在本文中,我们将分析 Ghidra 中的 STM32 固件二进制文件。该固件适用于意法半导体的 STM32F103C 开发板。
分析固件二进制文件,通常与分析 PE 或 ELF 文件不同。PE(可移植可执行文件)是 Windows 上的标准可执行文件格式。.exe文件是底层的 PE。PE 文件格式适用于 32 位 Windows 系统。PE64 文件格式与 PE 类似,但适用于 64 位系统。
相应地,在 Linux 上,我们有 ELF(可执行和可链接格式)文件,其用途相同。这两种文件格式都具有明确的结构。它们都有一个文件头,描述了文件在执行时在内存中的存放方式。文件头中提供了代码段和数据段的地址。Ghidra 等反汇编程序会利用这些信息自动区分代码段和数据段,并将文件加载到正确的地址。
另一方面,扁平固件文件只是一个二进制 blob,一堆字节,没有文件头或描述文件布局的元数据。在检查此类文件时,分析师必须亲自将信息提供给 Ghidra。
安装
下载地址:https://github.com/NationalSecurityAgency/ghidra
在github里下载后进入文件夹,安装java环境:jdk-24版本
然后运行工具ghidraRun.bat
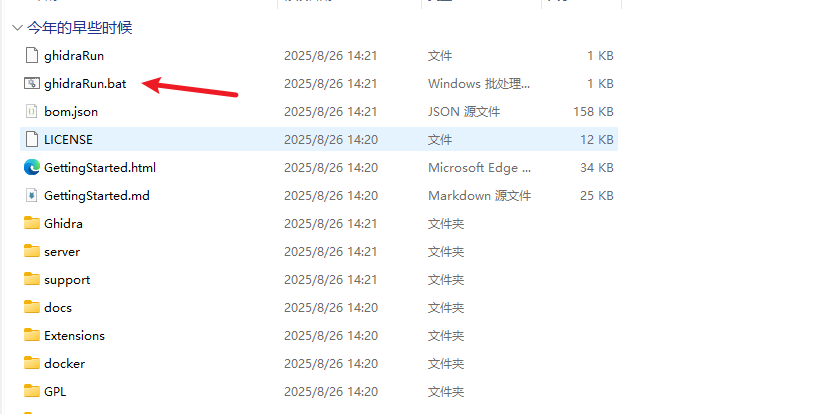
运行后会出现这个黑色的框框
将我们准备好的jdk文件根目录复制上去,然后回车
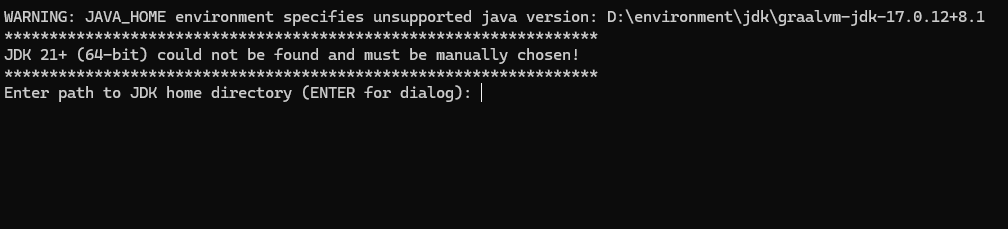
将我们准备好的jdk文件根目录复制上去,然后回车
如果出现这个界面的话就是配置成功

如图所示,我们只需保留主程序窗口就可以了
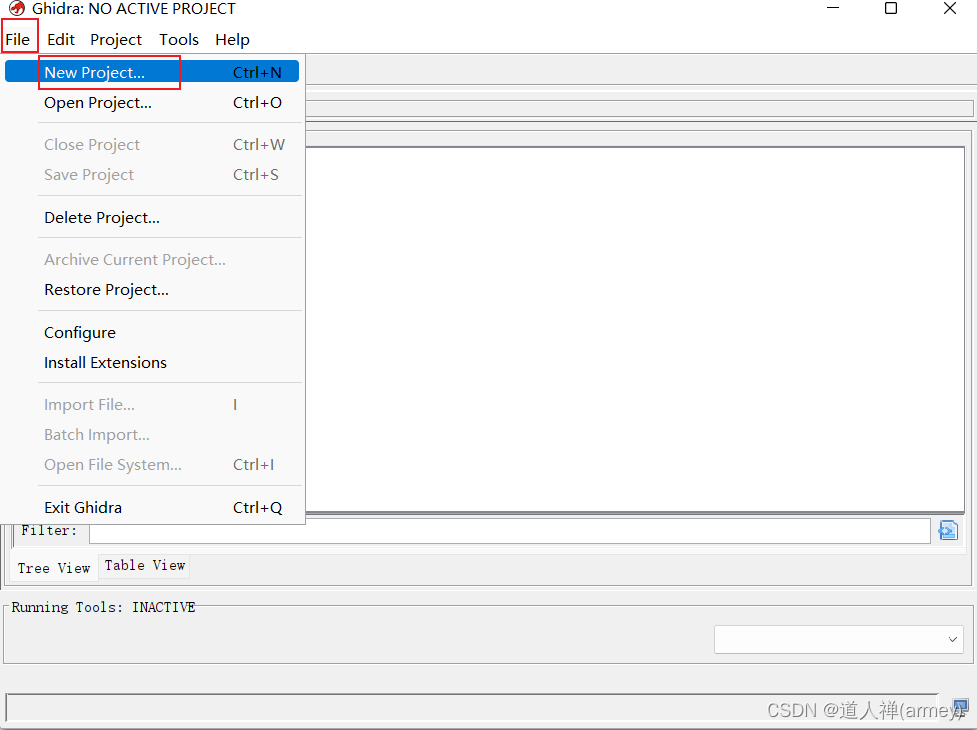
创建项目
- 在初始界面左上角选择
File->New Project...(也可以使用快捷键Ctrl+N)
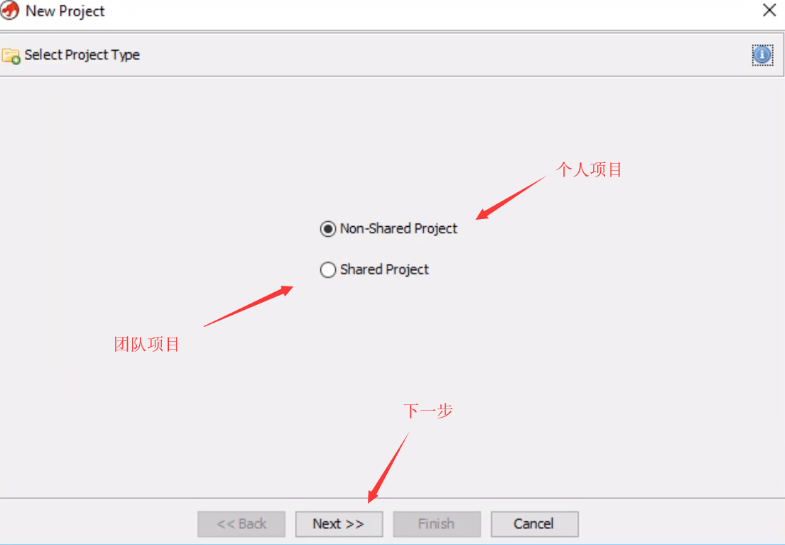
- 选择
Non-Shared Project,单击Next(另一个选择Shared Project是会在本地监听一个端口,方便分享)
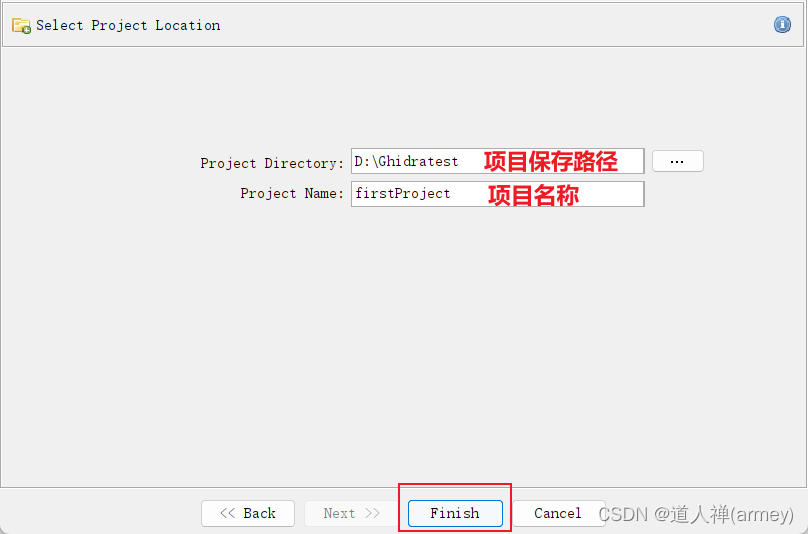
- 设置项目的保存路径 和项目的名称 ,设置完成后点击
Finish即可
导入项目文件
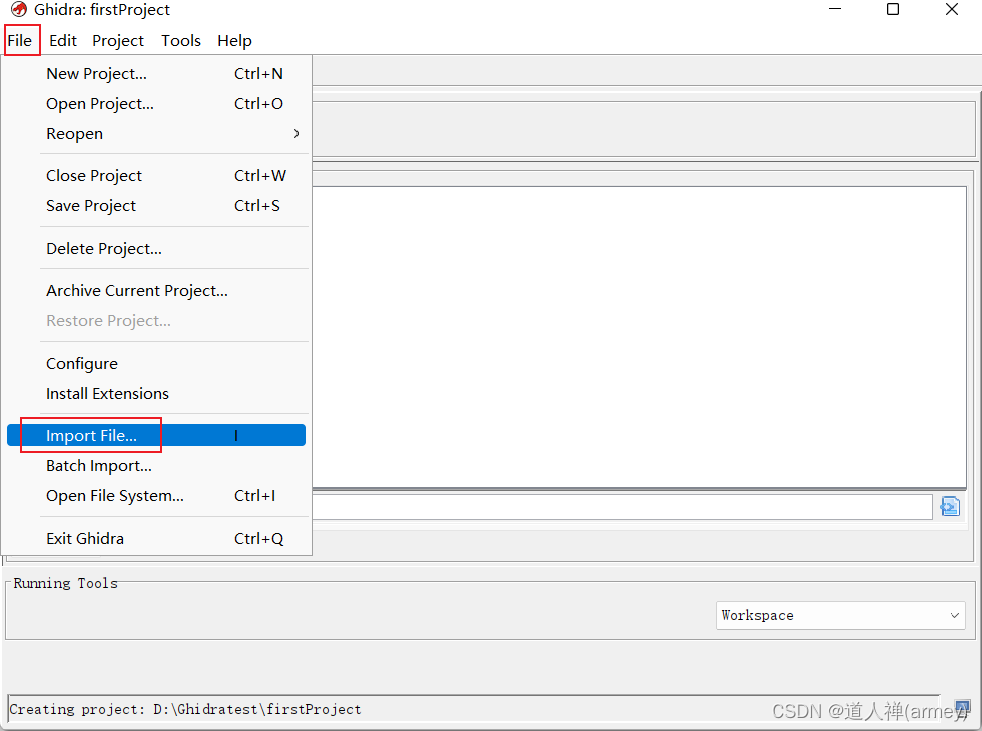
- 可以选择左上角的
File->Import File...(也可以直接将文件拖拽进Ghidra中)
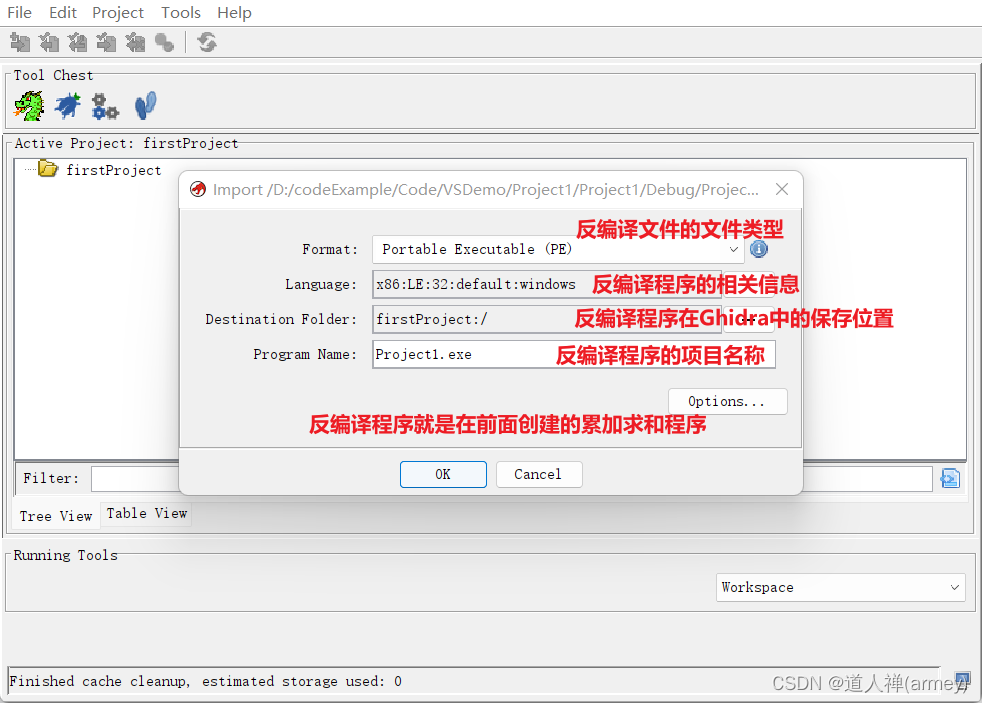
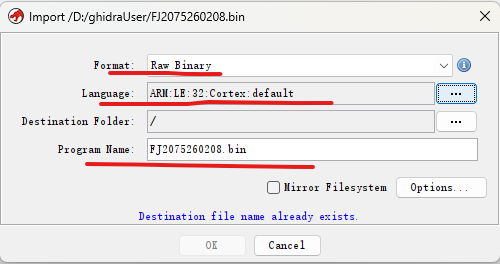
设置导入文件的信息
STM32F103 是一系列基于ARM Cortex-M3处理器的微控制器。而Cortex-M3 是一款 32 位处理器,默认内存端模式是小端模式。点击"语言选项"按钮,并将语言设置为"ARM-Cortex-32-little"。
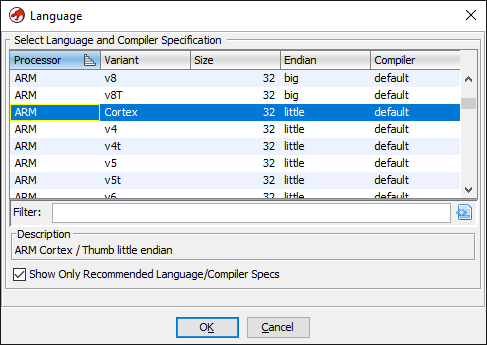
配置后,单击OK按钮即可
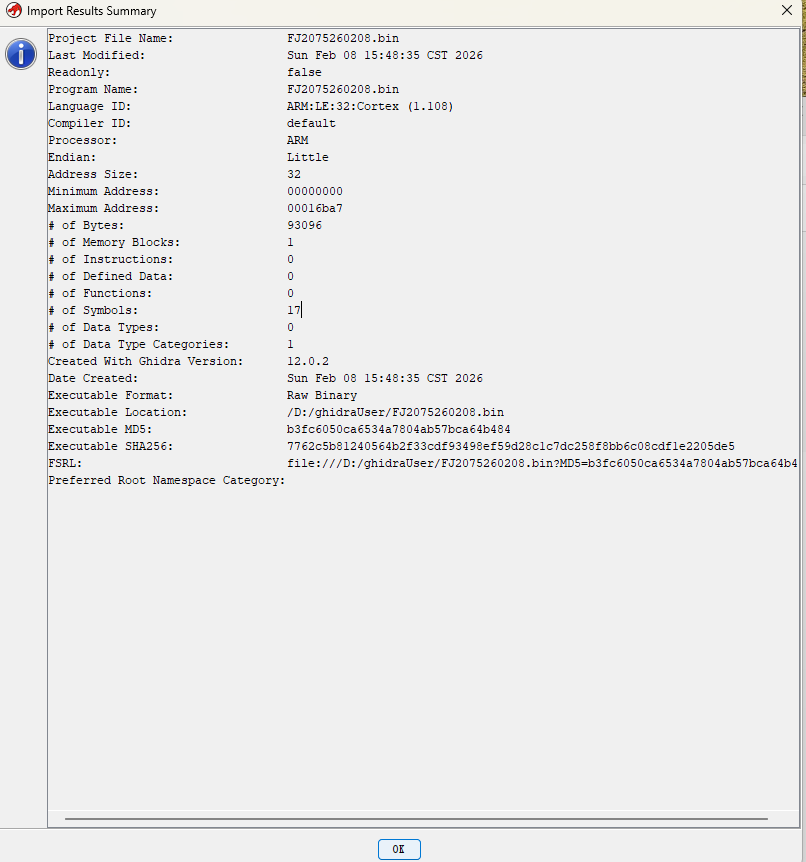
- 完成上述步骤后,Ghidra会进行自动分析,等待一段时间(取决于反编译软件的复杂程度),Ghidra会显示出反编译软件的相关信息
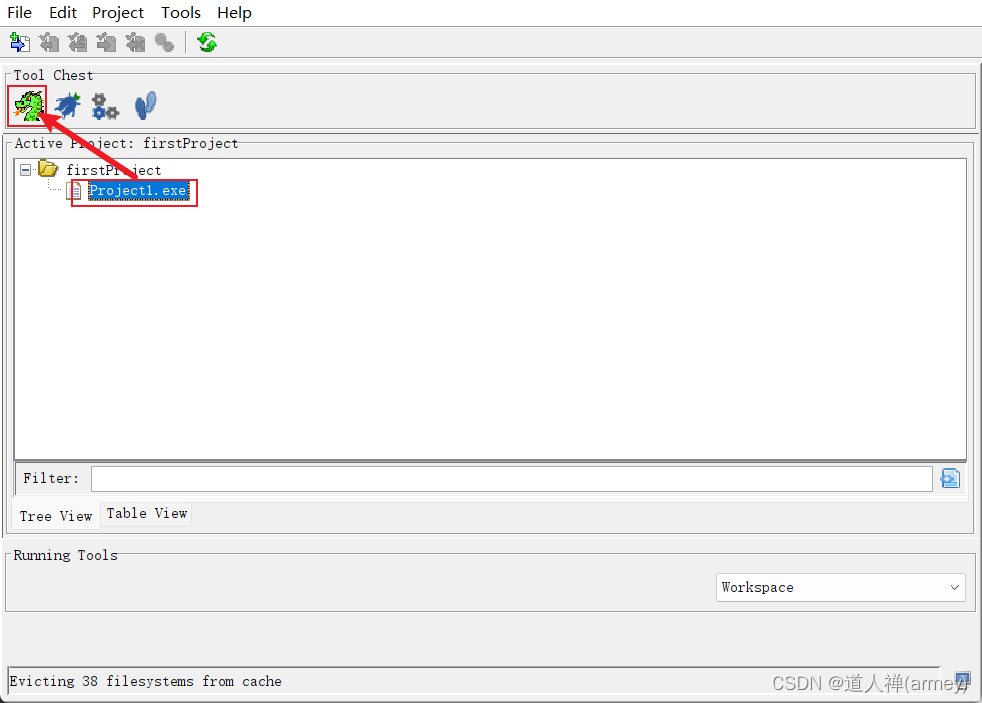
打开项目
- 将反编译的软件拖拽进Ghidra的CodeBrowser(左上角的龙图标)
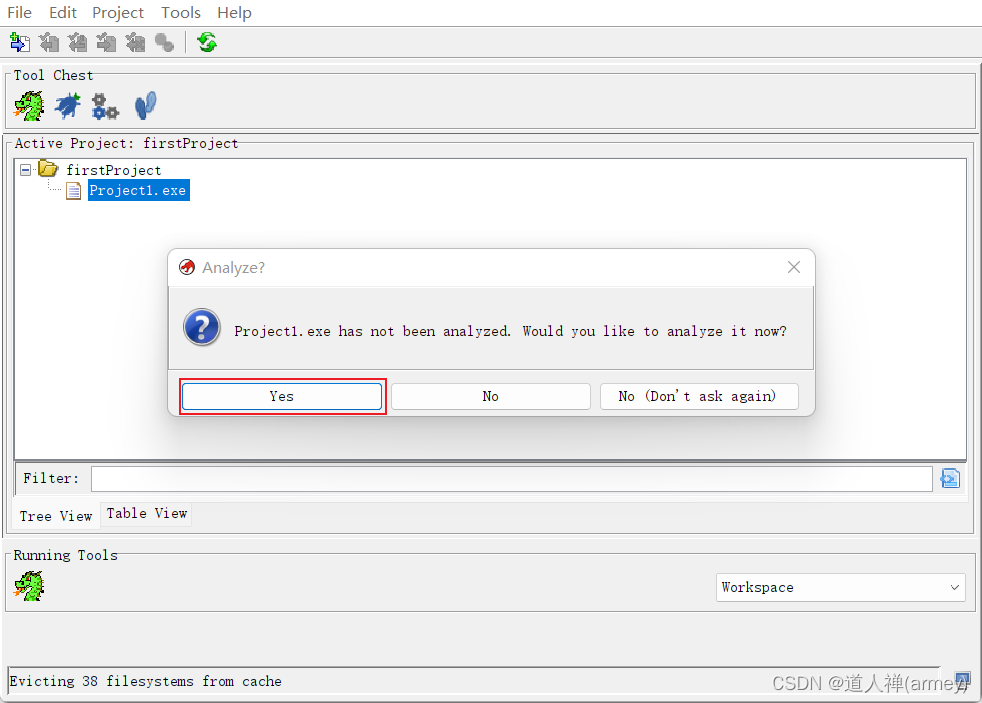
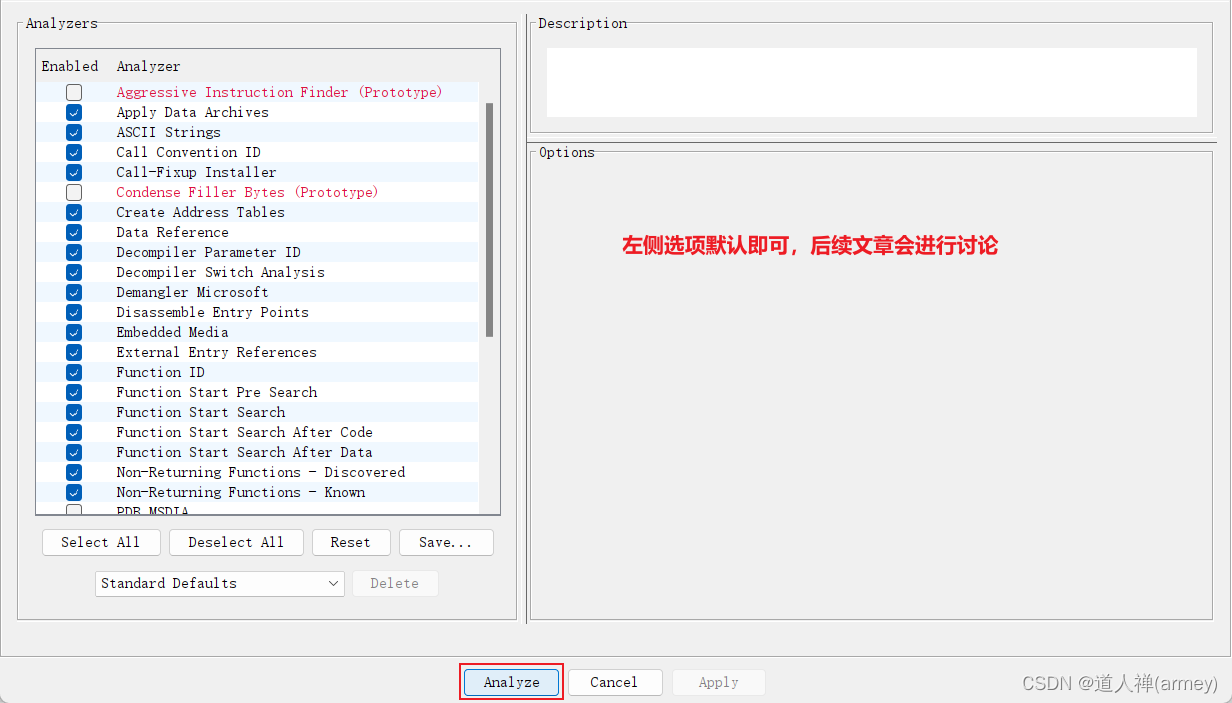
- 首次打开,会提示是否对反编译软件进行分析,单击
Yes,接着单击Analyze
我们现在可以继续加载文件并双击在反汇编程序中打开。
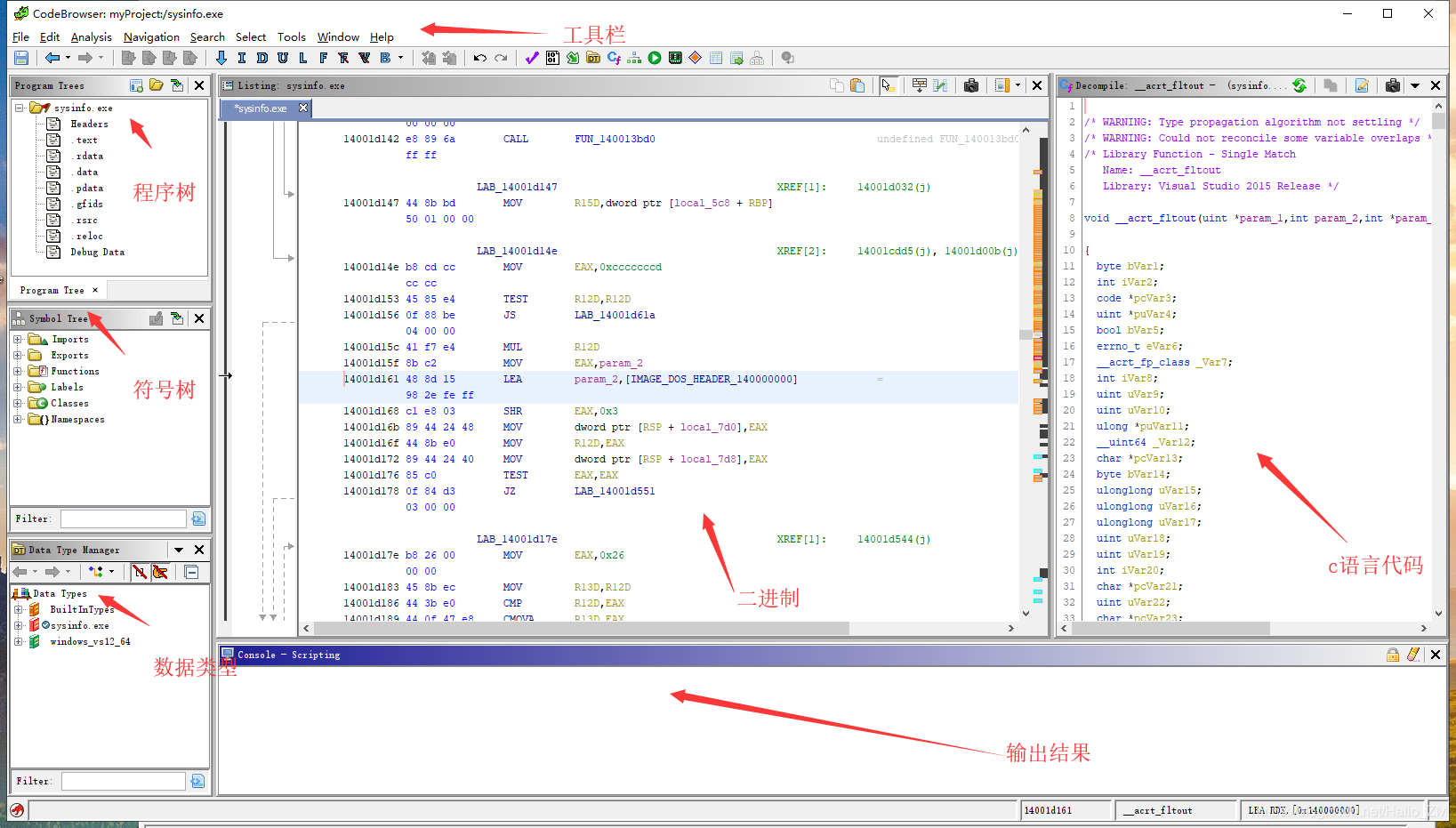
- 等待一段时间就可以得到反编译结果了
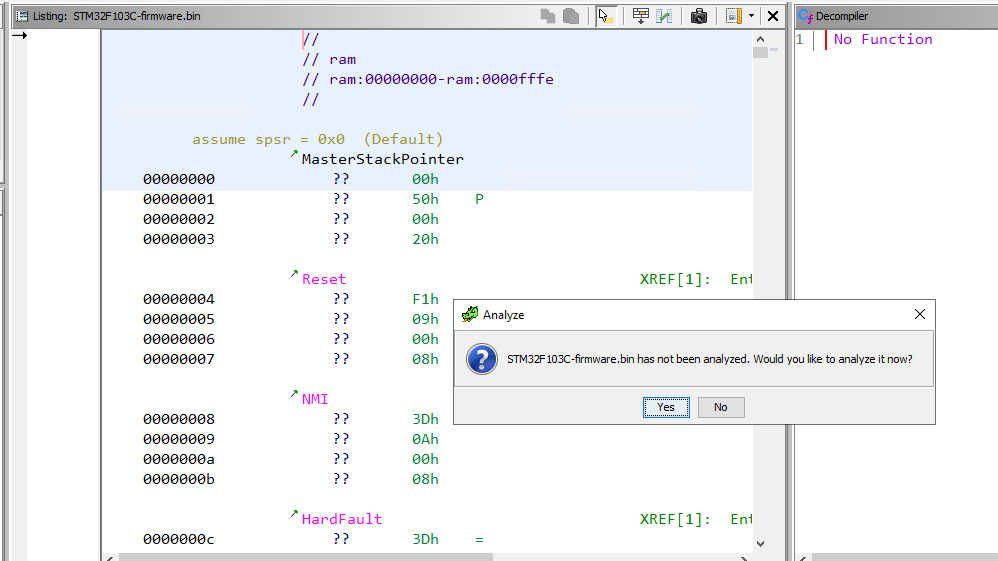
Ghidra 分析提示
Ghidra 将提示分析文件,我们点击"是",保留默认分析选项。分析完成后,我们来看看反汇编的代码。
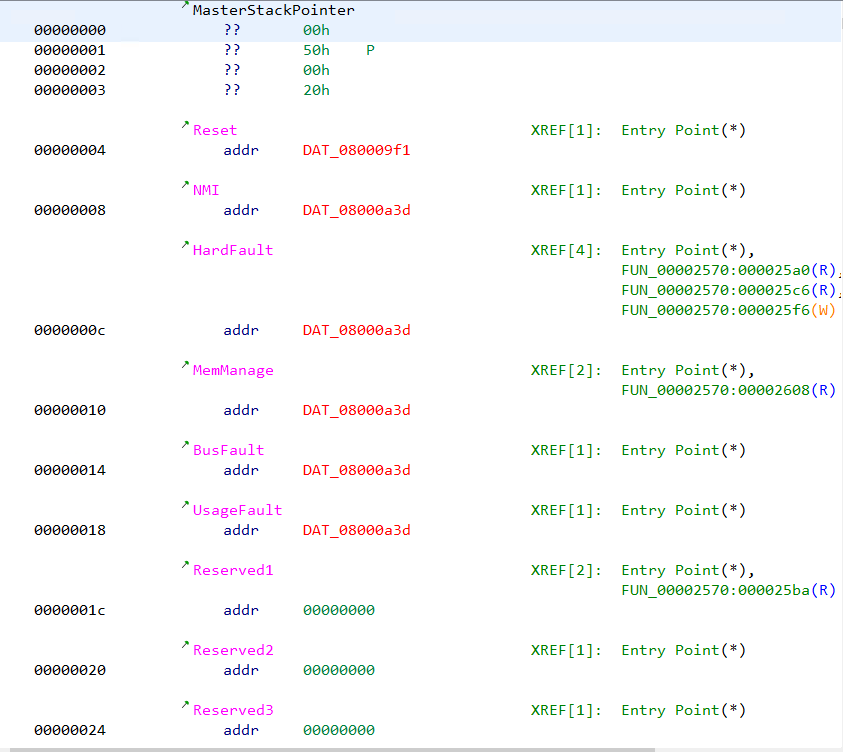
Ghidra 中未解析的地址以红色标记
我们注意到,有几个地址用红色文本标记。这些地址的形式为08000XXX。当文件中不存在指定的地址时,Ghidra 会将其标记为红色。双击该地址不会有任何结果。
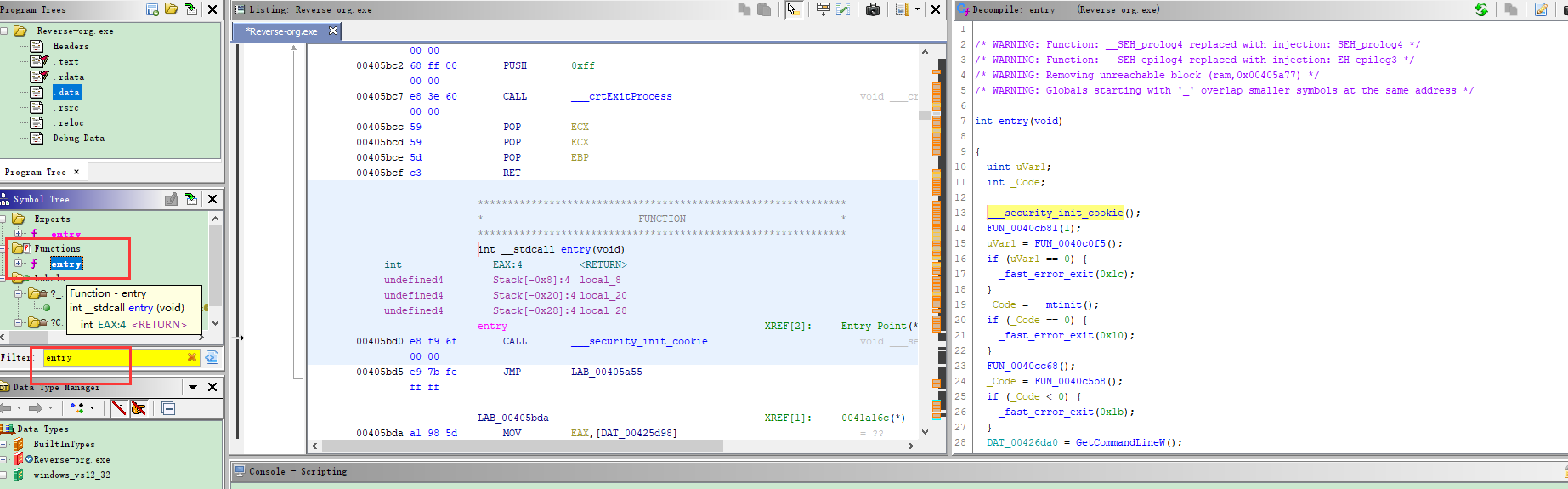
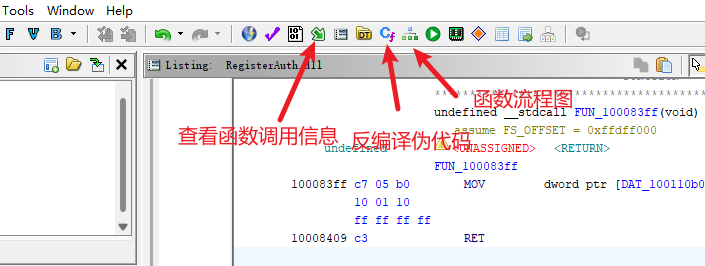
FUN_000003e4类似地,让我们通过在符号树上单击任何函数(比如)来分析它的反汇编列表。
怎么找到函数
我们可以找到左边的functions,找到entry(当然有些程序直接有main,或者_start等关键字)
通过Filter搜索可以更快一点,双击即可再右边看到entry代码