在配置好yolo虚拟环境的相关依赖之后(主要就是torch及其扩展库),接着就来到yolo的核心库ultralytics库安装了。
Ultralytics库
ultralytics库是YOLO的官方核心库,封装了YOLO的所有功能(训练、推理、部署)
ultralytics官网,有梯子会快很多,https://www.ultralytics.com/
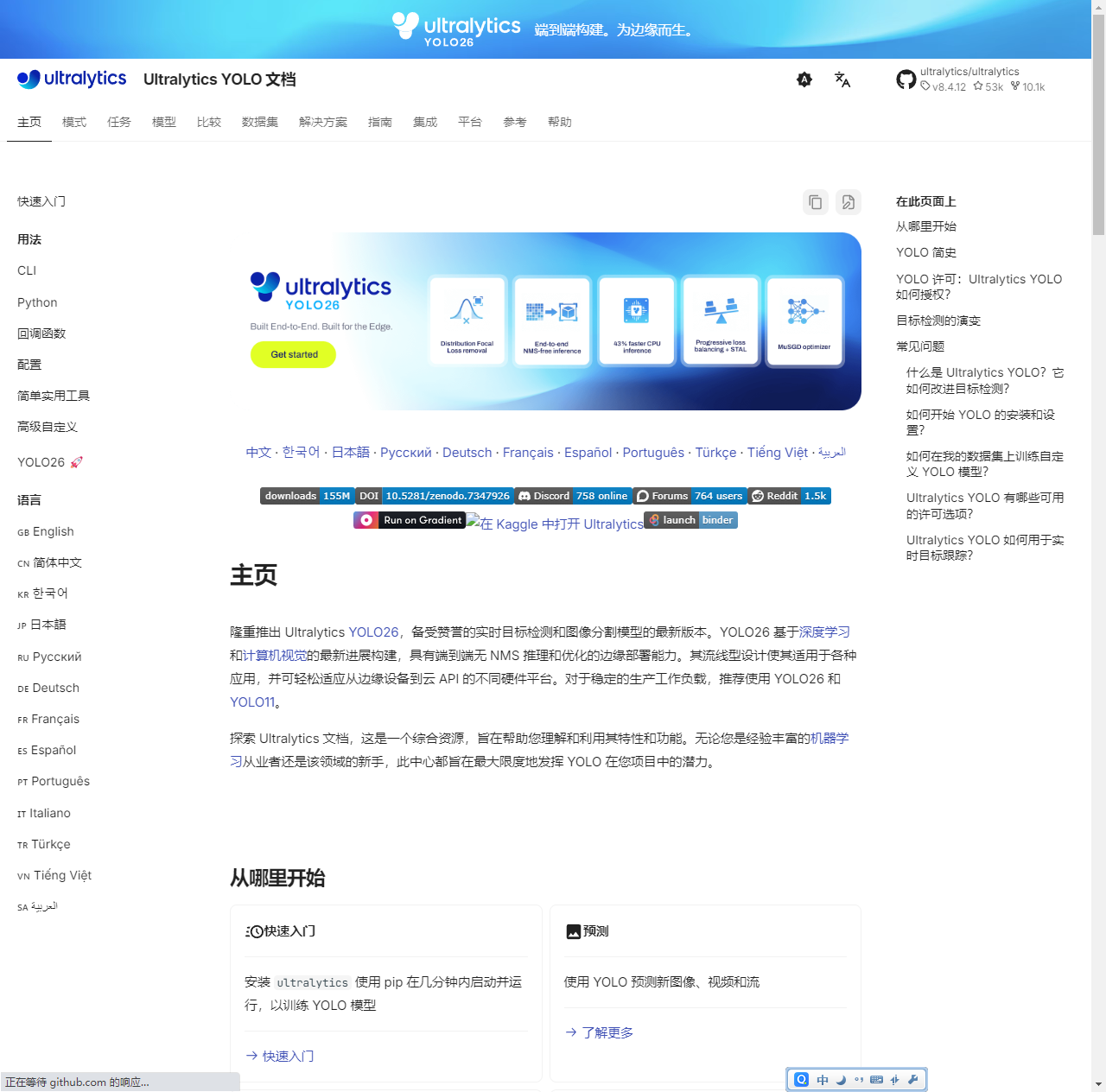
我们有很多关于yolo的使用都可以通过官方文档获取。
安装Ultralytics库
关于怎么安装Ultralytics库,我有两次经验,一次是跟着教程中从Ultralytics库的GitHub仓库上,下载某个版本的源代码.zip,
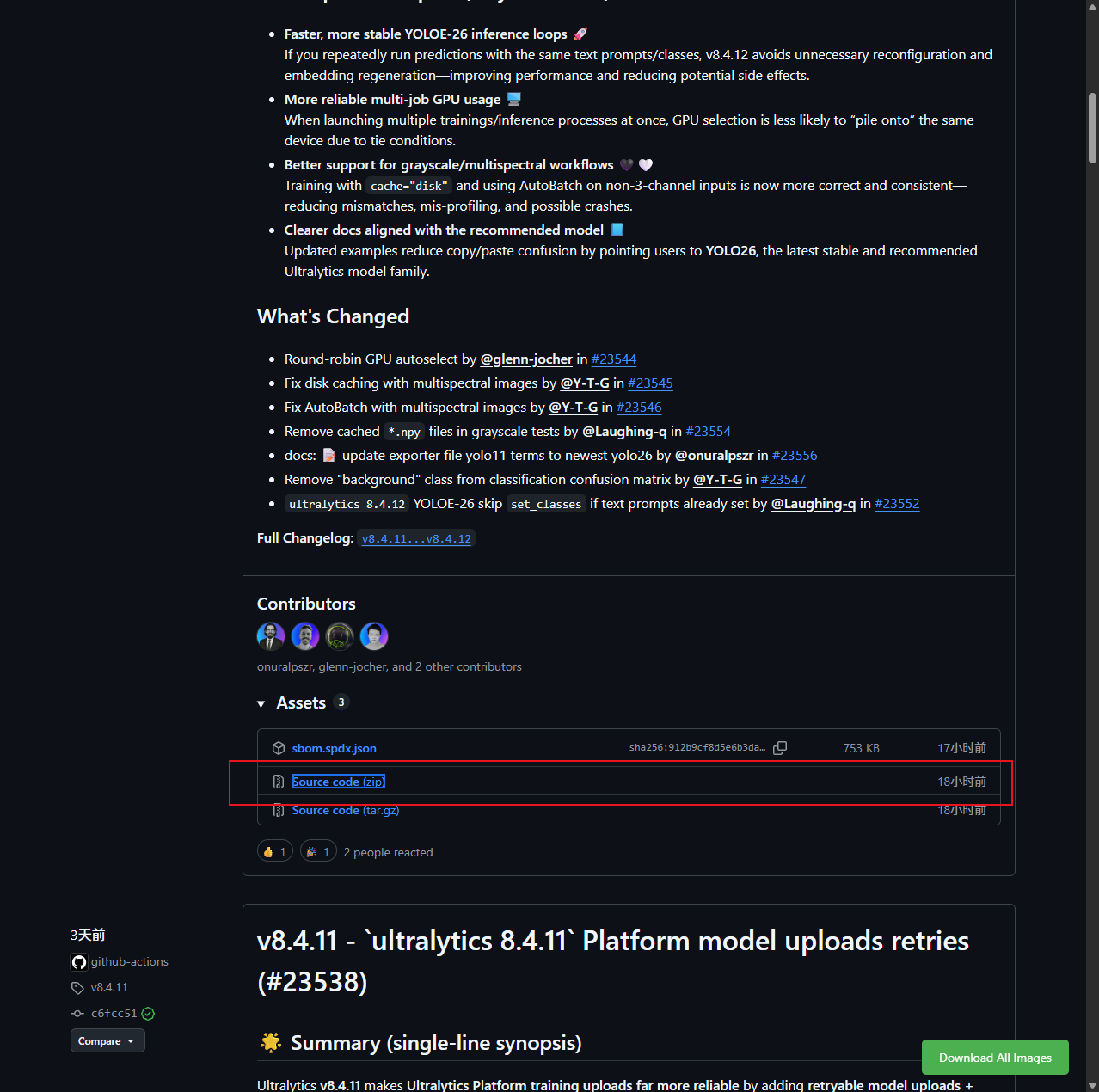 然后通过Xftp把该压缩包上传到Linux主机,
然后通过Xftp把该压缩包上传到Linux主机,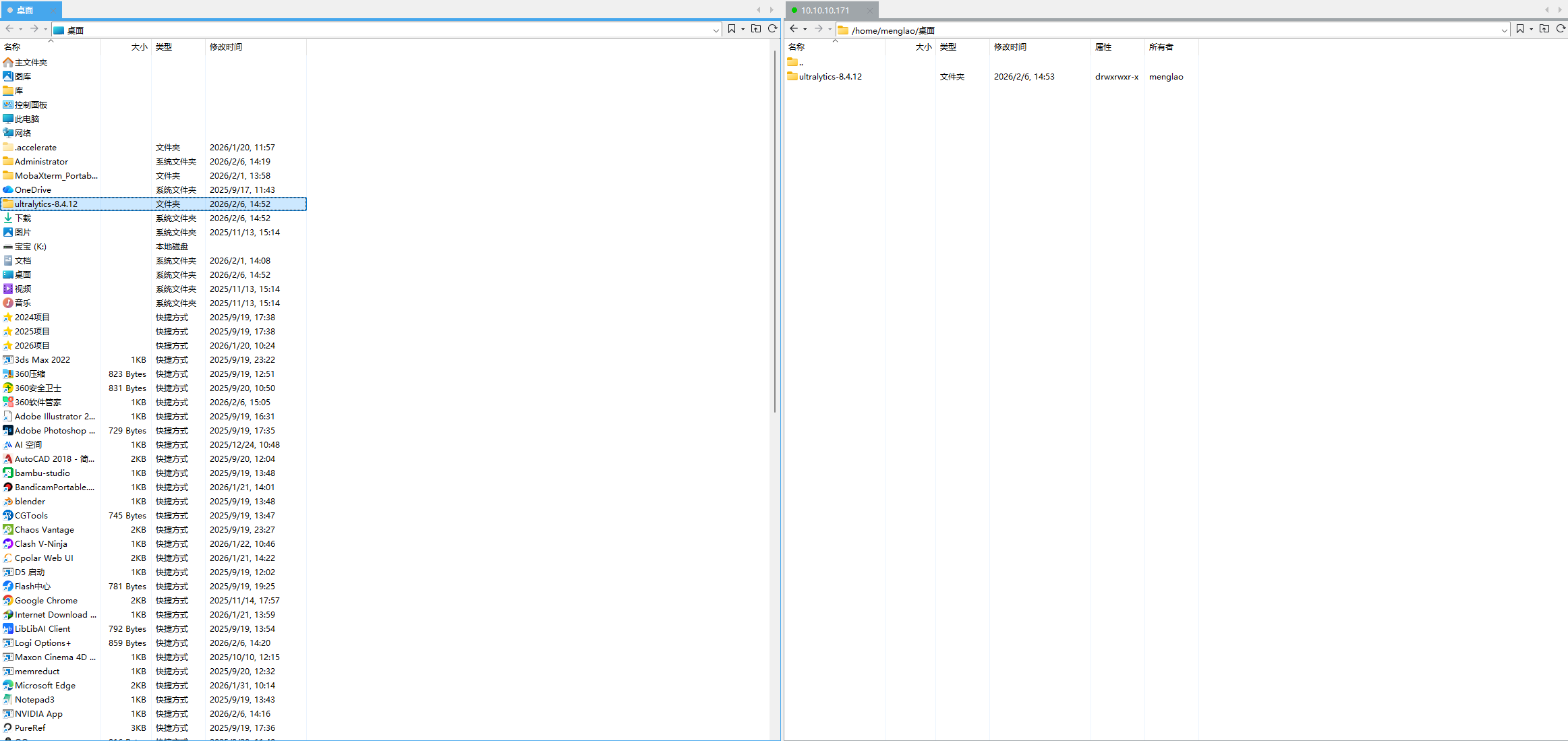 解压后通过:
解压后通过:
pip install -e .来安装
这样的安装方法,会使得安装完的Ultralytics库在pip list里面产生一个路径,这种安装方法有一个很大的坏处,特别是对新手而言,因为这个解压在桌面的ultralytics-8.4.12库文件,一旦后续有被修改或者误删的话,这个pip list中的Ultralytics库就会失效的了,所以我们来说第二种方法。

第二种安装方式更加适合新手使用,也就是很简单的指令,就是:
pip install ultralytics==8.4.12,这样既指定了最新版本(或者说是指定版本,其实这里不指定也是可以的,只是为了对比了GitHub上直接下载源代码而已),又可以直接安装在pip文件夹里,同一管理,这样就减少了误删Ultralytics库文件夹导致Ultralytics失效的情况。

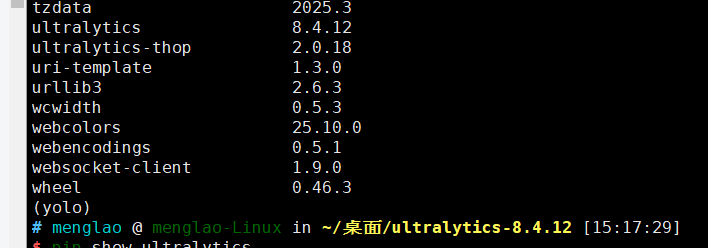
通过pip install ultralytics来安装可以明显看到,Ultralytics库被安装后不会再显示路径。
YOLO功能(task)
YOLO主要功能或者说能够完成的任务主要有,Detection(Object Detection对象检测)、Segmentation(实例分割)、Classification(图像分类)、Pose Estimation(姿态估计)、OCR(Optical Character Recognition,光学字符识别)、Tracking(目标跟踪)。

Object Detection(对象检测)
核心作用:识别图像 / 视频中多个目标的类别 + 位置(用矩形框标注)。

Segmentation(实例分割)
核心作用:在目标检测的基础上,额外输出目标的像素级轮廓(不仅知道 "有什么、在哪",还知道 "目标的形状")。
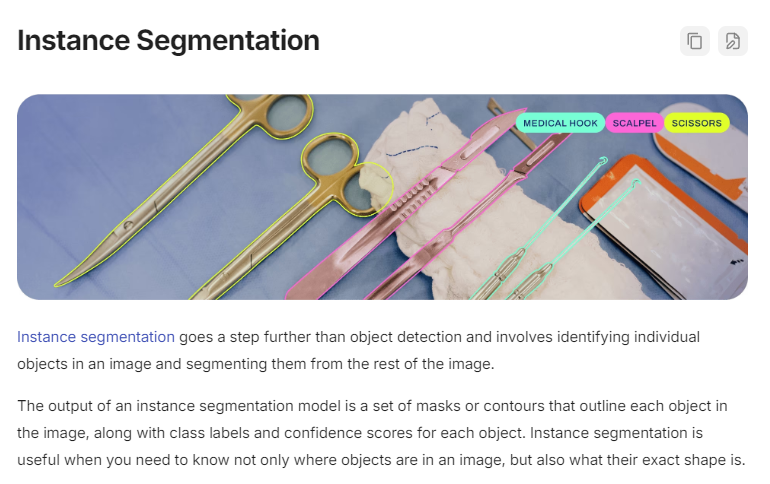
Classification(图像分类)
核心作用:判断整张图像的类别(不输出位置,只给 "这张图是什么" 的结果)。
Pose Estimation(姿态估计)
核心作用:识别图像中人体 / 动物的关键点(比如人的关节、动物的肢体),并标注位置。

OCR(Optical Character Recognition,光学字符识别)
核心作用:识别图像中的文字内容(包含文字的位置 + 文本内容)。
Tracking(目标跟踪)
核心作用:在视频序列中,对目标进行持续跟踪(给同一目标分配唯一 ID,避免重复计数)。

YOLO模式(mode)
核心常用模式有6 种 ,其中Predict (推理)、Train (训练)、Val (验证)、Export (导出) 是四大基础核心模式,Track (跟踪)、Benchmark (基准测试) 是针对视频 / 部署的拓展模式,所有模式都能和之前讲的 6 大视觉任务结合使用。
Predict (推理) - 最常用
其中Predict (推理) 最常用的,它的核心作用是用预训练模型 对图片 / 视频 / 摄像头 / 网络链接做视觉任务预测,直接输出结果(标注后的图片 / 视频、目标坐标 / 类别等),是新手最先接触的模式。
Train(训练)- 核心自定义开发功能
Train(训练)核心作用是 用自定义数据集 训练 / 微调 YOLO 模型,让模型适配你的专属场景(比如训练 "检测口罩""识别自定义零件" 的模型),支持基于预训练模型的迁移学习(新手推荐,训练快、效果好)。
Val / Validate(验证 / 评估)- 训练后必用
Val / Validate(验证 / 评估)核心作用 是用验证集 / 测试集评估训练好的模型(或预训练模型)的性能,输出专业评估指标,判断模型 "好不好用"。
Export(导出)- 部署必用
将训练好的 YOLO 模型(.pt 格式)转换为跨平台 / 高性能的部署格式,适配不同硬件(电脑 / 嵌入式 / 手机 / 显卡)和框架(OpenCV/TensorRT/ONNX Runtime),是模型从 "训练" 到 "实际应用" 的关键步骤。
Track(目标跟踪)- 视频/摄像头专用
在视频 / 摄像头流 中,对检测到的目标进行持续跟踪 ,给每个目标分配唯一 ID,避免同一目标被重复计数 / 识别,是检测模式的视频拓展版。
Benchmark(基准测试)- 优化必用
测试 YOLO 模型(原生.pt 或导出的格式)在当前硬件 上的推理速度 (FPS:每秒处理帧数)、延迟,对比不同格式 / 不同模型的性能,为部署优化提供依据。
YOLO模型架构(算法版本)&权重文件(.pt)
对于YOLO而言,我们经常可以看到什么YOLOV3、YOLOV5、YOLOV8、YOLO11甚至YOLO26,感觉总是搞不清楚,这些东西各自是什么,其实简单来说,这些都是YOLO的模型架构也就是算法的不同版本,而针对每一个架构或者版本,都各自有其不同的权重文件.pt文件。
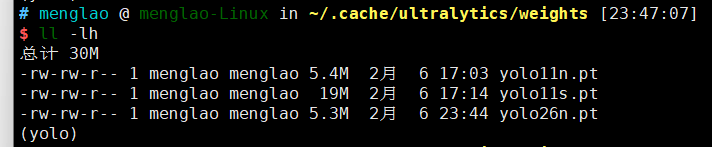
架构跟权重文件的关系就像是不同年代的iPhone,如iPhone13、iPhone15等(架构/算法),它们每一代都有自己的配置256g、512g、1T(权重文件.pt)。所以我们可以得知同一个手机型号(架构/算法)可以有很多种不同 的配置(权重文件.pt)。而一般来说这些权重文件会保存在/.cache/ultralytics/weights目录下,如图:

对于yolo而言不同的架构及不同的权重系数都是从yolo11n.pt这个文件名来定义的,例如yolo11n.pt就是说明它是yolo11版本的网络架构,然后权重是n。不同版本架构不同权重系数的.pt文件都是储存在weights目录下即可,无需在目录下新建v8、v11、v26这样的目录来单独存放不同版本架构的权重.pt文件,这样反而ultralytics库无法识别。
决定使用什么版本架构什么权重系数.pt文件的从来都不是在weights中的文件怎么分类,而是当例如执行predict(推理)模式时,输入了怎么样的指令,假设现在weights里有yolo11n.pt和yolo26n.pt两个不同版本不同权重的.py文件,决定使用什么样的权重文件。
yolo predict model=yolo11n.pt source=test.jpg
yolo predict model=yolo26n.pt source=test.jpg
决定使用什么权重文件的,从来只有其文件名。
正常来说如果需要调用yolo,CLI的执行指令是:
yolo task=detect mode=predict model=yolo11n.pt source=test.jpg
但是其实yolo有其双层简化,可以把指令简化为只输入predict(作为yolo指令后的第一个参数)
yolo predict model=yolo11n.pt source=test.jpg缩小了输入的繁琐。
其实yolo的CLI指令格式应该是:
yolo task=xxx(第一个参数) mode=xxx(第二个参数) model=xxx(第三个参数) source=t/home/menglao/Desktop/test.jpg
然后task(任务、功能)对应的就是上面提到过的detect、segment等等;
mode(模式)对应的就是上面提到过的predict、train、val、export等等;
而model(权重系数文件)对应的就是上面提到过的权重系数文件n、s、m、l、xl;
然后source=就是代表需要检测对象的路径,假设这个test.jpg是位于/home/menglao/Desktop就应该输入完整路径/home/menglao/Desktop/test.jpg。
yolo初体验
这里以目标检测road1.png为例:
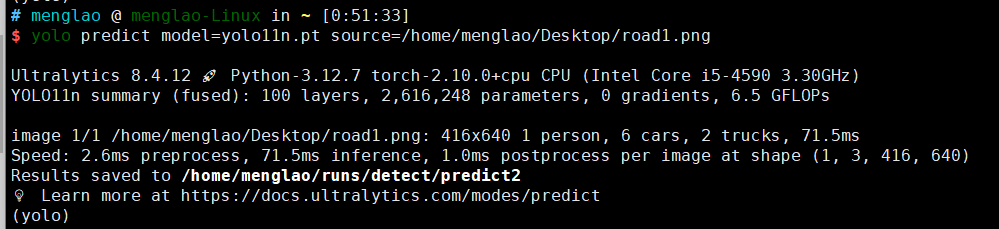
通过yolo的CLI指令,设定mode为predict model为yolo11n.pt source位置是/home/menglao/Desktop/roda1.png,可以看到这里会有个提示Results saved,
此时在/home/menglao/目录下会多了一个runs,而在/runs/detect/predict2目录下有一张图片road1.jpg,可以对比下和source的road1.png的区别:

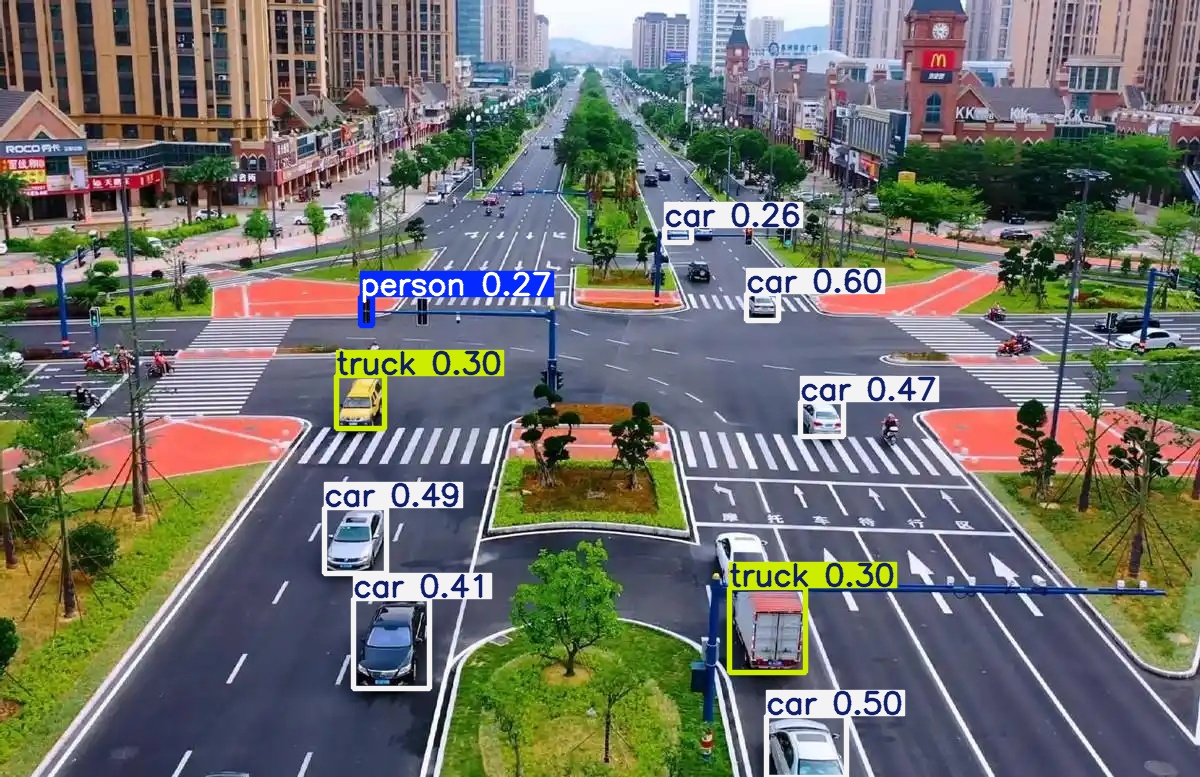
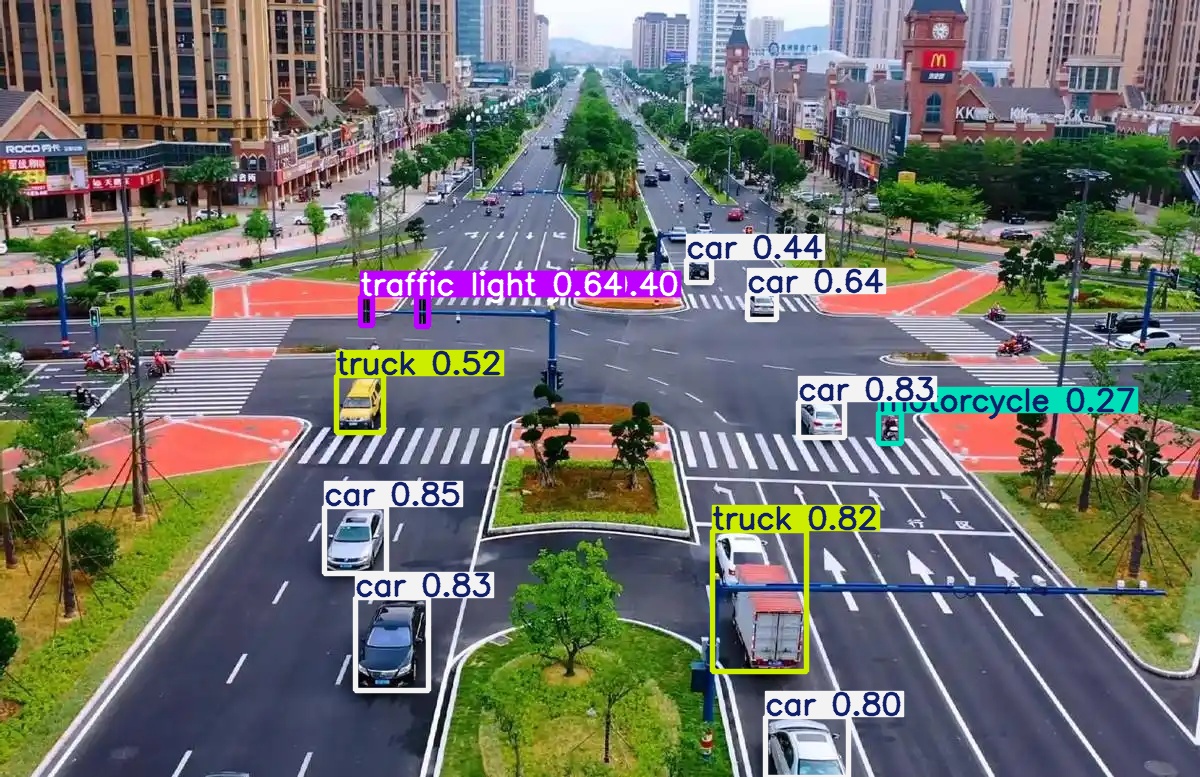
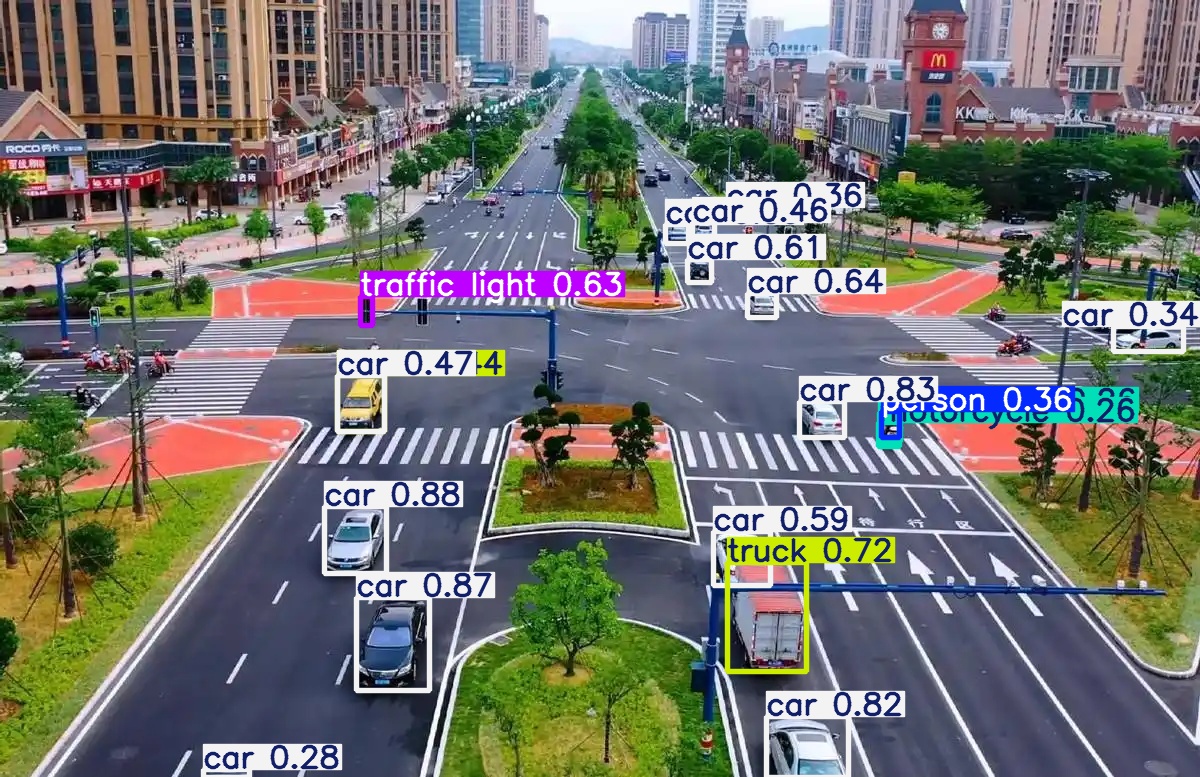
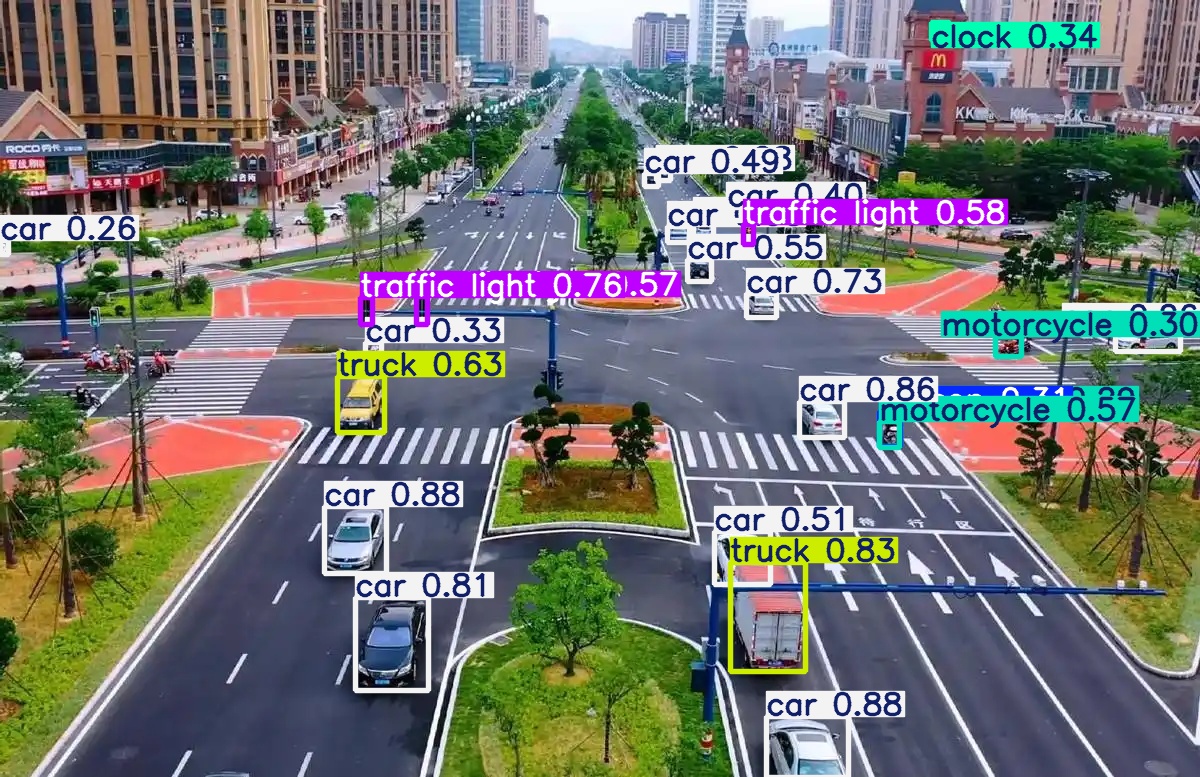
可以通过对比看得出不同架构版本,不同权重系数下predict出的结果还是有很明显的区别的。
同样是yolo11,n、m、x三个不同大小权重系数的模型,输出的图片识别内容差异很大;
同样是权重为x的不同架构版本yolo11和yolo26在同样检测同一张图的时候,识别出来的内容也有很大的区别。
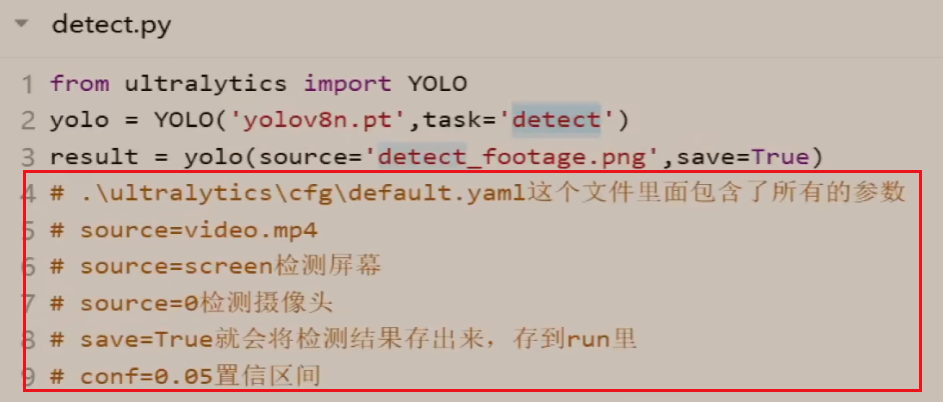
当然了,除了使用CLI来执行yolo,也可以通过python代码编写来通过python predict.py来解析这个程序的,如下(可以对比下跟CLI命令行的区别,其实我觉得没什么区别,除了不能省略task之外,其实也是需要指定source、model)


这里可以看看案例中的代码,主要重点关注后面多行注释!!!关于source的不同源的使用。