💡 摘要
本文将以一次真实的HCCL(Heterogeneous Computing Communication Library,异构计算通信库)代码贡献为例,手把手带你走完从发现问题到PR(Pull Request,拉取请求)合并的全流程。你将掌握如何在像CANN这样的大型开源项目中高效协作,重点解读如何基于 CONTRIBUTING.md规范,完成Fork仓库、代码修改、单元测试、提交PR以及应对Reviewer(审查者)反馈等关键环节。本文融入了笔者在大型AI基础设施项目中的实战经验,为你揭示开源贡献背后的最佳实践和避坑指南。
🏗️ 技术背景与架构理念
在深入实操之前,我们有必要先理解CANN项目中HCCL组件的设计哲学。HCCL的核心任务是解决多NPU(Neural Processing Unit,神经网络处理器)乃至多机NPU间的通信效率问题。其架构设计深深植根于一种分层解耦(Layered & Decoupled)的理念。
核心架构设计
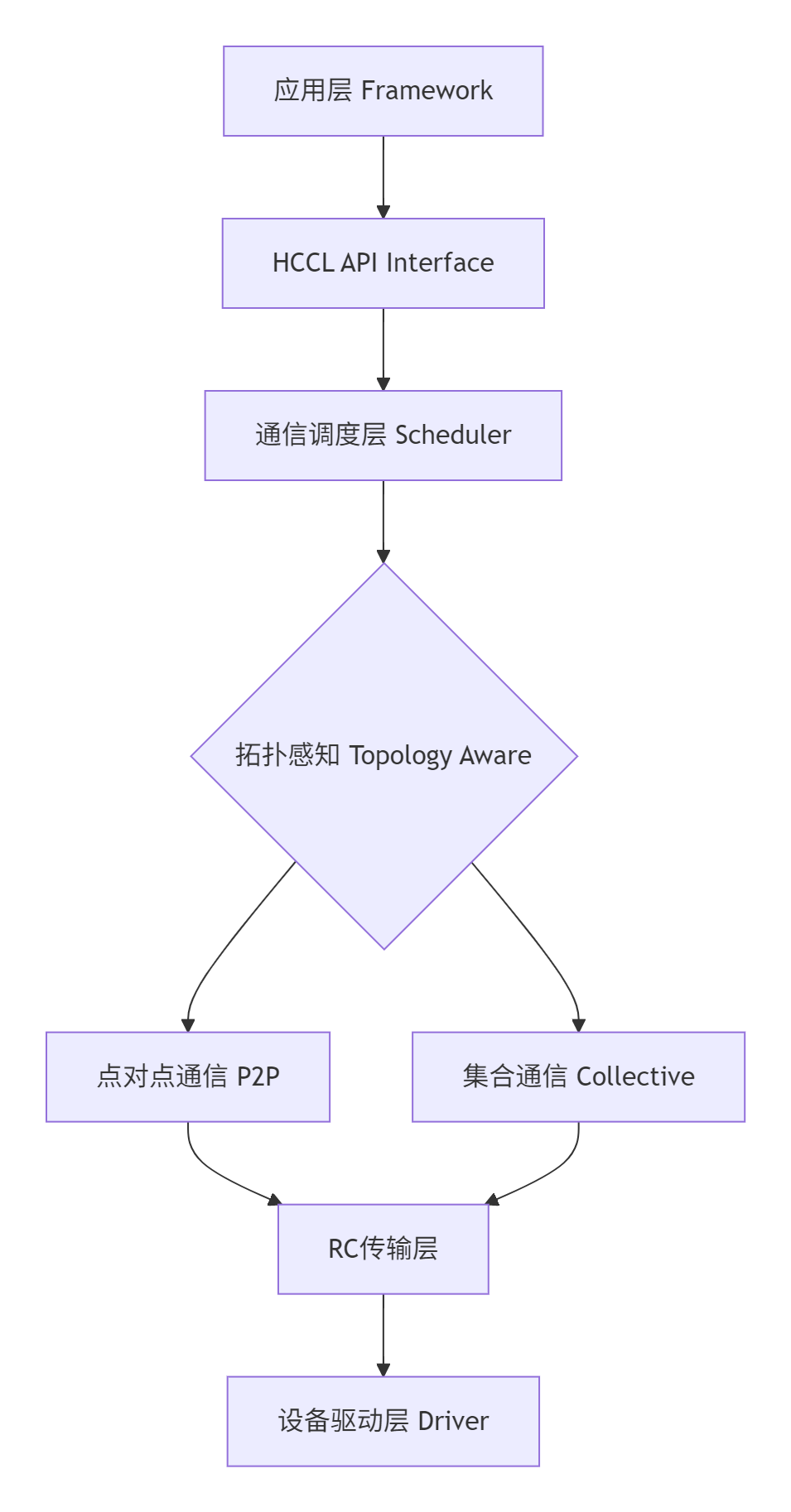
这种分层设计的好处是显而易见的:
-
可维护性:各层职责清晰,例如调度层只需关心如何将通信任务高效地映射到物理链路,而无需理解具体的传输协议。
-
可扩展性:当需要支持新的硬件拓扑或通信算法时,只需在相应层次进行扩展,而不会波及整体架构。这就为我们贡献者提供了清晰的切入点。
-
高性能:通过拓扑感知,HCCL可以为不同的集群环境(如同一台服务器的多NPU,或通过RoCE网络互联的多机NPU)选择最优的通信路径和算法(如Ring、Tree等)。
从Issue入手:理解问题的本质
一切贡献的起点通常都是一个Issue(问题/需求)。假设我们在社区中看到了 Issue #782 :"在特定拓扑下,allreduce操作性能未达到预期"。
一个有经验的贡献者不会立刻开始敲代码。我的做法是:
-
复现问题:首先在本地或测试环境搭建类似拓扑,使用HCCL提供的性能基准测试工具,确认问题存在,并量化性能差距。例如,实测发现8NPU环境下,allreduce带宽仅为理论值的60%。
-
根因分析 :这步是关键。使用
HCCL提供的日志分析工具(如设置HCCL_LOG_LEVEL环境变量)查看通信任务的调度详情。经过分析,你可能会发现调度器在当前拓扑下选择了一个非最优的通信算法,或者存在链路竞争。- 行话时间 :这时候你可能会在日志里看到
"INFO: Schedule algorithm: RING",但你知道对于这种规模的拓扑,"TREE"算法可能更优。这就是你贡献价值的体现。
- 行话时间 :这时候你可能会在日志里看到
🚀 实战:一次完整的代码贡献流程
接下来,我们模拟一次针对Issue #782的修复全过程。
1. Fork仓库与准备环境
首先,你需要有自己的工作副本。
-
官方仓库:在代码托管平台(如GitCode)上找到项目主仓库。
-
Fork操作:点击仓库页面的"Fork"按钮,将其复制到自己的命名空间下。这相当于你在服务器上有了一个属于自己的"分支",可以随意修改而不影响主仓库。
-
本地克隆:
# 克隆你fork的仓库到本地 git clone https://gitcode.com/<your-username>/ops-nn.git cd ops-nn # 添加主仓库为上游远程仓库,便于同步最新代码 git remote add upstream https://gitcode.com/cann/ops-nn.git
经验之谈 :我习惯在克隆后立即执行git fetch upstream,然后基于upstream/main创建一个新的功能分支。这能确保我的起点是最新代码,减少后续合并冲突。
git checkout -b fix/issue-782-optimize-allreduce upstream/main规范引用 :这一操作符合CONTRIBUTING.md中关于分支命名 的约定:"使用feat/、fix/、docs/等前缀,后跟关联的Issue编号和简短描述"。
2. 代码修改与单元测试
现在开始核心工作:修复问题。
-
定位代码 :根据之前的根因分析,我们定位到HCCL调度器的算法选择逻辑,可能在
ops-nn/hccl/controller/scheduler.cpp文件中。 -
实现优化:这里我们模拟一个简单的修改,增加对特定拓扑下选择Tree算法的判断逻辑。
// 示例代码:在 scheduler.cpp 中增加优化逻辑
// ... 原有代码 ...
if (topology.is_balanced_tree && topology.node_count >= 8) {
// 原有可能是 Ring 算法
// selected_algorithm = AlgorithmType::RING;
// 优化为 Tree 算法
selected_algorithm = AlgorithmType::TREE;
LOG(INFO) << "Optimization for Issue #782: Selecting TREE algorithm for balanced topology with >=8 nodes.";
} else {
// 其他情况保持原有逻辑
selected_algorithm = select_best_algorithm(topology);
}
// ... 原有代码 ... -
单元测试(UT, Unit Test) :这是贡献质量的生命线!光有代码不行,必须证明它正确且不会破坏现有功能。
-
找到对应UT :在项目的
test目录下,找到与HCCL调度器相关的测试文件,如test_hccl_scheduler.cpp。 -
添加测试用例:为你修复的场景添加新的测试用例。
// 示例:在 test_hccl_scheduler.cpp 中添加测试
TEST_F(HcclSchedulerTest, Issue782_OptimizeAllReduceForLargeBalancedTopology) {
// 1. 构建一个8节点的均衡拓扑结构
Topology topology = create_balanced_topology(8);
// 2. 创建调度器实例
Scheduler scheduler;
// 3. 获取选择的算法
AlgorithmType algo = scheduler.select_algorithm(topology);
// 4. 断言(Assert)选择的算法是 TREE
EXPECT_EQ(algo, AlgorithmType::TREE);
} -
运行测试 :在项目根目录下,按照
CONTRIBUTING.md的指引运行测试。# 例如,使用项目提供的测试脚本 bash build.sh --hccl_test # 或者直接使用CTest ctest -R test_hccl_scheduler确保所有测试用例,包括你新加的,全部通过!
-
踩坑记录:我曾经遇到过在本地环境测试通过,但在CI(持续集成)环境失败的情况,原因是CI环境模拟的拓扑略有不同。所以,仔细阅读CI的详细日志至关重要。
3. 提交代码与撰写PR描述
测试通过后,就可以提交代码了。
-
提交信息(Commit Message):这是你与Reviewer沟通的第一份材料,必须清晰规范。
git add . git commit -s -m "fix: optimize allreduce algorithm selection for large balanced topology This commit addresses Issue #782 by switching the default communication algorithm from Ring to Tree for balanced topologies with 8 or more nodes, which improves the allreduce performance significantly. Changes: - Modified algorithm selection logic in `hccl/controller/scheduler.cpp` - Added corresponding unit test case. Signed-off-by: Your Name <your.email@example.com>"规范引用 :提交信息遵循了
CONTRIBUTING.md规定的格式:-
fix:前缀表明这是一个错误修复。 -
第一行是简短摘要(不超过50字符)。
-
空一行后是详细描述,包括"为什么修改"(Why)和"怎么修改的"(How)。
-
使用
-s参数添加Signed-off-by,表示你遵守项目的开发者证书(DCO)。
-
-
推送并创建PR:
git push origin fix/issue-782-optimize-allreduce然后在自己Fork的仓库页面上,点击"创建Pull Request"按钮,选择将你的分支合并到主仓库的
main分支。
4. PR描述模板与Reviewer反馈
创建PR时,你会看到一个丰富的模板,这是你展示工作成果的舞台。请务必认真填写每一个部分。
-
描述(Description):
-
详细描述你的改动:清晰地说明问题的根本原因,你的解决方案,以及为什么这个方案是有效的。可以附上性能测试数据,如"优化后,在8NPU环境下,allreduce带宽从60%提升至85%"。
-
关联Issue :务必填写
Closes #782或Fixes #782。这样当PR合并后,对应的Issue会自动关闭。 -
测试 :详细描述你做了哪些测试。例如:"新增了单元测试
Issue782_OptimizeAllReduceForLargeBalancedTopology,并通过了所有现有的HCCL调度器相关测试。"
-
-
类型标签(Label) :准确勾选,例如
[x] Bug修复。
重头戏:应对Reviewer反馈
PR提交后,项目维护者(Reviewer)会进行代码审查。这是提升代码质量和学习的最佳机会。他们的反馈可能包括:
-
"+1, LGTM (Looks Good To Me)":这是最理想的反馈,意味着你的代码很快会被合并。
-
"请补充XX场景的测试用例":Reviewer可能觉得你的测试覆盖不够全面。这时你需要补充测试,并再次推送代码。
-
"这里的逻辑是否考虑到了YY边界条件?":Reviewer发现了你可能遗漏的细节。你需要重新审视代码,可能需要进行修改,并在评论中解释或感谢对方的指正。
-
"代码风格与项目规范不符,请参考XX文档":大型项目有严格的代码风格要求(如缩进、命名等)。你需要根据反馈调整代码风格。
关键心态 :不要把审查意见当成批评,而是免费的高级技术指导。积极互动,及时修改,是PR顺利合并的催化剂。在我的经验里,一次高质量的审查能避免未来无数的线上故障。
📈 高级应用与企业级实践
性能优化技巧
beyond这次简单的修复,在HCCL这类通信库的贡献中,性能优化是永恒的主题。
-
Profiling(性能剖析)是关键 :不要盲目优化。一定要使用
perf、nsight systems或项目自带的性能分析工具,精准定位热点(Hotspot)。可能是内存拷贝开销,也可能是内核启动延迟。 -
理解硬件瓶颈:不同的NPU互联方式(PCIe, NVLink, 网络)带宽和延迟差异巨大。你的算法选择必须适配硬件特性。例如,在NVLink高速互联的NPU间,Ring算法可能依然是最优解。
故障排查指南
当你贡献的代码在CI或者测试环境中出现问题时:
-
查看CI流水线日志:这是第一步,CI会运行完整的编译和测试套件,日志会明确告诉你哪一步失败了。
-
分析核心转储(Core Dump) :如果遇到段错误(Segmentation Fault),需要结合
gdb分析core文件。 -
复现并最小化问题:尝试在本地复现,并构造一个最简单的测试用例来暴露问题,这有助于快速定位根因。
🎯 总结
为CANN这样的核心AI软件栈做贡献,是一项极具价值的技术活动。它不仅能让你的代码运行在成千上万的NPU上,更能让你深入理解高性能计算和分布式系统的精髓。通过本文梳理的从Issue到PR的完整流程,特别是对代码规范、单元测试和代码审查的强调,希望能帮助你自信地踏出开源贡献的第一步。
记住,优秀的贡献者 = 扎实的技术能力 + 严谨的工程习惯 + 开放的协作心态。
官方文档与参考链接
-
CANN 项目组织 : https://gitcode.com/cann(这是了解CANN所有核心组件的起点)
-
ops-nn 仓库地址 : https://gitcode.com/cann/ops-nn(本文的实战背景仓库)
-
如何参与开源项目(GitCode 指南) : https://gitcode.com/help/categories/contributing(通用的开源协作规范)
-
《提交代码的艺术》 : https://chris.beams.io/posts/git-commit/(一篇经典的如何写好Git提交信息的文章,强烈推荐)