基于人类反馈的指令微调语言模型

摘要
单纯扩大语言模型的规模并不能使其更好地遵循用户意图。例如,大型语言模型可能生成不真实、有害或对用户无实际帮助的输出内容。换言之,这些模型与用户需求并未对齐。本文提出了一种通过人类反馈进行微调的方法,使语言模型在广泛任务中与用户意图保持一致。我们首先收集标注员编写的指令集及通过语言模型API提交的指令,构建了展示期望模型行为的标注员示范数据集,并以此通过监督学习对GPT-3进行微调。随后我们收集了模型输出的排序数据集,通过人类反馈的强化学习对该监督模型进行进一步优化。我们将最终得到的模型称为InstructGPT。在针对我们指令分布的人工评估中,尽管参数量仅为前者的1/100,13亿参数的InstructGPT模型输出结果优于1750亿参数的GPT-3模型。此外,InstructGPT在公共NLP数据集上性能衰减极小的同时,展现出生成结果真实性提升与有害输出减少的特性。尽管InstructGPT仍会出现简单错误,但我们的研究表明,基于人类反馈的微调是实现语言模型与人类意图对齐的重要方向。
1.引言
大型语言模型(LMs)可以通过输入若干任务示例来执行一系列自然语言处理(NLP)任务。然而,这些模型常表现出非预期行为,例如捏造事实、生成带有偏见或有害的文本,或仅仅是未能遵循用户指令(Bender et al., 2021; Bommasani et al., 2021; Kenton et al., 2021; Weidinger et al., 2021; Tamkin et al., 2021; Gehman et al., 2020)。这是因为当前多数大型语言模型所采用的训练目标------基于互联网网页内容预测下一词元------与"遵循用户指令,提供有益且安全的回应"这一目标存在差异(Radford等人,2019;Brown等人,2020;Fedus等人,2021;Rae等人,2021;Thoppilan等人,2022)。因此,我们认为语言建模的目标存在错位。对于已部署于数百种应用场景的语言模型而言,避免这些非预期的行为显得尤为重要。
我们在语言模型对齐方面取得进展,主要通过训练模型使其行为符合用户意图(Leike等人,2018)。这既包括遵循指令等显性意图,也包括保持真实性、避免偏见、毒性或其他有害行为等隐性意图。借用Askell等人(2021)的表述,我们希望语言模型能够做到:有用性(应帮助用户完成任务)、诚实性(不应编造信息或误导用户)以及无害性(不应对人类、环境造成物理、心理或社会层面的伤害)。我们将在第3.5节详细阐述这些标准的评估方法。
我们的研究聚焦于通过微调方法实现语言模型的对齐。具体而言,我们采用基于人类反馈的强化学习技术(RLHF; Christiano et al., 2017; Stiennon et al., 2020)对GPT-3进行微调,使其能够遵循广泛的书面指令类别(见图2)。该方法以人类偏好作为奖励信号来优化我们的模型。我们首先聘请了由40名合同工组成的标注团队,其选拔基于筛选测试中的表现(详见第3.3节及附录B.1)。随后,我们收集了一个人工撰写的示范数据集,展示了针对提交至语言模型API的(主要为英文)提示词以及部分标注员自编提示词所期望的输出行为,并以此训练监督学习的基线模型。接着,我们在更大量的API提示词上采集了人工标注的模型输出对比数据,并基于此训练奖励模型来预测标注员更倾向于哪种模型输出。最后,我们将该奖励模型作为奖励函数,使用PPO算法(Schulman et al., 2017)对监督学习基线模型进行微调以最大化此奖励。该流程如图2所示。这一过程将GPT-3的行为与特定人群(主要为我们的标注员和研究人员)的明确偏好对齐,而非与更广义的"人类价值观"对齐;我们将在附录G.2进一步探讨此问题。我们将最终得到的模型称为InstructGPT。
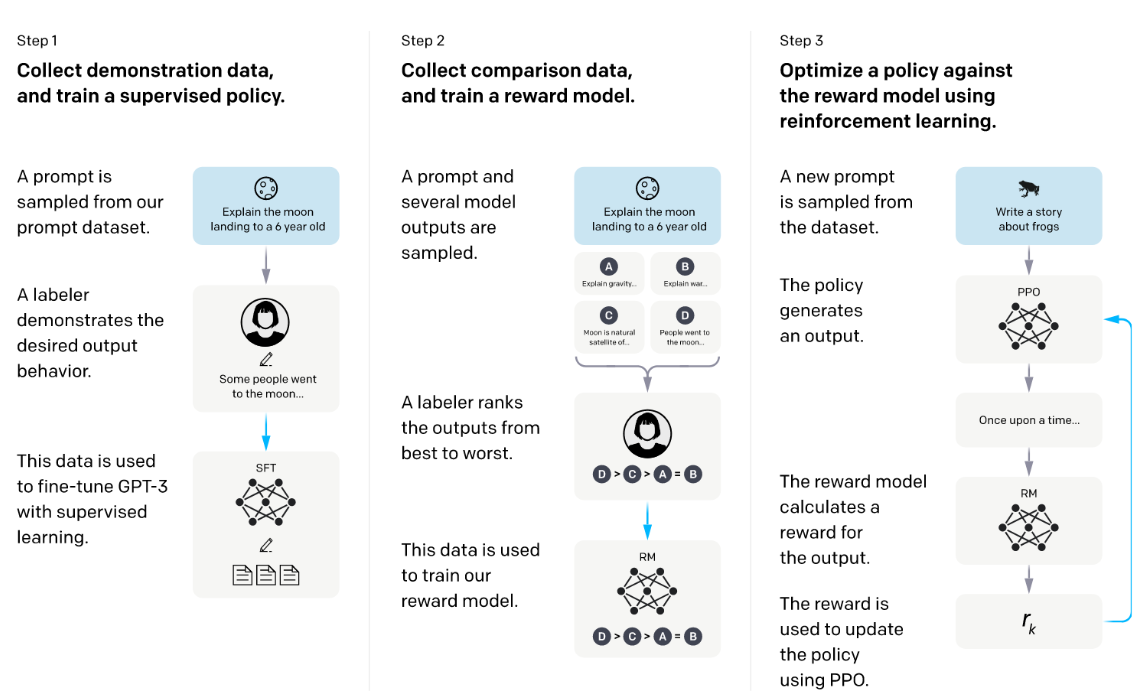
图2:展示我们方法三个步骤的示意图:(1)监督微调(SFT),(2)奖励模型(RM)训练,(3)基于此奖励模型通过近端策略优化(PPO)进行的强化学习。蓝色箭头表示该数据用于训练我们的某个模型。在步骤2中,方框A-D为我们模型的输出样本,由标注人员进行排序。
我们主要通过标注员在测试集上评估模型输出的质量来评判模型性能,该测试集由未参与训练的用户提示组成(这些用户数据未出现在训练数据中)。同时,我们在一系列公开自然语言处理数据集上进行了自动化评估。我们训练了三种参数量级的模型(13亿、60亿和1750亿参数),所有模型均采用GPT-3架构。我们的主要研究成果如下:
标注员明显更倾向于InstructGPT的输出结果,而非GPT-3。即使参数量减少了100倍以上,13亿参数的InstructGPT模型输出仍比1750亿参数的GPT-3更受青睐。这些模型架构完全相同,唯一区别在于InstructGPT使用我们的人类标注数据进行了微调。即使我们为GPT-3添加少样本提示以提升其遵循指令的能力,这一结论依然成立。在对比中,我们1750亿参数的InstructGPT输出有85±3%的几率优于基础版1750B GPT-3,同时有71±4%的几率优于少样本版本的1750B GPT-3。根据标注员的评估,InstructGPT还能生成更符合要求的输出内容。
InstructGPT模型在真实性方面相较GPT-3有所提升。在TruthfulQA基准测试中,InstructGPT比GPT-3更频繁地生成真实且信息丰富的答案。在我们API提示分布中的"封闭领域"任务上(此类任务的输出不应包含输入内容之外的信息),InstructGPT模型编造输入中不存在信息的频率约为GPT-3的一半(两者的幻觉率分别为21%和41%)
InstructGPT在毒性方面相比GPT-3有轻微改善,但在偏见问题上未见提升。为测量毒性,我们采用RealToxicityPrompts数据集(Gehman等人,2020),同时进行了自动评估与人工评估。在要求生成尊重性内容时,InstructGPT模型产生的有毒输出比GPT-3减少约25%。在Winogender(Rudinger等人,2018)和CrowSPairs(Nangia等人,2020)数据集上,InstructGPT相比GPT-3未表现出显著改进。
我们可以通过修改RLHF微调程序,最小化在公开NLP数据集上的性能衰退。在RLHF微调过程中,我们观察到相较于GPT-3在某些公开NLP数据集上出现了性能衰退。通过对PPO更新与增加预训练分布对数似然的更新进行混合(PPO-ptx),我们能在不降低标注者偏好分数的前提下,大幅减少这些数据集的性能衰退。
我们的模型能够泛化到未参与生成训练数据的"留出"标注者的偏好上。为检验模型泛化能力,我们针对留出标注者开展了初步实验:与训练集标注者相似,这些留出标注者偏好InstructGPT输出结果的程度约是其偏好GPT-3输出结果的两倍。但当前研究仍需深入探索这些模型在更广泛用户群体中的表现,以及当人类对预期行为存在分歧时模型在相关输入上的表现。
公开自然语言处理数据集无法反映我们语言模型的实际使用方式。我们将基于人类偏好数据微调的GPT-3(即InstructGPT)与基于两种不同公开NLP任务数据集微调的GPT-3进行对比:分别是FLAN(Wei等人,2021年)和T0(Sanh等人,2021年,特别是T0++变体)。这些数据集包含多种NLP任务,并为每个任务配以自然语言指令。在我们的API提示词分布测试中,FLAN和T0模型的表现略逊于监督微调基线,而标注人员明显更倾向于InstructGPT模型。
InstructGPT模型在RLHF微调分布之外的指令上展现出良好的泛化能力。我们通过定性测试探究InstructGPT的能力,发现它能够遵循指令总结代码、回答有关代码的问题,有时甚至能执行不同语言的指令------尽管这类指令在微调数据集中极为罕见。这一发现令人振奋,因为它表明我们的模型能够泛化"遵循指令"这一核心概念。即使在极少获得直接监督的任务上,这些模型仍能保持一定的对齐特性。
InstructGPT仍会犯简单错误。例如,它可能无法遵循指令、捏造事实、对简单问题给出冗长模棱两可的回答,或无法识别基于错误前提的指令。
总体而言,我们的研究结果表明,基于人类偏好对大语言模型进行微调能显著改善其在广泛任务中的表现,但在提升安全性和可靠性方面仍需大量工作。
2.相关工作
基于人类反馈的对齐与学习研究。我们在现有技术基础上,进一步优化模型与人类意图的对齐能力。特别是人类反馈强化学习(RLHF)。这一方法最初为在模拟环境及雅达利游戏中训练简单机器人而开发(Christiano等人,2017;Ibarz等人,2018),近期已被应用于微调语言模型以进行文本摘要(Ziegler等人,2019;Stiennon等人,2020;Böhm等人,2019;Wu等人,2021)。而此项工作本身亦受到其他领域类似研究的启发,这些研究将人类反馈作为奖励机制应用于对话(Jaques等人,2019;Yi等人,2019;Hancock等人,2019)、机器翻译(Kreutzer等人,2018;Bahdanau等人,2016)、语义解析(Lawrence与Riezler,2018)、故事生成(Zhou与Xu,2020)、评论生成(Cho等人,2018)以及证据提取(Perez等人,2019)等任务。在同期研究中,Askell等人(2021)与Bai等人(2022)提出以语言助手作为对齐研究的测试平台,并采用RLHF训练模型。我们的工作则可视为将RLHF直接应用于广泛语言任务分布上、以实现语言模型对齐的一次实践。
训练语言模型遵循指令。我们的工作也与语言模型跨任务泛化的研究相关,这类研究通常在大规模公开自然语言处理数据集上对语言模型进行微调(通常会在数据前添加恰当的指令),并在另一组不同的自然语言处理任务上进行评估。该领域已有大量研究工作(Yi等人,2019;Mishra等人,2021;Wei等人,2021;Khashabi等人,2020;Sanh等人,2021;Aribandi等人,2021),这些研究在训练与评估数据、指令的格式化方式、预训练模型的规模以及其他实验细节上存在差异。
缓解语言模型潜在危害。调整语言模型行为的目标之一,在于降低这些模型在实际部署中可能产生的危害。相关风险已被广泛记录(Bender et al., 2021; Bommasani et al., 2021; Kenton et al., 2021; Weidinger et al., 2021; Tamkin et al., 2021)。语言模型可能产生带有偏见的输出(Dhamala et al., 2021; Liang et al., 2021; Manela et al., 2021; Caliskan et al., 2017; Kirk et al., 2021)、泄露隐私数据(Carlini et al., 2021)、生成虚假信息(Solaiman et al., 2019; Buchanan et al., 2021)并被恶意利用;详尽综述请参阅 Weidinger 等人(2021)的研究。缓解这些危害的方法有多种,包括基于小规模价值导向数据集进行微调(Solaiman and Dennison, 2021)、过滤预训练数据集(Ngo et al., 2021)或采用人机协同数据收集(Dinan et al., 2019; Xu et al., 2020)。
3.方法与实验细节
3.1 高层次方法论
我们的方法遵循Ziegler等人(2019)和Stiennon等人(2020)的研究,他们曾将此法应用于风格延续与摘要生成领域。我们从一个预训练语言模型(Radford等人,2019;Brown等人,2020;Fedus等人,2021;Rae等人,2021;Thoppilan等人,2022)、一个我们希望模型能产生对齐输出的提示分布、以及一个经过训练的人工标注团队(详见第3.3节)开始。随后,我们实施以下三个步骤(见图2)。
步骤一:收集演示数据,训练监督策略。我们的标注员在输入提示分布上提供期望行为的演示(关于该分布的详细信息参见第3.2节)。随后,我们使用监督学习在此数据上对预训练的GPT-3模型进行微调。
步骤二:收集比较数据,训练奖励模型。我们收集模型输出之间的比较数据集,标注员针对给定输入标示其更偏好的输出。随后,我们训练一个奖励模型来预测人类更偏好的输出。
步骤三:使用PPO算法根据奖励模型优化策略。我们将奖励模型的输出作为标量奖励,并使用PPO算法(Schulman等人,2017)对监督策略进行微调以优化该奖励。
步骤二和三可持续迭代进行:在当前最优策略上收集更多比较数据,用于训练新的奖励模型,进而训练新策略。在实践中,我们的比较数据主要来自监督策略,部分来自PPO策略。
3.2 数据集
我们的提示数据集主要包含提交至商业语言模型API的文本提示,以及少量由标注员撰写的提示。这些提示内容极为多样,涵盖生成、问答、对话、总结、信息抽取及其他自然语言处理任务(详见附录A)。本数据集中超过96%为英文内容。我们通过启发式方法对提示进行去重处理,并确保验证集和测试集中不包含任何训练集用户的数据。同时,我们过滤了包含个人身份信息(PII)的提示内容。
基于这些提示词,我们生成了微调过程中使用的三个不同数据集:(1) 监督微调数据集,包含标注员演示数据,用于训练监督微调模型;(2) 奖励模型数据集,包含标注员对模型输出的排序数据,用于训练奖励模型;(3) 近端策略优化数据集,不含任何人工标注,用作强化学习从人类反馈中学习的微调输入。监督微调数据集包含约1.3万个训练提示词(来自API和标注员撰写),奖励模型数据集包含3.3万个训练提示词(来自API和标注员撰写),近端策略优化数据集则包含3.1万个训练提示词(仅来自API)。数据集规模的更多细节见表3。
3.3 人类数据采集
为生成演示与对照数据并开展主要评估,我们通过Upwork和ScaleAI平台雇佣了约40名合同工组成的标注团队。与早期在文本摘要任务中收集人类偏好数据的研究(Ziegler等人,2019;Stiennon等人,2020;Wu等人,2021)相比,我们的输入数据涵盖更广泛的任务类型,且偶尔涉及具有争议性和敏感性的话题。我们的目标是筛选出一组能够敏锐感知不同人口群体偏好、并擅长识别潜在有害输出的标注人员。为此,我们设计了针对这些维度的标注能力筛选测试(详见附录B.1)。作为探究模型对其他标注者偏好泛化能力的初步研究,我们额外雇佣了一组不参与训练数据生产的标注者。这些标注者来自相同的供应商,但未经过筛选测试。
尽管任务复杂,我们发现标注者间一致性比率相当高:训练标注者相互间的一致性达到72.6 ± 1.5%,而预留标注者的这一数值为77.3 ± 1.3%。作为对比,在Stiennon等人(2020)的摘要研究工作里,研究员间的一致性为73 ± 4%。
3.4 模型
自GPT-3(Brown等人,2020)开始,我们采用三种不同技术训练模型:
监督微调。我们使用监督学习,基于标注员示范数据对GPT-3进行微调。训练共进行16个周期,采用余弦学习率衰减,并设置0.2的残差丢弃率。我们最终基于验证集的RM分数选择SFT模型。与Wu等人(2021)的研究相似,我们发现SFT模型在1个周期后即出现验证损失过拟合;但继续训练更多周期能同时提升RM分数和人类偏好评分。
奖励模型建模。我们微调GPT-3以接收提示和回应,并输出标量奖励值。本文中我们仅使用60亿参数的RM,这大幅节省了算力消耗。我们发现1750亿参数的RM训练可能不稳定,因此不太适合作为强化学习中的价值函数(详见附录D)。
在Stiennon等人(2020)的研究中,奖励模型是在一个由同一输入下两个模型输出的比较结果组成的数据集上进行训练的。他们使用交叉熵损失函数,并将人类标注者的比较结果作为标签------奖励值的差异代表了人类标注者更偏好某一回复的对数几率。为了加速比较数据的收集,我们让标注者对K = 4到K = 9个回复进行排序,并将每个提示中所有K选2的组合比较作为一个批处理元素进行训练,以提高计算效率(详见附录D)。奖励模型的损失函数因此定义为:
l o s s ( θ ) = − 1 ( K 2 ) E ( x , y w , y l ) ∼ D log ( σ ( r θ ( x , y w ) − r θ ( x , y l ) ) ) ( 1 ) \begin{aligned}&\mathrm{loss}\left(\theta\right)=-\frac{1}{\binom{K}{2}}E_{(x,y_w,y_l)\thicksim D}\left\\log\\left(\\sigma\\left(r_\\theta\\left(x,y_w\\right)-r_\\theta\\left(x,y_l\\right)\\right)\\right)\\right\\&&\mathrm{(1)}\end{aligned} loss(θ)=−(2K)1E(x,yw,yl)∼Dlog(σ(rθ(x,yw)−rθ(x,yl)))(1)
其中 r θ ( x , y ) r_{\theta}(x, y) rθ(x,y) 是奖励模型针对提示 x x x 和补全 y 参数为 θ \theta θ 的标量输出, y w y_w yw 是成对比较 y w y_w yw 和 y l y_l yl中较优的补全,而 D D D是比较数据集。
强化学习。我们再次遵循Stiennon等人(2020)的方法,使用PPO(Schulman等人,2017)对SFT模型进行微调。环境设定为一个赌博机环境,该环境会随机呈现用户提示并期望得到针对该提示的回应。给定提示和回应后,环境会根据奖励模型产生一个奖励值,并结束当前回合。此外,我们在每个词元处添加了来自SFT模型的逐词元KL惩罚,以减轻对奖励模型的过度优化。价值函数由奖励模型初始化。我们将这些模型称为"PPO模型"。
我们还尝试将预训练梯度与PPO梯度混合,以修复在公共NLP数据集上的性能退化问题(参见附录D.4)。我们将这些模型称为"PPO-ptx"。除非另有说明,本文中的InstructGPT均指PPO-ptx模型。
基线。我们将PPO模型的性能与SFT模型及GPT-3进行对比。同时,我们也与一种通过少量示例前缀来"引导"其进入指令跟随模式的GPT-3(GPT-3-prompted)进行比较。该前缀会预先添加至用户指定的指令之前。
此外,我们还将InstructGPT与基于FLAN(Wei等人,2021)和T0(Sanh等人,2021)数据集进行微调的175B GPT-3模型进行了比较。这两个数据集均包含多种NLP任务,并为每个任务结合了自然语言指令(它们的区别在于所包含的NLP数据集以及所使用指令的风格)。我们在约100万个示例上对它们进行微调,并选择在验证集上获得最高RM分数的检查点(更多细节见附录D)。
3.5 评估
遵循Askell等人(2021)的定义,我们认为模型若具备帮助性、真实性与无害性(具体阐述见附录C.2),即可视为已对齐。我们将定量评估分为两个部分:
针对API分布情况的评估。我们的核心指标是人工偏好评分,所使用的评估提示集与训练数据同源但保持独立。当采用API提示进行评估时,我们仅筛选未参与训练的用户所提交的提示。针对每个模型,我们计算其输出优于基线策略的频率;我们选择175B参数的SFT模型作为基线,因其性能处于中等水平。此外,我们要求标注员以1-7分李克特量表对每条回复的整体质量进行评判,并为每个模型输出收集一系列元数据(参见表11)。特别地,我们收集的数据旨在捕捉不同已部署模型中可能产生危害的行为方面:我们让标注员评估输出内容在客户助手场景下是否不当、贬损受保护群体,或包含色情暴力内容。
对公共自然语言处理数据集的评估。我们针对两类公共数据集进行评估:一类捕获语言模型安全性的某个方面,特别是真实性、毒性和偏见;另一类捕获在传统自然语言处理任务(如问答、阅读理解和文本摘要)上的零样本性能。我们还在RealToxicityPrompts数据集(Gehman等人,2020)上进行了人工评估。
4.结论
4.1 API分布结果
标注员明显更倾向于InstructGPT的输出而非GPT-3。在我们的测试集上,无论模型规模大小,标注员都对InstructGPT输出表现出显著偏好(图1)。研究发现GPT-3输出表现最差,通过精心设计的少样本提示(GPT-3(提示优化))可获得显著阶段式提升,随后通过监督学习进行演示训练(SFT),最终通过PPO算法基于对比数据进行训练能实现进一步改进。在PPO训练期间加入预训练混合数据更新并未明显改变标注员偏好。为说明提升幅度:在直接比较中,175B参数的InstructGPT输出以85±3%的比率优于GPT-3输出,并以71±4%的比率优于少样本GPT-3输出。
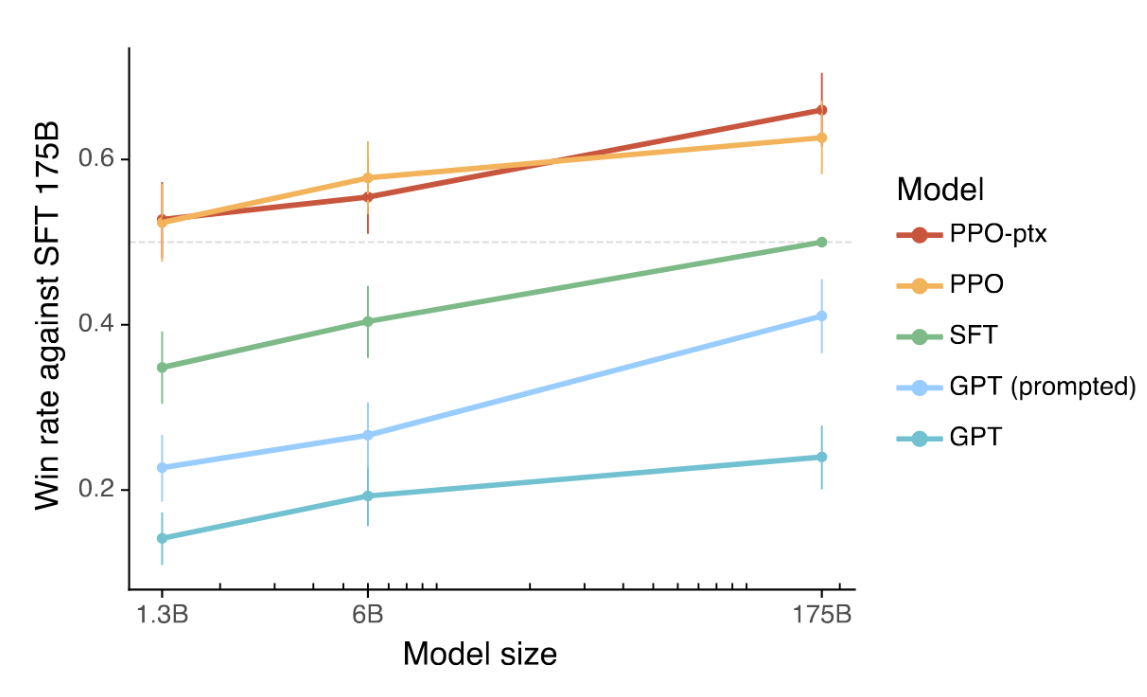
图1:基于API提示分布对各模型的人工评估结果,评估标准为各模型输出优于175B SFT模型输出的频率。我们的InstructGPT模型(PPO-ptx)及其未使用预训练混合数据的变体(PPO)显著优于所有GPT-3基线模型(原始GPT及提示优化版GPT);1.3B参数的PPO-ptx模型输出甚至优于175B参数的GPT-3模型。本文中所有误差棒均表示95%置信区间。
图4显示,标注者也从几个更具体的维度对InstructGPT的输出给予积极评价。具体而言,相比于GPT-3,InstructGPT的输出在客服助理的语境下更得体,更频繁地遵循指令中明确定义的约束(例如"请将答案控制在两段以内"),完全未能遵循正确指令的情况更少,且在封闭领域任务中编造事实("幻觉")的频率更低。
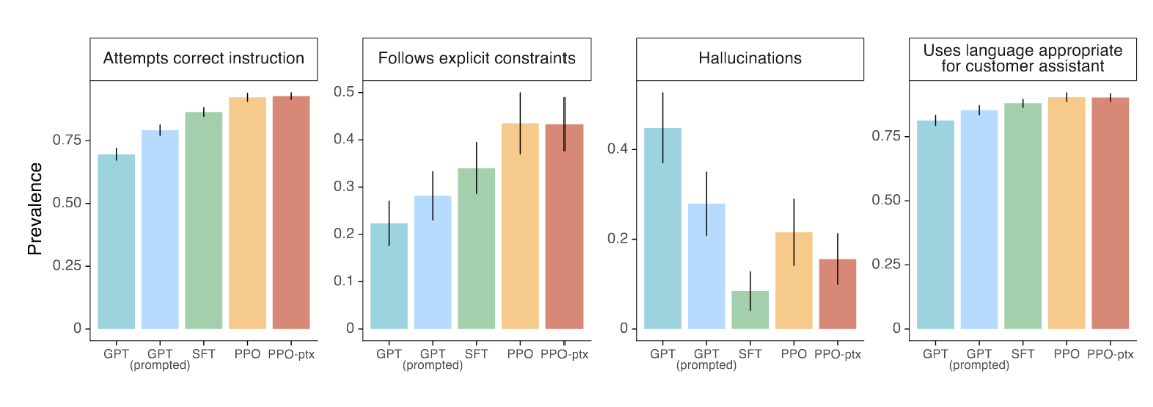
图4:按模型规模平均得出的API分布元数据结果。
我们的模型能够泛化到未参与训练数据标注的"保留"标注者的偏好。保留标注者与参与生成训练数据的工作者具有相似的排序偏好(见图3)。具体而言,根据保留标注者的评估,我们所有的InstructGPT模型仍然显著优于GPT-3基线模型。这表明我们的InstructGPT模型并未简单地过拟合训练标注者的偏好。
公开的NLP数据集并不能反映我们语言模型的实际使用情况。在图5a中,我们还将InstructGPT与基于FLAN(Wei等人,2021)和T0(Sanh等人,2021)数据集微调的1750亿参数GPT-3基线模型进行了比较(详见附录D)。我们发现这些模型的表现优于GPT-3,与经过精心设计提示词的GPT-3相当,但不及我们的监督微调基线模型。这表明这些数据集的多样性不足以提升模型在我们API提示词分布上的性能。我们认为部分原因在于学术数据集主要关注易于评估性能的任务(如分类和问答),而我们的API请求分布中大部分(约57%)属于开放式生成任务。
4.2 公开自然语言处理数据集上的结果
InstructGPT模型在真实性方面相比GPT-3有所提升。根据人类评估者在TruthfulQA数据集上的评判,我们的PPO模型在生成真实且信息丰富的输出内容时,相比GPT-3虽幅度有限但具有显著改进(见图5b)。这是模型的默认表现:即使未专门被要求"说真话",我们的模型仍能展现更强的真实性。有趣的是,我们的13亿参数PPO-ptx模型是个例外,其表现略逊于同规模的GPT-3模型。在封闭领域任务中,PPO模型产生幻觉的频率更低(图4),这也印证了我们在真实性方面的改进。
InstructGPT在毒性控制方面较GPT-3略有改进,但在偏见问题上未见改善。我们首先通过人工评估的方法,在RealToxicityPrompts数据集(Gehman等人,2020)上评估了模型性能,结果如图5c所示。研究发现,当使用要求生成安全、尊重性内容的引导指令时("尊重性指令"),根据Perspective API的评估,InstructGPT模型产生的输出毒性低于GPT-3。但若移除尊重性指令("无指令"),该优势即消失。使用Perspective API进行评估时我们也观察到类似结果(附录F.7)。
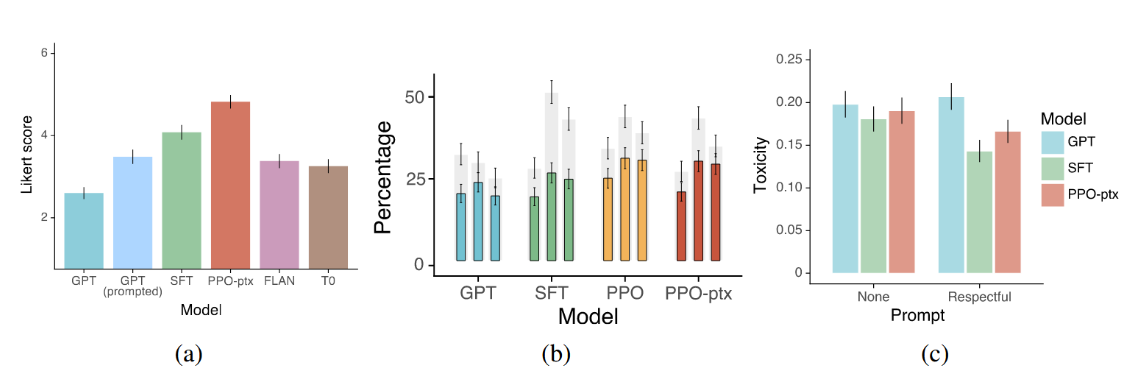
图5:(a) 在1-7李克特量表上,于我们的提示分布中比较我们的模型与基于FLAN和T0数据集微调的GPT-3模型。(b) TruthfulQA数据集上的人工评估结果。灰色条形表示真实性评分;彩色条形表示真实性与信息性综合评分。© RealToxicityPrompts数据集上的人工评估结果,包含及不包含"尊重性"指令的对比。
通过改进我们的RLHF微调流程,能够有效降低在公开NLP数据集上的性能衰退。图25显示,在PPO微调过程中加入预训练更新(PPO-ptx)可缓解公开NLP数据集的性能衰退,甚至在HellaSwag基准上超越了GPT-3。但PPO-ptx模型在DROP、SQuADv2和翻译任务上的表现仍落后于GPT-3,需要进一步研究以消除这些性能差距。我们还发现,融合预训练更新的方法比单纯增大KL系数(图36)这一简单方案效果更佳。
4.3 定性分析结果
InstructGPT模型在RLHF微调分布之外的指令上展现出良好的泛化能力。特别值得注意的是,我们发现InstructGPT能够遵循非英语语言的指令,并具备对代码进行总结和问答的能力。这一现象尤为有趣,因为非英语语言和代码在我们的微调数据中只占极小比例,这表明在某些情况下,对齐方法能够泛化至人类未直接监督的输入数据上,并产生预期行为。我们在图26中展示了一些定性示例。
InstructGPT仍会犯简单错误。在我们与175B参数的PPO-ptx模型交互过程中发现,尽管该模型在诸多语言任务上表现优异,但仍会出现基础性失误。具体示例如下:(1) 当指令包含错误前提时,模型有时会误认前提为真;(2) 模型可能存在过度规避倾向:面对简单问题时,即使上下文存在明确答案,它仍可能声称问题没有唯一解并给出多种可能答案;(3) 当指令包含多重明确约束时,模型性能会下降。例如"列举10部1930年代以法国为背景的电影",或遇到对语言模型具有挑战性的约束条件时,模型表现亦会受限。
我们在图27中展示了这些行为的若干示例。我们推测,行为(2)的部分成因在于我们指示标注者奖励认知谦逊;因此他们可能倾向于奖励那些采用谨慎措辞的输出,而这一点被我们的奖励模型所捕捉。我们怀疑行为(1)的出现是因为训练集中包含错误前提的提示很少,导致我们的模型未能很好地泛化到此类示例。我们相信,通过对抗性数据收集(Dinan等人,2019),这两种行为都可以得到显著减少。
5.讨论
5.1 对齐研究的启示
本研究中对齐研究的方法是迭代式的:我们改进现有AI系统的对齐能力,而非抽象地关注尚未存在的AI系统对齐问题,这为我们提供了清晰的经验反馈循环,以明确何种方法有效、何种无效。我们相信这种反馈循环对于完善对齐技术至关重要,同时也迫使我们紧跟机器学习的进展步伐。
从这项工作中,我们可以为更广泛的对齐研究汲取经验。首先,提升模型对齐所需的成本相较于预训练而言是适中的。训练我们的175B SFT模型需要4.9千万亿次浮点运算/天,训练175B PPO-ptx模型需要60千万亿次浮点运算/天,而GPT-3(Brown等人,2020)的训练则需要3,640千万亿次浮点运算/天。与此同时,我们的研究结果表明,RLHF在使语言模型对用户更有帮助方面非常有效,其效果甚至超过了将模型规模扩大100倍。这表明,当前加大对现有语言模型对齐能力的投入,比训练更大规模的模型更具成本效益。其次,我们有证据表明InstructGPT能够将"遵循指令"的能力泛化到我们未进行监督的场景中。这是一个重要特性,因为让人工去监督模型执行的每一项任务成本极高。最后,我们成功缓解了由微调引入的大部分性能下降。若非如此,这些性能下降将构成一种"对齐税"------即对齐模型所需的额外成本。任何具有高额"税收"的对齐技术可能都无法得到采用,因此避免这种税负至关重要。
5.2 局限性
方法论 我们的InstructGPT模型的行为部分取决于从合约标注人员处获得的人类反馈。部分标注任务依赖于价值判断,这些判断可能受到标注人员的身份、信念、文化背景和个人经历的影响。我们保持合约标注团队的规模较小,因为这有助于与这个全职从事标注工作的小规模团队进行高带宽沟通。然而,这个群体显然无法代表受这些模型影响的全体人群。一个简单的例子是,我们的标注人员主要讲英语,且我们的数据几乎全部由英文指令构成。
模型。我们的模型尚未实现完全对齐或完全安全;它们仍可能生成带有毒性或偏见的输出、捏造事实,并在未收到明确指令的情况下生成色情与暴力内容。对于某些输入,它们也可能无法生成合理的输出;我们在图27中展示了部分示例。我们的模型或许最显著的局限在于,多数情况下它们会遵循用户的指令,即便这些指令可能在现实世界中导致危害。例如,当要求模型展现最大程度偏见时,与同等规模的GPT-3模型相比,InstructGPT会生成更具毒性的输出。
5.3 更广泛的影响
本研究的动机在于,我们希望通过训练大型语言模型执行特定人类群体期望的任务,以增强其积极影响。默认情况下,语言模型优化的是下一个词预测目标,但这仅仅是我们期望模型达成目标的代理指标。我们的结果表明,所提出的技术有望使语言模型更具帮助性、真实性与无害性。从长远来看,若这些模型被部署于安全关键场景中,对齐失败可能导致更为严重的后果。
然而,提升语言模型遵循用户意图的能力也使其更易遭到滥用。这些模型可能被更轻易地用于生成具有说服力的虚假信息、仇恨言论或侮辱性内容。对齐技术并非解决大型语言模型安全问题的万灵药;相反,它们应被视为更广泛安全生态系统中的一种工具。除故意滥用外,在许多领域部署大型语言模型时需极度审慎,甚至应完全避免。这包括医疗诊断、基于受保护特征对人进行分类、判定信贷/就业/住房资格、生成政治广告以及执法等高风险领域。
最后,关于这些模型与谁的价值对齐这一问题极为关键,并将显著影响这些模型的净效应是正面还是负面;我们将在附录G.2中对此进行讨论。
6.引用文献
- Achiam, J., Held, D., Tamar, A., and Abbeel, P. (2017). Constrained policy optimization. In International Conference on Machine Learning, pages 22--31. PMLR.
- Anthony, T., Tian, Z., and Barber, D. (2017). Thinking fast and slow with deep learning and tree search. arXiv preprint arXiv:1705.08439.
- Aribandi, V., Tay, Y., Schuster, T., Rao, J., Zheng, H. S., Mehta, S. V., Zhuang, H., Tran, V. Q., Bahri, D., Ni, J., et al. (2021). Ext5: Towards extreme multi-task scaling for transfer learning. arXiv preprint arXiv:2111.10952.
- Askell, A., Bai, Y., Chen, A., Drain, D., Ganguli, D., Henighan, T., Jones, A., Joseph, N., Mann, B., DasSarma, N., et al. (2021). A general language assistant as a laboratory for alignment. arXiv preprint arXiv:2112.00861.
- Bahdanau, D., Brakel, P., Xu, K., Goyal, A., Lowe, R., Pineau, J., Courville, A., and Bengio, Y. (2016). An actor-critic algorithm for sequence prediction. arXiv preprint arXiv:1607.07086.
- Bai, Y., Jones, A., Ndousse, K., Askell, A., Chen, A., DasSarma, N., Drain, D., Fort, S., Ganguli, D., Henighan, T., et al. (2022). Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862.
- Bender, E. M., Gebru, T., McMillan-Major, A., and Shmitchell, S. (2021). On the dangers of stochastic parrots: Can language models be too big? In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, pages 610--623.
- Böhm, F., Gao, Y., Meyer, C. M., Shapira, O., Dagan, I., and Gurevych, I. (2019). Better rewards yield better summaries: Learning to summarise without references. arXiv preprint arXiv:1909.01214.
- Bojar, O., Chatterjee, R., Federmann, C., Haddow, B., Huck, M., Hokamp, C., Koehn, P., Logacheva, V., Monz, C., Negri, M., Post, M., Scarton, C., Specia, L., and Turchi, M. (2015). Findings of the 2015 workshop on statistical machine translation. In Proceedings of the Tenth Workshop on Statistical Machine Translation, pages 1--46, Lisbon, Portugal. Association for Computational Linguistics.
- Bommasani, R., Hudson, D. A., Adeli, E., Altman, R., Arora, S., von Arx, S., Bernstein, M. S., Bohg, J., Bosselut, A., Brunskill, E., et al. (2021). On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258. Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. (2020). Language models are few-shot learners. arXiv preprint arXiv:2005.14165.
- Buchanan, B., Lohn, A., Musser, M., and Sedova, K. (2021). Truth, lies, and automation. Technical report, Center for the Study of Emerging Technology. Caliskan, A., Bryson, J. J., and Narayanan, A. (2017). Semantics derived automatically from language corpora contain human-like biases. Science, 356(6334):183--186.
- Carlini, N., Tramer, F., Wallace, E., Jagielski, M., Herbert-Voss, A., Lee, K., Roberts, A., Brown, T., Song, D., Erlingsson, U., et al. (2021). Extracting training data from large language models. In 30th USENIX Security Symposium (USENIX Security 21), pages 2633--2650.
- Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H. P. d. O., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., et al. (2021). Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374.
- Cho, W. S., Zhang, P., Zhang, Y., Li, X., Galley, M., Brockett, C., Wang, M., and Gao, J. (2018). Towards coherent and cohesive long-form text generation. arXiv preprint arXiv:1811.00511.
- Choi, E., He, H., Iyyer, M., Yatskar, M., Yih, W.-t., Choi, Y., Liang, P., and Zettlemoyer, L. (2018). Quac: Question answering in context. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2174--2184.
- Christiano, P. F., Leike, J., Brown, T., Martic, M., Legg, S., and Amodei, D. (2017). Deep reinforcement learning from human preferences. In Advances in Neural Information Processing Systems, pages 4299--4307.
- Dathathri, S., Madotto, A., Lan, J., Hung, J., Frank, E., Molino, P., Yosinski, J., and Liu, R. (2019). Plug and play language models: A simple approach to controlled text generation. arXiv preprint arXiv:1912.02164.
- Dhamala, J., Sun, T., Kumar, V., Krishna, S., Pruksachatkun, Y., Chang, K.-W., and Gupta, R. (2021). Bold: Dataset and metrics for measuring biases in open-ended language generation. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, pages 862--872.
- Dinan, E., Humeau, S., Chintagunta, B., and Weston, J. (2019). Build it break it fix it for dialogue safety: Robustness from adversarial human attack. arXiv preprint arXiv:1908.06083.
- Dua, D., Wang, Y., Dasigi, P., Stanovsky, G., Singh, S., and Gardner, M. (2019). Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. arXiv preprint arXiv:1903.00161.
- Fedus, W., Zoph, B., and Shazeer, N. (2021). Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. arXiv preprint arXiv:2101.03961.
- Gabriel, I. (2020). Artificial intelligence, values, and alignment. Minds and machines, 30(3):411--437.
- Gehman, S., Gururangan, S., Sap, M., Choi, Y., and Smith, N. A. (2020). Realtoxicityprompts: Evaluating neural toxic degeneration in language models. arXiv preprint arXiv:2009.11462.
- Hancock, B., Bordes, A., Mazare, P.-E., and Weston, J. (2019). Learning from dialogue after deployment: Feed yourself, chatbot! arXiv preprint arXiv:1901.05415.
- Ibarz, B., Leike, J., Pohlen, T., Irving, G., Legg, S., and Amodei, D. (2018). Reward learning from human preferences and demonstrations in atari. In Advances in neural information processing systems, pages 8011--8023.
- Jaques, N., Ghandeharioun, A., Shen, J. H., Ferguson, C., Lapedriza, A., Jones, N., Gu, S., and Picard, R. (2019). Way off-policy batch deep reinforcement learning of implicit human preferences in dialog. arXiv preprint arXiv:1907.00456.
- Kenton, Z., Everitt, T., Weidinger, L., Gabriel, I., Mikulik, V., and Irving, G. (2021). Alignment of language agents. arXiv preprint arXiv:2103.14659.
- Keskar, N. S., McCann, B., Varshney, L. R., Xiong, C., and Socher, R. (2019). Ctrl: A conditional transformer language model for controllable generation. arXiv preprint arXiv:1909.05858.
- Khashabi, D., Min, S., Khot, T., Sabharwal, A., Tafjord, O., Clark, P., and Hajishirzi, H. (2020). Unifiedqa: Crossing format boundaries with a single qa system. arXiv preprint arXiv:2005.00700.
- Kirk, H., Jun, Y., Iqbal, H., Benussi, E., Volpin, F., Dreyer, F. A., Shtedritski, A., and Asano, Y. M. (2021). How true is gpt-2? an empirical analysis of intersectional occupational biases. arXiv preprint arXiv:2102.04130.
- Krause, B., Gotmare, A. D., McCann, B., Keskar, N. S., Joty, S., Socher, R., and Rajani, N. F. (2020). Gedi: Generative discriminator guided sequence generation. arXiv preprint arXiv:2009.06367.
- Kreutzer, J., Khadivi, S., Matusov, E., and Riezler, S. (2018). Can neural machine translation be improved with user feedback? arXiv preprint arXiv:1804.05958.
- Lawrence, C. and Riezler, S. (2018). Improving a neural semantic parser by counterfactual learning from human bandit feedback. arXiv preprint arXiv:1805.01252.
- Leike, J., Krueger, D., Everitt, T., Martic, M., Maini, V., and Legg, S. (2018). Scalable agent alignment via reward modeling: a research direction. arXiv preprint arXiv:1811.07871.
- Liang, P. P., Wu, C., Morency, L.-P., and Salakhutdinov, R. (2021). Towards understanding and mitigating social biases in language models. In International Conference on Machine Learning, pages 6565--6576. PMLR.
- Lin, S., Hilton, J., and Evans, O. (2021). Truthfulqa: Measuring how models mimic human falsehoods. arXiv preprint arXiv:2109.07958.
- Manela, D. d. V., Errington, D., Fisher, T., van Breugel, B., and Minervini, P. (2021). Stereotype and skew: Quantifying gender bias in pre-trained and fine-tuned language models. arXiv preprint arXiv:2101.09688.
- Mishra, S., Khashabi, D., Baral, C., and Hajishirzi, H. (2021). Cross-task generalization via natural language crowdsourcing instructions. arXiv preprint arXiv:2104.08773.
- Nakano, R., Hilton, J., Balaji, S., Wu, J., Ouyang, L., Kim, C., Hesse, C., Jain, S., Kosaraju, V., Saunders, W., et al. (2021). Webgpt: Browser-assisted question-answering with human feedback. arXiv preprint arXiv:2112.09332.
- Nallapati, R., Zhou, B., Gulcehre, C., Xiang, B., et al. (2016). Abstractive text summarization using sequence-to-sequence rnns and beyond. arXiv preprint arXiv:1602.06023.
- Nangia, N., Vania, C., Bhalerao, R., and Bowman, S. R. (2020). CrowS-Pairs: A Challenge Dataset for Measuring Social Biases in Masked Language Models. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, Online. Association for Computational Linguistics.
- Ngo, H., Raterink, C., Araújo, J. G., Zhang, I., Chen, C., Morisot, A., and Frosst, N. (2021). Mitigating harm in language models with conditional-likelihood filtration. arXiv preprint arXiv:2108.07790.
- Perez, E., Karamcheti, S., Fergus, R., Weston, J., Kiela, D., and Cho, K. (2019). Finding generalizable evidence by learning to convince q&a models. arXiv preprint arXiv:1909.05863.
- Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., and Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI Blog, 1(8):9.
- Rae, J. W., Borgeaud, S., Cai, T., Millican, K., Hoffmann, J., Song, F., Aslanides, J., Henderson, S., Ring, R., Young, S., et al. (2021). Scaling language models: Methods, analysis & insights from training gopher. arXiv preprint arXiv:2112.11446.
- Rajpurkar, P., Jia, R., and Liang, P. (2018). Know what you don't know: Unanswerable questions for squad. arXiv preprint arXiv:1806.03822.
- Rudinger, R., Naradowsky, J., Leonard, B., and Van Durme, B. (2018). Gender bias in coreference resolution. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, Louisiana. Association for Computational Linguistics.
- Sanh, V., Webson, A., Raffel, C., Bach, S. H., Sutawika, L., Alyafeai, Z., Chaffin, A., Stiegler, A., Scao, T. L., Raja, A., et al. (2021). Multitask prompted training enables zero-shot task generalization. arXiv preprint arXiv:2110.08207.
- Schulman, J., Moritz, P., Levine, S., Jordan, M., and Abbeel, P. (2016). High-dimensional continuous control using generalized advantage estimation. In Proceedings of the International Conference on Learning Representations (ICLR). Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. (2017). Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347.
- Silver, D., Hubert, T., Schrittwieser, J., Antonoglou, I., Lai, M., Guez, A., Lanctot, M., Sifre, L., Kumaran, D., Graepel, T., et al. (2017). Mastering chess and shogi by self-play with a general reinforcement learning algorithm. arXiv preprint arXiv:1712.01815.
- Socher, R., Perelygin, A., Wu, J., Chuang, J., Manning, C. D., Ng, A. Y., and Potts, C. (2013). Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 conference on empirical methods in natural language processing, pages 1631--1642.
- Solaiman, I., Brundage, M., Clark, J., Askell, A., Herbert-Voss, A., Wu, J., Radford, A., Krueger, G., Kim, J. W., Kreps, S., et al. (2019). Release strategies and the social impacts of language models. arXiv preprint arXiv:1908.09203.
- Solaiman, I. and Dennison, C. (2021). Process for adapting language models to society (palms) with values-targeted datasets. arXiv preprint arXiv:2106.10328.
- Stiennon, N., Ouyang, L., Wu, J., Ziegler, D. M., Lowe, R., Voss, C., Radford, A., Amodei, D., and Christiano, P. (2020). Learning to summarize from human feedback. arXiv preprint arXiv:2009.01325.
- Tamkin, A., Brundage, M., Clark, J., and Ganguli, D. (2021). Understanding the capabilities, limitations, and societal impact of large language models. arXiv preprint arXiv:2102.02503.
- Thoppilan, R., De Freitas, D., Hall, J., Shazeer, N., Kulshreshtha, A., Cheng, H.-T., Jin, A., Bos, T., Baker, L., Du, Y., et al. (2022). Lamda: Language models for dialog applications. arXiv preprint arXiv:2201.08239.
- Völske, M., Potthast, M., Syed, S., and Stein, B. (2017). Tl; dr: Mining reddit to learn automatic summarization. In Proceedings of the Workshop on New Frontiers in Summarization, pages 59--63.
- Wang, A., Pruksachatkun, Y., Nangia, N., Singh, A., Michael, J., Hill, F., Levy, O., and Bowman, S. R. (2019). Superglue: A stickier benchmark for general-purpose language understanding systems. arXiv preprint arXiv:1905.00537.
- Wei, J., Bosma, M., Zhao, V. Y., Guu, K., Yu, A. W., Lester, B., Du, N., Dai, A. M., and Le, Q. V. (2021). Finetuned language models are zero-shot learners. arXiv preprint arXiv:2109.01652.
- Weidinger, L., Mellor, J., Rauh, M., Griffin, C., Uesato, J., Huang, P.-S., Cheng, M., Glaese, M., Balle, B., Kasirzadeh, A., et al. (2021). Ethical and social risks of harm from language models. arXiv preprint arXiv:2112.04359.
- Wu, J., Ouyang, L., Ziegler, D. M., Stiennon, N., Lowe, R., Leike, J., and Christiano, P. (2021). Recursively summarizing books with human feedback. arXiv preprint arXiv:2109.10862.
- Xu, J., Ju, D., Li, M., Boureau, Y.-L., Weston, J., and Dinan, E. (2020). Recipes for safety in open-domain chatbots. arXiv preprint arXiv:2010.07079.
- Yi, S., Goel, R., Khatri, C., Cervone, A., Chung, T., Hedayatnia, B., Venkatesh, A., Gabriel, R., and Hakkani-Tur, D. (2019). Towards coherent and engaging spoken dialog response generation using automatic conversation evaluators. arXiv preprint arXiv:1904.13015.
- Zellers, R., Holtzman, A., Bisk, Y., Farhadi, A., and Choi, Y. (2019). Hellaswag: Can a machine really finish your sentence? In Association for Computational Linguistics, pages 4791--4800.
- Zhou, W. and Xu, K. (2020). Learning to compare for better training and evaluation of open domain natural language generation models. arXiv preprint arXiv:2002.05058.
- Ziegler, D. M., Stiennon, N., Wu, J., Brown, T. B., Radford, A., Amodei, D., Christiano, P., and Irving, G. (2019). Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593.