有一个变化,正在悄悄发生。
它没有体现在排行榜上,也没有写在 SOTA 的红字里,但你一旦意识到,就很难再忽视。
在越来越多系统里,计算机视觉不再是"核心模型",而是一个被调用的感知模块。
你会发现论文标题正在变:
从 A Better Detector 变成 Vision-enabled Agent Perception for Embodied AI
视觉模型不再被要求"赢下 mAP",而是被问三个更现实的问题:
- 它能不能被大模型稳定调用?
- 它能不能嵌进任务链里长期工作?
- 它能不能把自己的判断讲清楚?
这不是一句修辞,这是整个研究范式在挪位。
视觉不再"单飞",而是被编入系统
过去十年,计算机视觉的叙事非常清晰:
数据集 → 模型 → 指标 → 排行榜
谁的 backbone 更强、谁的 head 更精巧、谁能多抠 0.3 个点,
谁就是赢家。
但今天你会发现,在很多真实系统里,视觉模型的角色正在发生变化:
它不再是"做完任务就下线的主角",而是一个长期在线、随时被调用的感知器官。
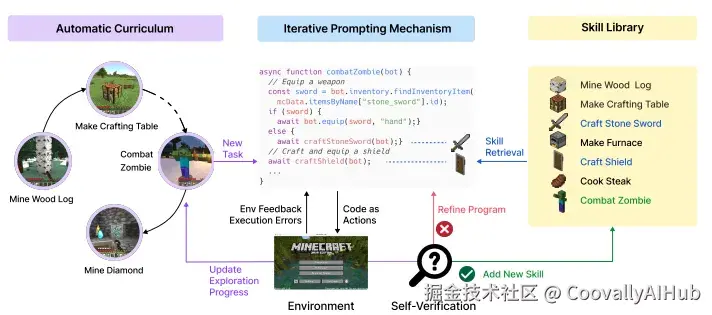
在 Agent 系统中,视觉往往只是这样一句话里的一个函数:
"先看一下环境,再决定下一步行动。"
典型变化:
- 不再追求极限精度,而是稳定、可控、可复用
- 不再输出一堆 logits,而是可被语言模型理解的结构化信息
- 不再只对 benchmark 负责,而是要对任务链的失败率负责
mAP 还重要,但它已经不是"终点"
这句话可能有点刺耳,但它是真的:
mAP 正在从"终极目标",变成"最低入场券"。
因为在 Agent 体系里,一个模型再准,如果它:
- 输出不稳定
- 无法解释
- 在长链任务中偶尔"发疯"
那它就是系统风险源。
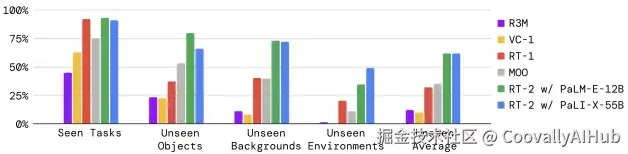
你会看到越来越多论文,刻意回避传统指标,转而报告:
- 任务成功率(Task Success Rate)
- 长程执行稳定性(Long-horizon Stability)
- 多模态协作表现(Vision ↔ Language)
这不是指标退化,而是评估对象换了:
以前评估的是:
"你看得准不准?"
现在评估的是:
"系统因为你,能不能活下去?"
视觉模型开始"为语言模型服务"
一个越来越明显的事实是:
视觉模型,正在为 LLM 打工。
这不是贬义,而是现实。
在多模态系统里,LLM 负责:
- 规划
- 推理
- 决策
- 解释
而视觉模型负责:
- 提供可靠的感知证据
- 把"世界状态"翻译成可讨论的信息
于是,一个新的能力变得极其重要:
视觉模型,能不能把自己"看到的东西"说清楚?
这也是为什么:
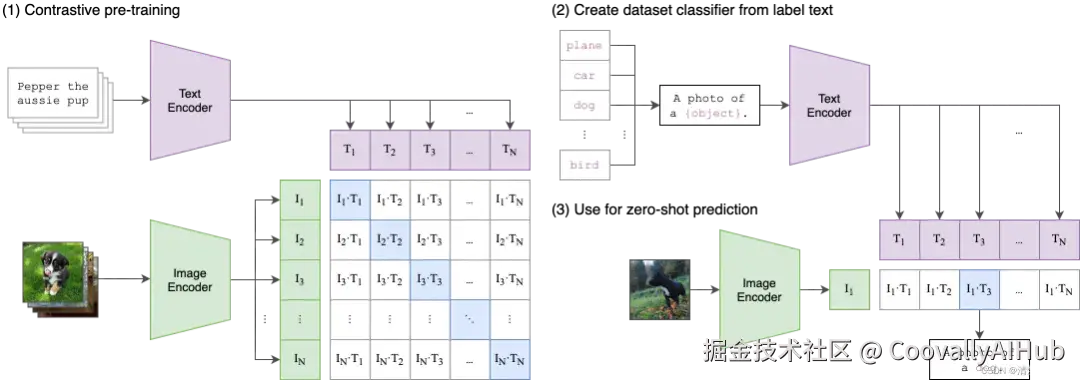
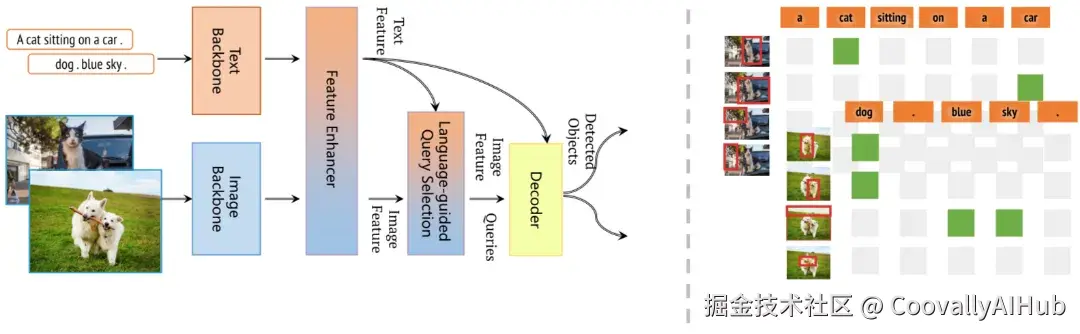
- CLIP 类模型仍然重要
- grounding、region-level semantics 被反复强调
- perception 不再是 end-to-end black box
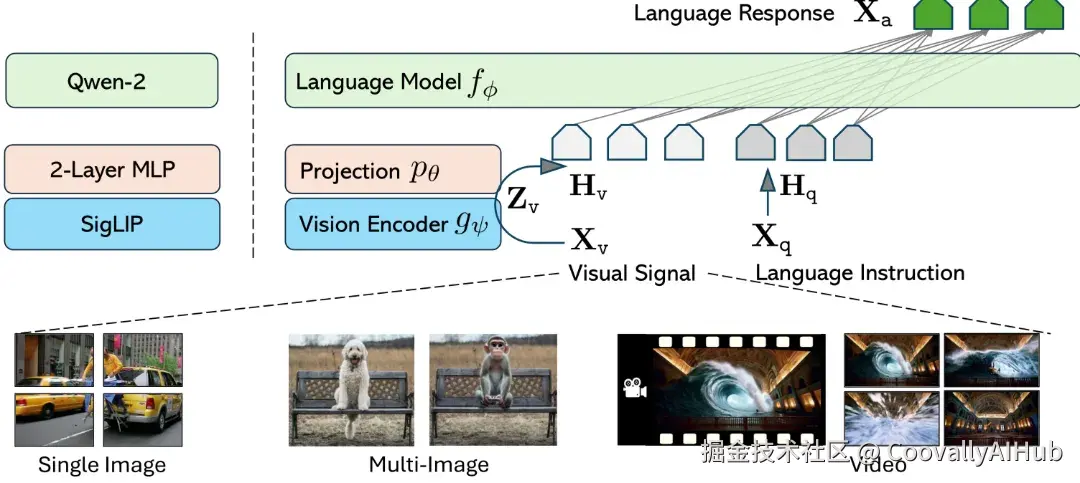
那我们这些"还在调 backbone 的人",该怎么办?
这是很多人心里没说出口的焦虑:
"我还在调 neck、刷 loss,世界已经在做 Agent 了?"
但冷静一点,你会发现一个更现实的结论:
Agent 不会淘汰视觉, 但会淘汰"只会刷指标的视觉"。
Agent 时代,对视觉研究者的要求反而更高了:
- 你是否理解模型在系统中的角色?
- 你是否关心失败样本会如何传导?
- 你是否能设计可解释、可控制的感知输出?
未来更值钱的,不是"再快 0.2",
而是:
一个"不会拖后腿"的视觉模块。
这不是终结,而是一次"位置调整"
如果一定要给这个趋势一个判断,那它更像是:
计算机视觉,从舞台中央,走进了系统核心。
不再被单独审视,而是作为智能系统的一部分被长期考验。
它失去了"单项冠军"的光环,但换来了真正决定系统成败的地位。
如果你现在还在做视觉,这不是坏消息。
这是一次提醒:
别只问模型准不准,开始问------系统为什么需要它。