本系列主要旨在帮助初学者学习和巩固Linux系统。也是笔者自己学习Linux的心得体会。

个人主页: 爱装代码的小瓶子
文章系列: Linux
2. C++
文章目录
- 1.前言:
- [2. 什么是进程池:](#2. 什么是进程池:)
-
- [2-1 它不只是"管道",核心区别在于](#2-1 它不只是"管道",核心区别在于)
- [2-2 进程池的核心作用](#2-2 进程池的核心作用)
-
- [1. **降低进程创建开销**](#1. 降低进程创建开销)
- [2. **控制并发数量**](#2. 控制并发数量)
- [3. **简化编程模型**](#3. 简化编程模型)
- [4. **负载均衡**](#4. 负载均衡)
- 3.实战:开始手敲一个简答的进程池:
-
- [3-1 第一大板块:start函数-创建一个进程池](#3-1 第一大板块:start函数-创建一个进程池)
- [3-2 第二大板块:run函数-运行进程池](#3-2 第二大板块:run函数-运行进程池)
-
- [1. 先来看`_tm.code()`](#1. 先来看
_tm.code()) - [2. 再来看 `_cm.select()`](#2. 再来看
_cm.select()) - [3. 最后来看 `ch.send(taskcode)`](#3. 最后来看
ch.send(taskcode))
- [1. 先来看`_tm.code()`](#1. 先来看
- [3-3 第三大板块:stop函数-最后的结束](#3-3 第三大板块:stop函数-最后的结束)
- 总结:
-
- 核心知识点
-
- [1. 进程池 vs 普通多进程](#1. 进程池 vs 普通多进程)
- [2. 四大核心类(封装层次)](#2. 四大核心类(封装层次))
- [3. 三大核心流程](#3. 三大核心流程)
1.前言:
我们在前一篇文章# 【C++与Linux基础】进程间通讯方式:匿名管道我们已经讲述了什么是管道。我们还是把他当作文件来看待。
先准备一个大小为2的数组 pipefd,我们先利用 pipe 函数创建管道,其中pipefd[0]拿到3号下标,pipefd[1]拿到了4号下标。随后利用fork()子进程来完成复制,这样我们就构成了下面的图片:
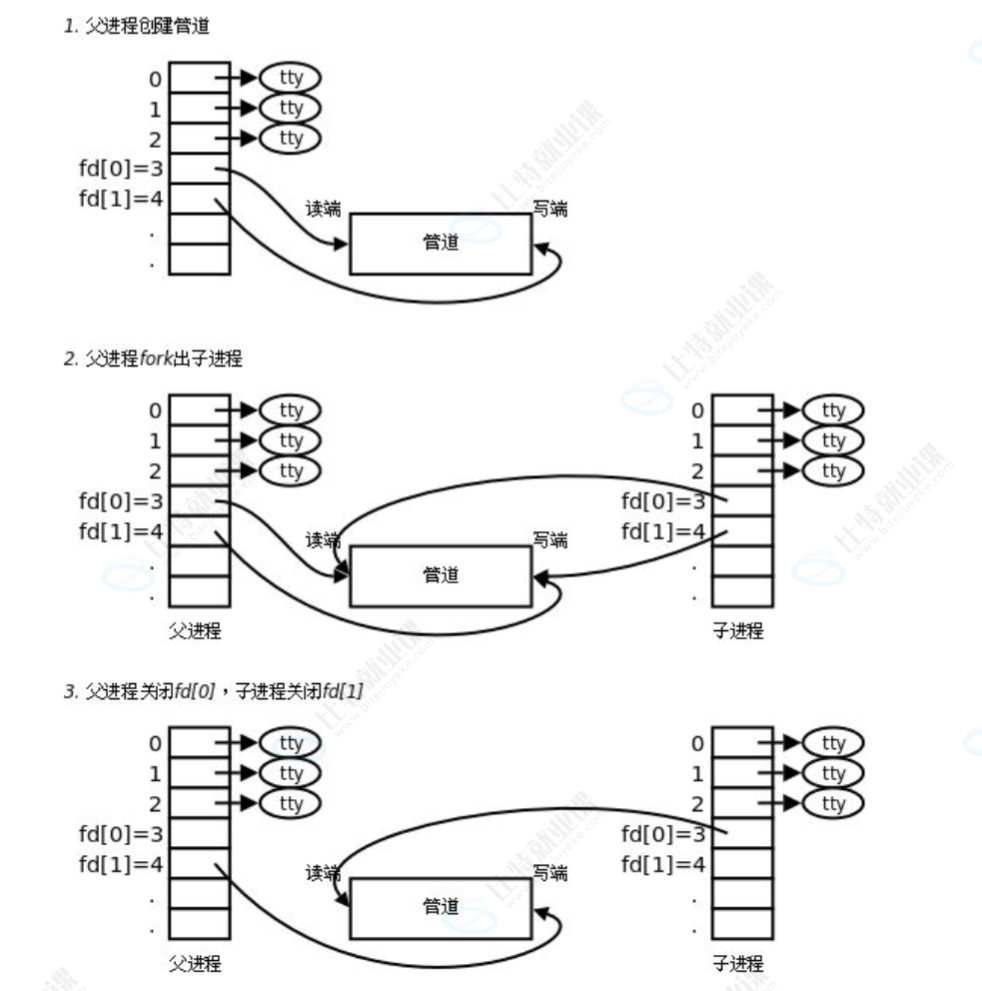
后面谁要写,就保留那个进程的 pipefd[1],关闭另一个。这样就构成了一个基础的管道。4
接着,我们就继续深入了管道5种特性:
- 匿名管道,只能用来进行具有血缘关系的进程进行进程间通信(常用与父子)
- 管道文件,自带同步机制
- 管道是面向字节流的管道是单向通信的
- 属于半双工的一种特殊情况
- (管道)文件的生命周期,是随进程的
总结了四种情况 :
- 写慢,读快:结果 :读端阻塞(等待)
- 写快,读慢:结果 :写端阻塞(等待)
- 写端关闭,读端继续:结果 :读端
read()返回 0(EOF,文件结束) - 读端关闭,写段继续:结果 :OS发送 SIGPIPE 信号(13号信号),终止写端进程
这个就是我们上一个文章最后的总结,今天我们继续来聊聊进程池:
2. 什么是进程池:
进程池(Process Pool) 是一种进程管理技术,它预先创建并维护一组可用的工作进程,而不是每次需要处理任务时才临时创建新进程。
什么是"池",这个我们很常见的,到底有什么魅力:
这个命名很形象:
- 就像线程池 、连接池 、内存池 一样,"池"表示一个可复用的资源集合
- 进程是昂贵的系统资源,创建和销毁进程开销很大(需要分配内存、初始化资源、建立进程控制块等)
- 进程池把这些进程"养"在那里,有任务就分配,没任务就等待,用完归还,循环复用
在这里我们时常把进程池理解成有多个管道构成,但其实实则不然:
2-1 它不只是"管道",核心区别在于
| 简单管道/多进程 | 进程池 |
|---|---|
| 来一个任务创建一个进程 | 预先创建固定数量的进程 |
| 任务完成进程就销毁 | 进程持续存活,等待下一个任务 |
| 进程数量随任务波动 | 进程数量可控,不会压垮系统 |
| 需要自己管理进程生命周期 | 自动调度、负载均衡、异常处理 |
2-2 进程池的核心作用
1. 降低进程创建开销
创建进程是重量级操作。进程池通过复用,把创建开销均摊到多个任务上。
2. 控制并发数量
防止同时运行几百个进程把系统拖垮。比如设置池大小为4,即使有100个任务,也最多只有4个进程在运行。
3. 简化编程模型
你只需提交任务,不用关心:
- 进程怎么创建
- 任务分配给哪个进程
- 进程崩溃怎么处理
- 结果怎么收集回来
4. 负载均衡
内置调度机制自动把任务分给空闲进程,避免有的进程忙死、有的进程闲死。
3.实战:开始手敲一个简答的进程池:
我们遵循Linux的设计哲学:先描述再组织,我们先来看看我们需要什么?多个管道,一个管道为了分辨,我们需要他的名字和编号。我们最好来好好的描述它。他应该提供哪些基础的接口:
- 应该提供它的名字,我们需要知道它的编号和名字,便于控制。
- 应该提供关闭和等待的函数,这里我们需要来控制这个管道的关闭和父进程的等待.
- 还需要一个发送任务码的函数,用来为上层提供这个接口
随后我们利用数组来组织他们,这一场的结构体,我们称为channermanager任务管理者,这里我们需要好好的照顾每一个管道。究竟选择哪一个管道来完成这次任务。协调每一个管道的关闭和等待。
我们还需要为上层的进程池提供一个任务,这里就会有,任务本身和任务管理者。任务管理者要提供选择哪一个任务。执行的具体的接口
这里我可能写的不清楚,但是我们再看看我们最上面的一个接口体(最后的封装),我们需要创建进程池,运行它,结束它。虽然这里对外暴露了这三个比较简单的函数,但是内部细节还是需要很小心的考虑的。
接下来,我们深入代码,来看看是怎么设计的:
cpp
static int nums = 5;
class ProcessPool
{
public:
ProcessPool()
: _processNum(nums)
{
// 初始化任务管理器:
_tm.Register(Upload);
_tm.Register(Download);
_tm.Register(Printlog);
}
~ProcessPool()
{
}
private:
// 一个进程池里面需要管理的:
ChannelManager _cm;
TaskManager _tm;
int _processNum;
};这里我们可以看到一个进程池里面所需要的:
_processNum创建几个管道的,我们这里默认是5个。ChannelManager _cm管道管理者,用来协调每一个管道的TaskManager _tm任务管理者,同上。
那么整个进程池就是有四个结构体来组成的:
class ProcessPoolclass ChannelManagerclass TaskManagerclass channer
为了逻辑的严密性,我们还是主要class ProcessPool的函数接口顺序创建进程池,运行它,结束它来讲解。我们来完成三个大板块:
3-1 第一大板块:start函数-创建一个进程池
我们不要考虑怎么创建一群管道,我们需要的是先创建一个具体的管道,这一套我们很熟悉:
cpp
// 1. 这里开始创建管道,先考虑创建一个管道:
int pipefd[2] = {0}; // 全部初始化为0
int ret = pipe(pipefd);
if (ret < 0)
{
std::cerr << "pipe fail" << std::endl;
exit(1);
}
// 2. 成功之后开始 创建子进程,这样就形成了管道:
pid_t subId = fork();
if (subId == 0)
{
close(pipefd[1]);
// 子进程:子进程来读取,不是写
Work(pipefd[0]);
close(pipefd[0]);
//一定要直接退出,不然会出现子进程在创建子进程。
_exit(0);
}
else if (subId > 0)
{
// 父进程:这里只是创建一个进程池:
close(pipefd[0]);
_cm.Insert(subId, pipefd[1]); // 父进程知道子进程的pid,直接传入
// 由于管道的同步性,父进程没有写入,子进程会阻塞等待
}
else
{
std::cerr << "fork fail" << std::endl;
return false;
}在子进程里面,我们值得关注的就是Work(pipefd[0]);,这个函数我们还没有实现。这个函数是子进程工作的函数。我们父进程传入了命令,子进程就需要读取,并执行它。我们必须要读取4个字节才开始工作,因此还需要continue来协调。当n == 0我们也需要结束这个循环。(情况3- 写端关闭,读端继续:结果 :读端 read() 返回 0(EOF,文件结束))
cpp
void Work(int wfd)
{
// 子进程的工作,子进程只进行读取
int code = 0;
while (true)
{
int n = read(wfd, &code, sizeof(code));
if (n > 0)
{
if (n != sizeof(code))
continue;
std ::cout << "子进程pid" << getpid() << "接受了["
<< code << "]指令" << std::endl;
_tm.Execute(code);
}
else if (n == 0)
{
std::cout << "父进程已经关闭,子进程也需要关闭" << std::endl;
break;
}
else
{
std::cerr << "子进程word fail" << std::endl;
exit(2);
}
}
}在父进程里面值得关注的就是 _cm.Insert(subId, pipefd[1])这个函数,我们其实按字面理解就可以知道,是用来为结构体 class ChannelManager初始化的函数。
cpp
void Insert(pid_t subId, int wfd)
{
_channers.emplace_back(subId, wfd);
}这里我们就完成了进程池的初始化。满足了,子进程已经在工作区等待父进程来发布命令,父进程也初始化了管道的管理者。一切准备就绪,接下来就是等待运行了。
3-2 第二大板块:run函数-运行进程池
运行函数可以这么讲,就是为父进程准备的,父进程来发号施令的令牌:
cpp
void run()
{
// 刚刚只是让进程池创建起来
// 1. 开始选择任务和管道
int taskcode = _tm.code(); // 通过任务管理器来分配任务
auto &ch = _cm.select(); // 通过管道管理来轮询选择管道
std::cout << "选择了一个子进程: " << ch.name() << std::endl;
// 2. 有了管道 发送任务
std::cout << "发送了一个任务码: " << taskcode << std::endl;
ch.send(taskcode);
}看似简单,这里涉及了好多的下一层的细节:
1. 先来看_tm.code()
为了下面的逻辑更加舒畅,在这里,我们要把 class TaskManager全部讲完!
首先,我们要知道什么是函数指针(函数指针是指向函数的指针 ,存储的是函数的入口地址。),什么是 Callback(回调函数 是通过函数指针传递的函数 ,由调用方在某个时机"回过头来调用" 。核心模式:A 把函数传给 B,B 在合适的时机调用这个函数)。
我们先给出三个具体的任务:
cpp
using Callback = std::function<void()>;
void Upload()
{
std::cout << "这是一个上传的任务 " << std::endl;
}
void Download()
{
std::cout << "这是一个下载的任务 " << std::endl;
}
void Printlog()
{
std::cout << "这是一个打印日志的任务" << std::endl;
}随后利用Callback来完成调用。 void Register(Callback cb)这个在一开始就给了是怎么初始化的。
int code()给出随机数,用来随机选择任务。void Execute(int code)执行任务的函数,要注意下标的问题。
cpp
class TaskManager
{
public:
TaskManager()
{
// 种下一颗随机数种子
srand(time(nullptr));
}
void Register(Callback cb)
{
// 注入任务
_tasks.emplace_back(cb);
}
int code()
{
if (_tasks.empty())
return -1;
// 随机提供任务的下标,为了防止溢出,还需要求余
return rand() % _tasks.size();
}
void Execute(int code)
{
if (code < _tasks.size() && code >= 0)
{
// 防止 code的范围 出现错误。
// 这里数组下标进行填充,进行调用
_tasks[code]();
}
else
{
std::cout << "下标错误" << std::endl;
}
}
~TaskManager()
{
}
private:
std::vector<Callback> _tasks;
};2. 再来看 _cm.select()
我们在注释里也已经讲过了,这是轮询来挑选哪一个管道的,这个函数是由管道管理者来完成的。
cpp
channer &select()
{
// 采用轮询的方式来选择一个管道:
auto &channer = _channers[_next];
_next++;
_next %= _channers.size();
return channer;
}我们需要为它提供一个next的下标,下次自动选择下一个。同时为了防止他溢出,我们还要余上数组的大小。
3. 最后来看 ch.send(taskcode)
我们通过select()这个函数得到了一个具体的管道,这是我们就需要利用这个管道来发送任务码。这个函数是管道本身提供的。所以这个函数是在结构体:class channer
cpp
void send(int taskcode)
{
//往指定的文件描述符里面写入
int n = write(_wfd, &taskcode, sizeof(taskcode));
(void)n;
}其实可以看到,拆开来还是很简单的。主要是逻辑还是难以连接起来的。
3-3 第三大板块:stop函数-最后的结束
我们完成了任务,我们就需要结束这个任务
cpp
void stop()
{
_cm.CloseProcess();
_cm.Wait();
}同理,这里还是留给_cm去完成这个任务。
cpp
void CloseProcess()
{
for (auto &channer : _channers)
{
channer.Close();
std::cout << "关闭" << channer.name() << std::endl;
}
}下面就是等待函数,这个管理就是管理怎么去停止。
cpp
void Wait()
{
for (auto &channer : _channers)
{
channer.wait();
}
}同样还是最底层提供了两个关闭和等待
cpp
void wait()
{
int n = waitpid(_subId, nullptr, 0);
(void)n;
}
void Close()
{
close(_wfd);
}总结:
一句话总结 :进程池的本质是用空间换时间------预创建进程、持久化管道、循环复用,将进程创建的开销均摊到多个任务上,实现高并发场景下的稳定服务。
核心知识点
1. 进程池 vs 普通多进程
| 对比项 | 普通多进程 | 进程池 |
|---|---|---|
| 创建时机 | 来任务才fork | 预创建,复用进程 |
| 进程数量 | 随任务波动 | 固定可控 |
| 通信方式 | 临时建立管道 | 持久化管道/IPC |
| 管理成本 | 手动管理生命周期 | 自动调度、负载均衡 |
2. 四大核心类(封装层次)
ProcessPool(进程池) ← 对外暴露 start/run/stop
├── ChannelManager _cm(管道管理者)← 轮询选择、关闭等待
│ └── vector<channer>(具体管道)
├── TaskManager _tm(任务管理者)← 注册任务、随机分发
│ └── vector<Callback>(函数指针数组)
└── int _processNum(进程数量)3. 三大核心流程
| 流程 | 关键函数 | 说明 |
|---|---|---|
| 初始化(start) | pipe() → fork() → _cm.Insert() |
创建管道、fork子进程、注册到管理器 |
| 运行(run) | _tm.code() → _cm.select() → ch.send() |
随机选任务 → 轮询选管道 → 发送任务码 |
| 结束(stop) | _cm.CloseProcess() → _cm.Wait() |
关闭写端 → waitpid等待子进程回收 |
感谢各位对本篇文章的支持。谢谢各位点个三连吧!

