漏洞修复自动化:利用 LLM 自动生成补丁与修复建议
你好,我是陈涉川。在这一篇章中,我们将跨越"检测"的边界,进入"修复"的深水区。如果说前面的章节是教会 AI 如何像侦探一样发现罪证,那么这一章则是教会 AI 像外科医生一样,在跳动的心脏上进行缝合手术。我们将探讨大语言模型(LLM)如何从单纯的代码补全工具,进化为具备安全意识的自动化补丁生成器。
引言:从"发现问题"到"解决问题"的最后一公里
2021 年 12 月,Log4Shell (CVE-2021-44228) 漏洞爆发。这是一个在此后数年内都让全球安全团队夜不能寐的时刻。在漏洞披露后的最初 72 小时内,全球数百万台服务器暴露在攻击之下。然而,对于大多数企业而言,真正的噩梦不在于"不知道有漏洞",而在于"修不过来"。
传统的应用安全测试(AST)工具,无论是静态的(SAST)还是动态的(DAST),其终点通常是一份长达数百页的 PDF 报告,列出了成千上万个潜在风险。由于缺乏足够的人力去理解业务逻辑并编写补丁,这些漏洞往往在积压列表(Backlog)中沉睡数月,直到被攻击者利用。根据 Veracode 的统计,修复一个高危漏洞的平均时间(MTTR)超过 60 天,而黑客开发出 Exploit 的平均时间不到 7 天。这就是致命的"补丁缺口"(Patch Gap)。
随着大语言模型(LLM)特别是代码生成模型(Code LLMs,如 Codex, StarCoder, CodeLlama)的崛起,我们迎来了一个历史性的转折点:自动化程序修复(Automated Program Repair, APR) 终于走出了学术界的象牙塔,具备了工业级的实战能力。
在本章中,我们将解构 AI 如何理解漏洞的语义,如何生成语法正确且逻辑安全的补丁,以及如何在不引入"次生灾害"(Regression Bugs)的前提下,实现软件系统的自我愈合。这不是关于辅助编程(Copilot),这是关于自治修复(Autonomous Remediation)。
第一章:自动化修复的演进史------从遗传算法到神经修复
要理解 LLM 为何能通过图灵测试级别的修复挑战,我们需要先回顾一下在它之前,计算机科学家们为了让机器"自己修 Bug"所做的尝试。
1.1 第一代:基于搜索的修复(Search-based APR)
早在 2009 年,GenProg 项目就标志着自动化修复的诞生。其核心思想是遗传算法(Genetic Algorithms)。
- 原理: 它将程序代码视为 DNA 序列。当测试用例失败(发现 Bug)时,它会对代码进行随机的"变异"(插入、删除、替换语句),然后运行测试。如果通过的测试用例变多了,这个"变异体"就被保留下来进行下一轮进化。
- 局限: 这是一种"盲目的试错"。它不理解代码的含义,只是在概率空间中乱撞。因此,它生成的补丁往往是荒谬的(比如删除了报错的那行代码,导致功能失效但不再报错),被称为"无意义补丁"(Nonsense Patches)。
1.2 第二代:基于语义的修复(Semantics-based APR)
为了解决"无意义补丁"问题,研究者引入了**符号执行(Symbolic Execution)**和约束求解(Constraint Solving)。
- 原理: 工具将有问题的代码段转换为数学约束公式,然后计算出满足"前置条件"和"后置条件"的代码逻辑。
- 局限: 这种方法虽然精确,但面临"状态空间爆炸"的问题,无法处理复杂的商业级代码,且对修复模板(Fix Templates)的依赖极高。
1.3 第三代:神经机器翻译(NMT)与 LLM
这是范式转移的时刻。我们将"修复 Bug"重新定义为"翻译问题":将"有 Bug 的代码"翻译成"修复后的代码",就像将中文翻译成英文一样。
- 早期 NMT: 使用 LSTM 或简单的 Transformer 模型,在 GitHub 的 Commit 历史(Before/After)上进行训练。例如 Tufano 等人的研究。
- LLM 时代: 现在的 LLM 不仅见过数千亿行代码,还见过与之相关的 Issue 讨论、文档描述和 CVE 分析。它们具备了推理能力(Reasoning),能够理解"为什么"这里有一个 SQL 注入,而不是仅仅记住"把 + 变成 ?"。
第二章:LLM 修复的核心机制------当代码成为概率分布
在 LLM 眼中,代码不是逻辑树,而是 Token 的概率流。理解这一点,是构建自动化修复系统的基石。
2.1 填空任务(Infilling)与因果推理
标准的 GPT 模型是自回归的(Autoregressive),即从左到右预测下一个词。但在修复场景中,我们往往需要修改代码中间的某一段。这就需要模型具备 FIM (Fill-In-the-Middle) 能力。
假设我们要修复一个 XSS 漏洞:
Python
原始代码
user_input = request.args.get('name')
return "Hello " + user_input # 漏洞点
修复目标
import html
user_input = request.args.get('name')
return "Hello " + html.escape(user_input) # 修复点
对于 LLM,输入不仅仅是漏洞代码,还必须包含上下文(Context)。我们将构建一个特殊的 Prompt 结构:
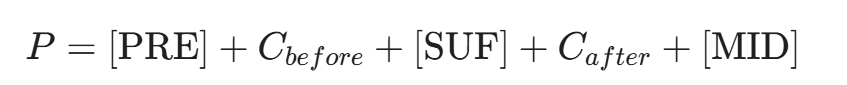
其中:
- C_{before}: 漏洞行之前的代码(包含导入库、函数定义)。
- C_{after}: 漏洞行之后的代码(包含返回语句)。
- MID: 提示模型生成中间的修复代码。
这种机制使得模型能够利用周围的变量定义和逻辑流,生成符合当前上下文的补丁,而不是凭空捏造变量。
2.2 漏洞上下文感知(Vulnerability Context Awareness)
仅仅给代码是不够的。为了提高修复的准确率(Fix Rate),我们需要向 LLM 注入"专家知识"。这通常包括:
- 静态分析报告: SAST 工具(如 Semgrep, CodeQL)的输出。例如:"Line 42: CWE-89 SQL Injection. Variable user_id is tainted."
- 错误追踪(Stack Trace): 如果是运行时错误,提供崩溃时的堆栈信息。
- CWE/CVE 描述: 检索知识库,告诉 LLM "什么是 SQL 注入"以及"标准修复模式是什么"。
这种技术被称为 RAG-based Repair(检索增强修复)。通过向 Prompt 中检索插入相似的历史修复案例(Few-shot prompting),LLM 的表现会显著提升。
2.3 自省式修复(Reflective Repair)------赋予 AI"自我纠错"的能力
早期的 LLM 修复不仅是"盲目的",而且是"固执的"。如果第一次生成的补丁无效,它往往会重复同样的错误。为了突破这一瓶颈,研究界引入了 Agentic Workflow(智能体工作流) ,即自省式修复。
这就像是一个初级程序员(LLM)和一个严厉的编译器(Environment)之间的对话。
- 原理: 这种机制不再是一次性生成(One-shot),而是一个名为 Reflexion 的循环过程:
- 生成(Generate): 模型提出一个修复方案 P_0。
- 验证(Verify): 系统运行测试用例,发现 P_0 失败,报错信息为 E_{error}。
- 反思(Reflect): 关键的一步。系统将 P_0 和 E_{error} 喂回给模型,并提问:"你之前的修复失败了,错误原因是 E_{error},请分析为什么失败,并给出一个新的计划。"
- 修正(Correct): 模型根据反思结果,生成新的补丁 P_1。
- 案例模拟:
- AI (尝试 1):return x + y;
- System:测试失败。输入 2, 3,期望 6,实际得到 5。
- AI (反思):啊,我看错了需求,原来是乘法而不是加法。
- AI (尝试 2) :return x * y; -> 测试通过。
- 价值: 研究表明,引入"反思"机制后,LLM 在 HumanEval 等基准测试上的修复成功率(Pass Rate)可以从 50% 飙升至 80% 以上。它让模型从单纯的"概率预测机"进化为了具备"逻辑推理与纠错能力"的智能体,能够解决那些需要多步推理的复杂逻辑漏洞。
第三章:提示工程(Prompt Engineering)在漏洞修复中的艺术
如何向 AI 提问,决定了你能得到什么样的补丁。在安全修复领域,Prompt Engineering 需要遵循极高的精确度。
3.1 角色扮演与思维链(Chain-of-Thought, CoT)
直接要求"修复这段代码"往往会得到平庸的结果。我们需要激发 LLM 的安全推理能力。
不仅要问 How,更要问 Why:
一个强有力的 Prompt 模板如下:
Role: You are a senior cybersecurity engineer and expert in secure coding.
Task: Analyze the provided code snippet which has been flagged with a vulnerability.
Input:
- Code: INSERT CODE
- Vulnerability Type: INSERT CWE-ID
- Error Location: Line N
Instructions:
- Analyze: Explain why this code is vulnerable step-by-step. Trace the data flow from source to sink. (Chain-of-Thought)
- Plan: Propose a remediation strategy that fixes the vulnerability without breaking the functionality.
- Patch: Generate the fixed code block. Use comments to explain the changes.
- Verify: Explain why your patch effectively mitigates the specific threat.
通过强制模型先进行分析(Analyze)和规划(Plan),我们实际上是在让模型在生成代码前"思考"。这能显著减少幻觉(Hallucination),即模型生成了看似修复但实际上引入了新 Bug 的代码。
3.2 约束提示(Constrained Prompting)
LLM 有时会"过度发挥",重构整个函数甚至改变业务逻辑。在补丁生成中,最小化变更(Minimal Diff) 是黄金法则。
我们需要在 Prompt 中加入约束:
- "Only modify the lines necessary to fix the vulnerability."(只修改必要行)
- "Do not change variable names or function signatures."(不要改名)
- "Ensure the complexity of the code does not increase significantly."(保持代码简洁)
第四章:超越文本------结构感知与 AST 引导的修复
将代码视为纯文本是危险的。一个括号的缺失、缩进的错误都会导致补丁无法编译。为了生成高质量的补丁,必须引入抽象语法树(AST)。
4.1 语法正确性保障
在 LLM 生成补丁后,我们不能直接提交。第一道关卡是语法解析器(Parser)。
如果生成的代码无法被解析为有效的 AST,说明它存在低级的语法错误。此时,我们可以构建一个反馈循环(Feedback Loop):
- LLM 生成 Patch P_0。
- Parser 尝试解析 P_0,失败,报错 E_{syntax}。
- 将 P_0 和 E_{syntax} 喂回给 LLM:"你生成的代码有语法错误,错误信息是...,请修正。"
- LLM 生成 Patch P_1。
这种迭代式修复(Iterative Repair) 能极大提高补丁的可编译率。
4.2 结构化掩码(Structural Masking)
在训练专门用于修复的 Code LLM 时,研究者开始使用基于 AST 的掩码策略。
不同于随机遮盖文本,我们遮盖 AST 中的特定子树(Subtree)。
例如,专门遮盖 if 条件判断块,或者 SQL 查询构建块。这迫使模型学习代码的结构化语义,而不是字符层面的统计规律。
第五章:补丁验证------从"看起来对"到"确实对"
这是自动化修复中最困难的一环。LLM 生成了代码,且没有语法错误,但这并不代表它修复了漏洞,更不代表它没有破坏现有功能。我们需要建立严格的验证体系。
5.1 测试驱动的生成(Test-Driven Generation)
在传统的 APR 中,我们需要预先存在测试用例。但在现实中,安全漏洞往往没有对应的测试用例(否则早就被测出来了)。
因此,AI 必须学会自己写测试。
流程如下:
- 生成复现脚本(Reproduction Script): 要求 LLM 根据漏洞描述,生成一个能触发该漏洞的攻击载荷(PoC)。
- 输入: "SQL 注入漏洞,参数 id"
- 输出: requests.get('url?id=1 OR 1=1') 并断言响应中包含数据库指纹。
- 生成回归测试(Regression Tests): 要求 LLM 为受影响的函数生成单元测试,覆盖正常业务逻辑,确保补丁不会导致服务不可用。
5.2 验证三部曲
只有通过以下三关的补丁,才能被称为"候选补丁(Candidate Patch)":
- 编译检查(Compilable): 代码符合语法规范。
- 安全通过(Security Check): 运行生成的 PoC 脚本,断言漏洞已不再触发。或者再次运行 SAST 工具,确认告警消失。
- 功能保持(Functionality Check): 运行现有的和新生成的回归测试,断言全部通过(Pass)。
5.3 评估指标:Pass@k
在学术界和工业界,衡量修复模型能力的标准指标是 Pass@k。
即:对于每个漏洞,让模型生成 k 个不同的补丁(比如 k=10)。如果这 k 个补丁中,至少有 1 个能通过所有测试,则视为修复成功。

简单来说,这个公式计算的是:当我们让模型生成 k 个方案时,其中至少有一个方案是正确的概率。这比只看唯一一次生成的准确率(Pass@1)更能客观反映模型在实际辅助修复中的潜力。
其中 n 是生成的样本总数,c 是正确的样本数。
目前的顶级模型(如 GPT-4)在 HumanEvalFix 等基准测试上的 Pass@1 已经能达到 40%-50% 的水平,结合迭代修复,Pass@10 可达 80% 以上。
第六章:实战演练------SQL 注入的自动化修复
让我们通过一个具体的案例,看看这一整套流程是如何在后台运作的。
6.1 场景描述
我们有一个遗留的 Python Flask 应用,存在一个经典的 SQL 注入漏洞。
python
# vulnerable_app.py
import sqlite3
from flask import Flask, request
app = Flask(__name__)
@app.route('/user')
def get_user():
username = request.args.get('username')
# 漏洞点:直接字符串拼接
query = "SELECT * FROM users WHERE username = '" + username + "'"
conn = sqlite3.connect('database.db')
cursor = conn.cursor()
cursor.execute(query) # 执行
return str(cursor.fetchall())6.2 Step 1: 静态分析与 Prompt 构建
SAST 工具扫描并标记了第 10 行。系统自动构建 Prompt:
Context:
The following Python code contains a SQL Injection vulnerability in get_user function.
Code:
Python
... (省略上下文)
query = "SELECT * FROM users WHERE username = '" + username + "'"
cursor.execute(query)
...
Goal: Fix the SQL Injection by using parameterized queries. Do not change the logic.
6.3 Step 2: 模型生成与 AST 检查
LLM 生成了如下补丁:
python
# Generated Patch A
query = "SELECT * FROM users WHERE username = ?"
cursor.execute(query, (username,))Parser 检查:语法正确。AST 分析显示,原本的 BinaryOp (Add) 节点被替换,且 execute 调用增加了参数。这符合参数化查询的结构特征。
6.4 Step 3: 验证与接受
系统运行测试:
- PoC 测试: 发送 username=' OR '1'='1。
- 修复前: 返回所有用户数据。
- 修复后: 返回空(因为数据库里没有名字叫 ' OR '1'='1 的人)。-> 安全通过。
- 功能测试: 发送 username=admin。
- 修复后: 返回 admin 的数据。-> 功能通过。
系统最终自动提交 Merge Request,并附上解释:"利用参数化查询修复 SQL 注入漏洞,已通过自动化测试验证。"
第七章:多模态修复------当代码不够时
有时候,修复一个漏洞需要的不仅仅是代码。特别是对于逻辑漏洞(Business Logic Flaws),仅看代码很难理解意图。未来的修复系统是多模态的(Multi-modal)。
7.1 利用文档与注释
如果代码中包含注释 // TODO: Add authentication here,或者对应的设计文档中写着"只有管理员可以访问此接口"。
多模态 LLM 可以读取这些非代码信息,理解开发者的原始意图(Original Intent)。
在修复时,它不仅仅是修补漏洞,更是补全被遗漏的业务逻辑。
7.2 利用运行时数据
对于性能回退(Performance Regression)或竞态条件(Race Condition)类的 Bug,静态代码很难体现。
通过输入动态性能剖析数据(Profiler Data) 或 日志文件(Logs),LLM 可以"看到"代码在运行时的瓶颈或死锁点,从而生成针对性的并发控制代码(如加锁)。
第八章:微调(Fine-tuning)------打造企业的专属安全修复师
虽然 GPT-4 等通用模型很强,但在特定的企业技术栈中,它们可能不懂内部框架的 API,或者不遵守代码规范。
为了达到工业级可用,企业需要对自己私有的代码库进行 微调(Fine-tuning)。
8.1 数据集构建:Commit-Pair 挖掘
我们可以挖掘企业 Git 历史中所有涉及"Fix"、"Security"、"Patch"关键词的提交。
构建成对数据:(Vulnerable_Version, Fixed_Version)。
这让模型学习企业内部特有的修复模式(Patterns)。
例如:你们公司的加密库不是 hashlib 而是 internal_crypto_lib。通用模型不知道这一点,但微调后的模型知道。
8.2 LoRA (Low-Rank Adaptation) 的应用
全量微调一个 70B 的模型成本极高。利用 LoRA 技术,我们只需要训练模型参数的 1% 甚至更少,就能让模型适配特定任务。
这使得每个开发团队都可以拥有一个专属于自己项目的"AI 修复助手",它懂你的变量命名习惯,也懂你的架构分层。
第九章:幻觉陷阱(The Hallucination Trap)------当良药变成毒药
LLM 最著名的弱点是"一本正经地胡说八道"。在闲聊时这或许无伤大雅,但在修补高危漏洞时,这可能是灾难性的。
9.1 "虚构依赖"与包幻觉(Package Hallucination)
研究发现,当要求 LLM 修复某些复杂的加密或数据处理漏洞时,模型有时会引入一个不存在的 Python 包 或 NPM 模块。
- 场景: AI 建议:"为了安全地处理这个 YAML 文件,请使用库 secure-yaml-parser-v2。"
- 风险: 这个库并不存在。如果开发者真的去 pip install,黑客可能抢先注册这个名字的恶意包(Typosquatting),从而通过供应链攻击入侵系统。
- 防御: 修复系统必须集成 包管理器校验器(Package Validator),在采纳补丁前,查询 PyPI 或 NPM 官方仓库,确认引入的依赖不仅存在,而且具有良好的声誉(Star数、维护活跃度)。
9.2 修复引发的次生漏洞(Regressive Bugs)
为了修复 SQL 注入,AI 可能会引入 拒绝服务(DoS)。
- 案例: AI 将字符串拼接改为复杂的正则表达式验证。
python
# AI 补丁
import re
if re.match(r"^([a-zA-Z0-9]+)*", user_input): # 引入了 ReDoS 漏洞!
process(user_input)- 分析: 虽然这阻止了 SQL 注入,但这个正则存在 灾难性回溯(Catastrophic Backtracking) 风险。攻击者发送特定的长字符串即可耗尽 CPU。
- 对策:多维安全扫描(Multi-dimensional Scanning)。 自动化修复流水线不能只验证"原漏洞是否修复",还必须对新生成的代码进行全量的 SAST 扫描,确保没有引入新的 CWE。
9.3 开源协议污染(License Contamination)------隐形的法律地雷
当 LLM 建议修复代码时,它引用的代码片段可能来自于它训练数据中的某个开源项目。
- 风险场景: 你的企业项目是闭源商业软件(Proprietary),但 AI 生成的修复补丁不仅逻辑正确,而且是一段受 GPL v3 协议保护的代码(例如来自 Linux 内核的某种特定实现)。
- 后果: 一旦这段代码被合入你的代码库,根据 GPL 的"传染性",理论上你的整个商业软件都需要被迫开源。这被称为"开源洗白(Open Source Laundering)"风险。
- 防御: 企业级修复系统必须包含**代码溯源(Code Attribution)**功能。在采纳补丁前,利用向量数据库检索该代码片段是否与 GitHub 上某些高风险许可证(GPL, AGPL)的项目高度相似。如果是,必须拒绝该补丁或要求 AI 重写。
第十章:超越单文件------代码仓库级(Repo-Level)的上下文感知
大多数现有的学术研究都集中在单函数修复。但在微服务架构中,修改一个接口定义可能需要同时修改 5 个相关文件。如果 LLM 看不到全局,它生成的补丁就是"断头"的。
10.1 静态程序分析与 RAG 的结合
为了让 LLM 理解整个仓库,我们不能把百万行代码都塞进 Context Window(尽管 Gemini 1.5 Pro 等模型正在解决这个问题,但成本依然高昂)。
更高效的方法是 基于图的检索(Graph-based Retrieval)。
- 构建代码属性图(Code Property Graph, CPG): 将整个项目解析为依赖图。节点是函数/类,边是调用关系(Call Graph)或数据流(Data Flow)。
- 上下文检索: 当 LLM 尝试修复 File A 中的函数 foo() 时,系统自动沿着 CPG 检索:
- 调用了 foo() 的所有函数(Caller)。
- foo() 调用的所有函数(Callee)。
- foo() 使用的全局变量定义。
- Prompt 增强: 将这些跨文件的代码片段一并喂给 LLM:"请修复 foo(),并注意它被 File B 和 File C 调用,确保接口兼容性。"
10.2 依赖感知(Dependency-Aware)的生成
当修复涉及第三方库升级(例如 Log4j 2.14 -> 2.17)时,LLM 必须知道这是否破坏了向后兼容性(Breaking Changes)。
这需要 AI 访问 外部知识库(如 Maven Central 的变更日志或 GitHub Release Notes)。
未来的 IDE 插件将不再是单纯的代码补全,而是一个 "依赖关系仲裁者",它能告诉你:"如果你升级这个包来修复漏洞,你需要修改以下 3 个文件的调用方式。"
第十一章:人机协同(Human-in-the-Loop)与可解释性
在安全领域,信任是奢侈品。资深的安全工程师绝不会盲目接受 AI 生成的代码。因此,自动化修复系统的 UX(用户体验)设计至关重要。
11.1 解释性补丁(Explainable Patches)
系统生成的 Pull Request (PR) 不能只有代码变更,必须包含 生成的解释文档。
- 漏洞原因: "第 42 行未对用户输入进行 HTML 实体编码,导致 XSS。"
- 修复策略: "引入 OWASP Java Encoder 库,使用 Encode.forHtml() 方法。"
- 安全性证明: "已生成攻击载荷 <script>alert(1)</script> 进行测试,修复后输出为 <script>...,攻击失效。"
- 副作用分析: "此修改仅影响显示层,不影响数据库存储格式。"
这种结构化的解释能将人工代码审查(Code Review)的时间从 30 分钟缩短到 3 分钟。
11.2 交互式修复(Interactive Repair)
如果工程师觉得 AI 的补丁太激进,他们应该能通过自然语言进行微调。
- Dev: "这个修复太复杂了,有没有更轻量级的方案?不要引入新库。"
- AI: "收到。这是方案 B:使用原生的 replace() 函数手动过滤,虽然不如库全面,但能防御 99% 的常见攻击且无依赖。"
这种 对话式编程(Conversational Programming) 将是 DevSecOps 的新常态。
11.3 算力成本账------修复一个 Bug 值多少钱?
自动化修复虽然好,但不是免费的。
- Token 经济学: 修复一个复杂的 Java 反序列化漏洞,可能需要输入整个类文件、相关的 XML 配置以及报错日志,Context 长度轻松超过 10k Tokens。加上"自省式修复"的多轮对话,修复一个 Bug 的 API 调用成本可能在 0.5 到 2 美元之间。
- ROI 计算:
- 人工修复: 安全工程师时薪 100 美元,修复+测试耗时 4 小时 = 400 美元。
- AI 修复: API 成本 2 美元 + 人工审核 15 分钟(25 美元) = 27 美元。
- 结论: 对于高危、紧急漏洞,AI 的 ROI 极高;但对于低优先级的 Code Smell(代码异味),盲目使用 GPT-4 可能会导致预算烧穿。未来的趋势是模型分级策略(Model Routing):简单语法错误交给低成本的 7B 模型(如 CodeLlama),复杂逻辑漏洞才调用昂贵的 GPT-4 或 Claude 3 Opus。
第十二章:机器对机器(Machine-vs-Machine, MvM)的终极博弈
这是网络安全的未来图景。
当黑客使用 AI 自动挖掘漏洞并生成 Exploit(漏洞利用代码)时,防御方的人工响应速度(数小时或数天)将完全失效。我们必须进入 机器光速攻防 时代。
12.1 自动攻防挑战赛(Cyber Grand Challenge, CGC)
DARPA 在 2016 年举办的 CGC 是这一领域的先驱。而在 LLM 时代,这变得更加惊心动魄。
- 攻击方 AI: 持续扫描目标网络,分析补丁差异(Patch Diffing),自动生成 N-Day Exploit。
- 防御方 AI: 监控流量,一旦发现异常(哪怕是未知的 0-Day),立即在沙箱中重放流量,分析崩溃点,并在毫秒级生成临时热补丁(Hotpatch)。
12.2 虚拟补丁(Virtual Patching)与 WAF 联动
在源代码修复发布之前,LLM 可以先生成 WAF(Web应用防火墙)规则。
- 漏洞: /api/v1/search 存在 SQL 注入。
- AI生成规则: Block request if URI matches /api/v1/search AND query_param contains (UNION|SELECT|SLEEP).
- 部署: 自动推送到边缘网关。
这为开发团队赢得了宝贵的"源代码修复时间"。
第十三章:代码实战------训练一个基于 T5 的漏洞修复模型
我们将使用 Hugging Face 的 transformers 库,演示如何微调一个 CodeT5 模型来执行代码修复任务。
13.1 数据集准备
我们需要 (Buggy_Code, Fixed_Code) 对。可以使用 BigVul 或 Defects4J 数据集。
python
# 示例数据格式
examples = [
{
"buggy": "query = 'SELECT * FROM users WHERE name = ' + user_input",
"fixed": "query = 'SELECT * FROM users WHERE name = ?', (user_input,)"
},
# ... 更多数据
]13.2 模型微调 (Fine-tuning)
python
import torch
from transformers import RobertaTokenizer, T5ForConditionalGeneration, Trainer, TrainingArguments
from datasets import Dataset
# 1. 加载预训练模型 (Salesforce/codet5-small)
model_name = "Salesforce/codet5-small"
tokenizer = RobertaTokenizer.from_pretrained(model_name)
model = T5ForConditionalGeneration.from_pretrained(model_name)
# 2. 数据预处理
def preprocess_function(examples):
# 输入: "Fix: " + 有漏洞的代码
inputs = ["Fix: " + code for code in examples["buggy"]]
# 目标: 修复后的代码
targets = examples["fixed"]
model_inputs = tokenizer(inputs, max_length=512, truncation=True, padding="max_length")
labels = tokenizer(targets, max_length=512, truncation=True, padding="max_length").input_ids
# 将 padding token 的 label 设为 -100,以便在计算 loss 时忽略
labels = [ [(l if l != tokenizer.pad_token_id else -100) for l in label] for label in labels]
model_inputs["labels"] = labels
return model_inputs
# 假设 dataset 已经加载为 Hugging Face Dataset 对象
# tokenized_datasets = dataset.map(preprocess_function, batched=True)
# 3. 定义训练参数
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=4,
num_train_epochs=3,
weight_decay=0.01,
save_total_limit=2,
)
# 4. 初始化 Trainer
# trainer = Trainer(
# model=model,
# args=training_args,
# train_dataset=tokenized_datasets["train"],
# eval_dataset=tokenized_datasets["test"],
# )
# 5. 开始训练
# trainer.train()13.3 推理与生成 (Inference)
python
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)
def generate_fix(buggy_code):
input_text = "Fix: " + buggy_code
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to(model.device)
outputs = model.generate(
input_ids,
max_length=512,
num_beams=5, # 使用 Beam Search 寻找最优解
early_stopping=True
)
fixed_code = tokenizer.decode(outputs[0], skip_special_tokens=True)
return fixed_code
# 测试
vuln_code = "cursor.execute('SELECT * FROM posts WHERE id = ' + post_id)"
print(f"Original: {vuln_code}")
print(f"Fixed: {generate_fix(vuln_code)}")
# 预期输出: cursor.execute('SELECT * FROM posts WHERE id = ?', (post_id,))代码解读
这段代码展示了利用 Sequence-to-Sequence (Seq2Seq) 架构处理代码修复的核心逻辑。
- Tokenizer: 将代码转化为 Token ID 序列。
- Beam Search: 在生成时,不是每次只选概率最高的词(Greedy),而是保留前 K 个最优路径,这对于代码生成至关重要,因为代码对语法的严谨性要求极高。
- CodeT5: 这是一个专门为代码理解和生成预训练的模型,它理解编程语言的语法结构,比通用的 T5 效果更好。
结语:构建数字世界的"免疫系统"------从被动防御到有机共生
我们正站在软件工程历史的一个奇点上。过去四十年,安全防御的本质是"亡羊补牢"------我们不得不依赖疲惫不堪的安全工程师,在海量的代码山中寻找那根致命的针。这种不对称的战争,让防御者永远处于劣势。
然而,LLM 驱动的自动化修复(APR)正在彻底重写这一规则。我们不再是在修补软件,而是在赋予软件生命力。
当代码具备了"感知痛苦(发现漏洞)"并"自我愈合(自动修复)"的能力时,软件系统将不再是冰冷的逻辑堆砌,而是一个有机的、具备**数字免疫力(Digital Immunity)**的生命体。未来的安全架构,将不再依赖于构建坚不可摧的"长城",因为没有系统是绝对完美的;真正的安全,在于像人体一样,当病毒入侵时,能以毫秒级的速度调动抗体,完成围剿与修复。
在这个新时代,安全工程师的角色将发生根本性的蜕变:
- 从"消防员"变为"免疫学家":不再亲自冲进火场灭火(写补丁),而是设计更高效的免疫机制(优化修复 Agent 的 prompt 和决策逻辑)。
- 从"守门员"变为"教练":通过高质量的数据反馈,训练 AI 模型识别更复杂的攻击模式,避免"免疫风暴"(误报和次生灾害)。
漏洞永远不会消失,但"漏洞导致灾难"的时代终将终结。这不仅是技术的胜利,更是人类智慧与机器算力共生进化的必然归宿。让我们拥抱这个**自治修复(Autonomous Remediation)**的时代,看着我们的系统在每一次攻击中,变得更加强大。
下期预告:第 24 篇《蜜罐进化:AI 驱动的动态高仿真诱饵系统》
既然我们已经学会了如何加固自身(修复漏洞),那么是否可以主动出击,诱捕攻击者呢?
传统的蜜罐(Honeypot)往往是静态的、容易被识破的。
黑客一眼就能看出:"哦,这个 SSH 服务版本是 2012 年的,这肯定是个陷阱。"
下一章,我们将探讨:
- 动态伪装: AI 如何实时生成逼真的业务数据(虚假的客户名单、动态的日志流),让黑客在蜜罐里"流连忘返"。
- 图灵测试级交互: 当黑客在蜜罐里输入 ls -la 时,AI 如何根据黑客的行为习惯,动态生成一个"刚刚好符合他预期"的文件列表?
- 反向溯源: 如何在黑客与 AI 诱饵互动的过程中,提取黑客的指纹和攻击工具特征?
敬请期待 第 24 篇《蜜罐进化:AI 驱动的动态高仿真诱饵系统》。
陈涉川
2026年02月08日