(时间 = 可学习的非线性状态演化)
前文
时间序列模型发展历程(第一讲:AR/MA/ARMA)-CSDN博客
时间序列模型发展历程(第二讲:平稳性危机与ARIMA诞生、SARIMA)-CSDN博客
时间序列模型发展历程(第三讲:指数平滑法 / Holt / Holt-Winters)-CSDN博客
时间序列模型发展历程(第四讲:State Space Models)-CSDN博客
时间序列模型发展历程(第五讲:第二代------机器学习时序模型 | SVR/RF/XGBoost/浅层ANN)-CSDN博客
目录
[一、RNN 出现前,人类已经"什么都有了"](#一、RNN 出现前,人类已经“什么都有了”)
[二、RNN 的本质:非线性状态空间模型](#二、RNN 的本质:非线性状态空间模型)
[三、最原始的 RNN 在干什么?](#三、最原始的 RNN 在干什么?)
[Vanilla RNN 的数学形式](#Vanilla RNN 的数学形式)
[四、但灾难立刻出现了:梯度消失 / 爆炸](#四、但灾难立刻出现了:梯度消失 / 爆炸)
[1️⃣ 问题不是"训练技巧",而是数学结构](#1️⃣ 问题不是“训练技巧”,而是数学结构)
[2️⃣ 后果是什么?](#2️⃣ 后果是什么?)
[六、LSTM 的核心思想(一句话)](#六、LSTM 的核心思想(一句话))
[七、LSTM 的状态拆分(关键设计)](#七、LSTM 的状态拆分(关键设计))
[1️⃣ 关键更新公式(只看结构)](#1️⃣ 关键更新公式(只看结构))
[九、从状态空间角度看 LSTM(非常重要)](#九、从状态空间角度看 LSTM(非常重要))
[🔥 下一讲:Attention / Transformer](#🔥 下一讲:Attention / Transformer)
一、RNN 出现前,人类已经"什么都有了"
我们先站在历史现场回看一下:
-
✅ 有 状态空间模型
→ 时间 = 状态递推
-
✅ 有 Kalman Filter
→ 不确定性推断
-
✅ 有 机器学习
→ 强非线性拟合
现在只差一件事:
让"状态转移函数"本身可学习,而且不受线性限制
这就是 RNN 出现的唯一原因。
二、RNN 的本质:非线性状态空间模型
我们直接写最核心的两行:
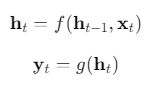
你现在应该立刻意识到:
这和状态空间模型是同一件事
| 状态空间 | RNN |
|---|---|
| 潜在状态 xt | 隐状态 ht |
| 转移矩阵 F | 非线性函数 fθ |
| 观测矩阵 H | 输出函数 gθ |
📌 唯一的本质变化:
f 从"线性矩阵" → "神经网络"
三、最原始的 RNN 在干什么?
Vanilla RNN 的数学形式
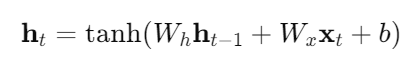
这一步发生了什么?
-
你不再手动设计状态
-
模型自己决定"记住什么"
-
时间结构端到端学习
这是革命性的。
四、但灾难立刻出现了:梯度消失 / 爆炸
现在我们进入RNN 发展史上最痛苦的一章。
1️⃣ 问题不是"训练技巧",而是数学结构
当你做 BPTT(时间反向传播)时:
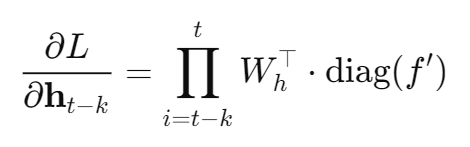
一句话解释:
这是在计算:
最终损失 L,
对 k 步之前隐藏状态 h的梯度。
也就是 BPTT 在问:
"现在的错误,
还能多大程度'怪到'过去的状态?"
这意味着:
-
如果 ∥Wh∥<1:
👉 梯度指数衰减(遗忘过去)
-
如果 ∥Wh∥>1:
👉 梯度爆炸
📌 这是一个乘法结构问题 ,
不是"多调几个 learning rate"能解决的。
2️⃣ 后果是什么?
RNN 理论上能记住很久,
实际上只能记住很短。
这在时间序列里是致命的:
-
季节性
-
长期趋势
-
延迟效应
全部学不好。
五、LSTM:不是"更深",而是"结构性修复"
现在进入一个你应该慢下来认真理解的地方。
LSTM 不是"更复杂的 RNN",
而是一次对时间梯度结构的手术。
六、LSTM 的核心思想(一句话)
不要让信息被反复乘矩阵,
让它"直线流动"。
这句话非常重要。
七、LSTM 的状态拆分(关键设计)
LSTM 把状态拆成两部分:
-
Cell state - ct:长期记忆
-
Hidden state - ht:当前输出
1️⃣ 关键更新公式(只看结构)
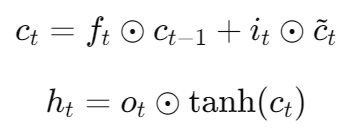
注意这件事:
ct−1 到 ct 是"加法路径"
📌 梯度可以沿着这条路径
几乎不衰减地向前传播
八、门控机制到底在"控制"什么?
很多人背公式,却没想清楚这点。
三个门,各自的语义是:
-
Forget gate - ft
→ 这段历史还要不要?
-
Input gate - it
→ 新信息值不值得写入?
-
Output gate - ot
→ 这段记忆现在该不该暴露?
👉 这不是工程 trick,
而是对"时间选择性记忆"的数学刻画。
九、从状态空间角度看 LSTM(非常重要)
你现在可以这样重新理解 LSTM:
一个具有可学习、非线性、选择性更新规则的状态空间模型
-
状态维度:自适应
-
状态转移:神经网络
-
噪声建模:隐式
📌 这一步,是现代时序建模真正的起点。
十、GRU:一次"工程化的简化"
GRU 不是新思想,而是:
把 LSTM 的门压缩到最小够用集
-
更少参数
-
更快收敛
-
表现接近
在很多时间序列任务中:
GRU ≈ LSTM
十一、到这里,你应该自然地产生最后一个疑问
你现在已经理解得足够深,一定会想到:
RNN 是"一步一步走时间"
如果序列很长,这不是很慢吗?
如果远处信息很重要,
为什么一定要"传过去"?
🔥 这个问题,直接引出了下一代。
🔥 下一讲:Attention / Transformer
(时间 = 可被"跳跃访问"的结构)
我们会讨论:
-
Transformer 在时间序列里到底解决了什么
-
为什么它在 NLP 成功,在 TS 反而"时灵时不灵"
-
为什么很多 TS Transformer 又"偷偷加回 RNN / 状态空间"