面对海量非结构化的旅游攻略,如何用技术手段一键提取关键信息与完整正文?这篇技术文章为你揭秘完整方案。
大家好,我是@iFeng的小屋。今天分享一个针对去哪儿网旅游攻略板块的爬虫项目,它能高效地批量抓取结构化游记数据,并深入详情页提取完整的正文内容。
一、项目概述与技术选型
1.1 项目背景
旅游攻略平台(如去哪儿网)包含大量用户生成的游记,这些数据对旅游行业分析、目的地研究、内容聚合等领域具有重要价值。然而,人工采集效率低下,且难以保证数据的结构化与一致性。本项目旨在通过自动化爬虫技术,高效、准确地批量采集游记的核心字段与全文内容。
二、展示爬取结果
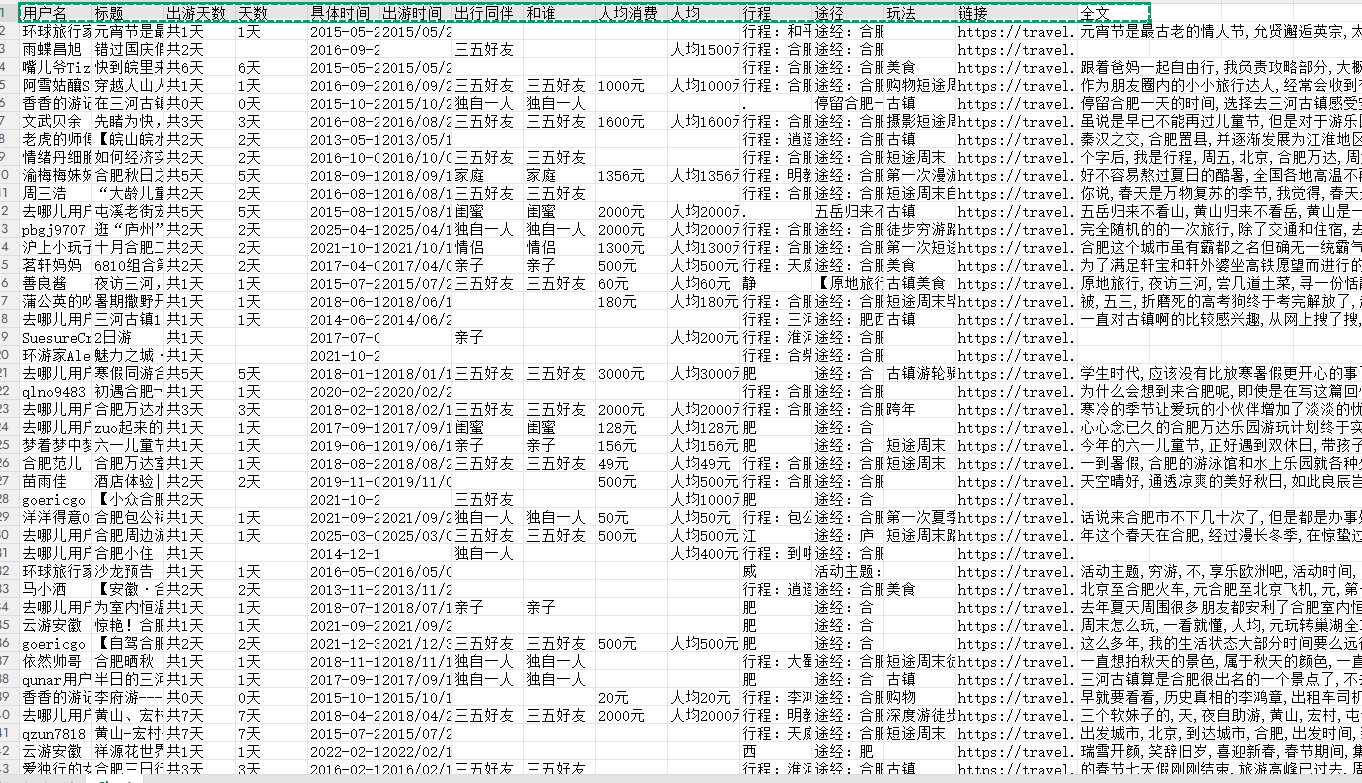
字段:++用户名,标题,出游天数,具体时间,出行同伴,人均消费,形成,途径,玩法,链接,全文。++
所有数据自动保存到Excel,拿去就能做分析!
三、爬虫代码
导入需要的库:
python
import time
import requests
from lxml import etree
import openpyxl
import re定义一个请求头,Cookie是关键:
python
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36...',
'referer': 'https://travel.qunar.com/...',
'cookie': "这里换成你自己的cookie", # 关键!不换爬不了
}Cookie怎么获取? 登录去哪儿网攻略页面后,按F12打开开发者工具,在Network里找个请求,复制完整的Cookie值就行。
3.1 核心操作:抓列表+抓详情
这个爬虫聪明在两步走:先抓列表页概要,再逐个进入详情页抓正文。
第一步:抓列表页,提取基本信息
python
def parse_one_page(html):
# 找到页面里所有游记条目
ii_list = html.xpath('//li[@class="list_item "]')
for ii in ii_list:
# 用XPath精准提取标题、作者、天数、费用等
title = ii.xpath('.//h2[@class="tit"]//text()')[0].strip()
user = ii.xpath('.//span[@class="user_name"]/a/text()')[0].strip()
# ... 提取其他字段
# 关键:拼凑出详情页的链接
url = 'https://travel.qunar.com/travelbook/note/' + ii.xpath('.//h2[@class="tit"]/a/@href')[0].replace('/youji/', '')第二步:深入详情页,抓取完整正文
python
# 访问上一步得到的详情页链接
res1 = requests.get(url, headers=headers, timeout=10)
hji2 = etree.HTML(res1.text)
# 定位到所有正文段落
memo_nodes = hji2.xpath('//div[@class="b_panel_schedule"]//div[@class="text js_memo_node"]')
quanwen_list = []
for node in memo_nodes:
# 获取每个段落的纯文本,并清理干净
text = node.xpath('string(.)').strip().replace('\xa0', '').replace('\n', '')
quanwen_list.append(text)
# 合并所有段落,形成完整游记正文
quanwen = '\n'.join(quanwen_list)
# 高级技巧:用正则提取纯中文,方便后续做文本分析
pattern = "[\u4e00-\u9fa5]+"
results = ','.join(re.findall(quanwen))3.2 翻页与保存
爬虫自动翻页,并把所有数据存进Excel:
python
# 主程序控制爬取1到15页
for i in range(1, 16):
url = f'https://travel.qunar.com/search/gonglue/22-hefei-300030/hot_heat/{i}.htm'
# 抓取并解析...
time.sleep(30) # 重要!等待一下,别把网站爬崩了
# 保存到Excel
sheet.append([用户名字段, 标题字段, ..., 全文字段]) # 把所有字段按顺序放进一行
wb.save('hefei.xlsx') # 保存文件四、如何运行?
-
装环境 :
pip install requests lxml openpyxl -
改配置 :把代码里的
cookie换成你自己的。 -
定目标:代码里默认爬"合肥",你想爬别的城市?改链接里的城市代码就行。
-
运行 :直接跑脚本,坐等
hefei.xlsx文件生成。
五、说明与源码
这个爬虫考虑了反爬,加了等待时间,但使用时还请注意频率,尊重网站规则。
代码里还有很多细节,比如异常处理、字段清洗、灵活翻页等。有需要的朋友,可以在我的公主号(与此号同名)自己获取。
我是iFeng,持续分享实用的Python技术干货。如果文章对你有帮助,欢迎点赞、收藏!