总结:使用全局方法(但是实现上使用半全局近似)计算权重,再使用局部方法进行在窗口内加权聚合。
文中的"全图引导滤波"可以看作是对何凯明引导滤波的一种非局部(Non-local)效率进化版。它借鉴了"引导"的思想(利用参考图信息指导平滑过程),但舍弃了局部线性的数学框架,改用递归的权重传播机制实现了更快的速度和更广的支撑范围。(其实和引导滤波关系不大)
文章目录
- 摘要
- 引言
- 2提出的滤波方法
-
- 3在局部立体匹配中的应用
- 4实验结果
- [5. 结论](#5. 结论)
- 附录
-
-
- [1. 中间状态的定义 (公式 4)](#1. 中间状态的定义 (公式 4))
- [2. 递归加速方案 (公式 5)](#2. 递归加速方案 (公式 5))
- [3. 最终组合 (公式 6)](#3. 最终组合 (公式 6))
- 总结
-
摘要
提出了一种新的全图像引导滤波 方法。与许多现有的邻域滤波器不同,所提出的滤波方法使用了所有的输入元素 。此外,还提出了一种称为权重传播的新方案来计算支持权重。它满足了边缘保持和低复杂度的要求。将其应用于局部立体匹配框架中的代价空间滤波中。采用本文提出的滤波方法的算法是目前Middlebury平台上速度和精度最好的局部算法之一。
引言
准确度和速度是立体匹配算法的两个主要性能指标。虽然全局算法通常会生成精确的视差图,但由于不可避免的迭代而相对缓慢,并且不能很好地扩展到高分辨率图像 。另一方面,许多现有的快速实现都是局部算法。局部立体匹配算法中最重要的步骤之一是代价聚合** 1 。它通常通过在一个支持窗口内对(加权)匹配代价进行求和来去除相似性度量过程中可能存在的噪声的影响。如果我们将和除以归一化常数,它恰好是一种邻域滤波方法**。 在本文中,我们从代价空间过滤的的角度来解决成本聚合问题。
可以使用具有固定大小卷积核的滤波器,例如,均匀的(盒子滤波器)或高斯的。然而,这些方法不能很好地保持物体的边界,导致生成的视差图边缘不饱满。一个更好的选择是使用边缘保持滤波器 。最初的自适应权重方法 2 使用双边滤波器 3 来保持视差边界。一个缺点是,双边滤波器暴力实现的复杂度依赖于核窗口的大小。尽管一些快速的实现 4 - 8 ,已经被重新提出,但是他们都是近似的方法,在降低复杂度的同时也降低了视差图质量。在 9 中,作者提出用测地距离来计算权重。尽管它在对象边界上表现更好,但复杂度仍然相对较高。利用多尺度方法提出了一个中间解 10 。在每个尺度中使用较小的支持窗口。在 11 中,作者使用迭代测地线扩散来得到更好的结果。最近提出的引导图像滤波器 12 同时满足边缘保持和线性复杂度两个要求。它使用局部线性模型。使用这种滤波器的局部立体匹配算法目前报告了最好的结果 13 。虽然它声明了1的复杂性,但如果使用彩色引导图像,则需要大约22个盒子滤波过程才能完成整个引导滤波方法。 此外,现有邻域滤波器的一个共同缺点是,支持窗口是固定大小的。这对它们在大的低纹理区域的性能造成了很大的影响。希尔施米勒 14 提出了从多个方向进行路径优化来快速逼近全局代价函数,但并不是所有的像素都被利用。在 15 中,作者使用两遍范式来执行有效的聚合,但性能受限于平滑核设计。最近,Yang 16 提出了一个非局部的解决方案,代价聚合仍然被限制在一个最小生成树上。
本文提出了一种新的滤波算法。每个像素对滤波方法都有贡献。这保证了滤波方法在同一对象中使用尽可能多的像素。采用本文提出的权重传播方案计算权重。由于我们使用从整个参考图像中计算出的权重来指导costvolume的滤波,我们将所提出的滤波算法称为全图像引导滤波。它有一个确切的实现。每个像素所需的平均运算为4次乘法和8次加法,速度极快。通过将其应用到局部立体匹配算法中,可以取得具有竞争力的结果。所提出的全图像引导滤波器详见第二节。 第三节将其应用到我们的局部立体匹配框架中。我们在第四节中报告了实验结果并给出了一些讨论,在第五节中总结了这篇信。
2提出的滤波方法
A. 滤波器建模
我们首先将待滤波的信号/图像表示为 C C C,引导图像 表示为 I I I,滤波器输出表示为 C ′ C' C′ 。那么像素 i i i 的输出值 C i ′ C'_i Ci′ 定义为:
C i ′ = 1 N i ∑ j ∈ Ω W i , j ( I ) C j ( 1 ) C'i = \frac{1}{N_i} \sum{j \in \Omega} W_{i,j}(I)C_j \quad (1) Ci′=Ni1j∈Ω∑Wi,j(I)Cj(1)
其中, N i = ∑ j W i , j ( I ) N_i = \sum_j W_{i,j}(I) Ni=∑jWi,j(I) 是归一化常数, W i , j ( I ) W_{i,j}(I) Wi,j(I) 是取决于引导图像 I I I 的像素对 ( i , j ) (i, j) (i,j) 的权重(引导图像可以是灰度图或彩色图 ), Ω \Omega Ω 代表包含输入信号/图像所有元素索引的集合 。
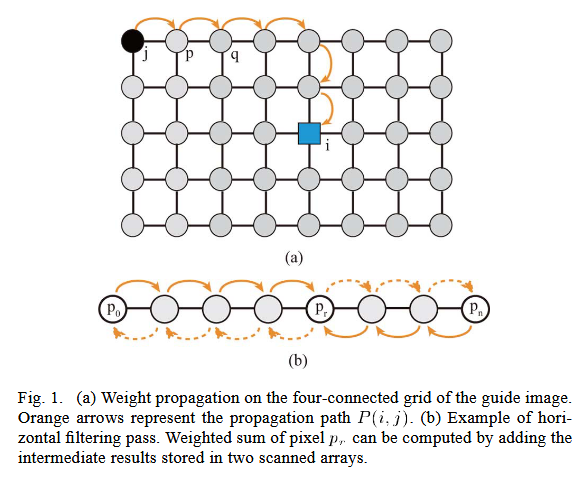
为了计算每个像素对 ( i , j ) (i, j) (i,j) 的权重,我们提出了一种称为权重传播的新方案 。在描述其工作原理之前,我们先基于引导图像构建一个四连通网格 。每个像素都表现为该网格上的一个节点,如图 1(a) 所示 。像素对 (i, j)的权重计算如下:
W i , j ( I ) = ∏ ( p , q ) ∈ P i , j T p , q ( I ) ( 2 ) W_{i,j}(I) = \prod_{(p,q) \in P_{i,j}} T_{p,q}(I) \quad (2) Wi,j(I)=(p,q)∈Pi,j∏Tp,q(I)(2)
其中 ( p , q ) ∈ P i , j (p,q) \in P_{i,j} (p,q)∈Pi,j 是连接节点对 ( i , j ) 的路径 P i , j 上的相邻节点, T p , q ( I ) i, j) 的路径 P_{i,j} 上的相邻节点,T_{p,q}(I) i,j)的路径Pi,j上的相邻节点,Tp,q(I) 是定义两个相邻节点间权重传播能力的传播函数 。确切地说,传播函数定义为:
T p , q ( I ) = exp ( − ∥ I p − I q ∥ σ ) ( 3 ) T_{p,q}(I) = \exp\left(-\frac{\|I_p - I_q\|}{\sigma}\right) \quad (3) Tp,q(I)=exp(−σ∥Ip−Iq∥)(3)
其中,两个相邻像素 ( p , q ) (p, q) (p,q) 之间的像素相似度通过 RGB 颜色空间中的欧几里得距离来衡量, σ \sigma σ 是一个调整滤波平滑程度的常数参数 。
连接节点对 ( i , j ) (i, j) (i,j) 的路径 P i , j P_{i,j} Pi,j 有无数条 。最佳路径应该是具有最小传播权重的路径 。但其计算复杂度太高,无法实现高效应用 。我们选择一种水平优先策略 的路径:对于每个终点节点 j j j,权重初始化为 1;权重值首先沿水平方向向目标像素 i i i 传播 ;当路径到达像素 i i i 所在的列后,再沿垂直方向传播直到到达目标节点 。我们将此过程称为权重传播,如图 1(a) 所示 。
B. O ( 1 ) O(1) O(1) 时间精确实现
为每一对节点计算权重是低效的,我们使用两轮模型来实现所提滤波方法 。滤波处理首先在水平方向的独立行中进行 。然后,使用相同的方法在独立的列中处理中间值 。
以水平传播为例,对于行中的元素 r r r,加权值的中间和由三项组成:来自左侧和右侧的加权和加上其自身的值 C r C_r Cr,可以表示为:
C r i m e d = ∑ i = 0 r − 1 W i , r ( I ) C i + ∑ i = r + 1 n W i , r ( I ) C i + C r C_r^{imed} = \sum_{i=0}^{r-1} W_{i,r}(I)C_i + \sum_{i=r+1}^n W_{i,r}(I)C_i + C_r Crimed=i=0∑r−1Wi,r(I)Ci+i=r+1∑nWi,r(I)Ci+Cr
= ∑ i = 0 r − 1 ( ∏ u = i + 1 r T u − , u ( I ) ) C i + ∑ i = r + 1 n ( ∏ u = r i − 1 T u , u + ( I ) ) C i + C r ( 4 ) = \sum_{i=0}^{r-1} \left( \prod_{u=i+1}^r T_{u^-,u}(I) \right) C_i + \sum_{i=r+1}^n \left( \prod_{u=r}^{i-1} T_{u,u^+}(I) \right) C_i + C_r \quad (4) =i=0∑r−1(u=i+1∏rTu−,u(I))Ci+i=r+1∑n(u=r∏i−1Tu,u+(I))Ci+Cr(4)
此处, u − u^- u− 是 u u u 的左邻节点, u + u^+ u+ 代表右邻节点 。公式 (4) 的计算可以通过使用两轮扫描范式进一步加速,这种范式在可以进行对称计算时常用 。一轮扫描过程从左到右进行,另一轮反向进行 。中间结果存储在两个临时数组中。扫描过程是对输入数组进行加权累积和的顺序计算,可表示为:
A r L = C r + ∑ i = 0 r − 1 ( ∏ u = i + 1 r T u − , u ( I ) ) C i A_r^L = C_r + \sum_{i=0}^{r-1} \left( \prod_{u=i+1}^r T_{u^-,u}(I) \right) C_i ArL=Cr+i=0∑r−1(u=i+1∏rTu−,u(I))Ci
= C r + T r − 1 , r ( C r − 1 + T r − 2 , r − 1 ( C r − 2 + ⋯ + T 0 , 1 ( C 0 ) ... ) ) = C_r + T_{r-1,r}(C_{r-1} + T_{r-2,r-1}(C_{r-2} + \dots + T_{0,1}(C_0)\dots)) =Cr+Tr−1,r(Cr−1+Tr−2,r−1(Cr−2+⋯+T0,1(C0)...))
= C r + T r − 1 , r A r − 1 L ( 5 ) = C_r + T_{r-1,r} A_{r-1}^L \quad (5) =Cr+Tr−1,rAr−1L(5)
其中 A L A^L AL 代表存储从左到右计算的加权累积和的临时数组 。设 A R A^R AR 为存储反向计算加权和的数组,(4) 式可以简单地通过以下方程计算:
C r i m e d = A r L + A r R − C r ( 6 ) C_r^{imed} = A_r^L + A_r^R - C_r \quad (6) Crimed=ArL+ArR−Cr(6)
这大大降低了复杂度。在水平过程中,每个元素平均只需要两次乘法和四次加法 。水平传播后,在独立列的中间结果上执行垂直传播 。可以使用与水平传播相同的操作 。至此,垂直传播后,每个元素平均需要四次乘法和八次加法 。
考虑到 (1) 式中的归一化项 N i N_i Ni,每个像素所需的操作将翻倍 。尽管如此,全图引导滤波的计算复杂度精确为 O ( 1 ) O(1) O(1) 。在诸如局部立体匹配问题等某些应用中,可以省略归一化项 N i N_i Ni 以进一步加速算法 。
C. 与邻域滤波器的比较
所提全图引导滤波器相较于现有邻域滤波器的主要优势在于,滤波过程由所有可用像素支持 。它确保了滤波器将尽可能多地利用相关的像素 。这一特性对于大面积无纹理区域的代价滤波非常重要 。通过权重传播计算出合理的支撑权重,从而保持锐利的物体边缘 。

这些优势可以通过图 2 的支撑权重示例来说明 。我们将所提方法与双边滤波(一种典型的邻域边缘保持滤波器)计算的支撑权重进行了比较 。图 2(a) 显示了无纹理区域内中心像素对应的支撑像素权重 。受限于固定核尺寸,双边滤波的支撑像素数量有限 。而在所提方法中,与中心像素处于同一区域的所有像素都对滤波过程有所贡献 。此外,锐利的物体边缘得到了很好的保持,图 2(b)© 提供了更多此类示例 。
在计算支撑权重时,许多邻域滤波器严重依赖相似性项,即衡量与中心像素的颜色差异 。因此,支撑窗口内的背景像素很容易被分配高权重 。这不利于保持锐利边缘 。如图 2 第二行所示,许多属于不同物体的像素被分配了较大的权重 。为了克服这一缺陷,已有研究通过增加衡量立体图像间像素相似性的权重项 。而我们仅根据引导图像计算支撑权重 。权重值从外围向中心像素传播 。不同区域的像素将被分配极低的权重,这些像素的影响在滤波过程中可以忽略不计 。图 2(d)-(g) 显示了某些选定区域的支撑权重 。
尽管有上述优点,所提滤波器的支撑权重计算严重依赖于引导图像的质量 。噪声较多的引导图像会在一定程度上降低滤波结果的质量 。
3在局部立体匹配中的应用
在一般的局部立体匹配算法中,通常执行四个步骤来生成最终的稠密视差图 。它们分别是:代价计算、代价体滤波、胜者为王(WTA)视差选择以及后处理 。
在代价计算阶段,需要计算代价体 C C C 。它是一个三维数组,存储了每个像素在所有可能候选视差下的匹配代价 。令 C i , d C_{i,d} Ci,d 代表像素 i = ( x , y ) i=(x,y) i=(x,y) 被分配视差 d d d 时的代价,我们通过下式计算对应代价:
C i , d = ( 1 − α ) ⋅ min ( C i , d B T , τ 1 ) + α ⋅ min ( C i , d G D , τ 2 ) ( 7 ) C_{i,d} = (1 - \alpha) \cdot \min(C_{i,d}^{BT}, \tau_1) + \alpha \cdot \min(C_{i,d}^{GD}, \tau_2) \quad (7) Ci,d=(1−α)⋅min(Ci,dBT,τ1)+α⋅min(Ci,dGD,τ2)(7)
其中 α \alpha α 是平衡两个子代价项的参数, τ 1 \tau_1 τ1 和 τ 2 \tau_2 τ2 是截断值 。 C B T C^{BT} CBT 表示 BT 度量 18 的代价, C G D C^{GD} CGD 是立体图像对梯度绝对差之和 。
然后,对于每个可能的候选视差 d d d,利用所提出的全图引导滤波 (也就是上一节的内容)计算第 d d d 个代价切片 C d C_d Cd 的滤波后代价体 C d ′ C'_d Cd′ 。在代价体滤波之后,通过 WTA 策略选择视差 D i D_i Di:
D i = arg min d ∈ R C i , d ′ ( 8 ) D_i = \arg \min_{d \in R} C'_{i,d} \quad (8) Di=argd∈RminCi,d′(8)
其中 R R R 是候选视差值的范围 。遮挡区域在后处理步骤中进行处理 。在我们的算法中,首先通过交叉检查(cross checking)检测遮挡和误匹配像素 。然后,使用同一扫描线上最近的非遮挡像素的最低视差值进行填充,并应用加权中值滤波来消除可能出现的条纹效应(streak-line effects) 。
4实验结果
性能测试在 Middlebury 立体基准测试集上进行 。平滑调整参数是可选的,且仅取决于引导图像 。对于所有四组基准测试立体图像对,该参数均被设置为常数值 σ = 0.08 \sigma=0.08 σ=0.08 。生成的视差结果及其对应的误差图绘制在图 3 中 。我们可以观察到,在无需图像分割辅助的情况下,视差图中的边缘得到了很好的保持 。更重要的是,大面积低纹理区域的视差也得到了正确恢复,这对于大多数局部立体匹配算法来说是难以实现的 。然而,在 Teddy 数据集的粉色泰迪熊附近仍存在一些错误,这是由于细小的重复纹理导致的 。

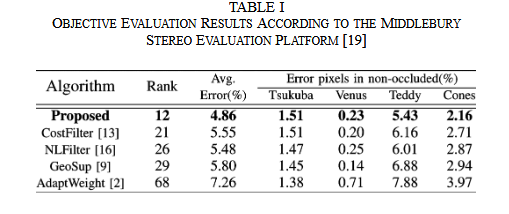
在提交时,我们的立体匹配算法在所有 136 种提交至立体评估平台的算法中排名第 12 位 。几乎所有表现更好的算法都使用了全局优化和/或分割技术 。平均误差可以降低到 4.06%,但通常需要几分钟才能获得此类结果 。我们的算法以极低的复杂度实现了具有竞争力的结果 。此外,在所有提交的方法中,我们的立体匹配算法在 Cones 数据集的非遮挡区域和不连续区域表现最佳 。
根据评估平台的数据,考虑到平均性能,所提方法目前是最好的局部立体匹配算法之一 。表 I 总结了定量结果 。对比结果表明,所提方法明显优于其他局部方法 。
我们在配置为 Core Duo 3.16 GHz CPU 和 2 GB 800 MHz RAM 的台式机上测试了该方法 。测试中未利用任何并行技术 。在 Middlebury 基准数据集上进行代价体滤波的平均运行时间约为 68 ms 。它的运行速度比非局部代价聚合方案 16 快 2.76 倍(188 ms),比使用引导图像滤波的方法 13 快 27 倍(1850 ms) 。
5. 结论
本文提出了一种新型的引导滤波算法 。输入信号中的所有元素都对滤波过程有所贡献 。新颖的权重传播方法确保了支撑元素被分配合理的权重,同时满足了边缘保持和低复杂度的要求 。我们将该方法应用于代价体滤波 。实验结果表明,在速度和准确度两方面,所提算法在 Middlebury 基准测试中均优于所有局部方法 。
附录
根据提供的文献资料,公式 (4) 到公式 (6) 展示了如何将复杂的全局加权求和简化为线性时间复杂度的递归计算过程。
以下是基于原文内容的推导与原理解析:
1. 中间状态的定义 (公式 4)
公式 (4) 定义了在水平扫描通程中,目标像素 r r r 接收到的所有加权贡献。其核心思想是将一行中的像素分为左侧、右侧和像素本身 。
C r i m e d = ∑ i = 0 r − 1 W i , r ( I ) C i + ∑ i = r + 1 n W i , r ( I ) C i + C r C_{r}^{imed}=\sum_{i=0}^{r-1}W_{i,r}(I)C_{i}+\sum_{i=r+1}^{n}W_{i,r}(I)C_{i}+C_{r} Crimed=i=0∑r−1Wi,r(I)Ci+i=r+1∑nWi,r(I)Ci+Cr
通过**权重传播(Weight Propagation)**模型,像素 i i i 到 r r r 的权重 W i , r W_{i,r} Wi,r 被定义为路径上相邻节点传播函数 T T T 的连乘积 :
- 左侧贡献推导 :对于 i < r i < r i<r,权重 W i , r = ∏ u = i + 1 r T u − , u W_{i,r} = \prod_{u=i+1}^{r}T_{u^{-},u} Wi,r=∏u=i+1rTu−,u 。
- 右侧贡献推导 :对于 i > r i > r i>r,权重 W i , r = ∏ u = r i − 1 T u , u + W_{i,r} = \prod_{u=r}^{i-1}T_{u,u^{+}} Wi,r=∏u=ri−1Tu,u+ 。
因此,公式 (4) 展开为 :
C r i m e d = ∑ i = 0 r − 1 ( ∏ u = i + 1 r T u − , u ( I ) ) C i + ∑ i = r + 1 n ( ∏ u = r i − 1 T u , u + ( I ) ) C i + C r C_{r}^{imed}=\sum_{i=0}^{r-1}\left(\prod_{u=i+1}^{r}T_{u^{-},u}(I)\right)C_{i} + \sum_{i=r+1}^{n}\left(\prod_{u=r}^{i-1}T_{u,u^{+}(I)}\right)C_{i} + C_{r} Crimed=i=0∑r−1(u=i+1∏rTu−,u(I))Ci+i=r+1∑n(u=r∏i−1Tu,u+(I))Ci+Cr
2. 递归加速方案 (公式 5)
为了避免对每个像素重复进行 O ( N ) O(N) O(N) 的求和,算法采用了两通扫描范式(Two-pass scan paradigm) 。公式 (5) 展示了左向累积和 A r L A_r^L ArL 的递归性质 :
推导步骤:
-
定义 A r L A_r^L ArL 为像素 r r r 及其左侧所有像素的加权和:
A r L = C r + W r − 1 , r C r − 1 + W r − 2 , r C r − 2 + ... A_r^L = C_r + W_{r-1,r}C_{r-1} + W_{r-2,r}C_{r-2} + \dots ArL=Cr+Wr−1,rCr−1+Wr−2,rCr−2+...
-
利用权重的传递性 W i , r = T r − 1 , r ⋅ W i , r − 1 W_{i,r} = T_{r-1,r} \cdot W_{i,r-1} Wi,r=Tr−1,r⋅Wi,r−1,可以提取出公因子 T r − 1 , r T_{r-1,r} Tr−1,r :
A r L = C r + T r − 1 , r ⋅ ( C r − 1 + T r − 2 , r − 1 C r − 2 + ... ) A_r^L = C_r + T_{r-1,r} \cdot (C_{r-1} + T_{r-2,r-1}C_{r-2} + \dots) ArL=Cr+Tr−1,r⋅(Cr−1+Tr−2,r−1Cr−2+...)
-
括号内的项恰好是前一个像素的累积和 A r − 1 L A_{r-1}^L Ar−1L :
A r L = C r + T r − 1 , r A r − 1 L A_r^L = C_r + T_{r-1,r}A_{r-1}^L ArL=Cr+Tr−1,rAr−1L
这种递归形式使得每个像素仅需一次乘法和一次加法即可完成单向累积 。
3. 最终组合 (公式 6)
在分别完成从左到右(得到 A L A^L AL)和从右到左(得到 A R A^R AR)的扫描后,公式 (6) 将两者合并 :
C r i m e d = A r L + A r R − C r C_{r}^{imed}=A_{r}^{L}+A_{r}^{R}-C_{r} Crimed=ArL+ArR−Cr
推导逻辑:
- A r L A_r^L ArL 包含了:左侧加权贡献 + 自身像素 C r C_r Cr 。
- A r R A_r^R ArR 包含了:右侧加权贡献 + 自身像素 C r C_r Cr 。
- 由于 C r C_r Cr 在两个数组中都被计入了一次,为了符合公式 (4) 的定义,必须减去一次 C r C_r Cr 以修正结果 。
总结
通过这种转换,原本需要 O ( N 2 ) O(N^2) O(N2) 的全图加权计算被简化为了 O ( 1 ) O(1) O(1) 的线性操作(即复杂度与窗口大小无关),每个元素在水平通程中仅需 2 次乘法和 4 次加法 。