标题:《SNAP: Towards Segmenting Anything in Any Point Cloud》
项目:https://neu-vi.github.io/SNAP/
来源:东北大学;The Mathworks
文章目录
摘要
交互式3D点云分割技术通过用户引导提示,能够高效标注复杂3D场景。然而现有方法通常局限于单一场景类型(室内或室外)和单一交互形式(空间点击或文本提示)。此外,多数据集训练常导致负迁移现象,使得工具缺乏通用性。
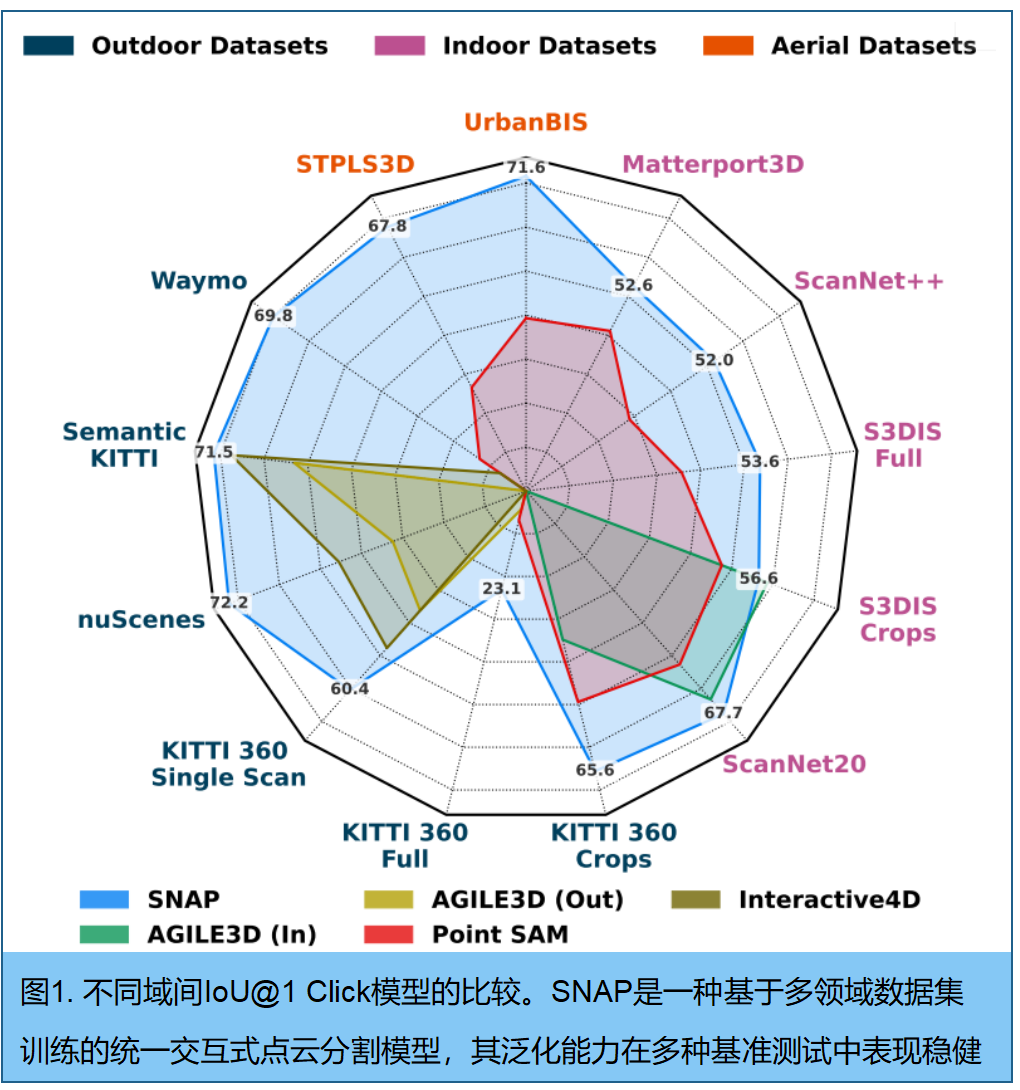
SNAP(任意点云中任意对象分割)是一个支持跨场景点云与文本提示的统一模型。该方法通过训练涵盖室内、室外及航拍环境的7个数据集,并采用领域自适应归一化防止负迁移,实现跨场景泛化能力。对于文本提示分割,我们无需人工干预即可自动生成 mask proposal,并将其与CLIP文本查询嵌入进行匹配,从而支持全景式和开放词汇表分割。大量实验表明,SNAP始终能产出高质量分割结果:在8/9个零样本基准测试中,其空间提示分割表现达到业界顶尖水平;在全部5个文本提示基准测试中均取得优异成绩。这些结果证明统一模型可媲美甚至超越特定领域专用方法,为可扩展3D标注提供了实用工具。
一、相关工作
基于空间提示的交互式3D分割技术。自SAM1问世以来,交互式分割在二维领域已发展成熟,但在三维空间中的应用仍相对有限。早期研究如InterObject3D2和AGILE3D3主要针对室内点云,通过正/负点击实现单目标或多目标分割。Point-SAM4则利用SAM生成的伪标签支持室内及部件级分割。Interactive4D5则采用四维空间框架处理室外激光雷达序列。然而这些研究普遍局限于室内或室外场景,对跨领域点云的泛化能力较弱。相比之下,SNAP系统专为跨领域稳健性而设计,能够灵活适配不同场景。
基于文本的三维分割研究。另一研究方向将自然语言作为三维分割的灵活接口。在此领域,开放词汇分割方法25-28致力于识别超出固定标签集的新型或用户指定类别。OpenScene25通过直接在三维域中预测点级CLIP嵌入(无需依赖图像)实现了这一目标。相比之下,26-28采用原始RGB图像或渲染的多视角图像提取CLIP图像特征,并将其与文本嵌入对齐以实现基于文本的分割。互补方向是全景分割,其目标是提供跨所有类别的实例级预测。7,29通过预测每个实例的CLIP标记并与预定义类别词汇表对齐,支持类特定实例分割,以此为例证该方法。SNAP能够在单一框架内同时适应开放词汇和全景分割场景。
三维分割中的二维基础模型迁移技术。由于标注三维数据的获取受限,近期研究如SAM3D30和SAMPro3D31主要致力于将稳健的二维基础模型迁移至三维领域。但这些方法需要配对的图像与点云数据,导致其在仅含激光雷达数据集或传统数据集的实际应用场景中存在局限。4,7,32采用SAM1生成基于RGB图像的伪标签,并利用这些数据训练室内场景的三维模型,而PointSAM4则进一步实现了部件级分割。虽然该过程能生成大量训练数据,但伪标注过程总会引入标签噪声。SNAP通过整合公开数据集进行训练,彻底规避了这一问题,并在多个未见数据集上实现了业界领先的表现。
二、点云编码
输入点云 P = P= P={ p i ∈ R 3 p_i∈ R^3 pi∈R3} i = 1 N ^N_{i=1} i=1N,采用 Point Transformer V3 (PTv3 33)提取逐点嵌入 F p c ∈ R N × D F_{pc}∈R^{N×D} Fpc∈RN×D。为支持跨域泛化,将PTv3中的常规批量归一化替换为域归一化。
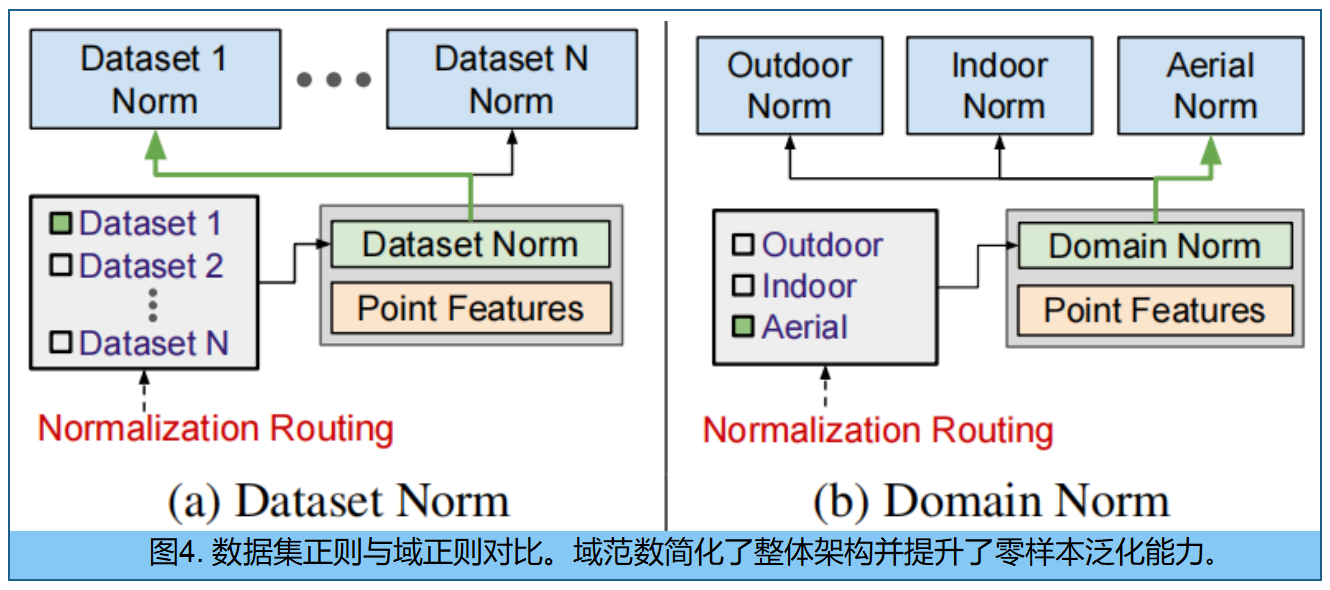
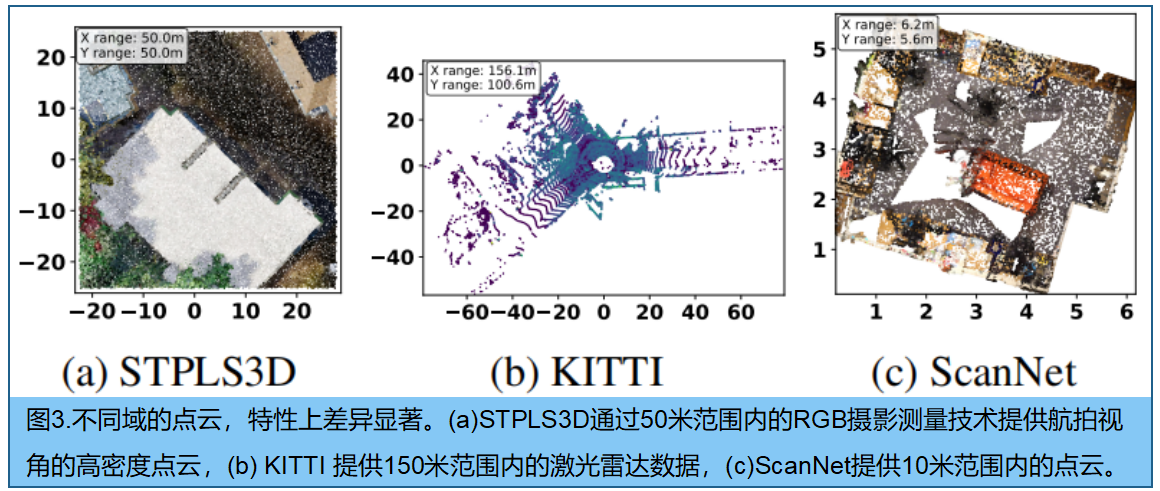
多数据集训练的域归一化 。多个点云数据集上训练单一模型时,由于不同数据集间显著的分布差异会导致负迁移现象6,其性能往往不如针对每个数据集单独训练的模型,如图3所示。为缓解这一问题,直接的解决方案是采用数据集特定归一化方法6,即为训练集中的每个数据集学习独特的归一化参数。数据集特定归一化还可能限制相关数据集之间的知识迁移,而这种迁移本可以从共享表征中获益。
域特定归一化方法 :将数据集按统计特性(如室内、室外或航拍)归类为更广泛的域,并为每个域单独学习归一化参数。该策略使模型既能有效适应不同数据分布,又可通过识别数据集所属的通用领域保持灵活性,从而更直观地应用于新数据集------相较于图4所示的特定数据集参数选择方案,这种决策方式更具直观性。
形式上,将域的集合表示为 D = D= D={ D j D_j Dj}。 第 k 层的来自第 j 个域的激活值 x ˉ j k \bar{x} ^k_j xˉjk 的域归一化表达式为:
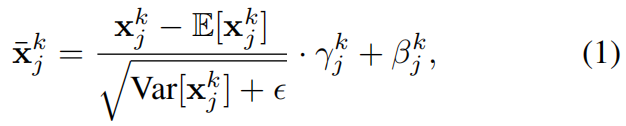
其中 γ j k γ_j^k γjk和 β j k β_j^k βjk是通过学习获得的领域特定缩放和平移参数 。与标准BN和数据集特定的归一化方法相比,这种领域特定的设计使模型能够在共享所有域核心模型权重的同时,有效适应各领域独特的统计特征。
三、空间提示分割
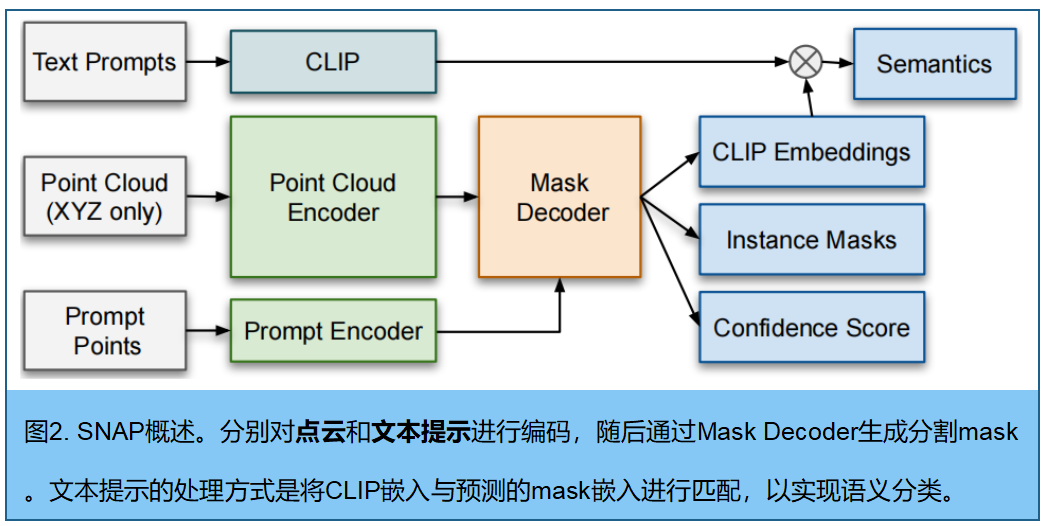
空间提示编码器 。给定一个空间提示点 p s p ∈ R 3 p_{sp}∈R^3 psp∈R3:
- 1.点云中找到其最近邻点 : i ∗ = a r g m i n i ∥ p s p − p i ∥ 2 i^∗=arg min_i∥p_{sp}−p_i∥^2 i∗=argmini∥psp−pi∥2
- 2.从逐点的PTv3 嵌入特征 F p c F_{pc} Fpc中获取对应的点嵌入 f s e m = f i ∗ f_{sem}=f_{i^∗} fsem=fi∗
- 3.同时计算提示点的位置编码 : f p o s = ϕ ( p s p ) f_{pos}= ϕ (p_{sp}) fpos=ϕ(psp), ϕ ( ⋅ ) ϕ(·) ϕ(⋅) 为文献34中定义的傅里叶编码函数。
- 4.最终的空间提示嵌入 : F s p = Φ s p ( f s e m ∥ f p o s ) ∈ R D F_{sp}= Φ_{sp} (f_{sem}∥f_{pos})∈R^D Fsp=Φsp(fsem∥fpos)∈RD, Φ s p ( ⋅ ) Φ_{sp}(·) Φsp(⋅)为学习得到的投影函数,·∥·表示特征拼接。
- 给定M个对象上的P个提示点(点击)时,最终得到 F s p ∈ R M × P × D F_{sp}∈R^{M×P×D} Fsp∈RM×P×D 。
掩码解码器 接收两个输入:点云嵌入的 F p c ∈ R N × D F_{pc}∈R^{N×D} Fpc∈RN×D,以及提示嵌入的 F s p ∈ R M × P × D F_{sp}∈R^{M×P×D} Fsp∈RM×P×D 。受SAM启发,为每个对象额外引入三个任务特定的可学习token,分别负责预测最后mask、其置信度评分以及CLIP嵌入,最终生成 F s p ∈ R M × ( P + 3 ) × D F_{sp}∈R^{M×(P+3)×D} Fsp∈RM×(P+3)×D。该过程先将点云的上下文信息整合到提示嵌入中,再利用优化后的提示对点云嵌入进行条件化处理。每个模块内部的更新顺序:
- Prompt 自注意力: Z 1 = Ψ 1 ( F s p , F s p ) Z_1 = Ψ_1 (F_{sp},F_{sp}) Z1=Ψ1(Fsp,Fsp)。
- Prompt-to-point 交叉注意力: Z 2 = Ψ 2 ( Z 1 , F ~ p c ) Z_2 = Ψ_2 (Z_1,\tilde{F}_{pc}) Z2=Ψ2(Z1,F~pc)。
- 前馈网络(FFN): Z s p = Φ ( Z 2 ) Z_{sp} = Φ (Z_2) Zsp=Φ(Z2)。
- Point-to-Prompt 交叉注意力: Z p c = Ψ 3 ( F ~ p c , Z s p ) Z_{pc} = Ψ_3 (\tilde{F}{pc},Z{sp}) Zpc=Ψ3(F~pc,Zsp)。
每个 Ψ ( ⋅ ) Ψ(·) Ψ(⋅)表示多头注意力模块,接收两个输入:一个查询,一个键值。 Φ Φ Φ 为位置依赖的前馈网络。 解码器最终输出精炼的提示嵌入 Z s p ∈ R M × ( P + 3 ) × D Z_{sp}∈ R^{M×(P +3)×D} Zsp∈RM×(P+3)×D 和条件化点云嵌入 Z p c ∈ R M × N × D Z_{pc} ∈ R^{M×N×D} Zpc∈RM×N×D。
为生成预测结果,首先将可学习的token嵌入从优化后的提示嵌入 Z s p Z_{sp} Zsp中分离。提取嵌入如下:mask token嵌入 Z m a s k ∈ R M × 1 × D Z_{mask}∈R^{M×1×D} Zmask∈RM×1×D、CLIP token 嵌入 Z C L I P ∈ R M × 1 × D Z_{CLIP}∈ R^{M×1×D} ZCLIP∈RM×1×D、mask置信度评分标记嵌入 Z S ∈ R M × 1 × D Z_S ∈ R^{M×1×D} ZS∈RM×1×D,以及辅助mask token 嵌入 Z a u x ∈ R M × P × D Z_{aux} ∈ R^{M×P×D} Zaux∈RM×P×D,并保留原始提示点嵌入作为辅助嵌入 Z a u x ∈ R M × P × D Z_{aux}∈R^{M×P×D} Zaux∈RM×P×D。

四、文本提示分割
流程包含两个阶段:(1) 通过空间提示分割模块,自动生成提示点以生成 mask proposal;(2) 将每个mask的预测CLIP嵌入,与输入文本提示进行匹配。
自动提示点生成。无需人工干预,采用迭代式粗到细的策略,实现点云全面分割。首先通过粗粒度体素化,以体素中心作为提示点生成初始mask候选。随后识别未分割区域,并在这些区域中使用逐步缩小的体素尺寸生成新提示,持续进行固定次数的迭代。最后通过非极大值抑制算法去除冗余重叠mask。该方法既能确保全面覆盖,又避免了在已分割区域的重复计算,相较于二维版本SAM1采用的均匀网格采样,实现了精度与效率的更优平衡。
文本提示编码与匹配。为对生成的 mask proposal 分类,采用CLIP文本编码器16对输入文本编码。训练时,使用类别名称作为文本提示来训练SNAP模型。具体而言,我们将类别名称封装在完整句子中(例如:班级名称的照片)。推理阶段,通过将生成的 mask proposal 与编码后的文本提示进行预测的CLIP嵌入对比,实现文本查询的匹配。该机制既支持使用预定义词汇表进行全景分割,也能为新对象类别提供开放词汇表分割。
五、训练
点击采样策略 。参照AGILE3D3和Interactive4D5的方法,采用迭代式点击采样策略 来模拟用户点击行为。与需要计算并排序误差区域以获取额外点击的复杂计算流程不同,我们通过从每个对象的未分割区域中随机采样点击,采用了一种更简便的方法。
训练损失 。基于先前研究1,3,5,我们采用Focal35和Dice36损失函数,利用标注的真实实例分割标签对掩码预测进行监督。参照5的方法,我们还引入了基于用户点击邻近度的权重调节机制。此外,为确保每次点击都能独立生成合理的掩码预测,我们采用了辅助掩码损失(Laux),该方法通过上述定义的辅助掩码token嵌入来生成额外的掩码预测。为提升掩码置信度评分的可靠性,我们还引入了评分预测损失(Lscore)。具体而言,每个掩码的目标评分定义为预测掩码与其对应真实掩码之间的交并比(IoU)。在监督预测类别标签时,我们使用Ltext损失函数,通过余弦距离惩罚预测文本标记的CLIP嵌入与类别词汇表之间的错误对齐。我们的整体损失函数可表示为:
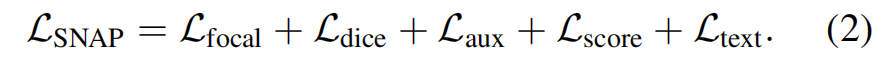
实验
实验设置
7个数据集:均带有真实实例分割标签,涵盖三大领域:
- (i)来自ScanNet11和HM3D12,37的室内场景;
- (ii)来自SemanticKITTI8,20、nuScenes9和Pandaset10的室外驾驶序列;
- (iii)来自STPLS3D13和dales14,23的航拍点云。
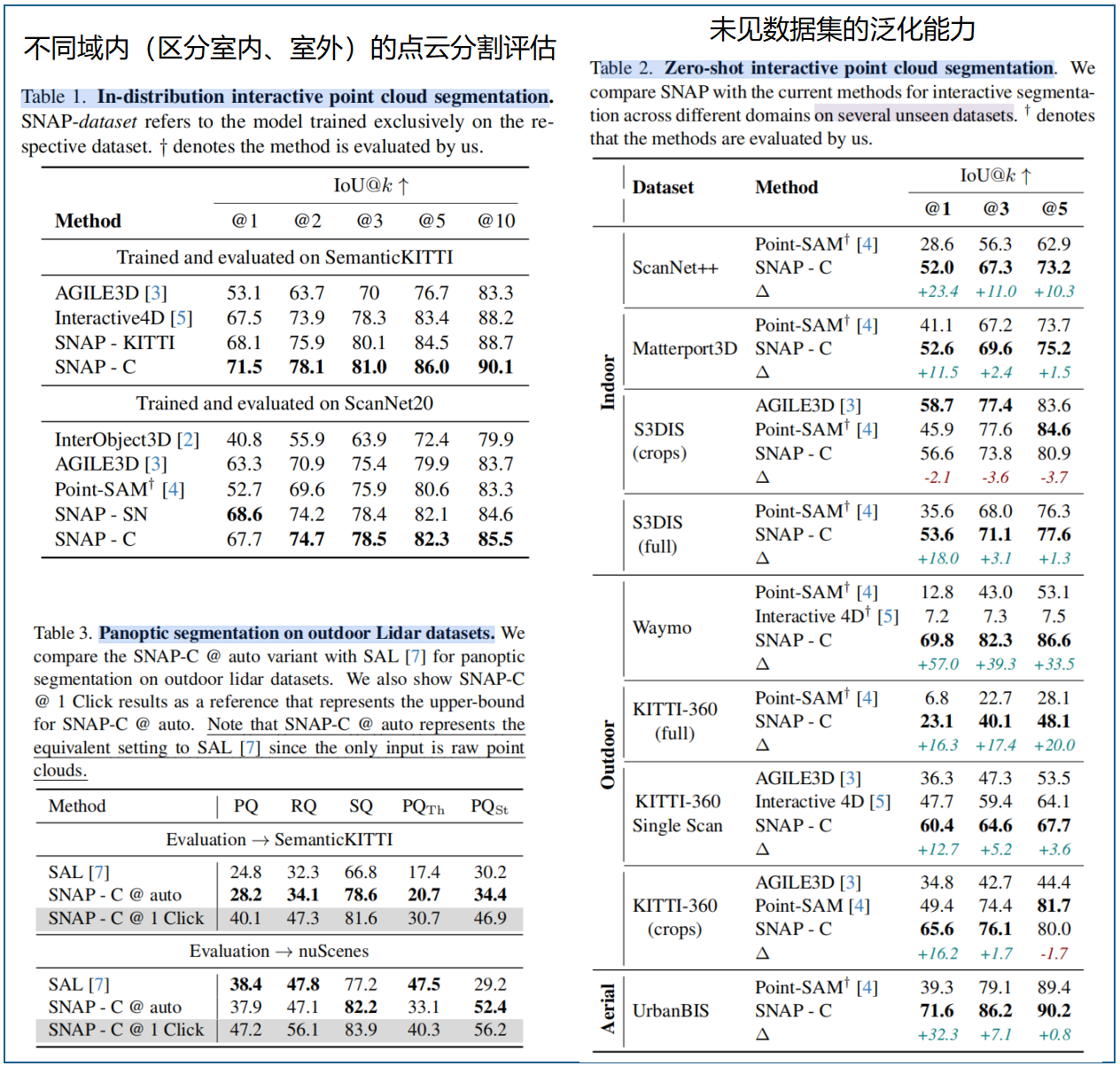
我们在各领域预留数据集上评估零样本性能:室内场景使用S3DIS19(完整版及裁剪版)、ScanNet++17和Matterport3D18;室外场景采用Waymo22和 KITTI -36021(完整版、裁剪版及单次扫描);航拍场景则使用UrbanBIS24
评估指标。采用IoU@k(即所有对象中每个对象通过k次点击获得的平均交并比)来评估空间提示分割效果。对象类别预测能力,采用平均精度(mAP)指标;对于全景分割,使用全景质量(PQ)、分割质量(SQ)和识别质量(RQ)作为评估指标
SNAP仅基于XYZ坐标进行操作,无需依赖任何额外的点属性(如颜色、法线、强度),因为这些特征在不同数据集中的可用性并不一致 。我们评估了 6种SNAP变体 以提供全面对比。
- 首先,训练了数据集特定模型:在SemanticKITTI8上训练的SNAP- KITTI 和在ScanNet11上训练的SNAP-SN。
- 其次,训练了利用所有可用域内数据集的域特定模型:SNAPIndoor、SNAP-Outdoor和SNAP-Aerial。
- 最后, SNAPC 代表我们在所有数据集上训练的完整模型,作为最具泛化性的变体 。,SNAP-C@auto指自动提示点生成设置,该模型仅提供点云数据以实现与基线方法的公平比较。

#pic_center =40%x80%
d \sqrt{d} d 1 8 \frac {1}{8} 81 x ˉ \bar{x} xˉ D ^ \hat{D} D^ I ~ \tilde{I} I~ ϵ \epsilon ϵ
ϕ \phi ϕ ∏ \prod ∏ a b c \sqrt{abc} abc ∑ a b c \sum{abc} ∑abc
/ $$ E \mathcal{E} E