探索华为CANN框架中的ACL仓库
探索华为CANN框架中的ACL仓库
华为的Compute Architecture for Neural Networks(CANN)是一个专为AI场景设计的异构计算平台,它将上层AI框架如MindSpore、PyTorch和TensorFlow与底层Ascend硬件连接起来,实现模型的编译、优化和部署。在CANN的核心组件中,Ascend Computing Language(ACL)扮演着关键角色,提供了一套编程接口,用于直接操作Ascend NPU硬件,实现高效的AI计算。
ACL仓库作为CANN组织的一部分,专注于提供Ascend计算语言的API和实现。这些API包括设备管理、内存分配、张量操作、流同步等基础功能,是开发者构建自定义AI应用的基石。ACL允许开发者绕过上层框架,直接与硬件交互,适用于需要极致性能优化的场景,如实时推理和大规模训练。通过ACL,开发者可以管理NPU设备、创建上下文、分配设备内存,并执行内核操作,从而充分利用Ascend芯片的计算能力。
CANN框架的架构设计精妙,将计算过程分为多个层级:前端框架适配、图优化、运算符库和运行时系统。ACL位于运行时层,提供低级API,支持C++和Python绑定,便于集成到各种应用中。例如,在MindSpore中,ACL被用于底层执行,确保模型在Ascend硬件上的高效运行。这不仅仅是API的集合,还涉及硬件特性的深度利用,如DaVinci架构的向量和立方体计算单元。
为了更好地理解ACL在CANN中的位置,我们可以看看CANN的架构图:
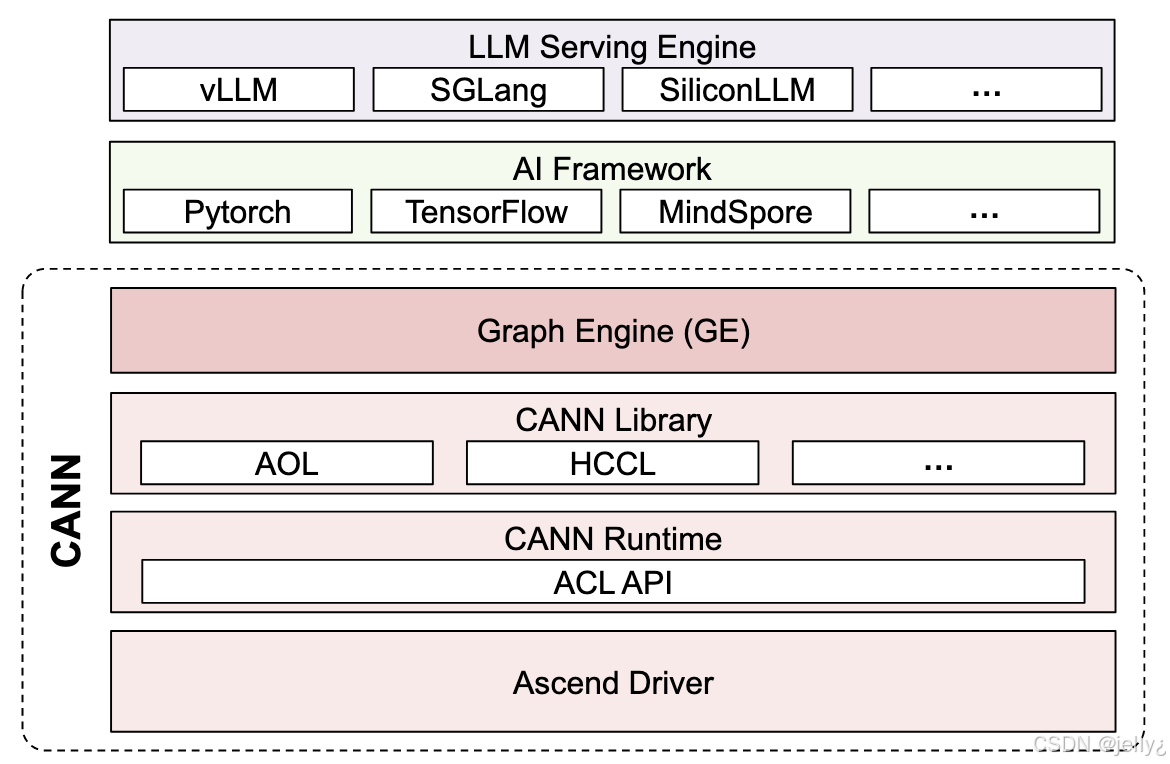
这个图展示了CANN库的结构,ACL API位于运行时层,支持上层库如AOL和HCCL的调用。
ACL仓库的核心功能
ACL仓库提供了丰富的API,用于Ascend设备的编程。首先是设备管理功能,包括aclInit初始化库、aclrtSetDevice设置设备、aclrtGetDeviceCount获取设备数量等。这些API确保开发者能正确初始化和选择NPU设备。
内存管理是ACL的另一核心,包括aclrtMalloc分配设备内存、aclrtMemcpy内存拷贝、aclrtFree释放内存。这些函数支持主机和设备间的数据传输,支持同步和异步模式,提高数据处理的效率。
张量操作API是ACL的亮点,如aclCreateTensorDesc创建张量描述、aclCreateDataBuffer创建数据缓冲区。这些API定义了张量的形状、数据类型和格式,支持NHWC、NCHW等多种布局,匹配Ascend硬件的优化需求。
流和事件管理功能允许并行执行,如aclrtCreateStream创建流、aclrtSynchronizeStream同步流。这在多任务AI应用中至关重要,能实现计算和数据传输的流水线并行。
此外,ACL支持模型加载和执行,通过aclmdlLoadFromFile加载模型、aclmdlExecute执行模型。这些API用于离线模型的推理,支持动态批处理和精度混合。
在兼容性方面,ACL与CANN的其他组件无缝集成。开发者可以使用Python绑定,在MindSpore脚本中调用ACL API,实现自定义优化。
以下是Ascend硬件架构的示意图,展示了Da Vinci AI Core的结构:
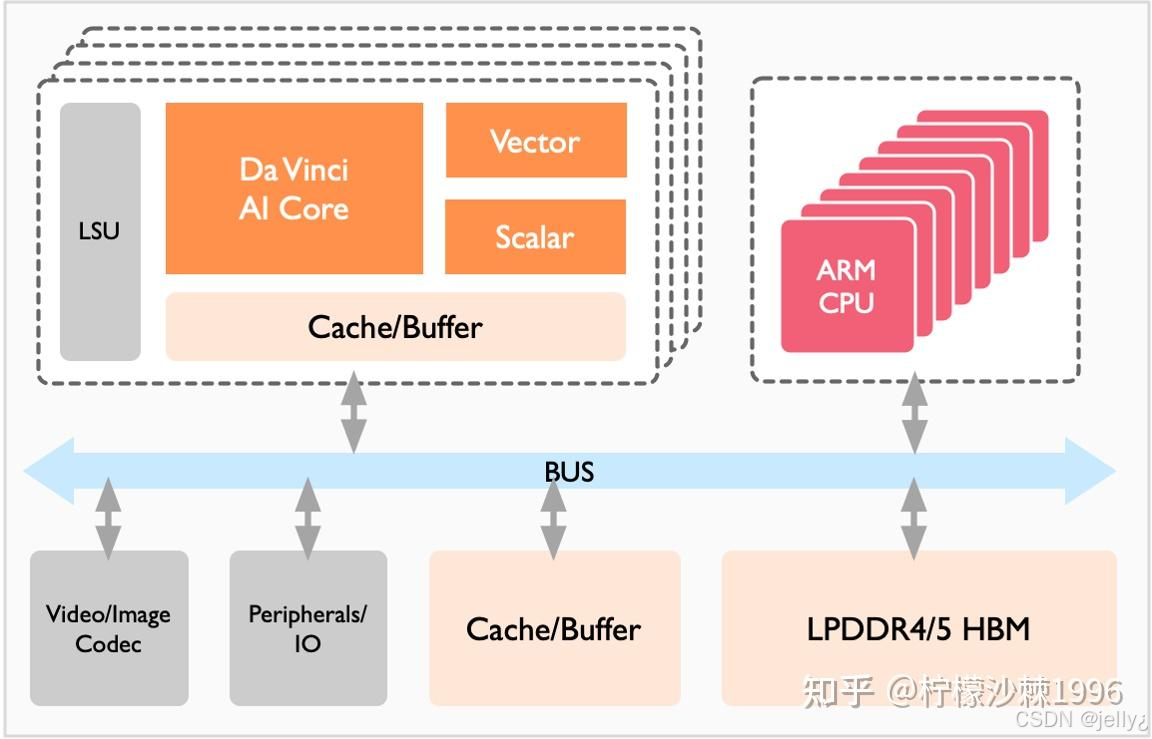
这个图解释了NPU内部的计算单元,ACL API正是针对这些单元设计的。
ACL的优化技术详解
ACL仓库的优化技术聚焦于硬件利用率。首先是异步执行模式。ACL支持异步内存拷贝和内核执行,通过流机制减少CPU等待时间,提高整体吞吐量。
其次是内存优化。ACL提供零拷贝机制,通过aclrtMallocHost分配 pinned 内存,减少数据传输开销。在大规模模型中,这能显著降低延迟。
自动量化支持是ACL的一项高级功能。API如aclSetTensorFormat允许设置低精度格式如INT8,支持模型从FP32到低精度的转换,同时保持精度。
ACL还集成图优化,通过aclmdlOptimize优化加载的模型,进行内核融合和子图分割,提高执行效率。
在调试方面,ACL提供aclrtSetOpWaitTimeout设置超时、aclGetRecentErrMsg获取错误信息,便于开发者诊断问题。
看看MindSpore与CANN的集成图:
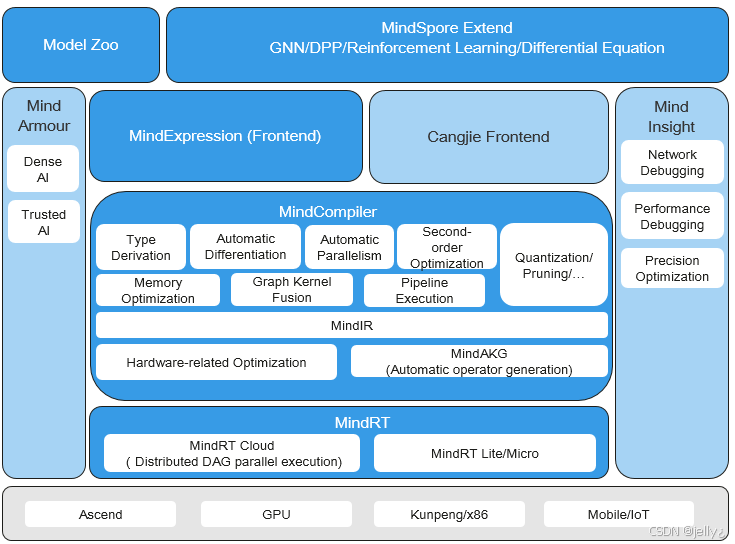
这个图展示了MindSpore的编译器和运行时如何依赖CANN的ACL,实现全场景部署。
ACL在实际应用中的案例
ACL仓库在AI应用中广泛使用。以图像处理为例,开发者可以使用ACL加载预训练模型,执行推理。在实时视频分析系统中,ACL的异步流管理确保帧处理不中断。
在自然语言处理中,ACL支持Transformer模型的执行。通过aclmdlSetDynamicBatchSize动态调整批大小,适应变长输入,提高效率。
推荐系统是另一个应用。ACL的内存管理用于处理海量 embedding,结合HCCL进行分布式计算,实现大规模用户推荐。
在医疗领域,ACL用于CT图像分割。开发者自定义内核,利用Ascend的向量单元加速卷积操作。
ACL鼓励开源贡献。仓库中包含示例代码,开发者可以fork并提交改进。
以下是另一个集成示意图:
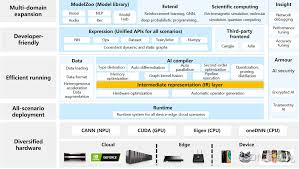
这个图强调了多域扩展,ACL作为底层支持。
ACL的代码实现示例
ACL仓库的代码结构包括头文件、源代码和示例。核心API用C++实现,Python绑定通过pybind11提供。
以下是一个简单的Python代码示例,使用ACL初始化设备并进行内存拷贝:
python
import acl
# 初始化ACL
ret = acl.init()
if ret != 0:
print("acl init failed")
# 获取设备数量
device_count = acl.rt.get_device_count()
print("device count:", device_count)
# 设置设备
ret = acl.rt.set_device(0)
if ret != 0:
print("set device failed")
# 分配主机内存
host_size = 1024
host_ptr, ret = acl.rt.malloc_host(host_size)
if ret != 0:
print("malloc host failed")
# 分配设备内存
device_ptr, ret = acl.rt.malloc(device_size, acl.mem_malloc_policy.ACL_MEM_MALLOC_NORMAL_ONLY)
if ret != 0:
print("malloc device failed")
# 内存拷贝:主机到设备
ret = acl.rt.memcpy(device_ptr, device_size, host_ptr, host_size, acl.memcpy_kind.ACL_MEMCPY_HOST_TO_DEVICE)
if ret != 0:
print("memcpy failed")
# 释放内存
acl.rt.free(device_ptr)
acl.rt.free_host(host_ptr)
# 重置设备
acl.rt.reset_device(0)
acl.finalize()这个示例展示了ACL的基本使用流程:初始化、内存分配、拷贝和释放。开发者可以基于此构建更复杂的应用。
另一个C++示例,展示张量创建:
cpp
#include "acl/acl.h"
int main() {
aclInit(nullptr);
aclrtSetDevice(0);
// 创建张量描述
aclTensorDesc* desc = aclCreateTensorDesc(ACL_FLOAT, 4, shape, ACL_FORMAT_NCHW);
if (desc == nullptr) {
std::cout << "create tensor desc failed" << std::endl;
return -1;
}
// 创建数据缓冲
aclDataBuffer* buffer = aclCreateDataBuffer(nullptr, 0);
if (buffer == nullptr) {
std::cout << "create data buffer failed" << std::endl;
return -1;
}
// 清理
aclDestroyDataBuffer(buffer);
aclDestroyTensorDesc(desc);
aclrtResetDevice(0);
aclFinalize();
return 0;
}这些代码片段来自ACL文档,展示了API的简洁性。
ACL的未来发展和挑战
未来,ACL将支持更多硬件,如新一代Ascend芯片。华为计划增强ACL的量子计算接口,探索混合AI。
挑战包括兼容性,需要更好支持ONNX等标准。性能方面,在超大规模模型中,内存管理需优化。
社区通过教程和文档促进参与。
另一个架构图:
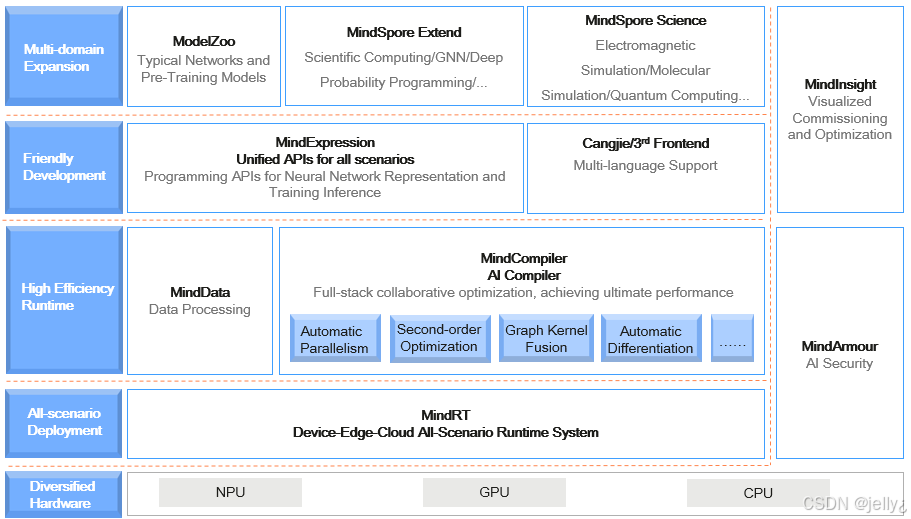
这个图展示了MindSpore的运行时,ACL的关键作用。
通过ACL,开发者能深入AI硬件编程,是CANN的宝贵资源。
结语
ACL仓库提供强大API,推动AI开发。适合追求性能的开发者。
更多CANN组织详情:https://atomgit.com/cann