1.hive常见问题,数据倾斜是什么?
数据倾斜指的是,数据分布不均匀,有两种情况Map不均匀和Reduce不均匀。如何发现的?打开hive-ui,可以发现某一个Map任务耗时远超其他的Map任务,此时没有特别好的手段,若是hiveSql,可以group by 这个key,看一下是哪个,对他进行业务上的拆分。Reduce的发现是卡在99%,其他的reduce都完成了,看一下Task处理数量,可以开启group by聚合,map端预聚合是默认开启的,看一下reduce日志,oom,还是节点挂了,观察他的sql,看看是聚合场景,还是join场景。group.skewindata,skewjoin。或者增大map端输出。主要的优化,建临时表(避免重复计算),索引,小表join大表(mapjoin)。
2.hive常在什么情况使用?他适合存储什么?
做离线数仓使用。离线数据、结构化和半结构化的数据。
3.hive的数据格式常用哪几种?适合啥业务?
orc、parquet解压速度快(snappy算法),压缩率中等,50%压缩率左右
gzip压缩(gzip算法)率高,解压速度慢
一般只hive用orc,spark/flink用parquet更好一些,其实两者差不太大
4.hive生成任务的原理是什么?
sql->ast(语法数,每个节点是一个函数)->生成执行计划->提交给资源调度其执行
资源调度
mr(架构简单,兼容性好)中间数据落磁盘,tez比mr快3~5资源复用,spark比mr快10中间数据落内存
可以指定引擎,比如mapreduce
map的task个数是根据block的数量决定的,如果block里面实际的数据有大有小,不均匀,就容易i造成数据倾斜,之后会进行shuffle,对相同key进行聚合,然后交给reduce进行整体计算,调整task.size也本质是调整block的切分数,其实还是按这个来的
5.根据这些原理,我们应该怎么优化?
(1)用临时表,减少多次聚合
(2)小表join大表,提高速度,示例/**mapjoin**/
(3)加索引
(4)加分区
(5)对key进行特殊处理,比如hash取值,最后再恢复,避免大key
6.hive的架构是什么?
hive 只是sql解析引擎,本身不做计算。设置执行引擎(set hive.execution.engine=spark)
hive主要由两部分组成,metastore和query engine,metastore是负责管理元数据一般与mysql元数据库做交互,query engine是执行引擎,是将hql转换为mapreduce或者spark的东西。他本身不参与计算而是依赖hadoop进行计算。
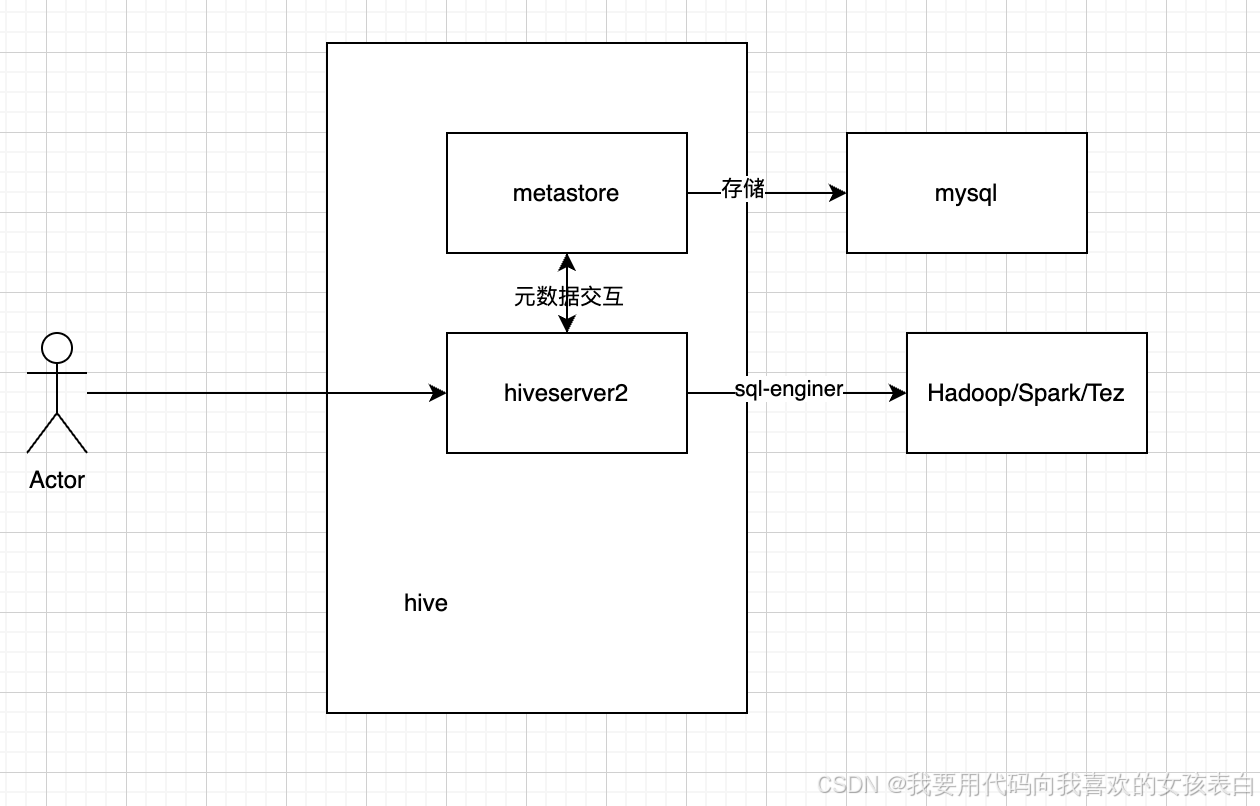
通过jps,可以看到hiverserver2和metastore服务。hiveserver2相当于服务端,通过beeline或jdbc或hive cli可以直接连接他执行相关hql,hiveserver2会与sql engine交互,从而进行计算。
7.yarn资源调度
hadoop2后有了yarn资源调度,他有哪些主要组件?
ResouceManager:整体的资源管控,与其他节点进行交互
NodeManager:对单台服务器的资源管控
Container:对单台服务器预先占用的资源,所以EMR一直都是满的,因为他被预先占用了
AppMaster:只有启动计算任务时候会出现,他会向RM申请资源