目录

温馨提示:
我的Linux环境为:Ubuntu 20.04 LTS
我的mysql版本为:Ver 8.0.42 for Linux on x86_64
为了方便操作,以下大部分操作使用超级用户身份
一、安装流程
前置: 获取 MySQL APT 配置包,用于给系统添加正确的软件源
下载官网:MySQL :: Begin Your Download
下载不要解压,通过 rz 指令传输到服务器中
开始安装:(安装过程忘记截图了,相当于省流了)
1.su - 切换为超级用户,确保安装包通过rz指令发送到了服务器
2.dpkg -i mysql-apt-config_0.8.36-1_all.deb 安装下载的 MySQL APT 配置包
3.设置安装选项,mysql8.0和确认工具...(安装过程中会跳出弹窗,我的是两个设置选项,第一个选择版本,第二个点enable确认安装组件和工具,最后选择OK回车)
4.apt-get update 更新一下安装包
5.apt-get install mysql-server 安装mysql(过程比较慢)
6.安装完成会弹窗,根据提示设置密码和确认密码
7.systemctl status mysql 查看mysql服务是否正常运行,有绿色字体就是正常运行

8.systemctl enable mysql 设置开机自启动(根据需求)
9.systemctl list-unit-files | grep mysql 查看自动动是否设置成功

关于主配置文件: /etc/mysql/mysql.conf.d/mysqld.cnf
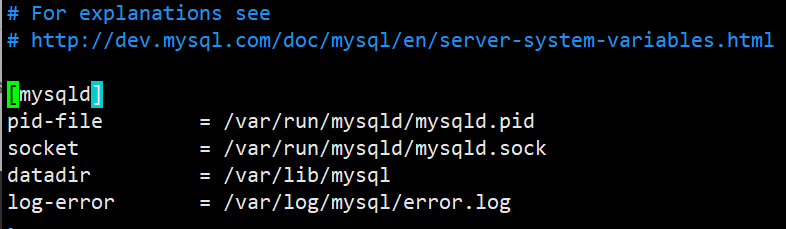
其中datadir是存放我们创建数据库的地方
这里面有些关键属性没写,因为已经内置了,默认也不需要手动配置,不过想配置可以通过修改该文件进行配置;默认配置可以通过mysql相关指令查到
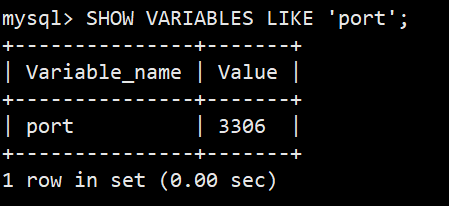
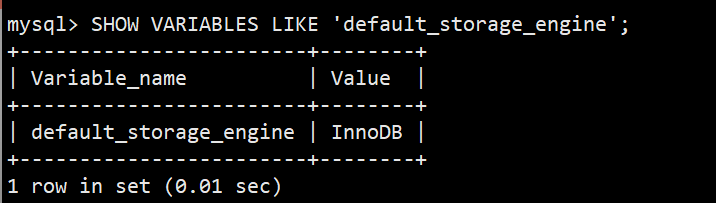
查看默认端口号:3306
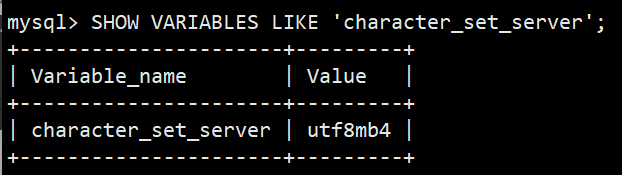
查看默认字符集:utf8mb4(更完整的 UTF-8)
查看默认存储引擎:innodb
二、SQL语句
1.SQL语句分类:
- DDL 【 data definition language 】数据定义语言,用来维护存储数据的结构;
代表语句:create ,drop ,alter - DML【data manipulation language】数据操纵语言,用来对数据进行操作;
代表指令: insert,delete,update - DQL【Data Query Language】,DML中单独分了一个DQL,数据查询语言;
代表指令: select - DCL【Data Control Language】数据控制语言,主要负责权限管理和事务;
代表指令: grant,revoke,commit
2.基础语句
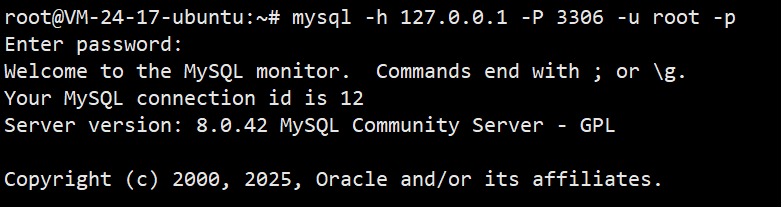
连接MySQL指令:mysql -h 127.0.0.1 -P 3306 -u root -p
**功能:**以root用户身份连接本机 MySQL 数据库,需要输入密码
选项:
-h:指明登录部署了mysql服务的主机ip,这里使用本地环回地址,表明登录自己的主机
-P:指明我们要访问的端口号
-u:指明登录的用户,这里使用的是root超级用户
-p:后跟密码,不建议后面直接跟密码,建议回车进行不回显输入
(注意:当 MySQL 部署在你当前的机器上时,-h 和 -P 这两个参数是可以省略的)
2.1库的操作
1.创建数据库
**语法:**create database db_name;
**功能:**本质就是再 /var/lib/mysql 下创建一个目录
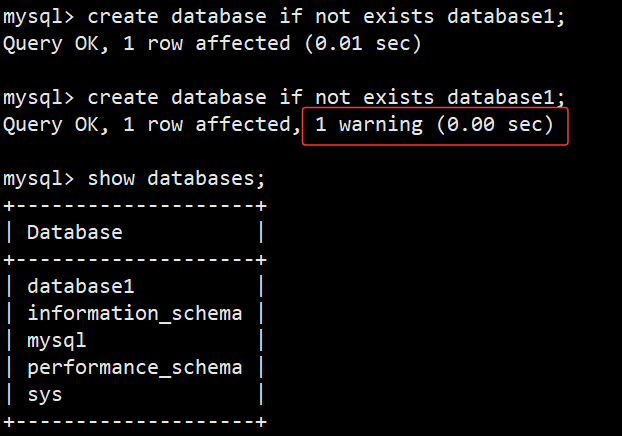
**语法:**create database if not exists db_name;
**功能:**如果创建的数据库存在,会抛出错误警告,不会导致已存在的数据库被覆盖,能更安全的创建数据库
**语法:**create database d1 charset=utf8mb4 collate utf8mb4_general_ci;
**功能:**创建一个字符集为utf8mb4,校验集为utf8mb4_general_ci的数据库
(注意:不设置的就会使用默认字符集和校验集,或者配置文件中设置的字符集和校验集)
字符集(Character Set):决定了数据库可以存储哪些字符,以及这些字符如何被编码成二进制数据,比如utf8mb4支持包括 Emoji 在内的所有 Unicode 字符。
校验集(Collation):定义了字符的比较和排序规则,比如是否区分大小写、是否区分重音,它直接影响
ORDER BY和WHERE条件的匹配结果**注意:**在较新的 MySQL 版本中,collate也可以直接用 = 符号赋值




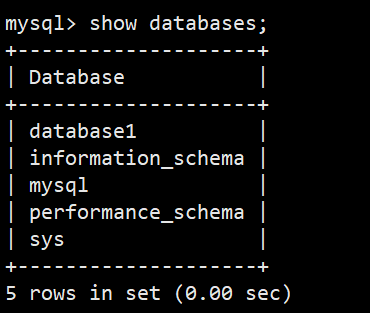
2.查看数据库
**语法:**show databases;
**功能:**查看已创建的数据库
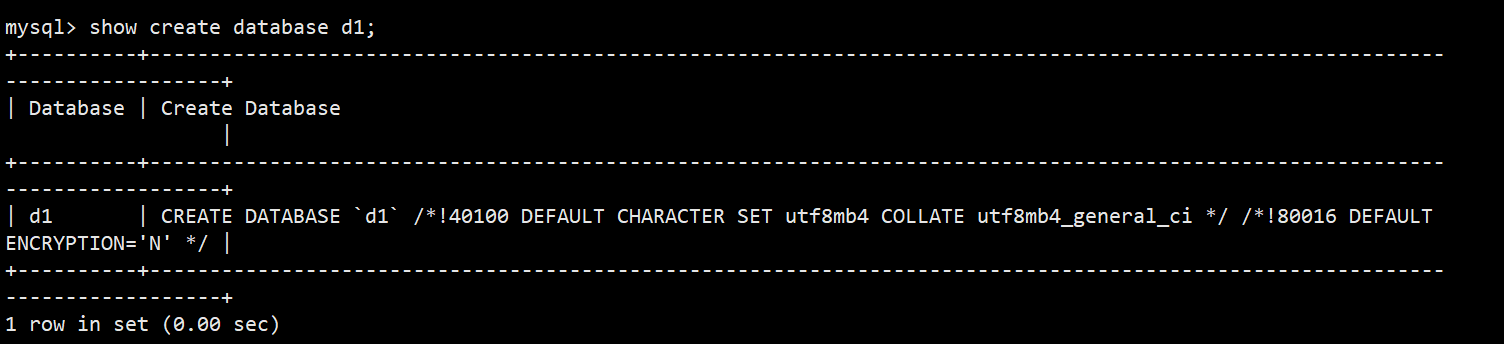
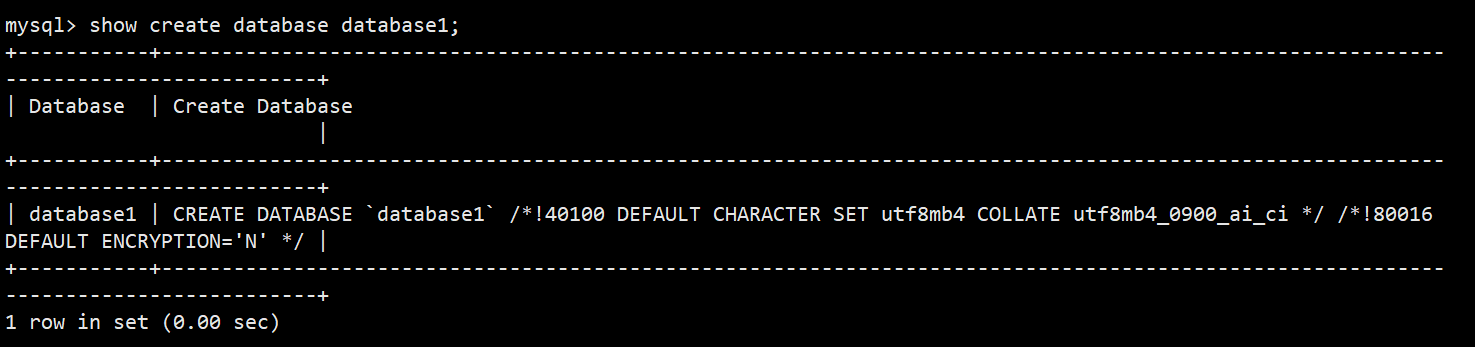
**语法:**show create database db_name;
**功能:**显示创建语句;/*!40100 default.... */这个不是注释,表示当前mysql版本大于4.01版本,就执行这句话,可以看到数据库创建时指定的字符集和是否启用加密(ENCRYPTION='N'表示没有启用加密)
**语法:**show processlist;
**功能:**可以查看有哪些人连接了我们当前的MySQL,以及具体的工作数据库
(注意:这个
event_scheduler不是普通的用户,它是 MySQL 内置的事件调度器守护进程)

3.删除数据库
**语法:**drop database db_name;
**功能:**本质就是再 /var/lib/mysql 下删除一个目录,对应的数据库文件夹被删除,级联删除,里面的数据表全部被删;也可以在databdase后加上if exists以此删除前判断是否存在该数据库

4.修改数据库
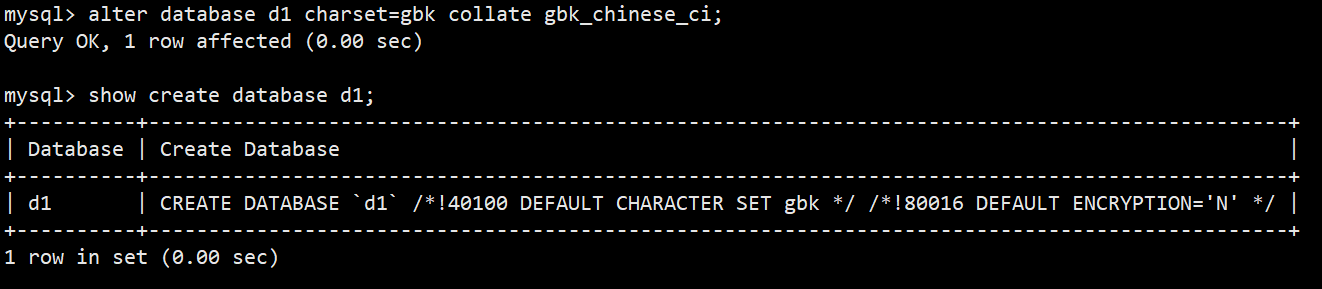
**语法:**alter database d1 charset=gbk collate gbk_chinese_ci;
**功能:**修改数据库d1的字符集和校验集
5.切换当前工作数据库
**语法:**use db_name;
功能: 用来切换当前工作数据库的核心命令;执行这条命令后,后续所有的 SQL 操作(比如
CREATE TABLE、SELECT、INSERT等)都会默认在db_name这个数据库里进行,无需每次都显式指定数据库名。
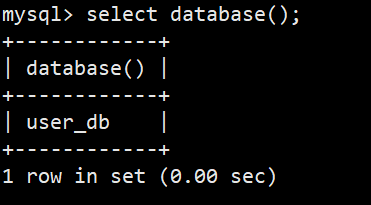
**补充语句:**select database();
**功能:**可以查看当前工作数据库
6.数据库的备份与还原
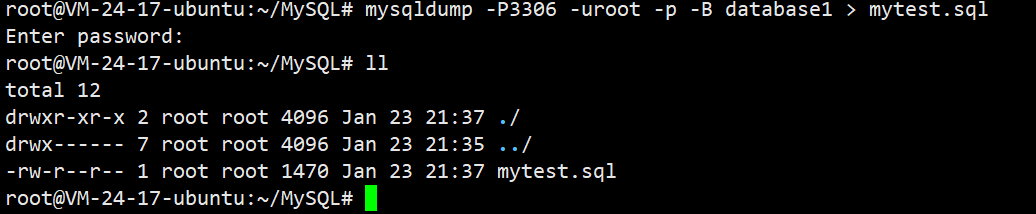
**备份指令:**mysqldump -P3306 -u root -p 密码 -B 数据库名 > 数据库备份存储的文件路径
**示例:**mysqldump -P3306 -uroot -p -B database1 > mytest.sql
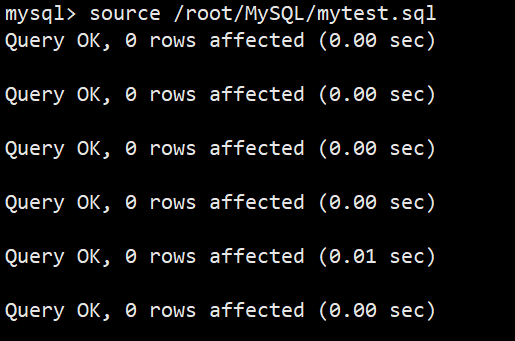
**还原语句:**source 路径
**示例:**source /root/MySQL/mytest.sql
注意事项
- 如果备份的不是整个数据库,而是其中的一张表,怎么做?
mysqldump -u root -p 数据库名 表名1 表名2 > D:/mytest.sql- 同时备份多个数据库
mysqldump -u root -p -B 数据库名1 数据库名2 ... > 数据库存放路径- 如果备份一个数据库时,没有带上-B参数, 在恢复数据库时,需要先创建空数据库,然后使用数据 库,再使用source来还原;(如果改变创建数据库的名称,这个过程也能完成对数据库重命名操作)
2.2表的操作
1.创建表
**语法:**create table table_name (
field1 datatype,
field2 datatype,
field3 datatype
) character set=字符集 collate=校验规则 engine=存储引擎;
- field 表示列名
- datatype 表示列的类型;参考下文数据类型
- character set 字符集,如果没有指定字符集,则以所在数据库的字符集为准
- collate 校验规则,如果没有指定校验规则,则以所在数据库的校验规则为准
- engine 存储引擎同上
- table后面可以跟if not exists,可以避免将已有同名表覆盖的风险
(**注意:**定义列时,最后一列的后面不跟逗号;另外最后一行的 = 号也可以用空格代替)
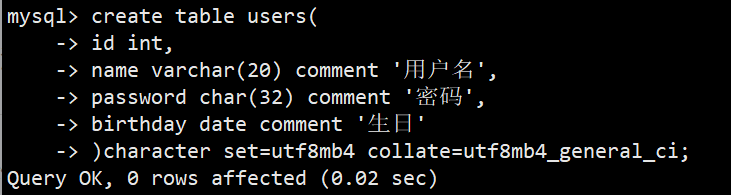
示例: create table users(
id int,
name varchar(20) comment '用户名',
password char(32) comment '密码',
birthday date comment '生日'
)character set=utf8mb4 collate=utf8mb4_general_ci;
- (comment后面跟的是备注)
**注意:**不同的存储引擎,创建表的文件后缀和数量不一样(还和mysql版本有关)

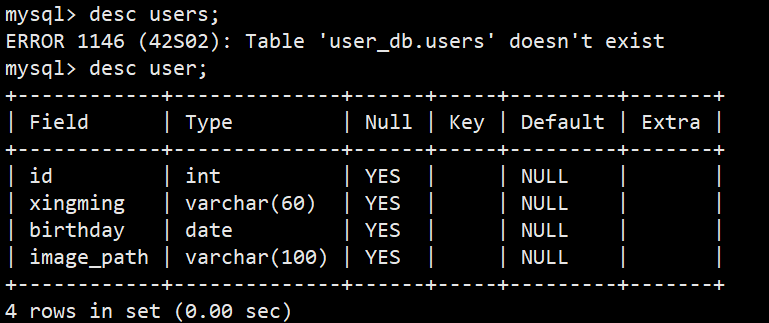
2.查看表结构
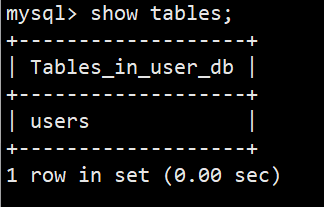
**语法:**show tables;
**功能:**可以查看当前数据库中有哪些表
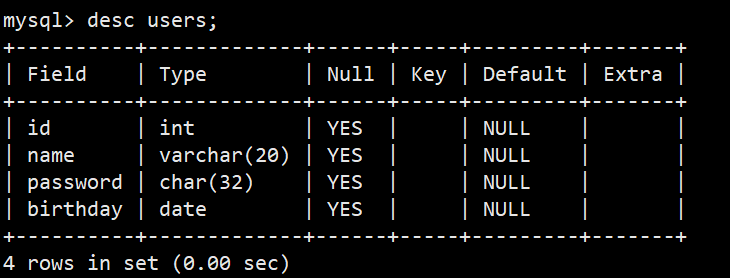
**语法:**desc 表名;
**功能:**查看详细的表结构
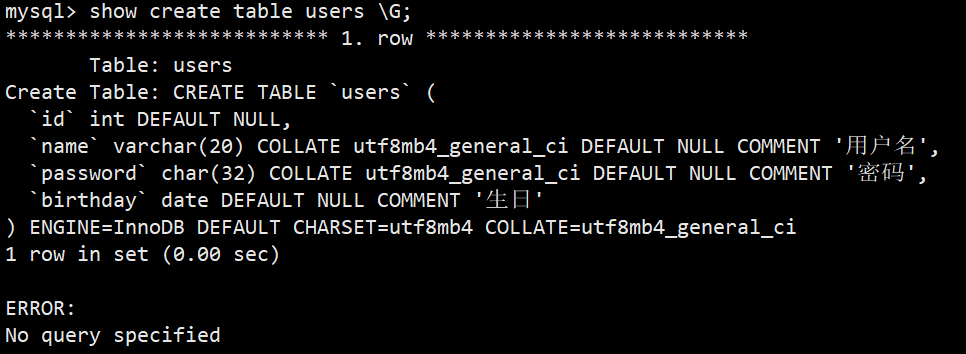
**语法:**show create table 表名 \G;
**功能:**可以查看建表时的语句(\G可以调整格式)
3.修改表
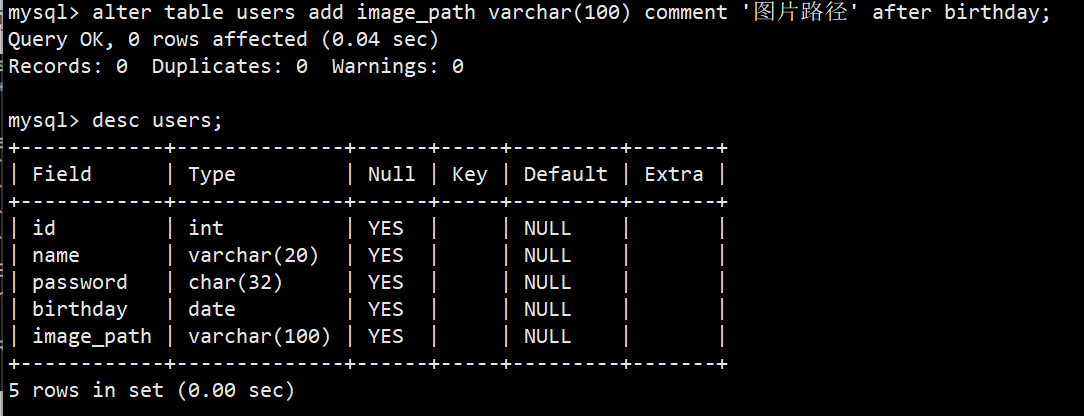
**语法:**alter table 表名 add 字段 字段类型 comment '备注' after 位于哪个字段后面;
**功能:**在指定表里新增一个字段,也就是新增列;如果想在表最前面新增字段可以把after以及后面的替换成first;如果不写after或first,新字段默认会添加到表结构的最后
**示例:**alter table users add image_path varchar(100) comment '图片路径' after birthday;
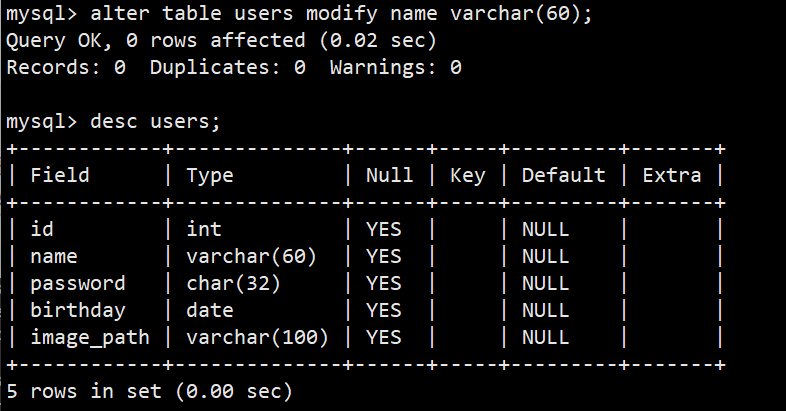
**语法:**alter table 表名 modify 字段 要修改的字段类型 comment '要修改的备注';
**功能:**修改字段的类型和备注,也可以只修改一部分
**示例:**alter table users modify name varchar(60);
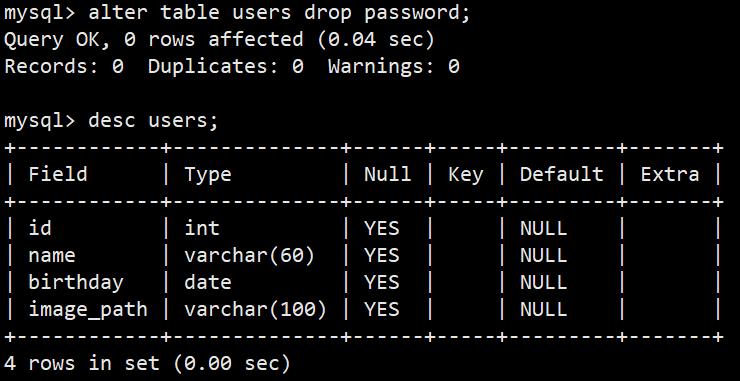
**语法:**alter table 表名 drop 要删除的字段;
**功能:**删除表的指定字段(注意:删除字段及其对应的列数据都没了)
**示例:**alter table users drop password;
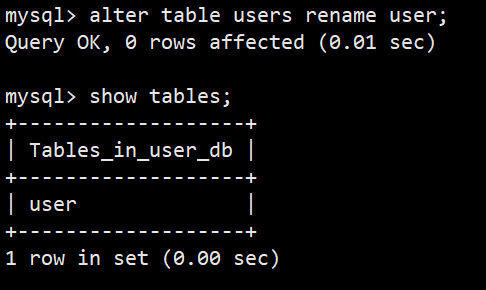
**语法:**alter table 表名 rename 新表名;
**功能:**修改表名
**示例:**alter table users rename to user;
**语法:**alter table 表名 change 旧字段名 新字段名 字段类型 其他属性;
**功能:**对字段重命名,注意新字段后面必须跟着字段类型;而其它属性如comment备注,如果不写,备注会保持原样
**示例:**alter table employee change name xingming varchar(60);

4.删除表
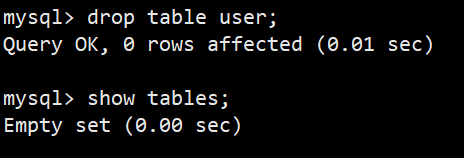
**语法:**drop table 表名;
**功能:**删除指定的表
- table后跟if exists可以避免删除表不存在的报错
- 一次性删除多张表,表之间用逗号分隔
2.3表数据的插入
1.插入数据
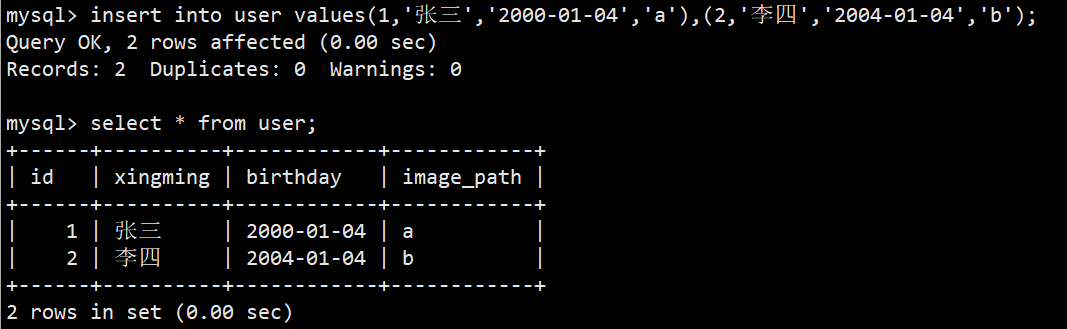
**语法:**insert into 表名 values(1,'张三','2000-01-04','a'),(2,'李四','2004-01-04','b');
**功能:**在指定表中新增两条记录,注意添加的数据类型和数量都要匹配上;表名后面可以加上括号(),在括号里面可以指定要插入数据的字段,默认不加就是全列插入;
**语法:**insert into 表名(字段,...) values (数据,...) on duplicate key update 字段=更新数据,...;
功能: 插入否则更新;插入数据时如果出现数据冲突则更新为on duplicate key update后面的数据;
插入结果有以下三种情况:
- 0 row affected: 表中有冲突数据,但冲突数据的值和 update 的值相等,相当于无事发生
- 1 row affected: 表中没有冲突数据,数据被插入,正常插入
- 2 row affected: 表中有冲突数据,并且数据已经被更新,相当于对已有数据进行了修改
**示例:**第三种情况
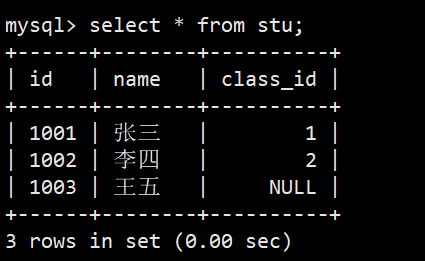
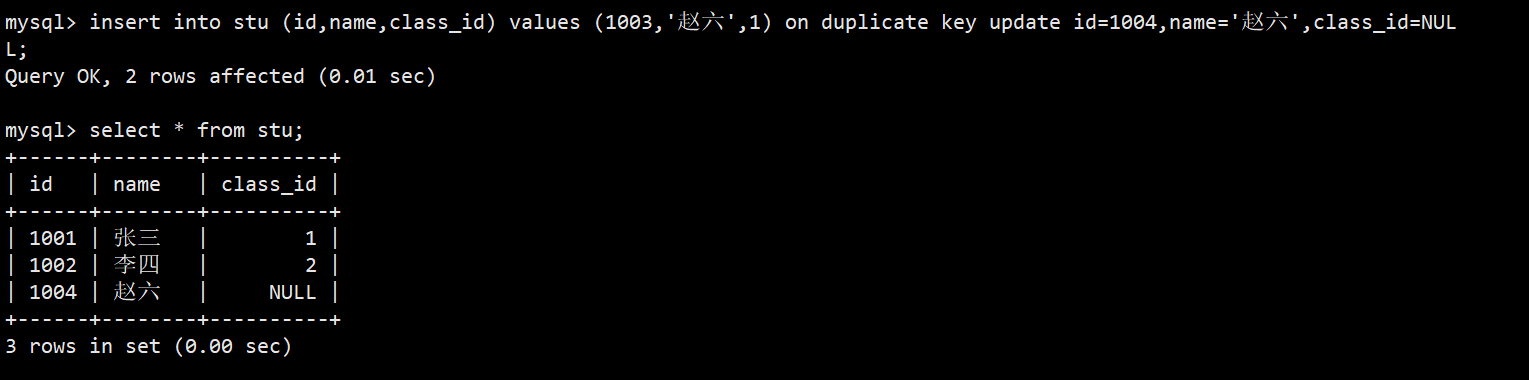
- 以上是现有数据,经过插入否则更新操作后,如下图:
- "Query OK, 2 rows affected (0.01 sec)"就对应着第三种情况,将冲突数据更新了
**语法:**replace into stu (字段,...) values (字段,...);
**功能:**主键 或者 唯一键 没有冲突,则直接插入;主键 或者 唯一键 如果冲突,则删除后再插入;
成功有两种情况:
- 1 row affected: 表中没有冲突数据,数据被插入
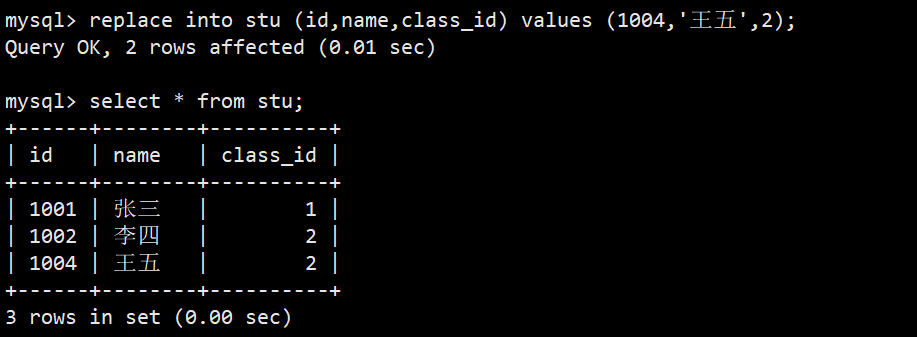
- 2 row affected: 表中有冲突数据,删除后重新插入
示例:
- 之前的'赵六'被删除了并且重新插入了'王五'
2.插入查询结果
**语法:**insert into 要插入的表名 select 查询语句;
**作用:**将查询的结果插入表中
**案例:**删除表中的重复记录 --- 表去重操作
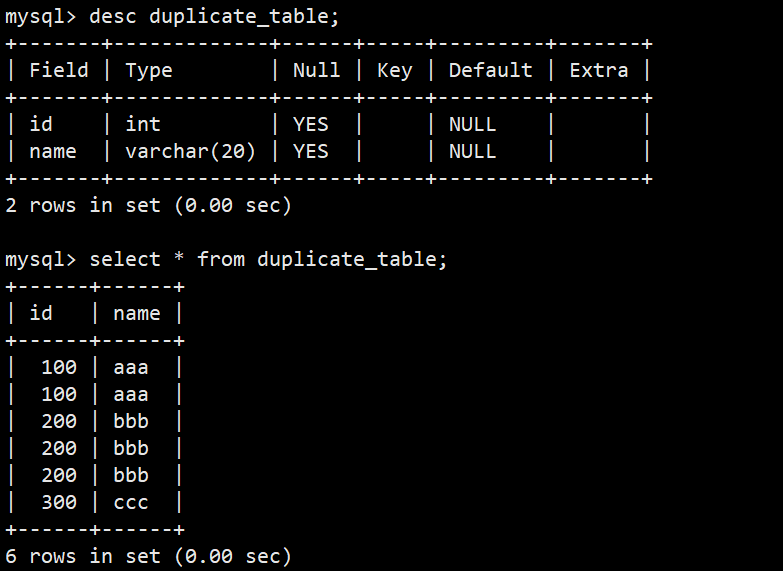
- 要去重的表结构和数据如下:
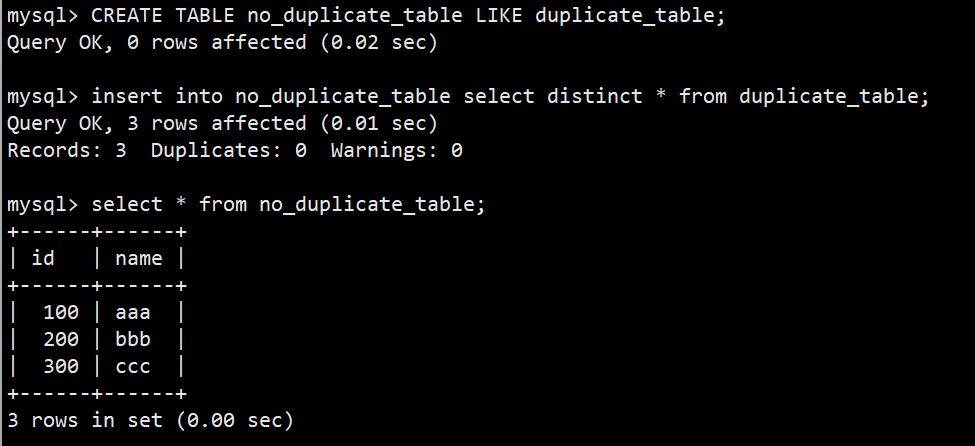
- 我们先创建一张空表 no_duplicate_table,结构和 duplicate_table 一样,然后将 duplicate_table 的去重数据插入到 no_duplicate_table:
- 语法:insert into no_duplicate_table select distinct * from duplicate_table;
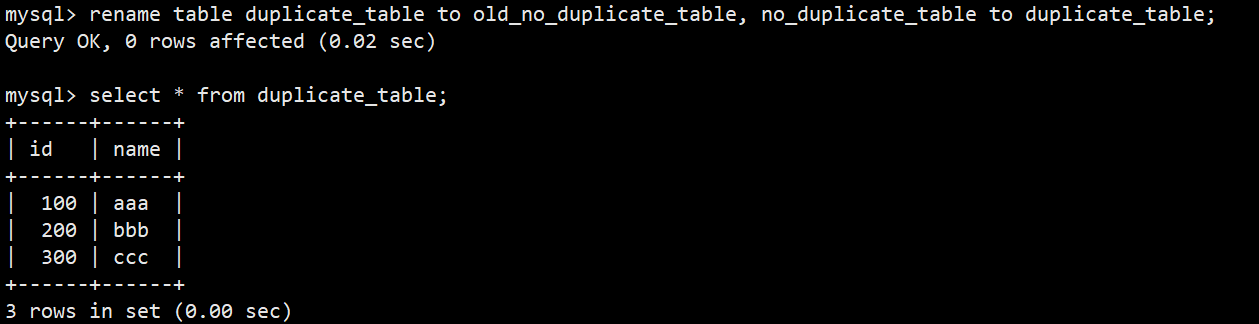
- 最后通过重命名表,实现原子的去重操作:
第一步:将原表 duplicate_table 重命名为 old_no_duplicate_table;
第二步:紧接着将原表 no_duplicate_table 重命名为 duplicate_table;- 语法:rename table duplicate_table to old_no_duplicate_table, no_duplicate_table to duplicate_table;
- 最后查询 duplicate_table 数据就被去重了
2.4基本查询
1.select
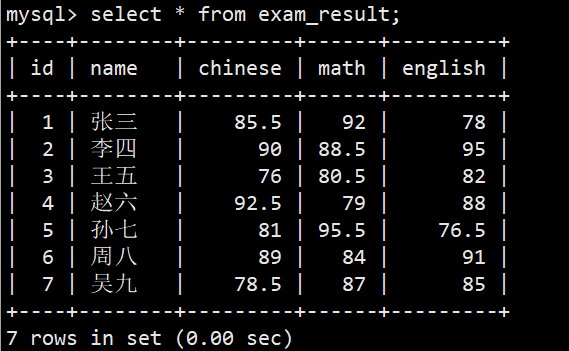
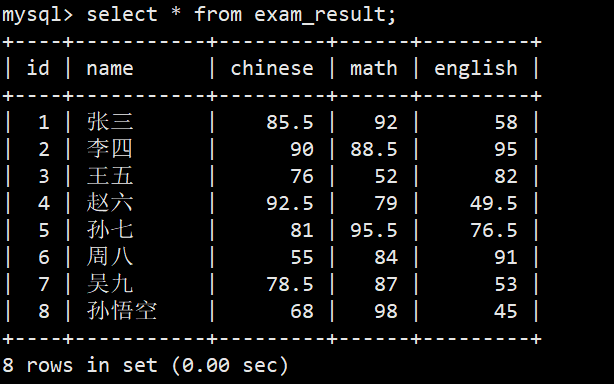
- 我们先创建一张成绩表,以及插入数据,如下图:
全列查询
- 语法:select * from 表名;
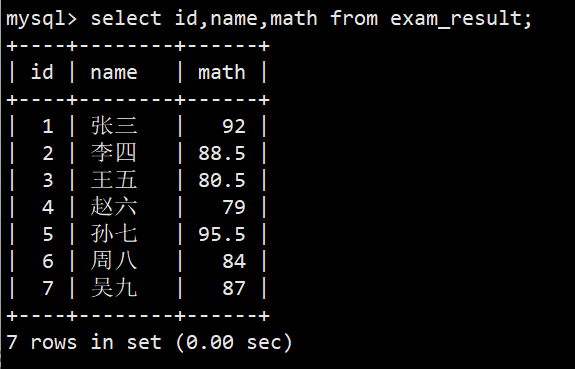
指定列查询
- 语法:select 字段,... from 表名;
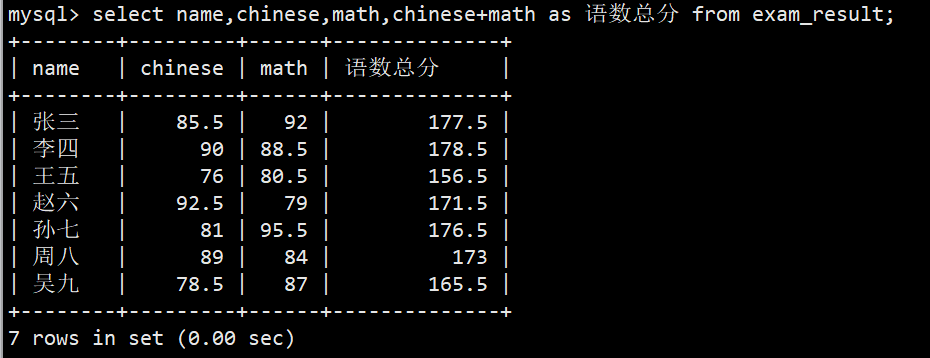
查询字段为表达式
- 语法:select 字段,... 表达式 as 重命名 from 表名;
- 重命名前的as可以省略,如果重命名和as都省略默认以表达式作为查询的列名
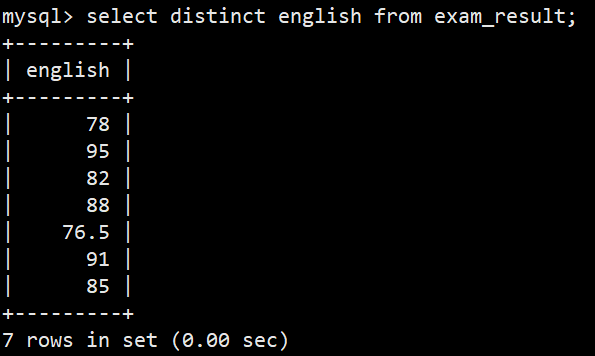
查询结果去重
- 语法:select distinct 字段,... from 表名;
2.where 条件子句
比较运算符:
|-------------------|----------------------------------------------------|
| 运算符 | 说明 |
| >, >=, <, <= | 大于,大于等于,小于,小于等于 |
| = | 等于,null 不安全,例如null = null的结果是 null |
| <=> | 等于,null 安全,例如null <=> null的结果是 true (1) |
| !=, <> | 不等于 |
| between a0 and a1 | 范围匹配,a0, a1,如果a0 <= value <= a1,返回 true (1) |
| in (option, ...) | 如果是 option 中的任意一个,返回 true (1) |
| is null | 是 null |
| is not null | 不是 null |
| like | 模糊匹配。%表示任意多个(包括 0 个)任意字符,_表示任意一个字符 |逻辑运算符:
|---------|---------------------------------|
| 运算符 | 说明 |
| and | 多个条件必须都为 true (1),结果才是 true (1) |
| or | 任意一个条件为 true (1),结果为 true (1) |
| not | 条件为 true (1),结果为 false (0) |
案例:接着select中的表结构查询(修改了数据)
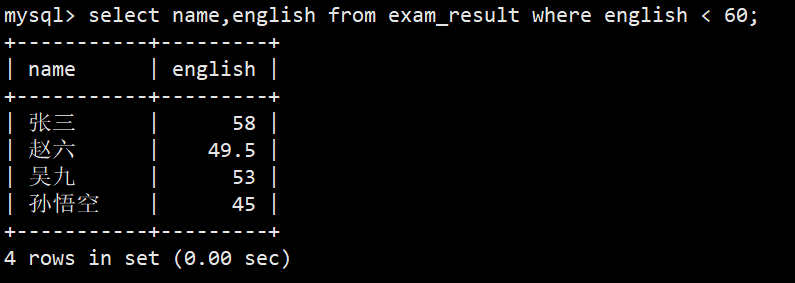
- 1.英语不及格的同学及英语成绩 < 60
- 语法:select name,english from exam_result where english < 60;
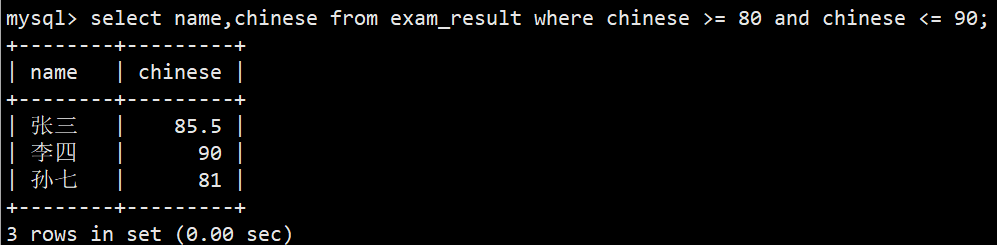
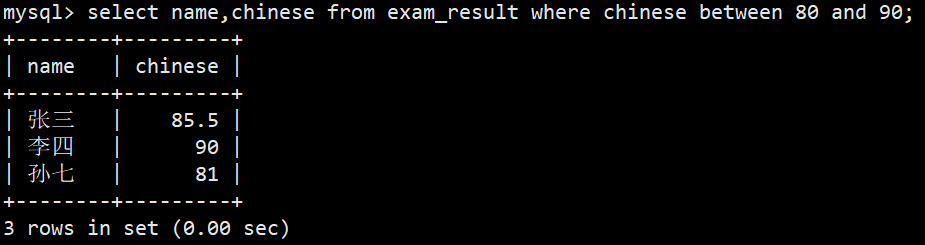
- 2.语文成绩在 80, 90 分的同学及语文成绩
- 语法1:select name,chinese from exam_result where chinese >= 80 and chinese <= 90;
- 语法2:select name,chinese from exam_result where chinese between 80 and 90;
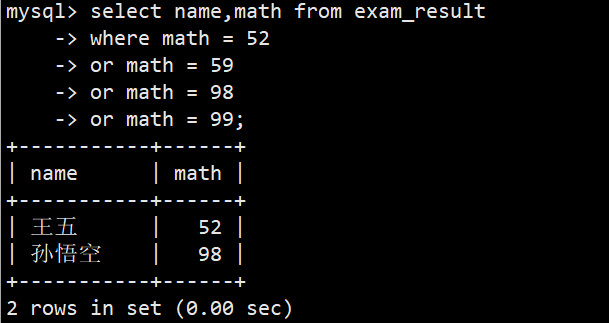
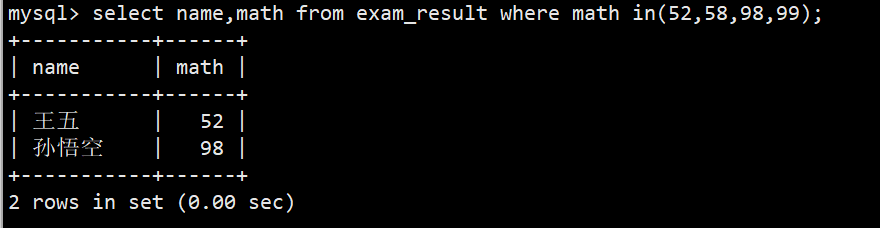
- 3.数学成绩是 52 或者 59 或者 98 或者 99 分的同学及数学成绩
- 语法1:select name,math from exam_result where math = 52 or math = 59 or math = 98 or math = 99;
- 语法2:select name,math from exam_result where math in(52,58,98,99);
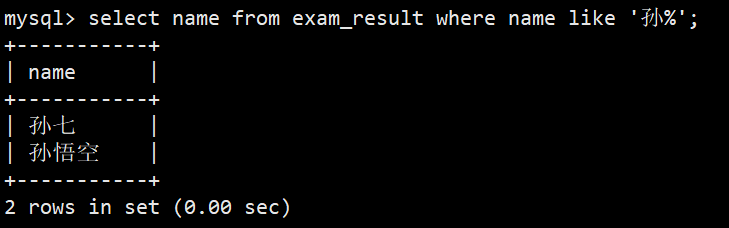
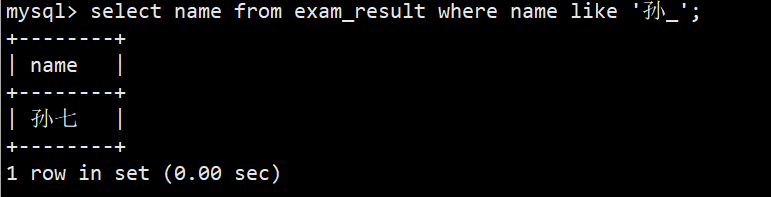
- 4.姓孙的同学 及 孙某同学(孙某是指两字,姓孙是两字及以上)
- %匹配多个字符语法:select name from exam_result where name like '孙%';
- 严格匹配一个字符语法:select name from exam_result where name like '孙';
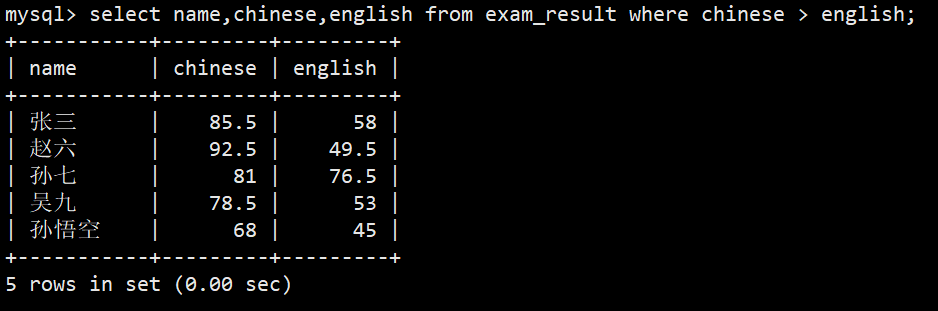
- 5.语文成绩好于英语成绩的同学
- 语法:select name,chinese,english from exam_result where chinese > english;
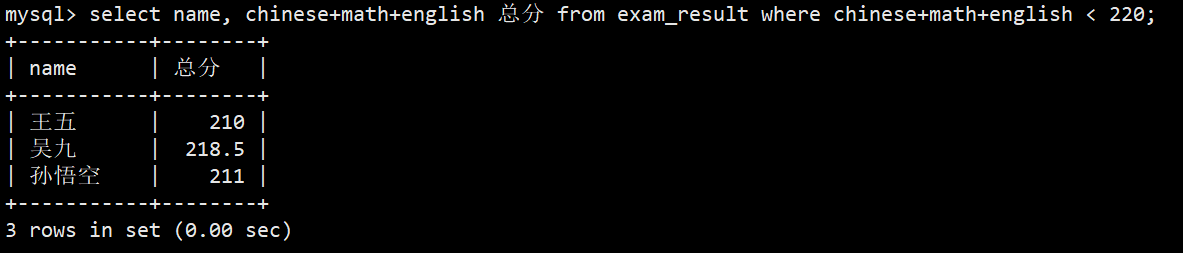
- 6.总分在 220 分以下的同学
- 语法:select name, chinese+math+english 总分 from exam_result where chinese+math+english < 220;
- 注意:这里where子句不能使用别名'总分'与220进行比较,这和实际语句执行顺序有关,where执行靠前识别不到重命名
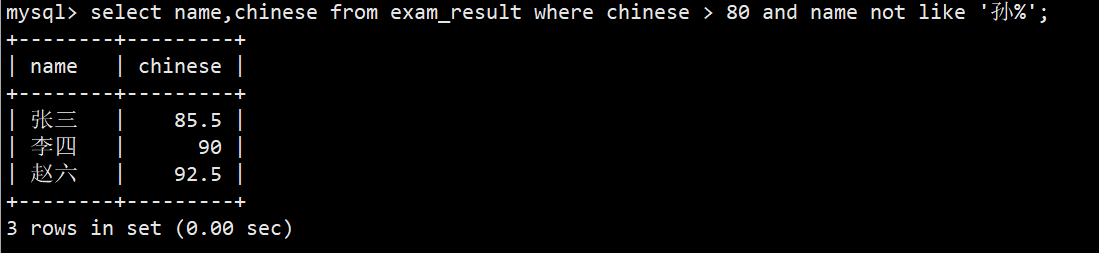
- 7.语文成绩 > 80 并且不姓孙的同学
- 语法:select name,chinese from exam_result where chinese > 80 and name not like '孙%';
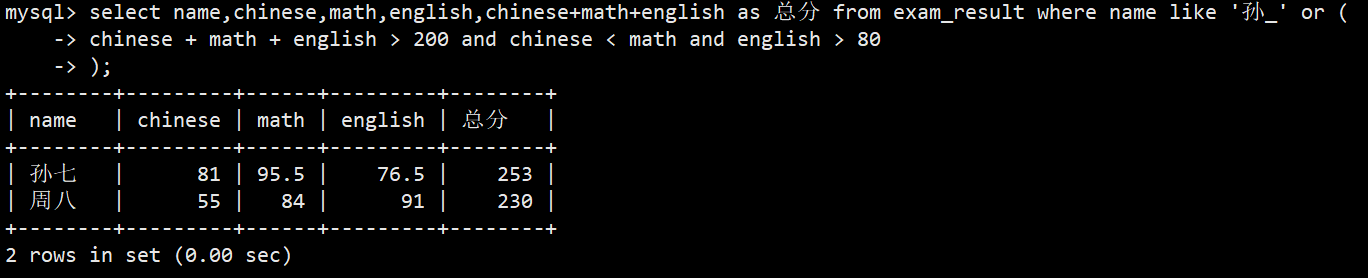
- 8.查孙某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80
- 语法:select name,chinese,math,english,chinese+math+english as 总分 from exam_result where name like '孙_' or ( chinese
- math + english > 200 and chinese < math and english > 80 );
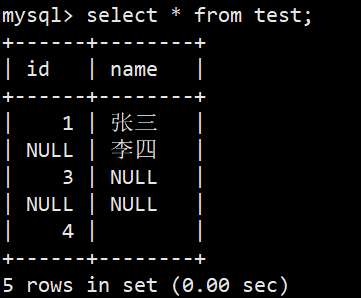
NULL相关查询,查询如下这张表:
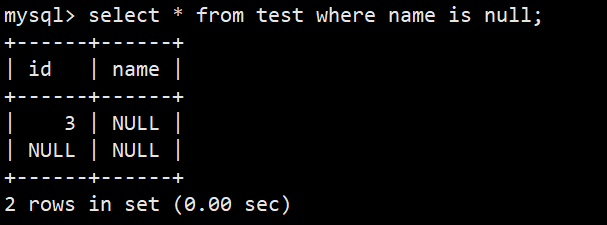
- 查询所有名字为空的数据
- 语法:select * from test where name is null; (注意不能直接用=,可以用<=>)
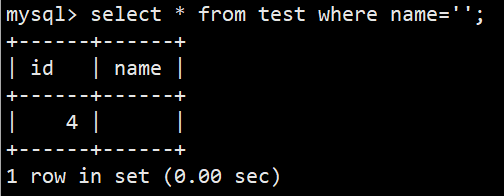
- 从结果上看很明显 id=4 的name=空串不属于null
- 查询名字为空串语法:select * from test where name='';
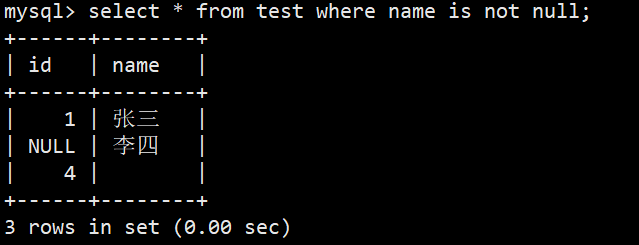
- 查询所有名字不为null语法:select * from test where name is not null;
3.order by结果排序
**语法:**select 字段,... from 表名 order by 要排序的字段 asc/desc;
**功能:**将查询到的结果根据要排序的字段进行排序,asc 为升序(从小到大),desc 为降序(从大到小),默认不写为asc升序
**示例:**依旧是2.4的成绩表
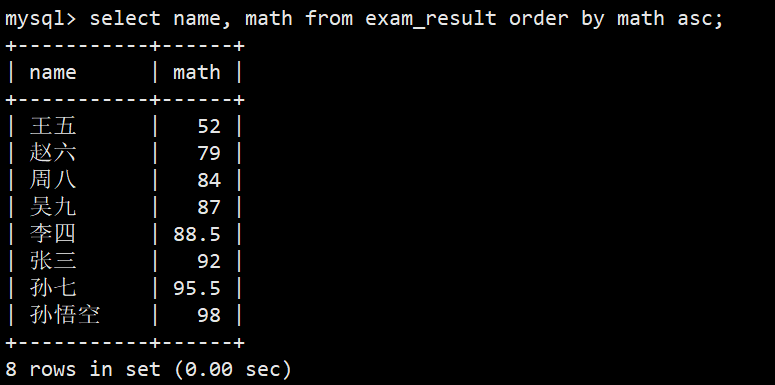
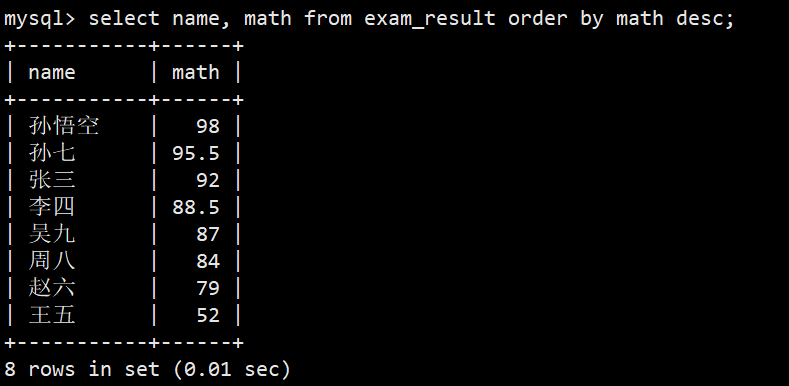
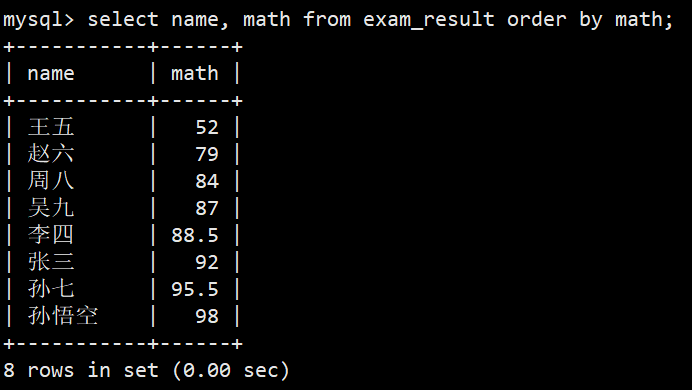
- 查询同学和其数学成绩,升序/降序排序
- 升序:select name, math from exam_result order by math asc;
- 降序:select name, math from exam_result order by math desc;
- 默认(升序):select name, math from exam_result order by math;
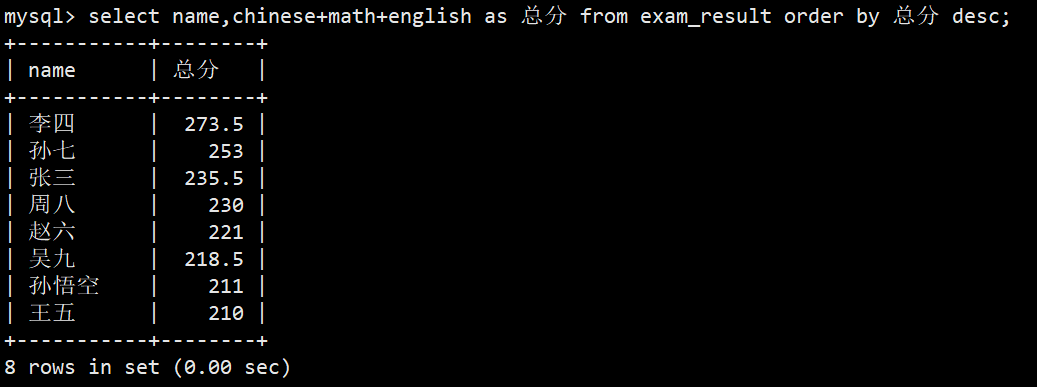
- 查询同学及总分,由高到低
- 语法:select name,chinese+math+english as 总分 from exam_result order by 总分 desc;
- 注意:order by 支持使用重命名,因为它实际执行顺序靠后,能识别到重命名
4.limit筛选分页结果
**语法:**在查询语句的末尾添加 limit,有三种常用写法:
- limit n:从结果的第 1 条开始,取前 n 条数据
- limit s, n:从结果的第 s+1 条开始,取 n 条数据(s 是起始位置的偏移量,从 0 开始计数)
- limit n offset s:和 limit s, n 效果完全相同,语义更清晰,推荐使用;注意这里n在前,s在后,意思还是跳过前s条数据,从s+1开始去n条数据
**作用:**当查询结果数据量很大时,通过分页只加载当前需要的少量数据,避免一次性查询大量数据导致的数据库性能问题,同时提升前端页面的加载速度和用户体验
示例:
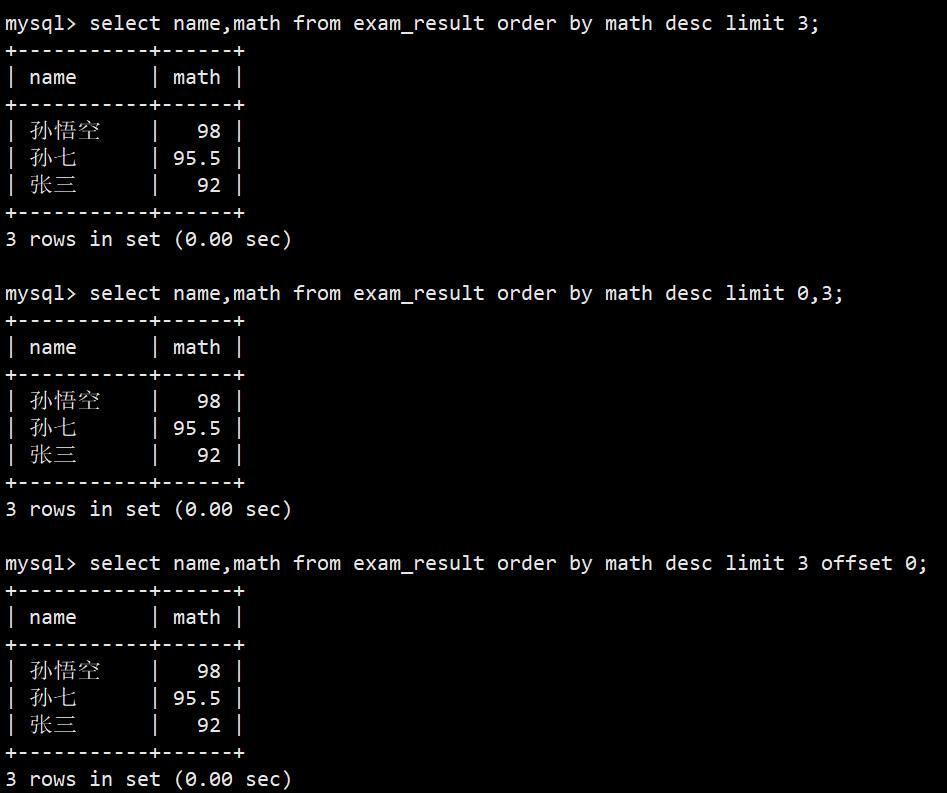
- 查询数学成绩前3名同学
- 语法1:select name,math from exam_result order by math desc limit 3;
- 语法2:select name,math from exam_result order by math desc limit 0,3;
- 语法3:select name,math from exam_result order by math desc limit 3 offset 0;
2.5表数据的更新
1.update数据更新
**语法:**update 要更新的表名 set 更新的字段 = 新数据 (where/order/limit查询结果);
**作用:**对查询的结果进行列值更新
**注意:**若不跟where等条件子句,会默认对整张表的指定字段执行全表更新,将表中所有行的该字段数据统一变更为 set 后指定的值
**示例:**还是上面那张成绩表
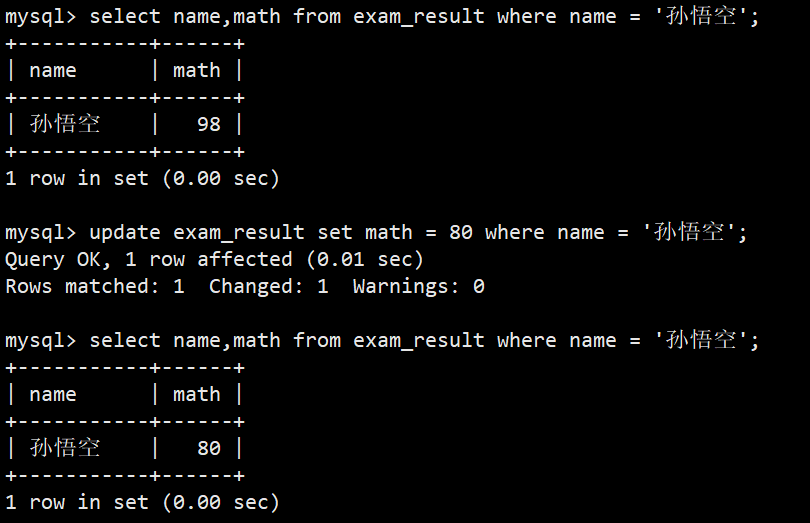
- 案例:将孙悟空同学的数学成绩变更为 80 分
- 语法:update exam_result set math = 80 where name = '孙悟空';
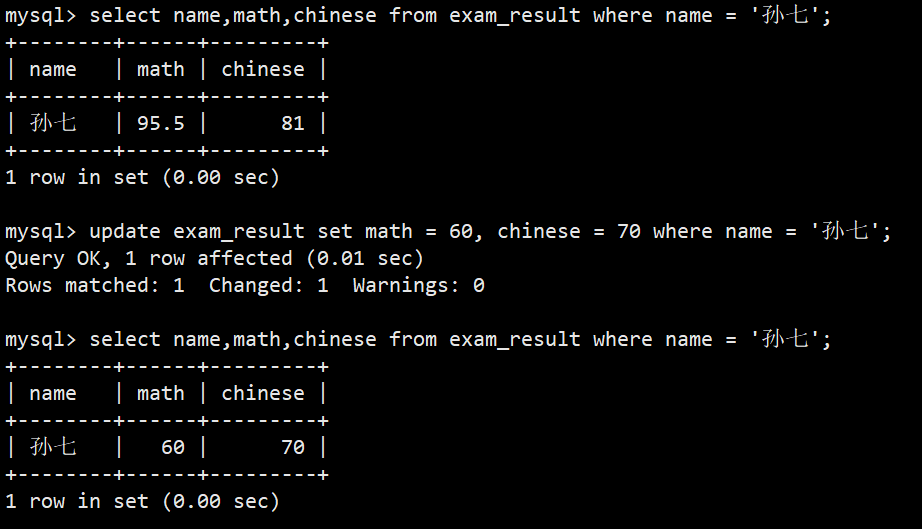
- 案例:将孙七同学的数学成绩变更为 60 分,语文成绩变更为 70 分
- 语法:update exam_result set math = 60, chinese = 70 where name = '孙七';
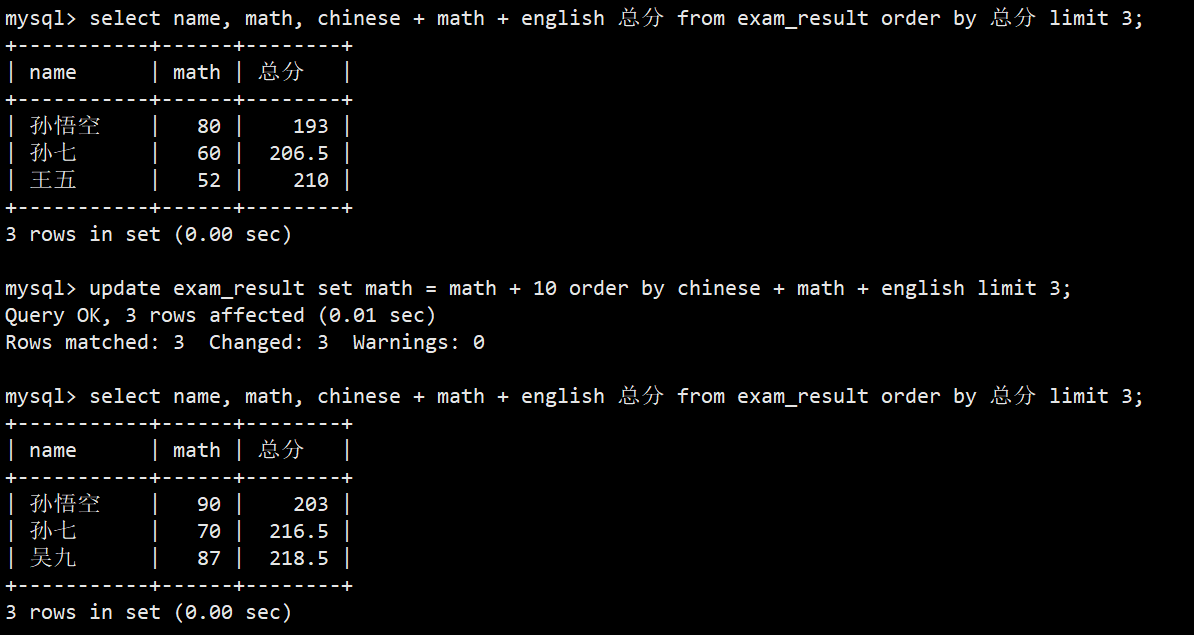
- 案例:将总成绩倒数前三的 3 位同学的数学成绩加上 10 分
- 语法:update exam_result set math = math + 10 order by chinese + math + english limit 3;
- 注意:增加或者减少某个字段的数值,只能使用类似 math = math + 10 这样的语法,而不能使用 += 或 -= 这样的编程语法
2.6表数据删除
1.delete删除数据
**语法:**delete from 表名(where/order/limit查询语句);
**注意:**不跟查询子句默认就是删除整张表的数据
**示例:**成绩表
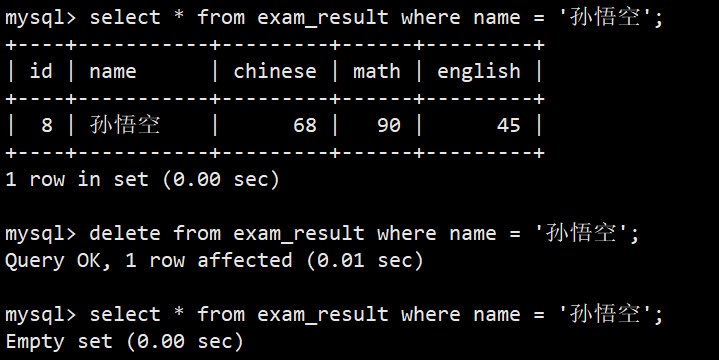
- 案例:删除孙悟空同学的考试成绩
- 语法:delete from exam_result where name = '孙悟空';
- 案例:删除整张表数据
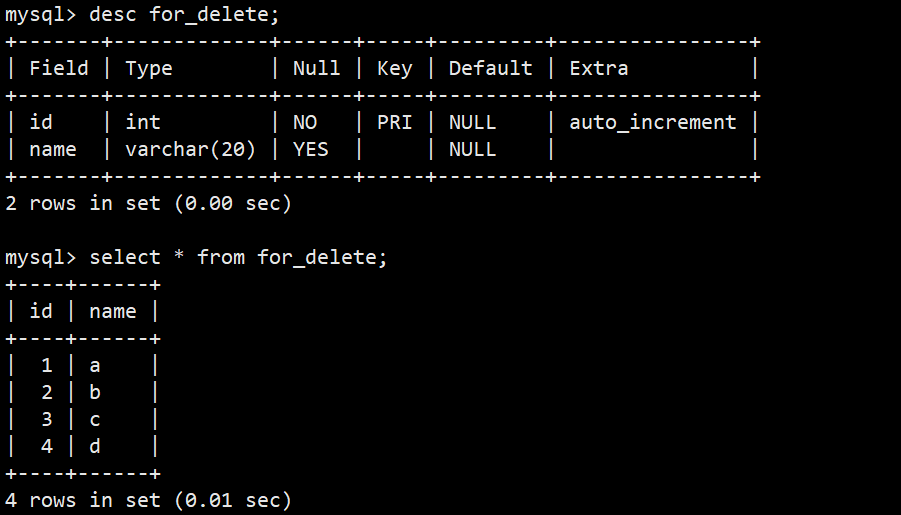
- 注意:删除整张表操作要慎用,这里另建表演示,新表如下图:
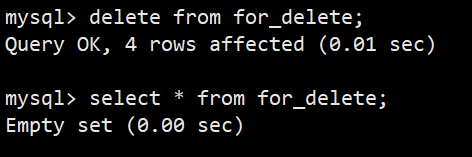
- 语法:delete from for_delete;
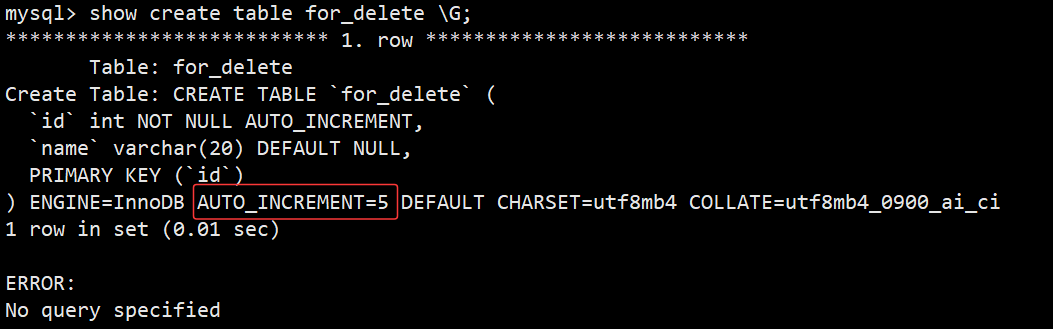
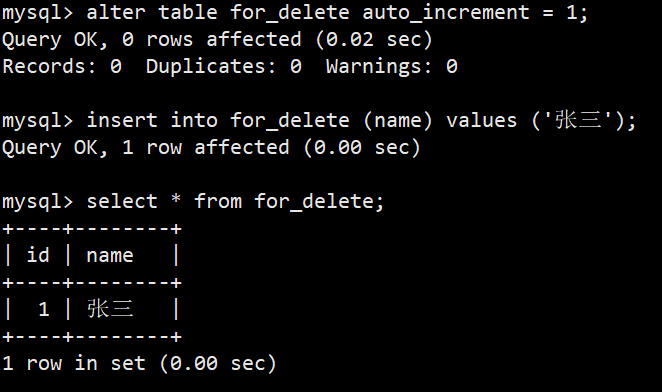
- 注意:因为我们id字段是设置了自增长,虽然我们删除了所有数据,但是下次重新插入name时,id是会从之前的数据继续递增的,我们通过查看建表语句就可以看到,如下图:
- 修改自增长语法:alter table for_delete auto_increment = 1;
2.truncate截断表
**语法:**truncate 表名;
特点:
- 只能对整表操作,不能像 delete 一样针对部分数据操作;
- 实际上 mysql 不对数据操作,所以比 delete 更快,但是 truncate 在删除数据的时候,并不经过真正的事务,所以无法回滚
- 会重置 auto_increment 项,所以我们不需要像delete那样重新设置
示例:
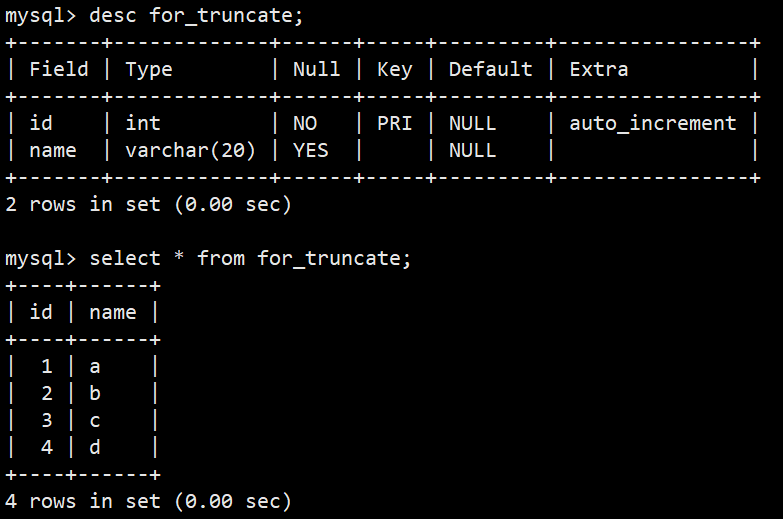
- 以上是准备要删除的表结构和数据;
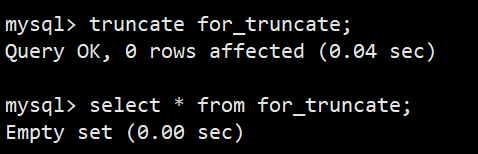
- 删除语法:truncate for_truncate;
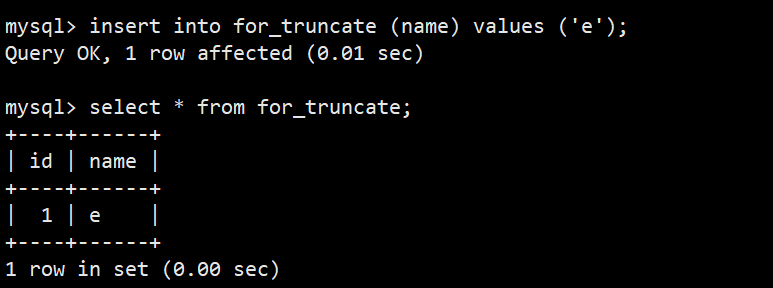
- 通过插入查询,可以看到 auto_increment 项被重置了
2.7聚合函数
|--------------------------|-----------------------|
| 函数 | 说明 |
| count(distinct expr) | 返回查询到的数据的数量 |
| sum(distinct expr) | 返回查询到的数据的总和,不是数字没有意义 |
| avg(distinct expr) | 返回查询到的数据的平均值,不是数字没有意义 |
| max(distinct expr) | 返回查询到的数据的最大值,不是数字没有意义 |
| min(distinct expr) | 返回查询到的数据的最小值,不是数字没有意义 |**案例:**以上面成绩表为例
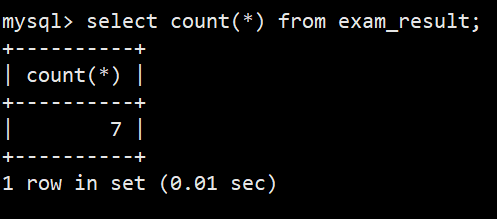
- 1.统计班级共有多少同学
- 语法:select count(*) from exam_result;
- 注意:使用 * 做统计,不受 NULL 影响,也可以是某个字段;
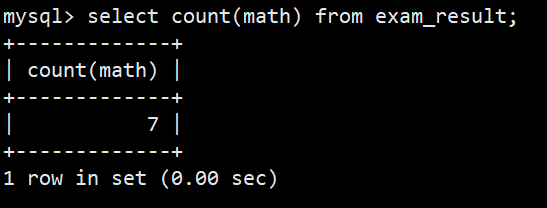
- 2.统计本次考试的数学成绩分数个数
- 语法:select count(math) from exam_result;
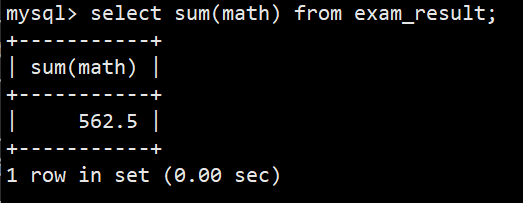
- 3.统计数学成绩总分
- 语法:select sum(math) from exam_result;
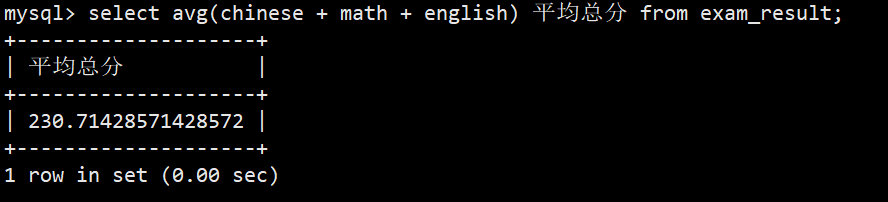
- 4.统计总分的平均分
- 语法:select avg(chinese + math + english) 平均总分 from exam_result;
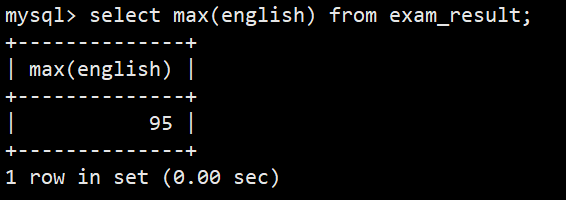
- 5.返回英语最高分
- 语法:select max(english) from exam_result;
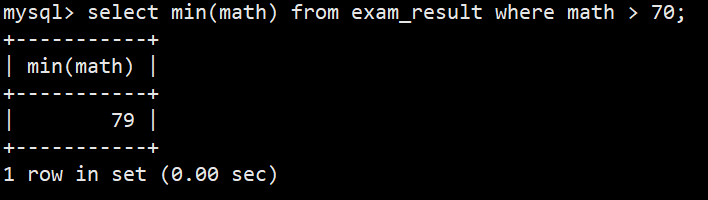
- 6.返回 > 70 分以上的数学最低分
- 语法:select min(math) from exam_result where math > 70;
(聚合函数后面也可以跟名称重命名)
三、多种查询方法
1.分组查询 group by
group by: SQL 中用于对查询结果按指定字段进行分组聚合 的核心子句,核心作用是将查询结果中字段值相同的行归为一个分组,把原本按单条记录展示的结果,聚合为按 "分组维度" 展示的组级结果;它必须配合聚合函数使用,实现对每个分组单独做统计计算,以此完成从 "单条数据查询" 到 "分类统计分析" 的转换,是实现各类分组统计需求的基础。
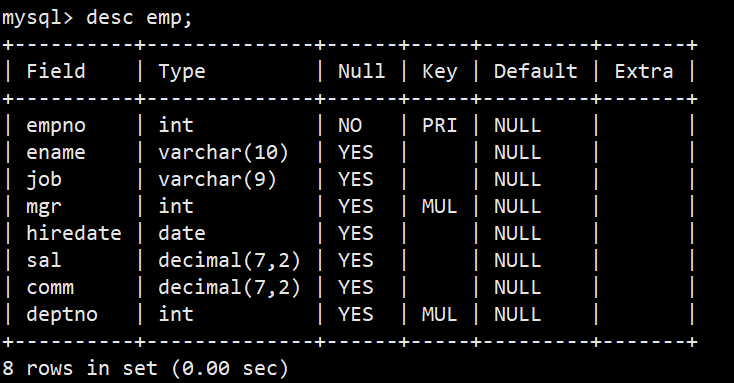
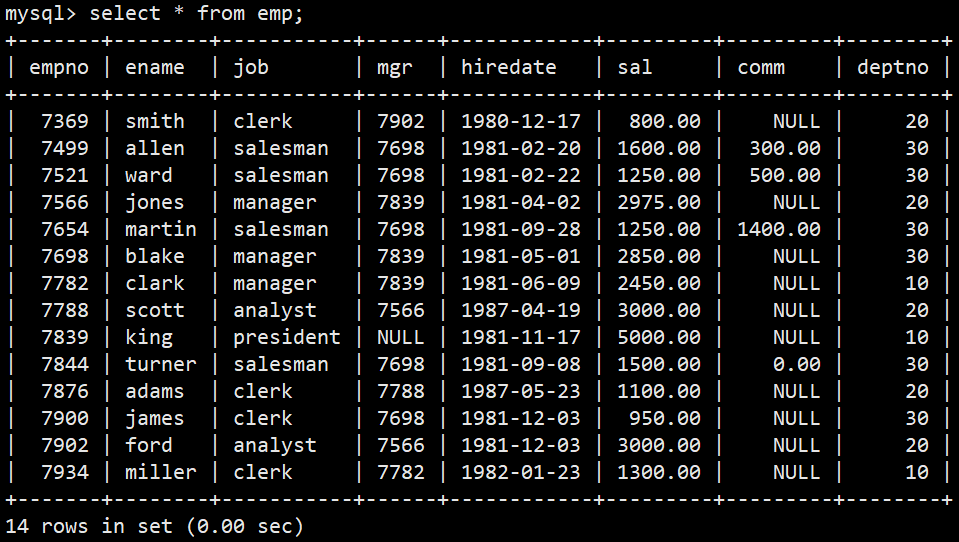
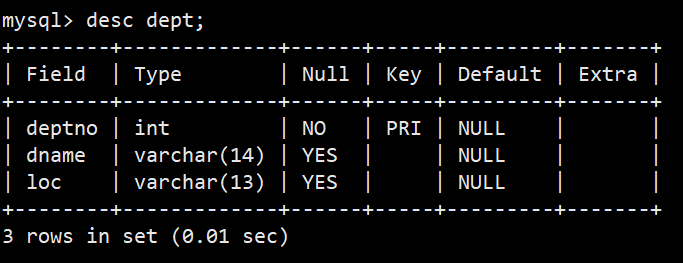
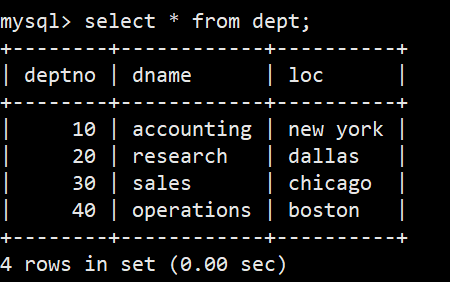
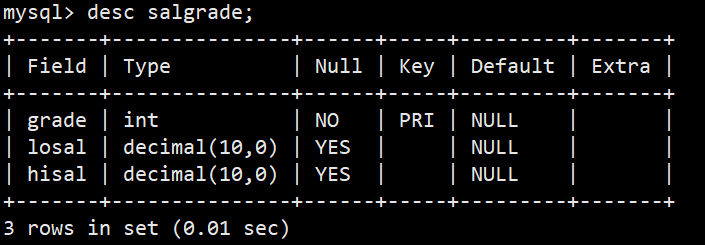
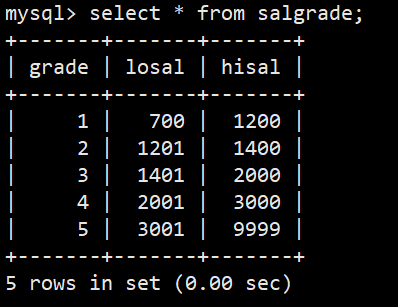
**案例:**创建一个雇员信息表(来自oracle 9i的经典测试表)
- EMP员工表:
- DEPT部门表:
- SALGRADE工资等级表:
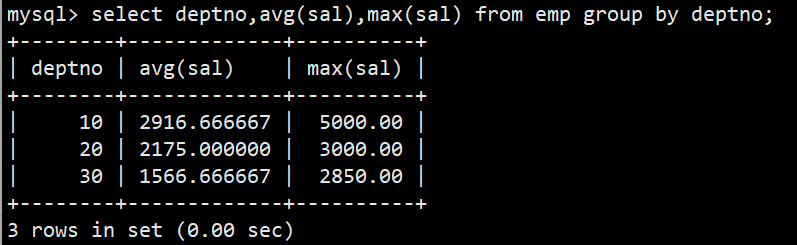
- 1.如何显示每个部门的平均工资和最高工资
- 解释:只有emp员工表中同时有部门号和工资信息,所以在emp表中做分组查询,这里要查询每个部门,所以我们对部门deptno进行分组;
- 语法:select deptno,avg(sal),max(sal) from emp group by deptno;
- 注意:一般只有 group by 后面指定分组的字段,以及聚合函数能出现在select的左侧;
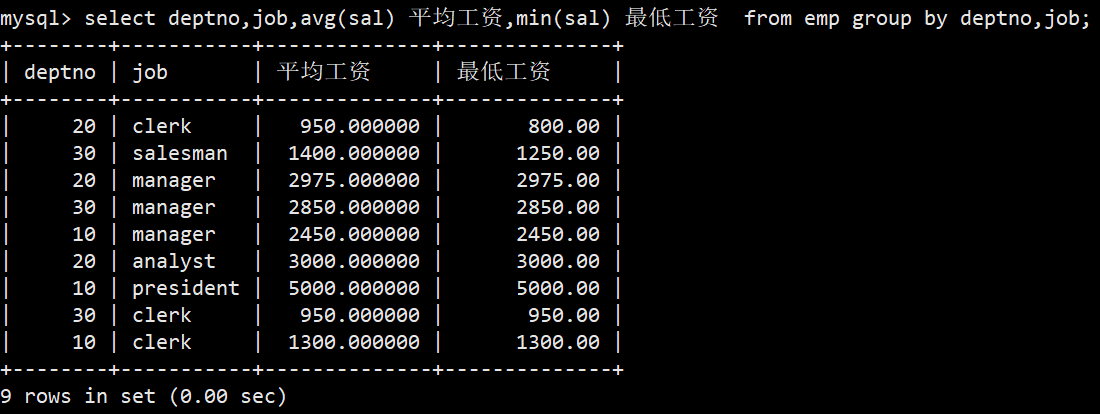
- 2.显示每个部门的每种岗位的平均工资和最低工资
- 解释:group by 后面可以指定多个分组字段,这里我们可以分组部门deptno和岗位job
- 语法:select deptno,job,avg(sal),min(sal) from emp group by deptno,job;
- 因为对两个字段进行了分组,所以不同部门相同岗位这样的就不是一组,只有相同部门和相同岗位才会被归为一组
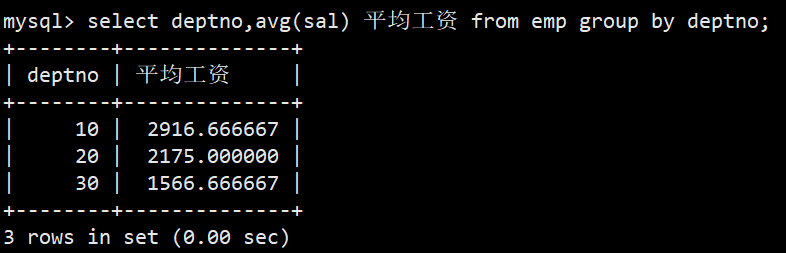
- 3.显示平均工资低于2000的部门和它的平均工资
- 我们可以先统计各个部门的平均工资:select deptno,avg(sal) 平均工资 from emp group by deptno;
- 再使用 having 配合 group by 进行进一步查询过滤:
- 语法:select deptno,avg(sal) 平均工资 from emp group by deptno having avg(sal) < 2000;
关于 having 和 where 的区别:
- where是对具体的任意列做条件筛选
- having是对分组聚合之后的结果进行条件筛选
- where 不能用聚合函数(如 avg、count),having 可以基于聚合函数筛选
- where 必须在 group by 之前,having 必须在 group by 之后

2.单表查询练习
**案例:**使用上面的emp员工表
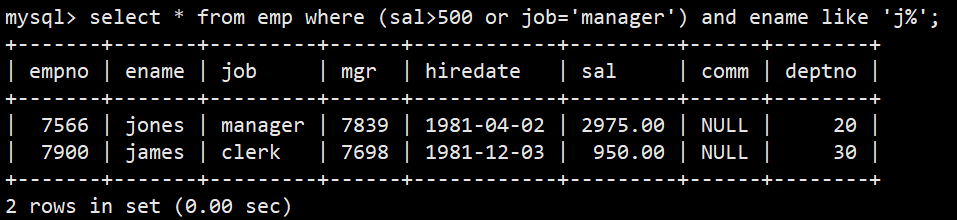
- 1.查询工资高于500或岗位为manager的雇员,同时还要满足他们的姓名首字母为大写的j
- 语法:select * from emp where (sal>500 or job='manager') and ename like 'j%';
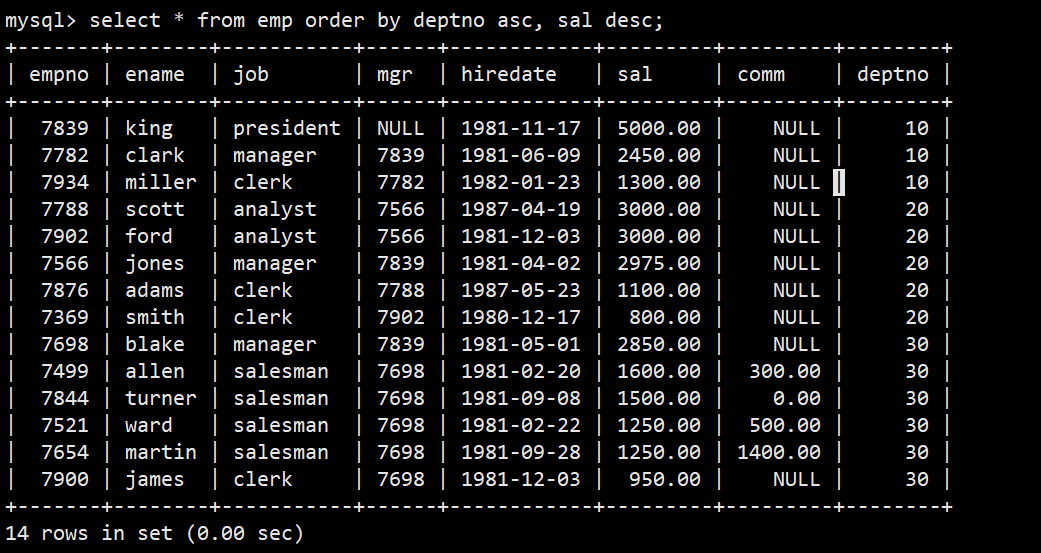
- 2.按照部门号升序而雇员的工资降序排序
- 语法:select * from emp order by deptno asc, sal desc;
- 解释:会先满足deptno升序,然后在deptno相同的情况下以sal降序
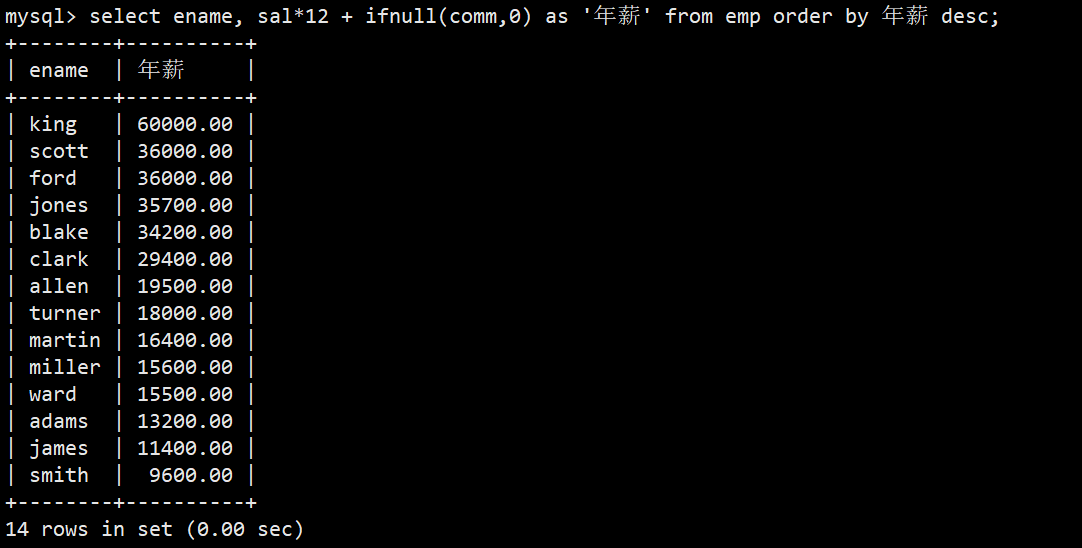
- 3.使用年薪进行降序排序
- 语法:select ename, sal*12 + ifnull(comm,0) as '年薪' from emp order by 年薪 desc;
- 解释:使用ifnull判断有没有奖金,ifnull使用介绍在下文其他函数中
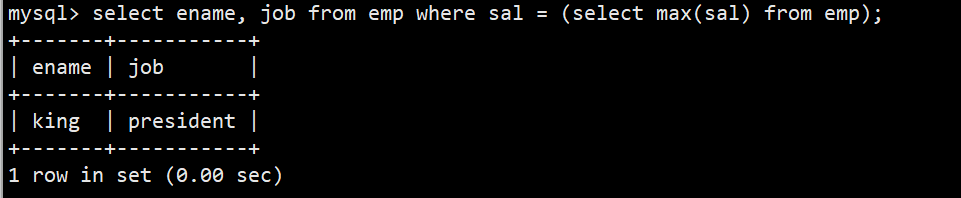
- 4.显示工资最高的员工的名字和工作岗位
- 语法:select ename, job from emp where sal = (select max(sal) from emp);(子查询)
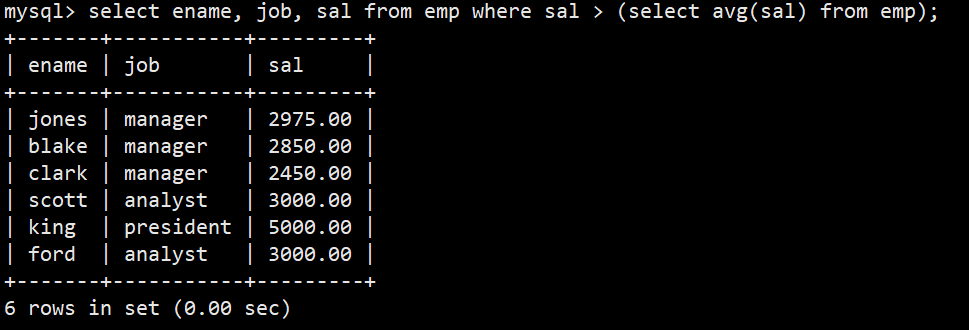
- 5.显示工资高于平均工资的员工信息
- 语法:select ename, job, sal from emp where sal > (select avg(sal) from emp);(子查询)
3.多表查询
实际开发中往往数据来自不同的表,所以需要多表查询
(1)笛卡尔积
- 以上面的oracle 9i的经典测试表为例,假如我们要查的数据包括员工名和其所在部门的部门名,那么部门名就只能去部门表中查了;
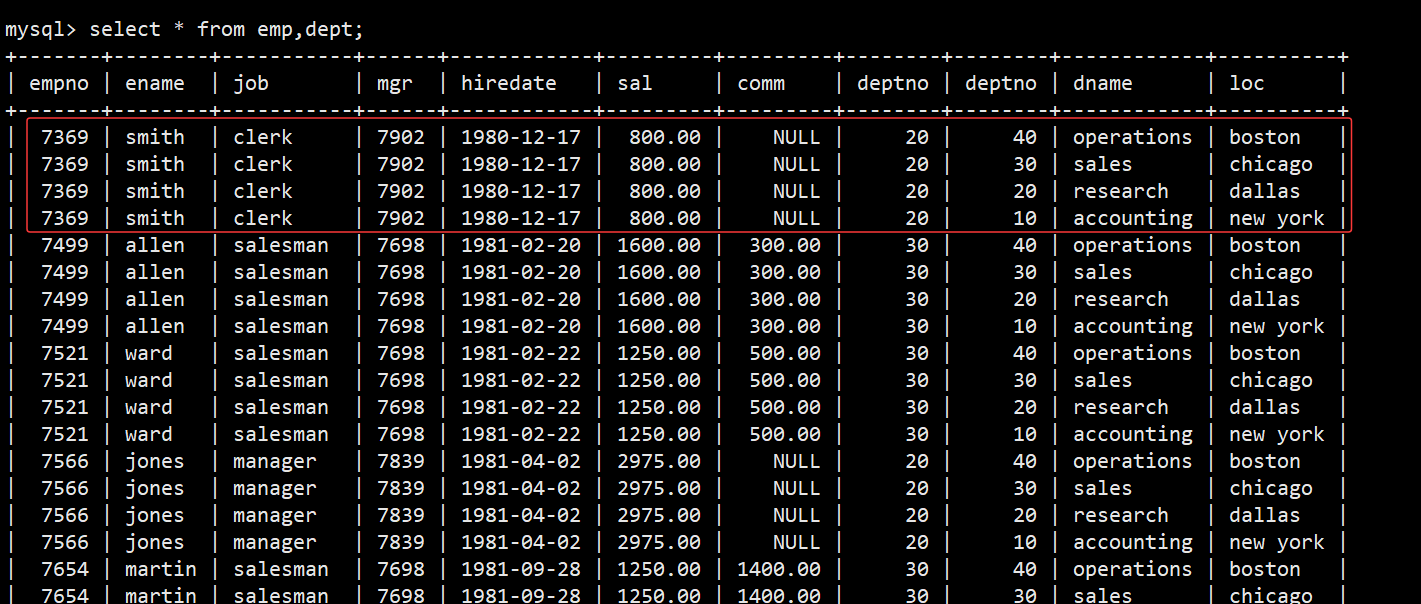
- 当我们直接查两张表会出现下面的效果:select * from emp,dept;
- 这里表显示太多了,截取一部分,我们可以看到查出来的两张表,其实是将两张表进行穷举组合形成一张新表,比如红色框内一个员工与4个部门的组合;
- 这种组合的计算方式就叫做 ---- 笛卡尔积
- 笛卡尔积结果集行数 = 表 A 的总行数 × 表 B 的总行数 × ... × 表 N 的总行数
**注意:**因为不同表有不同或相同字段名,因此在多表查询时,使用类似c++对象.成员的方式区分不同表的字段,例如emp表的ename字段就表示为:emp.ename
(2)多表查询案例
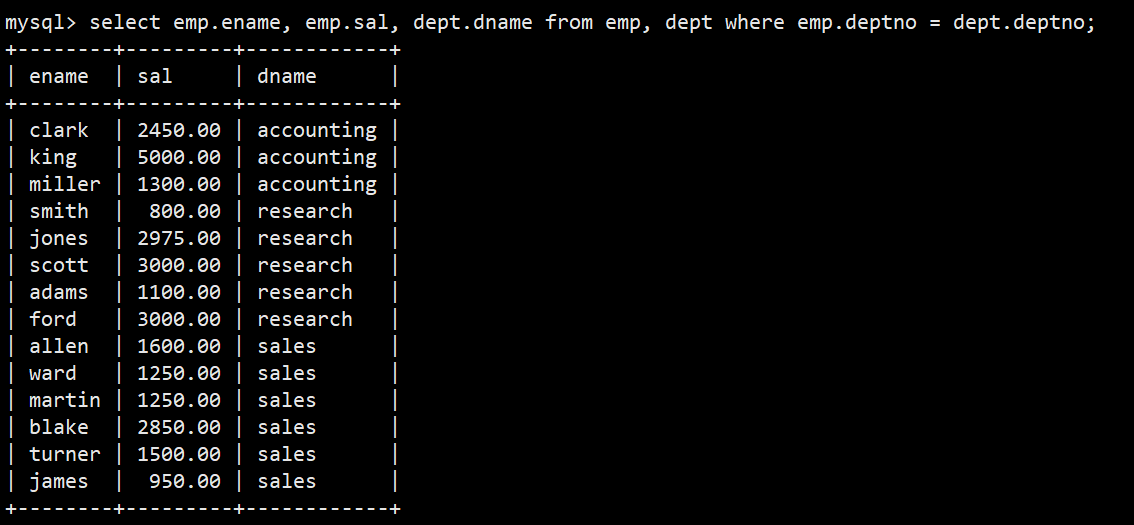
- 1.显示雇员名、雇员工资以及所在部门的名字
- 语法:select emp.ename, emp.sal, dept.dname from emp, dept where emp.deptno = dept.deptno;
- 解释:我们只需要在两者表的组合表中使用where自己过滤查询到两张表部门号相同的行信息即可;
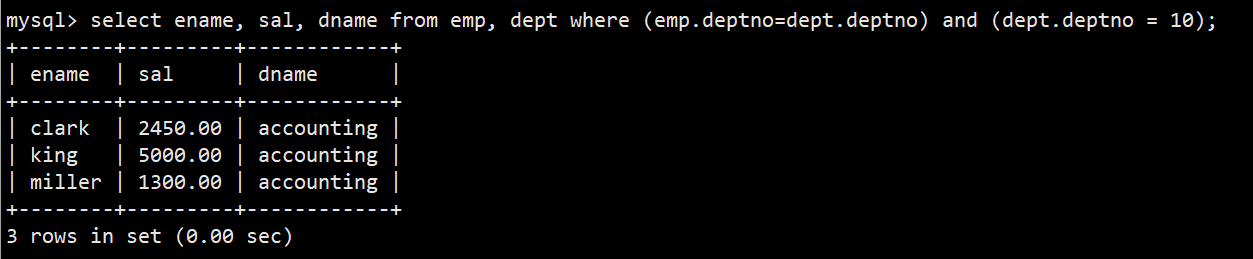
- 2.显示部门号为10的部门名,员工名和工资
- 语法:select ename, sal, dname from emp, dept where (emp.deptno=dept.deptno) and (dept.deptno = 10);
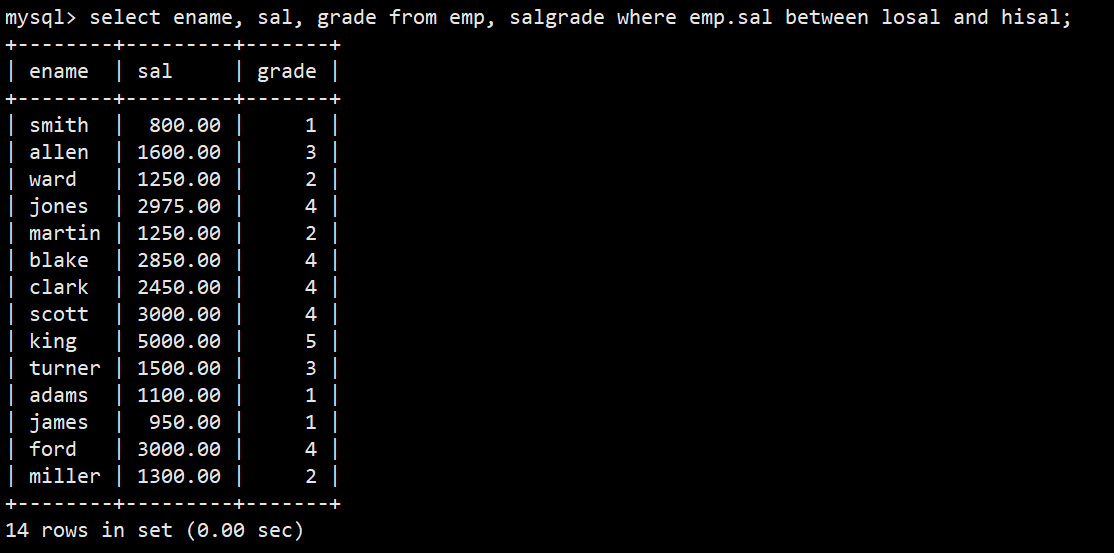
- 3.显示各个员工的姓名,工资,及工资级别
- 语法:select ename, sal, grade from emp, salgrade where emp.sal between losal and hisal;
4.自连接
自连接是指在同一张表连接查询
**用法:**在有些情况下,需要对自身表进行多次查询,为了一条语句解决,因此我们可以将自身表与自身表进行笛卡尔积组合
**注意:**自身笛卡尔积组合时,要重命名
**案例:**还是上面的oracle 9i的经典测试表
- 例:显示员工ford的上级领导的编号和姓名(mgr是员工领导的编号--empno)
- 解释:因为员工表emp既包含了普通员工也包含了领导,所以我们必须对这张表进行两次查询,这时候就可以用自连接了
- **语法:**select leader.empno, leader.ename from emp as leader, emp as worker where (leader.empno = worker.mgr) and (worker.ena= 'ename = 'ford');
- 语法解释:将插入的两张相同员工表分别重命名为 leader 和 worker,然后条件筛选员工名为ford的,并且其mgr与领导表的员工号empno相等的
当然也可以用子查询:select empno,ename from emp where emp.empno=(select mgr from emp where ename='FORD');这样就不用自连接了

5.子查询
概念: 子查询是将一个 SELECT 查询嵌套在另一个 SQL 语句的 WHERE/FROM/HAVING 等子句中,先执行内层嵌套查询,再将其结果作为外层语句的筛选、关联或计算依据的查询方式。
(以下案例还是使用oracle 9i的经典测试表)
(1)单行子查询
**概念:**内层只返 1 行结果,能直接跟 > < =用;
示例:
- 显示与smith同一部门的员工
- 语法:select * from emp where deptno = (select deptno from emp where ename = 'smith');
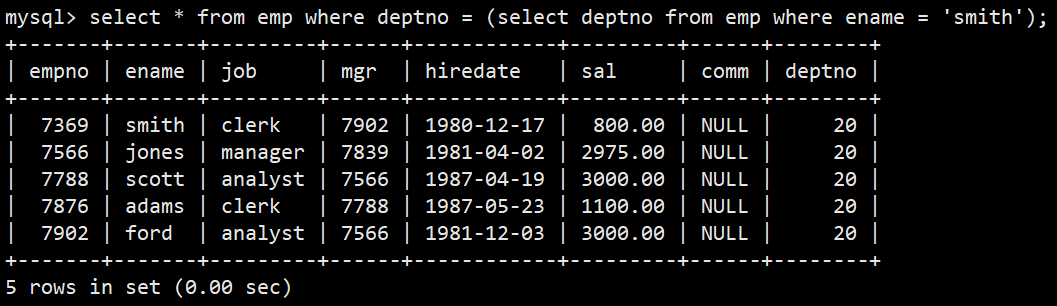
(2)多行子查询
概念: 内层返≥2 行结果,必须搭in/all/any才能用,直接用
=就报错。**关键字:**in/all/any是多行子查询中,外层查询与内层多行结果做条件匹配的关键字,其中in匹配任意一个,all匹配全部,any匹配任意一个(与in等效,仅语法场景有差异)
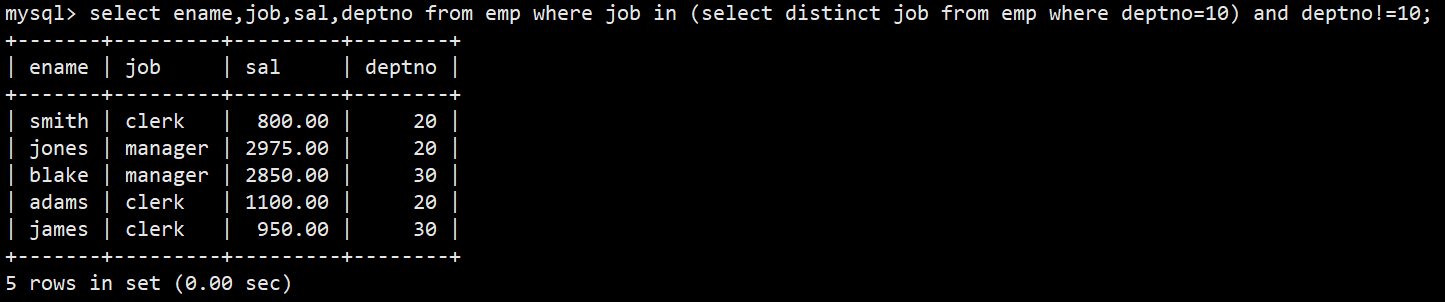
- 1.in关键字;查询和10号部门的工作岗位相同的雇员的名字,岗位,工资,部门号,但是不包含10自己的
- 语法:select ename,job,sal,deptno from emp where job in (select distinct job from emp where deptno=10) and deptno != 10;
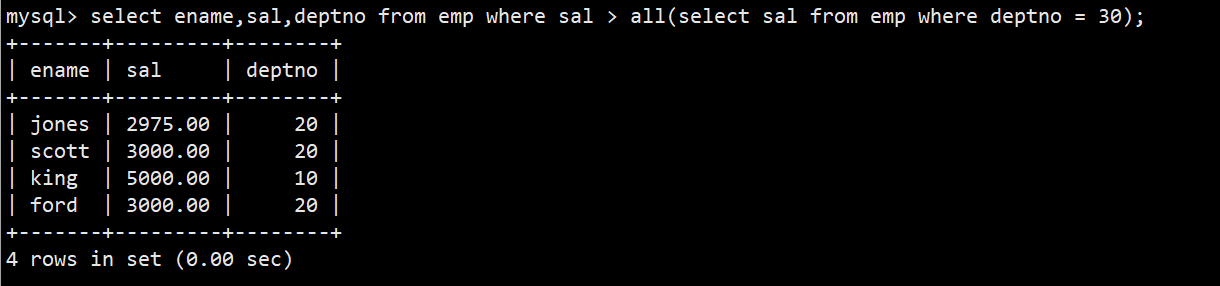
- 2.all关键字;显示工资比部门30的所有员工的工资高的员工的姓名、工资和部门号
- 语法:select ename,sal,deptno from emp where sal > all(select sal from emp where deptno = 30);
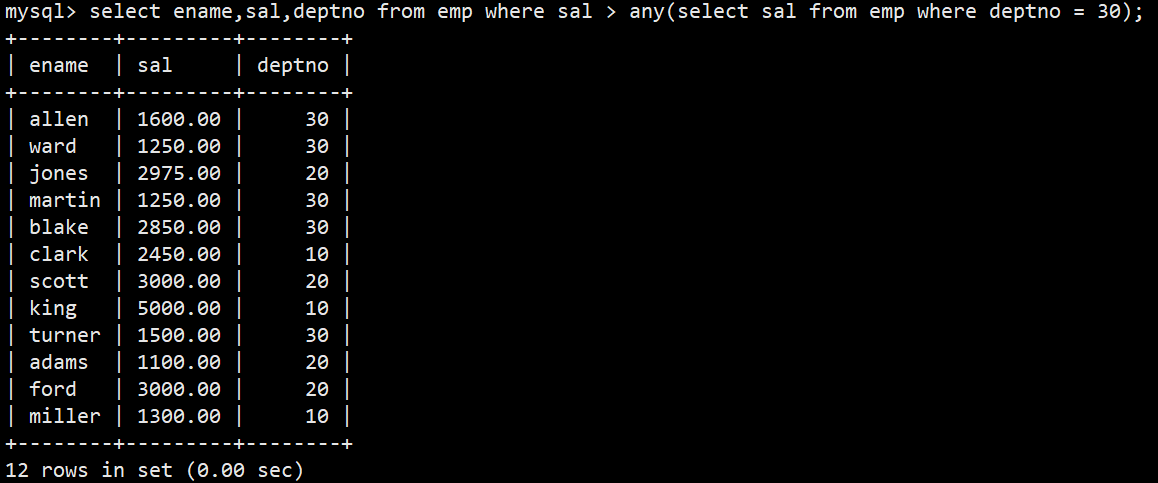
- 3.any关键字;显示工资比部门30的任意员工的工资高的员工的姓名、工资和部门号(包含自己部门的员工)
- 语法:select ename,sal,deptno from emp where sal > any(select sal from emp where deptno = 30);
(3)多列子查询
**概念:**单行子查询是指子查询只返回单列单行数据;多行子查询是指返回单列多行数据,都是针对单列而言的,而多列子查询则是指查询返回多个列数据的子查询语句
- 案例:查询和smith的部门和岗位完全相同的所有雇员,不含smith本人
- 语法:select ename from emp where (deptno, job) = (select deptno, job from emp where ename = 'smith') and ename != 'smith';

(4)在from子句中使用子查询
概念: 子查询语句出现在from子句中。这里要用到数据查询的技巧,把一个子查询当做一个临时表使用。
案例:
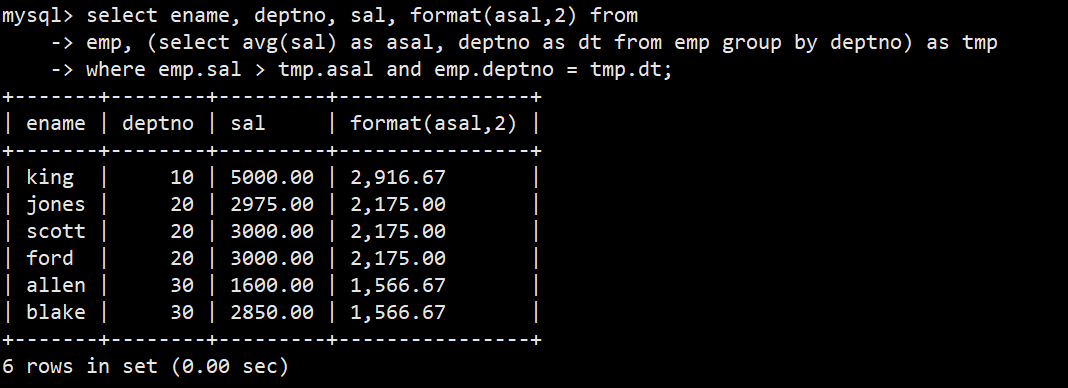
- 1.显示每个高于自己部门平均工资的员工的姓名、部门、工资、平均工资
- 语法:select ename, deptno, sal, format(asal,2) from emp, (select avg(sal) as asal, deptno as dt from emp group by deptno) as tmp where emp.sal > tmp.asal and emp.deptno = tmp.dt;
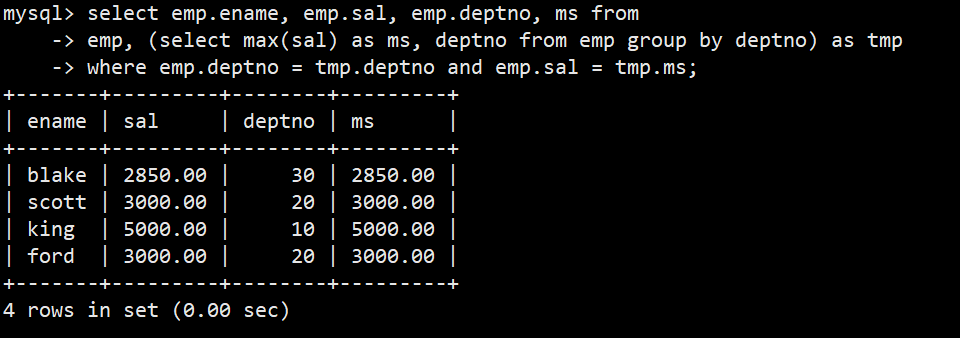
- 2.查找每个部门工资最高的人的姓名、工资、部门、最高工资
- 语法:select emp.ename, emp.sal, emp.deptno, ms from emp, (select max(sal) as ms, deptno from emp group by deptno) as tmp where emp.deptno = tmp.deptno and emp.sal = tmp.ms;
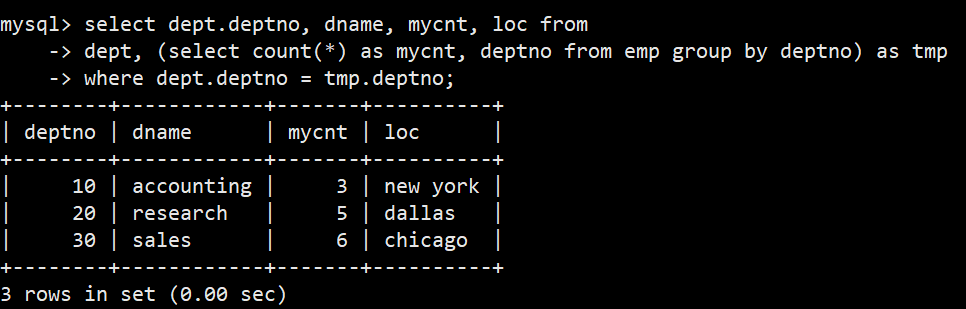
- 3.显示每个部门的信息(部门名,编号,地址)和人员数量
- 语法:select dept.deptno, dname, mycnt, loc from dept, (select count(*) as mycnt, deptno from emp group by deptno) as tmp where dept.deptno = tmp.deptno;
6.合并查询
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all
(1)union
概念: 该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行。
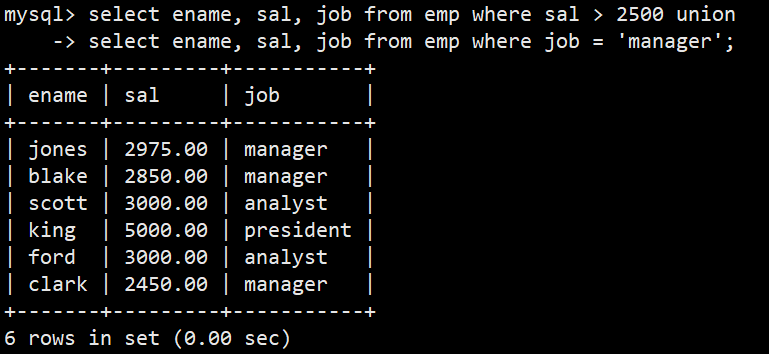
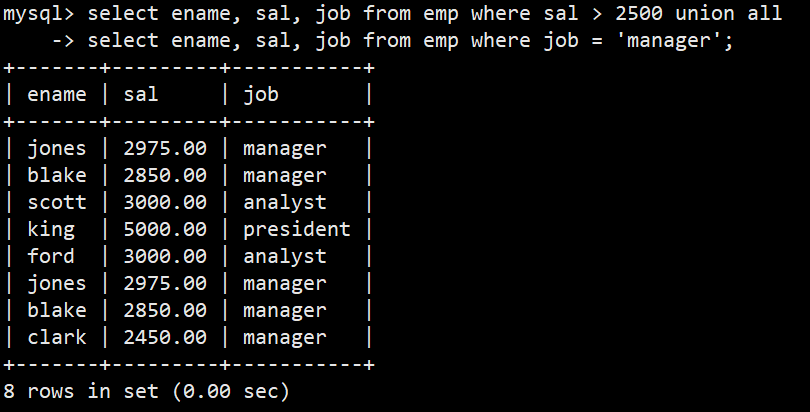
- 案例:将工资大于2500或职位是manager的人找出来
- 语法:select ename, sal, job from emp where sal > 2500 union select ename, sal, job from emp where job = 'manager';
(2)union all
概念: 该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行。
- 案例:将工资大于25000或职位是manager的人找出来
- 语法:select ename, sal, job from emp where sal > 2500 union all select ename, sal, job from emp where job = 'manager';
7.表的内连和外连
(1)内连接
概念: 内连接是通过关联条件(ON)只保留多张表中匹配关联条件的记录,不匹配的记录会被过滤掉的联表查询方式;内连接实际上就是利用where子句对两种表形成的笛卡儿积进行筛选,我们前面学习的查询都是内连接,也是在开发过程中使用的最多的连接查询。
语法:select 字段 from 表1 inner join 表2 on 连接条件 and 其他条件;
- 案例:显示smith的名字和部门名称
- 语法:select ename, dname from emp inner join dept on emp.deptno = dept.deptno and ename = 'smith';

(2)外连接
外连接分为左外连接和右外连接
2.1左外连接
**概念:**左外连接以左侧表为基准,保留左表所有记录,右表仅匹配关联条件的记录会显示,不匹配的字段填充 NULL 的联表查询方式;如果联合查询,左侧的表完全显示我们就说是左外连接。
语法:select 字段名 from 表名1 left join 表名2 on 连接条件;
2.2右外连接
**概念:**右外连接以右侧表为基准,保留右表所有记录,左表仅匹配关联条件的记录会显示,不匹配的字段填充 NULL 的联表查询方式;如果联合查询,右侧的表完全显示我们就说是右外连接。
语法:select 字段 from 表名1 right join 表名2 on 连接条件;
**案例:**oracle 9i的经典测试表
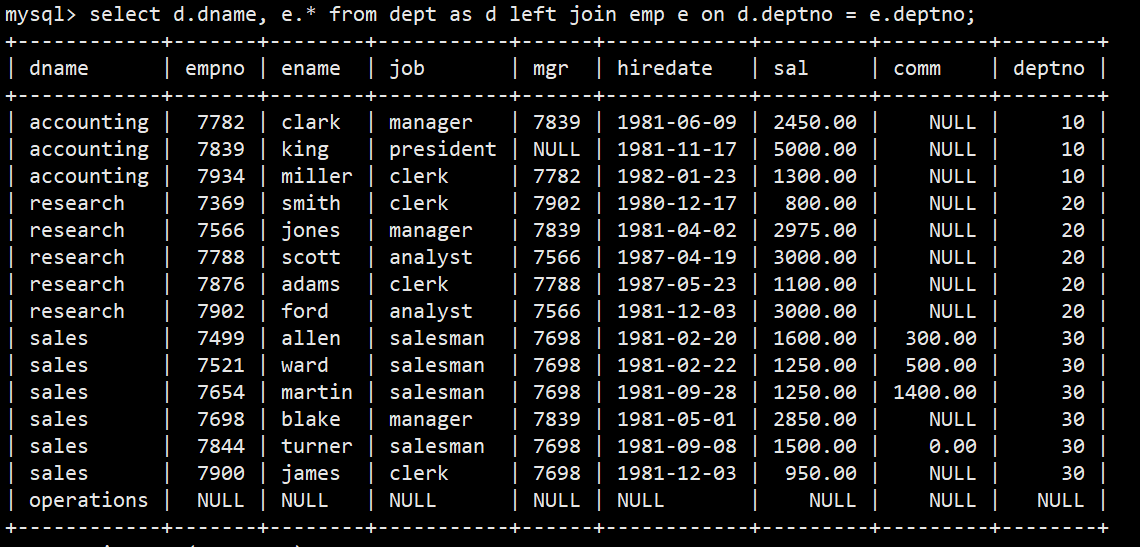
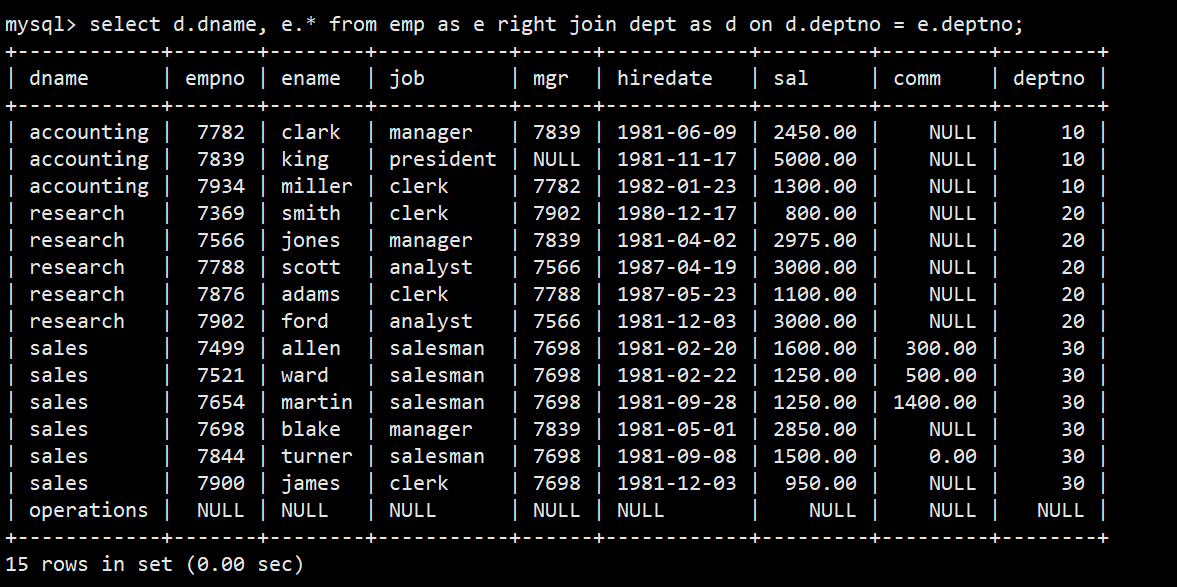
- 列出部门名称和这些部门的员工信息,同时列出没有员工的部门
- 左外连接:select d.dname, e.* from dept as d left join emp e on d.deptno = e.deptno;
- 右外连接:select d.dname, e.* from emp as e right join dept as d on d.deptno = e.deptno;
- 可以看到operations部门信息都为空
四、理解数据库
1.为什么要有数据库?文件也能储存数据啊
文件保存数据有以下几个缺点:
- 文件的安全性问题
- 文件不利于数据查询和管理
- 文件不利于存储海量数据
- 文件在程序中控制不方便
数据库存储介质:
- 磁盘
- 内存
所以,为了解决上述问题,专家们设计出更加利于管理数据的东西------数据库,它能更有效的管理数据
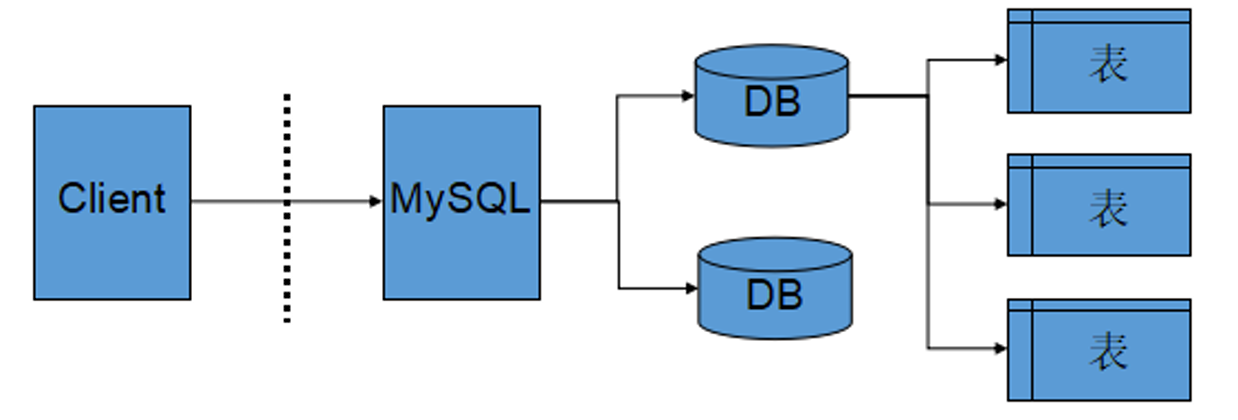
2.服务器、数据库、表之间的关系
- 所谓安装数据库服务器,只是在机器上安装了一个数据库管理系统程序,这个管理程序可以管理多 个数据库,一般开发人员会针对每一个应用创建一个数据库
- 为保存应用中实体的数据,一般会在数据库中创建多个表,以保存程序中实体的数据
- 数据库服务器、数据库和表的关系如下:
3.数据类型
(1)数值类型
|-------------------------------|------------------------------------------------------------------------|
| 数据类型 | 说明 |
| bit(m) | 位类型;m 指定位数,默认值 1,m范围 1-64;查询时默认以ASCII值显示 |
| tinyint unsigned | 1字节整数;带符号的范围 - 128~127,无符号范围 0~255;默认有符号 |
| bool | 使用 0 和 1 表示真和假;占1字节 |
| smallint unsigned | 2字节整数;带符号是 - 2^15 到 2^15-1,无符号是 2^16-1 |
| int unsigned | 4字节整数;带符号是 - 2^31 次方 到 2^31-1,无符号是 2^32-1 |
| bigint unsigned | 8字节整数;带符号是 - 2^63 次方 到 2^63-1,无符号是 2^64-1 |
| float(m,d)unsigned | m 指定显示长度,d 指定小数位数,占用 4 字节 |
| double(m,d) unsigned | 表示比 float 精度更大的小数,占用空间 8 字节 |
| decimal(m,d) unsigned | 定点数 m 指定总长度,d 表示小数点的位数;底层字符串精确存储,占用空间动态,每 9 位数字占用 4 字节,不足 9 位也按 4 字节计算 |
(2)文本、二进制类型
|-------------------|--------------------------------------|
| 数据类型 | 说明 |
| char(size) | 固定长度字符串,最大长度 255字节; |
| varchar(size) | 可变长度字符串,最大长度 65535字节;编码不同实际可设置的最大值不同 |
| blob | 二进制数据 |
| text | 大文本,不支持全文索引,不支持默认值 |
(3)时间日期
|-----------------------------|---------------------------------------------------------------------------|
| 数据类型 | 说明 |
| date/datetime/timestamp | 日期类型(yyyy-mm-dd)/(yyyy-mm-dd hh:mm:ss)/ timestamp 带时间戳 每次修改能够自动更新时间 |
(4)String类型
|----------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 数据类型 | 说明 |
| enum | enum 是一个字符串对象,其值来自表创建时在规定中显示枚举的一列值;相当于单选,如选性别enum('男','女');插入对应值时必须是设置的选项或者下标(从0开始) |
| set | set 是一个字符串对象,可以有零或多个值,其值来自表创建时规定的允许的一列值。指定多个 set 成员的 set 列值时各成员之间用逗号间隔开。该 set 成员值本身不能包含逗号;相当于多选,如选兴趣爱好set('爱好1', '爱好2' ...);set可以一次插入多个选项,用单引号括起来,逗号分隔;也可以把所有选项看作比特位,最左边选项对应比特位右边最低位,比特位对应的十进制数字可以一次选多个选项 |
数据类型是对字段的约束,但是数据类型约束很单一,需要有一些额外的约束,更好的保证数据的合法性
4.表的约束
表的约束:表中一定要有各种约束,通过约束,让我们未来插入数据库表中的数据是符合预期的。约束木质是通过技术手段,倒逼程序员,插入正确的数据。反过来,站在 mysql 的视角,凡是插入进来的数据,都是符合数据约束的!
约束的最终目标:保证数据的完整性和可预期性
约束有很多,这里介绍如下几个:
(1)空属性
两个值:null 和 not null
**作用:**约束该字段能否为空,null可以为空,null不用特意设置,默认字段就是可以为空;not null不可以为空;
示例:
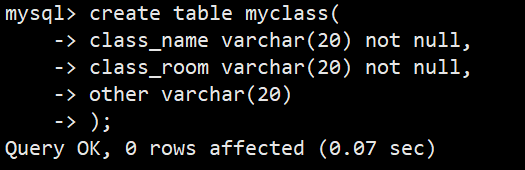
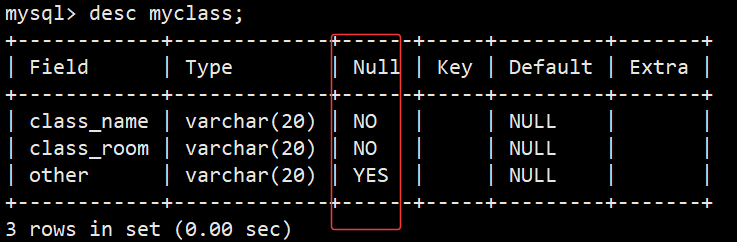
- 创建一个简单班级表,class_name 和 class_room 字段不能为空,other字段可以为空,表结构如下图:
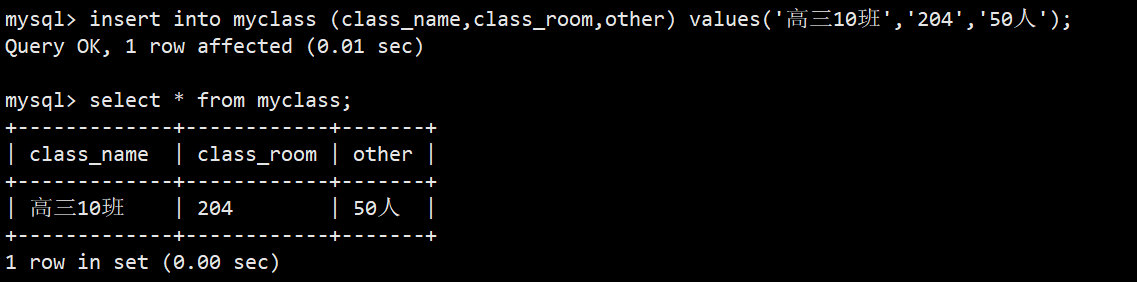
- 如图框住部分就是我们设置的空属性约束,NO就是不能为空,YES就是可以为空;此时我们往表里面分别插入完整数据和缺省数据看看效果:
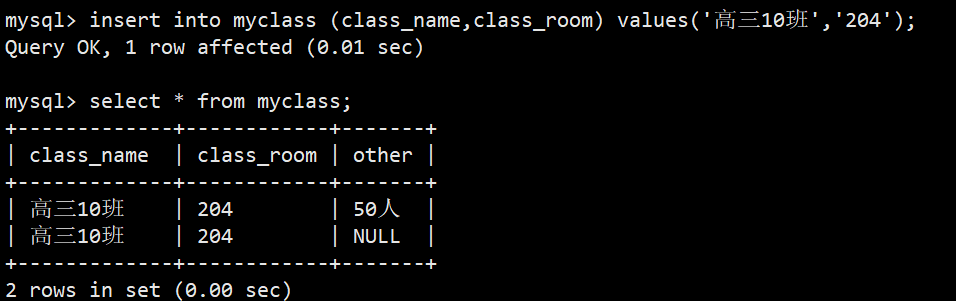
- 可以看到,前两次插入数据class_name和class_room都插入了具体数据,没有问题,other字段也可以省略;第三次是当我们不给class_room插入具体数据时就会报错;这就是空约束的效果

(2)默认值
**关键字:**default
**默认值:**某一种数据会经常性的出现某个具体的值,可以在一开始就指定好,在需要真实数据的时候, 用户可以选择性的使用默认值;相当于c++中的缺省值;
示例:
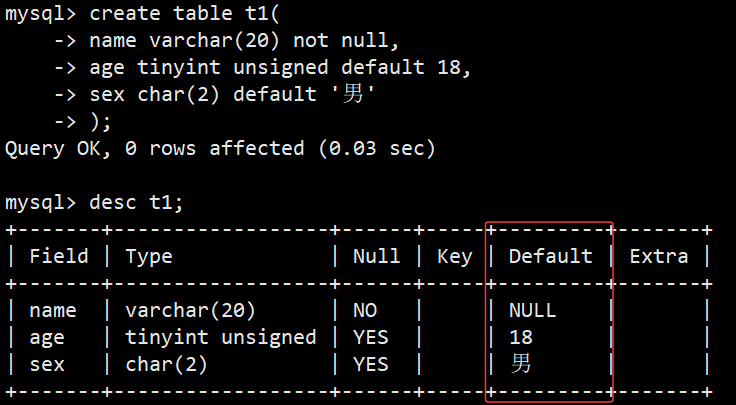
- 创建一张表,name字段不能为空,age字段默认值为18,sex字段默认男;如图可以从框住部分看到默认值;
- 当我们插入数据时,不给有默认值的插入就会自动使用默认值插入;
关于默认值和空属性:
结论:
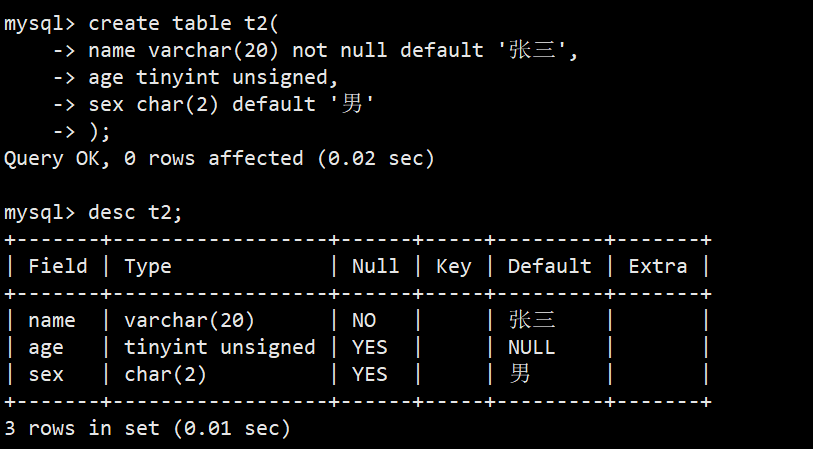
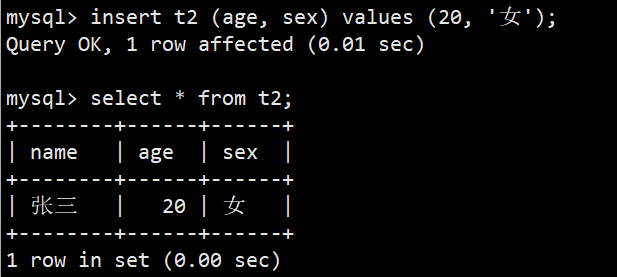
- 从主观感受上,default 和 not null 好像有点不搭,但其实这两者并不冲突,而是互相补充;如果一个字段同时设置的 not null 和 default,那么当用户插入数据时忽略这一列,mysql就会自动使用default的值插入
- 一个字段只有数据类型,没有手动设置任何约束时,它的默认值default其实是NULL,也就是可为NULL空
验证:
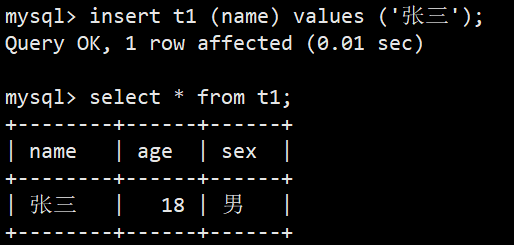
- 如上面这张表,当我们插入数据时忽略name字段,就会使用默认值:
- 通过查看建表语句,就可以看到age字段其实是带有默认值,这是mysql自动补全的
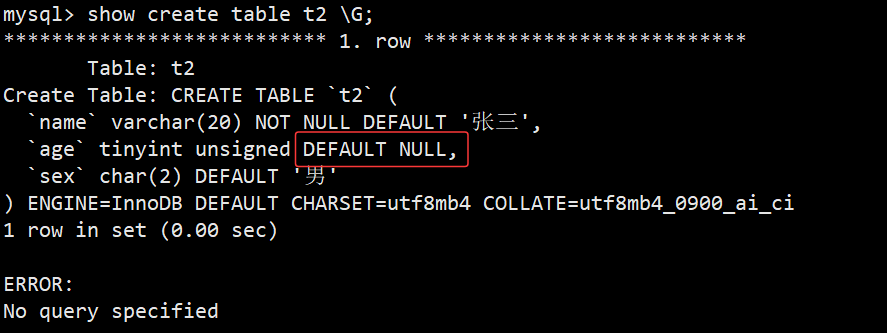
(3)列描述
**关键字:**comment
**列描述:**没有实际含义,专门用来描述字段,会根据表创建语句保存,用来给程序员或DBA 来进行了解;简单来说就是对字段的一种备注说明,在上面创建表时已经演示过了,这里不再演示;列描述不显示在 desc 的表结构中,查看需要show查看建表语句;
**如何理解comment是一种约束:**它可以看成是对程序员的一种软约束,当我们看到该字段的描述时,就能知道该字段的含义,以及应该插入什么样的数据;
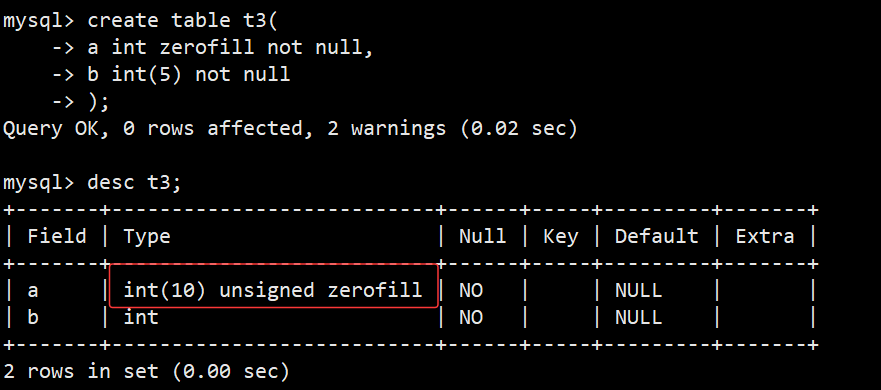
(4)zerofill
zerofill:是所有数值类型(整数 / 浮点 / 定点)通用属性 ,核心功能为按字段定义的显示宽度对数值左侧补 0(仅作用于查询显示,不改变实际存储值),使用时会自动为字段添加unsigned无符号属性,无法存储负数。
示例:
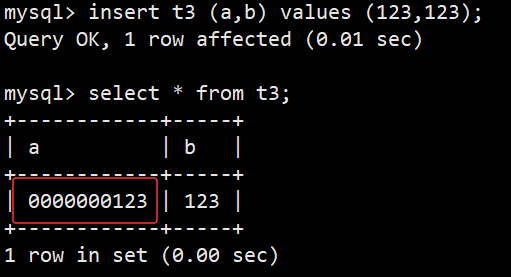
- 如图,创建表t3时,a字段后面没有跟括号数字,但是desc显示是10,这个数字是指整形的显示宽度(默认不指定就是10),对实际存储大小无影响,但是搭配zerofill,就能指定左侧补0的最大长度了;并且zerofill会自动将a字段设置为unsigned无符号整形;
- 插入数据的效果如上图所示,会在左侧剩余显示宽度处补0,如果超过设置的显示宽度就不会补0了;
(5)主键
**关键字:**primary key
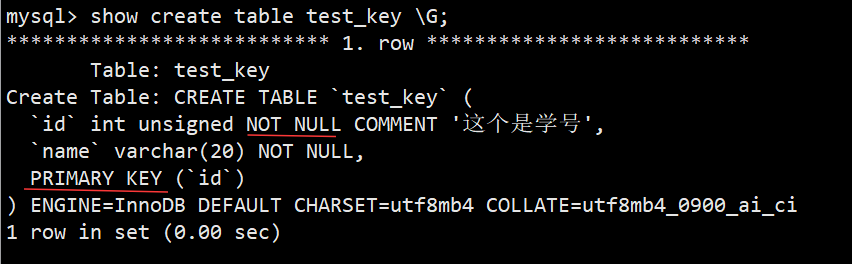
主键: primary key 是一张表中唯一且不能为空的标识字段,能唯一确定表中的每一行数据,自带唯一索引加速查询,一张表只能有一个 primary key,用于保证数据不重复、不缺失,是数据定位与关联表的核心依据;主键所在的列通常是整数类型。
注意: 主键一张表仅能定义一个,并非限制仅一个字段能作为主键组成部分,该主键既可是单个字段的单字段主键 ,也可是多个字段联合组成的复合主键。
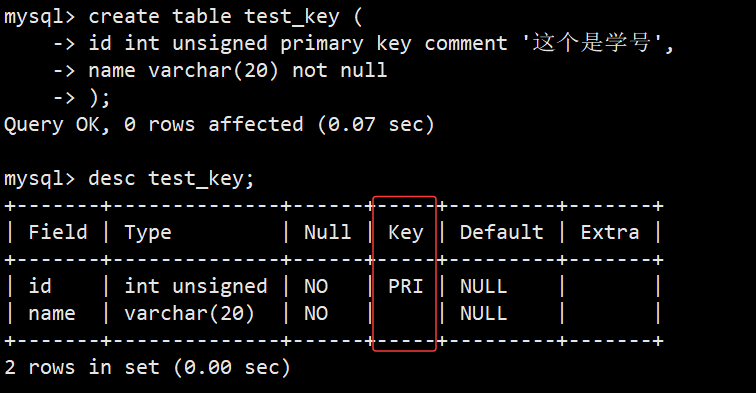
(1)两种建表时设置主键的方法:
- 第一种就是在字段类型后面跟上 primary key,表结构中 PRI 所在的行就是主键
- 通过建表语句我们就能看到第二种设置主键方式,就是在建表的最后一行使用 primary key(字段...) 进行设置,然后我们也能看到设置主键的字段会自动设置为 not null 约束;
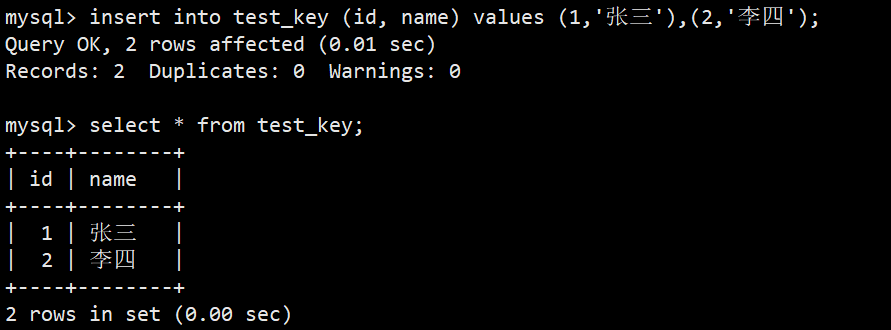
(2)主键的特性、删除操作、建表后添加操作:
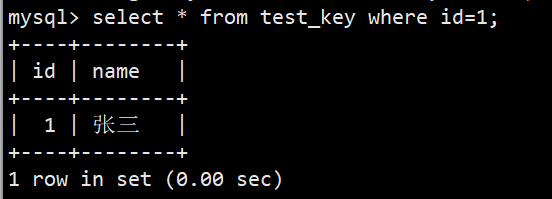
- 可以看到,当插入数据的 id 不重复时,可以正常插入,可是一旦插入重复的,就会报错,这就是一张表中主键唯一的特性;
- 通过该特性,我们可以很轻易通过where子句查询到主键对应的一列数据,如下图:
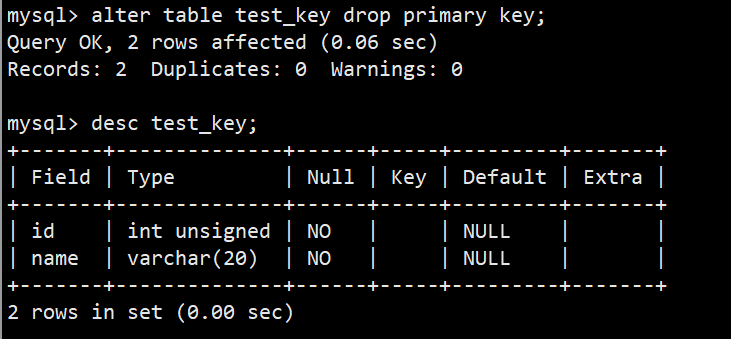
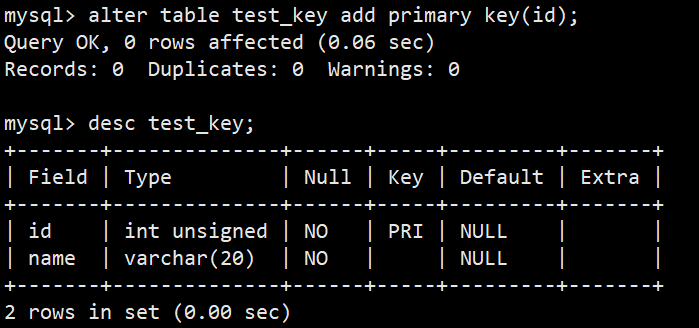
- 如何删除主键约束:使用 alter table 表名 drop primary key; 如下图:
- 后续如何设置主键:alter table 表名 add primary key(字段列表); 如下图:
(3)关于复合主键,简单点说就是两个及以上的字段都设置为主键,这些主键字段只要插入的数据组合不是完全一样的就没有问题;如下:
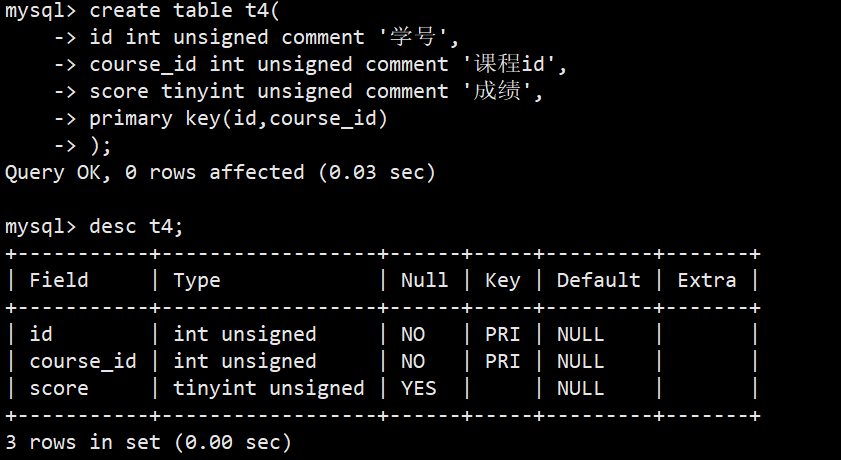
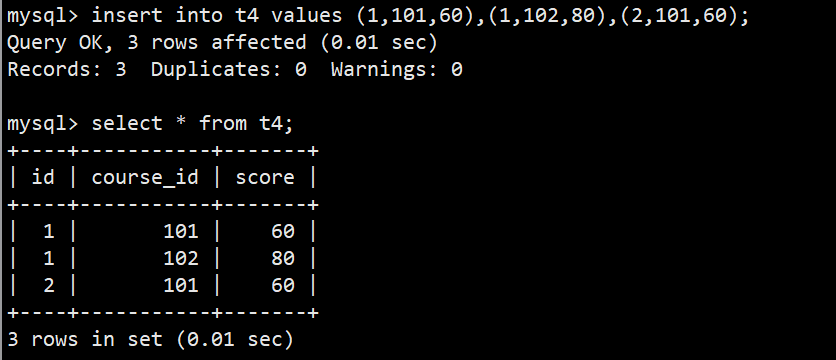
- 我们创建一个存储学生课程及其成绩的表,因为学生可以选多个课程,一个课程又可能被多个学生选,所以这种场景我们就可以把学生id和课程id都设置为主键;当我们插入数据时,只要不是插入相同的学生id和课程id就不会报错:
- 一旦插入与历史主键数据一样的就会报错:


(6)自增长
**自增长:**auto_increment;当对应的字段,不给值,会自动的被系统触发,系统会从当前字段中已经有的最大值 +1操作,得到一个新的不同的值。通常和主键搭配使用,作为逻辑主键。
自增长的特点:
- 任何一个字段要做自增长,前提是本身是一个索引(key一栏有值)也就是主键
- 自增长字段必须是整数
- 一张表最多只能有一个自增长
示例:
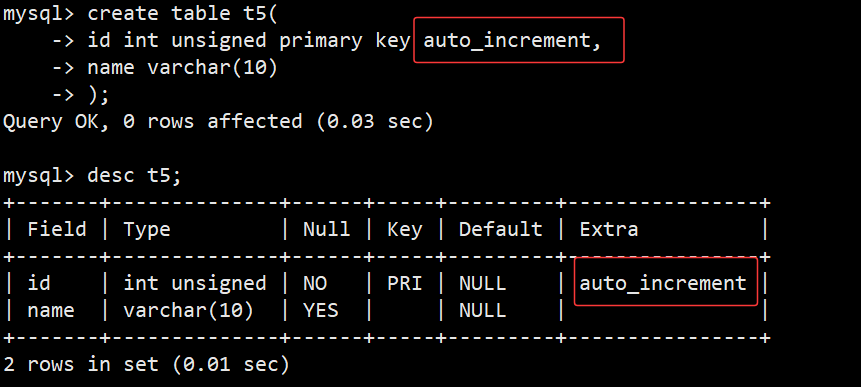
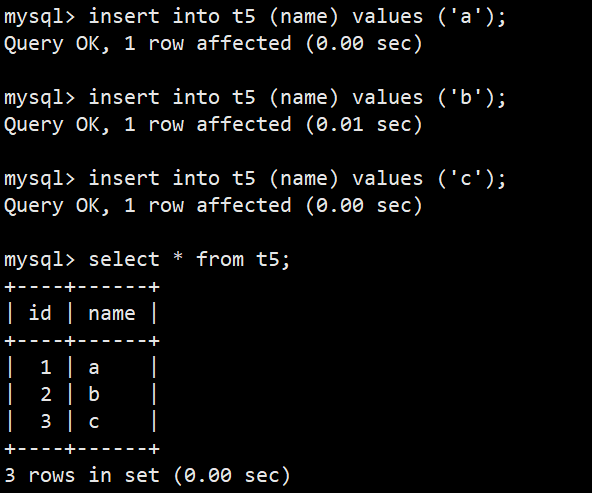
- 我们将id字段设置为主键并且自增,后面我们插入时可以忽略id字段直接插入name字段,id自动则会从0开始自增;如下图:
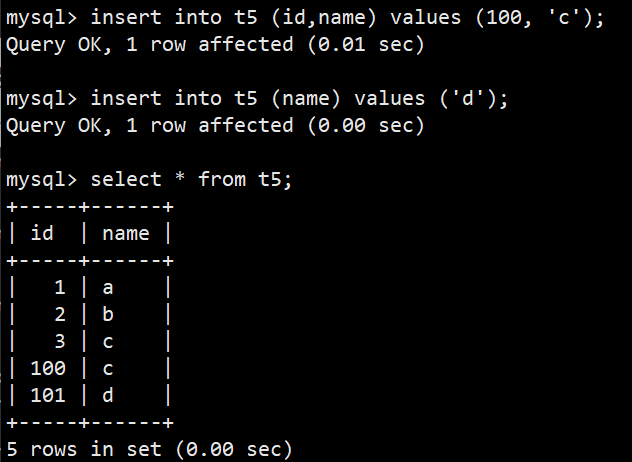
- 如果我们显示的给id插入一个较大的值,那么下次自增长将会从这个较大值开始递增;如下图:
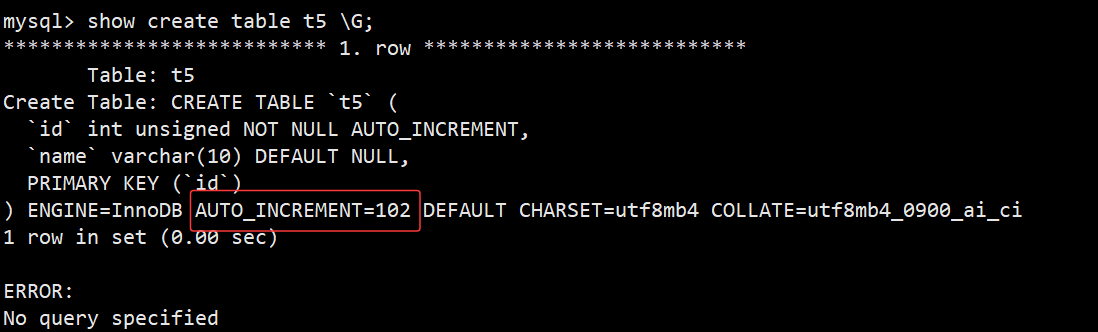
- 为什么设置了auto_increment的字段可以根据最新插入的值进行递增呢?原因我们可以通过查看建表语句看到:
- 如图,红色框内就是该表下次自增的值,我们也可以手动修改设置这个值,来控制下一次从多少开始自增;
- 手动修改语法:alter table 表名 auto_increment = 起始数值;
(7)唯一键
**唯一键:**unique key;一张表中有往往有很多字段需要唯一性,数据不能重复,但是一张表中只能有一个主键:唯一键就可以解决表中有多个字段需要唯一性约束的问题。
唯一键和主键的区别:
- 主键一张表只能有一个,并且不能为空;唯一键一张表可以设置多个,并且可以为空;
- 主键是表中行数据的唯一标识,用于精准定位单条数据、关联其他表(外键关联常用);唯一键仅用于保证数据唯一性,无行标识的核心作用;
**用途:**我们可以简单理解成,主键更多的是标识唯一性的。而唯一键更多的是保证在业务上,不要和别的信息出现重复;主键和唯一键是互相补充的;
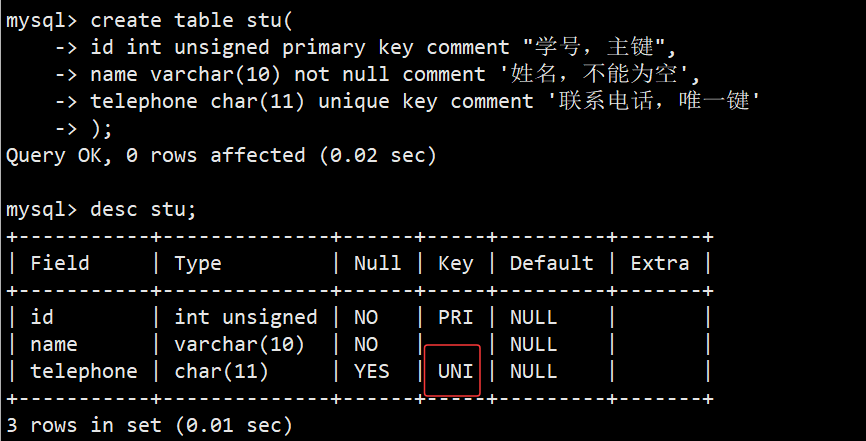
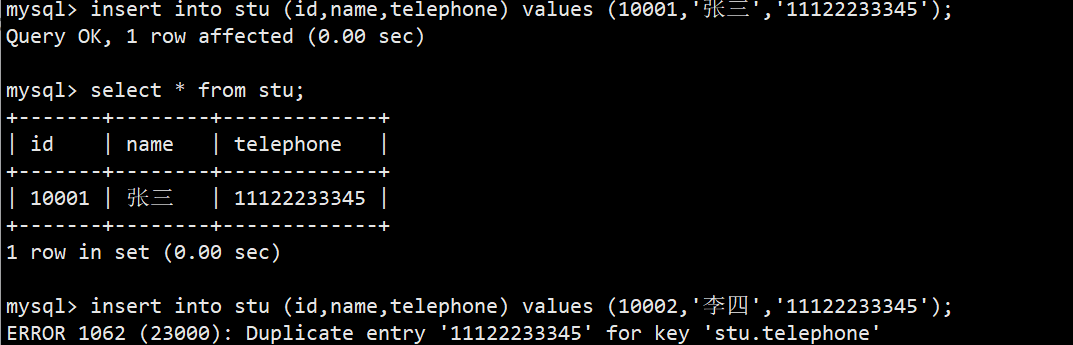
示例:
- 如上图,我们创建一张表stu,id字段设置为主键,而telephone字段设置为唯一键;唯一键的效果上看和主键差不多,都是不准插入重复值,如下图:
(key可以省略直接写unique效果一样)
(8)外键
**外键:**外键用于定义主表和从表之间的关系:外键约束主要定义在从表上,主表则必须是有主键约束或 unique 唯一键约束。当定义外键后,要求外键列数据必须在主表的主键列存在或为null。
**语法:**foreign key (当前从表字段名) references 主表名(主表字段)
举例解释:
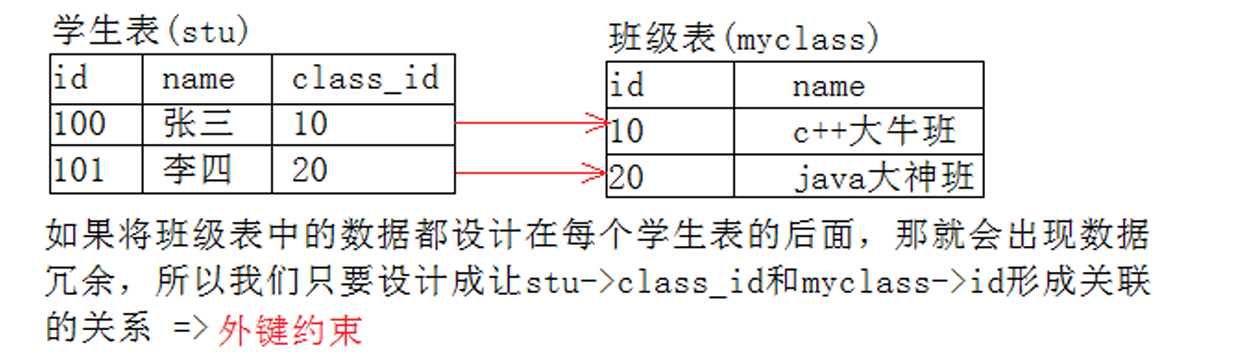
- 现在有一张班级表,班级表包括班级id和班级名字name;还有一张学生表,学生表包括学号id,姓名name,还有所属班级class_id;很明显主观上这两张表就有关系,就是学生表中的class_id字段与班级表中的id字段;所以这里学生表就是从表,班级表就是主表;学生表就是通过class_id与班级表进行关联;示意图如下:
演示:
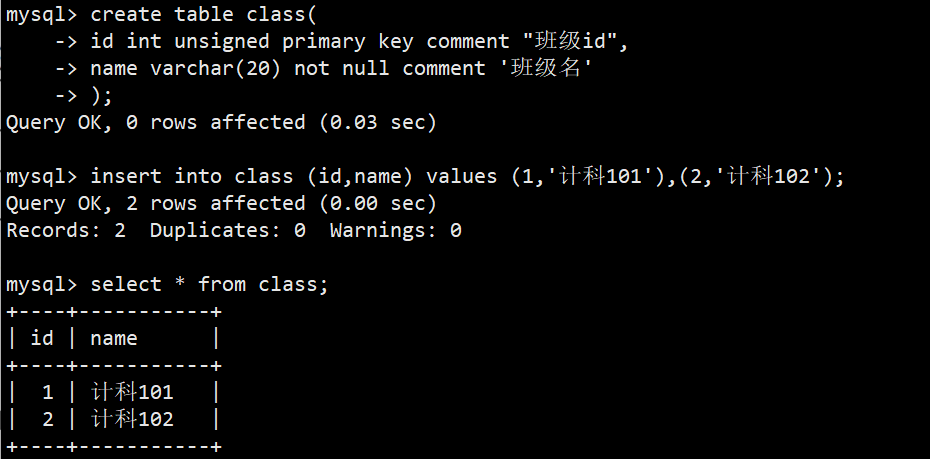
- 我们先定义主表,班级表class,并插入一些数据,如下图:
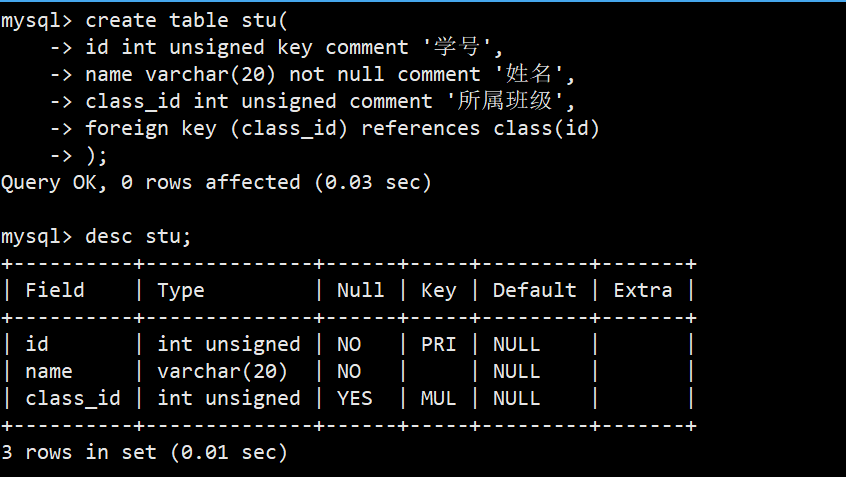
- 然后,再定义学生表,并设置外键class_id,如下图:
- 我们再往学生表里插入数据,如下图:
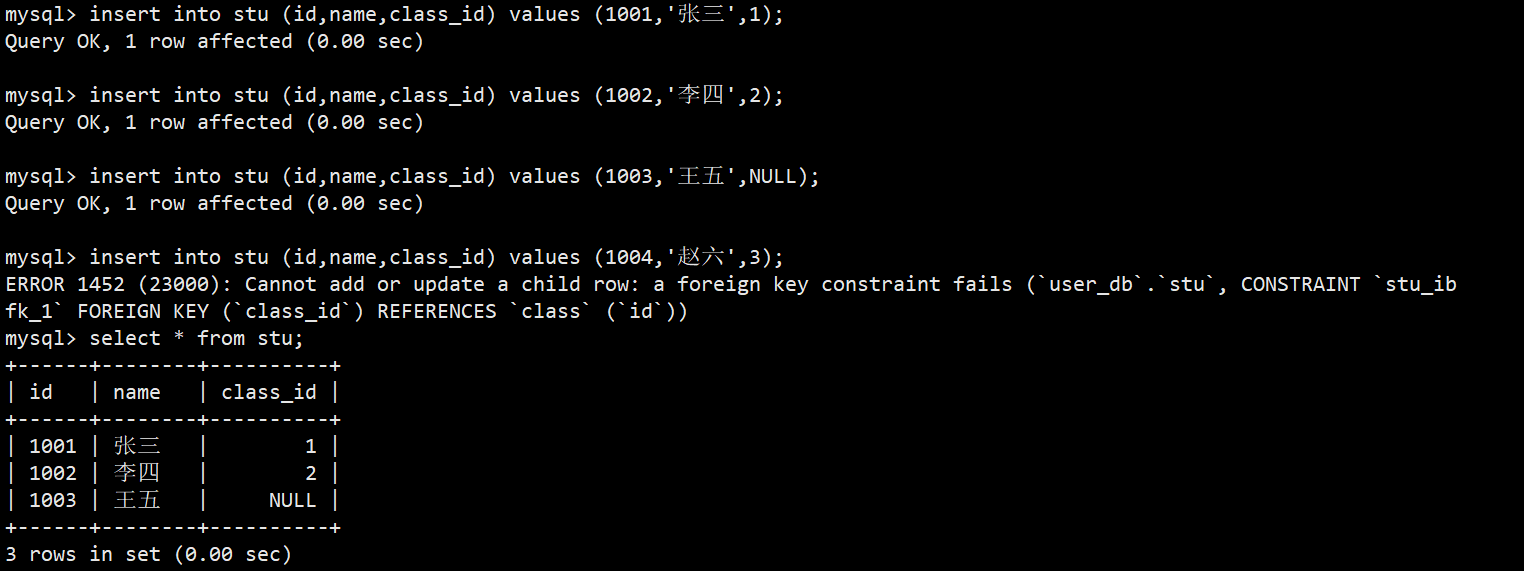
- 很明显,外键我们可以插入已有班级id,也可以插入NULL,但是不能插入不存在的班级id;
- 另外如果我们删除班级表中id=1的数据,我们会发现删除不了,如下图:
- 删除不了是因为对应班级id里关联了学生表中的数据,这就是外键的约束,能使表操作更加科学合理;

5.内置函数
(1)日期函数
|---------------------------------------|----------------------------------------------------------|
| 函数名称 | 描述 |
| current_date() | 当前日期 |
| current_time() | 当前时间 |
| current_timestamp() | 当前时间戳 |
| date(datetime) | 返回 datetime 参数的日期部分 |
| date_add(date, interval d_value_type) | 在 date 中添加日期或时间interval 后的数值单位可以是:year minute second day |
| date_sub(date, interval d_value_type) | 在 date 中减去日期或时间interval 后的数值单位可以是:year minute second day |
| datediff(date1, date2) | 两个日期的差,单位是天 |
| now() | 当前日期时间 |示例:
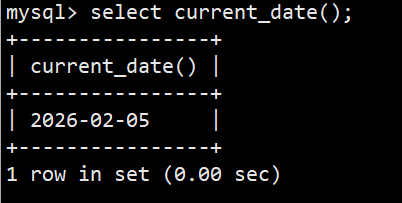
- 语法:select current_date();
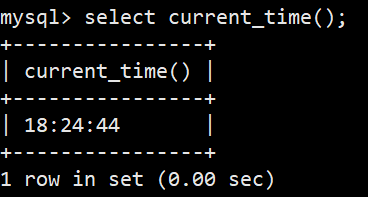
- 语法:select current_time();
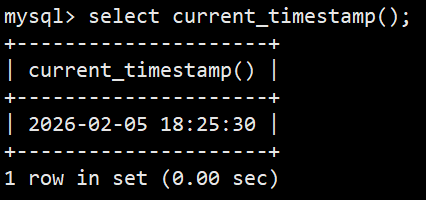
- 语法:select current_timestamp();
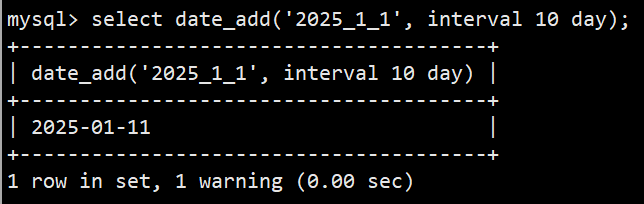
- 语法:select date_add('2025_1_1', interval 10 day); 加10天
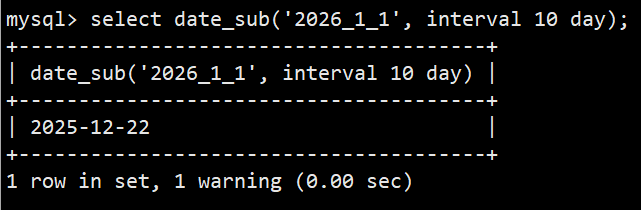
- 语法:select date_sub('2026_1_1', interval 10 day); 减10天
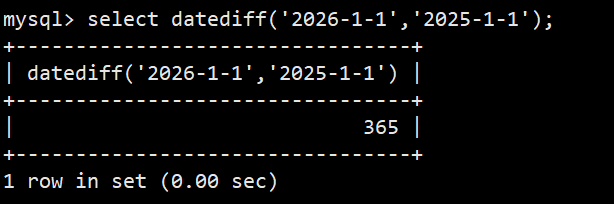
- 语法:select datediff('2026-1-1','2025-1-1'); 日期差
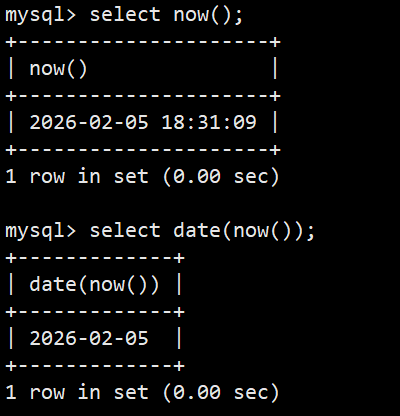
- date和now:
(2)字符串函数
|------------------------------------------|-------------------------------------|
| 函数名称 | 描述 |
| charset(str) | 返回字符串字符集(编码) |
| concat(string2 ,...) | 连接字符串 |
| instr(string, substring) | 返回 substring 在 string 中出现的位置,没有返回 0 |
| ucase(string2) | 转换成大写 |
| lcase(string2) | 转换成小写 |
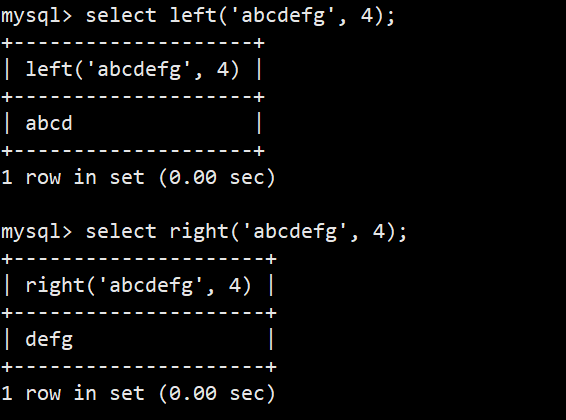
| left(string2, length) | 从 string2 中的左边起取 length 个字符 |
| length(string) | string 的长度 |
| replace(str, search_str, replace_str) | 在 str 中用 replace_str 替换 search_str |
| strcmp(string1, string2) | 逐字符比较两字符串大小 |
| substring(str, position, length) | 从 str 的 position 开始,取 length 个字符 |
| ltrim(string)、rtrim(string)、trim(string) | 去除前空格或后空格 |
- 与left(string2, length)对应的还有一个right:
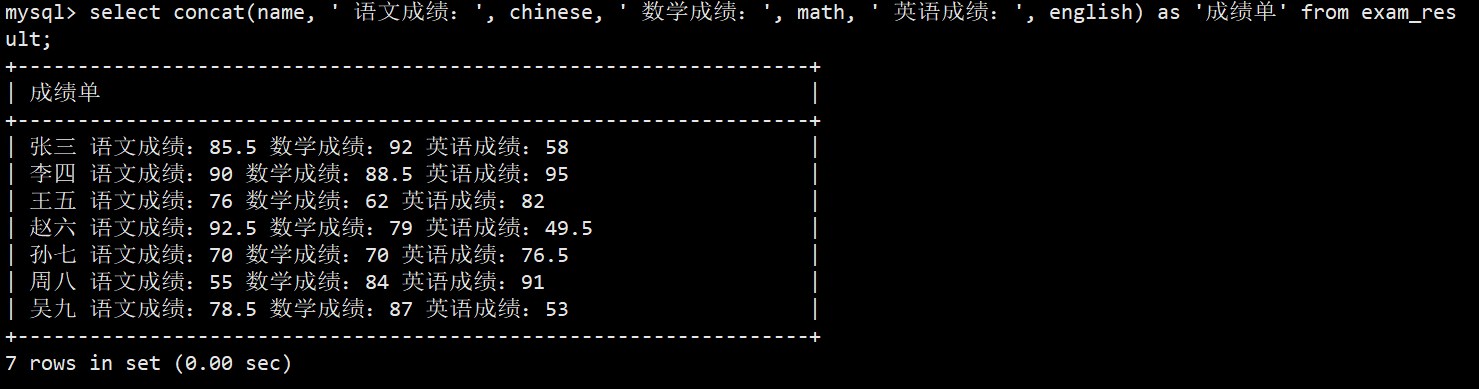
- 案例:将上面成绩表以成绩单的形式打印出来
- 语法:select concat(name, ' 语文成绩:', chinese, ' 数学成绩:', math, ' 英语成绩:', english) as '成绩单' from exam_result;
(3)数学函数
|----------------------------------|------------------------|
| 函数名称 | 描述 |
| abs(number) | 绝对值函数 |
| bin(decimal_number) | 十进制转换二进制 |
| hex(decimalNumber) | 转换成十六进制 |
| conv(number, from_base, to_base) | 进制转换 |
| ceiling(number) | 向上去整 |
| floor(number) | 向下去整 |
| format(number, decimal_places) | 格式化,保留小数位数 |
| hex(decimalNumber) | 转换成十六进制 |
| rand() | 返回随机浮点数,范围 [0.0, 1.0) |
| mod(number, denominator) | 取模,求余 |
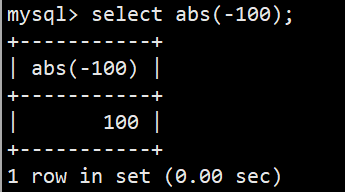
- 绝对值:select abs(-100);
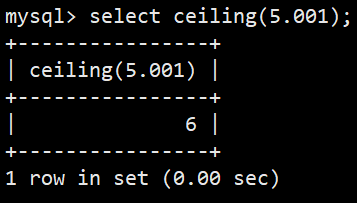
- 向上取整:select ceiling(5.001);
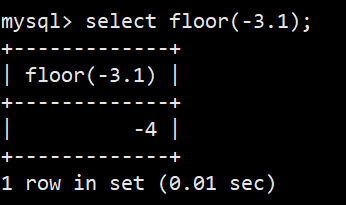
- 向下取整:select floor(-3.1);
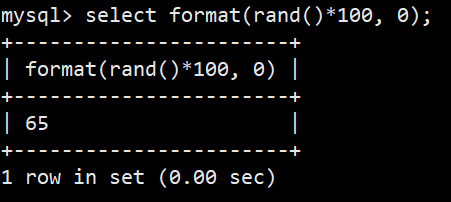
- 随机生成0-100数字:select format(rand()*100, 0);
(4)其他函数
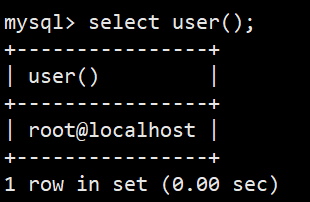
- user() 查询当前用户
- 语法:select user();
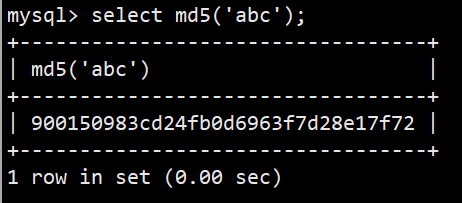
- md5(str)对一个字符串进行md5摘要,摘要后得到一个32位字符串(加密)
- 语法:select md5('abc');
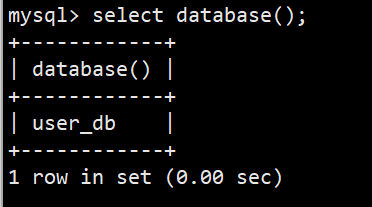
- database()显示当前正在使用的数据库
- 语法:select database();
- password()函数,MySQL数据库使用该函数对用户加密
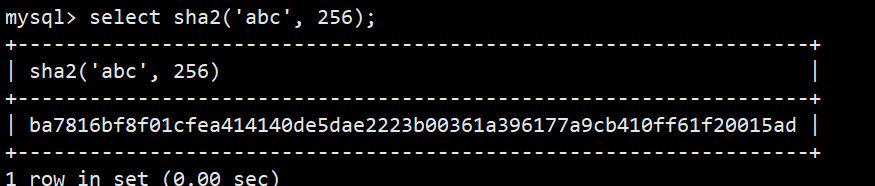
- 注意:高版本已移除,无法使用,可以使用sha2()
- sha2(str, hash):第二个参数是指定 SHA-2 加密算法的哈希长度,MySQL 仅支持224、256、384、512这四个有效值
- 如:select sha2('abc', 256);
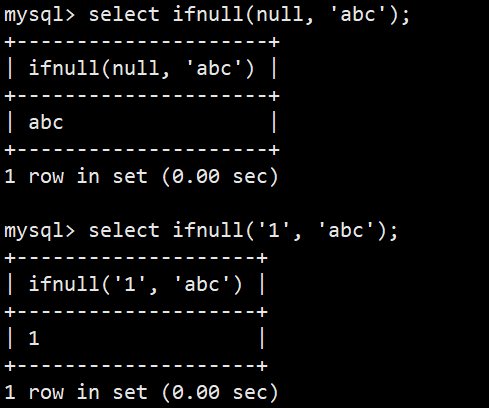
- ifnull(val1, val2) 如果val1为null,返回val2,否则返回val1的值;与C语言的 ? : 表达式效果类似
6.索引
6.1概念和原理
1.什么是索引:
- 索引是 MySQL 中可提升数据库检索性能的数据库对象,是一种空间换时间的设计,无需额外加内存、改程序或调 SQL,仅通过create index即可创建,本质是对数据表字段按特定数据结构组织的目录,用于快速定位数据。
- MySQL 中的索引包含主键索引(primary key)、唯一索引(unique)、普通索引(index)和全文索引(fulltext)这四类。
2.索引有什么用:
- 核心作用是成百上千倍提升海量数据的检索速度,通过减少 MySQL 与磁盘的 IO 交互次数实现查询优化;但会以增加插入、更新、删除等写操作的 IO 开销为代价,仅适用于海量数据的检索场景。
3.索引的底层数据结构和底层原理:
- 索引底层核心数据结构为B + 树 ,InnoDB/MyISAM 引擎均采用该结构,MEMORY 引擎同时支持 HASH 和 B + 树;MySQL 与磁盘交互的基本单位是16KB 的 page(页) ,也是 B + 树的基本组成单元,page 分为存储用户实际数据的数据页 和存储下级页最小键值 + 指针的目录页,多个 page 通过双向链表连接。
- 底层原理为:MySQL 会将数据按主键自动排序后组织在 page 中,以 page 为单位加载到内存的 Buffer Pool 中,利用局部性原理减少 IO 次数;B + 树以多层目录页和数据页构建,非叶子节点仅存键值和 page 指针,叶子节点存储实际数据(聚簇索引)或主键值(辅助索引)且叶子节点彼此相连,查找时自顶向下通过目录页快速定位目标数据页,大幅减少磁盘 IO 的 page 加载次数;辅助索引查询需先通过索引获取主键,再通过主键索引查询数据,该过程为回表查询。
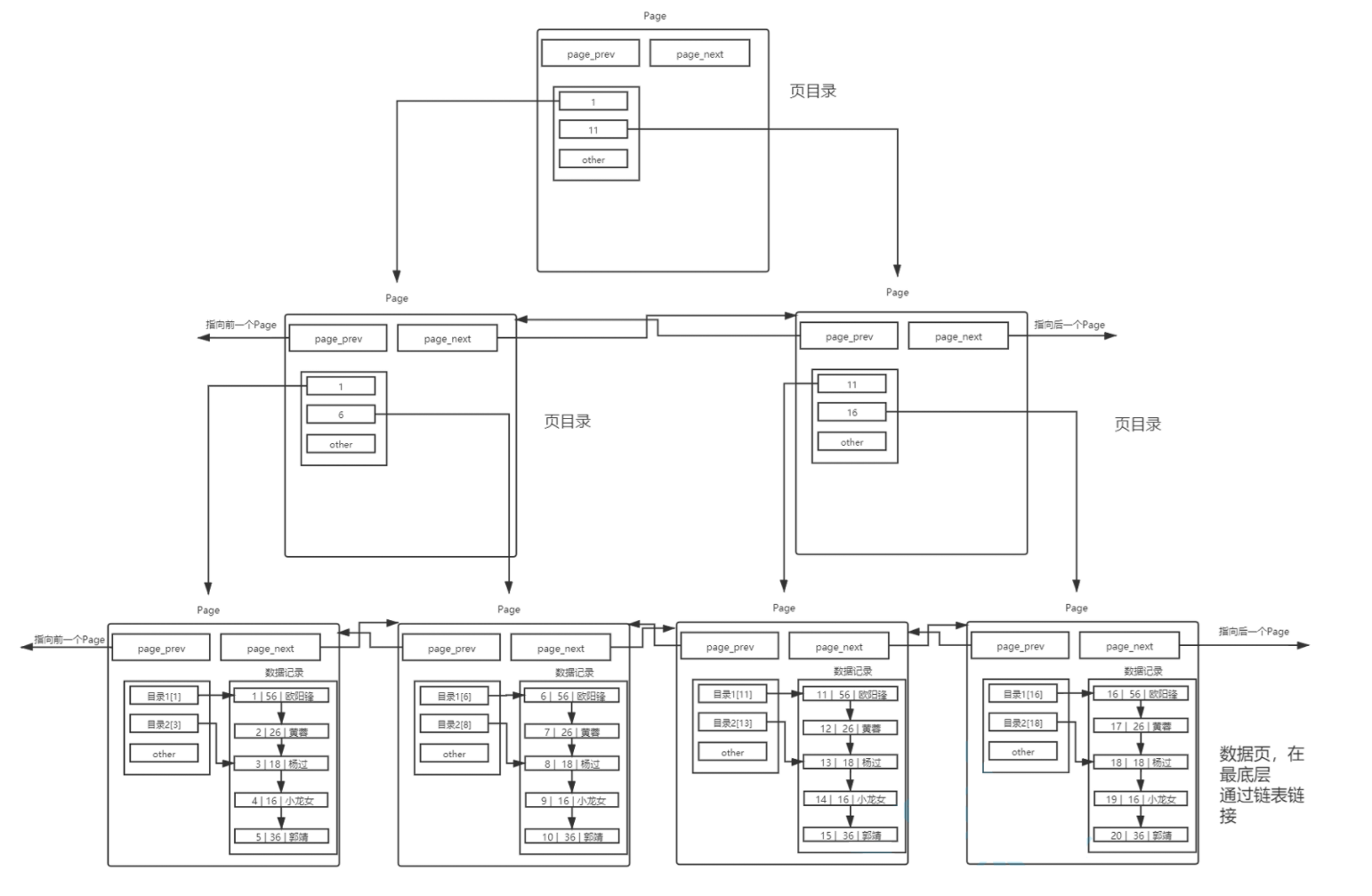
4.InnoDB 主键索引将表转为 B + 树的过程(全程以 16KB 的 page 为核心单位):
- 排数据,装入数据页 :将表中所有数据按主键值从小到大排序,分批存入一个个 16KB 的数据页(这是 B + 树的叶子节点);数据页之间通过双向链表连接,页内也会按主键建立小型目录,提升页内行数据的查找效率,数据页中存储完整的表行数据。
- 建目录页,管理数据页 :当数据页数量增多,MySQL 会自动生成目录页(这是 B + 树的非叶子节点);每个目录页仅存储「下级数据页 / 子目录页的最小主键值 + 对应 page 的指针」,目录页也按主键排序、双向链表连接,专门用来快速定位目标数据页。
- 叠层生成 B + 树 :若单级目录页无法管理所有下级 page,会向上生成更高层的目录页,最顶层为根目录页;最终形成「根目录页→中间目录页→数据页」的多层 B + 树,所有叶子节点(数据页)始终保持双向相连,仅数据页存完整行数据,所有目录页只存主键值 + page 指针。
5.同一张表设置多种索引,是否共用同一颗 B + 树?
- 答:不共用;每张表的每个辅助索引(唯一、普通、全文等)都会单独创建一棵独立的 B + 树,和主键索引的 B + 树彼此分离,不会共用。
- 且 InnoDB、MyISAM 两大主流引擎均遵循此规则,仅不同引擎的辅助索引 B + 树叶子节点存储内容有差异:
- InnoDB:主键索引 B + 树(聚簇索引)叶子节点存完整行数据;每个辅助索引 B + 树叶子节点仅存索引列值 + 对应行主键值,查询需回表。
- MyISAM:主键索引和所有辅助索引的 B + 树结构一致,叶子节点均只存数据行的磁盘地址,无回表概念,但依旧是一棵索引对应一棵独立 B + 树。
- 简单说:一张表有多少个索引(含主键),就有多少棵独立的 B + 树。
6.2索引操作
1.索引创建:
(1)创建主键索引
所谓创建主键索引就是设置主键约束
- 第一种方式:create table user1(id int primary key, name varchar(30));
- 第二种方式:create table user2(id int, name varchar(30), primary key(id));
- 第三种方式:alter table user3 add primary key(id);创建表以后再添加主键
主键索引的特点:
- 一个表中,最多有一个主键索引,当然可以使符合主键
- 主键索引的效率高(主键不可重复)
- 创建主键索引的列,它的值不能为null,且不能重复
- 主键索引的列基本上是int
(2)创建唯一索引
就是设置唯一键约束
- 第一种方式:create table user4(id int primary key, name varchar(30) unique);
- 第二种方式:create table user5(id int primary key, name varchar(30), unique(name));
- 第三张方式:alter table user6 add unique(name); 建表后再添加唯一键
唯一索引的特点:
- 一个表中,可以有多个唯一索引
- 查询效率高
- 如果在某一列建立唯一索引,必须保证这列不能有重复数据
- 如果一个唯一索引上指定not null,等价于主键索引
(3)创建普通索引
- 第一种方式:create table user8 (
id int primary key,
name varchar(20),
email varchar(30),
index(name) -- 在表的定义最后,指定某列为索引
);- 第二种方式:alter table user9 add index(name); 创建完表以后指定某列为普通索引
- 第三种方式:create index idx_name on user10(name); 创建一个索引名为 idx_name 的索引,同理第二种方式,也是在建表后再设置普通索引,不过这个可设置索引名
普通索引的特点:
- 一个表中可以有多个普通索引,普通索引在实际开发中用的比较多
- 如果某列需要创建索引,但是该列有重复的值,那么我们就应该使用普通索引
(4)全文索引
- 适用于大文字 / 文章字段检索,仅 MyISAM 引擎支持,默认仅支持英文,中文需借助 coreseek;不能用 like 模糊查询触发,需用 MATCH...AGAINST 语法。
- create table articles (
id int unsigned auto_increment not null primary key,
title varchar(200),
body text,
fulltext (title,body) -- 全文索引
)engine=myisam;- 使用语法:select * from articles where match (title,body) against ('检索关键词');
2.查询索引
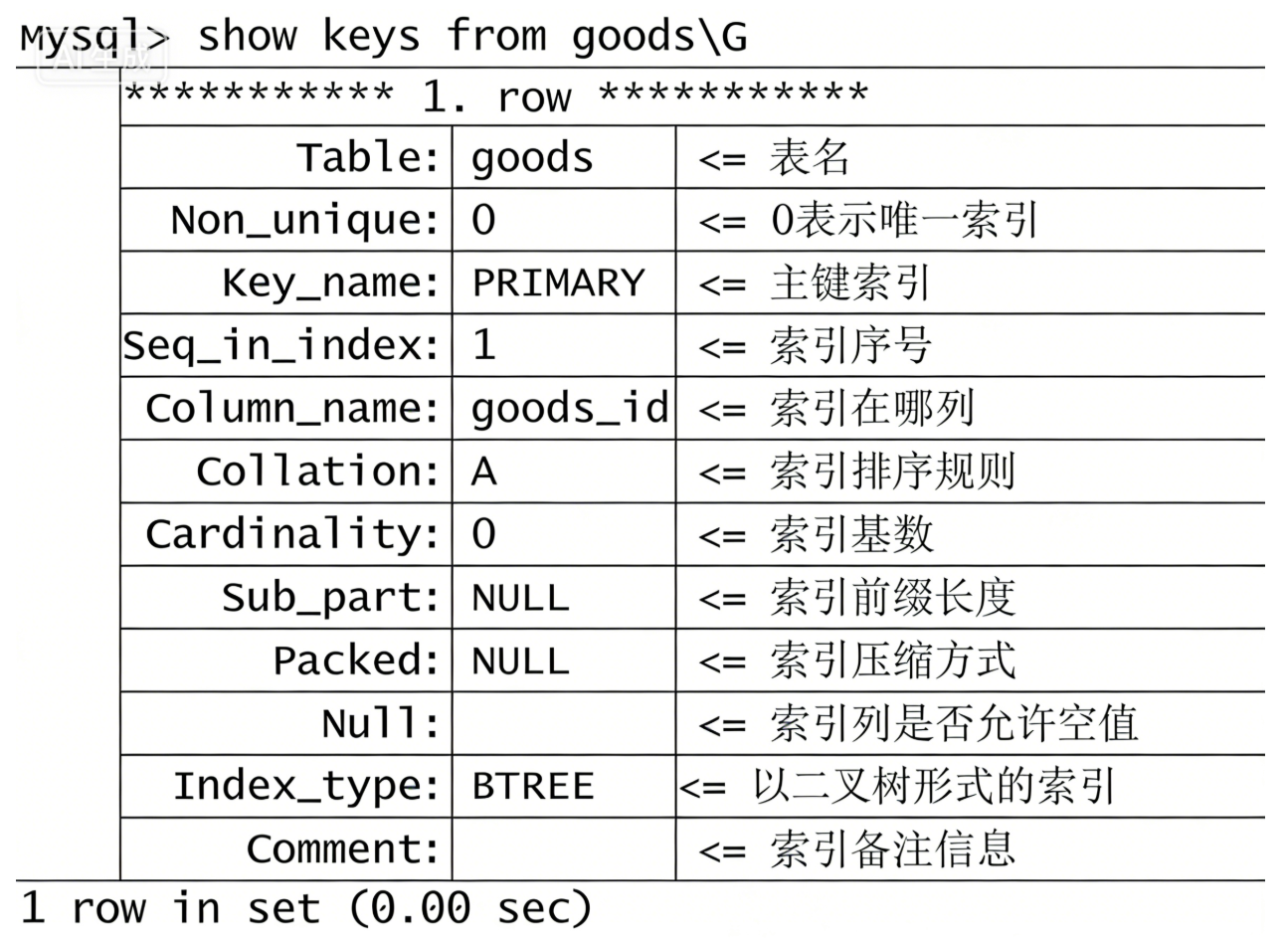
- 第一种方法: show keys from 表名
- 第二种方法: show index from 表名; 效果同上,只是语法区别
- 第三种方式:desc 表名; 信息比较简略

3.删除索引
- 第一种方法--删除主键索引: alter table 表名 drop primary key;
- 第二种方法--其他索引的删除: alter table 表名 drop index 索引名;索引名就是show keys from 表名 中的 Key_name 字段
- 第三种方法方法: drop index 索引名 on 表名
6.3索引创建原则
- 比较频繁作为查询条件的字段应该创建索引
- 唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件
- 更新非常频繁的字段不适合作创建索引
- 不会出现在where子句中的字段不该创建索引
7.事务
7.1事务的概念
1.什么是事务?
- 事务(Transaction)是 MySQL 中由一组具有逻辑相关性的 DML 语句构成的操作整体,MySQL 通过专属机制保证这组语句要么全部执行成功,要么全部执行失败;同时事务会规定不同客户端可看到不同的数据状态,主要用于处理操作量大、复杂度高的数据库数据操作。
2.事务有什么用?
- 事务核心用于解决数据库多并发操作下的数据不一致问题,通过commit 提交 实现事务执行结果的持久化存储,通过rollback 回滚(可回滚至事务开始或指定保存点)及操作异常时的自动回滚,保障数据库操作的原子性,避免部分语句执行导致的数据混乱;同时结合不同隔离级别设置实现事务间的隔离性,通过提交、回滚的操作规则确保事务执行前后数据库的一致性,大幅简化应用层的数据库编程模型,让开发者无需额外处理网络异常、服务器宕机、多操作并发冲突等潜在问题,稳定支撑复杂的数据库批量操作。
3.一个完整的事务,绝对不是简单的 sql 集合,还需要满足如下四个属性:
- **原子性:**一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中 间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个 事务从来没有执行过一样。
- **一致性:**在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完 全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
- **隔离性:**数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务 并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括:读未提交(Read uncommitted)、读提交( read committed)、可重复度(repeatable read)、串行化(Serializable)
- **持久性:**事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
(上面四个属性,可以简称为 ACID )
7.2事务的版本支持
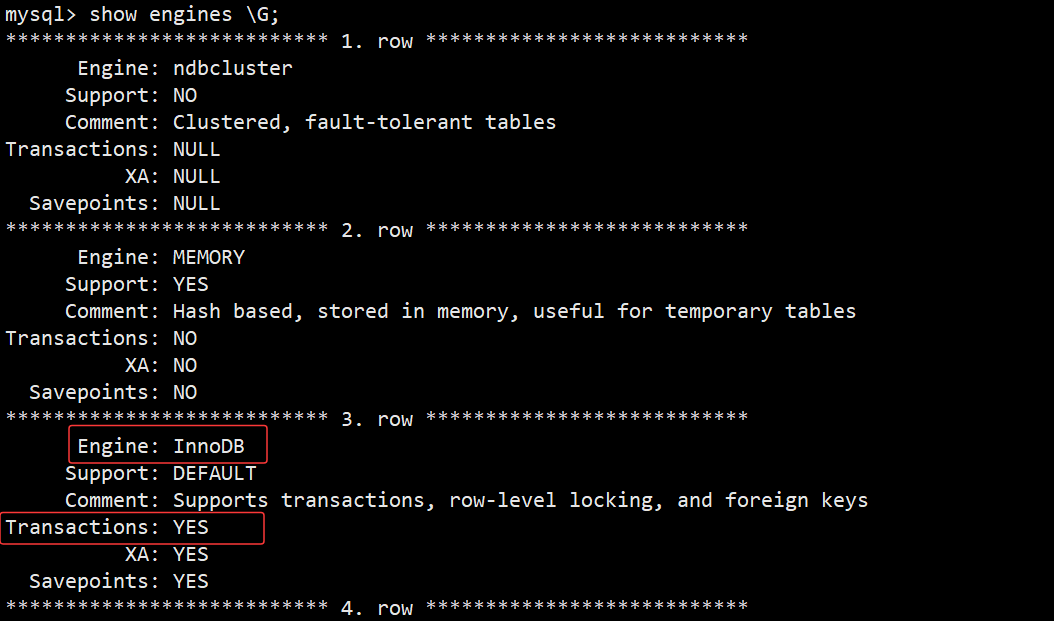
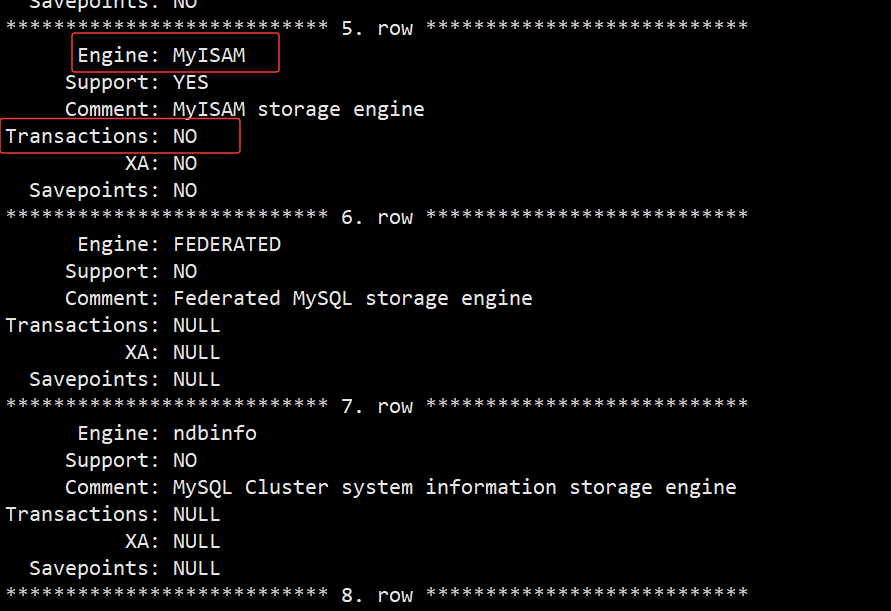
- 在 MySQL 中只有使用了 lnnodb 数据库引擎的数据库或表才支持事务, MyISAM 不支持。
- 可通过 show engines \G 查看支持数据库事务的引擎
7.3事务的提交方式
- 事务的提交方式常见的有两种:自动提交、手动提交
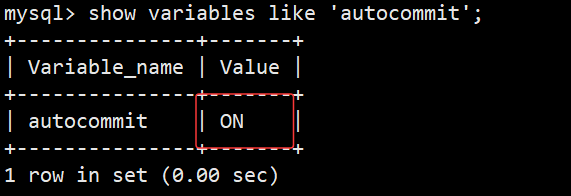
- 查看事务提交方式:show variables like 'autocommit';
- 红框内是 ON 就是自动提交、OFF就是手动提交
- 改变提交方式:set autocommit=0;
- 设置 autocommit=0 就是手动提交,设置 autocommit=1 就是自动提交;
自动提交和手动提交的区别:
- 自动提交(默认 autocommit=1):每条 DML 语句自动构成独立事务并即时提交,事务中若单条语句异常,仅该语句回滚,其他已提交语句不受影响。
- 手动提交(autocommit=0 或用 begin/start transaction 开启):需显式执行 commit 才会持久化事务修改,事务中若出现异常,整个未提交的事务会自动回滚至初始状态。
**注意:**我们之前执行的插入、更新、删除等 DML 操作,其实本质上都是一次独立的事务,只不过 mysql 默认开启 autocommit=1 的自动提交模式,因此每一条单次执行的 DML 语句都会被 mysql 自动封装成一个完整事务并隐式完成开启与提交,而查询类的 select 语句仅遵循事务隔离级别,不会触发事务提交。
7.4事务的基本操作
基本操作:
- 开启一次事务语法:begin 或者 start transaction
- 创建一个保存点:savepoint 保存点名;
- 回滚:rollback to 保存点; (可以撤回操作到该保存点)
或者直接 rollback; 直接回滚到事务开始时- 提交和结束一次事物:commit
自动提交+begin开启事物 与 手动提交+begin开启事物 的区别:
- 自动提交+begin开启事物:begin 会临时暂停 自动提交机制,此时多条 DML 语句会被纳入同一个事务,需显式执行 commit 提交 /rollback 回滚;事务完成(commit/rollback)后,autocommit 会自动恢复为 1,后续单条 DML 语句又会回到 "执行即提交" 的默认状态;若事务中出现异常,仅当前未提交的事务整体回滚,不影响 autocommit 的自动恢复。
- 手动提交+begin开启事物:autocommit 被永久修改为手动提交模式(直至主动改回 1 或会话断开),无需额外 begin,第一条 DML 语句就会自动开启事务;所有后续 DML 语句都会持续纳入当前事务,必须显式 commit/rollback 才能结束当前事务,且事务结束后 autocommit 仍为 0,下一条 DML 会自动开启新事务;若事务中出现异常,未提交的事务整体回滚,且 autocommit 不会自动恢复为 1。
- 从执行效果来看,手动提交(autocommit=0)+begin 开启事务,和自动提交(autocommit=1)+begin 开启事务,除了提交方式的改变外,事务内部的执行效果是完全一致的
- 换句话说,只要输入begin或者start transaction,事务便必须要通过commit提交,才会持久化,与是否设置set autocommit无关。
简单操作演示:
- 创建测试表:
- 插入一些数据:
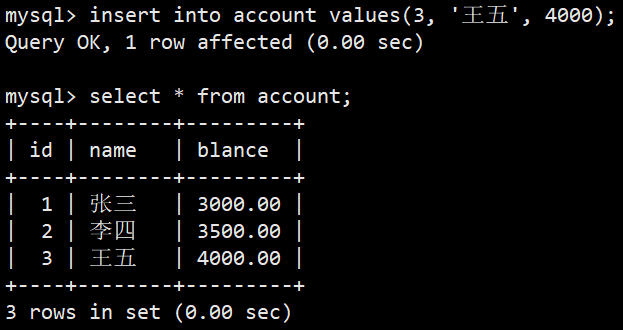
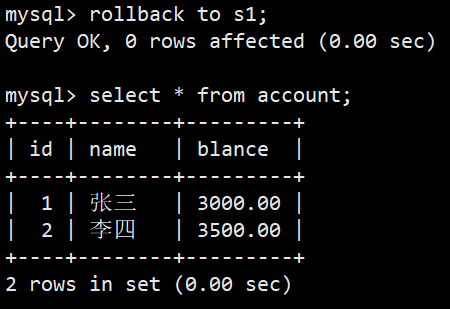
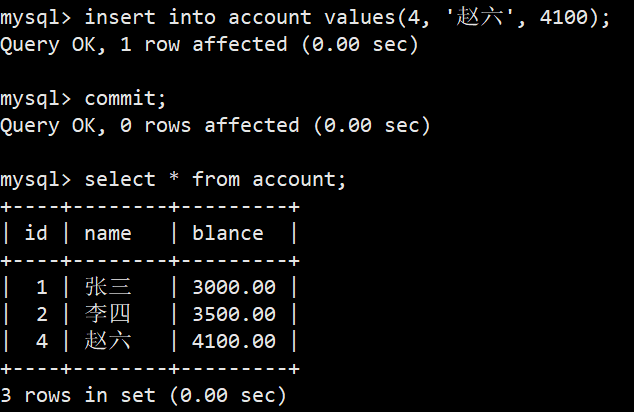
- 开始创建一个事务,创建保存点,插入数据,然后回滚一次:
- 插入数据并commit提交:
(ctrl + \ 可以触发mysql异常终止 Aborted,在事务中如果发生异常终止,MySQL 会自动回滚该事务中所有未提交的 DML 操作,不会将任何修改持久化到数据库。)
7.5事务隔离级别
(1)概念
事务隔离存在的意义和作用:
- 一个事务可能由多条SQL构成,也就意味着,任何一个事务,都有执行前,执行中,执行后的阶段。而所谓的原子性,其实就是让用户层,要么看到执行前,要么看到执行后。执行中出现问题, 可以随时回滚。所以单个事务,对用户表现出来的特性,就是原子性。
- 但,毕竟所有事务都要有个执行过程,那么在多个事务各自执行多个SQL的时候,就还是有可能会出现互相影响的情况。比如:多个事务同时访问同一张表,甚至同一行数据。
- 所以在数据库中,为了保证事务执行过程中尽量不受干扰,就有了一个重要特征:隔离性
- 数据库中,允许事务受不同程度的干扰,就有了一种重要特征:隔离级别
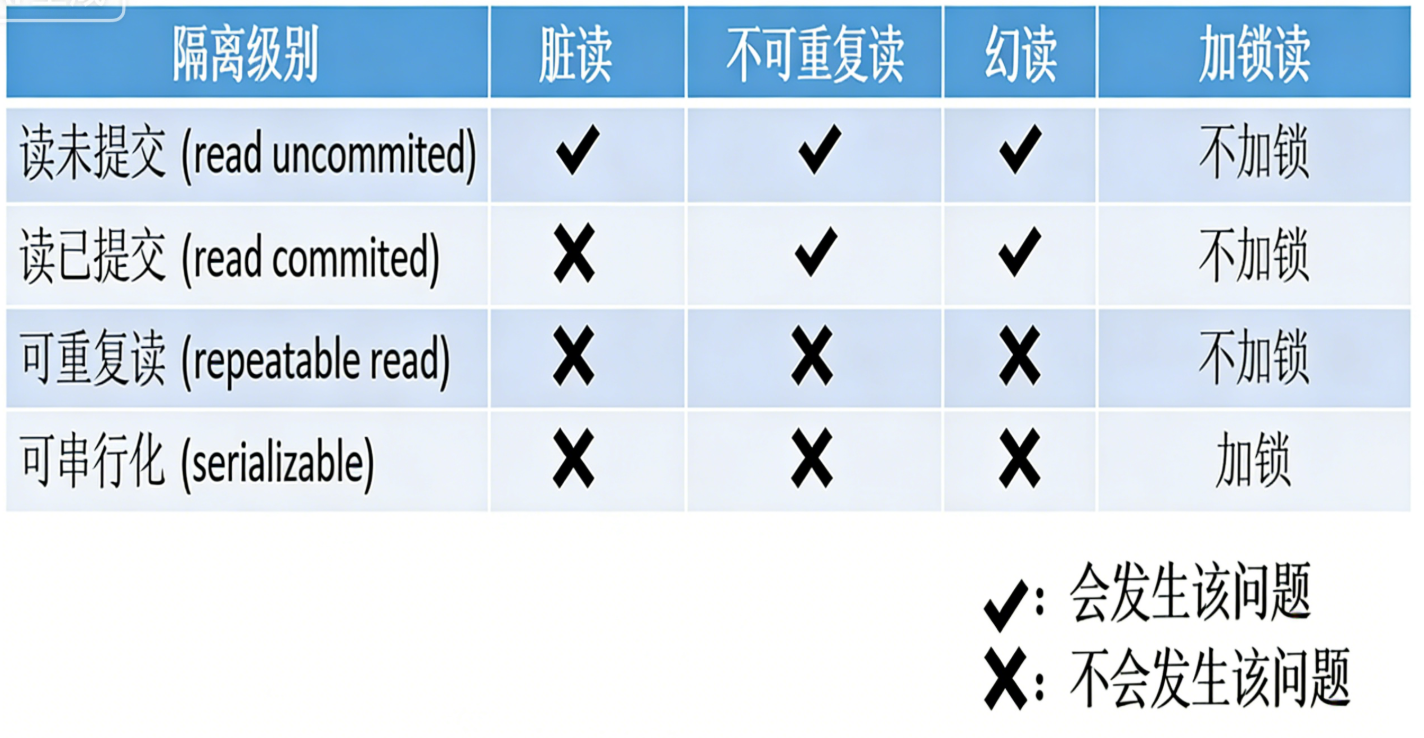
隔离级别:
- 读未提交【Read Uncommitted】: 在该隔离级别,所有的事务都可以看到其他事务没有提交的执行结果。(实际生产中不可能使用这种隔离级别的),但是相当于没有任何隔离性,也会有很多并发问题,如脏读,幻读,不可重复读等
- **读提交【Read Committed】:**该隔离级别是大多数数据库的默认的隔离级别(不是 MySQL 默认的)。它满足了隔离的简单定义:一个事务只能看到其他的已经提交的事务所做的改变。这种隔离级别会引起不可重复读,即一个事务执行时,如果多次 select, 可能得到不同的结果。
- **可重复读【Repeatable Read】:**这是 MySQL 默认的隔离级别,它确保同一个事务,在执行中,多次读取操作数据时,会看到同样的数据行。但是会有幻读问题(幻读是数据库事务并发时,同一个事务内多次执行完全相同的范围查询语句,却得到行数不一致的结果(仿佛凭空多了 / 少了记录)的并发问题,区别于针对单条记录值修改的不可重复读。)
- **串行化【Serializable】:**这是事务的最高隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决了幻读的问题。它在每个读的数据行上面加上共享锁,。但是可能会导致超时和锁竞争 (这种隔离级别太极端,实际生产基本不使用)
(隔离级别如何实现:隔离,基本都是通过锁实现的,不同的隔离级别,锁的使用是不同的。常见有,表锁,行锁,读锁,写锁,间隙锁(GAP),Next-Key锁(GAP+行锁)等)
(2)操作
查看隔离级别:
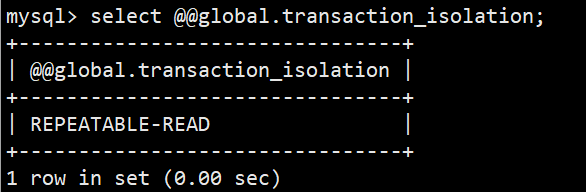
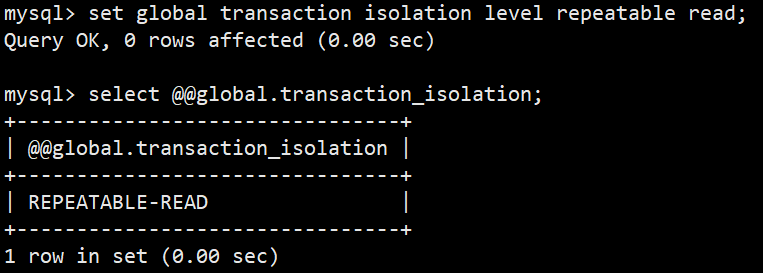
- 1.查看全局隔离级别:select @@global.transaction_isolation; (低于8.0版本使用 select @@global.tx_isolation;)
- 可以看到默认的全局隔离级别为可重复度
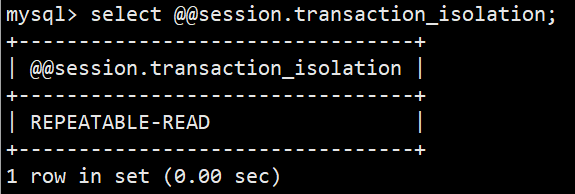
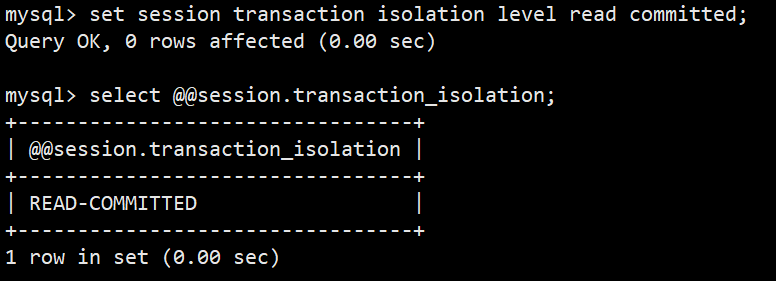
- 2.查看当前会话隔离级别:select @@session.transaction_isolation; (低于8.0版本使用 select @@session.tx_isolation;)
- 可以看到默认的当前会话隔离级别与全局隔离级别保持一致
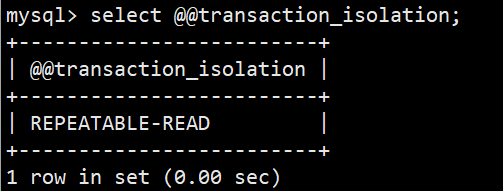
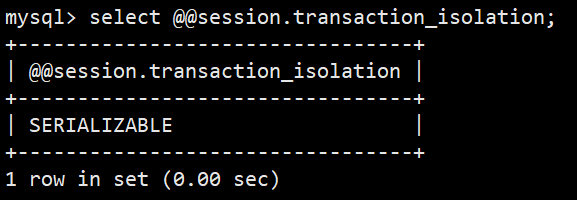
- 3.查看当前连接的隔离级别(与session级别一致):select @@transaction_isolation; (低于8.0版本使用 select @@tx_isolation;)
设置隔离级别:
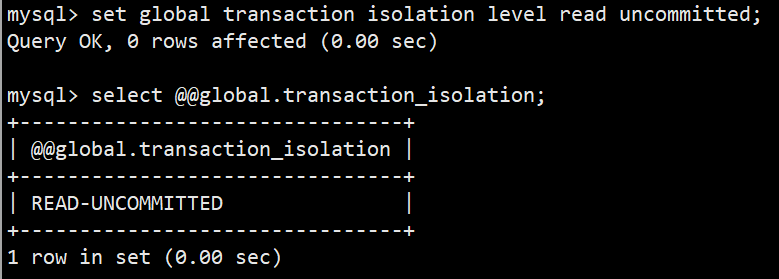
- 1.设置全局读未提交:set global transaction isolation level read uncommitted;
- 2.设置当前会话读提交:set session transaction isolation level read committed;
- 3.设置全局可重复读:set global transaction isolation level repeatable read;
- 4.设置当前会话串行化:set session transaction isolation level serializable;
事务隔离操作的辅助注意事项:
- 所有隔离级别测试均需结合事务开启(BEGIN/START TRANSACTION),未开启事务的单条 SQL 为 InnoDB 默认自动提交,无隔离特性;
- 若事务未提交(commit),客户端异常终止后,MySQL 会自动回滚事务,隔离级别设置失效;
- RR 级别是 MySQL 默认隔离级别,一般不建议修改,兼顾并发性能和数据一致性;
- 隔离级别仅对 InnoDB 引擎有效,MyISAM 引擎无事务及隔离级别相关操作。
8.视图
概念:
- 视图是一个虚拟表,其内容由查询定义。同真实的表一样,视图包含一系列带有名称的列和行数据。视图的数据变化会影响到基表,基表的数据变化也会影响到视图。
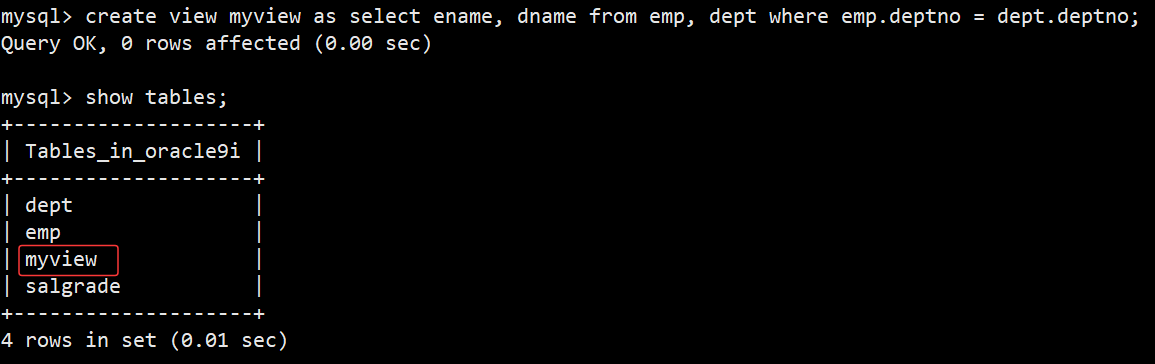
- 创建视图语法:create view 视图名 as select语句;
**示例:**使用oracle 9i的经典测试表
- 案例:用视图显示所有的员工名和其所在的部门名
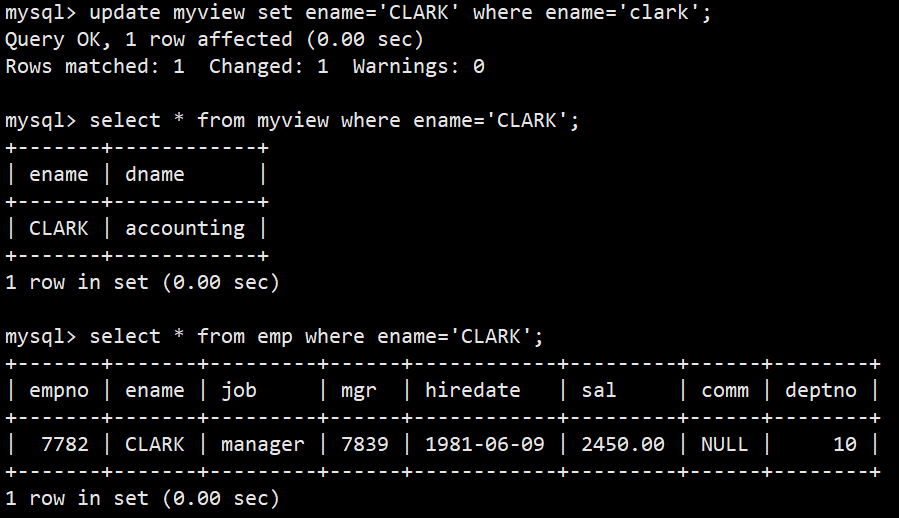
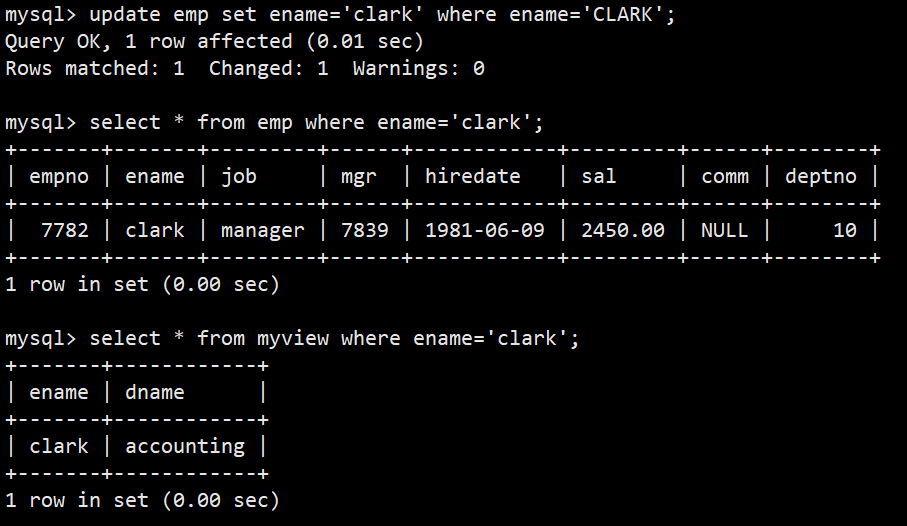
- 修改视图会影响基表,如修改clark名字为CLARK:
- 修改了基表,对视图有影响,如改回CLARK为clark:
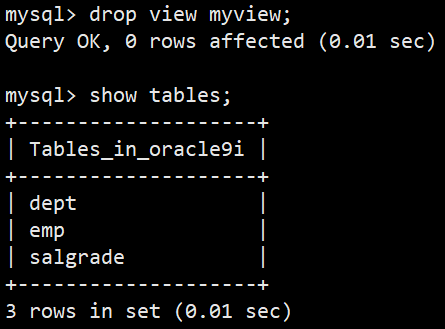
- 删除视图:drop view 视图名;
视图的规则和限制:
- 与表一样,必须唯一命名(不能出现同名视图或表名)
- 创建视图数目无限制,但要考虑复杂查询创建为视图之后的性能影响
- 视图不能添加索引,也不能有关联的触发器或者默认值
- 视图可以提高安全性,必须具有足够的访问权限
- order by 可以用在视图中,但是如果从该视图检索数据 select 中也含有 order by ,那么该视图中的 order by 将被覆盖
- 视图可以和表一起使用

9.用户管理
9.1用户信息
- MySQL中的用户,都存储在系统数据库mysql的user表中
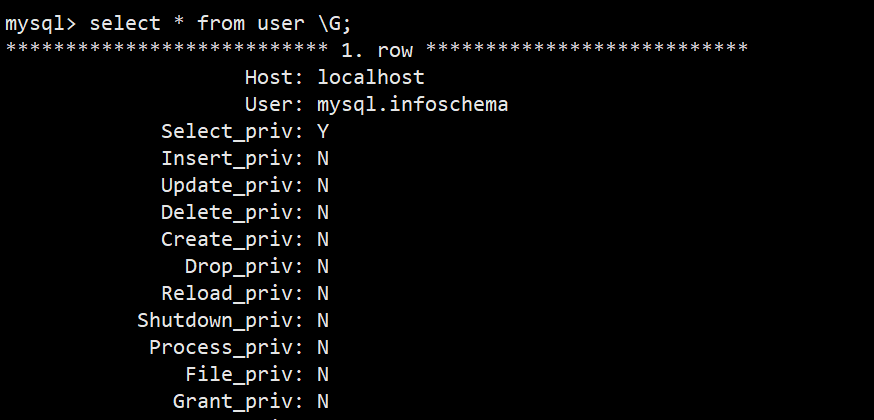
- select * from user \G; 能看到user表中的所有信息:
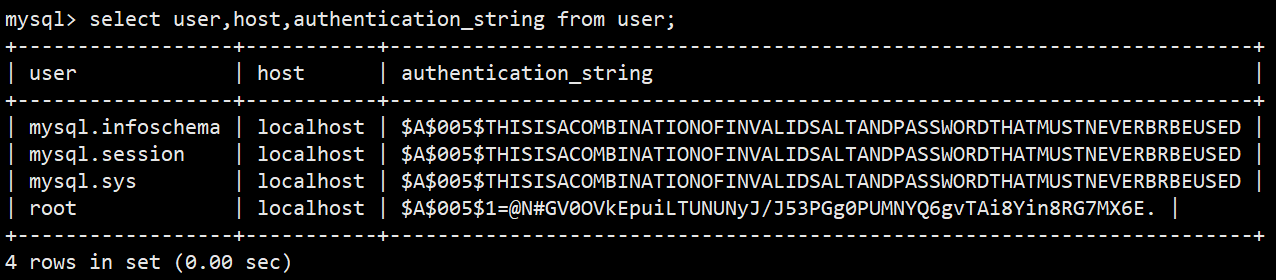
- 也可以只看用户名,登录主机和密码:select user,host,authentication_string from user;
- 前三个以mysql开头的用户是 MySQL 的系统内置用户:
- mysql.infoschema:用于访问information_schema(存储数据库元数据的系统库),支撑元数据查询等系统操作;
- mysql.session:用于 MySQL 内部进程的会话连接(比如系统后台线程与数据库的交互);
- mysql.sys:用于管理sys模式(MySQL 5.7 + 的性能监控 / 管理工具库),提供简化的性能统计视图。
字段解释:
- host:表示这个用户可以从哪个主机登陆,如果是localhost,表示只能从本机登陆
- user:用户名
- authentication_string: 用户密码通过password函数加密后的
- *_priv:用户拥有的权限
9.2创建用户
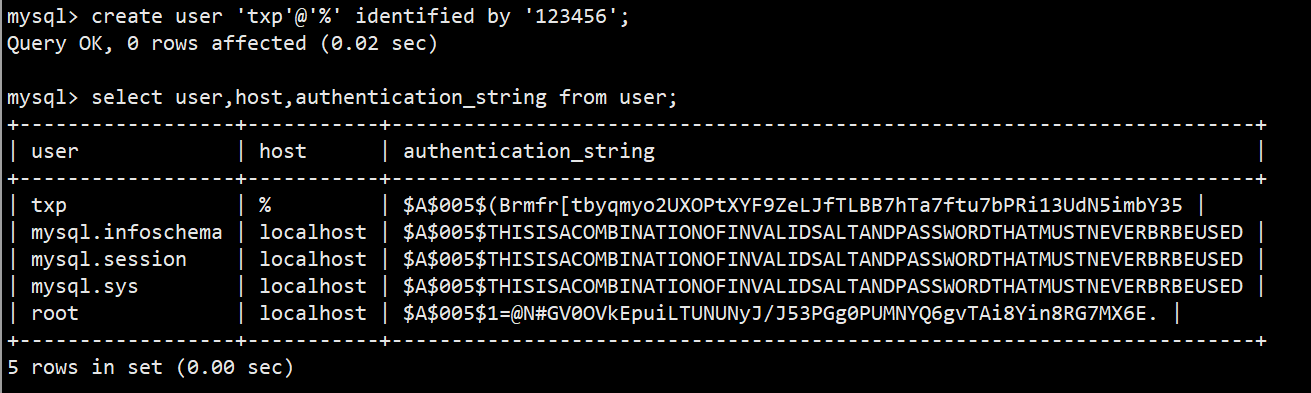
- 语法:create user '用户名'@'登陆主机/ip' identified by '密码'; 密码会自动加密
- %代表可以从任意地方登录,注意一般不建议这样设置
9.3删除用户
- 语法:drop user '用户名'@'主机名'
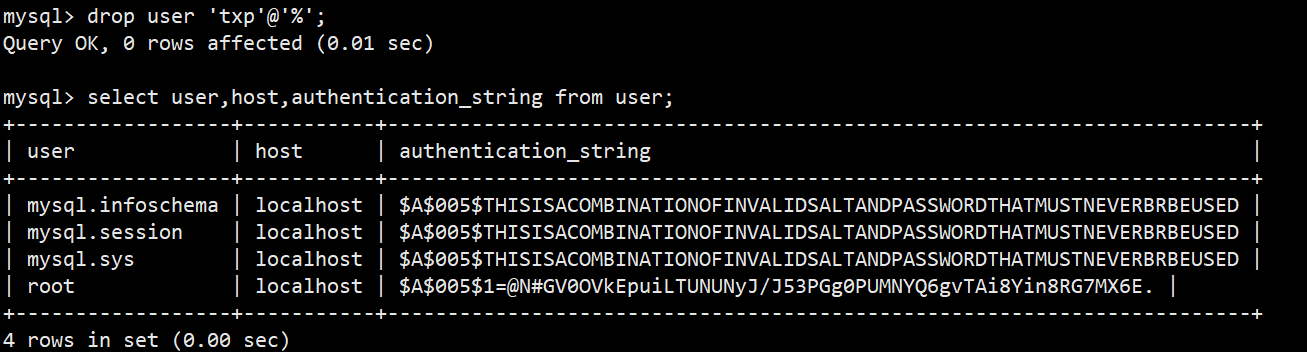
9.4修改用户密码
- 自己改自己密码:set password=password('新的密码');
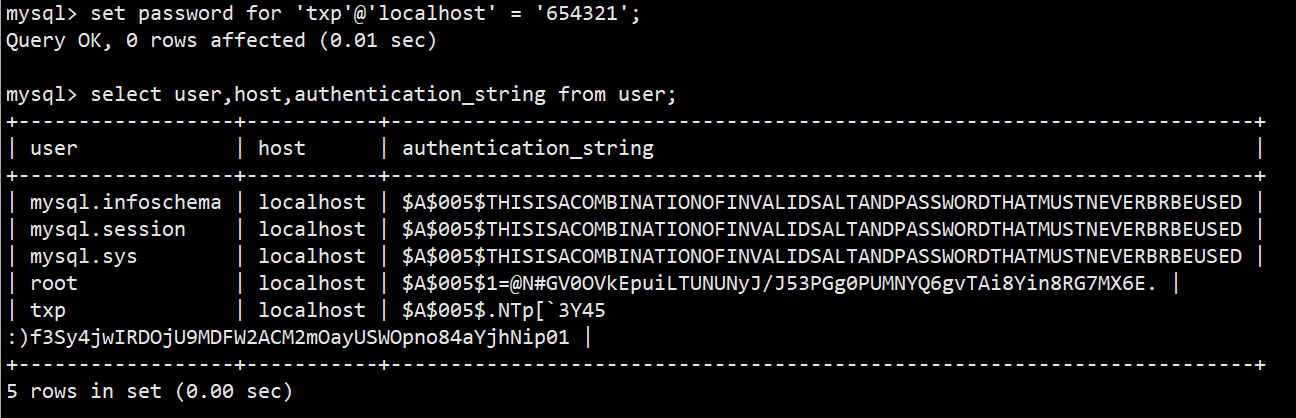
- root修改指定用户密码:set password for '用户名'@'主机名'=password('新的密码');
- 注意:8.0版本移除了password函数,可以使用以下语法:
- set password for '用户名'@'主机名' = '新密码'; 会自动加密
- alter user '用户名'@'主机名' identified by '新密码';
9.5给用户授权
- 刚创建的用户没有任何权限。需要给用户授权。
- 语法:grant 权限列表 on 库.对象名 to '用户名'@'登陆位置' identified by '密码'
- 权限列表:多个权限用逗号分开,常见权限如下
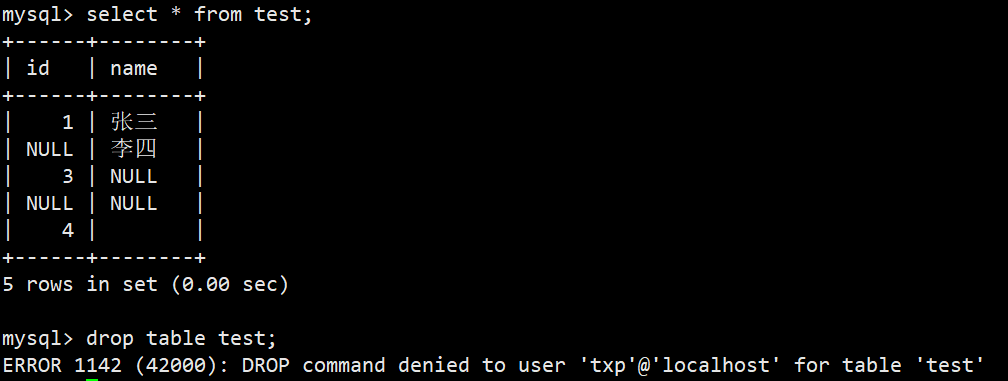
- 示例:给用户txp赋予user_db数据库下所有文件的select权限
- 此时该用户只能查看表,如果执行删除等操作就会被禁止:
- 回收权限语法:revoke 权限列表 on 库.对象名 from '用户名'@'登陆位置';


五、总结
访问mysql除了linux上这样纯命令行外,在语言中可以直接使用相关库和方法操作数据库,或者直接在电脑本地使用带图形化界面的客户端访问数据库,当然这些都是后话了;
以上就是本文的全部内容,感谢你的支持!!!