一、缓存基础知识点
1.1 缓存的核心意义
缓存是系统性能调优的核心手段,核心价值体现在:
- 降低系统响应时间,减少网络传输和应用延迟;
- 提高系统吞吐量,支持更多并发用户数;
- 复用数据、减少后端数据源(如 MySQL)的访问压力,保护后端服务;
- 降低带宽使用,节省资源成本。
核心原则:缓存离用户越近,性能提升效果越显著。
1.2 缓存的全层级分类
缓存不只有 Redis,而是覆盖客户端 - 网络 - 服务端的全层级体系,不同层级的缓存适用场景和实现方式不同。
| 缓存层级 | 细分类型 | 核心实现 / 技术 | 适用场景 |
|---|---|---|---|
| 客户端缓存 | 页面缓存 | HTML5 localStorage、离线应用缓存 | 前端页面静态资源、离线应用 |
| 浏览器缓存 | HTTP 头(Expires/Cache-Control/ETag)、if-modified-since | 浏览器端静态资源(图片、CSS、JS) | |
| APP 缓存 | 内存、本地文件、SQLite | 移动端 APP 本地数据存储 | |
| 网络缓存 | Web 代理缓存 | 正向代理(Squid)、反向代理(Nginx) | 企业网络加速、服务端静态资源缓存 |
| 边缘缓存 | Varnish、CDN(Cloud Front/ChinaCache) | 跨地域静态资源分发、高并发静态请求 | |
| 服务端缓存 | 数据库缓存 | InnoDB buffer pool、join_buffer 等 MySQL 缓存参数 | 数据库层 IO 性能优化 |
| 应用级缓存 | Java 缓存框架(Ehcache、Voldemort) | 应用内本地缓存、分布式应用级数据缓存 | |
| 平台级缓存 | 分布式缓存中间件(Redis、Memcached)、MongoDB(少用) | 跨应用 / 服务的分布式数据缓存 |
1.3 服务端缓存核心技术
(1)数据库缓存(MySQL)
- 核心参数 :
innodb_buffer_pool_size是 InnoDB 引擎性能调优的核心,建议设置为物理内存的 50%,并配合innodb_buffer_pool_instances提升并发; - 调优原则:将尽可能多的索引和数据放入缓存,减少磁盘 IO。
(2)应用级缓存(Java 特有)
- Ehcache:轻量级 Java 本地缓存框架,支持内存 + 磁盘存储;
- Voldemort:基于 Java 的分布式键值缓存,Amazon Dynamo 开源实现,支持多节点缓存同步,LinkedIn 核心技术。
(3)平台级缓存
- Redis/Memcached:Java 分布式缓存的主流选择,Redis 支持持久化、丰富数据结构,Memcached 专注于纯内存缓存;
- 面试考点:Redis 与 Memcached 的区别 、Redis 作为缓存的核心优势。
二、缓存一致性解决方案
使用缓存必然存在缓存与数据库数据不一致 的问题,核心原因是缓存无法感知数据库的修改,在Java 开发中主要围绕MySQL+Redis组合解决该问题。
2.1 核心问题前提
缓存的基础读取逻辑:先读缓存,缓存命中则返回;缓存未命中则读数据库,再将数据写入缓存,该逻辑是所有一致性方案的基础。
2.2 四种工程实践方案分析
方案 1:先更新缓存,再更新 DB(已淘汰方案)
核心问题 :缓存更新成功,数据库更新异常时,缓存与数据库数据永久不一致,且问题难以察觉;面试结论:实际开发中完全不使用,面试中需明确说明缺陷。
方案 2:先更新 DB,再更新缓存(已淘汰方案)
核心问题 :数据库更新成功,缓存更新失败(如网络异常、Redis 宕机),依然会导致数据不一致;额外缺陷 :若多个更新请求并发,会导致缓存被重复更新,浪费性能;面试结论 :实际开发中完全不使用,需说明更新失败的一致性问题 和并发更新的性能问题。
方案 3:先删除缓存,后更新 DB(有缺陷,可优化)
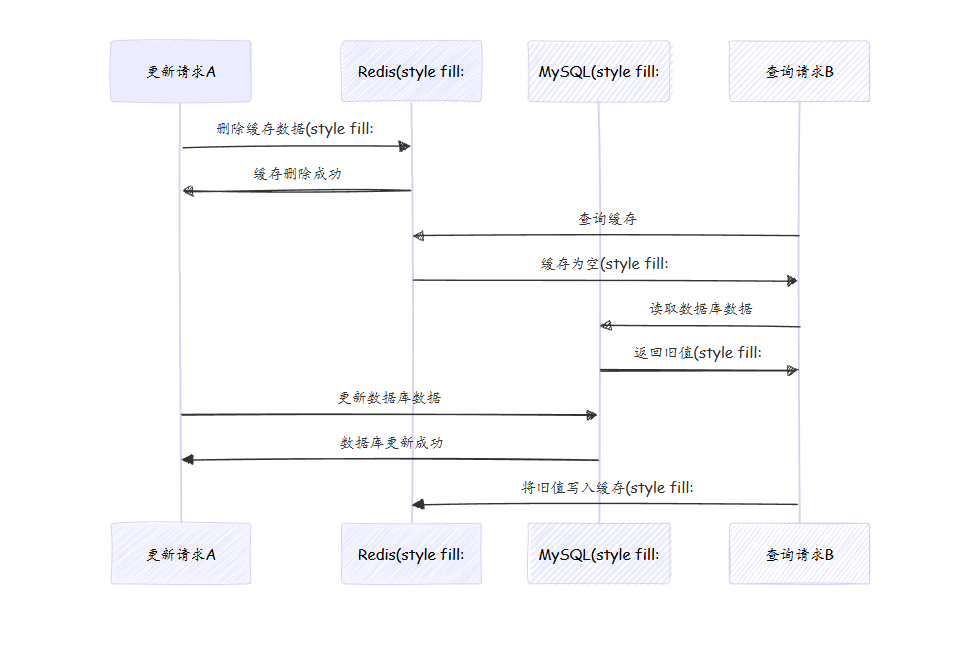
基本逻辑 :删除缓存数据 → 更新数据库 → 后续查询重新加载缓存;核心并发问题 :更新请求与查询请求并发时,会产生脏数据,具体流程:
- 请求 A(更新)删除 Redis 缓存;
- 请求 B(查询)发现缓存为空,读取数据库旧值;
- 请求 A(更新)完成数据库更新;
- 请求 B(查询)将旧值写入 Redis,导致缓存与数据库不一致。
脏数据产生流程示例:
**优化方案:延时双删策略(面试高频)**解决脏数据的核心方案,流程为:
- 先删除缓存;
- 再更新数据库;
- 休眠指定时间,再次删除缓存;
核心原理 :删除 1 秒内查询请求写入的脏数据,休眠时间为 读业务逻辑耗时 + 几百 ms,确保读请求完成后再删除脏数据。
读写分离架构下的额外问题与解决若 MySQL 采用读写分离,主库更新后从库同步存在延时,查询请求会从从库读取旧值,优化方案:
- 延时双删的休眠时间改为主从同步延时 + 几百 ms;
- 缓存填充的查询请求强制指向主库。
延时双删的性能优化 :将第二次删除改为异步线程执行,避免写请求阻塞,提升系统吞吐量。
方案 4:先更新 DB,后删除缓存(推荐,Cache Aside 核心)
基本逻辑 :更新数据库 → 删除缓存 → 后续查询重新加载最新数据;是 Java 开发中 MySQL+Redis 组合的主流方案。
(1)并发脏数据问题分析
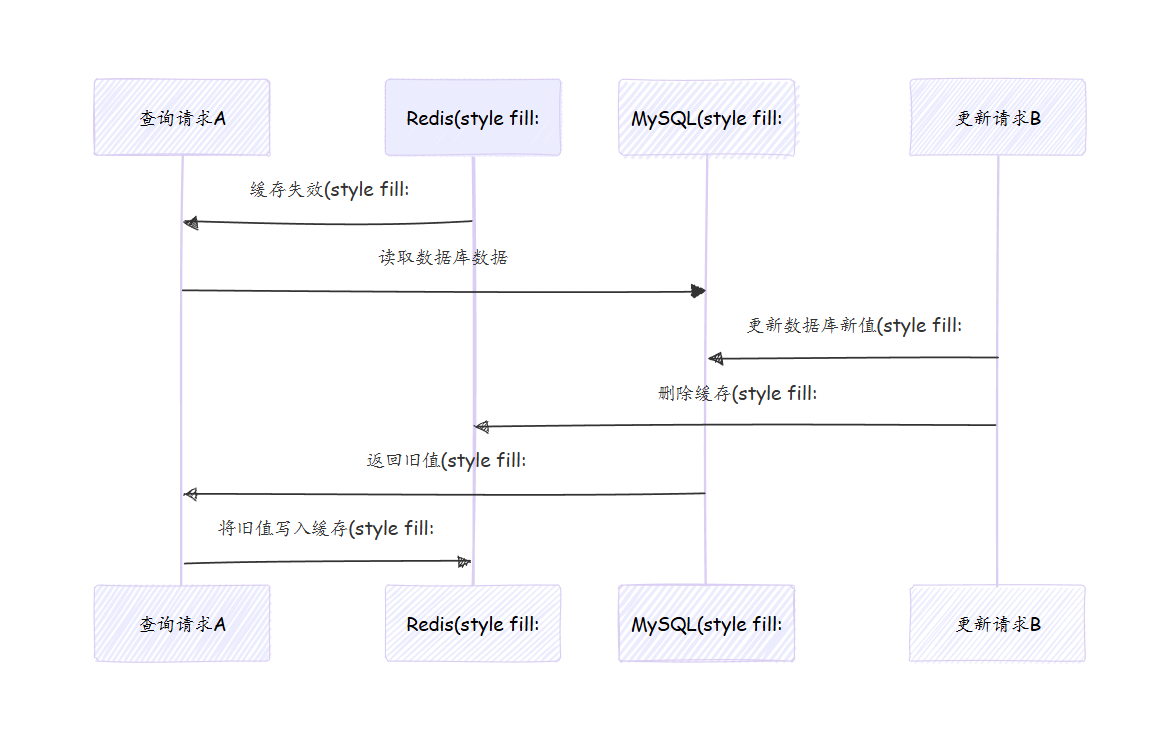
该方案仍存在并发脏数据的可能,但发生概率极低,触发条件为:
- 缓存刚好失效;
- 请求 A(查询)读取数据库旧值;
- 请求 B(更新)更新数据库新值;
- 请求 B(更新)删除缓存;
- 请求 A(查询)将旧值写入缓存。
触发前提:数据库写操作耗时 < 读操作耗时,而数据库读操作远快于写操作,因此该场景几乎不会发生。
流程示例:
(2)低概率问题的解决
- 给缓存设置过期时间:即使出现脏数据,过期后会自动刷新,是最简便的兜底方案;
- 异步延时删除缓存:进一步降低脏数据写入的概率。
(3)核心异常:删除缓存失败(面试高频)
问题 :数据库更新成功,但 Redis 删除缓存失败(如网络、宕机),导致缓存永久存脏数据;解决思路 :补偿机制,分为两种方案,面试中需掌握第二种(解耦)。
方案 1:消息队列直接补偿(耦合)
- 更新数据库成功;
- 删除缓存失败,将 Redis 的 key 作为消息体发送到 MQ;
- 消费者消费消息,重新删除 Redis 的 key
缺陷:业务代码与缓存删除逻辑深度耦合,侵入性强。
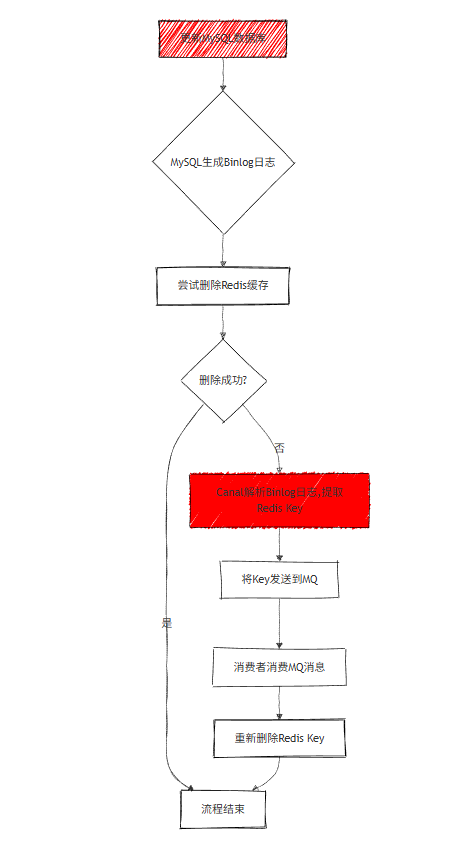
方案 2:基于 MySQL Binlog 的异步补偿(解耦,工业级方案)
核心技术:Canal(阿里开源,模拟 MySQL 从库,解析 Binlog)+ MQ(Kafka/RabbitMQ);
流程:
- 更新数据库,MySQL 生成 Binlog 日志;
- 删除缓存失败,无需业务代码干预;
- Canal 解析 Binlog 日志,将 Redis 的 key 发送到 MQ;
- 消费者消费消息,重新删除 Redis 的 key;
优势:业务代码无侵入,解耦数据库和缓存,是大厂主流实现。
流程示例(Binlog 补偿方案):
2.3 四种方案结论总结
| 方案 | 可用性 | 核心问题 | 面试回答建议 |
|---|---|---|---|
| 先更缓存再更 DB | 不可用 | 更新 DB 失败导致永久不一致 | 直接说明淘汰原因,无实际应用价值 |
| 先更 DB 再更缓存 | 不可用 | 更缓存失败 + 并发更新性能低 | 说明淘汰原因,补充并发更新的性能问题 |
| 先删缓存再更 DB | 可用(需优化) | 并发脏数据,读写分离主从延时 | 说明缺陷 + 延时双删优化 + 读写分离解决方案 |
| 先更 DB 再删缓存 | 推荐(工业级) | 极低概率脏数据,删缓存失败 | 核心推荐方案,说明低概率问题的解决 + Binlog 补偿机制(Canal+MQ) |
三、缓存更新的设计模式
Java 开发中缓存更新的设计模式共 4 种,面试中必考模式定义 、实现逻辑 、适用场景 和对比 ,其中Cache Aside 是主流,Write Behind是高性能设计的考点。
3.1 Cache Aside(旁路缓存模式)
核心定义
应用程序直接操作数据库 和缓存 ,缓存作为旁路存在,是使用最广泛的模式(Facebook《Scaling Memcache at Facebook》采用)。
核心逻辑
- 读:先读缓存 → 未命中读 DB → 将 DB 数据写入缓存 → 返回;
- 写:先写 DB → 再删缓存(Java 开发主流)/ 先删缓存 → 再写 DB(需优化);
一致性保障
- 不追求强一致性 ,通过降低脏数据概率实现最终一致性;
- 强一致性的实现(串行化、分布式锁、2PC)性能差、复杂度高,大厂均选择最终一致性;
适用场景:Java 分布式系统中MySQL+Redis 的主流组合,是面试中缓存设计的默认方案。
3.2 Read Through(读穿透模式)
核心定义
应用程序只操作缓存 ,由缓存服务自身 负责加载数据库数据,对应用层透明,解决 Cache Aside 中应用层需维护两个存储的问题。
核心逻辑
- 读缓存 → 未命中时,缓存服务自动读取数据库 → 将数据写入缓存 → 返回给应用;
适用场景:应用层希望简化数据操作,无需关注缓存与数据库的交互,如专用缓存中间件的封装。
3.3 Write Through(写穿透模式)
核心定义
应用程序只操作缓存 ,由缓存服务自身 负责同步更新数据库,同步写,缓存与数据库强一致。
核心逻辑
- 写缓存 → 缓存命中时,更新缓存 → 缓存服务自动同步更新数据库;
- 写缓存 → 缓存未命中时,直接更新数据库 → 返回(无需写入缓存);
优势与缺陷
- 优势:应用层逻辑简化,缓存与数据库强一致;
- 缺陷:写操作同步执行,性能受数据库写入速度限制;
适用场景:对数据一致性要求高,对写性能要求一般的场景。
3.4 Write Behind Caching(写回 / 写延迟模式)
核心定义
应用程序只操作缓存 ,由缓存服务 **** 异步批量 更新数据库,是高性能写的核心模式(Linux Page Cache 采用)。
核心逻辑
- 写缓存 → 缓存服务将更新操作记录下来 → 异步、批量将数据刷入数据库;
- 支持多次更新合并:对同一数据的多次写操作,缓存服务可合并为一次数据库更新;
优势与缺陷
- 优势:写操作性能极高,异步批量减少数据库 IO;
- 缺陷:数据最终一致性,缓存宕机会导致数据丢失,实现逻辑复杂(需跟踪脏数据);
适用场景:对写性能要求极高,对数据一致性要求为最终一致,可接受少量数据丢失的场景(如日志、统计数据)。
3.5 四种设计模式对比
| 模式 | 操作主体 | 数据一致性 | 性能 | 实现复杂度 | 主流程度 |
|---|---|---|---|---|---|
| Cache Aside | 应用层操作 DB + 缓存 | 最终一致(可优化) | 高 | 低 | ★★★★★ |
| Read Through | 应用层仅操作缓存 | 最终一致 | 中 | 中 | ★★★☆☆ |
| Write Through | 应用层仅操作缓存 | 强一致 | 中(同步写) | 中 | ★★☆☆☆ |
| Write Behind | 应用层仅操作缓存 | 最终一致 | 极高(异步批量) | 高 | ★★★☆☆ |