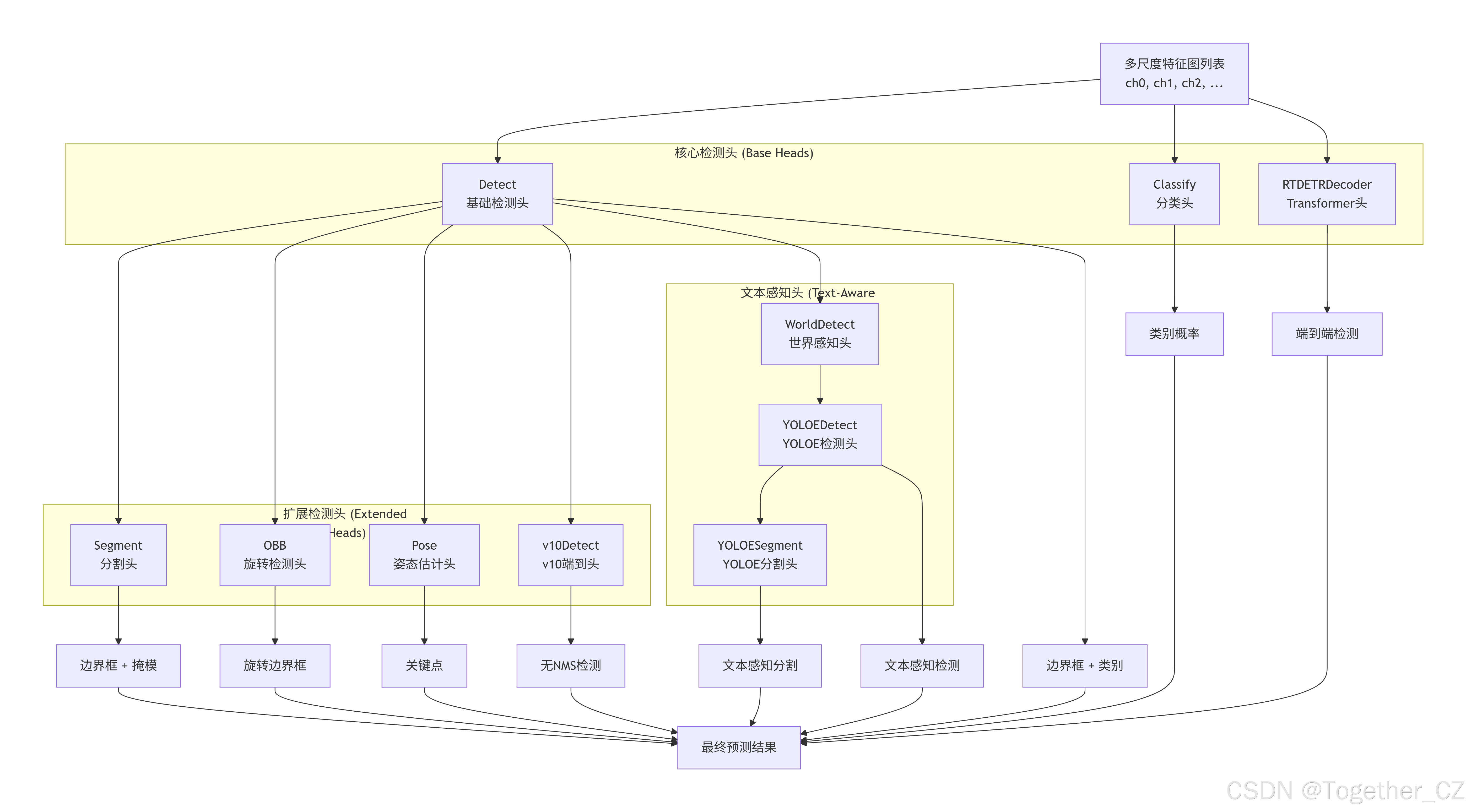
head模块是Ultralytics YOLO项目的核心组件之一,定义了各种任务专用的神经网络头部模块。这些头部模块负责将骨干网络提取的特征转换为具体的预测输出,如边界框、类别概率、掩模系数、关键点等。
基础依赖导入:
python
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
"""Model head modules.""" # 模型头部模块
from __future__ import annotations # 允许使用类型提示中的前向引用
import copy # 用于深度复制模块
import math # 数学运算
import torch # PyTorch深度学习框架
import torch.nn as nn # PyTorch神经网络模块
import torch.nn.functional as F # PyTorch函数式接口
from torch.nn.init import constant_, xavier_uniform_ # 参数初始化方法
from ultralytics.utils import NOT_MACOS14 # 工具函数:检查是否为MacOS 14
from ultralytics.utils.tal import dist2bbox, dist2rbox, make_anchors # 工具函数:边界框转换和锚点生成
from ultralytics.utils.torch_utils import TORCH_1_11, fuse_conv_and_bn, smart_inference_mode # PyTorch工具函数
from .block import DFL, SAVPE, BNContrastiveHead, ContrastiveHead, Proto, Proto26, RealNVP, Residual, SwiGLUFFN # 自定义块模块
from .conv import Conv, DWConv # 卷积模块
from .transformer import MLP, DeformableTransformerDecoder, DeformableTransformerDecoderLayer # Transformer模块
from .utils import bias_init_with_prob, linear_init # 工具函数
__all__ = "OBB", "Classify", "Detect", "Pose", "RTDETRDecoder", "Segment", "YOLOEDetect", "YOLOESegment", "v10Detect" # 导出模块列表head模块总体架构示意图如下所示:
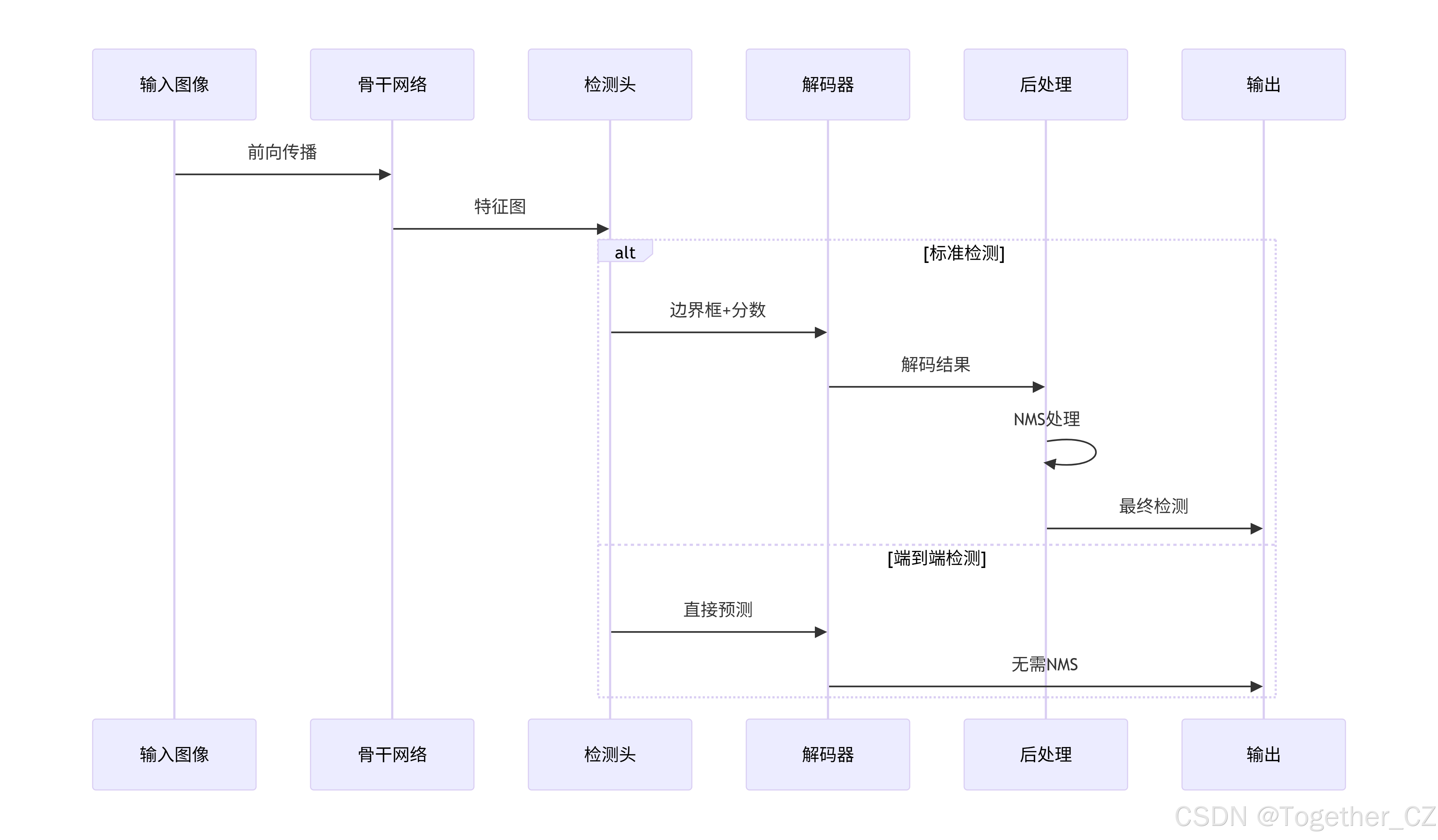
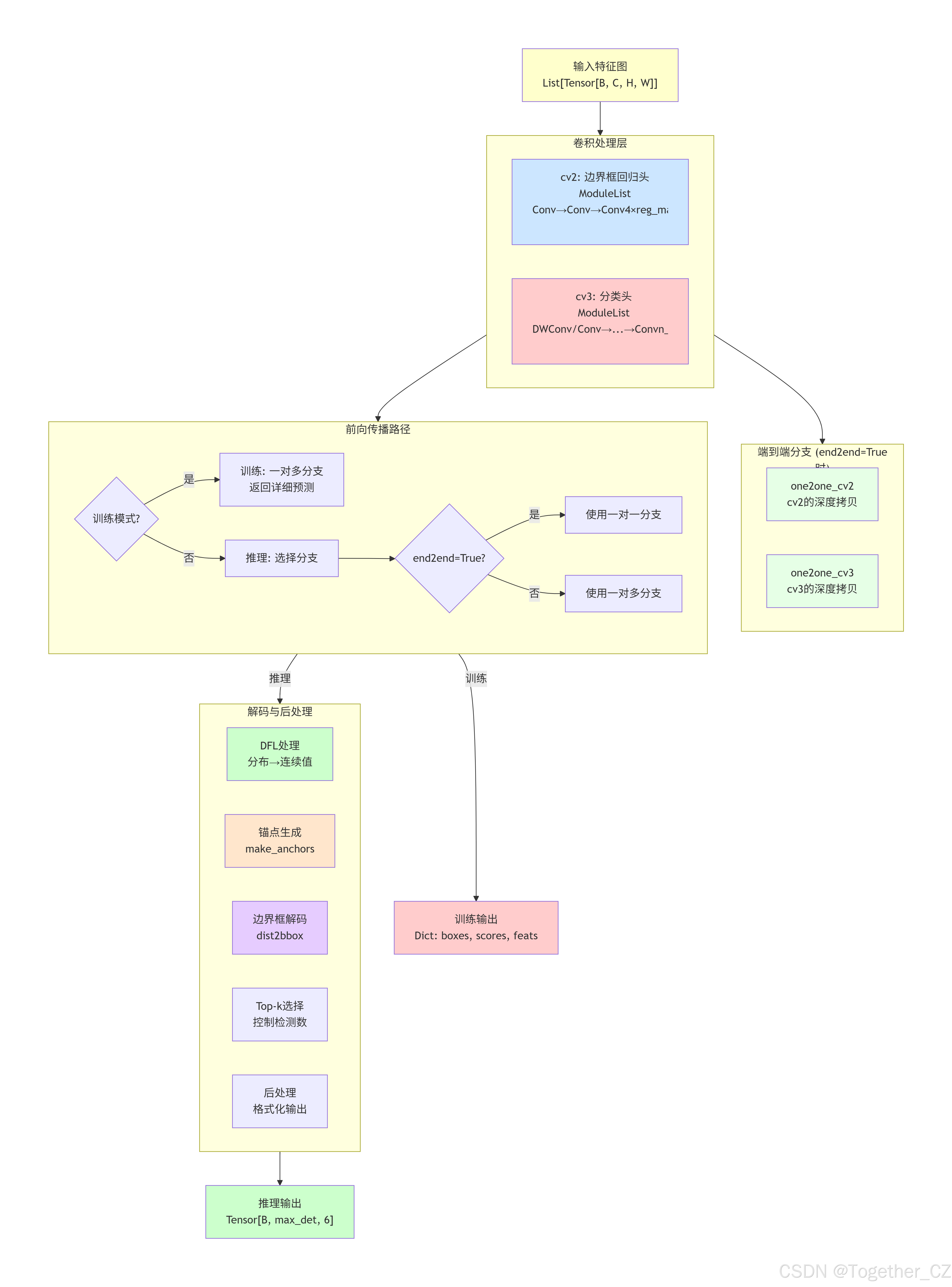
Detect类:YOLO检测头
Detect 类是YOLO检测系统的核心基础,实现了标准目标检测功能:
设计特点:
-
双分支架构:支持一对多(训练)和一对一(推理)双分支
-
DFL机制:使用Distribution Focal Loss进行边界框回归,提高精度
-
动态锚点:根据输入特征图动态生成锚点
-
多尺度处理:支持多层级特征图输入
核心组件:
-
cv2:边界框回归卷积头,输出4×reg_max个通道 -
cv3:分类卷积头,输出nc个类别通道 -
dfl:DFL层,将离散分布转换为连续坐标 -
one2one_cv2/cv3:端到端推理专用分支
工作流程:
-
训练阶段:使用一对多分支生成密集预测
-
推理阶段:根据end2end标志选择分支
-
解码过程:通过DFL和锚点将预测转换为实际边界框
Detect架构示意图如下所示:
python
class Detect(nn.Module):
"""
YOLO 检测头,用于目标检测模型。
该类实现 YOLO 模型中预测边界框和类别概率的检测头。支持训练与推理模式,并可选择端到端检测能力。
属性:
dynamic (bool):是否强制重建网格。
export (bool):导出模式标志。
format (str):导出格式。
end2end (bool):端到端检测模式。
max_det (int):每张图像最大检测数量。
shape (tuple):输入形状。
anchors (torch.Tensor):锚点。
strides (torch.Tensor):特征图步长。
legacy (bool):v3/v5/v8/v9 模型的向后兼容性。
xyxy (bool):输出格式,xyxy 或 xywh。
nc (int):类别数量。
nl (int):检测层数量。
reg_max (int):DFL 通道数。
no (int):每个锚点的输出数。
stride (torch.Tensor):构建时计算的步长。
cv2 (nn.ModuleList):边界框回归卷积层。
cv3 (nn.ModuleList):分类卷积层。
dfl (nn.Module):分布焦点损失层。
one2one_cv2 (nn.ModuleList):一对一边界框回归卷积层。
one2one_cv3 (nn.ModuleList):一对一分类卷积层。
方法:
forward:执行前向传播并返回预测结果。
forward_end2end:端到端检测的前向传播。
bias_init:初始化检测头偏置。
decode_bboxes:从预测解码边界框。
postprocess:后处理模型预测。
示例:
创建 80 类的检测头
detect = Detect(nc=80, ch=(256, 512, 1024))
x = [torch.randn(1, 256, 80, 80), torch.randn(1, 512, 40, 40), torch.randn(1, 1024, 20, 20)]
outputs = detect(x)
"""
dynamic = False # force grid reconstruction # 是否动态重建网格,默认False
export = False # export mode # 是否导出模式,默认False
format = None # export format # 导出格式,默认None
max_det = 300 # max_det # 最大检测数,默认300
shape = None # 输入形状,默认None
anchors = torch.empty(0) # init # 锚点,初始化为空张量
strides = torch.empty(0) # init # 步长,初始化为空张量
legacy = False # backward compatibility for v3/v5/v8/v9 models # 是否为旧版模型,默认False
xyxy = False # xyxy or xywh output # 输出格式是否为xyxy,默认False(使用xywh格式)
def __init__(self, nc: int = 80, reg_max=16, end2end=False, ch: tuple = ()):
"""
使用指定的类别数和通道数初始化 YOLO 检测层。
参数:
nc (int):类别数量。
reg_max (int):DFL 最大通道数。
end2end (bool):是否使用端到端无 NMS 检测。
ch (tuple):骨干网络特征图的通道大小元组。
"""
super().__init__() # 调用父类nn.Module的初始化方法
self.nc = nc # number of classes # 设置类别数量
self.nl = len(ch) # number of detection layers # 检测层数量等于输入特征图数量
self.reg_max = reg_max # DFL channels (ch[0] // 16 to scale 4/8/12/16/20 for n/s/m/l/x) # DFL通道数
self.no = nc + self.reg_max * 4 # number of outputs per anchor # 每个锚点的输出数量 = 类别数 + 4*reg_max
self.stride = torch.zeros(self.nl) # strides computed during build # 步长,在构建时计算,初始化为零
# 计算通道数:c2用于边界框回归,c3用于分类
c2, c3 = max((16, ch[0] // 4, self.reg_max * 4)), max(ch[0], min(self.nc, 100)) # channels
# 创建边界框回归卷积层列表
# 每个检测层包含:Conv -> Conv -> Conv(输出4*reg_max个通道)
self.cv2 = nn.ModuleList(
nn.Sequential(Conv(x, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for x in ch
)
# 创建分类卷积层列表
# 如果是旧版模型,使用简单的Conv结构
# 否则使用更复杂的DWConv结构
self.cv3 = (
nn.ModuleList(nn.Sequential(Conv(x, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, self.nc, 1)) for x in ch)
if self.legacy # 如果是旧版模型
else nn.ModuleList( # 否则使用新结构
nn.Sequential(
nn.Sequential(DWConv(x, x, 3), Conv(x, c3, 1)), # DWConv + Conv
nn.Sequential(DWConv(c3, c3, 3), Conv(c3, c3, 1)), # DWConv + Conv
nn.Conv2d(c3, self.nc, 1), # 1x1卷积输出类别数
)
for x in ch
)
)
# 创建DFL层(分布焦点损失层),如果reg_max>1则使用DFL,否则使用恒等映射
self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity()
# 如果使用端到端检测,创建一对一的检测头
if end2end:
self.one2one_cv2 = copy.deepcopy(self.cv2) # 深度复制边界框回归头
self.one2one_cv3 = copy.deepcopy(self.cv3) # 深度复制分类头
@property
def one2many(self):
"""
返回一对多检测头组件,用于 v5/v8/v9/11 的向后兼容
"""
# 返回一对多检测头组件,用于向后兼容
return dict(box_head=self.cv2, cls_head=self.cv3)
@property
def one2one(self):
"""
返回一对一检测头组件
"""
return dict(box_head=self.one2one_cv2, cls_head=self.one2one_cv3)
@property
def end2end(self):
"""
检查模型是否有一对一检测头(用于判断是否为端到端检测)
"""
return hasattr(self, "one2one") # 如果存在one2one属性,则返回True
def forward_head(
self, x: list[torch.Tensor], box_head: torch.nn.Module = None, cls_head: torch.nn.Module = None
) -> dict[str, torch.Tensor]:
"""
拼接并返回预测的边界框和类别概率"""
# 拼接并返回预测的边界框和类别概率
if box_head is None or cls_head is None: # for fused inference # 如果是融合推理模式
return dict() # 返回空字典
bs = x[0].shape[0] # batch size # 获取批量大小
# 处理每个检测层的边界框预测
# 1. 对每个特征图应用边界框回归头
# 2. 调整形状为(bs, 4*reg_max, -1)
# 3. 在最后一个维度上拼接所有检测层的输出
boxes = torch.cat([box_head[i](x[i]).view(bs, 4 * self.reg_max, -1) for i in range(self.nl)], dim=-1)
# 处理每个检测层的类别预测
# 1. 对每个特征图应用分类头
# 2. 调整形状为(bs, nc, -1)
# 3. 在最后一个维度上拼接所有检测层的输出
scores = torch.cat([cls_head[i](x[i]).view(bs, self.nc, -1) for i in range(self.nl)], dim=-1)
# 返回包含边界框、类别分数和特征的字典
return dict(boxes=boxes, scores=scores, feats=x)
def forward(
self, x: list[torch.Tensor]
) -> dict[str, torch.Tensor] | torch.Tensor | tuple[torch.Tensor, dict[str, torch.Tensor]]:
"""
拼接并返回预测的边界框和类别概率
"""
# 使用一对多检测头进行前向传播
preds = self.forward_head(x, **self.one2many)
# 如果是端到端检测模式
if self.end2end:
# 分离特征图以避免梯度传播
x_detach = [xi.detach() for xi in x]
# 使用一对一检测头进行前向传播
one2one = self.forward_head(x_detach, **self.one2one)
# 将两种预测结果合并
preds = {"one2many": preds, "one2one": one2one}
# 如果是训练模式,直接返回预测结果
if self.training:
return preds
# 推理模式:进行推理
# 如果是端到端检测,使用一对一预测结果,否则使用一对多预测结果
y = self._inference(preds["one2one"] if self.end2end else preds)
# 如果是端到端检测,进行后处理
if self.end2end:
y = self.postprocess(y.permute(0, 2, 1))
# 如果是导出模式,只返回推理结果,否则返回推理结果和预测结果
return y if self.export else (y, preds)
def _inference(self, x: dict[str, torch.Tensor]) -> torch.Tensor:
"""
基于多级特征图解码预测的边界框和类别概率。
参数:
x (dict[str, torch.Tensor]):来自不同检测层的特征图列表。
返回:
(torch.Tensor):解码后的边界框和类别概率的拼接张量。
"""
# Inference path # 推理路径
dbox = self._get_decode_boxes(x) # 获取解码后的边界框
return torch.cat((dbox, x["scores"].sigmoid()), 1) # 将边界框和sigmoid后的类别分数拼接在一起
def _get_decode_boxes(self, x: dict[str, torch.Tensor]) -> torch.Tensor:
"""
基于锚点和步长获取解码后的边界框
"""
shape = x["feats"][0].shape # BCHW # 获取特征图形状
# 如果需要动态重建网格或形状发生变化
if self.format != "imx" and (self.dynamic or self.shape != shape):
# 生成锚点和步长
self.anchors, self.strides = (a.transpose(0, 1) for a in make_anchors(x["feats"], self.stride, 0.5))
self.shape = shape # 更新形状
boxes = x["boxes"] # 获取边界框预测
# 针对特定导出格式的特殊处理
if self.export and self.format in {"tflite", "edgetpu"}:
# Precompute normalization factor to increase numerical stability
# 预计算归一化因子以提高数值稳定性
# See https://github.com/ultralytics/ultralytics/issues/7371
grid_h = shape[2] # 网格高度
grid_w = shape[3] # 网格宽度
grid_size = torch.tensor([grid_w, grid_h, grid_w, grid_h], device=boxes.device).reshape(1, 4, 1)
norm = self.strides / (self.stride[0] * grid_size) # 计算归一化因子
dbox = self.decode_bboxes(self.dfl(boxes) * norm, self.anchors.unsqueeze(0) * norm[:, :2])
else:
# 常规解码过程
dbox = self.decode_bboxes(self.dfl(boxes), self.anchors.unsqueeze(0)) * self.strides
return dbox # 返回解码后的边界框
def bias_init(self):
"""
初始化检测头的偏置,注意:需要步长信息可用
"""
# 遍历一对多检测头的边界框回归头和分类头
for i, (a, b) in enumerate(zip(self.one2many["box_head"], self.one2many["cls_head"])): # from
a[-1].bias.data[:] = 2.0 # box # 边界框回归头偏置初始化为2.0
# 分类头偏置初始化公式:log(5 / nc / (640 / stride[i])^2)
# 解释:基于经验公式初始化,考虑类别数、图像大小和特征图步长
b[-1].bias.data[: self.nc] = math.log(
5 / self.nc / (640 / self.stride[i]) ** 2
) # cls (.01 objects, 80 classes, 640 img)
# 如果是端到端检测,还需要初始化一对一检测头的偏置
if self.end2end:
for i, (a, b) in enumerate(zip(self.one2one["box_head"], self.one2one["cls_head"])): # from
a[-1].bias.data[:] = 2.0 # box # 边界框回归头偏置初始化为2.0
b[-1].bias.data[: self.nc] = math.log(
5 / self.nc / (640 / self.stride[i]) ** 2
) # cls (.01 objects, 80 classes, 640 img)
def decode_bboxes(self, bboxes: torch.Tensor, anchors: torch.Tensor, xywh: bool = True) -> torch.Tensor:
"""
从预测解码边界框
"""
# 使用dist2bbox函数将距离表示转换为边界框坐标
return dist2bbox(
bboxes,
anchors,
xywh=xywh and not self.end2end and not self.xyxy, # 确定输出格式
dim=1, # 在哪个维度上操作
)
def postprocess(self, preds: torch.Tensor) -> torch.Tensor:
"""
对 YOLO 模型预测结果进行后处理。
参数:
preds (torch.Tensor):原始预测,形状为 (batch_size, num_anchors, 4 + nc),最后一维格式为 [x, y, w, h, class_probs]。
返回:
(torch.Tensor):处理后的预测,形状为 (batch_size, min(max_det, num_anchors), 6),最后一维格式为 [x, y, w, h, max_class_prob, class_index]。
"""
# 将预测分割为边界框和类别分数
boxes, scores = preds.split([4, self.nc], dim=-1)
# 获取top-k索引
scores, conf, idx = self.get_topk_index(scores, self.max_det)
# 根据索引收集对应的边界框
boxes = boxes.gather(dim=1, index=idx.repeat(1, 1, 4))
# 拼接边界框、分数和置信度
return torch.cat([boxes, scores, conf], dim=-1)
def get_topk_index(self, scores: torch.Tensor, max_det: int) -> tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
"""
从分数中获取 Top-K 索引。
参数:
scores (torch.Tensor):分数张量,形状为 (batch_size, num_anchors, num_classes)。
max_det (int):每张图像最大检测数。
返回:
(torch.Tensor, torch.Tensor, torch.Tensor):最高分数、类别索引和过滤后的索引。
"""
batch_size, anchors, nc = scores.shape # i.e. shape(16,8400,84) # 获取形状信息
# 确定k值:导出模式下使用max_det,推理模式下使用min(max_det, anchors)
# 这是为了TensorRT兼容性(需要k为常量)和安全性
k = max_det if self.export else min(max_det, anchors)
# 获取每个锚点的最高分数,然后取top-k
ori_index = scores.max(dim=-1)[0].topk(k)[1].unsqueeze(-1)
# 根据索引收集分数
scores = scores.gather(dim=1, index=ori_index.repeat(1, 1, nc))
# 展平并获取top-k分数和索引
scores, index = scores.flatten(1).topk(k)
# 计算原始索引
idx = ori_index[torch.arange(batch_size)[..., None], index // nc] # original index
# 返回最高分数、类别索引(取模nc)和原始索引
return scores[..., None], (index % nc)[..., None].float(), idx
def fuse(self) -> None:
"""
移除一对多检测头以优化推理
"""
self.cv2 = self.cv3 = None # 将一对多检测头设置为NoneSegment类
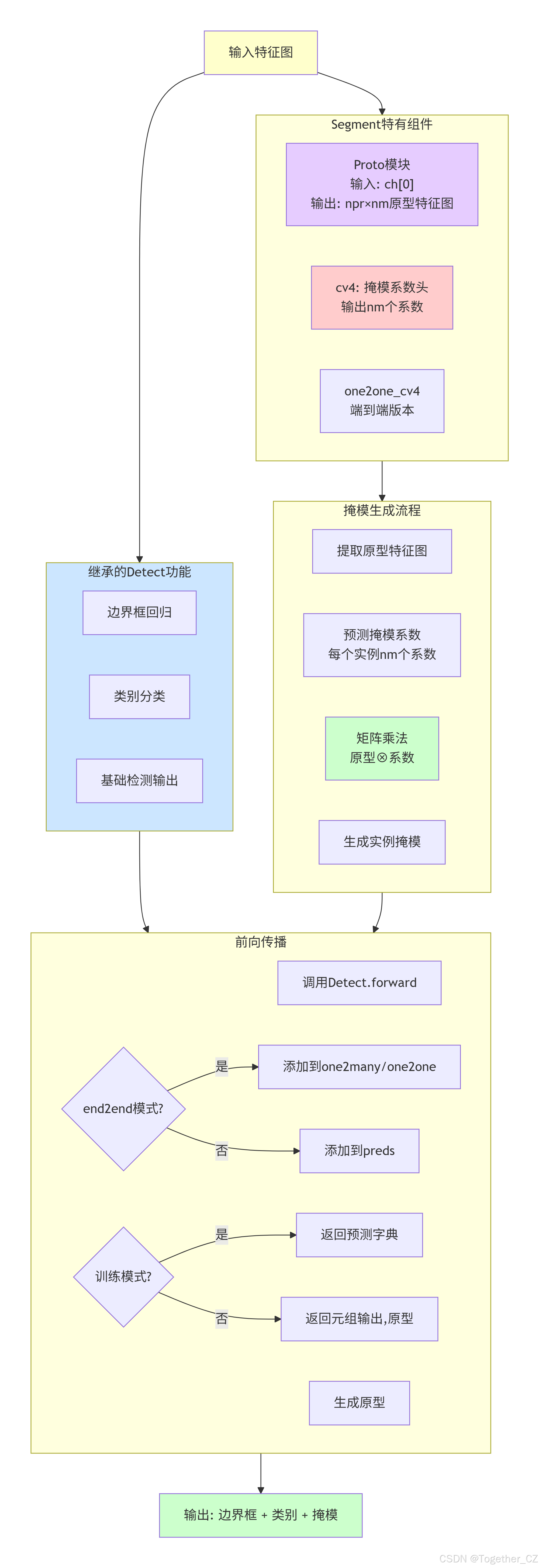
Segment 类在Detect基础上扩展了实例分割功能:
设计特点:
-
两阶段掩模生成:原型 + 系数的掩模生成方式
-
参数共享:所有实例共享同一组原型特征
-
高效计算:原型只需计算一次,与系数进行线性组合
核心组件:
-
proto:原型生成模块,生成k个原型特征图 -
cv4:掩模系数预测头,输出nm个系数通道 -
nm:掩模数量(原型通道数) -
npr:原型特征图数量
掩模生成流程:
最终掩模 = Σ(系数_i × 原型_i)其中系数是每个实例预测的,原型是所有实例共享的
Segment架构示意图如下所示:
python
class Segment(Detect):
"""
YOLO 分割头,用于分割模型。
该类继承自 Detect 检测头,增加了实例分割任务的掩模预测能力。
属性:
nm (int):掩模数量。
npr (int):原型数量。
proto (Proto):原型生成模块。
cv4 (nn.ModuleList):掩模系数卷积层。
方法:
forward:返回模型输出和掩模系数。
示例:
创建分割头
segment = Segment(nc=80, nm=32, npr=256, ch=(256, 512, 1024))
x = [torch.randn(1, 256, 80, 80), torch.randn(1, 512, 40, 40), torch.randn(1, 1024, 20, 20)]
outputs = segment(x)
"""
def __init__(self, nc: int = 80, nm: int = 32, npr: int = 256, reg_max=16, end2end=False, ch: tuple = ()):
"""
初始化 YOLO 模型属性,包括掩模数量、原型数量和卷积层。
参数:
nc (int):类别数量。
nm (int):掩模数量。
npr (int):原型数量。
reg_max (int):DFL 最大通道数。
end2end (bool):是否使用端到端无 NMS 检测。
ch (tuple):骨干网络特征图的通道大小元组。
"""
# 调用父类Detect的初始化方法
super().__init__(nc, reg_max, end2end, ch)
self.nm = nm # number of masks # 掩模数量
self.npr = npr # number of protos # 原型数量
# 创建原型生成模块,输入通道为ch[0],输出原型数为npr,掩模数为nm
self.proto = Proto(ch[0], self.npr, self.nm) # protos
# 计算掩模系数头的通道数
c4 = max(ch[0] // 4, self.nm)
# 创建掩模系数卷积层列表
# 每个检测层包含:Conv -> Conv -> Conv(输出nm个通道)
self.cv4 = nn.ModuleList(nn.Sequential(Conv(x, c4, 3), Conv(c4, c4, 3), nn.Conv2d(c4, self.nm, 1)) for x in ch)
# 如果是端到端检测,创建一对一掩模系数头
if end2end:
self.one2one_cv4 = copy.deepcopy(self.cv4)
@property
def one2many(self):
"""
返回一对多头部组件,用于向后兼容
"""
# 包含边界框回归头、分类头和掩模系数头
return dict(box_head=self.cv2, cls_head=self.cv3, mask_head=self.cv4)
@property
def one2one(self):
"""
返回一对一头部组件
"""
# 包含边界框回归头、分类头和掩模系数头
return dict(box_head=self.one2one_cv2, cls_head=self.one2one_cv3, mask_head=self.one2one_cv4)
def forward(self, x: list[torch.Tensor]) -> tuple | list[torch.Tensor] | dict[str, torch.Tensor]:
"""
如果是训练模式,返回模型输出和掩模系数;否则返回输出和掩模系数
"""
#
# 调用父类的forward方法获取检测输出
outputs = super().forward(x)
# 如果是元组,取第二个元素(预测结果),否则直接使用输出
preds = outputs[1] if isinstance(outputs, tuple) else outputs
# 生成掩模原型,使用第一个特征图
proto = self.proto(x[0]) # mask protos
# 如果是字典(训练和验证时)
if isinstance(preds, dict): # training and validating during training
if self.end2end: # 如果是端到端检测
# 将原型添加到一对多和一对一预测中
preds["one2many"]["proto"] = proto
preds["one2one"]["proto"] = proto.detach()
else:
preds["proto"] = proto # 将原型添加到预测中
# 如果是训练模式,返回预测结果
if self.training:
return preds
# 推理模式:如果是导出模式,返回输出和原型;否则返回元组
return (outputs, proto) if self.export else ((outputs[0], proto), preds)
def _inference(self, x: dict[str, torch.Tensor]) -> torch.Tensor:
"""
解码预测的边界框和类别概率,并与掩模系数拼接
"""
# 调用父类的_inference方法获取检测预测
preds = super()._inference(x)
# 将检测预测与掩模系数拼接
return torch.cat([preds, x["mask_coefficient"]], dim=1)
def forward_head(
self, x: list[torch.Tensor], box_head: torch.nn.Module, cls_head: torch.nn.Module, mask_head: torch.nn.Module
) -> torch.Tensor:
"""
拼接并返回预测的边界框、类别概率和掩模系数
"""
# 调用父类的forward_head方法获取边界框和类别预测
preds = super().forward_head(x, box_head, cls_head)
# 如果存在掩模系数头
if mask_head is not None:
bs = x[0].shape[0] # batch size # 获取批量大小
# 处理每个检测层的掩模系数预测
# 1. 对每个特征图应用掩模系数头
# 2. 调整形状为(bs, nm, -1)
# 3. 在最后一个维度上拼接所有检测层的输出
preds["mask_coefficient"] = torch.cat([mask_head[i](x[i]).view(bs, self.nm, -1) for i in range(self.nl)], 2)
return preds # 返回预测结果
def postprocess(self, preds: torch.Tensor) -> torch.Tensor:
"""
对 YOLO 模型预测结果进行后处理。
参数:
preds (torch.Tensor):原始预测,形状为 (batch_size, num_anchors, 4 + nc + nm),最后一维格式为 [x, y, w, h, class_probs, mask_coefficient]。
返回:
(torch.Tensor):处理后的预测,形状为 (batch_size, min(max_det, num_anchors), 6 + nm),最后一维格式为 [x, y, w, h, max_class_prob, class_index, mask_coefficient]。
"""
# 将预测分割为边界框、类别分数和掩模系数
boxes, scores, mask_coefficient = preds.split([4, self.nc, self.nm], dim=-1)
# 获取top-k索引
scores, conf, idx = self.get_topk_index(scores, self.max_det)
# 根据索引收集对应的边界框
boxes = boxes.gather(dim=1, index=idx.repeat(1, 1, 4))
# 根据索引收集对应的掩模系数
mask_coefficient = mask_coefficient.gather(dim=1, index=idx.repeat(1, 1, self.nm))
# 拼接边界框、分数、置信度和掩模系数
return torch.cat([boxes, scores, conf, mask_coefficient], dim=-1)
def fuse(self) -> None:
"""
移除一对多检测头以优化推理
"""
# 将一对多检测头设置为None
self.cv2 = self.cv3 = self.cv4 = NoneSegment26 类 - 改进版分割头
Segment26 是Segment的改进版本,主要区别在于:
改进点:
-
原型生成器不同:使用Proto26替代Proto
-
多尺度特征利用:Proto26使用所有特征图,而Proto只使用第一个特征图
-
分离特征处理:在forward中分离特征以避免梯度传播问题
Proto26特点:
-
输入:所有特征图列表
-
输出:更丰富的原型表示
-
支持语义分割(return_semseg参数)
前向传播差异:
# Segment: 直接调用父类forward
# Segment26: 调用Detect.forward(避免Segment的额外处理)
proto = self.proto([xi.detach() for xi in x], return_semseg=False)架构示意图如下所示:

python
class Segment26(Segment):
"""
YOLO26 分割头,用于分割模型。
该类继承自 Detect 检测头,增加了实例分割任务的掩模预测能力。
属性:
nm (int):掩模数量。
npr (int):原型数量。
proto (Proto):原型生成模块。
cv4 (nn.ModuleList):掩模系数卷积层。
方法:
forward:返回模型输出和掩模系数。
示例:
创建分割头
segment = Segment26(nc=80, nm=32, npr=256, ch=(256, 512, 1024))
x = [torch.randn(1, 256, 80, 80), torch.randn(1, 512, 40, 40), torch.randn(1, 1024, 20, 20)]
outputs = segment(x)
"""
def __init__(self, nc: int = 80, nm: int = 32, npr: int = 256, reg_max=16, end2end=False, ch: tuple = ()):
"""
初始化 YOLO 模型属性,包括掩模数量、原型数量和卷积层。
参数:
nc (int):类别数量。
nm (int):掩模数量。
npr (int):原型数量。
reg_max (int):DFL 最大通道数。
end2end (bool):是否使用端到端无 NMS 检测。
ch (tuple):骨干网络特征图的通道大小元组。
"""
# 调用父类Segment的初始化方法
super().__init__(nc, nm, npr, reg_max, end2end, ch)
# 使用Proto26原型生成模块,与Segment类不同
self.proto = Proto26(ch, self.npr, self.nm, nc) # protos
def forward(self, x: list[torch.Tensor]) -> tuple | list[torch.Tensor] | dict[str, torch.Tensor]:
"""
如果是训练模式,返回模型输出和掩模系数;否则返回输出和掩模系数
"""
# 直接调用Detect的forward方法,而不是Segment的forward方法
outputs = Detect.forward(self, x)
# 如果是元组,取第二个元素(预测结果),否则直接使用输出
preds = outputs[1] if isinstance(outputs, tuple) else outputs
# 生成掩模原型,使用所有特征图
proto = self.proto(x) # mask protos
# 如果是字典(训练和验证时)
if isinstance(preds, dict): # training and validating during training
if self.end2end: # 如果是端到端检测
# 将原型添加到一对多和一对一预测中
preds["one2many"]["proto"] = proto
# 如果原型是元组,则分离每个元素;否则直接分离
preds["one2one"]["proto"] = (
tuple(p.detach() for p in proto) if isinstance(proto, tuple) else proto.detach()
)
else:
preds["proto"] = proto # 将原型添加到预测中
# 如果是训练模式,返回预测结果
if self.training:
return preds
# 推理模式:如果是导出模式,返回输出和原型;否则返回元组
return (outputs, proto) if self.export else ((outputs[0], proto), preds)
def fuse(self) -> None:
"""
移除一对多检测头和原型模块的额外部分以优化推理
"""
# 调用父类的fuse方法
super().fuse()
# 如果原型模块有fuse方法,则调用它
if hasattr(self.proto, "fuse"):
self.proto.fuse()OBB 类 - 旋转目标检测头
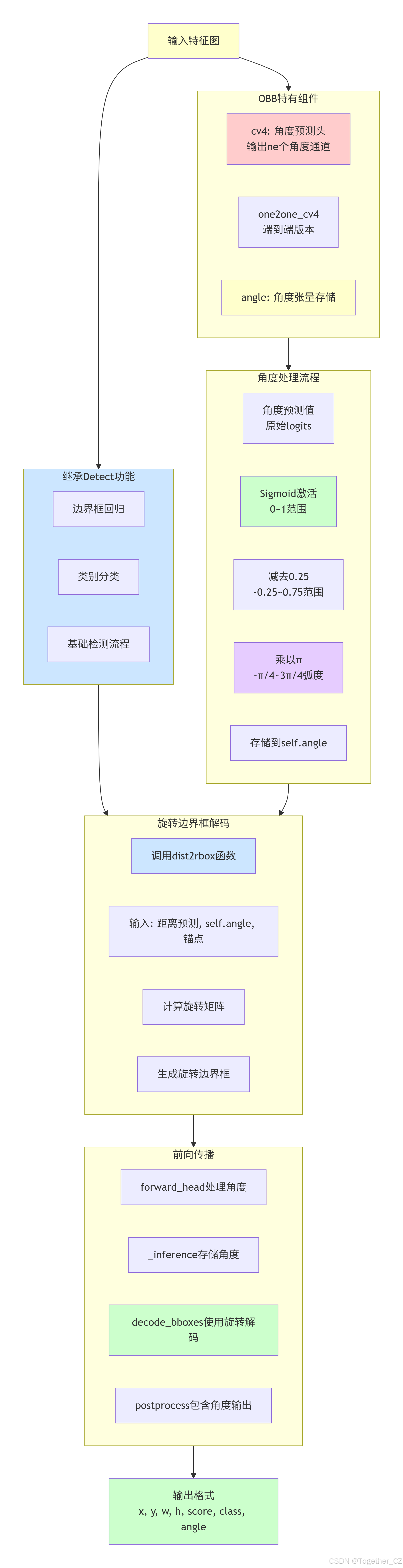
OBB(Oriented Bounding Box)类扩展Detect以实现旋转目标检测:
设计特点:
-
角度预测:增加角度预测头,输出旋转角度
-
角度表示:将角度范围-π/4, 3π/4映射到sigmoid输出
-
旋转边界框解码:使用dist2rbox函数解码旋转框
核心组件:
-
ne:额外参数数量(通常为1,表示角度) -
cv4:角度预测头 -
angle:存储预测的角度张量
角度处理公式:
angle = (sigmoid(output) - 0.25) * π将sigmoid的0,1映射到-π/4, 3π/4
解码过程:
使用dist2rbox函数,结合预测的距离、角度和锚点生成旋转边界框
整体架构示意图如下所示:
python
class OBB(Detect):
"""
YOLO OBB 检测头,用于带旋转角度的目标检测模型。
该类继承自 Detect 检测头,增加了带旋转角度的定向边界框预测能力。
属性:
ne (int):额外参数数量(角度参数)。
cv4 (nn.ModuleList):角度预测卷积层。
angle (torch.Tensor):预测的旋转角度。
方法:
forward:拼接并返回预测的边界框和类别概率。
decode_bboxes:解码旋转边界框。
示例:
创建 OBB 检测头
obb = OBB(nc=80, ne=1, ch=(256, 512, 1024))
x = [torch.randn(1, 256, 80, 80), torch.randn(1, 512, 40, 40), torch.randn(1, 1024, 20, 20)]
outputs = obb(x)
"""
def __init__(self, nc: int = 80, ne: int = 1, reg_max=16, end2end=False, ch: tuple = ()):
"""
使用类别数 nc 和层通道 ch 初始化 OBB。
参数:
nc (int):类别数量。
ne (int):额外参数数量(角度参数)。
reg_max (int):DFL 最大通道数。
end2end (bool):是否使用端到端无 NMS 检测。
ch (tuple):骨干网络特征图的通道大小元组。
"""
# 调用父类Detect的初始化方法
super().__init__(nc, reg_max, end2end, ch)
self.ne = ne # number of extra parameters # 额外参数数量(角度参数)
# 计算角度预测头的通道数
c4 = max(ch[0] // 4, self.ne)
# 创建角度预测卷积层列表
# 每个检测层包含:Conv -> Conv -> Conv(输出ne个通道)
self.cv4 = nn.ModuleList(nn.Sequential(Conv(x, c4, 3), Conv(c4, c4, 3), nn.Conv2d(c4, self.ne, 1)) for x in ch)
# 如果是端到端检测,创建一对一角度预测头
if end2end:
self.one2one_cv4 = copy.deepcopy(self.cv4)
@property
def one2many(self):
"""
返回一对多头部组件,用于向后兼容
"""
# 包含边界框回归头、分类头和角度预测头
return dict(box_head=self.cv2, cls_head=self.cv3, angle_head=self.cv4)
@property
def one2one(self):
"""
返回一对一头部组件
"""
# 包含边界框回归头、分类头和角度预测头
return dict(box_head=self.one2one_cv2, cls_head=self.one2one_cv3, angle_head=self.one2one_cv4)
def _inference(self, x: dict[str, torch.Tensor]) -> torch.Tensor:
"""
解码预测的边界框和类别概率,并与旋转角度拼接
"""
# 为了decode_bboxes的方便,将角度存储为实例属性
self.angle = x["angle"] # TODO: need to test obb # 存储角度预测
# 调用父类的_inference方法获取检测预测
preds = super()._inference(x)
# 将检测预测与角度拼接
return torch.cat([preds, x["angle"]], dim=1)
def forward_head(
self, x: list[torch.Tensor], box_head: torch.nn.Module, cls_head: torch.nn.Module, angle_head: torch.nn.Module
) -> torch.Tensor:
"""
拼接并返回预测的边界框、类别概率和角度
"""
# 调用父类的forward_head方法获取边界框和类别预测
preds = super().forward_head(x, box_head, cls_head)
# 如果存在角度预测头
if angle_head is not None:
bs = x[0].shape[0] # batch size # 获取批量大小
# 处理每个检测层的角度预测
# 1. 对每个特征图应用角度预测头
# 2. 调整形状为(bs, ne, -1)
# 3. 在最后一个维度上拼接所有检测层的输出
angle = torch.cat(
[angle_head[i](x[i]).view(bs, self.ne, -1) for i in range(self.nl)], 2
) # OBB theta logits # OBB角度logits
# 将角度从sigmoid输出转换为弧度:[-pi/4, 3pi/4]
# sigmoid输出范围[0,1],减去0.25后范围[-0.25,0.75],乘以pi后范围[-pi/4, 3pi/4]
angle = (angle.sigmoid() - 0.25) * math.pi # [-pi/4, 3pi/4]
preds["angle"] = angle # 将角度添加到预测结果中
return preds # 返回预测结果
def decode_bboxes(self, bboxes: torch.Tensor, anchors: torch.Tensor) -> torch.Tensor:
"""
解码旋转边界框
"""
# 使用dist2rbox函数将距离表示转换为旋转边界框坐标
return dist2rbox(bboxes, self.angle, anchors, dim=1)
def postprocess(self, preds: torch.Tensor) -> torch.Tensor:
"""
对 YOLO 模型预测结果进行后处理。
参数:
preds (torch.Tensor):原始预测,形状为 (batch_size, num_anchors, 4 + nc + ne),最后一维格式为 [x, y, w, h, class_probs, angle]。
返回:
(torch.Tensor):处理后的预测,形状为 (batch_size, min(max_det, num_anchors), 7),最后一维格式为 [x, y, w, h, max_class_prob, class_index, angle]。
"""
# 将预测分割为边界框、类别分数和角度
boxes, scores, angle = preds.split([4, self.nc, self.ne], dim=-1)
# 获取top-k索引
scores, conf, idx = self.get_topk_index(scores, self.max_det)
# 根据索引收集对应的边界框
boxes = boxes.gather(dim=1, index=idx.repeat(1, 1, 4))
# 根据索引收集对应的角度
angle = angle.gather(dim=1, index=idx.repeat(1, 1, self.ne))
# 拼接边界框、分数、置信度和角度
return torch.cat([boxes, scores, conf, angle], dim=-1)
def fuse(self) -> None:
"""
移除一对多检测头以优化推理
"""
# 将一对多检测头设置为None
self.cv2 = self.cv3 = self.cv4 = NoneBB26 类 - 改进版旋转检测头
OBB26 是OBB的改进版本,主要区别在于:
关键改进:
-
原始角度输出:不应用sigmoid激活,直接输出原始角度值
-
简化前向传播:直接调用Detect.forward_head,避免OBB的角度转换
-
更灵活的角度表示:将角度转换移至损失函数或后处理阶段
角度处理差异:
# OBB: 在forward_head中转换角度
angle = (angle.sigmoid() - 0.25) * math.pi
# OBB26: 直接存储原始logits
preds["angle"] = angle # 原始输出设计优势:
-
灵活性:允许在训练中使用不同的角度损失函数
-
数值稳定性:避免sigmoid的饱和区问题
-
扩展性:更容易支持其他角度表示方法
整体架构示意图如下所示:
python
class OBB26(OBB):
"""
YOLO26 OBB 检测头,用于带旋转角度的目标检测模型。该类继承自 OBB 检测头,对角度处理进行了修改:直接输出原始角度预测,而不经过 Sigmoid 变换。
属性:
ne (int):额外参数数量(角度参数)。
cv4 (nn.ModuleList):角度预测卷积层。
angle (torch.Tensor):预测的旋转角度。
方法:
forward_head:拼接并返回预测的边界框、类别概率和原始角度。
示例:
创建 OBB26 检测头
obb26 = OBB26(nc=80, ne=1, ch=(256, 512, 1024))
x = [torch.randn(1, 256, 80, 80), torch.randn(1, 512, 40, 40), torch.randn(1, 1024, 20, 20)]
outputs = obb26(x)
"""
def forward_head(
self, x: list[torch.Tensor], box_head: torch.nn.Module, cls_head: torch.nn.Module, angle_head: torch.nn.Module
) -> torch.Tensor:
"""
拼接并返回预测的边界框、类别概率和原始角度
"""
# 直接调用Detect的forward_head方法,而不是OBB的forward_head方法
preds = Detect.forward_head(self, x, box_head, cls_head)
# 如果存在角度预测头
if angle_head is not None:
bs = x[0].shape[0] # batch size # 获取批量大小
# 处理每个检测层的角度预测
# 1. 对每个特征图应用角度预测头
# 2. 调整形状为(bs, ne, -1)
# 3. 在最后一个维度上拼接所有检测层的输出
angle = torch.cat(
[angle_head[i](x[i]).view(bs, self.ne, -1) for i in range(self.nl)], 2
) # OBB theta logits (raw output without sigmoid transformation) # OBB角度logits(原始输出,不经过sigmoid变换)
preds["angle"] = angle # 将原始角度添加到预测结果中
return preds # 返回预测结果Pose 类 - 姿态估计头
Pose 类在Detect基础上扩展了人体姿态估计功能:
设计特点:
-
关键点预测:增加关键点预测头,输出nk个关键点值
-
多维表示:支持2D(x,y)或3D(x,y,可见性)关键点
-
关键点解码:将预测值转换为实际图像坐标
核心组件:
-
kpt_shape:关键点形状(数量, 维度) -
nk:关键点值总数 = 数量 × 维度 -
cv4:关键点预测头
关键点表示:
-
2D关键点:
[x0, y0, x1, y1, ...] -
3D关键点:
[x0, y0, v0, x1, y1, v1, ...],v为可见性分数
解码公式:
x = (pred_x * 2.0 + (anchor_x - 0.5)) * stride
y = (pred_y * 2.0 + (anchor_y - 0.5)) * stride
可见性 = sigmoid(pred_v)特殊处理:
-
MacOS14 MPS兼容性:避免原地sigmoid操作
-
导出格式优化:针对TFLite/EdgeTPU的特殊处理
整体架构示意图如下所示:
python
class Pose(Detect):
"""
YOLO 姿态估计头,用于关键点检测模型。
该类继承自 Detect 检测头,增加了姿态估计任务的关键点预测能力。
属性:
kpt_shape (tuple):关键点数量和维度(2 表示 x,y;3 表示 x,y,visible)。
nk (int):关键点值的总数。
cv4 (nn.ModuleList):关键点预测卷积层。
方法:
forward:执行 YOLO 模型前向传播并返回预测结果。
kpts_decode:从预测结果解码关键点。
示例:
创建姿态估计检测头
pose = Pose(nc=80, kpt_shape=(17, 3), ch=(256, 512, 1024))
x = [torch.randn(1, 256, 80, 80), torch.randn(1, 512, 40, 40), torch.randn(1, 1024, 20, 20)]
outputs = pose(x)
"""
def __init__(self, nc: int = 80, kpt_shape: tuple = (17, 3), reg_max=16, end2end=False, ch: tuple = ()):
"""
使用默认参数和卷积层初始化 YOLO 网络。
参数:
nc (int):类别数量。
kpt_shape (tuple):关键点数量和维度(2 表示 x,y;3 表示 x,y,visible)。
reg_max (int):DFL 最大通道数。
end2end (bool):是否使用端到端无 NMS 检测。
ch (tuple):骨干网络特征图的通道大小元组。
"""
# 调用父类Detect的初始化方法
super().__init__(nc, reg_max, end2end, ch)
self.kpt_shape = kpt_shape # number of keypoints, number of dims (2 for x,y or 3 for x,y,visible) # 关键点形状
self.nk = kpt_shape[0] * kpt_shape[1] # number of keypoints total # 关键点值总数
# 计算关键点预测头的通道数
c4 = max(ch[0] // 4, self.nk)
# 创建关键点预测卷积层列表
# 每个检测层包含:Conv -> Conv -> Conv(输出nk个通道)
self.cv4 = nn.ModuleList(nn.Sequential(Conv(x, c4, 3), Conv(c4, c4, 3), nn.Conv2d(c4, self.nk, 1)) for x in ch)
# 如果是端到端检测,创建一对一关键点预测头
if end2end:
self.one2one_cv4 = copy.deepcopy(self.cv4)
@property
def one2many(self):
"""
返回一对多头部组件,用于向后兼容
"""
# 包含边界框回归头、分类头和姿态预测头
return dict(box_head=self.cv2, cls_head=self.cv3, pose_head=self.cv4)
@property
def one2one(self):
"""
返回一对一头部组件
"""
# 包含边界框回归头、分类头和姿态预测头
return dict(box_head=self.one2one_cv2, cls_head=self.one2one_cv3, pose_head=self.one2one_cv4)
def _inference(self, x: dict[str, torch.Tensor]) -> torch.Tensor:
"""
解码预测的边界框和类别概率,并与关键点拼接
"""
# 调用父类的_inference方法获取检测预测
preds = super()._inference(x)
# 将检测预测与解码后的关键点拼接
return torch.cat([preds, self.kpts_decode(x["kpts"])], dim=1)
def forward_head(
self, x: list[torch.Tensor], box_head: torch.nn.Module, cls_head: torch.nn.Module, pose_head: torch.nn.Module
) -> torch.Tensor:
"""
拼接并返回预测的边界框、类别概率和关键点"""
# 调用父类的forward_head方法获取边界框和类别预测
preds = super().forward_head(x, box_head, cls_head)
# 如果存在姿态预测头
if pose_head is not None:
bs = x[0].shape[0] # batch size # 获取批量大小
# 处理每个检测层的关键点预测
# 1. 对每个特征图应用姿态预测头
# 2. 调整形状为(bs, nk, -1)
# 3. 在最后一个维度上拼接所有检测层的输出
preds["kpts"] = torch.cat([pose_head[i](x[i]).view(bs, self.nk, -1) for i in range(self.nl)], 2)
return preds # 返回预测结果
def postprocess(self, preds: torch.Tensor) -> torch.Tensor:
"""
对 YOLO 模型预测结果进行后处理。
参数:
preds (torch.Tensor):原始预测,形状为 (batch_size, num_anchors, 4 + nc + nk),最后一维格式为 [x, y, w, h, class_probs, keypoints]。
返回:
(torch.Tensor):处理后的预测,形状为 (batch_size, min(max_det, num_anchors), 6 + self.nk),最后一维格式为 [x, y, w, h, max_class_prob, class_index, keypoints]。
"""
# 将预测分割为边界框、类别分数和关键点
boxes, scores, kpts = preds.split([4, self.nc, self.nk], dim=-1)
# 获取top-k索引
scores, conf, idx = self.get_topk_index(scores, self.max_det)
# 根据索引收集对应的边界框
boxes = boxes.gather(dim=1, index=idx.repeat(1, 1, 4))
# 根据索引收集对应的关键点
kpts = kpts.gather(dim=1, index=idx.repeat(1, 1, self.nk))
# 拼接边界框、分数、置信度和关键点
return torch.cat([boxes, scores, conf, kpts], dim=-1)
def fuse(self) -> None:
"""
移除一对多检测头以优化推理
"""
# 将一对多检测头设置为None
self.cv2 = self.cv3 = self.cv4 = None
def kpts_decode(self, kpts: torch.Tensor) -> torch.Tensor:
"""
从预测解码关键点
"""
ndim = self.kpt_shape[1] # 关键点维度(2或3)
bs = kpts.shape[0] # 批量大小
# 如果是导出模式
if self.export:
# 调整形状为(bs, 关键点数量, 维度, -1)
y = kpts.view(bs, *self.kpt_shape, -1)
# 针对特定导出格式的特殊处理
if self.format in {"tflite", "edgetpu"}:
# 预计算归一化因子以提高数值稳定性
grid_h, grid_w = self.shape[2], self.shape[3] # 网格高度和宽度
grid_size = torch.tensor([grid_w, grid_h], device=y.device).reshape(1, 2, 1)
norm = self.strides / (self.stride[0] * grid_size) # 计算归一化因子
# 解码关键点坐标
a = (y[:, :, :2] * 2.0 + (self.anchors - 0.5)) * norm
else:
# 常规解码
a = (y[:, :, :2] * 2.0 + (self.anchors - 0.5)) * self.strides
# 如果有关键点可见性维度,添加sigmoid处理后的可见性分数
if ndim == 3:
a = torch.cat((a, y[:, :, 2:3].sigmoid()), 2)
# 调整形状为(bs, nk, -1)
return a.view(bs, self.nk, -1)
else:
# 非导出模式
y = kpts.clone() # 复制关键点预测
# 如果有关键点可见性维度,对可见性分数应用sigmoid
if ndim == 3:
if NOT_MACOS14: # 如果不是MacOS14
y[:, 2::ndim].sigmoid_() # 原地sigmoid
else: # Apple macOS14 MPS bug https://github.com/ultralytics/ultralytics/pull/21878
y[:, 2::ndim] = y[:, 2::ndim].sigmoid() # 避免MPS bug
# 解码x坐标:(预测值*2 + (锚点x-0.5)) * 步长
y[:, 0::ndim] = (y[:, 0::ndim] * 2.0 + (self.anchors[0] - 0.5)) * self.strides
# 解码y坐标:(预测值*2 + (锚点y-0.5)) * 步长
y[:, 1::ndim] = (y[:, 1::ndim] * 2.0 + (self.anchors[1] - 0.5)) * self.strides
return y # 返回解码后的关键点
Pose26 类 - 改进版姿态估计头
Pose26 是Pose的增强版本,主要改进包括:
核心增强:
-
不确定性估计:增加关键点不确定性预测(sigma_x, sigma_y)
-
流模型集成:集成RealNVP模型用于概率建模
-
改进的解码公式:使用不同的坐标解码方式
新增组件:
-
flow_model:RealNVP流模型 -
cv4_kpts:关键点预测头(分离) -
cv4_sigma:不确定性预测头 -
nk_sigma:不确定性参数数量 = 关键点数 × 2
解码公式差异:
# Pose: x = (pred * 2.0 + (anchor - 0.5)) * stride
# Pose26: x = (pred + anchor) * stride # 简化公式不确定性预测:
-
每个关键点预测两个不确定性值(x方向、y方向)
-
仅在训练阶段使用,推理时可选择性地使用
设计优势:
-
更准确的定位:不确定性估计提高关键点精度
-
概率建模:流模型支持概率分布学习
-
鲁棒性:对遮挡和模糊关键点处理更好
整体架构示意图如下所示:

python
class Pose26(Pose):
"""
YOLO26 姿态估计头,用于关键点检测模型。
该类继承自 Detect 检测头,增加了姿态估计任务的关键点预测能力。
属性:
kpt_shape (tuple):关键点数量和维度(2 表示 x,y;3 表示 x,y,visible)。
nk (int):关键点值的总数。
cv4 (nn.ModuleList):关键点预测卷积层。
方法:
forward:执行 YOLO 模型前向传播并返回预测结果。
kpts_decode:从预测结果解码关键点。
示例:
创建姿态估计检测头
pose = Pose(nc=80, kpt_shape=(17, 3), ch=(256, 512, 1024))
x = [torch.randn(1, 256, 80, 80), torch.randn(1, 512, 40, 40), torch.randn(1, 1024, 20, 20)]
outputs = pose(x)
"""
def __init__(self, nc: int = 80, kpt_shape: tuple = (17, 3), reg_max=16, end2end=False, ch: tuple = ()):
"""
使用默认参数和卷积层初始化 YOLO 网络。
参数:
nc (int):类别数量。
kpt_shape (tuple):关键点数量和维度(2 表示 x,y;3 表示 x,y,visible)。
reg_max (int):DFL 最大通道数。
end2end (bool):是否使用端到端无 NMS 检测。
ch (tuple):骨干网络特征图的通道大小元组。
"""
# 调用父类Pose的初始化方法
super().__init__(nc, kpt_shape, reg_max, end2end, ch)
# 添加流模型用于不确定性估计
self.flow_model = RealNVP()
# 计算关键点预测头的通道数
c4 = max(ch[0] // 4, kpt_shape[0] * (kpt_shape[1] + 2))
# 创建关键点特征提取卷积层列表
# 每个检测层包含:Conv -> Conv
self.cv4 = nn.ModuleList(nn.Sequential(Conv(x, c4, 3), Conv(c4, c4, 3)) for x in ch)
# 创建关键点预测头
self.cv4_kpts = nn.ModuleList(nn.Conv2d(c4, self.nk, 1) for _ in ch)
# 计算不确定性参数数量:每个关键点有两个sigma值(x和y方向的不确定性)
self.nk_sigma = kpt_shape[0] * 2 # sigma_x, sigma_y for each keypoint
# 创建不确定性预测头
self.cv4_sigma = nn.ModuleList(nn.Conv2d(c4, self.nk_sigma, 1) for _ in ch)
# 如果是端到端检测,创建一对一版本的各个头
if end2end:
self.one2one_cv4 = copy.deepcopy(self.cv4)
self.one2one_cv4_kpts = copy.deepcopy(self.cv4_kpts)
self.one2one_cv4_sigma = copy.deepcopy(self.cv4_sigma)
@property
def one2many(self):
"""
返回一对多头部组件,用于向后兼容
"""
# 包含边界框回归头、分类头、姿态特征头、关键点头和不确定性头
return dict(
box_head=self.cv2,
cls_head=self.cv3,
pose_head=self.cv4,
kpts_head=self.cv4_kpts,
kpts_sigma_head=self.cv4_sigma,
)
@property
def one2one(self):
"""
返回一对一头部组件
"""
# 包含边界框回归头、分类头、姿态特征头、关键点头和不确定性头
return dict(
box_head=self.one2one_cv2,
cls_head=self.one2one_cv3,
pose_head=self.one2one_cv4,
kpts_head=self.one2one_cv4_kpts,
kpts_sigma_head=self.one2one_cv4_sigma,
)
def forward_head(
self,
x: list[torch.Tensor],
box_head: torch.nn.Module,
cls_head: torch.nn.Module,
pose_head: torch.nn.Module,
kpts_head: torch.nn.Module,
kpts_sigma_head: torch.nn.Module,
) -> torch.Tensor:
"""
拼接并返回预测的边界框、类别概率和关键点
"""
# 直接调用Detect的forward_head方法获取边界框和类别预测
preds = Detect.forward_head(self, x, box_head, cls_head)
# 如果存在姿态预测头
if pose_head is not None:
bs = x[0].shape[0] # batch size # 获取批量大小
# 提取关键点特征
features = [pose_head[i](x[i]) for i in range(self.nl)]
# 处理关键点预测
preds["kpts"] = torch.cat([kpts_head[i](features[i]).view(bs, self.nk, -1) for i in range(self.nl)], 2)
# 如果是训练模式,处理不确定性预测
if self.training:
preds["kpts_sigma"] = torch.cat(
[kpts_sigma_head[i](features[i]).view(bs, self.nk_sigma, -1) for i in range(self.nl)], 2
)
return preds # 返回预测结果
def fuse(self) -> None:
"""
移除一对多检测头以优化推理
"""
# 调用父类的fuse方法
super().fuse()
# 将其他头设置为None
self.cv4_kpts = self.cv4_sigma = self.flow_model = self.one2one_cv4_sigma = None
def kpts_decode(self, kpts: torch.Tensor) -> torch.Tensor:
"""
从预测解码关键点
"""
ndim = self.kpt_shape[1] # 关键点维度(2或3)
bs = kpts.shape[0] # 批量大小
# 如果是导出模式
if self.export:
# 针对特定导出格式的特殊处理
if self.format in {
"tflite",
"edgetpu",
}: # required for TFLite export to avoid 'PLACEHOLDER_FOR_GREATER_OP_CODES' bug
# 预计算归一化因子以提高数值稳定性
y = kpts.view(bs, *self.kpt_shape, -1)
grid_h, grid_w = self.shape[2], self.shape[3]
grid_size = torch.tensor([grid_w, grid_h], device=y.device).reshape(1, 2, 1)
norm = self.strides / (self.stride[0] * grid_size) # 计算归一化因子
# 解码关键点坐标
a = (y[:, :, :2] + self.anchors) * norm
else:
# NCNN修复
y = kpts.view(bs, *self.kpt_shape, -1)
a = (y[:, :, :2] + self.anchors) * self.strides
# 如果有关键点可见性维度,添加sigmoid处理后的可见性分数
if ndim == 3:
a = torch.cat((a, y[:, :, 2:3].sigmoid()), 2)
# 调整形状为(bs, nk, -1)
return a.view(bs, self.nk, -1)
else:
# 非导出模式
y = kpts.clone() # 复制关键点预测
# 如果有关键点可见性维度,对可见性分数应用sigmoid
if ndim == 3:
if NOT_MACOS14: # 如果不是MacOS14
y[:, 2::ndim].sigmoid_() # 原地sigmoid
else: # Apple macOS14 MPS bug https://github.com/ultralytics/ultralytics/pull/21878
y[:, 2::ndim] = y[:, 2::ndim].sigmoid() # 避免MPS bug
# 解码x坐标:(预测值 + 锚点x) * 步长
y[:, 0::ndim] = (y[:, 0::ndim] + self.anchors[0]) * self.strides
# 解码y坐标:(预测值 + 锚点y) * 步长
y[:, 1::ndim] = (y[:, 1::ndim] + self.anchors[1]) * self.strides
return y # 返回解码后的关键点Classify 类 - 分类头
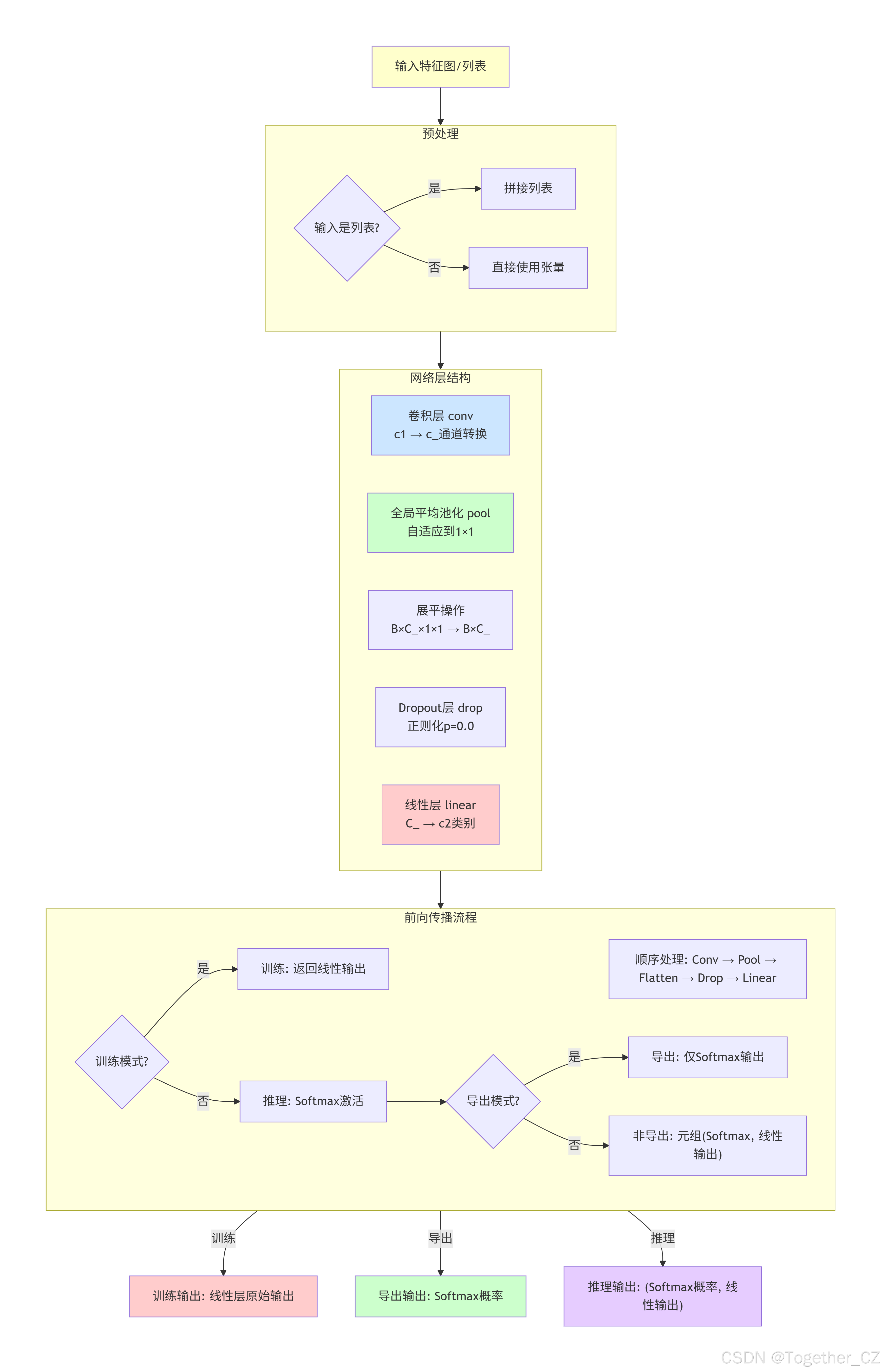
Classify 类是一个独立的分类头,不继承自Detect:
设计特点:
-
简单直接:专为纯分类任务设计
-
全局池化:使用自适应平均池化将空间特征转换为全局特征
-
端到端分类:直接输出类别概率
核心组件:
-
conv:特征转换卷积层(输入通道→中间通道) -
pool:自适应平均池化层(任何尺寸→1×1) -
drop:Dropout正则化层 -
linear:最终分类线性层
工作流程:
-
特征提取:卷积层提取高级特征
-
空间聚合:全局平均池化聚合空间信息
-
分类决策:线性层+softmax输出类别概率
整体架构示意图如下所示:
python
class Classify(nn.Module):
"""
YOLO 分类头,即 x(b,c1,20,20) → x(b,c2)。
该类实现将特征图转换为类别预测的分类头。
属性:
export (bool):导出模式标志。
conv (Conv):特征转换卷积层。
pool (nn.AdaptiveAvgPool2d):全局平均池化层。
drop (nn.Dropout):Dropout 正则化层。
linear (nn.Linear):最终分类线性层。
方法:
forward:对输入图像数据执行 YOLO 模型前向传播。
示例:
创建分类头
classify = Classify(c1=1024, c2=1000)
x = torch.randn(1, 1024, 20, 20)
output = classify(x)
"""
export = False # export mode # 导出模式标志,默认False
def __init__(self, c1: int, c2: int, k: int = 1, s: int = 1, p: int | None = None, g: int = 1):
"""
初始化 YOLO 分类头,将输入张量从 (b,c1,20,20) 变换为 (b,c2) 形状。
参数:
c1 (int):输入通道数。
c2 (int):输出类别数。
k (int, 可选):卷积核大小。
s (int, 可选):步长。
p (int, 可选):填充。
g (int, 可选):分组数。
"""
super().__init__() # 调用父类nn.Module的初始化方法
c_ = 1280 # efficientnet_b0 size # 中间通道数,参考EfficientNet-B0
# 卷积层:将输入通道c1转换为中间通道c_
self.conv = Conv(c1, c_, k, s, p, g)
# 全局平均池化层:将特征图池化为1x1大小
self.pool = nn.AdaptiveAvgPool2d(1) # to x(b,c_,1,1)
# Dropout层:用于正则化,防止过拟合
self.drop = nn.Dropout(p=0.0, inplace=True)
# 线性层:将中间通道c_转换为输出类别数c2
self.linear = nn.Linear(c_, c2) # to x(b,c2)
def forward(self, x: list[torch.Tensor] | torch.Tensor) -> torch.Tensor | tuple:
"""
对输入图像数据执行YOLO模型前向传播
"""
# 如果输入是列表,将其拼接
if isinstance(x, list):
x = torch.cat(x, 1)
# 前向传播流程:
# 1. 卷积层
# 2. 全局平均池化
# 3. 展平为1D向量
# 4. Dropout
# 5. 线性层
x = self.linear(self.drop(self.pool(self.conv(x)).flatten(1)))
# 如果是训练模式,返回线性层输出
if self.training:
return x
# 推理模式:对线性层输出应用softmax
y = x.softmax(1) # get final output # 获取最终输出
# 如果是导出模式,只返回softmax输出;否则返回softmax输出和原始输出
return y if self.export else (y, x)WorldDetect 类 - 世界感知检测头
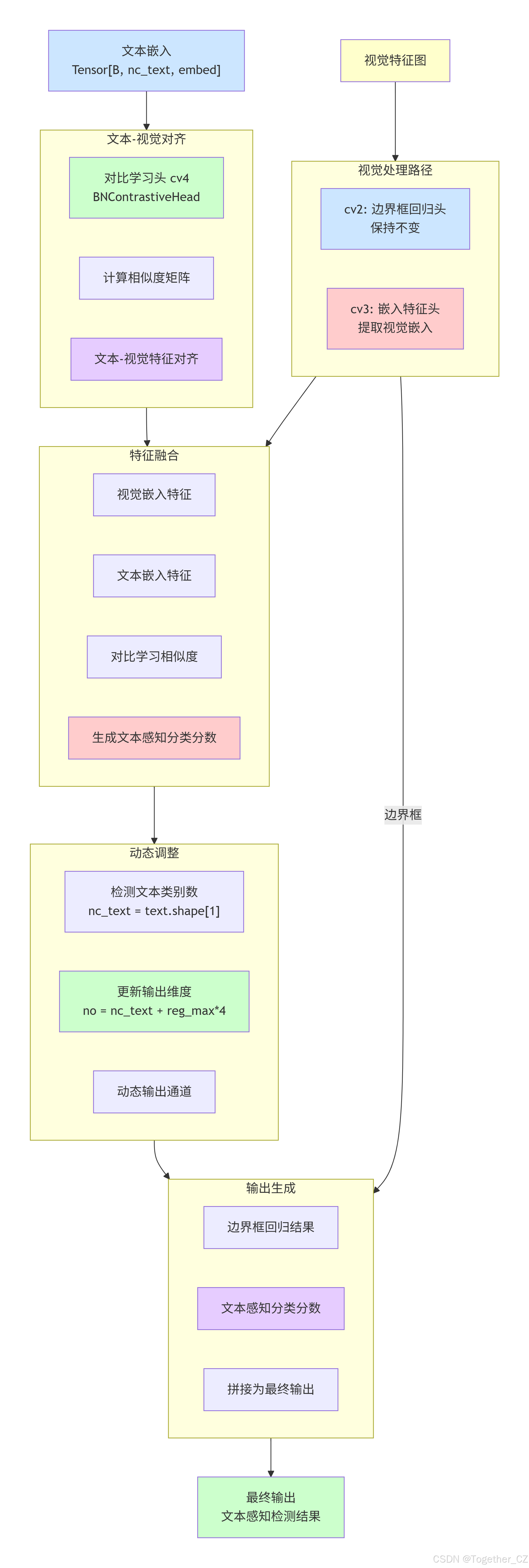
WorldDetect 类扩展Detect以支持文本嵌入增强的语义理解:
设计特点:
-
文本-视觉对齐:通过对比学习对齐文本和视觉特征
-
动态词汇:支持推理时使用不同的文本嵌入
-
语义增强:利用文本语义信息改善检测
核心组件:
-
cv3:嵌入特征提取头(输出embed维度) -
cv4:对比学习头(BNContrastiveHead或ContrastiveHead) -
nc:动态变化(根据输入文本的类别数)
工作流程:
-
视觉特征提取:cv3提取视觉嵌入特征
-
文本特征输入:外部提供文本嵌入
-
对比学习:cv4计算文本-视觉相似度
-
动态输出:根据文本类别数调整输出维度
关键机制:
-
文本嵌入与视觉特征的相似度计算
-
动态调整输出通道以适应不同文本词汇
-
保持边界框回归与文本无关
整体架构示意图如下所示;
python
class WorldDetect(Detect):
"""
用于将 YOLO 检测模型与文本嵌入的语义理解相结合的头。
该类扩展了标准 Detect 检测头,引入文本嵌入以增强目标检测任务中的语义理解能力。
属性:
cv3 (nn.ModuleList):嵌入特征卷积层。
cv4 (nn.ModuleList):文本-视觉对齐对比头层。
方法:
forward:拼接并返回预测的边界框和类别概率。
bias_init:初始化检测头偏置。
示例:
创建 WorldDetect 检测头
world_detect = WorldDetect(nc=80, embed=512, with_bn=False, ch=(256, 512, 1024))
x = [torch.randn(1, 256, 80, 80), torch.randn(1, 512, 40, 40), torch.randn(1, 1024, 20, 20)]
text = torch.randn(1, 80, 512)
outputs = world_detect(x, text)
"""
def __init__(
self,
nc: int = 80,
embed: int = 512,
with_bn: bool = False,
reg_max: int = 16,
end2end: bool = False,
ch: tuple = (),
):
"""
使用 nc 个类别和层通道 ch 初始化 YOLO 检测层。
参数:
nc (int):类别数量。
embed (int):嵌入维度。
with_bn (bool):对比头是否使用批归一化。
reg_max (int):DFL 最大通道数。
end2end (bool):是否使用端到端无 NMS 检测。
ch (tuple):骨干网络特征图的通道大小元组。
"""
# 调用父类Detect的初始化方法
super().__init__(nc, reg_max=reg_max, end2end=end2end, ch=ch)
# 计算嵌入特征头的通道数
c3 = max(ch[0], min(self.nc, 100))
# 创建嵌入特征卷积层列表
# 每个检测层包含:Conv -> Conv -> Conv(输出embed个通道)
self.cv3 = nn.ModuleList(nn.Sequential(Conv(x, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, embed, 1)) for x in ch)
# 创建对比头列表:如果with_bn为True则使用BNContrastiveHead,否则使用ContrastiveHead
self.cv4 = nn.ModuleList(BNContrastiveHead(embed) if with_bn else ContrastiveHead() for _ in ch)
def forward(self, x: list[torch.Tensor], text: torch.Tensor) -> dict[str, torch.Tensor] | tuple:
"""
拼接并返回预测的边界框和类别概率
"""
# 保存原始特征用于锚点生成
feats = [xi.clone() for xi in x] # save original features for anchor generation
# 处理每个检测层
for i in range(self.nl):
# 处理流程:
# 1. 通过cv3提取嵌入特征
# 2. 通过cv4将嵌入特征与文本嵌入进行对比
# 3. 将边界框回归结果和对比结果拼接
x[i] = torch.cat((self.cv2[i](x[i]), self.cv4[i](self.cv3[i](x[i]), text)), 1)
# 更新输出数量:类别数可能在不同文本下变化
self.no = self.nc + self.reg_max * 4 # self.nc could be changed when inference with different texts
bs = x[0].shape[0] # 批量大小
# 拼接所有检测层的输出
x_cat = torch.cat([xi.view(bs, self.no, -1) for xi in x], 2)
# 分割为边界框和类别分数
boxes, scores = x_cat.split((self.reg_max * 4, self.nc), 1)
# 构建预测字典
preds = dict(boxes=boxes, scores=scores, feats=feats)
# 如果是训练模式,返回预测结果
if self.training:
return preds
# 推理模式:进行推理
y = self._inference(preds)
# 如果是导出模式,只返回推理结果;否则返回推理结果和预测结果
return y if self.export else (y, preds)
def bias_init(self):
"""
初始化检测头的偏置,注意:需要步长信息可用
"""
m = self # self.model[-1] # Detect() module # 获取当前模块
# 遍历边界框回归头、嵌入特征头和对比头
for a, b, s in zip(m.cv2, m.cv3, m.stride): # from
a[-1].bias.data[:] = 1.0 # box # 边界框回归头偏置初始化为1.0
# 分类头偏置初始化公式:log(5 / m.nc / (640 / s) ** 2)
# 注意:这里b[-1]是嵌入特征头的最后一层,不是分类头
# 实际分类由对比头处理,这里保持原注释但可能不准确
# b[-1].bias.data[:] = math.log(5 / m.nc / (640 / s) ** 2) # cls (.01 objects, 80 classes, 640 img)LRPCHead 类 - 轻量级区域建议分类头
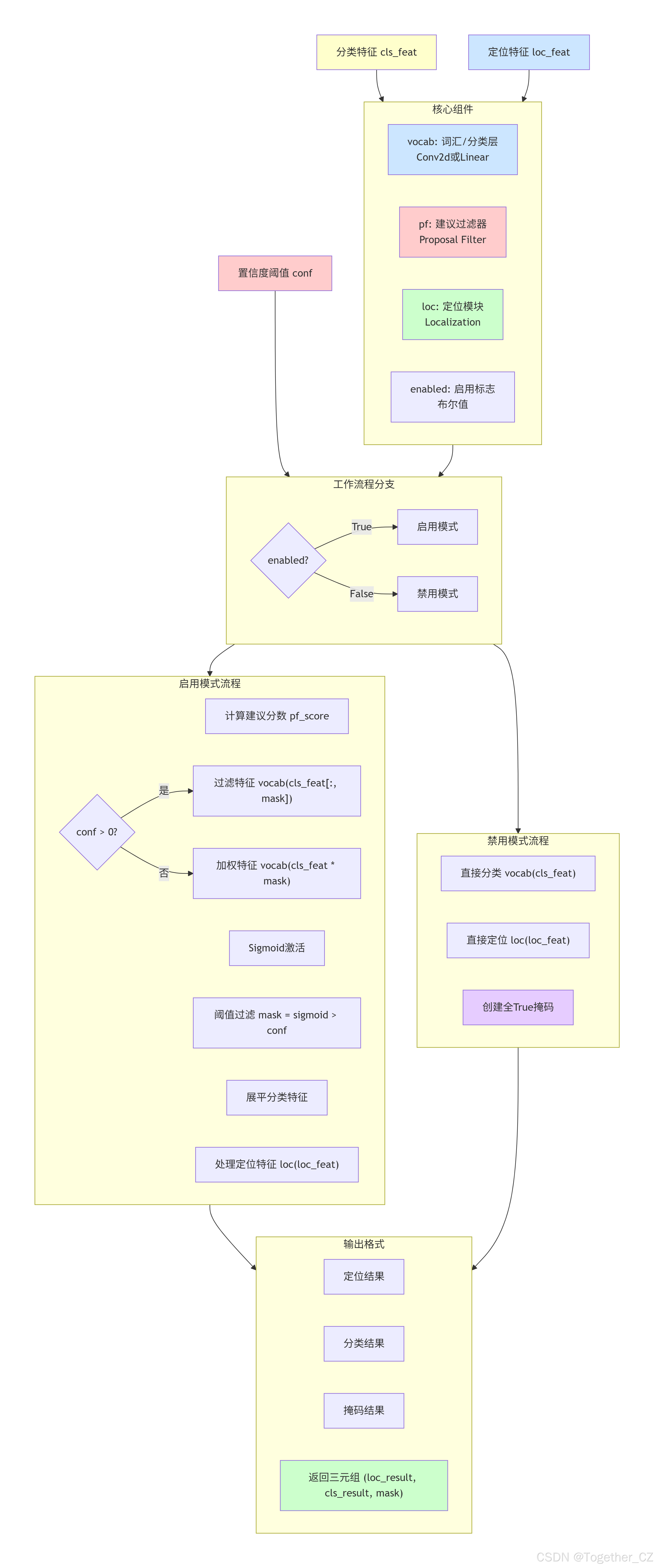
LRPCHead 类实现轻量级区域建议和分类:
设计特点:
-
建议过滤:先过滤低质量区域建议,再分类
-
动态计算:根据置信度阈值动态选择建议
-
卷积转线性:将1×1卷积转换为线性层以提高效率
核心组件:
-
vocab:词汇/分类层(可能是Conv2d或Linear) -
pf:建议过滤器(Proposal Filter) -
loc:定位模块(Localization) -
enabled:启用标志
工作流程:
-
建议过滤:pf模块计算建议分数并过滤
-
特征选择:根据过滤结果选择特征
-
分类处理:vocab层处理选择的特征
-
定位处理:loc模块处理定位特征
关键方法:
-
conv2linear:静态方法,将1×1卷积转换为线性层 -
根据enabled标志决定是否进行动态过滤
优化策略:
-
仅在enabled=True时进行建议过滤
-
使用掩码选择或加权特征
-
支持不同的置信度阈值
整体架构示意图如下所示:
python
class LRPCHead(nn.Module):
"""
轻量级区域建议与分类头,用于高效目标检测。
该检测头将区域建议过滤与分类相结合,支持动态词汇表的高效检测。
属性:
vocab (nn.Module):词汇/分类层。
pf (nn.Module):建议过滤模块。
loc (nn.Module):定位模块。
enabled (bool):该头是否启用。
方法:
conv2linear:将 1×1 卷积层转换为线性层。
forward:处理分类和定位特征以生成检测建议。
示例:
创建 LRPC 检测头
vocab = nn.Conv2d(256, 80, 1)
pf = nn.Conv2d(256, 1, 1)
loc = nn.Conv2d(256, 4, 1)
head = LRPCHead(vocab, pf, loc, enabled=True)
"""
def __init__(self, vocab: nn.Module, pf: nn.Module, loc: nn.Module, enabled: bool = True):
"""
使用词汇、建议过滤和定位组件初始化 LRPCHead。
参数:
vocab (nn.Module):词汇/分类模块。
pf (nn.Module):建议过滤模块。
loc (nn.Module):定位模块。
enabled (bool):是否启用头功能。
"""
super().__init__() # 调用父类nn.Module的初始化方法
# 如果启用,将词汇卷积层转换为线性层;否则保持不变
self.vocab = self.conv2linear(vocab) if enabled else vocab
self.pf = pf # 建议过滤模块
self.loc = loc # 定位模块
self.enabled = enabled # 是否启用
@staticmethod
def conv2linear(conv: nn.Conv2d) -> nn.Linear:
"""
将1x1卷积层转换为线性层
"""
# 确保输入是1x1卷积层
assert isinstance(conv, nn.Conv2d) and conv.kernel_size == (1, 1)
# 创建线性层,输入通道和输出通道与卷积层相同
linear = nn.Linear(conv.in_channels, conv.out_channels)
# 将卷积权重从4D(输出通道,输入通道,1,1)转换为2D(输出通道,输入通道)
linear.weight.data = conv.weight.view(conv.out_channels, -1).data
# 复制偏置
linear.bias.data = conv.bias.data
return linear # 返回线性层
def forward(self, cls_feat: torch.Tensor, loc_feat: torch.Tensor, conf: float) -> tuple[tuple, torch.Tensor]:
"""
处理分类和定位特征以生成检测建议
"""
if self.enabled: # 如果头启用
# 计算建议过滤分数
pf_score = self.pf(cls_feat)[0, 0].flatten(0)
# 根据置信度阈值创建掩码
mask = pf_score.sigmoid() > conf
# 处理分类特征
# 1. 展平空间维度:(批量,通道,高,宽) -> (批量,通道,高*宽)
# 2. 转置:(批量,通道,高*宽) -> (批量,高*宽,通道)
cls_feat = cls_feat.flatten(2).transpose(-1, -2)
# 根据掩码过滤特征或加权
if conf:
# 如果conf>0,使用掩码过滤
cls_feat = self.vocab(cls_feat[:, mask] if conf else cls_feat * mask.unsqueeze(-1).int())
else:
# 如果conf=0,使用掩码加权
cls_feat = self.vocab(cls_feat * mask.unsqueeze(-1).int())
# 处理定位特征
loc_feat = self.loc(loc_feat)
# 返回定位结果、分类结果和掩码
return self.loc(loc_feat), cls_feat.transpose(-1, -2), mask
else:
# 如果头未启用,直接处理
cls_feat = self.vocab(cls_feat)
loc_feat = self.loc(loc_feat)
# 返回定位结果、分类结果和全True掩码
return (
loc_feat,
cls_feat.flatten(2),
torch.ones(cls_feat.shape[2] * cls_feat.shape[3], device=cls_feat.device, dtype=torch.bool),
)YOLOEDetect 类 - YOLOE检测头
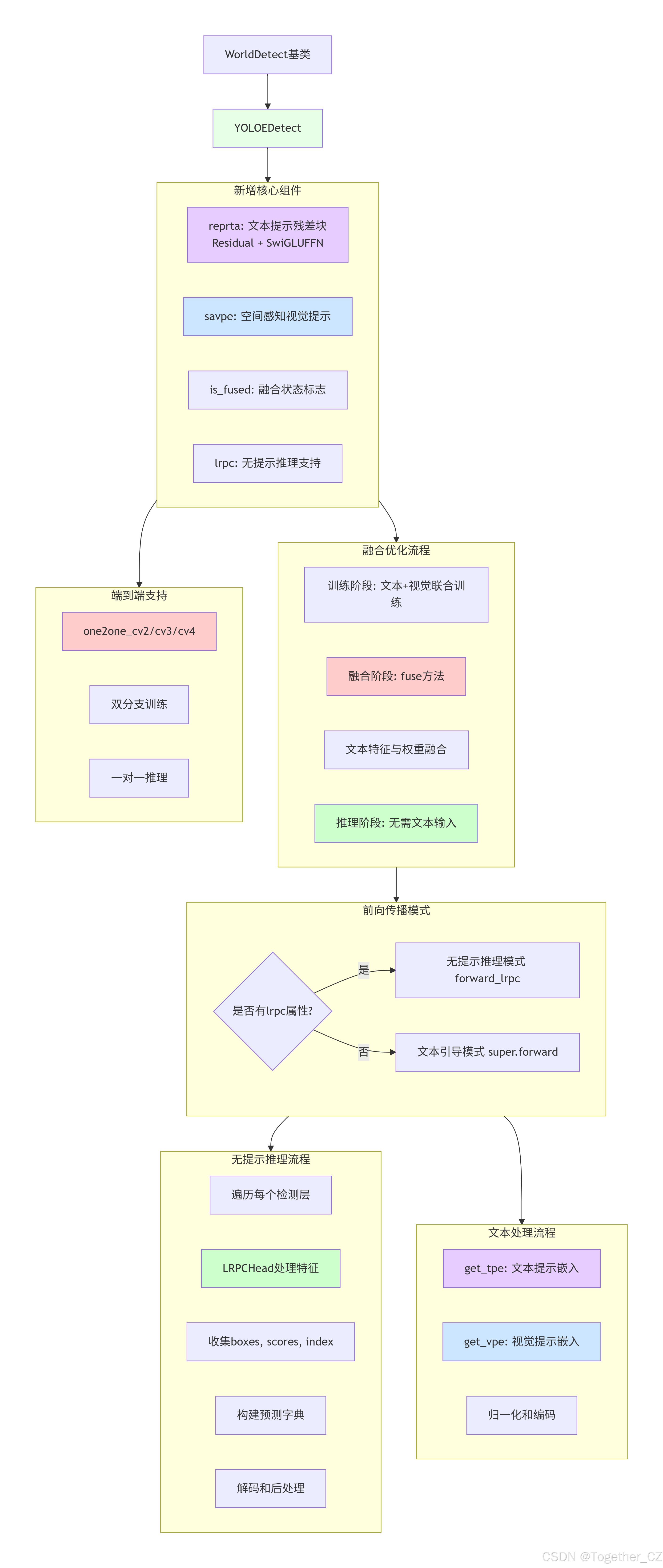
YOLOEDetect 类实现文本引导的检测,是WorldDetect的增强版:
设计特点:
-
文本-权重融合:训练后将文本特征融合到模型权重中
-
无提示推理:支持无文本输入的推理模式(LRPC)
-
复杂架构:更深的卷积结构和残差连接
核心组件:
-
reprta:文本提示嵌入残差块(Residual + SwiGLUFFN) -
savpe:空间感知视觉提示嵌入 -
is_fused:融合状态标志 -
lrpc:无提示推理支持
关键方法:
-
fuse:融合文本特征到模型权重 -
get_tpe:获取文本提示嵌入 -
get_vpe:获取视觉提示嵌入 -
forward_lrpc:无提示推理前向传播
融合优化:
-
训练阶段:文本和视觉特征分别处理
-
融合阶段:将文本特征融合到卷积权重
-
推理阶段:使用融合后的权重,无需文本输入
架构优势:
-
训练时充分利用文本语义
-
推理时保持高效单模态处理
-
支持端到端和无提示两种模式
整体架构示意图如下所示:
python
class YOLOEDetect(Detect):
"""
用于将 YOLO 检测模型与文本嵌入的语义理解相结合的头。
该类扩展了标准 Detect 检测头,通过文本嵌入和视觉提示嵌入支持文本引导检测,增强语义理解能力。
属性:
is_fused (bool):模型是否已融合用于推理。
cv3 (nn.ModuleList):嵌入特征卷积层。
cv4 (nn.ModuleList):文本-视觉对齐对比头层。
reprta (Residual):文本提示嵌入残差块。
savpe (SAVPE):空间感知视觉提示嵌入模块。
embed (int):嵌入维度。
方法:
fuse:将文本特征与模型权重融合以优化推理。
get_tpe:获取归一化的文本提示嵌入。
get_vpe:获取空间感知的视觉提示嵌入。
forward_lrpc:使用融合的文本嵌入处理特征以进行无提示模型推理。
forward:使用类别提示嵌入处理特征以生成检测。
bias_init:初始化检测头偏置。
示例:
创建 YOLOEDetect 检测头
yoloe_detect = YOLOEDetect(nc=80, embed=512, with_bn=True, ch=(256, 512, 1024))
x = [torch.randn(1, 256, 80, 80), torch.randn(1, 512, 40, 40), torch.randn(1, 1024, 20, 20)]
cls_pe = torch.randn(1, 80, 512)
outputs = yoloe_detect(x, cls_pe)
"""
is_fused = False # 融合标志,初始为False
def __init__(
self, nc: int = 80, embed: int = 512, with_bn: bool = False, reg_max=16, end2end=False, ch: tuple = ()
):
"""
使用 nc 个类别和层通道 ch 初始化 YOLO 检测层。
参数:
nc (int):类别数量。
embed (int):嵌入维度。
with_bn (bool):对比头是否使用批归一化。
reg_max (int):DFL 最大通道数。
end2end (bool):是否使用端到端无 NMS 检测。
ch (tuple):骨干网络特征图的通道大小元组。
"""
# 调用父类Detect的初始化方法
super().__init__(nc, reg_max, end2end, ch)
# 计算嵌入特征头的通道数
c3 = max(ch[0], min(self.nc, 100))
# 确保c3 <= embed
assert c3 <= embed
# 要求使用批归一化
assert with_bn
# 创建嵌入特征卷积层列表
# 如果是旧版模型,使用简单的Conv结构
# 否则使用更复杂的DWConv结构
self.cv3 = (
nn.ModuleList(nn.Sequential(Conv(x, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, embed, 1)) for x in ch)
if self.legacy # 如果是旧版模型
else nn.ModuleList( # 否则使用新结构
nn.Sequential(
nn.Sequential(DWConv(x, x, 3), Conv(x, c3, 1)), # DWConv + Conv
nn.Sequential(DWConv(c3, c3, 3), Conv(c3, c3, 1)), # DWConv + Conv
nn.Conv2d(c3, embed, 1), # 1x1卷积输出嵌入维度
)
for x in ch
)
)
# 创建对比头列表:如果with_bn为True则使用BNContrastiveHead,否则使用ContrastiveHead
self.cv4 = nn.ModuleList(BNContrastiveHead(embed) if with_bn else ContrastiveHead() for _ in ch)
# 如果是端到端检测,创建一对一版本的各个头
if end2end:
self.one2one_cv3 = copy.deepcopy(self.cv3) # overwrite with new cv3 # 用新的cv3覆盖
self.one2one_cv4 = copy.deepcopy(self.cv4)
# 创建文本提示嵌入残差块
self.reprta = Residual(SwiGLUFFN(embed, embed))
# 创建空间感知视觉提示嵌入模块
self.savpe = SAVPE(ch, c3, embed)
self.embed = embed # 嵌入维度
@smart_inference_mode()
def fuse(self, txt_feats: torch.Tensor = None):
"""
将文本特征与模型权重融合以优化推理
"""
if txt_feats is None: # means eliminate one2many branch # 表示消除一对多分支
self.cv2 = self.cv3 = self.cv4 = None # 将一对多头设置为None
return
# 如果已经融合,直接返回
if self.is_fused:
return
# 确保不是训练模式
assert not self.training
# 处理文本特征
txt_feats = txt_feats.to(torch.float32).squeeze(0)
# 融合一对多头的文本提示
self._fuse_tp(txt_feats, self.cv3, self.cv4)
# 如果是端到端检测,融合一对一头的文本提示
if self.end2end:
self._fuse_tp(txt_feats, self.one2one_cv3, self.one2one_cv4)
# 删除reprta并替换为恒等映射
del self.reprta
self.reprta = nn.Identity()
self.is_fused = True # 设置融合标志为True
def _fuse_tp(self, txt_feats: torch.Tensor, cls_head: torch.nn.Module, bn_head: torch.nn.Module) -> None:
"""
将文本提示嵌入与模型权重融合以优化推理
"""
for cls_h, bn_h in zip(cls_head, bn_head):
# 确保类型正确
assert isinstance(cls_h, nn.Sequential)
assert isinstance(bn_h, BNContrastiveHead)
# 获取卷积层
conv = cls_h[-1]
assert isinstance(conv, nn.Conv2d)
# 获取对比头的参数
logit_scale = bn_h.logit_scale
bias = bn_h.bias
norm = bn_h.norm
# 计算文本特征权重
t = txt_feats * logit_scale.exp()
# 融合卷积层和批归一化层
conv: nn.Conv2d = fuse_conv_and_bn(conv, norm)
# 获取融合后的权重和偏置
w = conv.weight.data.squeeze(-1).squeeze(-1)
b = conv.bias.data
# 计算新的权重和偏置
w = t @ w # 文本特征与权重点积
b1 = (t @ b.reshape(-1).unsqueeze(-1)).squeeze(-1) # 文本特征与偏置点积
b2 = torch.ones_like(b1) * bias # 对比头偏置
# 创建新的1x1卷积层
conv = (
nn.Conv2d(
conv.in_channels,
w.shape[0],
kernel_size=1,
)
.requires_grad_(False) # 设置为不需要梯度
.to(conv.weight.device) # 移动到相同设备
)
# 设置新卷积层的权重和偏置
conv.weight.data.copy_(w.unsqueeze(-1).unsqueeze(-1))
conv.bias.data.copy_(b1 + b2)
# 替换原始卷积层
cls_h[-1] = conv
# 融合对比头
bn_h.fuse()
def get_tpe(self, tpe: torch.Tensor | None) -> torch.Tensor | None:
"""
获取归一化的文本提示嵌入
"""
# 如果tpe为None,返回None;否则通过reprta处理并归一化
return None if tpe is None else F.normalize(self.reprta(tpe), dim=-1, p=2)
def get_vpe(self, x: list[torch.Tensor], vpe: torch.Tensor) -> torch.Tensor:
"""
获取空间感知的视觉提示嵌入
"""
# 如果视觉提示嵌入的第二维为0(无视觉提示),返回零张量
if vpe.shape[1] == 0: # no visual prompt embeddings
return torch.zeros(x[0].shape[0], 0, self.embed, device=x[0].device)
# 如果视觉提示嵌入是4D的(批量,数量,高,宽),通过savpe处理
if vpe.ndim == 4: # (B, N, H, W)
vpe = self.savpe(x, vpe)
# 确保视觉提示嵌入是3D的(批量,数量,维度)
assert vpe.ndim == 3 # (B, N, D)
return vpe # 返回视觉提示嵌入
def forward(self, x: list[torch.Tensor]) -> torch.Tensor | tuple:
"""
使用类别提示嵌入处理特征以生成检测
"""
# 如果有无提示推理的lrpc属性,调用forward_lrpc方法
if hasattr(self, "lrpc"): # for prompt-free inference # 用于无提示推理
return self.forward_lrpc(x[:3]) # 只使用前3个特征图
# 否则调用父类的forward方法
return super().forward(x)
def forward_lrpc(self, x: list[torch.Tensor]) -> torch.Tensor | tuple:
"""
使用融合的文本嵌入处理特征以生成检测(用于无提示模型)
"""
boxes, scores, index = [], [], [] # 初始化列表
bs = x[0].shape[0] # 批量大小
# 根据是否端到端检测选择使用哪个头
cv2 = self.cv2 if not self.end2end else self.one2one_cv2
cv3 = self.cv3 if not self.end2end else self.one2one_cv2
# 处理每个检测层
for i in range(self.nl):
# 提取分类特征和定位特征
cls_feat = cv3[i](x[i])
loc_feat = cv2[i](x[i])
# 确保lrpc[i]是LRPCHead类型
assert isinstance(self.lrpc[i], LRPCHead)
# 通过LRPCHead处理特征
box, score, idx = self.lrpc[i](
cls_feat,
loc_feat,
# 确定置信度阈值
0 if self.export and not self.dynamic else getattr(self, "conf", 0.001),
)
# 收集结果
boxes.append(box.view(bs, self.reg_max * 4, -1))
scores.append(score)
index.append(idx)
# 构建预测字典
preds = dict(boxes=torch.cat(boxes, 2), scores=torch.cat(scores, 2), feats=x, index=torch.cat(index))
# 进行推理
y = self._inference(preds)
# 如果是端到端检测,进行后处理
if self.end2end:
y = self.postprocess(y.permute(0, 2, 1))
# 如果是导出模式,只返回推理结果;否则返回推理结果和预测结果
return y if self.export else (y, preds)
def _get_decode_boxes(self, x):
"""
解码预测的边界框用于推理
"""
# 调用父类的_get_decode_boxes方法
dbox = super()._get_decode_boxes(x)
# 如果有无提示推理的lrpc属性,根据索引过滤边界框
if hasattr(self, "lrpc"):
dbox = dbox if self.export and not self.dynamic else dbox[..., x["index"]]
return dbox # 返回解码后的边界框
@property
def one2many(self):
"""
返回一对多头部组件,用于向后兼容
"""
# 包含边界框回归头、分类头和对比头
return dict(box_head=self.cv2, cls_head=self.cv3, contrastive_head=self.cv4)
@property
def one2one(self):
"""
返回一对一头部组件
"""
# 包含边界框回归头、分类头和对比头
return dict(box_head=self.one2one_cv2, cls_head=self.one2one_cv3, contrastive_head=self.one2one_cv4)
def forward_head(self, x, box_head, cls_head, contrastive_head):
"""
拼接并返回预测的边界框、类别概率和文本嵌入
"""
# 确保输入有4个特征:3个特征图和1个文本嵌入
assert len(x) == 4, f"Expected 4 features including 3 feature maps and 1 text embeddings, but got {len(x)}."
# 如果box_head或cls_head为None(融合推理模式),返回空字典
if box_head is None or cls_head is None: # for fused inference
return dict()
bs = x[0].shape[0] # batch size # 获取批量大小
# 处理边界框预测
boxes = torch.cat([box_head[i](x[i]).view(bs, 4 * self.reg_max, -1) for i in range(self.nl)], dim=-1)
# 更新类别数(来自文本嵌入)
self.nc = x[-1].shape[1]
# 处理类别预测(通过对比头)
scores = torch.cat(
[contrastive_head[i](cls_head[i](x[i]), x[-1]).reshape(bs, self.nc, -1) for i in range(self.nl)], dim=-1
)
# 更新输出数量
self.no = self.nc + self.reg_max * 4 # self.nc could be changed when inference with different texts
# 返回预测字典
return dict(boxes=boxes, scores=scores, feats=x[:3])
def bias_init(self):
"""
初始化检测头的偏置,注意:需要步长信息可用
"""
# 遍历一对多头
for i, (a, b, c) in enumerate(
zip(self.one2many["box_head"], self.one2many["cls_head"], self.one2many["contrastive_head"])
):
a[-1].bias.data[:] = 2.0 # box # 边界框回归头偏置初始化为2.0
b[-1].bias.data[:] = 0.0 # 分类头偏置初始化为0.0
# 对比头偏置初始化公式:log(5 / self.nc / (640 / self.stride[i]) ** 2)
c.bias.data[:] = math.log(5 / self.nc / (640 / self.stride[i]) ** 2)
# 如果是端到端检测,初始化一对一头的偏置
if self.end2end:
for i, (a, b, c) in enumerate(
zip(self.one2one["box_head"], self.one2one["cls_head"], self.one2one["contrastive_head"])
):
a[-1].bias.data[:] = 2.0 # box # 边界框回归头偏置初始化为2.0
b[-1].bias.data[:] = 0.0 # 分类头偏置初始化为0.0
# 对比头偏置初始化公式:log(5 / self.nc / (640 / self.stride[i]) ** 2)
c.bias.data[:] = math.log(5 / self.nc / (640 / self.stride[i]) ** 2)YOLOESegment 类 - YOLOE分割头
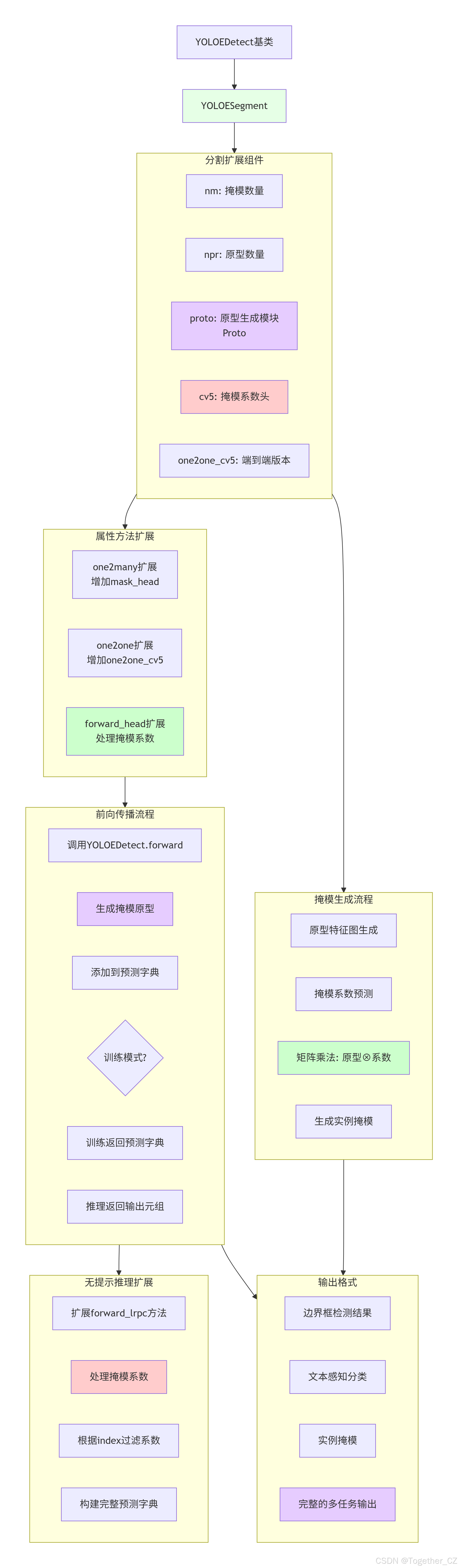
YOLOESegment 类在YOLOEDetect基础上添加分割功能:
设计特点:
-
多任务集成:检测 + 分割 + 文本感知
-
继承扩展:复用YOLOEDetect的文本处理能力
-
掩模生成:添加原型和掩模系数预测
核心组件:
-
nm:掩模数量 -
npr:原型数量 -
proto:原型生成模块(Proto) -
cv5:掩模系数预测头 -
one2one_cv5:端到端掩模系数头
属性扩展:
-
one2many:包含box_head, cls_head, mask_head, contrastive_head -
one2one:包含相应的one2one版本
工作流程:
-
基础检测:复用YOLOEDetect的检测功能
-
文本处理:复用文本-视觉对齐
-
掩模生成:添加原型和系数预测
-
结果融合:组合检测和分割结果
无提示推理支持:
-
扩展
forward_lrpc方法以处理掩模系数 -
在无文本输入时仍能生成分割结果
整体架构示意图如下所示:
python
class YOLOESegment(YOLOEDetect):
"""
YOLO 分割头,具备文本嵌入能力。
该类继承自 YOLOEDetect,增加了实例分割任务的掩模预测能力,支持文本引导的语义理解。
属性:
nm (int):掩模数量。
npr (int):原型数量。
proto (Proto):原型生成模块。
cv5 (nn.ModuleList):掩模系数卷积层。
方法:
forward:返回模型输出和掩模系数。
示例:
创建 YOLOESegment 分割头
yoloe_segment = YOLOESegment(nc=80, nm=32, npr=256, embed=512, with_bn=True, ch=(256, 512, 1024))
x = [torch.randn(1, 256, 80, 80), torch.randn(1, 512, 40, 40), torch.randn(1, 1024, 20, 20)]
text = torch.randn(1, 80, 512)
outputs = yoloe_segment(x, text)
"""
def __init__(
self,
nc: int = 80,
nm: int = 32,
npr: int = 256,
embed: int = 512,
with_bn: bool = False,
reg_max=16,
end2end=False,
ch: tuple = (),
):
"""
使用类别数、掩模参数和嵌入维度初始化 YOLOESegment。
参数:
nc (int):类别数量。
nm (int):掩模数量。
npr (int):原型数量。
embed (int):嵌入维度。
with_bn (bool):对比头是否使用批归一化。
reg_max (int):DFL 最大通道数。
end2end (bool):是否使用端到端无 NMS 检测。
ch (tuple):骨干网络特征图的通道大小元组。
"""
# 调用父类YOLOEDetect的初始化方法
super().__init__(nc, embed, with_bn, reg_max, end2end, ch)
self.nm = nm # 掩模数量
self.npr = npr # 原型数量
# 创建原型生成模块
self.proto = Proto(ch[0], self.npr, self.nm)
# 计算掩模系数头的通道数
c5 = max(ch[0] // 4, self.nm)
# 创建掩模系数卷积层列表
self.cv5 = nn.ModuleList(nn.Sequential(Conv(x, c5, 3), Conv(c5, c5, 3), nn.Conv2d(c5, self.nm, 1)) for x in ch)
# 如果是端到端检测,创建一对一掩模系数头
if end2end:
self.one2one_cv5 = copy.deepcopy(self.cv5)
@property
def one2many(self):
"""
返回一对多头部组件,用于向后兼容
"""
# 包含边界框回归头、分类头、掩模系数头和对比头
return dict(box_head=self.cv2, cls_head=self.cv3, mask_head=self.cv5, contrastive_head=self.cv4)
@property
def one2one(self):
"""
返回一对一头部组件
"""
# 包含边界框回归头、分类头、掩模系数头和对比头
return dict(
box_head=self.one2one_cv2,
cls_head=self.one2one_cv3,
mask_head=self.one2one_cv5,
contrastive_head=self.one2one_cv4,
)
def forward_lrpc(self, x: list[torch.Tensor]) -> torch.Tensor | tuple:
"""
使用融合的文本嵌入处理特征以生成检测(用于无提示模型)
"""
boxes, scores, index = [], [], [] # 初始化列表
bs = x[0].shape[0] # 批量大小
# 根据是否端到端检测选择使用哪个头
cv2 = self.cv2 if not self.end2end else self.one2one_cv2
cv3 = self.cv3 if not self.end2end else self.one2one_cv3
cv5 = self.cv5 if not self.end2end else self.one2one_cv5
# 处理每个检测层
for i in range(self.nl):
# 提取分类特征和定位特征
cls_feat = cv3[i](x[i])
loc_feat = cv2[i](x[i])
# 确保lrpc[i]是LRPCHead类型
assert isinstance(self.lrpc[i], LRPCHead)
# 通过LRPCHead处理特征
box, score, idx = self.lrpc[i](
cls_feat,
loc_feat,
# 确定置信度阈值
0 if self.export and not self.dynamic else getattr(self, "conf", 0.001),
)
# 收集结果
boxes.append(box.view(bs, self.reg_max * 4, -1))
scores.append(score)
index.append(idx)
# 处理掩模系数
mc = torch.cat([cv5[i](x[i]).view(bs, self.nm, -1) for i in range(self.nl)], 2)
index = torch.cat(index) # 拼接索引
# 构建预测字典
preds = dict(
boxes=torch.cat(boxes, 2),
scores=torch.cat(scores, 2),
feats=x,
index=index,
# 根据导出模式和动态标志处理掩模系数
mask_coefficient=mc * index.int() if self.export and not self.dynamic else mc[..., index],
)
# 进行推理
y = self._inference(preds)
# 如果是端到端检测,进行后处理
if self.end2end:
y = self.postprocess(y.permute(0, 2, 1))
# 如果是导出模式,只返回推理结果;否则返回推理结果和预测结果
return y if self.export else (y, preds)
def forward(self, x: list[torch.Tensor]) -> tuple | list[torch.Tensor] | dict[str, torch.Tensor]:
"""
如果是训练模式,返回模型输出和掩模系数;否则返回输出和掩模系数
"""
# 调用父类的forward方法
outputs = super().forward(x)
# 如果是元组,取第二个元素(预测结果),否则直接使用输出
preds = outputs[1] if isinstance(outputs, tuple) else outputs
# 生成掩模原型
proto = self.proto(x[0]) # mask protos
# 如果是字典(训练和验证时)
if isinstance(preds, dict): # training and validating during training
if self.end2end: # 如果是端到端检测
# 将原型添加到一对多和一对一预测中
preds["one2many"]["proto"] = proto
preds["one2one"]["proto"] = proto.detach()
else:
preds["proto"] = proto # 将原型添加到预测中
# 如果是训练模式,返回预测结果
if self.training:
return preds
# 推理模式:如果是导出模式,返回输出和原型;否则返回元组
return (outputs, proto) if self.export else ((outputs[0], proto), preds)
def _inference(self, x: dict[str, torch.Tensor]) -> torch.Tensor:
"""
解码预测的边界框和类别概率,并与掩模系数拼接
"""
# 调用父类的_inference方法获取检测预测
preds = super()._inference(x)
# 将检测预测与掩模系数拼接
return torch.cat([preds, x["mask_coefficient"]], dim=1)
def forward_head(
self,
x: list[torch.Tensor],
box_head: torch.nn.Module,
cls_head: torch.nn.Module,
mask_head: torch.nn.Module,
contrastive_head: torch.nn.Module,
) -> torch.Tensor:
"""
拼接并返回预测的边界框、类别概率和掩模系数
"""
# 调用父类的forward_head方法获取边界框和类别预测
preds = super().forward_head(x, box_head, cls_head, contrastive_head)
# 如果存在掩模系数头
if mask_head is not None:
bs = x[0].shape[0] # batch size # 获取批量大小
# 处理每个检测层的掩模系数预测
preds["mask_coefficient"] = torch.cat([mask_head[i](x[i]).view(bs, self.nm, -1) for i in range(self.nl)], 2)
return preds # 返回预测结果
def postprocess(self, preds: torch.Tensor) -> torch.Tensor:
"""
对 YOLO 模型预测结果进行后处理。
参数:
preds (torch.Tensor):原始预测,形状为 (batch_size, num_anchors, 4 + nc + nm),最后一维格式为 [x, y, w, h, class_probs, mask_coefficient]。
返回:
(torch.Tensor):处理后的预测,形状为 (batch_size, min(max_det, num_anchors), 6 + nm),最后一维格式为 [x, y, w, h, max_class_prob, class_index, mask_coefficient]。
"""
# 将预测分割为边界框、类别分数和掩模系数
boxes, scores, mask_coefficient = preds.split([4, self.nc, self.nm], dim=-1)
# 获取top-k索引
scores, conf, idx = self.get_topk_index(scores, self.max_det)
# 根据索引收集对应的边界框
boxes = boxes.gather(dim=1, index=idx.repeat(1, 1, 4))
# 根据索引收集对应的掩模系数
mask_coefficient = mask_coefficient.gather(dim=1, index=idx.repeat(1, 1, self.nm))
# 拼接边界框、分数、置信度和掩模系数
return torch.cat([boxes, scores, conf, mask_coefficient], dim=-1)YOLOESegment26 类 - YOLOE26分割头
YOLOESegment26 类是YOLOESegment的改进版本:
设计特点:
-
改进的原型生成:使用Proto26替代Proto
-
多尺度特征利用:Proto26使用所有特征图
-
梯度分离:避免原型生成影响检测梯度
-
语义分割支持:可选的语义分割输出
核心改进:
-
proto:替换为Proto26模块 -
前向传播中分离特征(
xi.detach()) -
支持语义分割任务(
return_semseg参数)
Proto26特点:
-
输入:所有特征图列表
-
输出:更丰富的原型表示
-
可选语义分割输出
前向传播差异:
-
直接调用YOLOEDetect.forward(非YOLOESegment.forward)
-
特征分离:
[xi.detach() for xi in x] -
更灵活的原型生成
设计优势:
-
更好的多尺度特征利用
-
减少任务间干扰
-
支持语义分割扩展
整体架构示意图如下所示:
python
class YOLOESegment26(YOLOESegment):
"""
YOLOE 风格分割头模块,使用 Proto26 生成掩模。
该类通过集成原型生成模块和卷积层来预测掩模系数,扩展了 YOLOEDetect 的功能以支持分割任务。
参数:
nc (int):类别数量,默认为 80。
nm (int):掩模数量,默认为 32。
npr (int):原型通道数,默认为 256。
embed (int):嵌入维度,默认为 512。
with_bn (bool):是否使用批归一化,默认为 False。
reg_max (int):边界框最大回归值,默认为 16。
end2end (bool):是否使用端到端检测模式,默认为 False。
ch (tuple[int, ...]):每个尺度的输入通道数。
属性:
nm (int):分割掩模数量。
npr (int):原型通道数。
proto (Proto26):用于分割的原型生成模块。
cv5 (nn.ModuleList):从特征生成掩模系数的卷积层。
one2one_cv5 (nn.ModuleList, 可选):用于端到端检测分支的 cv5 深拷贝。
"""
def __init__(
self,
nc: int = 80,
nm: int = 32,
npr: int = 256,
embed: int = 512,
with_bn: bool = False,
reg_max=16,
end2end=False,
ch: tuple = (),
):
"""
调用YOLOEDetect的初始化方法,而不是YOLOESegment的
"""
YOLOEDetect.__init__(self, nc, embed, with_bn, reg_max, end2end, ch)
self.nm = nm # 掩模数量
self.npr = npr # 原型数量
# 使用Proto26原型生成模块
self.proto = Proto26(ch, self.npr, self.nm, nc) # protos
# 计算掩模系数头的通道数
c5 = max(ch[0] // 4, self.nm)
# 创建掩模系数卷积层列表
self.cv5 = nn.ModuleList(nn.Sequential(Conv(x, c5, 3), Conv(c5, c5, 3), nn.Conv2d(c5, self.nm, 1)) for x in ch)
# 如果是端到端检测,创建一对一掩模系数头
if end2end:
self.one2one_cv5 = copy.deepcopy(self.cv5)
def forward(self, x: list[torch.Tensor]) -> tuple | list[torch.Tensor] | dict[str, torch.Tensor]:
"""
如果是训练模式,返回模型输出和掩模系数;否则返回输出和掩模系数
"""
# 调用YOLOEDetect的forward方法
outputs = YOLOEDetect.forward(self, x)
# 如果是元组,取第二个元素(预测结果),否则直接使用输出
preds = outputs[1] if isinstance(outputs, tuple) else outputs
# 生成掩模原型,分离特征以避免梯度传播
proto = self.proto([xi.detach() for xi in x], return_semseg=False) # mask protos
# 如果是字典(训练和验证时)
if isinstance(preds, dict): # training and validating during training
# 如果是端到端检测且不是无提示模型
if self.end2end and not hasattr(self, "lrpc"): # not prompt-free
# 将原型添加到一对多和一对一预测中
preds["one2many"]["proto"] = proto
preds["one2one"]["proto"] = proto.detach()
else:
preds["proto"] = proto # 将原型添加到预测中
# 如果是训练模式,返回预测结果
if self.training:
return preds
# 推理模式:如果是导出模式,返回输出和原型;否则返回元组
return (outputs, proto) if self.export else ((outputs[0], proto), preds)RTDETRDecoder 类 - Transformer解码器头
RTDETRDecoder 类实现基于Transformer的实时检测解码器:
设计特点:
-
Transformer架构:基于Deformable DETR设计
-
可变形注意力:高效处理多尺度特征
-
端到端检测:无需NMS后处理
-
查询机制:可学习或基于内容的查询初始化
核心组件:
-
input_proj:输入投影层(特征图→隐藏维度) -
decoder:可变形Transformer解码器 -
denoising_class_embed:去噪训练类别嵌入 -
query_pos_head:查询位置编码头 -
enc/dec_score_head:编码器/解码器分数预测头 -
enc/dec_bbox_head:编码器/解码器边界框预测头
关键机制:
-
查询选择:基于编码器分数选择top-k查询
-
可变形注意力:仅关注少量采样点
-
去噪训练:添加噪声查询提高鲁棒性
-
动态锚点:根据特征图形状生成锚点
工作流程:
-
特征投影:多尺度特征图投影到统一维度
-
编码器处理:生成初始分数和边界框
-
查询选择:选择最有希望的查询位置
-
解码器迭代:多层解码器 refine 预测
-
输出生成:直接输出最终预测
整体架构示意图如下所示:
python
class RTDETRDecoder(nn.Module):
"""
实时可变形 Transformer 解码器(RTDETRDecoder)模块,用于目标检测。
该解码器模块利用 Transformer 架构和可变形卷积来预测图像中目标的边界框和类别标签。它集成多层特征,并通过一系列 Transformer 解码器层输出最终预测结果。
属性:
export (bool):导出模式标志。
hidden_dim (int):隐藏层维度。
nhead (int):多头注意力头数。
nl (int):特征层级数。
nc (int):类别数量。
num_queries (int):查询点数量。
num_decoder_layers (int):解码器层数。
input_proj (nn.ModuleList):骨干特征输入投影层。
decoder (DeformableTransformerDecoder):Transformer 解码器模块。
denoising_class_embed (nn.Embedding):去噪类别嵌入。
num_denoising (int):去噪查询数量。
label_noise_ratio (float):训练标签噪声比例。
box_noise_scale (float):训练边界框噪声尺度。
learnt_init_query (bool):是否学习初始查询嵌入。
tgt_embed (nn.Embedding):查询目标嵌入。
query_pos_head (MLP):查询位置头。
enc_output (nn.Sequential):编码器输出层。
enc_score_head (nn.Linear):编码器分数预测头。
enc_bbox_head (MLP):编码器边界框预测头。
dec_score_head (nn.ModuleList):解码器分数预测头。
dec_bbox_head (nn.ModuleList):解码器边界框预测头。
方法:
forward:运行前向传播并返回边界框和分类分数。
示例:
创建 RTDETRDecoder
decoder = RTDETRDecoder(nc=80, ch=(512, 1024, 2048), hd=256, nq=300)
x = [torch.randn(1, 512, 64, 64), torch.randn(1, 1024, 32, 32), torch.randn(1, 2048, 16, 16)]
outputs = decoder(x)
"""
export = False # export mode # 导出模式标志,默认False
shapes = [] # 形状列表
anchors = torch.empty(0) # 锚点张量
valid_mask = torch.empty(0) # 有效掩码张量
dynamic = False # 动态标志
def __init__(
self,
nc: int = 80,
ch: tuple = (512, 1024, 2048),
hd: int = 256, # hidden dim # 隐藏维度
nq: int = 300, # num queries # 查询数量
ndp: int = 4, # num decoder points # 解码器点数
nh: int = 8, # num head # 注意力头数
ndl: int = 6, # num decoder layers # 解码器层数
d_ffn: int = 1024, # dim of feedforward # 前馈网络维度
dropout: float = 0.0,
act: nn.Module = nn.ReLU(),
eval_idx: int = -1,
# Training args # 训练参数
nd: int = 100, # num denoising # 去噪数量
label_noise_ratio: float = 0.5,
box_noise_scale: float = 1.0,
learnt_init_query: bool = False,
):
"""
使用给定参数初始化 RTDETRDecoder 模块。
参数:
nc (int):类别数量。
ch (tuple):骨干特征图通道。
hd (int):隐藏层维度。
nq (int):查询点数量。
ndp (int):解码器点数。
nh (int):多头注意力头数。
ndl (int):解码器层数。
d_ffn (int):前馈网络维度。
dropout (float):Dropout 率。
act (nn.Module):激活函数。
eval_idx (int):评估索引。
nd (int):去噪数量。
label_noise_ratio (float):标签噪声比例。
box_noise_scale (float):边界框噪声尺度。
learnt_init_query (bool):是否学习初始查询嵌入。
"""
super().__init__() # 调用父类nn.Module的初始化方法
self.hidden_dim = hd # 隐藏维度
self.nhead = nh # 注意力头数
self.nl = len(ch) # num level # 特征层级数
self.nc = nc # 类别数量
self.num_queries = nq # 查询数量
self.num_decoder_layers = ndl # 解码器层数
# Backbone feature projection # 骨干特征投影
# 创建输入投影层列表:每个层包含1x1卷积和批归一化
self.input_proj = nn.ModuleList(nn.Sequential(nn.Conv2d(x, hd, 1, bias=False), nn.BatchNorm2d(hd)) for x in ch)
# NOTE: simplified version but it's not consistent with .pt weights.
# self.input_proj = nn.ModuleList(Conv(x, hd, act=False) for x in ch)
# Transformer module # Transformer模块
# 创建可变形Transformer解码器层
decoder_layer = DeformableTransformerDecoderLayer(hd, nh, d_ffn, dropout, act, self.nl, ndp)
# 创建可变形Transformer解码器
self.decoder = DeformableTransformerDecoder(hd, decoder_layer, ndl, eval_idx)
# Denoising part # 去噪部分
# 创建去噪类别嵌入
self.denoising_class_embed = nn.Embedding(nc, hd)
self.num_denoising = nd # 去噪数量
self.label_noise_ratio = label_noise_ratio # 标签噪声比例
self.box_noise_scale = box_noise_scale # 边界框噪声尺度
# Decoder embedding # 解码器嵌入
self.learnt_init_query = learnt_init_query # 是否学习初始查询
if learnt_init_query: # 如果学习初始查询
self.tgt_embed = nn.Embedding(nq, hd) # 创建目标嵌入
# 查询位置头:MLP将4维位置编码转换为2*hd维再转换为hd维
self.query_pos_head = MLP(4, 2 * hd, hd, num_layers=2)
# Encoder head # 编码器头
# 编码器输出层:线性层+层归一化
self.enc_output = nn.Sequential(nn.Linear(hd, hd), nn.LayerNorm(hd))
# 编码器分数预测头
self.enc_score_head = nn.Linear(hd, nc)
# 编码器边界框预测头:MLP将hd维转换为4维(边界框)
self.enc_bbox_head = MLP(hd, hd, 4, num_layers=3)
# Decoder head # 解码器头
# 解码器分数预测头列表:每个解码器层一个
self.dec_score_head = nn.ModuleList([nn.Linear(hd, nc) for _ in range(ndl)])
# 解码器边界框预测头列表:每个解码器层一个
self.dec_bbox_head = nn.ModuleList([MLP(hd, hd, 4, num_layers=3) for _ in range(ndl)])
self._reset_parameters() # 重置参数
@staticmethod
def _generate_anchors(
shapes: list[list[int]],
grid_size: float = 0.05,
dtype: torch.dtype = torch.float32,
device: str = "cpu",
eps: float = 1e-2,
) -> tuple[torch.Tensor, torch.Tensor]:
"""
为给定形状生成特定网格大小的锚点边界框,并验证其有效性。
参数:
shapes (list):特征图形状列表。
grid_size (float, 可选):网格单元基础大小。
dtype (torch.dtype, 可选):张量数据类型。
device (str, 可选):创建张量的设备。
eps (float, 可选):数值稳定性小值。
返回:
anchors (torch.Tensor):生成的锚点框。
valid_mask (torch.Tensor):锚点有效掩码。
"""
anchors = [] # 锚点列表
for i, (h, w) in enumerate(shapes): # 遍历每个特征图形状
# 创建y坐标网格
sy = torch.arange(end=h, dtype=dtype, device=device)
# 创建x坐标网格
sx = torch.arange(end=w, dtype=dtype, device=device)
# 创建网格坐标
grid_y, grid_x = torch.meshgrid(sy, sx, indexing="ij") if TORCH_1_11 else torch.meshgrid(sy, sx)
grid_xy = torch.stack([grid_x, grid_y], -1) # (h, w, 2) # 网格坐标
# 归一化网格坐标
valid_WH = torch.tensor([w, h], dtype=dtype, device=device)
grid_xy = (grid_xy.unsqueeze(0) + 0.5) / valid_WH # (1, h, w, 2)
# 设置宽度和高度
wh = torch.ones_like(grid_xy, dtype=dtype, device=device) * grid_size * (2.0**i)
# 拼接坐标和宽高,调整形状
anchors.append(torch.cat([grid_xy, wh], -1).view(-1, h * w, 4)) # (1, h*w, 4)
# 拼接所有特征层的锚点
anchors = torch.cat(anchors, 1) # (1, h*w*nl, 4)
# 创建有效掩码:锚点坐标在(eps, 1-eps)范围内
valid_mask = ((anchors > eps) & (anchors < 1 - eps)).all(-1, keepdim=True) # 1, h*w*nl, 1
# 将锚点转换为log空间
anchors = torch.log(anchors / (1 - anchors))
# 将无效锚点设置为inf
anchors = anchors.masked_fill(~valid_mask, float("inf"))
# 返回锚点和有效掩码
return anchors, valid_mask
def forward(self, x: list[torch.Tensor], batch: dict | None = None) -> tuple | torch.Tensor:
"""
运行模块的前向传播,返回输入的边界框和分类分数。
参数:
x (list[torch.Tensor]):来自骨干网络的特征图列表。
batch (dict, 可选):训练的批次信息。
返回:
outputs (tuple | torch.Tensor):训练时返回边界框、分数和其他元数据的元组;推理时返回形状为 (bs, 300, 4+nc) 的张量,包含边界框和类别分数。
"""
from ultralytics.models.utils.ops import get_cdn_group
# Input projection and embedding # 输入投影和嵌入
feats, shapes = self._get_encoder_input(x)
# Prepare denoising training # 准备去噪训练
dn_embed, dn_bbox, attn_mask, dn_meta = get_cdn_group(
batch,
self.nc,
self.num_queries,
self.denoising_class_embed.weight,
self.num_denoising,
self.label_noise_ratio,
self.box_noise_scale,
self.training,
)
embed, refer_bbox, enc_bboxes, enc_scores = self._get_decoder_input(feats, shapes, dn_embed, dn_bbox)
# Decoder # 解码器
dec_bboxes, dec_scores = self.decoder(
embed,
refer_bbox,
feats,
shapes,
self.dec_bbox_head,
self.dec_score_head,
self.query_pos_head,
attn_mask=attn_mask,
)
# 构建输出
x = dec_bboxes, dec_scores, enc_bboxes, enc_scores, dn_meta
# 如果是训练模式,返回所有输出
if self.training:
return x
# 推理模式:拼接解码的边界框和sigmoid后的分数
# (bs, 300, 4+nc)
y = torch.cat((dec_bboxes.squeeze(0), dec_scores.squeeze(0).sigmoid()), -1)
# 如果是导出模式,只返回y;否则返回y和所有输出
return y if self.export else (y, x)
def _get_encoder_input(self, x: list[torch.Tensor]) -> tuple[torch.Tensor, list[list[int]]]:
"""
处理并返回编码器输入:从输入获取投影特征并进行拼接。
参数:
x (list[torch.Tensor]):来自骨干网络的特征图列表。
返回:
feats (torch.Tensor):处理后的特征。
shapes (list):特征图形状列表。
"""
# Get projection features # 获取投影特征
x = [self.input_proj[i](feat) for i, feat in enumerate(x)]
# Get encoder inputs # 获取编码器输入
feats = [] # 特征列表
shapes = [] # 形状列表
for feat in x: # 遍历每个特征图
h, w = feat.shape[2:] # 获取高度和宽度
# [b, c, h, w] -> [b, h*w, c] # 展平空间维度并转置
feats.append(feat.flatten(2).permute(0, 2, 1))
# [nl, 2] # 记录形状
shapes.append([h, w])
# [b, h*w, c] # 拼接所有特征
feats = torch.cat(feats, 1)
return feats, shapes # 返回特征和形状
def _get_decoder_input(
self,
feats: torch.Tensor,
shapes: list[list[int]],
dn_embed: torch.Tensor | None = None,
dn_bbox: torch.Tensor | None = None,
) -> tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]:
"""
从提供的特征和形状生成并准备解码器所需的输入。
参数:
feats (torch.Tensor):来自编码器的处理后的特征。
shapes (list):特征图形状列表。
dn_embed (torch.Tensor, 可选):去噪嵌入。
dn_bbox (torch.Tensor, 可选):去噪边界框。
返回:
embeddings (torch.Tensor):解码器查询嵌入。
refer_bbox (torch.Tensor):参考边界框。
enc_bboxes (torch.Tensor):编码边界框。
enc_scores (torch.Tensor):编码分数。
"""
bs = feats.shape[0] # 批量大小
# 如果需要动态生成锚点或形状发生变化
if self.dynamic or self.shapes != shapes:
# 生成锚点和有效掩码
self.anchors, self.valid_mask = self._generate_anchors(shapes, dtype=feats.dtype, device=feats.device)
self.shapes = shapes # 更新形状
# Prepare input for decoder # 准备解码器输入
# 编码器输出:有效掩码*特征
features = self.enc_output(self.valid_mask * feats) # bs, h*w, 256
# 编码器分数预测
enc_outputs_scores = self.enc_score_head(features) # (bs, h*w, nc)
# Query selection # 查询选择
# 获取top-k索引:选择每个批次中分数最高的num_queries个位置
# (bs*num_queries,)
topk_ind = torch.topk(enc_outputs_scores.max(-1).values, self.num_queries, dim=1).indices.view(-1)
# 创建批次索引:为每个查询点分配批次索引
# (bs*num_queries,)
batch_ind = torch.arange(end=bs, dtype=topk_ind.dtype).unsqueeze(-1).repeat(1, self.num_queries).view(-1)
# 根据索引选择top-k特征
# (bs, num_queries, 256)
top_k_features = features[batch_ind, topk_ind].view(bs, self.num_queries, -1)
# 根据索引选择top-k锚点
# (bs, num_queries, 4)
top_k_anchors = self.anchors[:, topk_ind].view(bs, self.num_queries, -1)
# Dynamic anchors + static content # 动态锚点+静态内容
# 参考边界框 = 编码器边界框预测 + top-k锚点
refer_bbox = self.enc_bbox_head(top_k_features) + top_k_anchors
# 编码边界框:sigmoid激活
enc_bboxes = refer_bbox.sigmoid()
# 如果有去噪边界框,将其与参考边界框拼接
if dn_bbox is not None:
refer_bbox = torch.cat([dn_bbox, refer_bbox], 1)
# 编码分数:根据索引选择top-k分数
enc_scores = enc_outputs_scores[batch_ind, topk_ind].view(bs, self.num_queries, -1)
# 嵌入:如果学习初始查询,使用目标嵌入;否则使用top-k特征
embeddings = self.tgt_embed.weight.unsqueeze(0).repeat(bs, 1, 1) if self.learnt_init_query else top_k_features
# 如果是训练模式,分离梯度
if self.training:
refer_bbox = refer_bbox.detach()
if not self.learnt_init_query:
embeddings = embeddings.detach()
# 如果有去噪嵌入,将其与嵌入拼接
if dn_embed is not None:
embeddings = torch.cat([dn_embed, embeddings], 1)
# 返回嵌入、参考边界框、编码边界框和编码分数
return embeddings, refer_bbox, enc_bboxes, enc_scores
def _reset_parameters(self):
"""
使用预定义的权重和偏置初始化或重置模型各组件的参数
"""
# Class and bbox head init # 类别和边界框头初始化
# 类别偏置初始化:基于概率的偏置初始化
bias_cls = bias_init_with_prob(0.01) / 80 * self.nc
# NOTE: the weight initialization in `linear_init` would cause NaN when training with custom datasets.
# linear_init(self.enc_score_head) # 注意:linear_init在自定义数据集训练时会导致NaN
# 编码器分数预测头偏置初始化
constant_(self.enc_score_head.bias, bias_cls)
# 编码器边界框预测头最后一层权重初始化为0
constant_(self.enc_bbox_head.layers[-1].weight, 0.0)
# 编码器边界框预测头最后一层偏置初始化为0
constant_(self.enc_bbox_head.layers[-1].bias, 0.0)
# 遍历解码器分数预测头和边界框预测头
for cls_, reg_ in zip(self.dec_score_head, self.dec_bbox_head):
# linear_init(cls_) # 注意:linear_init在自定义数据集训练时会导致NaN
# 解码器分数预测头偏置初始化
constant_(cls_.bias, bias_cls)
# 解码器边界框预测头最后一层权重初始化为0
constant_(reg_.layers[-1].weight, 0.0)
# 解码器边界框预测头最后一层偏置初始化为0
constant_(reg_.layers[-1].bias, 0.0)
# 编码器输出层初始化
linear_init(self.enc_output[0]) # 线性初始化
xavier_uniform_(self.enc_output[0].weight) # Xavier均匀初始化权重
# 如果学习初始查询,初始化目标嵌入权重
if self.learnt_init_query:
xavier_uniform_(self.tgt_embed.weight)
# 查询位置头权重初始化
xavier_uniform_(self.query_pos_head.layers[0].weight)
xavier_uniform_(self.query_pos_head.layers[1].weight)
# 输入投影层权重初始化
for layer in self.input_proj:
xavier_uniform_(layer[0].weight)v10Detect 类 - YOLOv10检测头
v10Detect 类实现YOLOv10的检测头,专注于端到端优化:
设计特点:
-
强制端到端 :
end2end = True(硬编码) -
双重分配:同时优化一对多和一对一分支
-
一致预测:确保两个分支预测一致性
-
轻量分类头:使用分组卷积优化效率
核心组件:
-
cv3:轻量分类头(分组卷积优化) -
one2one_cv3:一对一分类头(深度拷贝)
架构特点:
-
简化初始化 :直接调用父类
__init__并设置end2end=True -
结构优化:使用分组卷积减少计算量
-
专注端到端:所有设计围绕端到端优化
轻量分类头结构:
Conv(x, x, 3, g=x) → Conv(x, c3, 1)
Conv(c3, c3, 3, g=c3) → Conv(c3, c3, 1)
Conv(c3, nc, 1)使用分组卷积(g=x, g=c3)大幅减少参数
设计哲学:
-
在训练中同时优化两个分支
-
通过一致性损失确保预测对齐
-
推理时直接使用一对一分支
-
完全消除NMS需求
整体架构示意图如下所示:
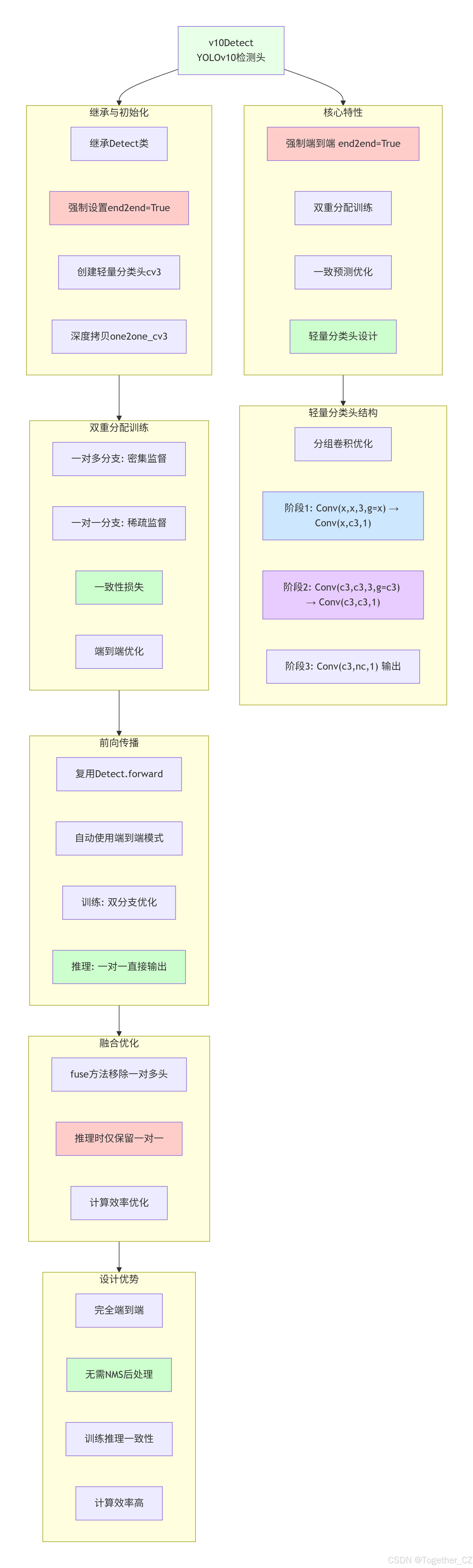
python
class v10Detect(Detect):
"""
YOLOv10 检测头,来自论文 https://arxiv.org/pdf/2405.14458。
该类实现了 YOLOv10 检测头,采用双分配训练和一致的双重预测,以提升效率和性能。
属性:
end2end (bool):端到端检测模式。
max_det (int):最大检测数量。
cv3 (nn.ModuleList):轻量分类头层。
one2one_cv3 (nn.ModuleList):一对一分类头层。
方法:
init:使用指定的类别数和输入通道初始化 v10Detect 对象。
forward:执行 v10Detect 模块的前向传播。
bias_init:初始化 Detect 模块的偏置。
fuse:移除一对多头以优化推理。
示例:
创建 v10Detect 检测头
v10_detect = v10Detect(nc=80, ch=(256, 512, 1024))
x = [torch.randn(1, 256, 80, 80), torch.randn(1, 512, 40, 40), torch.randn(1, 1024, 20, 20)]
outputs = v10_detect(x)
"""
end2end = True # 端到端检测模式,默认为True
def __init__(self, nc: int = 80, ch: tuple = ()):
"""
使用指定的类别数和输入通道初始化 v10Detect 对象。
参数:
nc (int):类别数量。
ch (tuple):骨干网络特征图的通道大小元组。
"""
# 调用父类Detect的初始化方法,设置end2end=True
super().__init__(nc, end2end=True, ch=ch)
# 计算轻量分类头的通道数
c3 = max(ch[0], min(self.nc, 100)) # channels
# Light cls head # 轻量分类头
# 创建轻量分类头列表
self.cv3 = nn.ModuleList(
nn.Sequential(
nn.Sequential(Conv(x, x, 3, g=x), Conv(x, c3, 1)), # 分组卷积 + 1x1卷积
nn.Sequential(Conv(c3, c3, 3, g=c3), Conv(c3, c3, 1)), # 分组卷积 + 1x1卷积
nn.Conv2d(c3, self.nc, 1), # 1x1卷积输出类别数
)
for x in ch
)
# 创建一对一分类头(深度复制)
self.one2one_cv3 = copy.deepcopy(self.cv3)
def fuse(self):
"""
移除一对多头以优化推理
"""
# 将一对多头设置为None
self.cv2 = self.cv3 = Nonehead模块核心设计模式总结:
核心类继承关系如下所示:
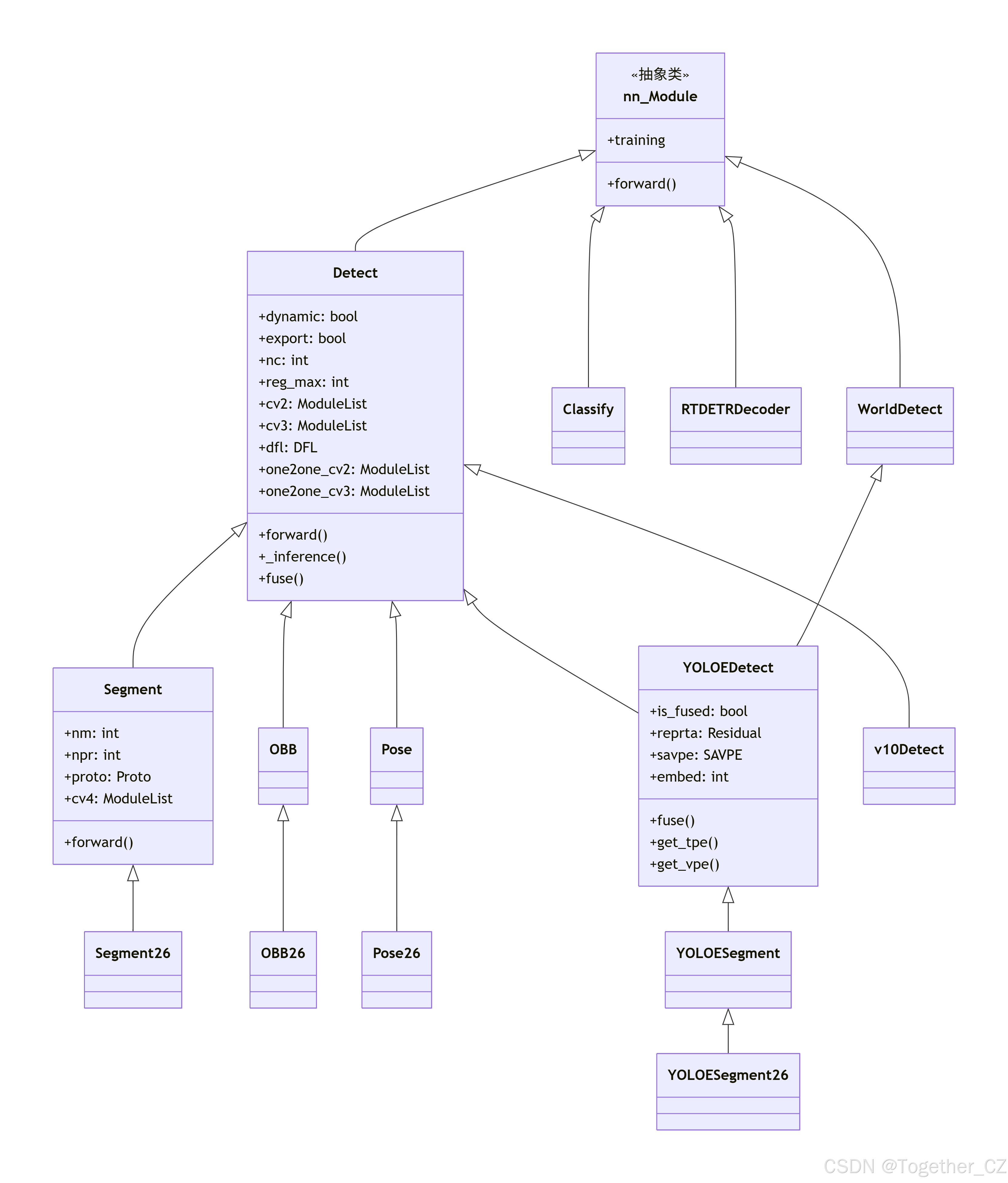
完整数据流转示意图如下所示:
训练阶段数据流如下所示:
推理阶段数据流如下所示: