目录
- 理解卷积层、池化层和全连接层:神经网络的核心构建模块
-
- 一、卷积层:空间特征的"提取器"
- 二、池化层:特征的"压缩器"与"鲁棒性增强器"
-
- [2.1 常见的池化操作类型](#2.1 常见的池化操作类型)
-
- [(1)最大池化(Max Pooling)](#(1)最大池化(Max Pooling))
- [(2)平均池化(Average Pooling)](#(2)平均池化(Average Pooling))
- [(3)全局池化(Global Pooling)](#(3)全局池化(Global Pooling))
- [2.2 池化层的输出尺寸计算](#2.2 池化层的输出尺寸计算)
- [2.3 池化层的核心作用](#2.3 池化层的核心作用)
- [2.5 池化层的代码实现(PyTorch)](#2.5 池化层的代码实现(PyTorch))
- 三、全连接层:特征的"分类器"与"整合器"
-
- [3.1 全连接层的数学原理](#3.1 全连接层的数学原理)
- [3.2 全连接层的工程细节](#3.2 全连接层的工程细节)
- [3.3 全连接层的核心作用](#3.3 全连接层的核心作用)
- [3.5 全连接层的代码实现(PyTorch)](#3.5 全连接层的代码实现(PyTorch))
- [3.6 全连接层的优缺点](#3.6 全连接层的优缺点)
- 四、三层协同工作:CNN的特征提取与分类流程
- 五、三层的核心区别与适用场景
- 六、举例演示:基于CNN架构说明
-
- 6.1输入:一张待识别的手写数字
- [6.2 计算过程](#6.2 计算过程)
-
- [6.2.1 计算1-原始尺寸到卷积层](#6.2.1 计算1-原始尺寸到卷积层)
- [6.2.2 计算2-卷积层到到池化层(平均池化)](#6.2.2 计算2-卷积层到到池化层(平均池化))
- [6.2.3 计算3-池化层到全连接](#6.2.3 计算3-池化层到全连接)
- 七、经典CNN网络的卷积架构详解(附架构图建议)
-
- [7.1 LeNet:CNN的"开山鼻祖",极简卷积架构(1998)](#7.1 LeNet:CNN的“开山鼻祖”,极简卷积架构(1998))
-
- [7.1.1 架构](#7.1.1 架构)
- [7.1.2 关键设计亮点](#7.1.2 关键设计亮点)
- [7.2 AlexNet:CNN爆发的"里程碑",深层卷积架构(2012)](#7.2 AlexNet:CNN爆发的“里程碑”,深层卷积架构(2012))
-
- [7.2.1 架构](#7.2.1 架构)
- [7.2.2 关键设计亮点](#7.2.2 关键设计亮点)
- [7.3 VGGNet:"深度为王",统一卷积架构(2014)](#7.3 VGGNet:“深度为王”,统一卷积架构(2014))
-
- [7.3.1 核心卷积架构拆解](#7.3.1 核心卷积架构拆解)
- [7.3.2 关键设计亮点](#7.3.2 关键设计亮点)
- [7.4 GoogLeNet:"创新模块",高效卷积架构(2014)](#7.4 GoogLeNet:“创新模块”,高效卷积架构(2014))
-
- [7.4.1 架构(inception模块和整体流程)](#7.4.1 架构(inception模块和整体流程))
- [7.4.2 关键设计亮点](#7.4.2 关键设计亮点)
- [7.5 ResNet:"残差连接",超深层卷积架构(2015)](#7.5 ResNet:“残差连接”,超深层卷积架构(2015))
- [7.6 五大经典网络卷积架构总结](#7.6 五大经典网络卷积架构总结)
- 七、总结
理解卷积层、池化层和全连接层:神经网络的核心构建模块
在深度学习的视觉任务(图像分类、目标检测、语义分割等)中,卷积神经网络(CNN)凭借其对空间特征的高效提取能力成为主流模型,而卷积层(Convolution Layer) 、**池化层(Pooling Layer)和全连接层(Fully Connected Layer)**正是CNN的三大核心组件。这三层各司其职、层层配合,从原始图像的像素信息中逐步提取低级特征(边缘、纹理)、中级特征(形状、轮廓)和高级特征(物体、场景),最终实现对图像的理解和分类。
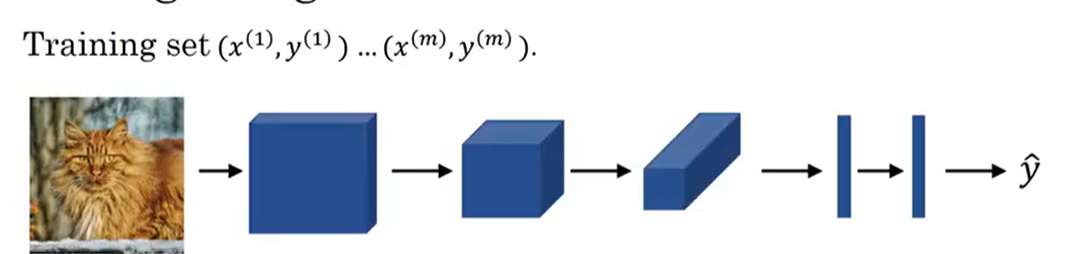
本文将从核心原理 、数学公式 、工程实现细节 、作用与意义四个维度,全面拆解卷积层、池化层和全连接层,同时结合代码示例和图片建议,让抽象的神经网络层变得直观易懂,建立对CNN基础架构的系统性认知。
一、卷积层:空间特征的"提取器"
卷积层是CNN的核心特征提取模块 ,其设计灵感来源于人类视觉系统的感受野机制------人类眼睛对视野内的局部区域敏感,而非一次性感知全部画面。卷积层通过局部卷积操作 ,在保留图像空间结构的前提下,提取局部特征,同时通过权值共享大幅减少模型参数,解决了全连接层处理图像时参数爆炸的问题。
1.1 核心概念铺垫
在理解卷积操作前,需先明确3个基础概念,这是理解卷积层的关键:
- 感受野(Receptive Field):卷积核在输入特征图上的覆盖区域,即输出特征图上的一个像素点,对应输入特征图上的局部区域大小。
- 权值共享(Weight Sharing):同一卷积核在输入特征图的所有位置进行卷积时,使用相同的权重参数,避免对每个像素点单独赋值。
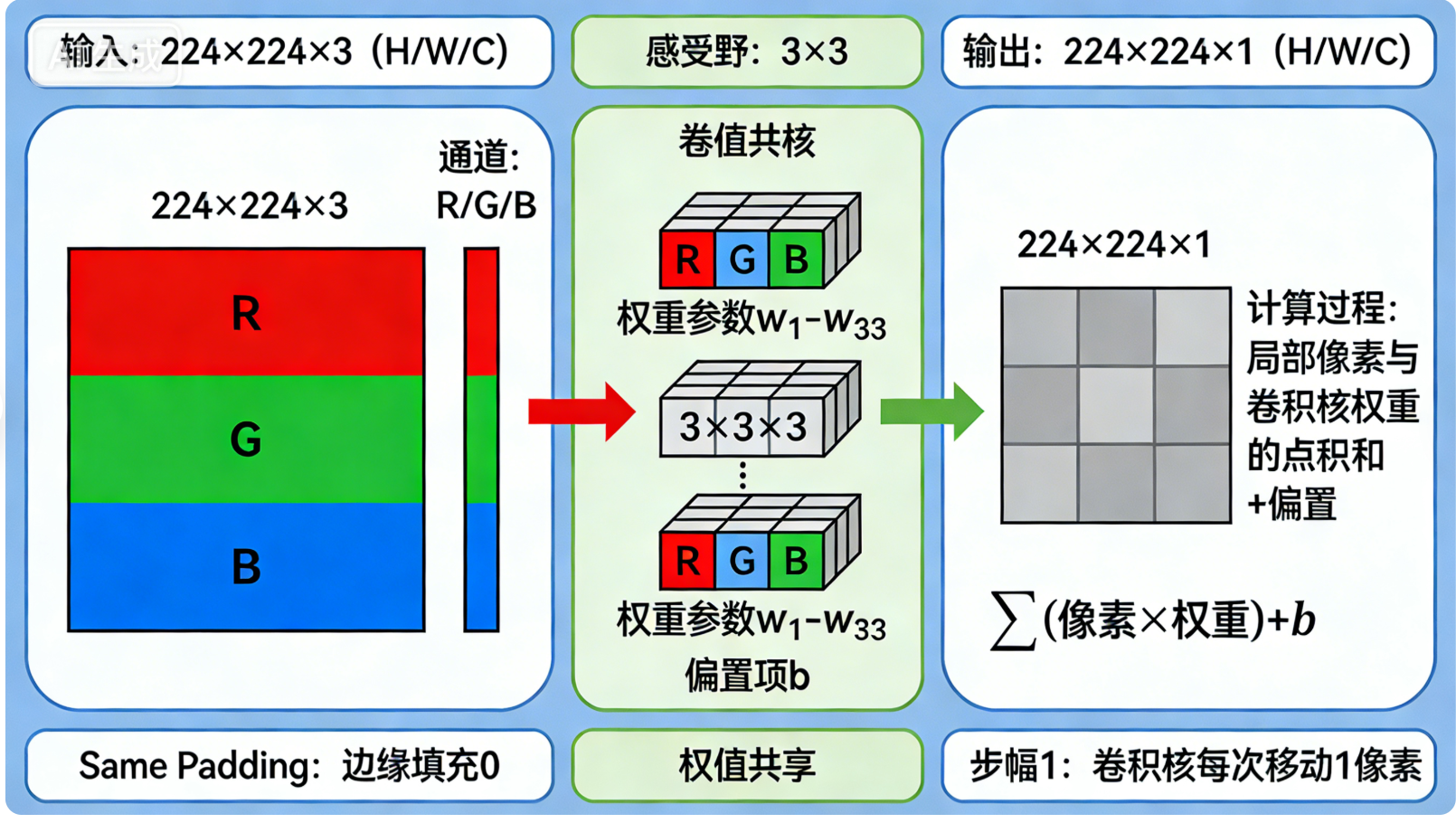
- 卷积核(Kernel/Filter):也叫滤波器,是一个小型的权重矩阵,是卷积层提取特征的"工具",其大小通常为3×3、5×5,深度与输入特征图的通道数一致。
1.2 卷积操作的数学原理
卷积层的输入可以是原始图像(单通道如灰度图:H×W×1;三通道如RGB图:H×W×3)或上一层的特征图(Feature Map),输出为经过卷积操作后的新特征图。
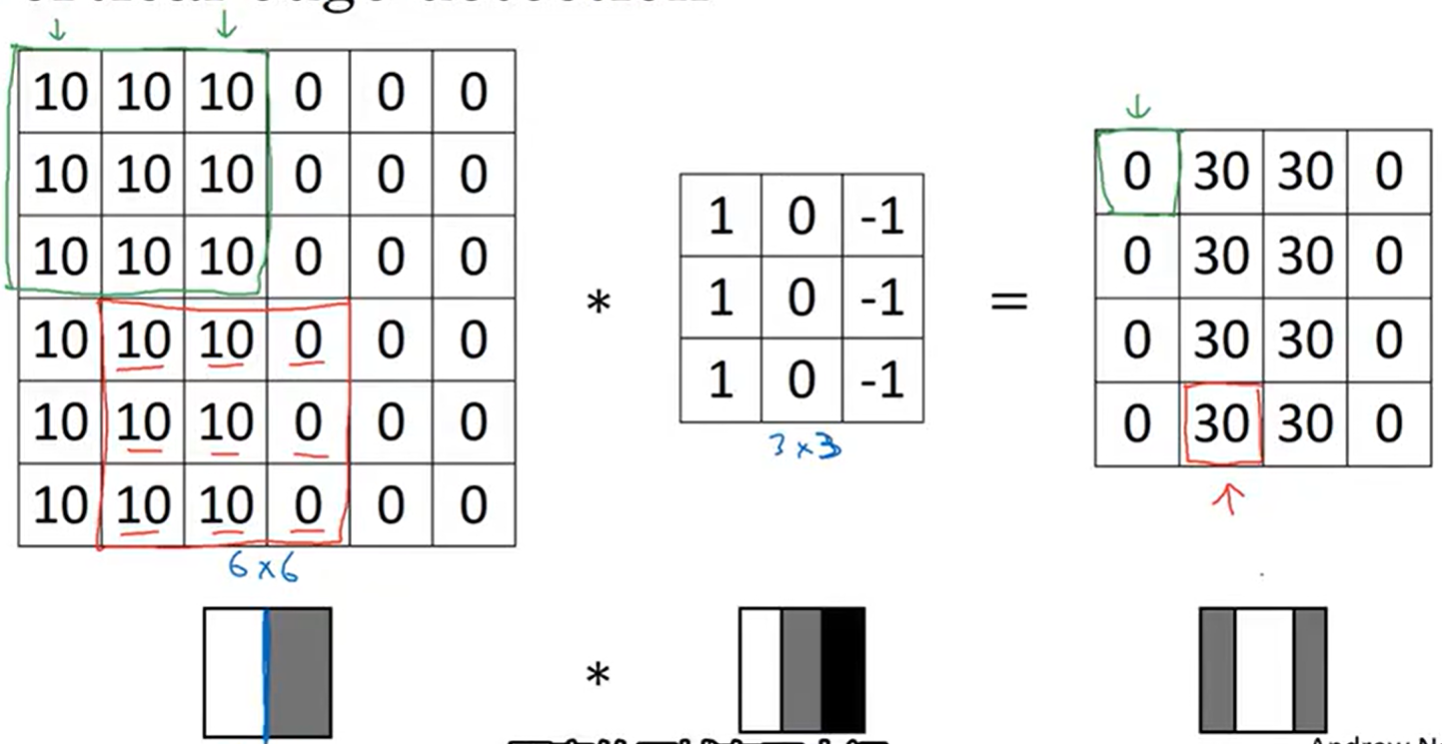
二维卷积的基本公式
对于二维卷积(2D Convolution) (最常用的图像卷积操作),设输入特征图为 X ∈ R H i n × W i n × C i n X \in \mathbb{R}^{H_{in} \times W_{in} \times C_{in}} X∈RHin×Win×Cin( H i n H_{in} Hin为高度, W i n W_{in} Win为宽度, C i n C_{in} Cin为通道数),卷积核为 K ∈ R k h × k w × C i n × C o u t K \in \mathbb{R}^{k_h \times k_w \times C_{in} \times C_{out}} K∈Rkh×kw×Cin×Cout( k h k_h kh为卷积核高度, k w k_w kw为卷积核宽度, C o u t C_{out} Cout为输出通道数,即卷积核的数量),卷积操作的数学表达式为:
Y i , j , c o u t = ∑ m = 0 k h − 1 ∑ n = 0 k w − 1 ∑ c i n = 0 C i n − 1 X i + m − p , j + n − p , c i n ⋅ K m , n , c i n , c o u t + b c o u t Y_{i,j,c_{out}} = \sum_{m=0}^{k_h-1} \sum_{n=0}^{k_w-1} \sum_{c_{in}=0}^{C_{in}-1} X_{i+m-p,j+n-p,c_{in}} \cdot K_{m,n,c_{in},c_{out}} + b_{c_{out}} Yi,j,cout=m=0∑kh−1n=0∑kw−1cin=0∑Cin−1Xi+m−p,j+n−p,cin⋅Km,n,cin,cout+bcout
其中:
- Y i , j , c o u t Y_{i,j,c_{out}} Yi,j,cout:输出特征图在 ( i , j ) (i,j) (i,j)位置、第 c o u t c_{out} cout个通道的像素值;
- p p p:填充(Padding)的大小,用于控制输出特征图的尺寸;
- b c o u t b_{c_{out}} bcout:第 c o u t c_{out} cout个卷积核对应的偏置项,每个输出通道对应一个偏置。
输出特征图尺寸计算
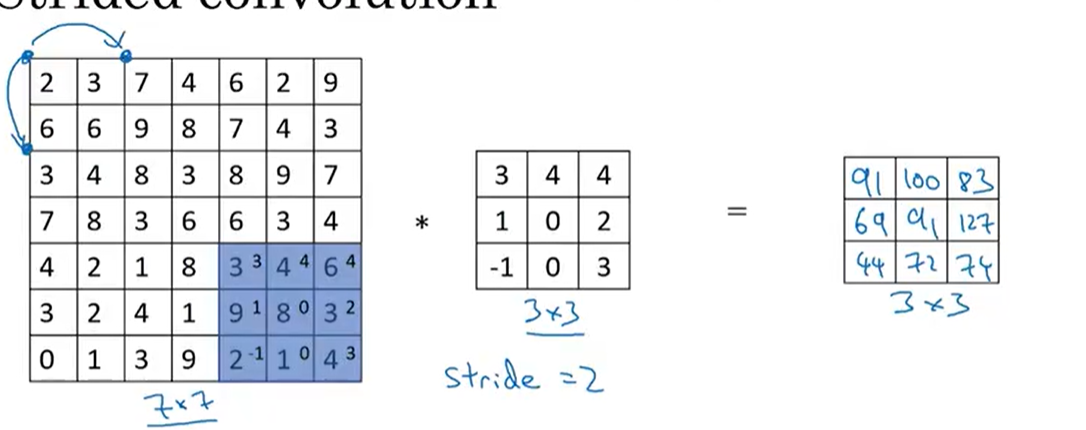
卷积操作后,输出特征图的尺寸由输入尺寸 、卷积核大小 、填充(Padding) 、**步幅(Stride)**四个参数决定,核心公式为:
H o u t = ⌊ H i n + 2 p − k h s + 1 ⌋ H_{out} = \lfloor \frac{H_{in} + 2p - k_h}{s} + 1 \rfloor Hout=⌊sHin+2p−kh+1⌋
W o u t = ⌊ W i n + 2 p − k w s + 1 ⌋ W_{out} = \lfloor \frac{W_{in} + 2p - k_w}{s} + 1 \rfloor Wout=⌊sWin+2p−kw+1⌋
其中:
- s s s:步幅(Stride),卷积核在输入特征图上水平/垂直方向每次移动的像素数;
- ⌊ ⋅ ⌋ \lfloor \cdot \rfloor ⌊⋅⌋:向下取整操作,确保尺寸为整数。

常用填充策略:
- Valid Padding : p = 0 p=0 p=0,无填充,输出特征图尺寸小于输入,会丢失边缘信息;
- Same Padding : p = ⌊ k − 1 2 ⌋ p=\lfloor \frac{k-1}{2} \rfloor p=⌊2k−1⌋( k k k为卷积核边长,如3×3卷积核 p = 1 p=1 p=1),填充后输出特征图尺寸与输入完全一致,保留边缘信息,是实际工程中最常用的策略。
1.3 卷积层的工程细节
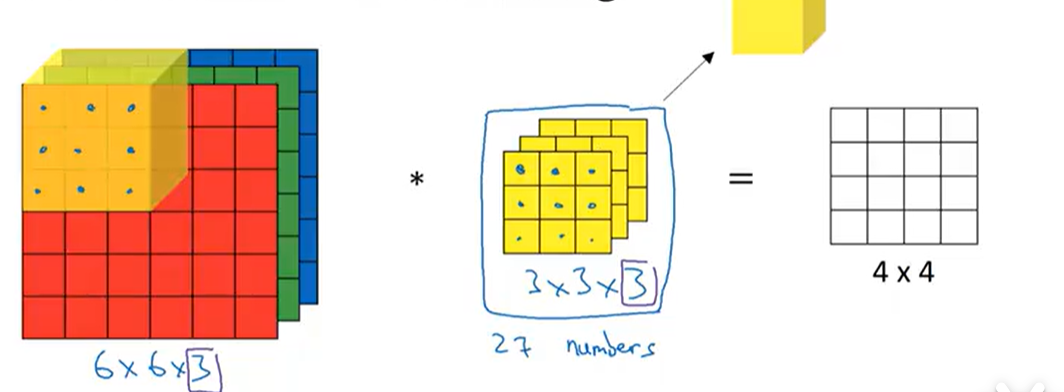
- 多通道卷积:输入为多通道时,每个通道对应一个卷积核子矩阵,同一输出通道的所有通道卷积结果相加,得到该通道的特征图(即"逐通道卷积,逐通道求和");
- 卷积核的数量:输出通道数等于卷积核数量,卷积核数量越多,提取的特征越丰富(如16个卷积核提取16种不同的低级特征);
- 分组卷积(Group Convolution):将输入通道和卷积核分成若干组,每组内单独卷积,减少参数数量(如MobileNet、ResNeXt中使用),是标准卷积的优化版本;
- 偏置项 :可选参数,部分场景(如批量归一化后)会省略偏置,因为批量归一化的平移操作会覆盖偏置的作用。
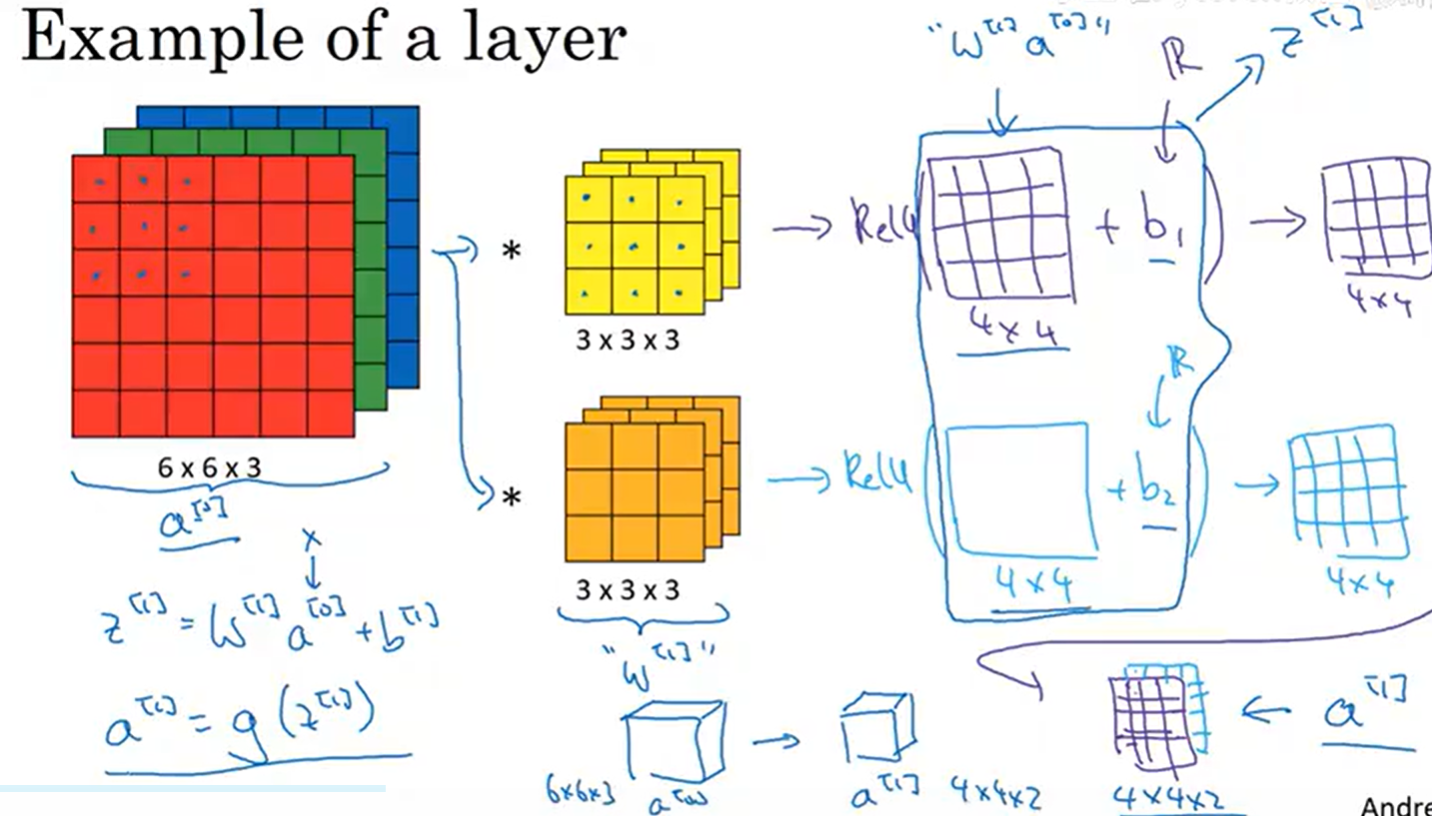
1.4 卷积层的核心作用
- 局部特征提取:聚焦输入的局部区域,捕捉边缘、纹理、角点等低级空间特征,这是图像的基础特征;
- 权值共享:大幅减少模型参数(如3×3卷积核处理224×224×3的图像,仅需27个权重,而全连接层需要224×224×3=150528个权重),降低过拟合风险;
- 空间结构保留:输出特征图仍保持H×W的二维结构,保留了像素间的空间位置关系(如"左边的边缘和右边的纹理相连"),这是CNN优于全连接网络处理图像的关键;
- 特征映射:通过不同的卷积核,将输入映射为不同的特征图,实现特征的多样化表达。
1.6 卷积层的代码实现(PyTorch)
PyTorch中使用nn.Conv2d实现二维卷积层,以下为经典的3×3 Same Padding、步幅1的卷积层实现,包含输入输出尺寸验证:
python
import torch
import torch.nn as nn
# 定义卷积层:输入通道3(RGB),输出通道16,卷积核3×3,步幅1,Same Padding
conv_layer = nn.Conv2d(
in_channels=3,
out_channels=16,
kernel_size=3,
stride=1,
padding=1 # Same Padding: padding=(kernel_size-1)//2
)
# 构造输入:batch_size=4,3通道,224×224的图像 (N, C, H, W)
x = torch.randn(4, 3, 224, 224)
# 卷积操作
y = conv_layer(x)
# 输出尺寸验证:Same Padding+步幅1,输出尺寸与输入一致
print(f"输入尺寸: {x.shape}") # torch.Size([4, 3, 224, 224])
print(f"输出尺寸: {y.shape}") # torch.Size([4, 16, 224, 224])
print(f"卷积核参数数量: {sum(p.numel() for p in conv_layer.parameters())}") # 16*(3*3*3 +1) = 448二、池化层:特征的"压缩器"与"鲁棒性增强器"
池化层通常紧跟在卷积层之后,是CNN的特征降维与鲁棒性提升模块 。其核心思想是对卷积层输出的特征图进行局部下采样 ,在减少特征图尺寸(高度、宽度)和模型计算量的同时,保留关键特征,并且让特征对微小的位置变化不敏感(即平移不变性)。
池化层没有可学习的参数,仅通过固定的规则对局部区域进行聚合操作,这是其与卷积层的核心区别。
2.1 常见的池化操作类型
工程中最常用的池化操作有两种:最大池化(Max Pooling)和平均池化(Average Pooling) ,此外还有全局池化(Global Pooling)等变体,适用于不同的场景。
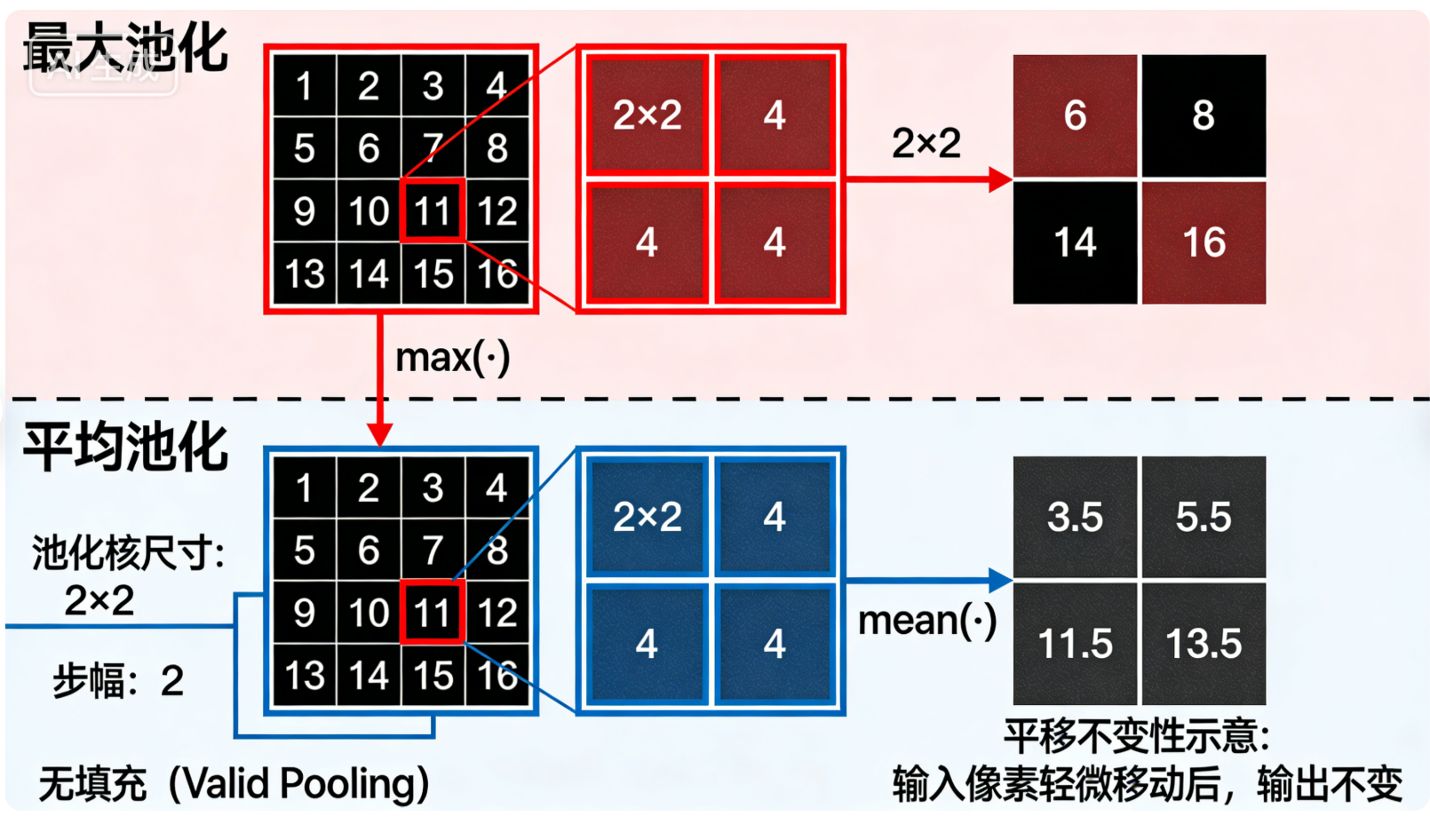
(1)最大池化(Max Pooling)
取局部区域内的最大值 作为该区域的代表值,能够有效保留特征图中的纹理、边缘、轮廓 等强特征,是视觉任务中最常用的池化方式。
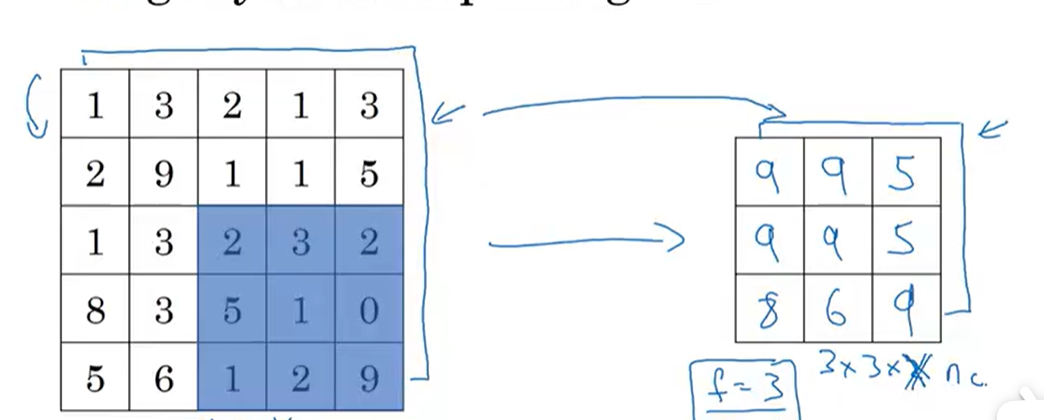
数学表达式 :
Y i , j , c = max m = 0 p h − 1 max n = 0 p w − 1 X i ⋅ s + m , j ⋅ s + n , c Y_{i,j,c} = \max_{m=0}^{p_h-1} \max_{n=0}^{p_w-1} X_{i \cdot s + m, j \cdot s + n, c} Yi,j,c=m=0maxph−1n=0maxpw−1Xi⋅s+m,j⋅s+n,c
其中: p h 、 p w p_h、p_w ph、pw为池化核的高度和宽度, s s s为池化步幅, c c c为通道数。
(2)平均池化(Average Pooling)
取局部区域内的平均值 作为该区域的代表值,能够保留特征图的整体灰度信息 ,平滑特征波动,常用于模型的最后一层特征降维。
数学表达式 :
Y i , j , c = 1 p h × p w ∑ m = 0 p h − 1 ∑ n = 0 p w − 1 X i ⋅ s + m , j ⋅ s + n , c Y_{i,j,c} = \frac{1}{p_h \times p_w} \sum_{m=0}^{p_h-1} \sum_{n=0}^{p_w-1} X_{i \cdot s + m, j \cdot s + n, c} Yi,j,c=ph×pw1m=0∑ph−1n=0∑pw−1Xi⋅s+m,j⋅s+n,c
(3)全局池化(Global Pooling)
属于池化的特殊形式,池化核大小与特征图的尺寸一致,即对整个特征图的每个通道取最大值(全局最大池化)或平均值(全局平均池化),输出为1×1×C的特征向量,常用于替代全连接层,减少模型参数。
2.2 池化层的输出尺寸计算
池化层的输出尺寸计算规则与卷积层一致,仅无填充(或极少使用填充),核心公式为:
H o u t = ⌊ H i n − p h s + 1 ⌋ H_{out} = \lfloor \frac{H_{in} - p_h}{s} + 1 \rfloor Hout=⌊sHin−ph+1⌋
W o u t = ⌊ W i n − p w s + 1 ⌋ W_{out} = \lfloor \frac{W_{in} - p_w}{s} + 1 \rfloor Wout=⌊sWin−pw+1⌋
工程常用配置 :池化核2×2,步幅2,此时输出特征图的高度和宽度为输入的1/2,实现无损降维(无信息重叠,无特征丢失)。
2.3 池化层的核心作用
- 特征降维:减小特征图的H×W尺寸,降低后续层的计算量和参数数量,避免模型过拟合;
- 提升平移不变性:即使输入图像中的物体发生微小的平移,池化操作后仍能提取到相同的特征(如物体向右移动1像素,最大池化仍能取到该区域的最大值);
- 提升尺度不变性:对特征图的局部压缩,让模型对物体的尺度变化有一定的鲁棒性(如物体稍微放大/缩小,仍能被识别);
- 保留关键特征:最大池化保留局部最强特征,平均池化保留局部整体特征,均能在降维的同时保留特征的核心信息;
- 防止过拟合:通过减少特征数量,降低模型的复杂度,避免模型对训练数据的细节过度拟合。
2.5 池化层的代码实现(PyTorch)
PyTorch中使用nn.MaxPool2d实现最大池化,nn.AvgPool2d实现平均池化,nn.AdaptiveAvgPool2d实现自适应全局平均池化,以下为常用配置的代码实现:
python
import torch
import torch.nn as nn
# 1. 最大池化:2×2池化核,步幅2,无填充
max_pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
# 2. 平均池化:2×2池化核,步幅2,无填充
avg_pool = nn.AvgPool2d(kernel_size=2, stride=2, padding=0)
# 3. 全局平均池化:自适应输出1×1
global_avg_pool = nn.AdaptiveAvgPool2d((1, 1))
# 构造输入:卷积层输出的16通道224×224特征图 (N, C, H, W)
x = torch.randn(4, 16, 224, 224)
# 池化操作
y_max = max_pool(x)
y_avg = avg_pool(x)
y_global = global_avg_pool(x)
# 输出尺寸验证
print(f"输入尺寸: {x.shape}") # torch.Size([4, 16, 224, 224])
print(f"最大池化输出尺寸: {y_max.shape}") # torch.Size([4, 16, 112, 112]) (224/2=112)
print(f"平均池化输出尺寸: {y_avg.shape}") # torch.Size([4, 16, 112, 112])
print(f"全局平均池化输出尺寸: {y_global.shape}") # torch.Size([4, 16, 1, 1])
# 池化层无参数验证
print(f"最大池化参数数量: {sum(p.numel() for p in max_pool.parameters())}") # 0三、全连接层:特征的"分类器"与"整合器"
全连接层(FC层)通常位于CNN的最后几层 ,是将高维特征映射为类别概率的分类模块 。其核心思想是将池化层(或卷积层)输出的二维特征图展平为一维特征向量,然后通过全连接操作将特征向量映射到类别空间,最终通过激活函数(如Softmax)得到每个类别的概率。
全连接层的所有神经元都与上一层的所有神经元相连,因此没有空间结构,仅负责特征的线性整合和非线性映射,是CNN中参数数量最多的层。
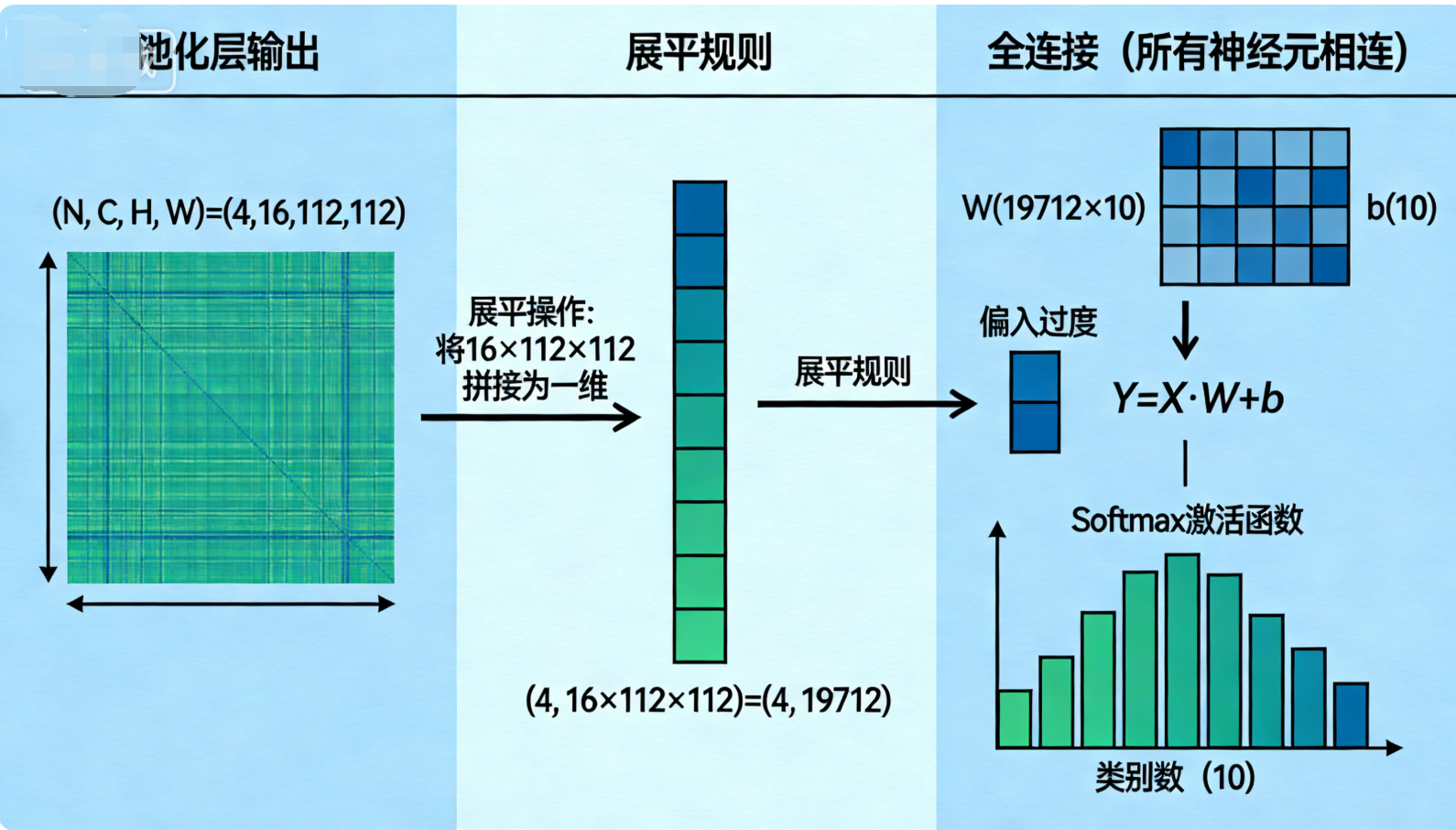
3.1 全连接层的数学原理
全连接层的输入为展平后的一维特征向量 X ∈ R N X \in \mathbb{R}^{N} X∈RN( N N N为特征向量的维度,即 H i n × W i n × C i n H_{in} \times W_{in} \times C_{in} Hin×Win×Cin),输出为类别空间的特征向量 Y ∈ R M Y \in \mathbb{R}^{M} Y∈RM( M M M为类别数),核心数学表达式为:
Y = X ⋅ W + b Y = X \cdot W + b Y=X⋅W+b
其中:
- W ∈ R N × M W \in \mathbb{R}^{N \times M} W∈RN×M:全连接层的权重矩阵,是可学习的参数;
- b ∈ R M b \in \mathbb{R}^{M} b∈RM:全连接层的偏置向量,每个类别对应一个偏置;
- 若加入非线性激活函数(如ReLU、Softmax),则表达式为: Y = σ ( X ⋅ W + b ) Y = \sigma(X \cdot W + b) Y=σ(X⋅W+b)( σ \sigma σ为激活函数)。
关键步骤:特征展平(Flatten)
全连接层要求输入为一维向量,因此需要先将二维特征图展平,展平的规则为:保留批量维度,将通道、高度、宽度维度拼接为一维 ,即对于输入 ( N , C , H , W ) (N, C, H, W) (N,C,H,W),展平后为 ( N , C × H × W ) (N, C \times H \times W) (N,C×H×W)。
3.2 全连接层的工程细节
- 特征展平:必须保证展平后的维度与全连接层的输入维度一致,否则会出现维度不匹配错误;
- 激活函数:全连接层后通常加入激活函数,中间层用ReLU(引入非线性,提升模型表达能力),最后一层用Softmax(将特征向量映射为0-1的概率分布,且概率和为1);
- Dropout:全连接层参数多,易过拟合,通常加入Dropout层(随机失活部分神经元),降低过拟合风险;
- 全局池化替代 :在现代CNN(如ResNet、MobileNet)中,常用**全局平均池化(GAP)**替代全连接层的前几层,将特征图直接映射为 ( N , C , 1 , 1 ) (N, C, 1, 1) (N,C,1,1),展平后为 ( N , C ) (N, C) (N,C),大幅减少参数数量。
3.3 全连接层的核心作用
- 特征整合:将卷积层和池化层提取的高维空间特征,整合为一维的全局特征向量,实现特征的线性融合;
- 类别映射:将全局特征向量映射到类别空间,建立特征与类别的对应关系;
- 非线性表达:通过激活函数引入非线性,让模型能够拟合复杂的特征-类别映射关系;
- 输出概率:最后一层通过Softmax激活函数,将特征向量转换为类别概率,实现对图像的分类。
3.5 全连接层的代码实现(PyTorch)
PyTorch中使用nn.Flatten实现特征展平,nn.Linear实现全连接层,以下为CNN经典的"卷积+池化+展平+全连接"完整流程实现,包含图像分类的端到端操作:
python
import torch
import torch.nn as nn
# 定义完整的CNN小模型:卷积+最大池化+展平+全连接(分类10个类别)
class SimpleCNN(nn.Module):
def __init__(self, num_classes=10):
super(SimpleCNN, self).__init__()
# 卷积池化模块
self.features = nn.Sequential(
nn.Conv2d(3, 16, 3, 1, 1), # 卷积层:3→16通道,224×224
nn.ReLU(inplace=True), # 激活函数
nn.MaxPool2d(2, 2) # 最大池化:224→112×112
)
# 全连接模块
self.classifier = nn.Sequential(
nn.Flatten(), # 展平:(N,16,112,112)→(N,16×112×112)
nn.Linear(16*112*112, 512), # 全连接层1:19712→512
nn.ReLU(inplace=True), # 激活函数
nn.Dropout(0.5), # Dropout:防止过拟合
nn.Linear(512, num_classes) # 全连接层2:512→10(类别数)
)
def forward(self, x):
x = self.features(x)
x = self.classifier(x)
return x
# 实例化模型,分类10个类别
model = SimpleCNN(num_classes=10)
# 构造输入:4张RGB图像,224×224
x = torch.randn(4, 3, 224, 224)
# 前向传播
y = model(x)
# 输出尺寸验证:(N, num_classes)=(4,10)
print(f"输入尺寸: {x.shape}") # torch.Size([4, 3, 224, 224])
print(f"输出尺寸: {y.shape}") # torch.Size([4, 10])
# 模型总参数数量
print(f"模型总参数数量: {sum(p.numel() for p in model.parameters()):,}") # 约1030万3.6 全连接层的优缺点
优点
- 特征整合能力强:能够将局部特征整合为全局特征,建立特征与类别的直接对应关系;
- 分类效果好:在传统CNN中,全连接层是分类的核心,能够拟合复杂的分类边界;
- 实现简单:数学原理和代码实现都较为简单,易于理解和调试。
缺点
- 参数数量庞大 :全连接层的权重矩阵维度为 N × M N×M N×M, N N N通常为几万甚至几十万,导致参数数量激增,易过拟合;
- 丢失空间信息:展平操作破坏了特征的空间结构,无法利用图像的空间上下文信息;
- 计算量高:全连接层的矩阵乘法计算量远大于卷积层和池化层,增加了模型的推理时间。
解决方案 :使用全局平均池化(GAP)替代全连接层的前几层,将特征图直接映射为 ( N , C ) (N, C) (N,C),再用一个轻量的全连接层映射到类别空间,大幅减少参数数量。
四、三层协同工作:CNN的特征提取与分类流程
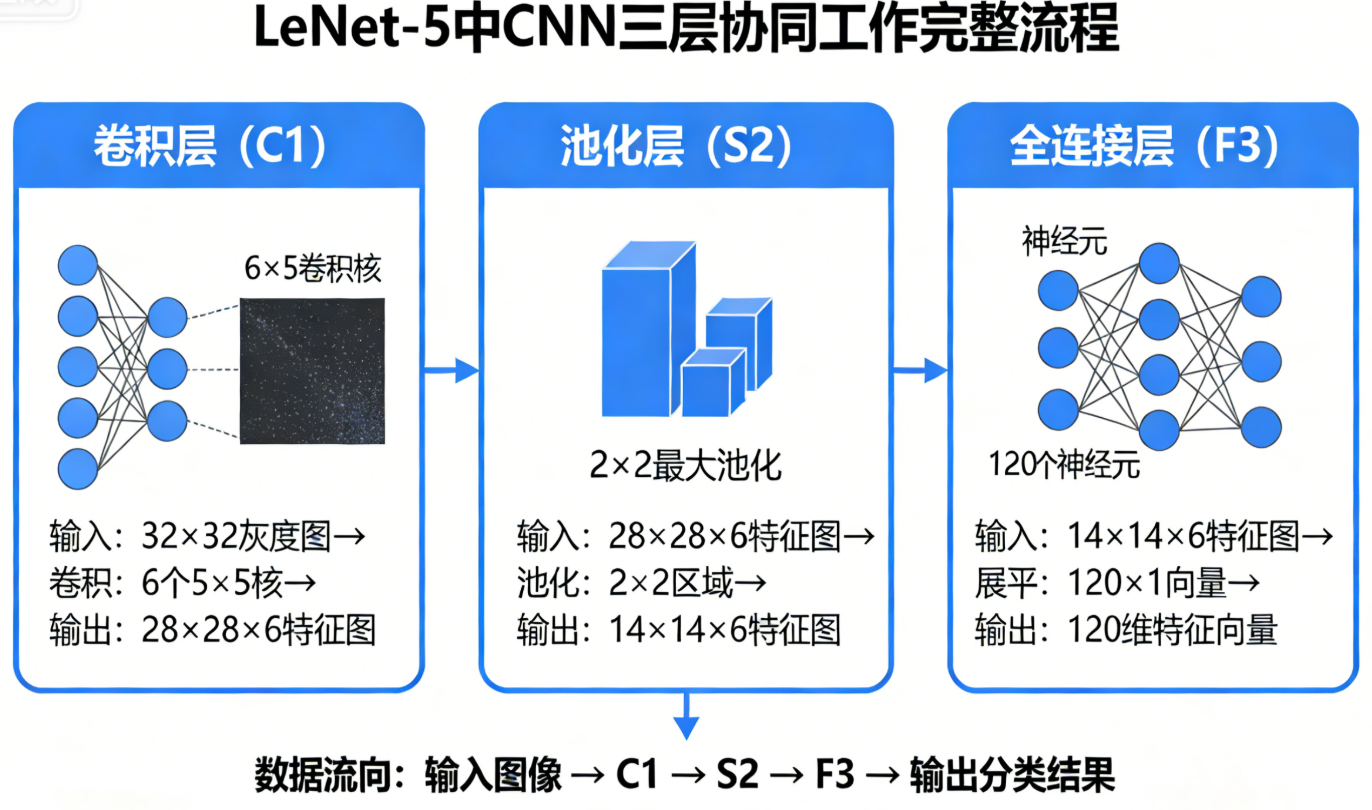
卷积层、池化层和全连接层并非孤立存在,而是层层配合、逐级递进,构成了CNN的完整特征提取与分类流程。以经典的LeNet-5为例,三层的协同工作流程如下:
- 输入层:原始图像(如28×28的手写数字灰度图);
- 卷积层1:用6个5×5的卷积核提取低级特征(边缘、纹理),输出6×24×24的特征图;
- 池化层1:2×2最大池化,降维为6×12×12的特征图;
- 卷积层2:用16个5×5的卷积核提取中级特征(形状、轮廓),输出16×8×8的特征图;
- 池化层2:2×2最大池化,降维为16×4×4的特征图;
- 展平层:将16×4×4展平为256维的一维特征向量;
- 全连接层1:256→120,整合全局特征;
- 全连接层2:120→84,进一步映射特征;
- 全连接层3:84→10,映射到10个数字的类别空间,通过Softmax得到类别概率;
- 输出层:概率最大的类别为预测结果。
核心规律 :卷积层提取特征,池化层降维增强鲁棒性,全连接层分类,从低级到高级,从局部到全局,逐步实现对图像的理解。
五、三层的核心区别与适用场景
为了更清晰地理解卷积层、池化层和全连接层的差异,以下从核心操作 、可学习参数 、空间结构 、核心作用 、适用场景五个维度进行对比:
| 网络层 | 核心操作 | 可学习参数 | 空间结构 | 核心作用 | 适用场景 |
|---|---|---|---|---|---|
| 卷积层 | 局部卷积(点积和+偏置) | 有(W+b) | 保留 | 提取局部空间特征 | CNN的特征提取层(前几层) |
| 池化层 | 局部下采样(max/mean) | 无 | 保留 | 特征降维,提升鲁棒性 | 卷积层之后,配合卷积层降维 |
| 全连接层 | 矩阵乘法+偏置 | 有(W+b) | 丢失 | 特征整合,类别映射 | CNN的分类层(最后几层) |
六、举例演示:基于CNN架构说明
6.1输入:一张待识别的手写数字
我们的起点是一张 32×32×1 的灰度图像,也就是图中那个手写的"7"。
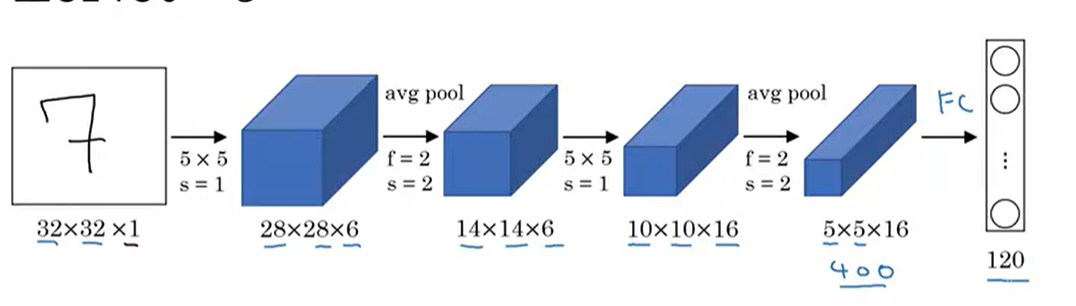
上面这张图完整展示了拆解的CNN流程,从输入的手写"7",到两次卷积+池化,再到全连接层的输出。
输入 (32×32×1)
↓
卷积层1 (5×5, s=1, 6个核) → 特征图 (28×28×6)
↓
池化层1 (2×2, s=2) → 降维特征图 (14×14×6)
↓
卷积层2 (5×5, s=1, 16个核) → 特征图 (10×10×16)
↓
池化层2 (2×2, s=2) → 降维特征图 (5×5×16)
↓
摊平 → 向量 (400维)
↓
全连接层 → 向量 (120维)
↓
输出层 → 概率分布 (10维)- 32×32 代表图像的宽和高,这是一个标准的小尺寸输入。
- 1 代表它是单通道的灰度图(彩色图像会是3通道:R、G、B)。
- 这个原始像素矩阵就是整个网络的"原材料",每一个像素的取值范围是 0~255,代表灰度的深浅。
6.2 计算过程
6.2.1 计算1-原始尺寸到卷积层
输入尺寸 32×32,卷积核 f=5,步长 s=1,没有填充时:
输出尺寸 = 输入尺寸 − f s + 1 = 32 − 5 1 + 1 = 28 \text{输出尺寸} = \frac{\text{输入尺寸} - f}{s} + 1 = \frac{32 - 5}{1} + 1 = 28 输出尺寸=s输入尺寸−f+1=132−5+1=28
所以输出特征图的尺寸是 28×28×6,其中:
28×28是特征图的宽和高6代表6个卷积核生成了6张不同的特征图,对应6种不同的特征。
6.2.2 计算2-卷积层到到池化层(平均池化)
输入尺寸 28×28,池化窗口 f=2,步长 s=2:
输出尺寸 = 输入尺寸 − f s + 1 = 28 − 2 2 + 1 = 14 \text{输出尺寸} = \frac{\text{输入尺寸} - f}{s} + 1 = \frac{28 - 2}{2} + 1 = 14 输出尺寸=s输入尺寸−f+1=228−2+1=14
所以输出特征图的尺寸是 14×14×6,通道数保持不变(还是6个特征图)。
关键作用
- 降维:特征图尺寸从28×28压缩到14×14,计算量直接减少为原来的1/4,大大提升了网络的效率。
- 鲁棒性:即使数字"7"在图像中有轻微的位移或变形,池化后的特征依然能被正确识别,因为它关注的是"有没有"特征,而不是"在哪里"有特征。
- 通道不变:池化只对空间维度(宽、高)进行压缩,不改变通道数,6个特征图依然保留各自的特征信息。
接下来就是持续循环循环,然后进入全连接层
6.2.3 计算3-池化层到全连接
当特征经过两次卷积+池化后,会被"摊平"成一个一维向量,送入全连接层,进行最终的分类决策。
- 5×5×16 的特征图会被展开成一个 400 维的向量(计算:5×5×16 = 400)。
- 这一步的目的是将二维的特征图转换为一维的向量,以便全连接层处理。
关键作用
- 特征整合:全连接层将卷积和池化提取的局部特征进行全局整合,形成对整个图像的抽象表示。
- 分类决策:基于整合后的特征,做出最终的分类判断(比如"这是数字7")。
七、经典CNN网络的卷积架构详解(附架构图建议)
从CNN的发展历程来看,LeNet、AlexNet、VGGNet、ResNet、GoogLeNet这五个经典网络,代表了卷积架构的五次关键迭代------从简单的"卷积+池化"堆叠,到深度提升、创新模块引入,每一种架构都优化了特征提取效率和模型性能,其核心差异集中在卷积层的堆叠方式、过滤器(卷积核)配置、池化策略上,同时也体现了三大核心层的协同逻辑演变。下面我们逐一对每个网络的卷积架构进行详细拆解,同时给出对应的架构图建议,方便后续生成直观可视化内容。
7.1 LeNet:CNN的"开山鼻祖",极简卷积架构(1998)
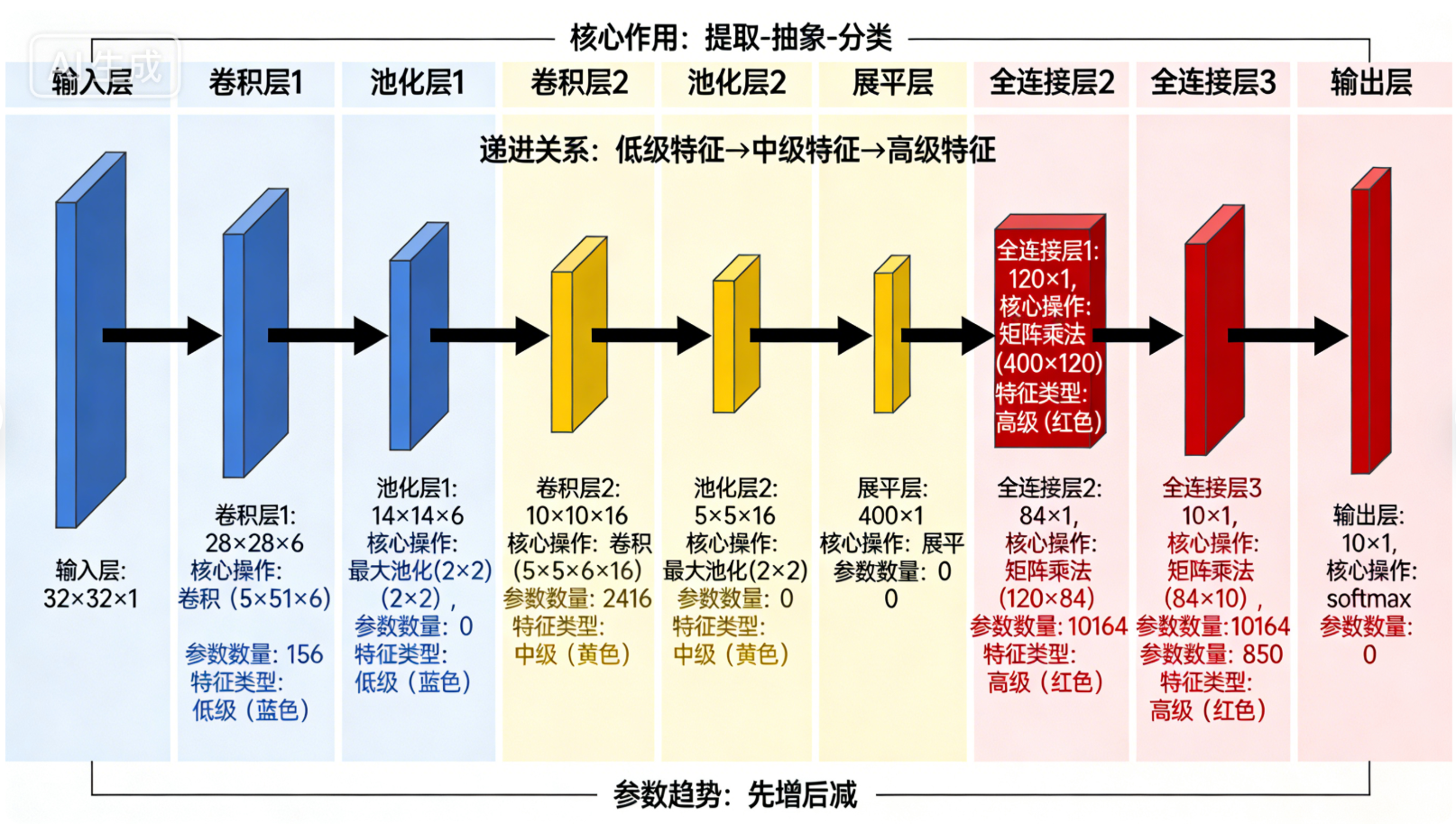
LeNet是由Yann LeCun提出的第一个实用CNN网络,主要用于手写数字识别(MNIST数据集),其卷积架构极其简洁,奠定了"卷积层→池化层→全连接层 "的经典流程,是理解三大核心层协同工作的最佳入门案例,核心特点是"浅层、小过滤器、少通道"。
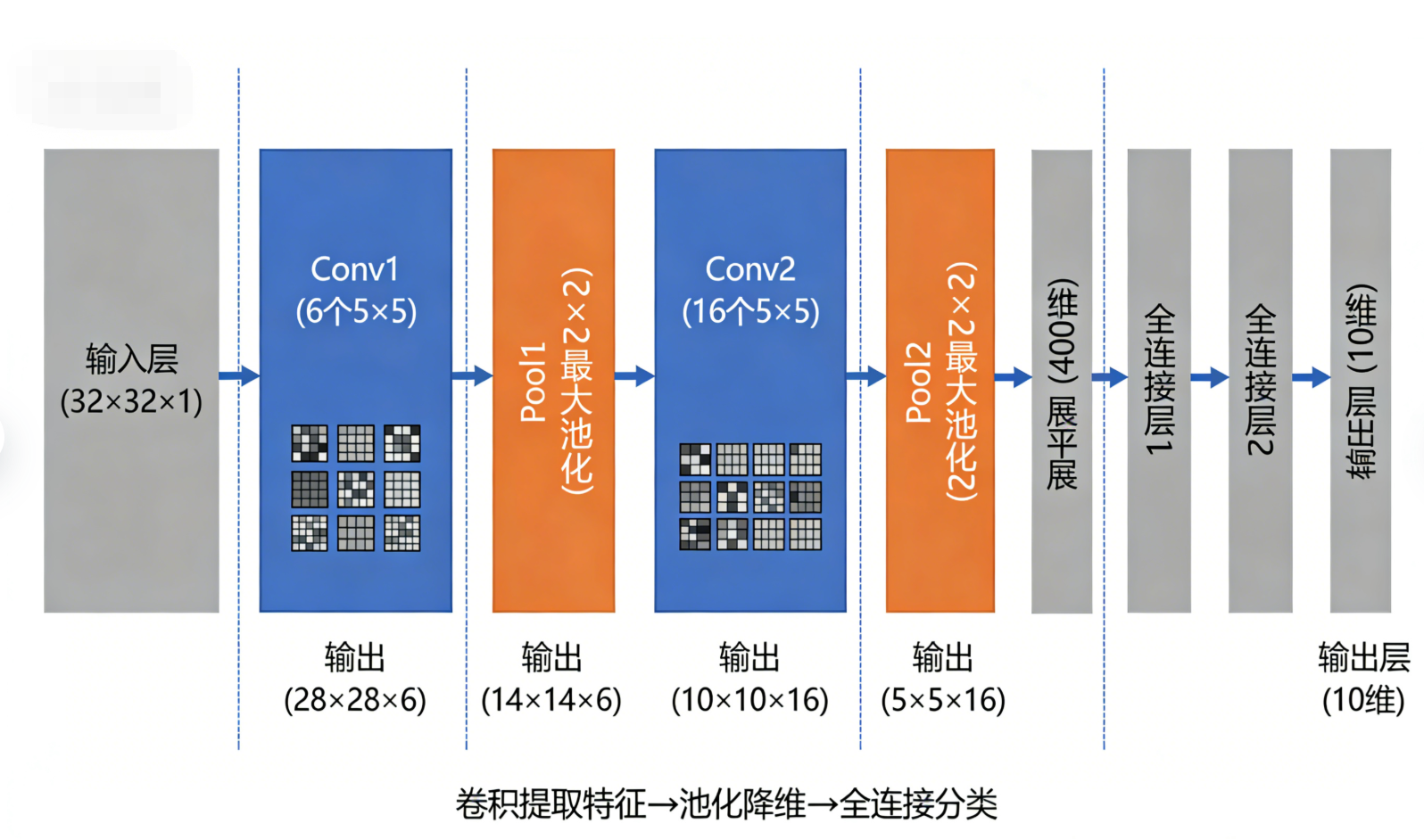
7.1.1 架构
以上述图片为例子:
-
输入层:32×32×1(灰度手写数字图像,单通道,尺寸较小,无需过多降维);
-
卷积层1(Conv1):使用6个5×5的卷积核(过滤器层数=6,即输出通道数=6),步幅=1,无填充(Valid Padding),输出特征图尺寸=32-5+1=28,最终输出28×28×6;
-
池化层1(Pool1):采用2×2最大池化,步幅=2,无填充,输出特征图尺寸=28/2=14,最终输出14×14×6(第一次降维,保留关键特征,减少计算量);
-
卷积层2(Conv2):使用16个5×5的卷积核(过滤器层数=16,通道数提升,提取更丰富特征),步幅=1,无填充,输出特征图尺寸=14-5+1=10,最终输出10×10×16;
-
池化层2(Pool2):同样是2×2最大池化,步幅=2,无填充,输出特征图尺寸=10/2=5,最终输出5×5×16(第二次降维,进一步压缩冗余信息);
-
全连接层衔接:将5×5×16的特征图展平为400维一维向量,后续连接2个全连接层,最终输出10维(对应10个数字类别)。
7.1.2 关键设计亮点
-
首次实现"卷积提取特征→池化降维→全连接分类"的完整流程,每一个卷积层后紧跟池化层,形成"卷积-池化"配对,避免特征冗余;
-
过滤器尺寸固定为5×5,通道数从6提升到16,符合"浅层少通道 、深层多通道"的设计逻辑,逐步提取更复杂的特征;
-
无填充设计,因为输入尺寸小,轻微丢失边缘信息不影响手写数字识别,简化计算。
7.2 AlexNet:CNN爆发的"里程碑",深层卷积架构(2012)
AlexNet是2012年ImageNet图像分类竞赛的冠军模型,正确率远超传统方法,标志着CNN进入实用化阶段。其卷积架构在LeNet的基础上大幅升级,核心特点是"深层 、多通道 、大尺寸输入 、ReLU激活 ",首次引入了Dropout、LRN(局部响应归一化 ),解决了深层网络的过拟合和梯度消失问题,同时优化了卷积和池化的搭配逻辑。
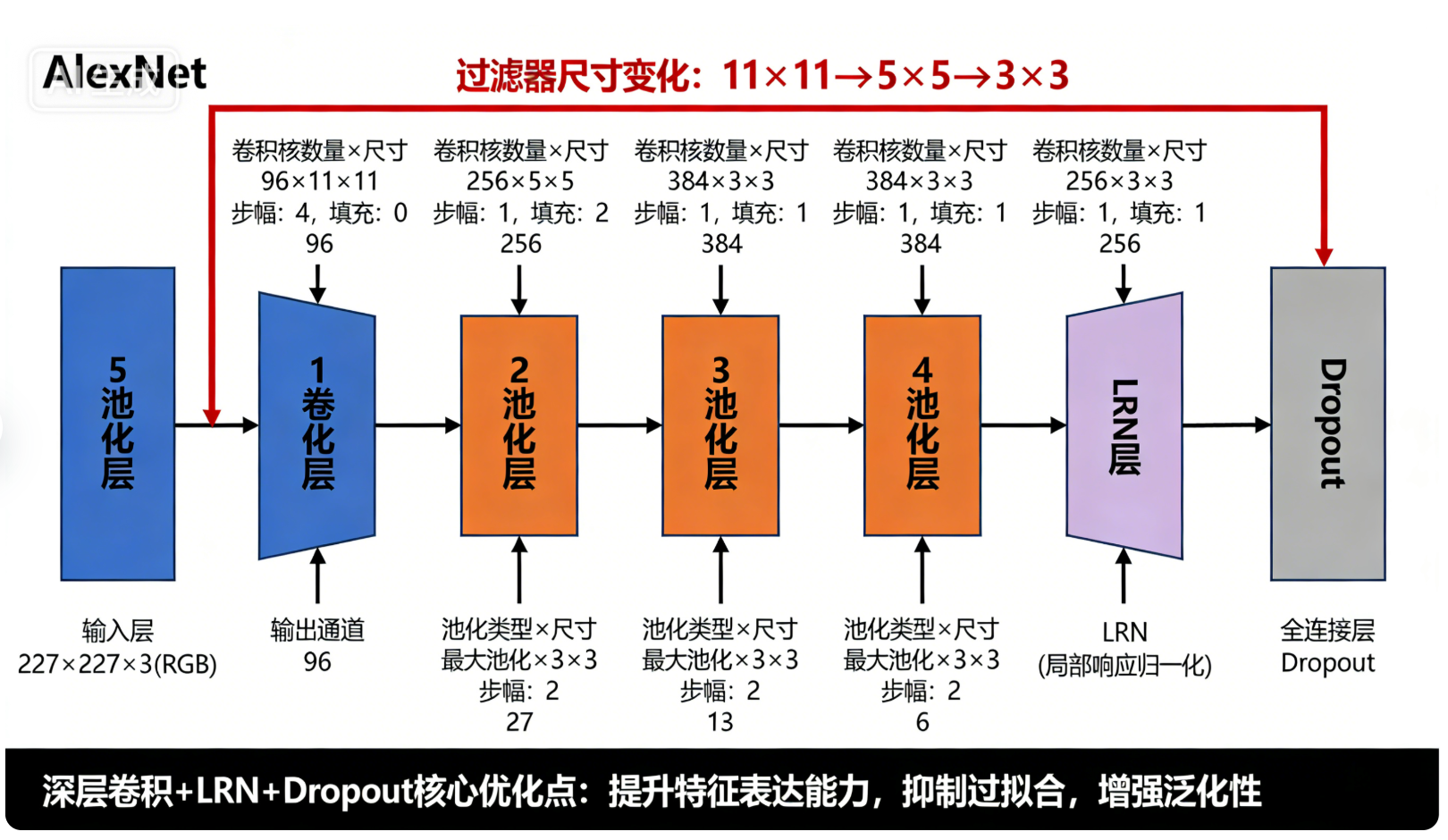
7.2.1 架构
以上述图片为例:
-
输入层:227×227×3(RGB彩色图像,三通道,尺寸远大于LeNet,需要多轮卷积降维);
-
卷积层1(Conv1):使用96个11×11的卷积核(过滤器层数=96,通道数大幅提升),步幅=4(快速降维,减少计算量),无填充,输出特征图尺寸=(227-11)/4 +1=55,最终输出55×55×96;
-
LRN层1:局部响应归一化,增强特征对比度,不改变特征图尺寸,输出仍为55×55×96(辅助优化,非核心层);
-
池化层1(Pool1):3×3最大池化,步幅=2,无填充,输出特征图尺寸=(55-3)/2 +1=27,最终输出27×27×96;
-
卷积层2(Conv2):使用256个5×5的卷积核(过滤器层数=256,通道数继续提升),步幅=1,填充=2(Same Padding,保留尺寸),输出特征图尺寸=(27+2×2-5)/1 +1=27,最终输出27×27×256;
-
LRN层2:再次使用LRN,输出仍为27×27×256;
-
池化层2(Pool2):3×3最大池化,步幅=2,无填充,输出特征图尺寸=(27-3)/2 +1=13,最终输出13×13×256;
-
卷积层3(Conv3):使用384个3×3的卷积核(过滤器层数=384,过滤器尺寸从11、5缩小到3×3,提取更精细特征),步幅=1,填充=1(Same Padding),输出尺寸=13,最终输出13×13×384;
-
卷积层4(Conv4):使用384个3×3的卷积核(过滤器层数=384,与上一层通道数一致,进一步细化特征),步幅=1,填充=1,输出尺寸=13,最终输出13×13×384;
-
卷积层5(Conv5):使用256个3×3的卷积核(过滤器层数=256,通道数减少,压缩特征),步幅=1,填充=1,输出尺寸=13,最终输出13×13×256;
-
池化层3(Pool3):3×3最大池化,步幅=2,无填充,输出特征图尺寸=(13-3)/2 +1=6,最终输出6×6×256;
-
全连接层衔接:将6×6×256展平为9216维向量,连接3个全连接层(4096→4096→1000),最终输出1000维(对应ImageNet的1000个类别),加入Dropout防止过拟合。
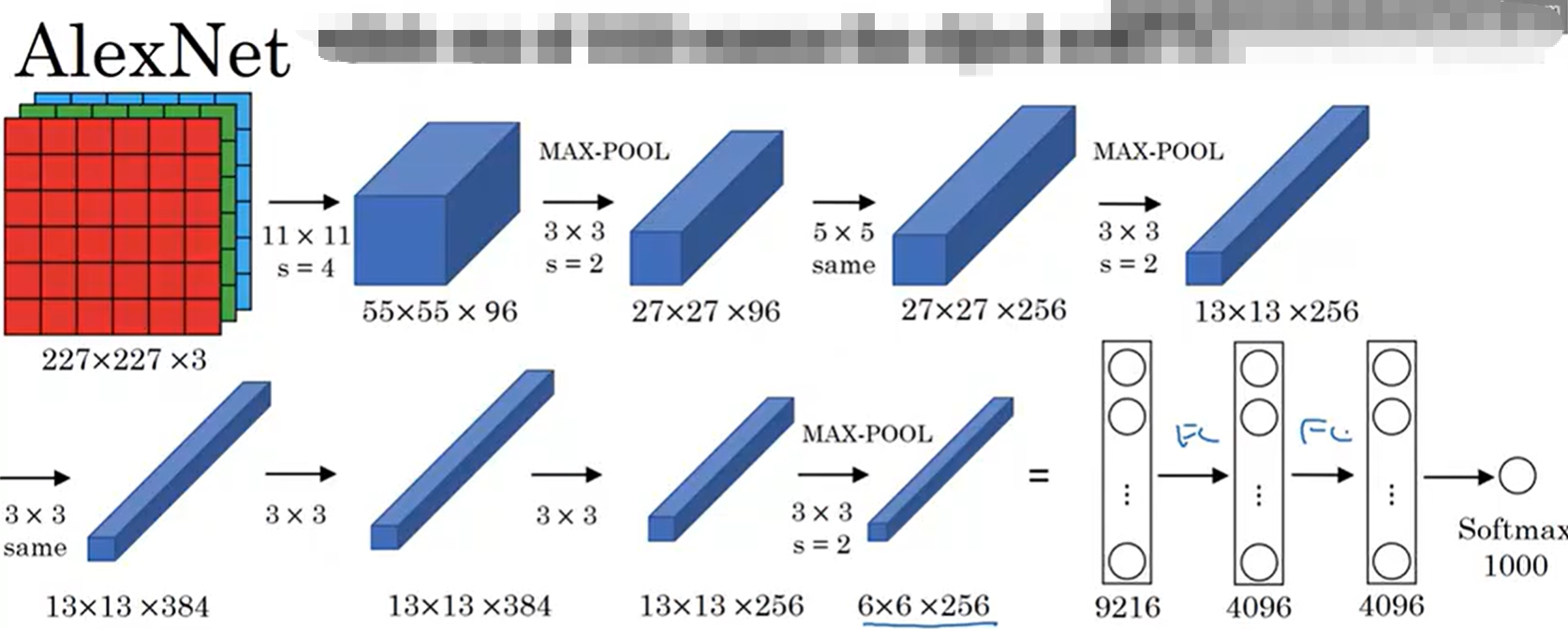
7.2.2 关键设计亮点
-
卷积层从LeNet的2层增加到5层,首次实现深层卷积架构,过滤器尺寸从大到小(11→5→3),先快速降维、再精细提取特征;
-
过滤器层数大幅提升(从96到384),通道数的增减遵循"先增后减"逻辑,既保证特征丰富性,又避免冗余;
-
引入11×11大尺寸卷积核(LeNet仅用5×5),快速压缩输入尺寸,减少计算量;同时引入Same Padding,避免边缘信息丢失;
-
池化层采用3×3(LeNet用2×2),步幅2,在降维的同时保留更多局部特征,搭配LRN和Dropout,解决深层网络的过拟合和梯度消失问题。
7.3 VGGNet:"深度为王",统一卷积架构(2014)
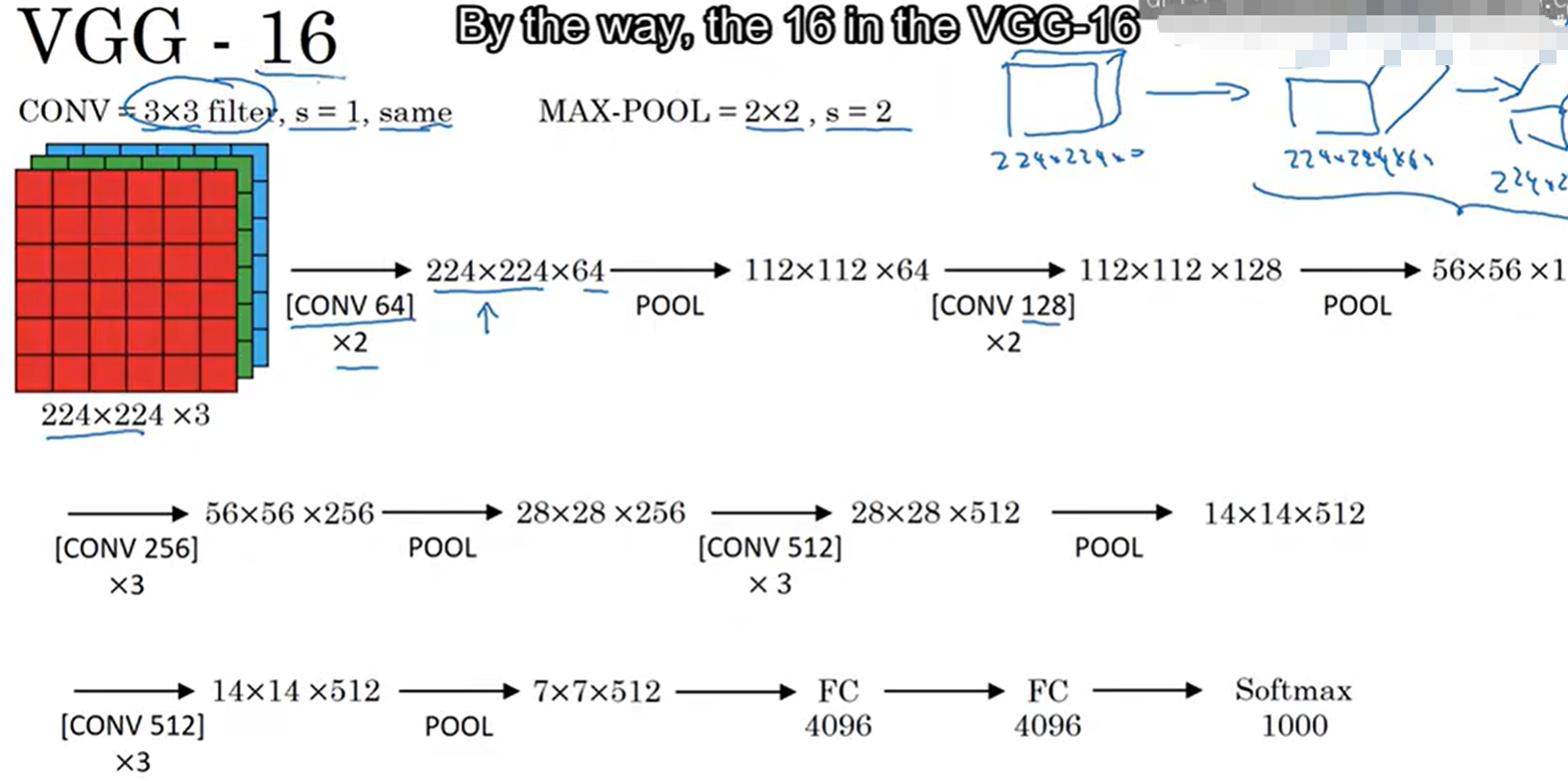
VGGNet是2014年ImageNet竞赛的亚军模型(正确率略低于GoogLeNet),其核心贡献是"统一卷积核尺寸 、提升网络深度 ",提出了"用多个3×3卷积核替代大尺寸卷积核 "的设计思路,让卷积架构更规整、更易迁移,同时进一步验证了"深度提升能提升模型性能"的核心逻辑。VGGNet有多个变体(VGG11、VGG13、VGG16、VGG19),数字代表网络总层数(卷积层+全连接层),其中VGG16(13个卷积层+3个全连接层)最常用。
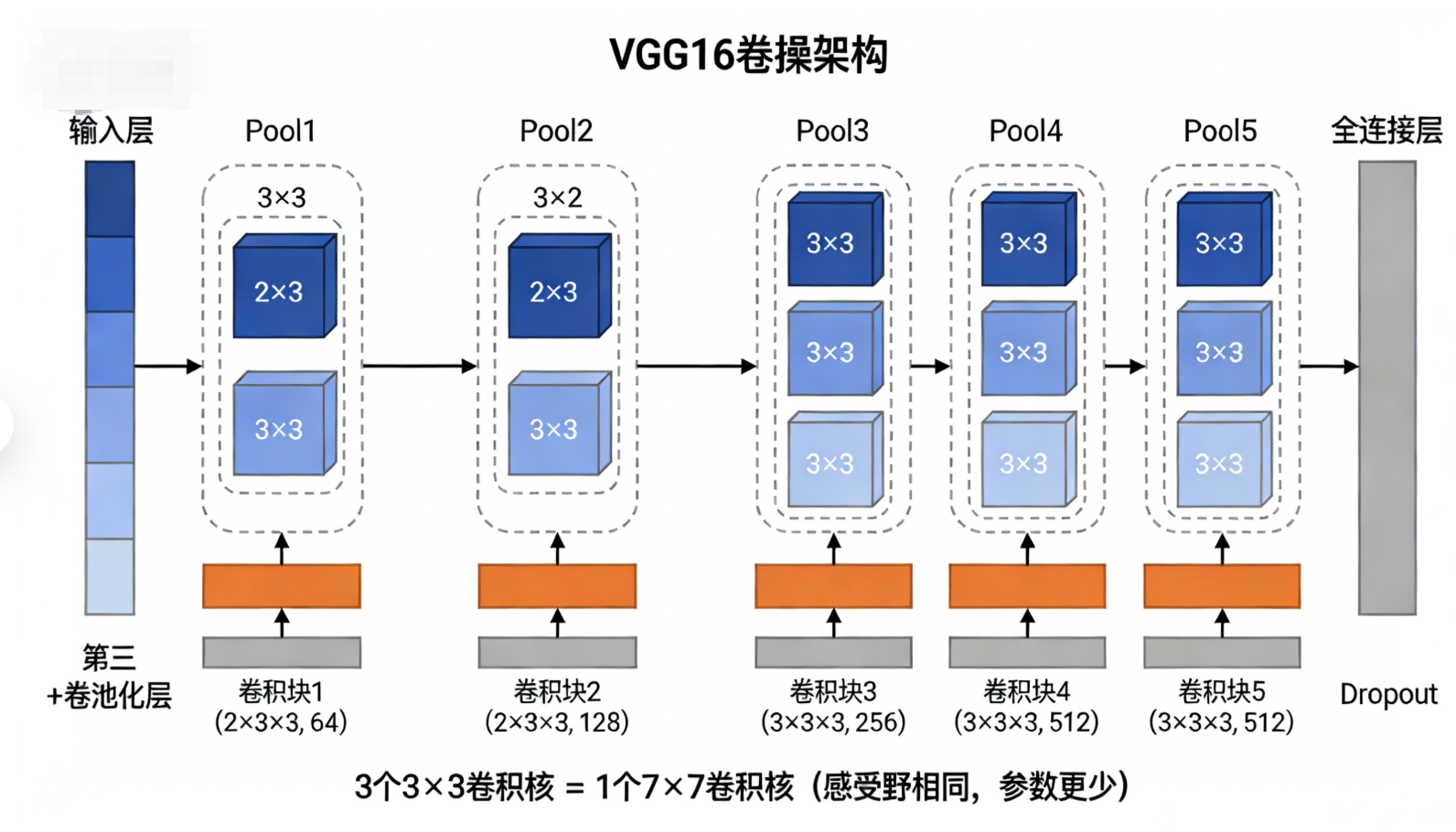
7.3.1 核心卷积架构拆解
以VGG16为例
-
输入层:224×224×3(RGB彩色图像,与AlexNet输入尺寸接近,轻微差异不影响核心架构);
-
第一卷积块(Conv1-1、Conv1-2):2个3×3卷积核,过滤器层数=64(每层都是64,通道数不变),步幅=1,填充=1(Same Padding),输出尺寸=224,最终输出224×224×64;
-
池化层1(Pool1):2×2最大池化,步幅=2,无填充,输出尺寸=112,最终输出112×112×64;
-
第二卷积块(Conv2-1、Conv2-2):2个3×3卷积核,过滤器层数=128(通道数翻倍,提升特征丰富性),步幅=1,填充=1,输出尺寸=112,最终输出112×112×128;
-
池化层2(Pool2):2×2最大池化,步幅=2,输出尺寸=56,最终输出56×56×128;
-
第三卷积块(Conv3-1、Conv3-2、Conv3-3):3个3×3卷积核,过滤器层数=256(通道数翻倍),步幅=1,填充=1,输出尺寸=56,最终输出56×56×256;
-
池化层3(Pool3):2×2最大池化,步幅=2,输出尺寸=28,最终输出28×28×256;
-
第四卷积块(Conv4-1、Conv4-2、Conv4-3):3个3×3卷积核,过滤器层数=512(通道数翻倍),步幅=1,填充=1,输出尺寸=28,最终输出28×28×512;
-
池化层4(Pool4):2×2最大池化,步幅=2,输出尺寸=14,最终输出14×14×512;
-
第五卷积块(Conv5-1、Conv5-2、Conv5-3):3个3×3卷积核,过滤器层数=512(通道数不变,进一步细化特征),步幅=1,填充=1,输出尺寸=14,最终输出14×14×512;
-
池化层5(Pool5):2×2最大池化,步幅=2,输出尺寸=7,最终输出7×7×512;
-
全连接层衔接:将7×7×512展平为25088维向量,连接3个全连接层(4096→4096→1000),输出1000维类别概率,加入Dropout防止过拟合。
7.3.2 关键设计亮点
-
统一使用3×3卷积核(AlexNet有11、5、3三种尺寸),这是VGGNet最核心的设计:用2个3×3卷积核替代1个5×5卷积核(感受野相同,都是5×5),用3个3×3卷积核替代1个7×7卷积核,既减少参数数量(3×3×3 < 7×7),又增加非线性表达(多一层卷积+激活);
-
卷积层以"块"为单位堆叠(2-2-3-3-3),每个块内通道数不变,块之间通道数翻倍(64→128→256→512→512),结构规整,易理解、易实现;
-
池化层统一使用2×2最大池化、步幅2,每经过一个池化层,特征图尺寸减半、通道数不变或翻倍,形成"卷积块提取特征→池化层降维"的固定节奏;
-
深度大幅提升(13个卷积层),但通过3×3小卷积核减少参数,避免参数爆炸,同时提升特征提取的精细度。
7.4 GoogLeNet:"创新模块",高效卷积架构(2014)
GoogLeNet是2014年ImageNet竞赛的冠军模型,其核心创新是引入了"inception模块",打破了LeNet、AlexNet、VGGNet"卷积层→池化层"的线性堆叠模式,通过"多尺度卷积并行"的方式,在同一层提取不同尺度的特征,大幅提升特征提取效率,同时减少参数数量,实现"高效深层"架构(总层数22层,卷积层数量远超VGG16,但参数仅为VGG16的1/12)。
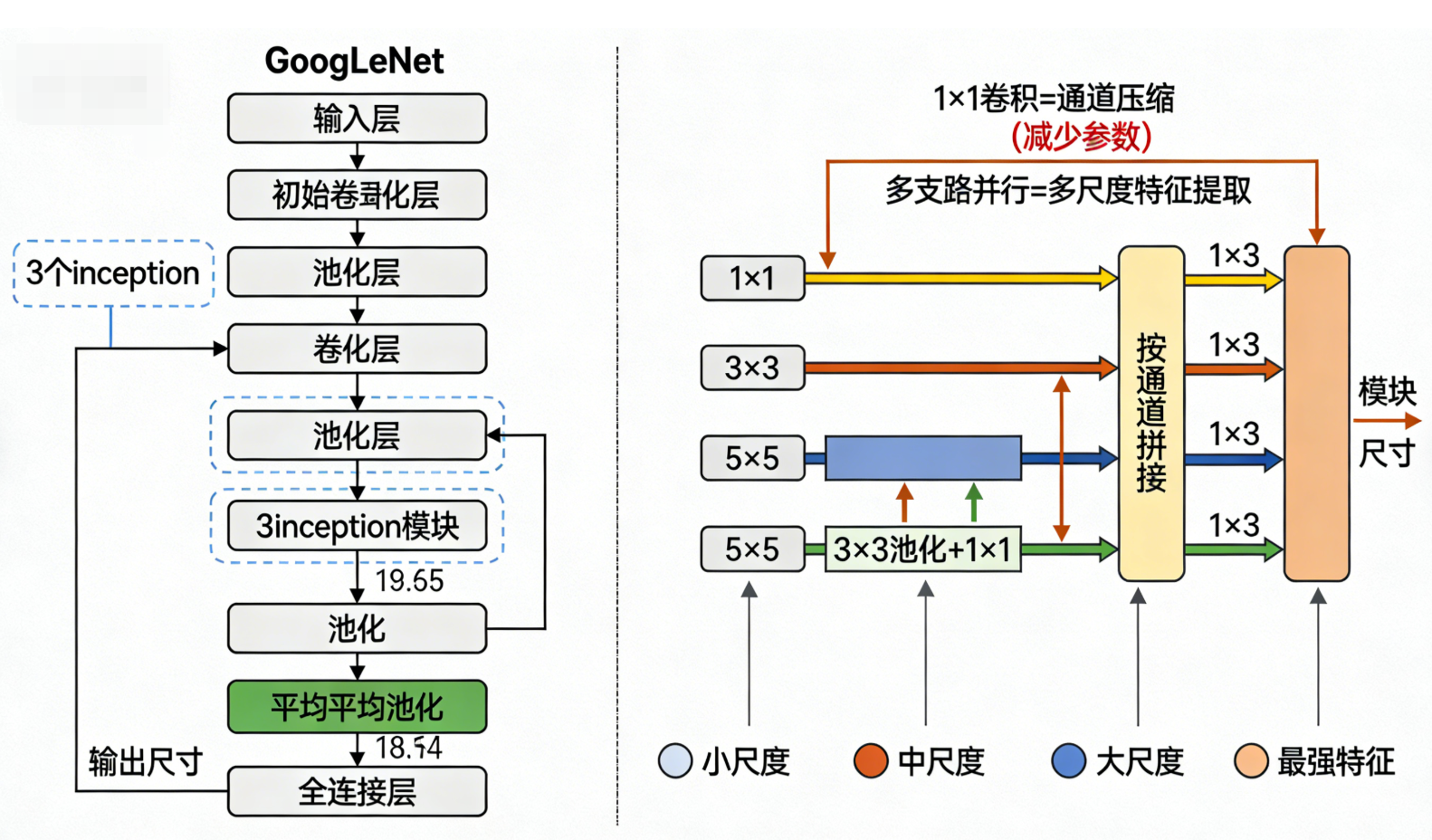
7.4.1 架构(inception模块和整体流程)
-
输入层:224×224×3(RGB彩色图像);
-
初始卷积层(Conv1):1个7×7卷积核,过滤器层数=64,步幅=2,填充=3(Same Padding),输出尺寸=112,最终输出112×112×64;
-
池化层1(Pool1):3×3最大池化,步幅=2,填充=1,输出尺寸=56,最终输出56×56×64;
-
卷积层2(Conv2):1个1×1卷积核(首次引入1×1卷积,用于通道压缩),过滤器层数=64,步幅=1,填充=0;接着1个3×3卷积核,过滤器层数=192,步幅=1,填充=1,输出尺寸=56,最终输出56×56×192;
-
池化层2(Pool2):3×3最大池化,步幅=2,填充=1,输出尺寸=28,最终输出28×28×192;
-
核心模块:inception模块(共9个,分为3组,每组3个,分别对应不同深度),这是GoogLeNet卷积架构的核心,每个inception模块内部包含4条并行的卷积/池化支路,同时提取不同尺度的特征:
-
支路1:1×1卷积核(过滤器层数按需配置),步幅=1,填充=0,提取小尺度特征,同时压缩通道;
-
支路2:1×1卷积核(通道压缩)→3×3卷积核(过滤器层数按需配置),步幅=1,填充=1,提取中尺度特征;
-
支路3:1×1卷积核(通道压缩)→5×5卷积核(过滤器层数按需配置),步幅=1,填充=2,提取大尺度特征;
-
支路4:3×3最大池化(步幅=1,填充=1)→1×1卷积核(通道压缩),提取局部最强特征;
-
模块输出:将4条支路的特征图按通道拼接(concat),输出通道数=4条支路通道数之和,尺寸保持不变(28→28→(支路1+支路2+支路3+支路4));
-
池化层穿插:每组inception模块后穿插1个3×3最大池化层(步幅=2,填充=1),实现特征降维,尺寸依次从28→14→7;
-
全局平均池化层(GAP):替代传统全连接层的前几层,将最后一个inception模块输出的7×7×1024特征图,通过全局平均池化(池化核7×7),输出1×1×1024的特征向量(大幅减少参数);
-
全连接层衔接:1个全连接层(1024→1000),输出1000维类别概率,加入Dropout防止过拟合。
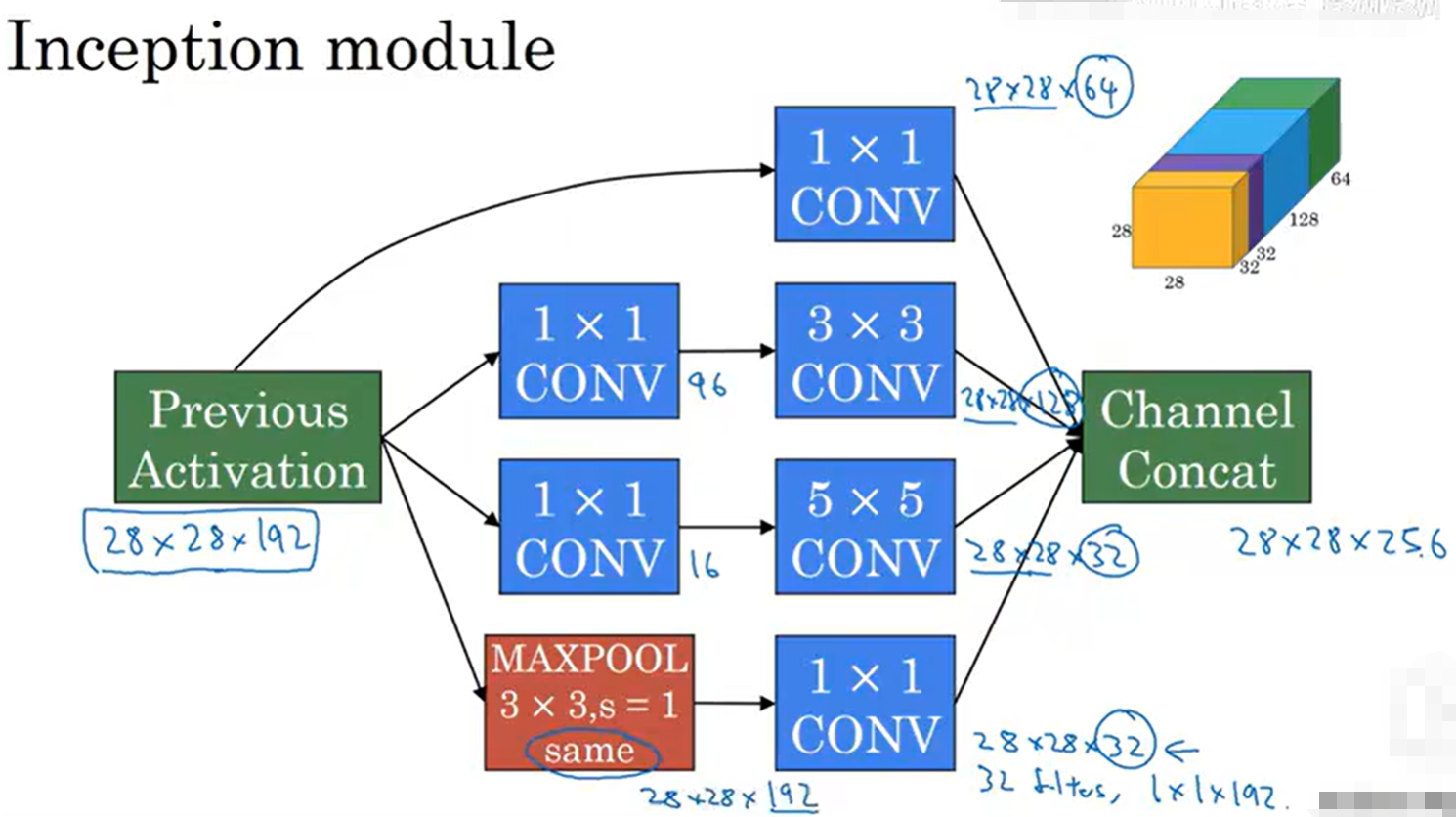
7.4.2 关键设计亮点
-
核心创新:inception模块,多尺度卷积并行,同时提取小、中、大尺度特征,无需人为设计卷积核尺寸和通道数,让模型自动学习最优特征尺度;
-
引入1×1卷积核:核心作用是"通道压缩",减少后续大尺寸卷积核的参数数量(如1×1卷积压缩通道后,3×3卷积的参数可减少一半以上);
-
用全局平均池化(GAP)替代部分全连接层,参数数量从VGG16的1.38亿减少到1100万,大幅降低过拟合风险;
-
非线性表达更强:inception模块内部的多支路卷积+激活,以及模块之间的堆叠,让模型能拟合更复杂的特征映射关系。
7.5 ResNet:"残差连接",超深层卷积架构(2015)
ResNet(残差网络)是2015年ImageNet竞赛的冠军模型,其核心创新是引入了"残差连接(Residual Connection)",彻底解决了深层网络的梯度消失问题,让网络深度可以突破100层、甚至1000层(经典变体:ResNet18、ResNet34、ResNet50、ResNet101、ResNet152,数字代表网络总层数)。ResNet的卷积架构基于VGGNet的"卷积块+池化层 "模式,新增残差连接,让特征可以"跨层流动" ,同时优化了卷积核配置,引入了"瓶颈块 (Bottleneck Block)"提升效率。
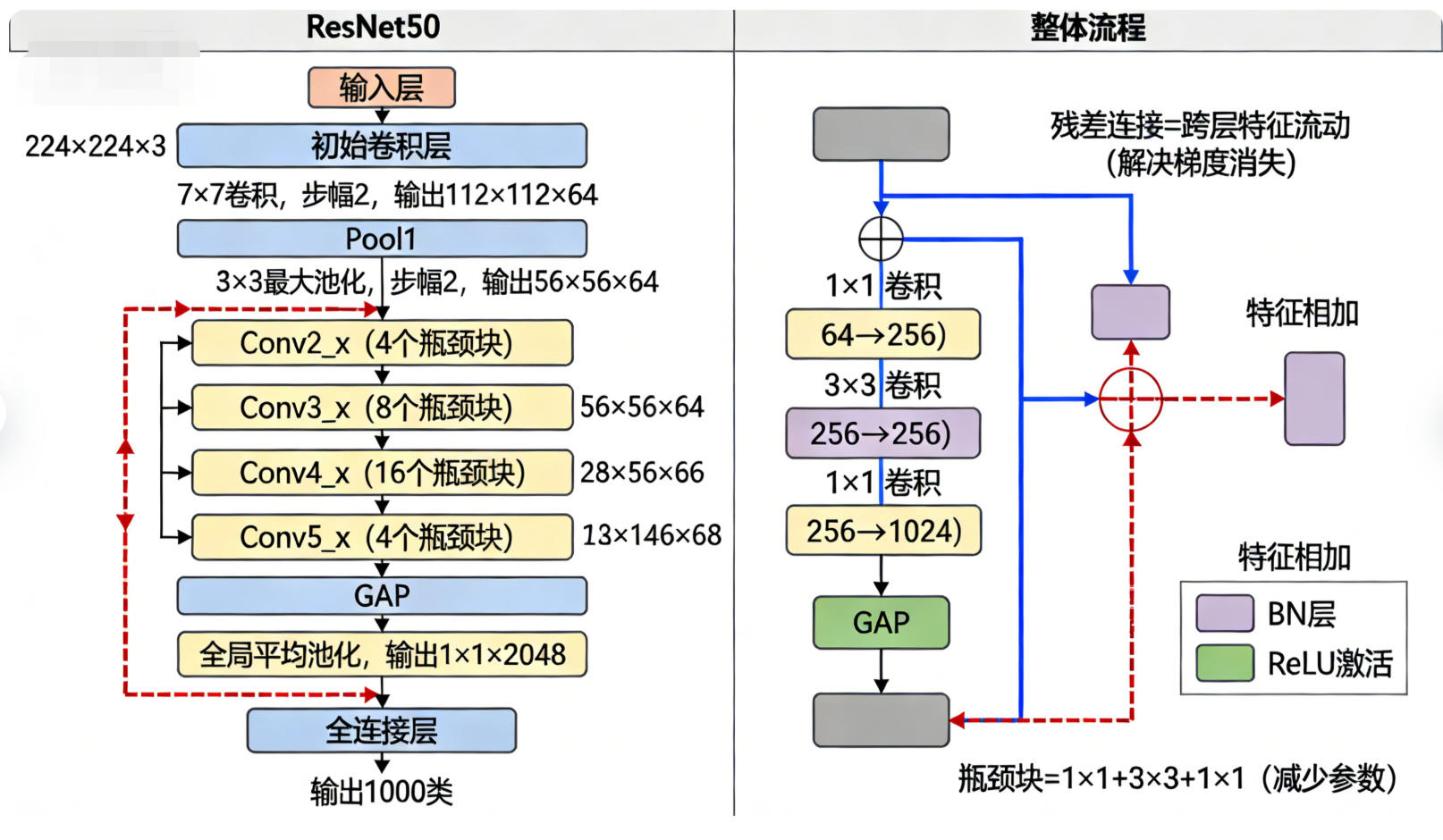
7.5.1核心卷积架构拆解
以ResNet50为例,16个残差块+1个全连接层,共50层:
-
输入层:224×224×3(RGB彩色图像);
-
初始卷积层(Conv1):1个7×7卷积核,过滤器层数=64,步幅=2,填充=3(Same Padding),输出尺寸=112,最终输出112×112×64;
-
池化层1(Pool1):3×3最大池化,步幅=2,填充=1,输出尺寸=56,最终输出56×56×64;
-
核心模块:残差块(共16个,分为4组,每组4个,分别对应Conv2_x、Conv3_x、Conv4_x、Conv5_x),ResNet50采用"瓶颈块(Bottleneck Block)",每个瓶颈块由3个卷积层组成,同时包含1条残差连接支路:
-
主支路(特征提取):1×1卷积核(过滤器层数=64,通道压缩)→3×3卷积核(过滤器层数=64,特征提取)→1×1卷积核(过滤器层数=256,通道恢复/提升),步幅按需设置(块之间步幅=2,块内部步幅=1),填充按需设置(保证尺寸匹配);
-
残差连接支路(跨层流动):若主支路输入输出尺寸、通道数一致,直接将输入特征图与主支路输出特征图相加(Y = 主支路输出 + 输入);若尺寸/通道数不一致,通过1×1卷积核调整尺寸和通道数,再相加;
-
激活函数:每个卷积层后加入BN(批量归一化)和ReLU激活,残差相加后再加入ReLU激活,进一步缓解梯度消失;
- 残差块分组与尺寸变化:
-
Conv2_x(4个瓶颈块):过滤器层数从64→256,步幅=1,输出尺寸=56,最终输出56×56×256;
-
Conv3_x(4个瓶颈块):过滤器层数从256→512,步幅=2,输出尺寸=28,最终输出28×28×512;
-
Conv4_x(4个瓶颈块):过滤器层数从512→1024,步幅=2,输出尺寸=14,最终输出14×14×1024;
-
Conv5_x(4个瓶颈块):过滤器层数从1024→2048,步幅=2,输出尺寸=7,最终输出7×7×2048;
-
全局平均池化层(GAP):将7×7×2048的特征图,通过全局平均池化(池化核7×7),输出1×1×2048的特征向量;
-
全连接层衔接:1个全连接层(2048→1000),输出1000维类别概率,无Dropout(BN层已能有效防止过拟合)。
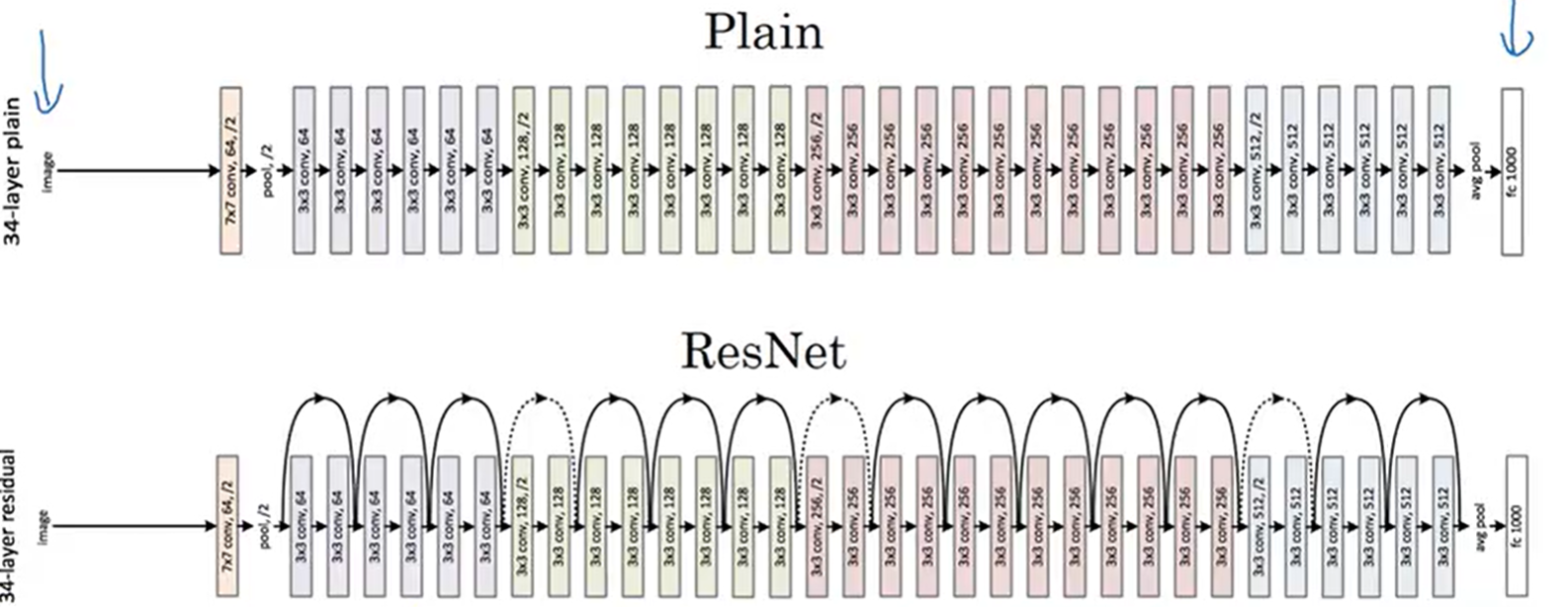
7.5.2关键设计亮点
-
核心创新:残差连接,让特征可以跨层流动,梯度可以通过残差支路反向传播,彻底解决深层网络的梯度消失问题,实现超深层架构(ResNet152有152层);
-
瓶颈块设计:用"1×1→3×3→1×1"的卷积组合,替代VGGNet的3×3卷积块,在保证感受野的同时,大幅减少参数数量,提升计算效率;
-
引入BN层:每个卷积层后加入BN层,替代LRN层,既缓解梯度消失,又加速模型训练,减少过拟合;
-
架构规整:基于VGGNet的"卷积块+池化层"模式,残差块分组清晰,通道数和尺寸变化有规律(每经过一组残差块,尺寸减半、通道数翻倍),易迁移、易扩展。
7.6 五大经典网络卷积架构总结
从LeNet到ResNet,CNN的卷积架构演变核心是"深度提升、效率优化、创新模块引入",三大核心层的搭配逻辑也在不断完善:
-
卷积层:从浅层(2层)到超深层(100+层),从大尺寸卷积核(11×11、7×7)到小尺寸(3×3),从单一尺度到多尺度(inception),从线性堆叠到残差跨层(ResNet),核心目标是"更高效、更精细地提取特征";
-
池化层:从2×2、3×3最大池化,到全局平均池化(GAP),从仅用于降维,到用于替代部分全连接层,核心目标是"在减少冗余的同时,保留关键特征,提升模型鲁棒性";
-
全连接层:从多层堆叠(LeNet、AlexNet、VGGNet),到用GAP+单层全连接(GoogLeNet、ResNet),核心目标是"减少参数数量,避免过拟合,同时实现高效分类"。
七、总结
卷积层、池化层和全连接层是卷积神经网络的三大核心构建模块,各自承担着特征提取 、特征降维 和特征分类的关键任务,三者的协同工作让CNN能够高效处理图像等空间数据。卷积层通过局部卷积和权值共享,在保留空间结构的前提下提取局部特征,解决了参数爆炸的问题;池化层通过局部下采样,在降维的同时提升特征的鲁棒性,让模型对微小变化不敏感;全连接层通过特征展平和矩阵乘法,将高维特征映射为类别概率,实现对图像的最终分类。
从理论到工程实现,三层的设计都围绕着**"提取有效特征、降低模型复杂度、提升分类准确率"**的核心目标,而这也是深度学习的本质。理解这三层的原理和协同关系,是掌握CNN乃至更复杂的深度学习模型(如ResNet、YOLO、Transformer)的基础,更是从事计算机视觉相关工作的必备知识。
随着深度学习的发展,三层也在不断优化(如卷积层的分组卷积、深度可分离卷积,池化层的自适应池化,全连接层的全局池化替代),但核心思想始终未变------从数据中提取有效特征,实现对数据的理解和预测。