演示视频
https://www.bilibili.com/video/BV1zQFsz9Eq6/
一、基础环境配置
| 硬件/软件 | 规格/版本 |
|---|---|
| CPU | i7-13700KF |
| GPU | RTX 4090 |
| 推理框架 | TensorRT 8.6 |
| 优化工具 | TensorRTx |
| 模型规格 | YOLOv8n (FP16精度) |
| 视频规格 | 1080p @ 30fps |
二、核心处理流程(单路)
-
拉流:通过FFmpeg解封装RTSP流(使用MP4文件推流模拟实时场景,主机拉取1080P RTSP流);
-
解码:输入H264编码流,解码得到NV12格式图像;
-
格式转换:通过NPP库将NV12图像转为BGR格式;
-
图像预处理:对BGR图像执行LetterBox(等比放缩+居中),减少形变导致的精度损失;
-
模型推理:逐帧输入LetterBox处理后的BGR图像,运行YOLOv8n FP16模型(COCO80类别)推理;
-
推理后处理:GPU端完成推理输出解码+NMS(非极大值抑制),使用TensorRTx的CUDA核函数实现,输出检测结果;
-
可视化处理:GPU端基于检测结果画框+写字(通过OpenCV生成字符小图,传输至GPU合成);
-
格式回转换:将带检测框的BGR图像转回NV12格式;
-
放缩拼接:对NV12图像缩放到指定尺寸,按布局拼接8路图像(便于查看多路推理结果);
-
编码推流 :将拼接后的NV12图像编码为H264,通过
rtsp_demo开源项目封装为RTSP流,支持外部拉流播放。
三、关键技术参考
1. NVIDIA视频编解码SDK
-
提供编解码Sample参考程序,包含NV12图像resize、图像格式转换的CUDA核函数示例;
2. TensorRTx
-
对自定义网络的优化深度高于原生TensorRT;
-
性能优势:4090上YOLOv5s的推理速度比原生TensorRT快15-25%,FP16精度下可达350+ FPS;
-
兼容性:封装版本适配逻辑,同一套代码兼容TensorRT 8.0-8.6,提供跨平台CUDA核函数实现;
四、播放方式
在PC端通过ffplay拉取最终输出的RTSP流,实时播放8路带检测框的视频画面。
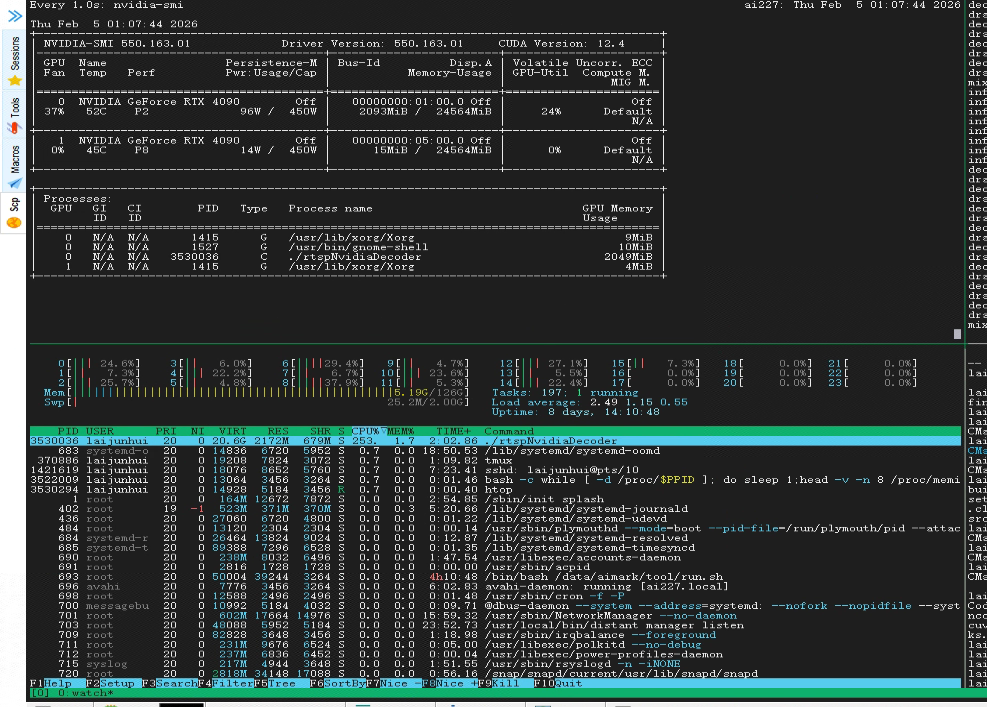
五、性能指标(8路满负载)
-
最大支持路数:8路(瓶颈为模型推理,超过则推理环节掉帧);
-
CPU占用:253%(CPU满载为2400%);
-
系统内存占用:2172MB;
-
GPU显存占用:2049MB。
总结
-
整套方案基于RTX 4090+TensorRTx优化,实现了8路1080p@30fps的YOLOv8n实时检测,核心瓶颈在模型推理环节;
-
全程最大化利用GPU算力(解码、预处理、推理、后处理、可视化均在GPU完成),CPU占用率低,硬件资源利用效率高;
-
关键优化点包括TensorRTx的CUDA核函数加速、NPP库的格式转换、LetterBox预处理减少精度损失。