpu_sort_array_array(u32 * const data,
const u32 num_lists,
const u32 num_elements)
{
const u32 tid = (blockIdx.x*blockDim.x)+threadIdx.x;
__shared__ u32 sort_tmp[NUM_ELEM];
__shared__ u32 sort_tmp_1[NUM_ELEM];
copy_data_to_shared(data,sort_tmp,num_lists,num_elements,tid);
radix_sort2(sort_tmp,num_lists,num_elements,rid,sort_tmp_1);
merge_array6(sort_tmp,data,num_lists,num_elements,tid);
}函数copy_data_to_shared以行的形式将数据从全局内存读入到共享内存。要想程序尽可能的快,就要使用共享内存替换全局内存。以行的形式访问全局内存性能最好,以列的形式访问将产生离散的内存模式,除非每个线程都访问 同一列,且所有的地址都是相邻的。
cpp
__device__ void copy_data_to_shared(const u32 * data,
u32 * sort_tmp,
const u32 num_lists,
const u32 num_elements,
const u32 tid)
{
for (u32 i=0;i<num_elements;i+=num_list)
{
sort_tmp[i+tid]=data[i+tid];
}
__syncthreads();
}当编译程序时,在nvcc编译器选项中选择添加 -v 标志,编译器将打印出一条不相关的信息,用于说明创建了一个栈帧。
当函数调用一个子函数,并传入参数时,这些参数必须以某种方式提供给被调用的函数,比如执行以下的函数调用:
cpp
dest_array[i]=find_min(srs_array,
list_indexes,
num_lists,
num_elements_per_list);此时有两种方式可以采用,一种是通过寄存器传递需要的值,另一种就是创建一个叫栈帧对的内存区。大多数现代处理器有一个很大的寄存器组,对于一层调用而言一般是足够的,老式架构的处理器会用到栈帧,将参数值压入到栈中,被调用的函数值从栈中弹出。
cpp
__device__ void merge_array1(const u32 * const src_array,
u32 * const dest_array,
const u32 num_lists,
const u32 num_elements,
const u32 tid)
{
__shared__ u32 list_indexes[MAX_NUM_LISTS];
list_indexes[tid]=0;
__syncthreads();
if (tid==0) //单个线程跑
{
const u32 num_elements_per_list = (num_elements/num_lists);
for (u32 i=0;i<num_elements;i++)
{
u32 min_val=0xFFFFFFFF;
u32 min_idx=0;
for(u32 list=0;list<num_lists;list++)
{
if(list_indexes[list]<num_elements_per_list)
{
const u32 src_idx=list+(list_indexes[list]*num_lists);
const u32 data = src_data[src_idx];
if (data<=min_val])
{
min_val = data;
min_idx = list;
}
}
}
list_indexes[min_idx]++;
dest_array[i]=min_val;
}
}
}merge_array1函数将原先的merge_array函数与find_min函数合并起来。重新编译将不再产生栈帧。
4.2.2.1 并行合并
为了获取更好的性能,只用一个线程进行合并是不够的。但是因为是合并到同一个列表,使用多个线程会引入问题。线程必须以某种方式进行合作,这使得合并变得更加复杂。
cpp
__device__ void merge_array6(const u32 * const src_array,
u32 * const dest_array,
const u32 num_lists,
const u32 num_elements,
const u32 tid)
{
const u32 num_elements_per_list = (num_elements/num_lists);
__shared__ u32 list_indexes[MAX_NUM_LISTS];
list_indexes[tid]=0;
__syncthreads();
for (u32 i=0;i<num_elements;i++)
{
__shared__ u32 min_val;
__shared__ u32 u32 min_tid;
if(list_indexes[tid]<num_elements_per_list)
{
const u32 src_idx=tid+(list_indexes[tid]*num_lists);
data = src_data[src_idx];
}
else
{
data = 0xFFFFFFFF;
}
if (tid==0)
{
min_val = 0xFFFFFFFF;
min_tid 0xFFFFFFFF;
}
__syncthreads();
atomicMin(&min_val,data);
__syncthreads();
if (min_val==data)
{
atomicMin(&min_tid,tid);
}
__syncthreads();
if (tid==min_tid) //只用了一个线程将结果写入到输出
{
list_indexes[tid]++;
dest_array[i]=data;
}
}
}这个版本的代码使用了num_lists个线程进行合并操作,但是只用了一个线程一次将结果写入到输出数据列表。使用多个线程比较出最小的值,然后只用一个线程将结果写入输出。在函数中使用了atomicMin函数,每个线程从列表中获取的数据作为输入参数,调用atomicMin,取代了原先的单个线程访问列表中的所有元素找到最小值。