机器学习算法原理与实践-入门(三):使用数学方法实现KNN
在前两篇文章中,我们已经掌握了KNN算法的理论基础和各种距离计算方式。今天,我们将进入真正的实践环节------不使用任何机器学习库,仅凭数学方法和Python基础功能,从零开始实现一个完整的KNN分类器。这个过程会让你真正理解算法的每个细节,而不仅仅是停留在"调用API"的层面。
一、从理论到实践:为什么要手动实现?
很多机器学习学习者习惯直接调用sklearn等现成库,这虽然能快速完成任务,但存在三个根本问题:
- 黑箱操作:只知道输入输出,不理解内部逻辑
- 调试困难:遇到问题时无法定位根本原因
- 能力局限:无法根据实际需求定制算法
通过手动实现KNN,你将获得:
- 对算法每个步骤的深刻理解
- 根据业务需求调整算法的能力
- 调试和优化机器学习模型的基础技能
这就像学习开车:自动挡能让你快速上路,但只有学会手动挡,才能真正理解汽车的运作原理。
二、KNN算法的数学骨架:三步走策略
从数学角度看,KNN算法可以分解为三个核心步骤,每个步骤都有明确的数学原理支撑:
1. 距离计算:量化相似性
数学本质:在多维空间中定义"远近"关系
对于二维空间中的两点A(x₁, y₁)和B(x₂, y₂),欧氏距离公式为:
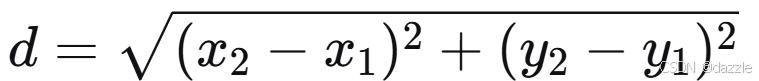
这个公式扩展到n维空间后,就是我们之前学习的欧氏距离通用形式。
2. 近邻搜索:找出K个最相似的样本
数学本质:排序与选择问题
假设有m个训练样本,我们需要:
- 计算测试点到每个训练点的距离(m次计算)
- 从m个距离值中找出最小的K个
- 记录这K个最近邻居的索引和距离
3. 投票决策:基于多数原则分类
数学本质:统计推断
对于分类问题:
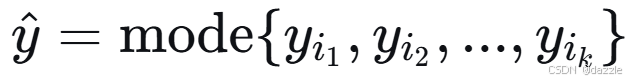
三、手动实现KNN:代码逐行解析
python
import numpy as np
from matplotlib import pyplot as plt
from collections import Counter
# ============ 第一步:准备数据 ============
# 定义三个类别的训练数据点
point1 = [[7.7, 6.1], [3.1, 5.9], [8.6, 8.8], [9.5, 7.3], [3.9, 7.4], [5.0, 5.3], [1.0, 7.3]]
point2 = [[0.2, 2.2], [4.5, 4.1], [0.5, 1.1], [2.7, 3.0], [4.7, 0.2], [2.9, 3.3], [7.3, 7.9]]
point3 = [[9.2, 0.7], [9.2, 2.1], [7.3, 4.5], [8.9, 2.9], [9.5, 3.7], [7.7, 3.7], [9.4, 2.4]]
# 合并所有数据点到一个数组中
# np.concatenate函数将多个数组合并,axis=0表示按行合并
train_data = np.concatenate((point1, point2, point3), axis=0)
# 创建对应的标签数组
# 0表示第一类,1表示第二类,2表示第三类
train_label = np.array([0] * len(point1) + [1] * len(point2) + [2] * len(point3))
# 定义测试点
test_point = [3.3, 4.2]
# ============ 第二步:设置K值 ============
# K是KNN算法的核心参数,表示要考虑的最近邻居数量
k = 3 # 通常取奇数,避免投票平局
# ============ 第三步:计算距离 ============
# 使用广播机制计算测试点到所有训练点的欧氏距离
# 广播机制:test_point会被自动复制扩展,与train_data的每一行进行计算
# (test_point - train_data) ** 2 计算每个维度的平方差
# np.sum(..., axis=1) 对每个点的所有维度求和
# np.sqrt(...) 对每个和开平方,得到欧氏距离
distances = np.sqrt(np.sum((test_point - train_data) ** 2, axis=1))
# 打印计算出的距离,便于理解
print("测试点到每个训练点的距离:")
for i, dist in enumerate(distances):
print(f"训练点{i}: ({train_data[i][0]:.1f}, {train_data[i][1]:.1f}) -> 距离: {dist:.2f}")
# ============ 第四步:找出K个最近邻居 ============
# np.argsort返回距离从小到大的索引
sorted_indices = np.argsort(distances)
# 获取最近的k个邻居的索引
nearest_indices = sorted_indices[:k]
# 收集最近邻居的信息
nearest_points = [] # 最近邻居的坐标
nearest_distances = [] # 最近邻居的距离
nearest_labels = [] # 最近邻居的标签
for idx in nearest_indices:
nearest_points.append(train_data[idx])
nearest_distances.append(distances[idx])
nearest_labels.append(train_label[idx])
# 打印最近邻居的信息
print(f"\n最近的{k}个邻居:")
for i in range(k):
print(f"邻居{i+1}: 坐标({nearest_points[i][0]}, {nearest_points[i][1]}), "
f"距离: {nearest_distances[i]:.2f}, 标签: {nearest_labels[i]}")
# ============ 第五步:投票决定类别 ============
# 使用Counter统计最近邻居中各类别的数量
label_counter = Counter(nearest_labels)
# most_common返回出现次数最多的元素及其计数
most_common_label = label_counter.most_common()[0][0]
print(f"\n投票结果:")
for label, count in label_counter.items():
print(f"标签{label}: {count}票")
print(f"预测结果:测试点属于类别 {most_common_label}")
# ============ 第六步:可视化展示 ============
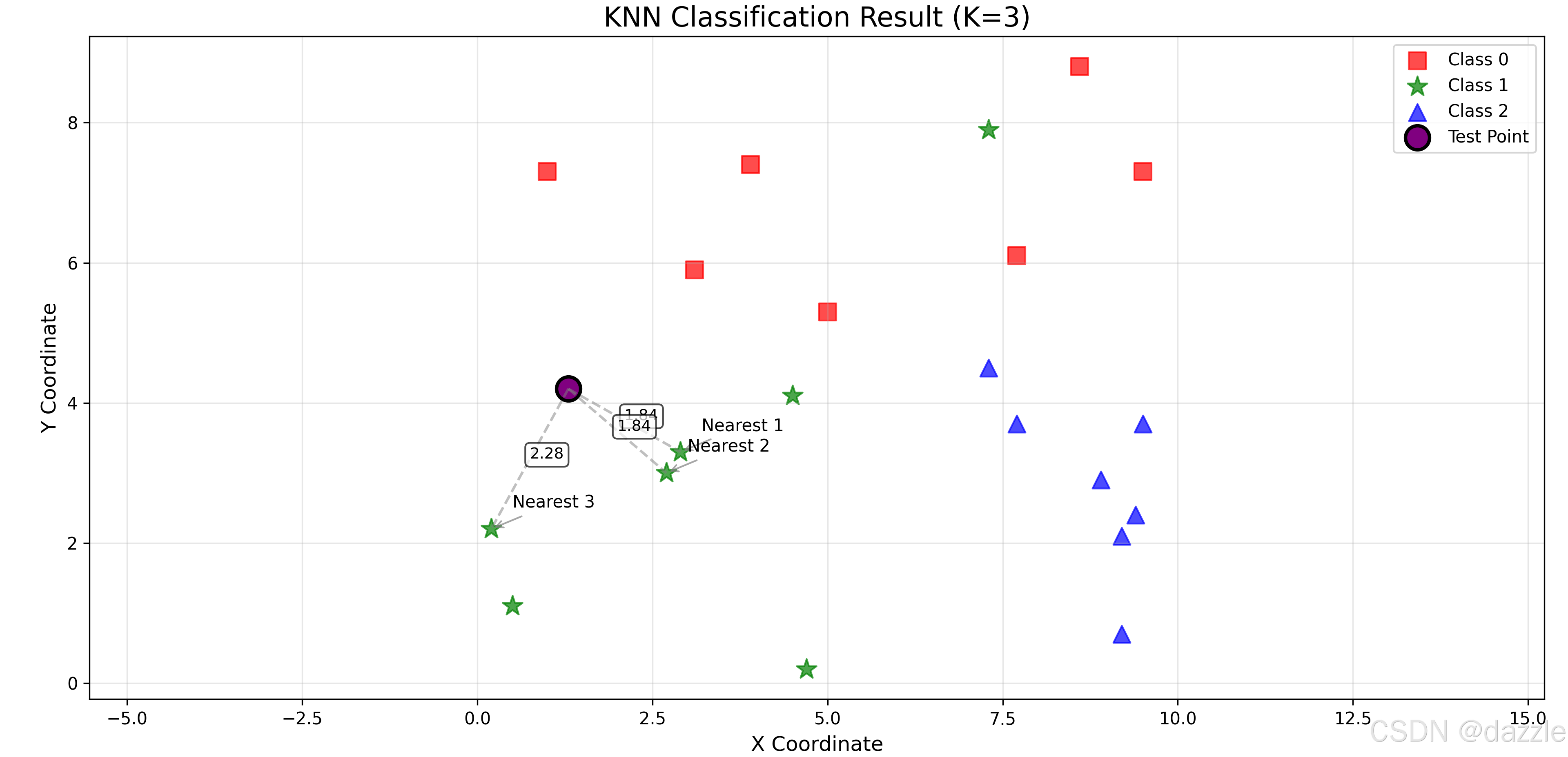
plt.figure(figsize=(10, 8))
plt.title(f"KNN Classification Result (K={k})", fontsize=16)
# 绘制三类训练数据点
plt.scatter(train_data[train_label == 0, 0], train_data[train_label == 0, 1],
marker='s', s=100, label='Class 0', color='red', alpha=0.7)
plt.scatter(train_data[train_label == 1, 0], train_data[train_label == 1, 1],
marker='*', s=150, label='Class 1', color='green', alpha=0.7)
plt.scatter(train_data[train_label == 2, 0], train_data[train_label == 2, 1],
marker='^', s=100, label='Class 2', color='blue', alpha=0.7)
# 绘制测试点
plt.scatter(test_point[0], test_point[1],
marker='o', s=200, label='Test Point', color='purple', edgecolors='black', linewidths=2)
# 绘制测试点到最近邻居的连线
for i in range(k):
# 绘制连线
plt.plot([test_point[0], nearest_points[i][0]],
[test_point[1], nearest_points[i][1]],
'gray', linestyle='--', alpha=0.5)
# 在连线中点标注距离
mid_x = (test_point[0] + nearest_points[i][0]) / 2
mid_y = (test_point[1] + nearest_points[i][1]) / 2
plt.annotate(f"{nearest_distances[i]:.2f}",
xy=(mid_x, mid_y),
xytext=(mid_x, mid_y),
fontsize=9,
bbox=dict(boxstyle="round,pad=0.3", facecolor="white", alpha=0.7))
# 标注最近邻居
for i, point in enumerate(nearest_points):
plt.annotate(f"Nearest {i+1}",
xy=(point[0], point[1]),
xytext=(point[0]+0.3, point[1]+0.3),
arrowprops=dict(arrowstyle="->", color="gray", alpha=0.7))
# 设置图形属性
plt.xlabel('X Coordinate', fontsize=12)
plt.ylabel('Y Coordinate', fontsize=12)
plt.legend()
plt.grid(True, alpha=0.3)
plt.axis('equal') # 确保坐标轴比例一致
# 显示图形
plt.tight_layout()
plt.show()四、代码实现的关键技术点
1. NumPy的广播机制
代码中(test_point - train_data) ** 2这一行利用了NumPy的广播机制。虽然test_point是形状为(2,)的一维数组,而train_data是形状为(21, 2)的二维数组,但NumPy会自动将test_point扩展为(21, 2)的数组,然后进行逐元素运算。
2. 距离计算的向量化实现
传统的for循环方式:
python
distances = []
for point in train_data:
dist = np.sqrt((test_point[0]-point[0])**2 + (test_point[1]-point[1])**2)
distances.append(dist)向量化实现:
python
distances = np.sqrt(np.sum((test_point - train_data) ** 2, axis=1))性能对比:向量化实现比循环实现快数十倍,这是科学计算中的常用优化技巧。
3. 索引排序与选择
np.argsort(distances)返回的是排序后的索引,而不是距离值本身。这使我们能够:
- 保持距离数组不变
- 通过索引同时访问距离、坐标和标签
- 选择前k个最小距离对应的所有信息
4. 多数投票的简洁实现
使用collections.Counter可以优雅地统计最近邻居中各类别的数量:
python
from collections import Counter
label_counter = Counter(nearest_labels)
most_common_label = label_counter.most_common()[0][0]与scikit-learn实现的对比
我们的实现 vs scikit-learn实现
| 特性 | 我们的实现 | scikit-learn实现 |
|---|---|---|
| 代码行数 | 约60行 | 3行(调用API) |
| 灵活性 | 完全可控,可任意修改 | 受限于API设计 |
| 性能 | 基础实现,未经优化 | 高度优化,支持多种加速算法 |
| 功能完整性 | 基础KNN功能 | 完整功能,支持多种参数配置 |
| 学习价值 | 深入理解算法细节 | 快速应用 |
何时使用手动实现?
- 学习阶段:深入理解算法原理
- 特殊需求:需要定制化的距离度量或投票策略
- 教学演示:向他人讲解算法细节
- 资源受限:无法安装大型机器学习库的环境
何时使用scikit-learn?
- 生产环境:需要稳定、高效的实现
- 快速原型:快速验证想法
- 复杂任务:需要集成多种算法
- 团队协作:使用标准接口便于协作
下一篇预告
在掌握了KNN算法的手动实现后,我们将进入机器学习中另一个核心概念的学习:
机器学习算法原理与实践-入门(四):前向传播与损失函数
我们将从神经网络的基础开始,深入理解信息如何在网络中流动,以及如何通过损失函数来衡量预测的好坏。这是理解深度学习的关键第一步。