长短期记忆网络(Long Short-Term Memory,LSTM)是由Hochreiter和Schmidhuber于1997年提出的循环神经网络(RNN)改进模型 (算是一种特殊的RNN),核心解决了传统RNN处理长序列时的梯度消失/梯度爆炸 问题,实现了对长距离依赖关系的有效捕捉,是深度学习中处理序列数据的核心模型之一。LSTM的设计围绕"选择性记忆"展开,通过细胞状态 和门控机制让模型自主决定保留、丢弃和更新信息。
一、LSTM的诞生背景:传统RNN的局限性
循环神经网络(RNN)的核心是利用时序关联性 处理序列数据(如文本、语音、时间序列),其通过将上一时刻的隐藏状态ht−1h_{t-1}ht−1与当前时刻的输入xtx_txt融合,得到当前隐藏状态hth_tht,实现"记忆"历史信息的功能。但传统RNN的隐藏状态更新为非线性连乘计算 ,公式为:
ht=tanh(W⋅ht−1,xt+b)h_t = \tanh(W·h_{t-1},x_t + b)ht=tanh(W⋅ht−1,xt+b)
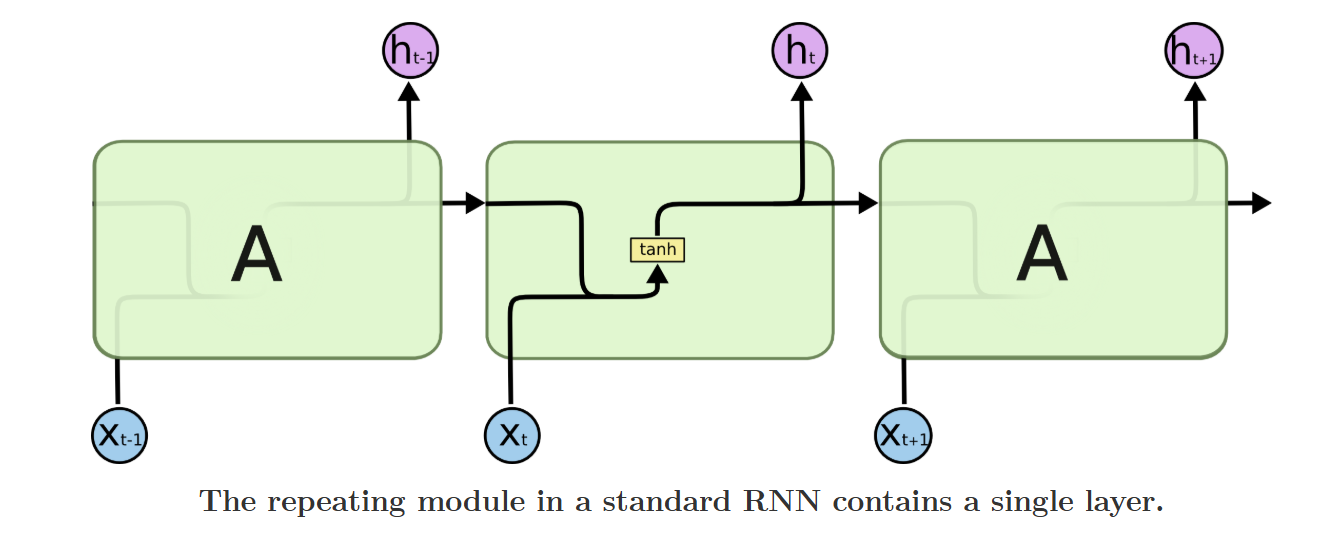
在模型训练的反向传播过程中,梯度通过链式法则层层求导,最终表现为多个权重矩阵的连乘 :当序列较长时,连乘结果会快速趋近于0(梯度消失)或无穷大(梯度爆炸),导致模型无法学习到长序列中远距离的依赖关系(如长句子中开头和结尾的语义关联、时间序列中数月前的关键特征)。
为解决这一问题,LSTM引入了细胞状态(Cell State)作为"记忆主线",并通过门控机制实现对信息的选择性控制,让梯度能稳定传播,从而有效捕捉长距离依赖。
二、LSTM的核心结构:细胞状态与门控机制
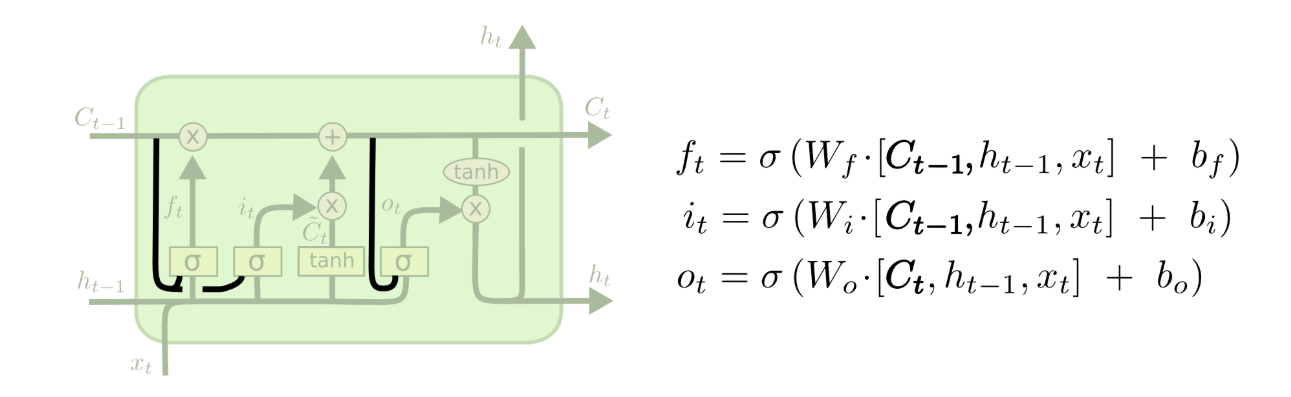
LSTM的核心创新是细胞状态(CtC_tCt)和三大门控(遗忘门、输入门、输出门),这一结构让模型摆脱了传统RNN的非线性记忆瓶颈,实现"长短期记忆"的结合。
1. 细胞状态(CtC_tCt):LSTM的"记忆核心"
细胞状态是LSTM中贯穿整个序列的线性信息流 ,是模型存储历史信息的主要载体,其更新仅通过按元素点乘 和按元素加法 实现,无复杂非线性变换。这种线性特性让梯度在传播时避免了连乘衰减,是LSTM缓解梯度消失的关键基础。细胞状态的更新规则会结合门控机制,实现"丢弃无用旧信息、存入有用新信息"的功能。
2. 门控机制:选择性控制信息的传递
门控是LSTM实现"选择性记忆"的核心,本质是sigmoid激活函数 +按元素点乘(⊙\odot⊙)的组合。sigmoid函数的输出值在0,10,10,1之间,其中0表示完全阻挡信息传递,1表示完全允许信息传递 ,点乘操作则让门控的输出值对信息进行"加权筛选"。LSTM包含三个独立的门控,分别负责不同的信息处理任务,且所有门控的输入均为上一时刻隐藏状态ht−1h_{t-1}ht−1和当前时刻输入xtx_txt的拼接结果ht−1,xth_{t-1},x_tht−1,xt。
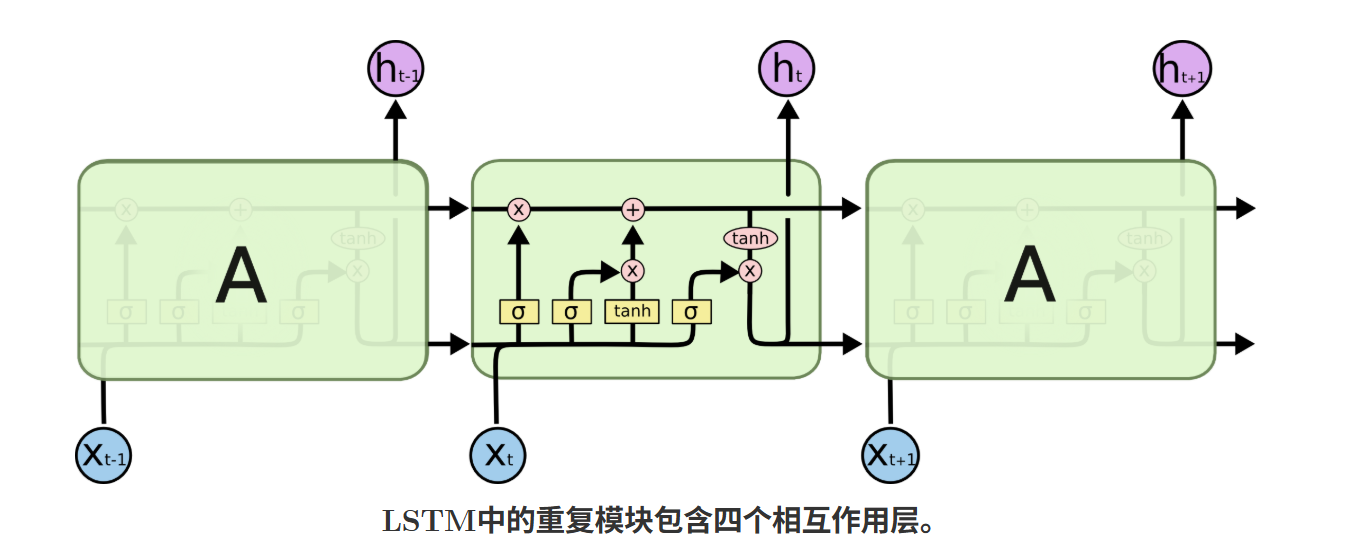
三、LSTM的完整计算流程(单时刻)
LSTM的计算围绕t时刻 展开,输入为当前时刻序列特征xtx_txt(维度为din,1d_{in},1din,1)和上一时刻隐藏状态ht−1h_{t-1}ht−1(维度为dhid,1d_{hid},1dhid,1),输出为当前时刻隐藏状态hth_tht(维度为dhid,1d_{hid},1dhid,1)和当前时刻细胞状态CtC_tCt(维度为dhid,1d_{hid},1dhid,1),其中dind_{in}din为输入维度,dhidd_{hid}dhid为隐藏层维度(超参数)。
步骤1:计算遗忘门(ftf_tft)------丢弃细胞状态中的无用旧信息
遗忘门的作用是筛选并丢弃细胞状态中历史的无用信息 (如长句子中无关的前置词汇、时间序列中过时的特征),公式为:
ft=σ(Wf⋅ht−1,xt+bf)f_t = \sigma(W_f·h_{t-1},x_t + b_f)ft=σ(Wf⋅ht−1,xt+bf)
其中:σ\sigmaσ为sigmoid激活函数,WfW_fWf为遗忘门权重矩阵(维度dhid,dhid+dind_{hid},d_{hid}+d_{in}dhid,dhid+din),bfb_fbf为遗忘门偏置项(维度dhid,1d_{hid},1dhid,1),ftf_tft为遗忘门输出(维度dhid,1d_{hid},1dhid,1),值越接近0,对应位置的旧信息越容易被丢弃。
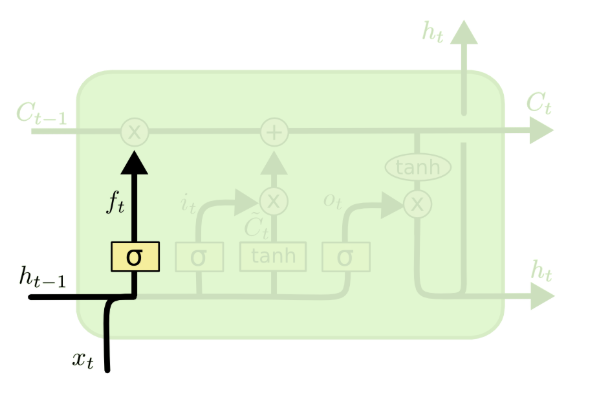
步骤2:计算输入门(iti_tit)与候选细胞状态(C~t\tilde{C}_tC~t)------准备存入新信息
输入门负责筛选当前时刻的有用新信息 ,候选细胞状态则负责生成当前时刻的所有新信息候选 ,二者配合完成"新信息的筛选与生成",是细胞状态更新的基础,公式分别为:
it=σ(Wi⋅ht−1,xt+bi)i_t = \sigma(W_i·h_{t-1},x_t + b_i)it=σ(Wi⋅ht−1,xt+bi)
C~t=tanh(WC⋅ht−1,xt+bC)\tilde{C}_t = \tanh(W_C·h_{t-1},x_t + b_C)C~t=tanh(WC⋅ht−1,xt+bC)
其中:Wi、WCW_i、W_CWi、WC为对应权重矩阵,bi、bCb_i、b_Cbi、bC为对应偏置项;tanh\tanhtanh为双曲正切激活函数,输出值在−1,1-1,1−1,1之间,用于对新信息进行归一化 ,避免数值溢出;iti_tit为输入门输出(维度dhid,1d_{hid},1dhid,1),值越接近1,对应位置的新信息越容易被保留。
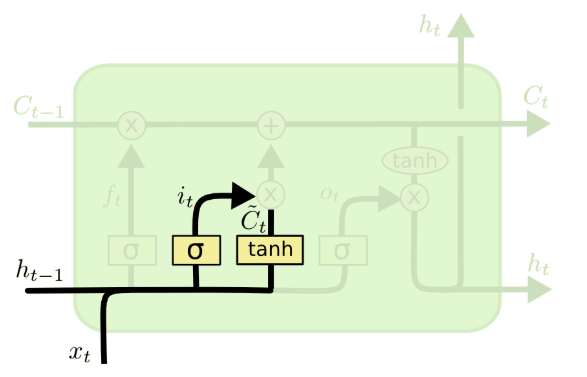
步骤3:更新细胞状态(CtC_tCt)------遗忘旧信息+存入新信息
细胞状态的更新是LSTM记忆更新 的核心步骤,通过遗忘门对旧细胞状态加权 和输入门对候选细胞状态加权 后的按元素加法 实现,公式为:
Ct=ft⊙Ct−1+it⊙C~tC_t = f_t \odot C_{t-1} + i_t \odot \tilde{C}_tCt=ft⊙Ct−1+it⊙C~t
其中:Ct−1C_{t-1}Ct−1为上一时刻的细胞状态,⊙\odot⊙为按元素点乘(同维度矩阵对应位置相乘)。这一步的物理意义非常明确:先通过遗忘门丢弃旧细胞状态中的无用信息,再通过输入门将筛选后的新信息存入细胞状态 ,实现了记忆的"动态更新"。
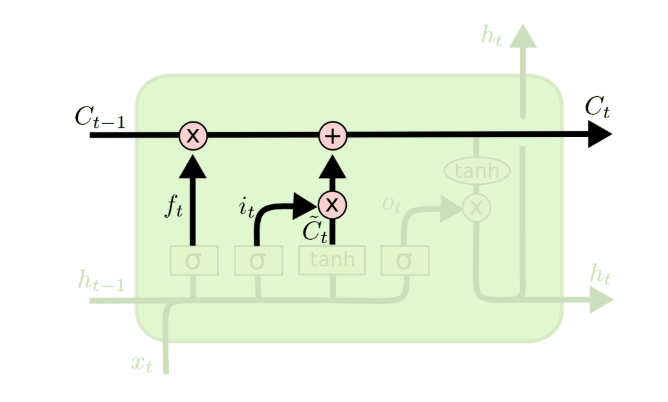
步骤4:计算输出门(oto_tot)与当前隐藏状态(hth_tht)------生成当前输出
输出门负责筛选细胞状态中需要输出的信息 ,当前隐藏状态hth_tht是LSTM的最终输出(既作为模型当前时刻的特征输出,也作为下一时刻的输入传递),公式分别为:
ot=σ(Wo⋅ht−1,xt+bo)o_t = \sigma(W_o·h_{t-1},x_t + b_o)ot=σ(Wo⋅ht−1,xt+bo)
ht=ot⊙tanh(Ct)h_t = o_t \odot \tanh(C_t)ht=ot⊙tanh(Ct)
其中:WoW_oWo为输出门权重矩阵,bob_obo为输出门偏置项;先通过tanh\tanhtanh将细胞状态CtC_tCt的取值映射到−1,1-1,1−1,1,再通过输出门oto_tot筛选,最终得到隐藏状态hth_tht。这一步让模型仅输出与当前任务相关的信息,避免无关记忆的干扰。
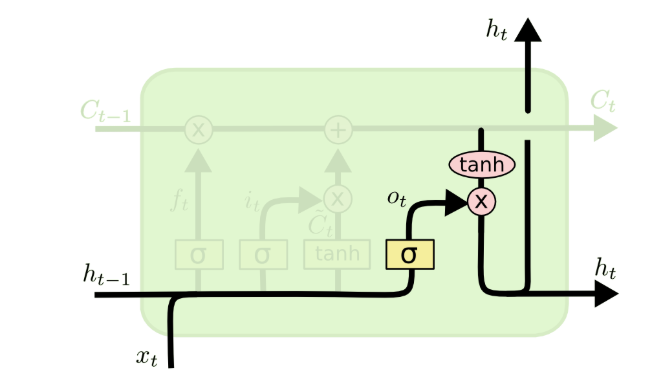
单时刻计算总结 :LSTM通过"遗忘→筛选新信息→更新记忆→输出有用信息"的四步流程,实现了对信息的选择性处理;而在整个序列中,细胞状态CtC_tCt沿时序线性传播,隐藏状态hth_tht逐时刻传递,共同构成了LSTM的记忆体系。
四、LSTM缓解梯度消失的核心原理
LSTM能有效缓解梯度消失,根本原因是细胞状态的线性更新特性 ,结合反向传播的梯度计算可清晰解释这一原理:
在模型训练的反向传播中,我们需要计算当前时刻细胞状态对前一时刻细胞状态的梯度 ∂Ct∂Ct−1\frac{\partial C_t}{\partial C_{t-1}}∂Ct−1∂Ct,根据细胞状态更新公式求导可得:
∂Ct∂Ct−1=ft\frac{\partial C_t}{\partial C_{t-1}} = f_t∂Ct−1∂Ct=ft
遗忘门ftf_tft由sigmoid函数生成,取值在0,10,10,1之间,模型训练时可通过学习让ftf_tft趋近于1 (如将遗忘门偏置初始化为1),此时∂Ct∂Ct−1≈1\frac{\partial C_t}{\partial C_{t-1}} \approx 1∂Ct−1∂Ct≈1,梯度能沿着细胞状态的线性流稳定传播,不会像传统RNN那样因非线性连乘而快速衰减。
即使序列较长,梯度也能通过细胞状态传递到远距离的时刻,让模型学习到长距离依赖关系。而梯度爆炸问题则可通过梯度裁剪(Gradient Clipping)解决,将梯度范数限制在固定阈值内,避免梯度无穷大。
五、LSTM的经典变体
原始LSTM的结构虽能解决梯度消失问题,但存在参数量大、训练速度慢 的缺点,且部分场景下门控的信息捕捉能力可进一步优化。因此研究者基于原始LSTM提出了多种变体,其中Peephole LSTM、GRU、双向LSTM、堆叠LSTM是最经典、应用最广泛的四种。
1. Peephole LSTM(带窥视孔的LSTM)
原始LSTM的所有门控仅依赖ht−1h_{t-1}ht−1和xtx_txt,无法直接感知细胞状态CtC_tCt的信息。Peephole LSTM的改进是让门控直接"窥视"细胞状态 ,将细胞状态加入门控的输入中,例如遗忘门和输入门加入上一时刻细胞状态Ct−1C_{t-1}Ct−1,输出门加入当前时刻细胞状态CtC_tCt,公式示例:
ft=σ(Wf⋅ht−1,xt,Ct−1+bf)f_t = \sigma(W_f·h_{t-1},x_t,C_{t-1} + b_f)ft=σ(Wf⋅ht−1,xt,Ct−1+bf)
这一改进让门控能更精准地感知记忆状态,提升了模型对细粒度信息的捕捉能力,适合对记忆精度要求高的任务(如精密时间序列预测)。
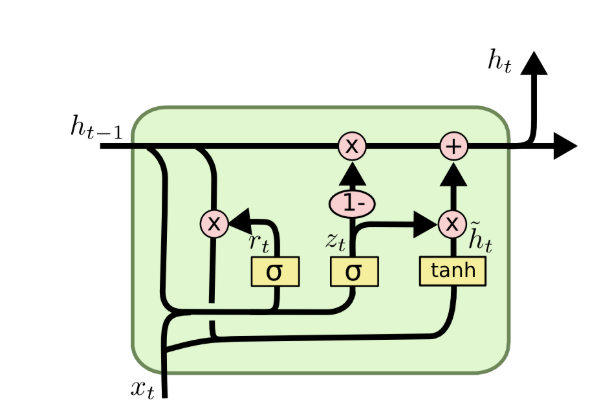
2. GRU(门控循环单元)------LSTM的简化版
GRU由Cho等人于2014年提出,是对LSTM的极致简化 ,其将遗忘门和输入门合并为更新门 ,取消了独立的细胞状态,用隐藏状态替代细胞状态的记忆功能,同时新增重置门 控制历史信息的使用,最终仅保留两个门控,参数量比LSTM减少约1/3,训练速度大幅提升。
GRU的核心公式为:
{zt=σ(Wz⋅ht−1,xt+bz)更新门rt=σ(Wr⋅ht−1,xt+br)重置门h~t=tanh(W⋅rt⊙ht−1,xt+b)候选隐藏状态ht=(1−zt)⊙ht−1+zt⊙h~t当前隐藏状态\begin{cases} z_t = \sigma(W_z·h_{t-1},x_t + b_z) \quad \text{更新门} \\ r_t = \sigma(W_r·h_{t-1},x_t + b_r) \quad \text{重置门} \\ \tilde{h}t = \tanh(W·r_t \\odot h_{t-1},x_t + b) \quad \text{候选隐藏状态} \\ h_t = (1-z_t) \odot h{t-1} + z_t \odot \tilde{h}_t \quad \text{当前隐藏状态} \end{cases}⎩ ⎨ ⎧zt=σ(Wz⋅ht−1,xt+bz)更新门rt=σ(Wr⋅ht−1,xt+br)重置门h~t=tanh(W⋅rt⊙ht−1,xt+b)候选隐藏状态ht=(1−zt)⊙ht−1+zt⊙h~t当前隐藏状态
其中,更新门ztz_tzt控制"保留旧记忆"和"融入新记忆"的比例,重置门rtr_trt控制是否忽略历史隐藏状态。GRU在保持LSTM长距离依赖捕捉能力的同时,实现了轻量级训练 ,是实际工程中最常用的序列模型之一(如小数据量、低计算资源场景)。
3. 双向LSTM(BiLSTM)------捕捉上下文双向依赖
原始LSTM和GRU均为单向模型 ,仅能从左到右处理序列,无法捕捉反向的依赖关系(如文本中"后词对前词的语义影响"、视频中"后续帧对前序帧的动作关联")。双向LSTM的核心是由前向LSTM和后向LSTM并行组成:
- 前向LSTM:从序列首端到末端处理,捕捉正向时序依赖;
- 后向LSTM:从序列末端到首端处理,捕捉反向时序依赖;
- 最终隐藏状态:将前向和后向的隐藏状态按维度拼接,融合双向信息。
双向LSTM是自然语言处理(NLP)的基础模型,适合命名实体识别、词性标注、情感分析等需要上下文信息的任务,但参数量是单向LSTM的2倍,且无法处理实时序列(需获取整个序列后才能反向计算)。
4. 堆叠LSTM(Stacked LSTM)------提取多层抽象特征
堆叠LSTM是将多层LSTM按层级堆叠 ,上层LSTM的输入为下层LSTM的隐藏状态输出,底层LSTM的输入为原始序列数据。每一层LSTM负责提取序列的不同粒度特征:底层提取浅层特征(如文本中的字/词特征、时间序列的原始数值特征),上层提取深层抽象特征(如文本中的语义特征、时间序列的趋势特征)。
堆叠LSTM的特征表达能力远强于单层LSTM,但层数过多会导致参数量剧增、过拟合、训练难度加大,实际应用中一般堆叠1-4层,且需配合Dropout、L2正则化等防止过拟合。
六、LSTM的训练技巧与超参数设置
LSTM的结构比传统RNN复杂,对超参数和训练策略更敏感,不合理的设置会导致模型训练缓慢、过拟合或效果不佳,以下是工程中经验证的核心训练技巧和超参数设置原则,是LSTM实际应用的关键知识点。
1. 核心超参数及取值范围
LSTM的超参数直接决定模型的容量和性能,核心超参数及常用取值如下:
| 超参数 | 含义 | 常用取值范围 |
|---|---|---|
| hidden_size | 隐藏层/细胞状态维度 | 64/128/256/512 |
| num_layers | 堆叠LSTM的层数 | 1-4层 |
| seq_len | 序列长度(固定输入维度) | 依任务而定(如NLP中句子长度20/50/100) |
| batch_size | 批大小 | 16/32/64 |
| learning_rate | 学习率 | 1e-4 ~ 1e-3 |
| dropout_rate | Dropout正则化率 | 0.2 ~ 0.5 |
2. 关键训练技巧
- 输入预处理 :序列数据需做归一化/标准化 (如时间序列的Z-Score标准化),文本数据需通过Embedding层将离散的字/词映射为连续的低维词向量,且所有序列需通过Padding(补0)/Truncation(截断)统一长度;
- 偏置初始化 :将遗忘门的偏置初始化为1,让模型训练初期倾向于保留旧信息,提升训练稳定性(避免初始时过度丢弃记忆);
- 优化器选择 :优先使用Adam优化器,其自适应学习率特性能适配LSTM的梯度变化,避免学习率过大导致梯度爆炸、过小导致训练缓慢;
- 梯度裁剪:设置梯度范数阈值(如5.0),当梯度范数超过阈值时,对梯度进行缩放,彻底解决梯度爆炸问题;
- 防止过拟合 :结合Dropout(加在门控或隐藏层后)、早停(Early Stopping)、L2正则化,其中Dropout需注意:仅在层间使用,不可在时序方向使用(避免破坏序列关联性);
- 批量归一化(BN) :LSTM中不建议直接对隐藏状态/细胞状态使用BN(会破坏时序依赖),可使用层归一化(Layer Normalization,LN),对每个样本的特征做归一化,适配序列数据。
七、LSTM的应用场景
LSTM因能有效捕捉长序列的时序依赖,成为序列数据处理的基础模型,广泛应用于自然语言处理、时间序列预测、语音识别、计算机视觉等领域,核心应用场景如下:
- 自然语言处理(NLP):文本分类(情感分析、垃圾邮件识别)、命名实体识别(NER)、机器翻译、文本生成、问答系统、词性标注,核心解决长文本的上下文关联问题;
- 时间序列预测:股价预测、气象预报、电力负荷预测、交通流量预测、水质监测,捕捉时间序列的长周期趋势和规律;
- 语音识别:将语音的声学特征序列映射为文字序列,实现语音转文字(ASR),是语音识别系统的核心时序模型;
- 计算机视觉:视频分析(动作识别、视频分类、行为检测)、图像描述生成,将视频帧/图像特征作为序列,捕捉帧间时序关联或融合视觉与语言特征;
- 其他领域:生物信息学(DNA/RNA序列分析、蛋白质结构预测)、推荐系统(用户行为序列分析,实现个性化推荐)、工业检测(设备运行状态时序分析,实现故障预警)。
八、LSTM的优缺点
优点
- 有效缓解梯度消失:细胞状态的线性流让梯度稳定传播,能捕捉长序列的长距离依赖,这是其核心优势;
- 选择性记忆:门控机制实现对信息的动态筛选,灵活保留有用信息、丢弃无用信息,特征表达能力强;
- 适应性强:通过变体(GRU、BiLSTM、Stacked LSTM)可适配不同任务和计算资源场景;
- 特征融合能力强:隐藏状态融合了历史信息和当前信息,能为后续任务提供更全面的序列特征。
缺点
- 结构复杂,训练效率低:参数量远大于传统RNN和GRU,训练速度慢,对计算资源要求较高;
- 并行性差:因序列的时序性,LSTM需按时刻逐次计算,无法像CNN、Transformer那样实现批量并行计算,处理极长序列时效率极低;
- 对超参数敏感:隐藏层维度、序列长度、学习率等超参数的微小变化会导致模型性能大幅波动,调参难度较大;
- 无法处理极长序列:对于1000步以上的极长序列,LSTM仍会出现梯度衰减,且计算耗时剧增;
- 存在信息冗余:对短序列的处理中,门控机制的复杂结构会造成信息冗余,效果不如传统RNN/GRU。
九、LSTM与Transformer的对比
Transformer是2017年提出的基于自注意力机制的序列模型,目前已成为NLP、计算机视觉等领域的主流模型,与LSTM相比,二者的核心差异如下:
- 长距离依赖捕捉 :Transformer通过自注意力机制直接计算序列中任意两个位置的关联,捕捉长距离依赖的能力远强于LSTM,且无序列长度限制;
- 并行性:Transformer无需按时刻逐次计算,可对整个序列进行批量并行处理,训练效率远高于LSTM;
- 参数量与数据需求:Transformer参数量更大,需要大量数据训练才能发挥效果;LSTM对小数据量的适应性更强,训练成本更低;
- 时序性 :LSTM天生融入时序信息,适合强时序的序列预测任务;Transformer本身无时序性,需通过位置编码引入时序信息。
应用场景选择:大数据量、高计算资源场景(如大模型训练、机器翻译、文本生成)优先使用Transformer;小数据量、低计算资源、强时序依赖场景(如小型时间序列预测、嵌入式设备的序列处理)优先使用LSTM/GRU。
我们在努力扩大自己,以靠近,以触及我们自身以外的世界。 ---博尔赫斯谈话录