目录
[5.1 数组](#5.1 数组)
[5.1.1 Array(数组)的介绍](#5.1.1 Array(数组)的介绍)
[5.1.2 数组定义](#5.1.2 数组定义)
[5.1.3 数组的初始化](#5.1.3 数组的初始化)
[5.1.4 数组的遍历](#5.1.4 数组的遍历)
[5.1.5 数组是值类型](#5.1.5 数组是值类型)
[5.1.6 多维数组](#5.1.6 多维数组)
[5.1.7 数组练习题](#5.1.7 数组练习题)
[5.2 切片](#5.2 切片)
[5.2.1 为什么要使用切片](#5.2.1 为什么要使用切片)
[5.2.2 切片的定义](#5.2.2 切片的定义)
[5.2.3 关于 nil 的认识](#5.2.3 关于 nil 的认识)
[5.2.4 切片的循环遍历](#5.2.4 切片的循环遍历)
[5.2.5 基于数组定义切片](#5.2.5 基于数组定义切片)
[5.2.6 切片再切片](#5.2.6 切片再切片)
[5.2.7 关于切片的长度和容量](#5.2.7 关于切片的长度和容量)
[5.2.8 切片的本质](#5.2.8 切片的本质)
[5.2.9 使用 make()函数构造切片](#5.2.9 使用 make()函数构造切片)
[5.2.10 切片不能直接比较](#5.2.10 切片不能直接比较)
[5.2.11 切片是引用数据类型--注意切片的赋值拷贝](#5.2.11 切片是引用数据类型--注意切片的赋值拷贝)
[5.2.12 append()方法为切片添加元素](#5.2.12 append()方法为切片添加元素)
[5.2.13 切片的扩容策略](#5.2.13 切片的扩容策略)
[5.2.14 使用 copy()函数复制切片](#5.2.14 使用 copy()函数复制切片)
[5.2.15 从切片中删除元素](#5.2.15 从切片中删除元素)
[5.2.16 Golang 切片排序算法以及 sort 包](#5.2.16 Golang 切片排序算法以及 sort 包)
[5.2.17 练习题](#5.2.17 练习题)
[5.3 map](#5.3 map)
[5.3.1 map 的介绍](#5.3.1 map 的介绍)
[5.3.2 map 基本使用](#5.3.2 map 基本使用)
[5.3.3 判断某个键是否存在](#5.3.3 判断某个键是否存在)
[5.3.4 map 的遍历](#5.3.4 map 的遍历)
[5.3.5 使用 delete()函数删除键值对](#5.3.5 使用 delete()函数删除键值对)
[5.3.6 元素为 map 类型的切片](#5.3.6 元素为 map 类型的切片)
[5.3.7 值为切片类型的 map](#5.3.7 值为切片类型的 map)
[5.3.8 练习题](#5.3.8 练习题)
[5.4 指针](#5.4 指针)
[5.4.1 指针存在的意义](#5.4.1 指针存在的意义)
[5.4.2 指针地址和指针类型](#5.4.2 指针地址和指针类型)
[5.4.3 指针取值](#5.4.3 指针取值)
[5.4.4 指针传值示例](#5.4.4 指针传值示例)
[5.4.5 new 和 make](#5.4.5 new 和 make)
[5.5 接口(interface)](#5.5 接口(interface))
[5.5.1 接口的介绍](#5.5.1 接口的介绍)
[5.5.2 Golang 接口的定义](#5.5.2 Golang 接口的定义)
[5.5.3 空接口](#5.5.3 空接口)
[5.5.4 类型断言](#5.5.4 类型断言)
[5.5.5 接口嵌套](#5.5.5 接口嵌套)
[5.6 结构体](#5.6 结构体)
[5.6.1 关于Golang 结构体](#5.6.1 关于Golang 结构体)
[5.6.2 Golang type 关键词自定义类型和类型别名](#5.6.2 Golang type 关键词自定义类型和类型别名)
[5.6.3 结构体定义初始化的几种方法](#5.6.3 结构体定义初始化的几种方法)
[5.6.4 结构体方法和接收者](#5.6.4 结构体方法和接收者)
[5.6.5 给任意类型添加方法](#5.6.5 给任意类型添加方法)
[5.6.6 结构体的匿名字段](#5.6.6 结构体的匿名字段)
[5.6.7 嵌套结构体](#5.6.7 嵌套结构体)
[5.6.8 嵌套匿名结构体](#5.6.8 嵌套匿名结构体)
[5.6.9 关于嵌套结构体的字段名冲突](#5.6.9 关于嵌套结构体的字段名冲突)
[5.6.10 结构体的继承](#5.6.10 结构体的继承)
[5.6.11 Go结构体和 JSON 相互转换 序列化 反序列化](#5.6.11 Go结构体和 JSON 相互转换 序列化 反序列化)
[5.6.12 结构体值接收者和指针接收者实现接口的区别](#5.6.12 结构体值接收者和指针接收者实现接口的区别)
[5.6.13 一个结构体实现多个接口](#5.6.13 一个结构体实现多个接口)
5.1 数组
5.1.1 Array(数组)的介绍
数组是指一系列同一类型数据的集合 。数组中包含的每个数据被称为数组元素(element),这种类型可以是任意的原始类型,比如 int、string 等,也可以是用户自定义的类型。一个数组包含的元素个数 被称为数组的长度。在 Go 中数组是一个长度固定的数据类型,数组的长度是类型的一部分 ,也就是说 5int 和10int 是两个不同的类型。Golang中数组的另一个特点是占用 内存 的连续性 ,也就是说数组中的元素是被分配到连续的内存地址中的,因而索引数组元素的速度非常快。和数组对应的类型是 Slice(切片) ,Slice 是可以增长和收缩的动态序列,功能也更灵活,但是想要理解 Slice 工作原理的话需要先理解数组,所以本节主要为大家讲解数组的使用。

数组基本语法:
Go
package main
import "fmt"
func main() {
// 定义一个数组变量,存储3个以太坊钱包地址
var walletAddresses [3]string // 使用string类型存储地址
// 在数组变量中插入以太坊钱包地址
walletAddresses[0] = "0x742d35Cc6634C0532925a3b844Bc454e4438f44e" // 示例地址1
walletAddresses[1] = "0x53d284357ec70cE289D6D64134DfAc8E511c8a3D" // 示例地址2
walletAddresses[2] = "0xC02aaA39b223FE8D0A0e5C4F27eAD9083C756Cc2" // WETH合约地址
fmt.Println("钱包地址列表:", walletAddresses)
}5.1.2 数组定义
Go
var 数组变量名 [元素数量]T比如:var a 5int, 数组的长度必须是常量,并且长度是数组类型的一部分。一旦定义,长度不能变。 5int 和4int 是不同的类型。
Go
var a [3]int
var b [4]int
a = b //不可以这样做,因为此时 a 和 b 是不同的类型数组可以通过下标进行访问,下标是从 0 开始,最后一个元素下标是:len-1,访问越界(下标在合法范围之外),则触发访问越界,会 panic。
5.1.3 数组的初始化
数组的初始化也有很多方式。
(1)方法一:初始化列表
初始化数组时可以使用初始化列表来设置数组元素的值。
Go
package main
import "fmt"
func main() {
// 智能合约存储使用量(单位:bytes)
var contractStorageUsage [3]uint32
// 智能合约部署Gas消耗(部分初始化)
var deploymentGasCosts = [3]int64{1500000, 2000000}
// 智能合约名称(完全初始化)
var contractNames = [3]string{"UniswapV3", "AaveV3", "Compound"}
fmt.Println("合约存储使用量:", contractStorageUsage) // [0 0 0]
fmt.Println("部署Gas消耗:", deploymentGasCosts) // [1500000 2000000 0]
fmt.Println("智能合约名称:", contractNames) // [UniswapV3 AaveV3 Compound]
}(2)方法二:自行推断 --》...
按照上面的方法每次都要确保提供的初始值和数组长度一致,一般情况下我们可以让编译器根据初始值的个数自行推断数组的长度,例如:
Go
package main
import "fmt"
func main() {
// 固定长度的区块Gas限制数组
var blockGasLimits [3]uint64
// 自动推断长度的交易Gas消耗数组
var transactionGasCosts = [...]uint64{21000, 65000}
// 自动推断长度的区块确认时间数组(秒)
var blockConfirmationTimes = [...]int{
12, // Ethereum PoS
600, // Bitcoin
2, // Solana
3, // Polygon
1, // Avalanche
}
fmt.Println(blockGasLimits) // [0 0 0]
fmt.Printf("区块Gas限制数组类型:%T\n", blockGasLimits)
fmt.Println(transactionGasCosts) // [21000 65000]
fmt.Printf("交易Gas消耗数组类型:%T\n", transactionGasCosts)
fmt.Println(blockConfirmationTimes) // [12 600 2 3 1]
fmt.Printf("区块确认时间数组类型:%T\n", blockConfirmationTimes)
}(3)方法三:索引值
我们还可以使用指定索引值的方式来初始化数组,例如:
Go
package main
import "fmt"
func main() {
// 稀疏初始化:在特定索引位置设置智能合约地址
addresses := [...]string{1: "0xC02aaA39b223FE8D0A0e5C4F27eAD9083C756Cc2", 3: "0xdAC17F958D2ee523a2206206994597C13D831ec7"}
fmt.Println(addresses) // [ 0xC02aaA39b223FE8D0A0e5C4F27eAD9083C756Cc2 0xdAC17F958D2ee523a2206206994597C13D831ec7]
fmt.Println(addresses[0]) // 空字符串
fmt.Printf("数组类型: %T\n", addresses) // type of addresses:[4]string
}5.1.4 数组的遍历
遍历数组 a 有以下两种方法:
(1)通过数组下标来访问
Go
package main // 定义当前文件属于main包,表示这是一个可独立执行的Go程序
import "fmt" // 导入fmt包,用于格式化输入输出(这里主要用于打印输出)
func main() {
// 定义一个字符串数组,包含5个区块链网络名称
// 使用...让编译器自动计算数组长度,数组类型为[5]string
var blockchainNetworks = [...]string{"Ethereum", "Polygon", "BNB Chain", "Solana", "Avalanche"}
// 使用传统的for循环遍历数组
// i := 0 初始化循环变量i为0(数组索引从0开始)
// i < len(blockchainNetworks) 循环条件:当i小于数组长度时继续执行
// i++ 每次循环后i增加1
for i := 0; i < len(blockchainNetworks); i++ {
// 通过索引i访问数组元素并打印到控制台
fmt.Println(blockchainNetworks[i])
}
}(2)通过 range 来访问
Go
package main
import "fmt"
func main() {
// 定义一个字符串数组,包含5个Web3.0热门项目名称
// 使用...自动推导数组长度,类型为[5]string
var web3Projects = [...]string{"Uniswap", "Aave", "Compound", "Curve", "MakerDAO"}
// 使用range关键字遍历数组
// range会返回两个值:当前元素的索引(index)和值(value)
// index:数组元素的索引(从0开始)
// value:数组元素的值
for index, value := range web3Projects {
// 打印每个项目的索引和名称
fmt.Println(index, value)
}
}5.1.5 数组是值类型
数组是值类型 ,赋值和传参会复制整个数组。因此改变的是副本的值,不会改变本身的值。
Go
package main
import "fmt"
// 修改一维数组(代表交易数量数组)
func modifyTransactionArray(x [3]int) {
x[0] = 100 // 尝试修改第一个元素
}
// 修改二维数组(代表多钱包余额数组)
func modifyBalanceArray(x [3][2]float64) {
x[2][0] = 100.0 // 尝试修改第三个钱包的第一个代币余额
}
func main() {
// 初始化一个交易数量数组(3笔交易的数量)
transactions := [3]int{10, 20, 30} // 分别代表10 ETH、20 ETH、30 ETH的交易数量
modifyTransactionArray(transactions) // 传递数组副本给函数
// 由于Go中数组是值类型,函数内部修改的是副本,不影响原始数组
fmt.Println("交易数量数组:", transactions) // 输出: [10 20 30]
// 初始化一个多钱包余额数组(3个钱包,每个钱包有2种代币的余额)
walletBalances := [3][2]float64{
{1.5, 2000.0}, // 钱包1: 1.5 ETH, 2000 USDT
{2.5, 3000.0}, // 钱包2: 2.5 ETH, 3000 USDT
{3.5, 4000.0}, // 钱包3: 3.5 ETH, 4000 USDT
}
modifyBalanceArray(walletBalances) // 传递数组副本给函数
// 同样,函数内部修改的是副本,不影响原始数组
fmt.Println("钱包余额数组:", walletBalances) // 输出: [[1.5 2000] [2.5 3000] [3.5 4000]]
}注意:
(1)数组支持**"=="、"!="** 操作符,因为内存总是被初始化过的。
(2)n*T 表示指针数组,*nT 表示数组指针。
5.1.6 多维数组
Go 语言是支持多维数组的,我们这里以二维数组为例(数组中又嵌套数组)。
Go
var 数组变量名 [元素数量][元素数量]T
var variable_name [SIZE1][SIZE2]...[SIZEN] variable_type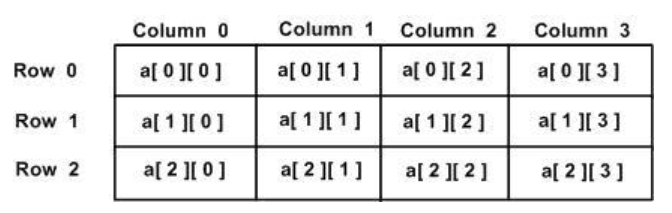
(1)二维数组的定义
Go
package main
import "fmt"
func main() {
// 定义一个二维字符串数组,表示不同区块链生态中的主要代币
// 第一维:不同的区块链网络
// 第二维:每个网络中的主要代币
blockchainTokens := [2][2]string{
{"Ethereum", "Ether (ETH)"}, // 以太坊生态,主网代币ETH
{"Polygon", "MATIC"}, // Polygon网络,原生代币MATIC
{"BNB Chain", "BNB"}, // BNB Chain,原生代币BNB
}
fmt.Println(blockchainTokens) // 打印整个二维数组
// 输出: [[Ethereum Ether (ETH)] [Polygon MATIC] [BNB Chain BNB]]
fmt.Println(blockchainTokens[2][1]) // 支持索引取值:BNB
}(2)二维数组的遍历
Go
package main
import "fmt"
func main() {
// 定义一个二维字符串数组,表示不同区块链网络及其主要代币
// 注意:数组的第一维度定义为3,表示3个区块链网络
// 第二维度定义为2,每个网络包含两个主要代币名称
blockchainTokens := [3][2]string{
{"Ethereum", "ETH"}, // 以太坊网络及其主网代币
{"Polygon", "MATIC"}, // Polygon网络及其原生代币
{"BNB Chain", "BNB"}, // BNB Chain网络及其原生代币
// 注:不能添加第四行,因为第一维度定义为3,只能有3行数据
}
// 遍历二维数组,逐层获取数据
// 第一层循环:获取每一行的数据(每个区块链网络的信息)
for networkIndex, networkTokens := range blockchainTokens {
// networkIndex: 行索引(0, 1, 2),代表区块链网络的索引
// networkTokens: 每行的值,是一个包含2个字符串的数组
// 第二层循环:获取每一列的数据(每个代币的具体信息)
for tokenIndex, tokenName := range networkTokens {
// tokenIndex: 列索引(0, 1),代表代币信息在行中的位置
// tokenName: 代币名称,如"Ethereum"或"ETH"
// 格式化输出:显示[行索引][列索引]--代币名称
fmt.Printf("[%d][%d]--%s\n", networkIndex, tokenIndex, tokenName)
}
}
}注意: 多维数组只有第一层可以使用"..."来让编译器推导数组长度。例如:
Go
package main
import "fmt"
func main() {
// 支持的写法:外层维度自动推导,内层维度固定为2
// 表示不同区块链网络的代币对(交易对)
tokenPairs := [...][2]string{
{"ETH", "USDT"}, // ETH/USDT交易对
{"BTC", "USDT"}, // BTC/USDT交易对
{"SOL", "USDT"}, // SOL/USDT交易对
{"MATIC", "USDT"}, // MATIC/USDT交易对
}
fmt.Println("支持的写法:外层自动推导,内层固定")
fmt.Printf("tokenPairs类型: %T\n", tokenPairs) // 输出: [4][2]string
fmt.Println("交易对列表:")
for i, pair := range tokenPairs {
fmt.Printf(" %d. %s/%s\n", i+1, pair[0], pair[1])
}
// ❌ 不支持的写法:内层维度使用...推导
// 下面的代码会导致编译错误
/*
invalidNetworks := [3][...]string{
{"Ethereum", "ETH"},
{"Polygon", "MATIC"},
{"BNB Chain", "BNB"},
}
*/
}5.1.7 数组练习题
练习题1:请求出数组{{12, 34},{56, 13},{8, 45},{90, 32},}的和、平均值以及最大值。
Go
package main
import "fmt"
func main() {
a := [...][2]int{
{12, 34},
{56, 13},
{8, 45},
{90, 32},
}
max := a[0][0]
var sum int
var avg float64
var cou int
// 二维数组的遍历
for index1, value := range a { // 得到每一行的数据
for index2, value1 := range value { // 得到每一列的数据
// 计算最大值的逻辑
if max < a[index1][index2] {
max = a[index1][index2]
}
fmt.Printf("[%d][%d] --> %d\n", index1, index2, value1)
sum += value1 // 得到每次遍历后的值
cou += 1 // 计数:算出求和的数值个数,用于后面求取 平均值。
fmt.Printf("第%d个数据,求和的结果为%d\n", cou, sum)
}
}
avg = float64(sum) / float64(cou)
fmt.Println("------------------------------------------------------")
fmt.Printf("总和为:%f\n", float64(sum))
fmt.Printf("平均值为:%f\n", float64(avg))
fmt.Printf("最大值为:%f\n", float64(max))
}练习题2:从数组1, 3, 5, 7, 8中找出和为 8 的两个元素的下标分别为(0,3)和(1,2)。
Go
package main
import "fmt"
func main() {
a := [...]int{1, 3, 5, 7, 8}
for i := 0; i < len(a); i++ {
for j := i + 1; j < len(a); j++ {
if a[i]+a[j] == 8 {
fmt.Println("和为8的下表为:%d--%d", i, j)
}
}
}
}5.2 切片
5.2.1 为什么要使用切片
因为数组的长度是固定的并且数组长度属于类型的一部分,所以数组有很多的局限性。例如:
Go
package main
import "fmt"
// 计算以太坊钱包的ETH总余额
// 函数接收一个长度为4的数组,代表4个不同钱包的ETH余额
func calculateTotalBalance(balances [4]float64) float64 {
total := 0.0
for _, balance := range balances {
total = total + balance // 累加所有钱包的ETH余额
}
return total
}
func main() {
// 定义4个钱包的ETH余额数组(单位:ETH)
walletBalances1 := [4]float64{1.5, 2.3, 0.8, 5.2}
fmt.Println("4个钱包的总余额:", calculateTotalBalance(walletBalances1), "ETH")
// 定义5个钱包的ETH余额数组
walletBalances2 := [5]float64{1.5, 2.3, 0.8, 5.2, 3.1}
// 下面这行会导致编译错误:
// fmt.Println(calculateTotalBalance(walletBalances2))
// 错误信息:cannot use walletBalances2 (variable of type [5]float64) as [4]float64 value in argument to calculateTotalBalance
}这个求和函数只能接受4int 类型,其他的都不支持。所以传入长度为 5 的数组的时候就会报错。
5.2.2 切片的定义
切片(Slice)是一个拥有相同类型元素的可变长度的序列 。它是基于数组类型做的一层封装 。它非常灵活,支持自动扩容。 切片是一个引用类型 ,它的内部结构包含地址 、长度 和容量。
声明切片类型的基本语法如下:
Go
var name []T其中:
(1)name:表示变量名
(2)T:表示切片中的元素类型
举个例子:
Go
package main
import "fmt"
func main() {
// 声明一个字符串切片,用于存储以太坊钱包地址
var walletAddresses []string
// 声明并初始化一个整型切片,用于存储交易金额(单位:ETH)
var transactionAmounts = []int{}
// 声明并初始化一个布尔切片,用于存储交易状态(成功/失败)
var transactionStatuses = []bool{false, true}
// 声明并初始化一个字符串切片,用于存储代币符号
// var tokenSymbols = []string{"ETH", "BTC", "SOL"}
fmt.Println("钱包地址切片:", walletAddresses) // []
fmt.Println("交易金额切片:", transactionAmounts) // []
fmt.Println("交易状态切片:", transactionStatuses) // [false true]
// nil切片和空切片的比较
fmt.Println("钱包地址切片是否为nil:", walletAddresses == nil) // true
fmt.Println("交易金额切片是否为nil:", transactionAmounts == nil) // false
fmt.Println("交易状态切片是否为nil:", transactionStatuses == nil) // false
// 切片是引用类型,不支持直接比较,只能和nil比较
// fmt.Println(transactionStatuses == tokenSymbols) // 编译错误:切片不支持比较操作
}5.2.3 关于 nil 的认识
当你声明了一个变量 , 但却还并没有赋值时 , Golang 中会自动给你的变量赋值一个默认零值。这是每种类型对应的零值。
Go
bool -> false
numbers -> 0
string-> ""
pointers -> nil
slices -> nil
maps -> nil
channels -> nil
functions -> nil
interfaces -> nil5.2.4 切片的循环遍历
切片的循环遍历和数组的循环遍历是一样的。
Go
package main
import "fmt"
func main() {
// 定义一个字符串切片,包含4个主要的区块链网络名称
var blockchainNetworks = []string{"Ethereum", "Polygon", "BNB Chain", "Solana"}
// 方法1: for循环遍历
fmt.Println("=== 方法1: for循环遍历 ===")
for i := 0; i < len(blockchainNetworks); i++ {
fmt.Printf("索引 %d: %s\n", i, blockchainNetworks[i])
}
// 方法2: 通过range关键字遍历
fmt.Println("\n=== 方法2: range关键字遍历 ===")
for index, value := range blockchainNetworks {
fmt.Printf("索引 %d: %s\n", index, value)
}
}5.2.5 基于数组定义切片
由于切片的底层就是一个数组,所以我们可以基于数组定义切片。
Go
package main
import "fmt"
func main() {
// 定义一个数组,表示以太坊连续5个区块的交易数量
blockTransactionCounts := [5]int{100, 125, 150, 175, 200}
// 基于数组创建切片,获取第2到第4个区块的交易数量(前闭后开)
recentTransactions := blockTransactionCounts[1:4] // 包括blockTransactionCounts[1],blockTransactionCounts[2],blockTransactionCounts[3]
fmt.Println("原始区块交易数量:", blockTransactionCounts) // [100 125 150 175 200]
fmt.Println("最近3个区块的交易数量:", recentTransactions) // [125 150 175]
fmt.Printf("切片类型: %T\n", recentTransactions) // type of recentTransactions:[]int
}5.2.6 切片再切片
除了基于数组得到切片,我们还可以通过切片来得到切片。
Go
package main
import "fmt"
func main() {
// 定义一个包含6个主要区块链网络的数组
blockchainNetworks := [...]string{"Ethereum", "Polygon", "BNB Chain", "Solana", "Avalanche", "Arbitrum"}
fmt.Printf("原始数组:\n")
fmt.Printf(" 值: %v\n", blockchainNetworks)
fmt.Printf(" 类型: %T\n", blockchainNetworks)
fmt.Printf(" 长度: %d\n", len(blockchainNetworks))
fmt.Printf(" 容量: %d\n\n", cap(blockchainNetworks))
// 创建第一个切片:获取索引1到3的元素(前闭后开)
layer1Networks := blockchainNetworks[1:3] // ["Polygon", "BNB Chain"]
fmt.Printf("第一层切片 (索引1:3):\n")
fmt.Printf(" 值: %v\n", layer1Networks)
fmt.Printf(" 类型: %T\n", layer1Networks)
fmt.Printf(" 长度: %d\n", len(layer1Networks))
fmt.Printf(" 容量: %d\n\n", cap(layer1Networks))
// 从第一个切片创建第二个切片:从layer1Networks的索引1开始,长度为5
// 注意:layer1Networks的底层数组仍然是blockchainNetworks
// 所以容量是从"BNB Chain"开始到底层数组末尾:blockchainNetworks[2:] -> 4个元素
// 因此可以扩展到["BNB Chain", "Solana", "Avalanche", "Arbitrum"]
layer2Networks := layer1Networks[1:5] // ["BNB Chain", "Solana", "Avalanche", "Arbitrum"]
fmt.Printf("第二层切片 (从第一层切片的索引1开始,长度为5):\n")
fmt.Printf(" 值: %v\n", layer2Networks)
fmt.Printf(" 类型: %T\n", layer2Networks)
fmt.Printf(" 长度: %d\n", len(layer2Networks))
fmt.Printf(" 容量: %d\n", cap(layer2Networks))
}**注意:**对切片进行再切片时,索引不能超过原数组的长度,否则会出现索引越界的错误。
5.2.7 关于切片的长度和容量
切片拥有自己的长度和容量,我们可以通过使用内置的 len()函数求长度,使用内置的 cap() 函数求切片的容量。
(1)切片的长度就是它所包含的元素个数。
(2)切片的容量是从它的第一个元素开始数,到其底层数组元素末尾的个数。
**注意:**理解切片容量对于性能优化很重要,因为频繁的重新分配内存(扩容)会影响程序性能。
(3)切片 s 的长度和容量可通过表达式 len(s) 和**cap(s)**来获取。
在 Go 里,切片(slice) 是一个"描述符",它内部其实包含三个字段:
Go
ptr *T // 指向底层数组的某个位置
len int // 当前可见长度:你能用下标访问的元素个数
cap int // 从 ptr 开始到底层数组末尾的元素个数(最大可扩张长度)用一句话概括:
len 是你"现在"有多少个元素可用;cap 是你"在不搬家(不重新分配底层数组)"的前提下最多还能扩展到多少个元素。
(1)可视化例子
Go
a := [10]int{0,1,2,3,4,5,6,7,8,9} // 底层数组
s := a[3:7] // 切片 [3,4,5,6]内存示意图:

-
你可以
s[0]~s[3]合法访问(共 4 个,len=4)。 -
如果执行
s = append(s, x),Go 会把x放在a[7]的位置,然后len变成 5,cap仍是 7,不会重新分配数组。 -
当
len == cap时再append,底层数组装不下,Go 就会申请一块更大新数组,把数据复制过去,**ptr 和 cap 都会变**。
(2)代码速测
Go
s := make([]int, 4, 10) // len=4, cap=10
fmt.Println(len(s), cap(s)) // 4 10
s = s[:6] // 把"视野"拉长到 6,没超 cap,合法
fmt.Println(len(s), cap(s)) // 6 10
s = s[:11] // 运行时 panic: slice bounds out of range [:11] with capacity 10(3)一句话记忆
len 是"现在有多长",cap 是"还能再长多少而不搬家"。
这可能会有面试题:切片和容量的区别。
在Go语言中,切片(Slice) 是一个引用类型,它由三个部分组成:指向底层数组的指针、当前元素数量(长度len)和底层数组的总容量(容量cap)。长度表示切片当前包含的元素个数,即你可以访问的有效数据范围(slice[0]到slice[len(slice)-1]);容量则表示切片从第一个元素开始,到底层数组末尾的最大元素数量,它反映了切片在不重新分配内存的情况下最多可以容纳多少元素。当通过append添加元素时,如果长度超过容量,Go会自动创建一个新的底层数组(通常容量翻倍),并将原数据复制过去,因此容量决定了切片增长的内存开销和性能特性。
Go
package main
import "fmt"
func main() {
// 定义一个切片,表示以太坊连续6个区块中的交易数量(单位:千笔)
blockTransactionCounts := []int{200, 250, 300, 350, 400, 450}
fmt.Println("区块交易数量:", blockTransactionCounts)
fmt.Printf("原始切片: 长度:%v, 容量:%v\n", len(blockTransactionCounts), cap(blockTransactionCounts))
// 获取前2个区块的交易数量
firstTwoBlocks := blockTransactionCounts[:2] // [200, 250] 长度 = 2 容量 = 6
fmt.Println("\n前2个区块交易数量:", firstTwoBlocks)
fmt.Printf("切片: 长度:%v, 容量:%v\n", len(firstTwoBlocks), cap(firstTwoBlocks))
// 获取第2到第4个区块的交易数量
blocksTwoToFour := blockTransactionCounts[1:4] // [250, 300, 350] 长度 = 3 容量 = 5
fmt.Println("\n第2到第4个区块交易数量:", blocksTwoToFour)
fmt.Printf("切片: 长度:%v, 容量:%v\n", len(blocksTwoToFour), cap(blocksTwoToFour))
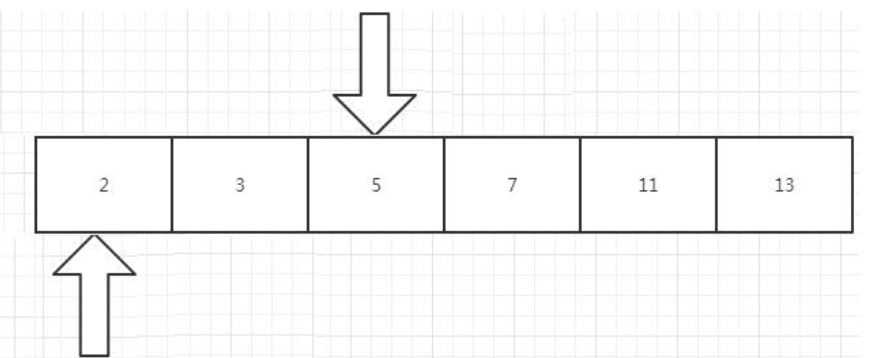
}(1)第一个输出为2,3,5,7,11,13,长度为 6,容量为 6

(2)c :=s:2后输出:2 3, 左指针 s0,右指针 s2 , 所以长度为 2,容量为 6
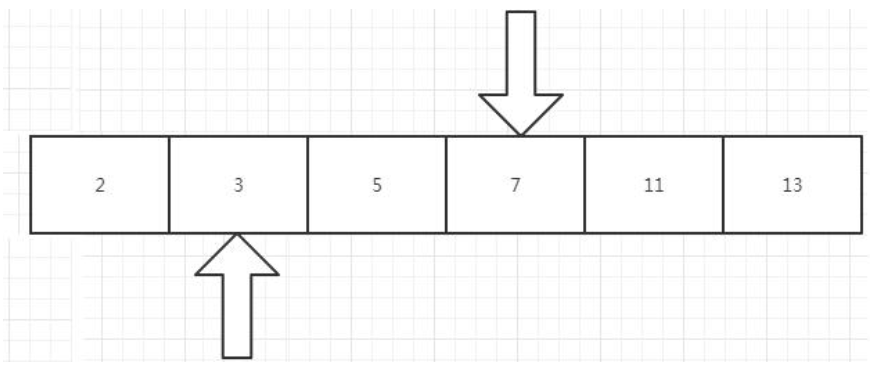
(3)d := s1:3后输出:3 5, 左指针 s1,右指针 s3 , 所以长度为 2,容量为 5.
5.2.8 切片的本质
切片的本质就是对底层数组的封装,它包含了三个信息:底层数组的指针、切片的长度(len)和切片的容量(cap)。
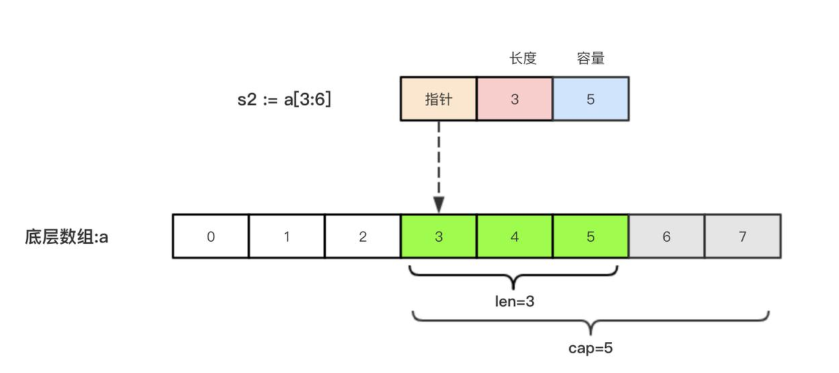
举个例子,现在有一个数组 a := 8int{0, 1, 2, 3, 4, 5, 6, 7},切片 s1 := a:5,相应示意图如下。
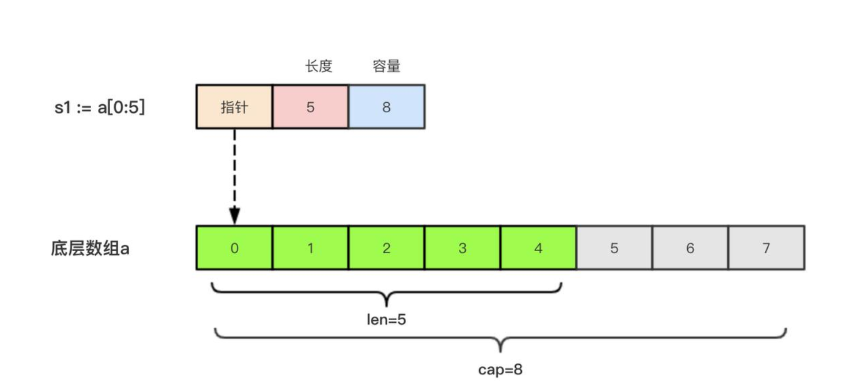
切片 s2 := a3:6,相应示意图如下:
5.2.9 使用 make()函数构造切片
我们上面都是基于数组来创建的切片,如果需要动态的创建一个切片,我们就需要使用内置的 make()函数,格式如下:
Go
make([]T, size, cap)其中:
T:切片的元素类型
size:切片中元素的数量
cap:切片的容量
举个例子:
Go
package main
import "fmt"
func main() {
// 使用make()函数创建一个切片,用于存储以太坊交易哈希
// 参数1:切片类型 []string
// 参数2:初始长度(length)为 2,表示切片当前有2个空字符串元素
// 参数3:容量(capacity)为 10,表示底层数组可以容纳最多10个元素
transactionHashes := make([]string, 2, 10)
fmt.Println("交易哈希切片:", transactionHashes) // 输出: [ ]
fmt.Println("切片长度:", len(transactionHashes)) // 输出: 2
fmt.Println("切片容量:", cap(transactionHashes)) // 输出: 10
}上面代码中 a 的内部存储空间已经分配了 10 个,但实际上只用了 2 个。 容量并不会影响当前元素的个数,所以 len(a)返回 2,cap(a)则返回该切片的容量。
问题:分配容量以后,不使用是不是占用内存?
会占用,但"占多少"要分两层看:
(1)切片描述符本身
slice变量只是一个 24 字节(64 位系统)的小标头(ptr + len + cap),不管你把cap设到多大,这 24 字节始终不变,不会多占。(2)底层数组
make([]T, len, cap)会在堆上一次性分配 cap 个元素 的数组。
只要数组还被切片引用,整个数组就处于"使用中",Go 运行时不会把它归还给 OS(Operating System:操作系统-> 主要是指对内存的使用),也不允许被 GC(Garbage Collection:垃圾回收)。
因此,cap 中未使用的那部分(cap-len)同样占用物理内存,只是你还没有索引到而已。
(3)验证代码
Gofunc main() { // 分配 0 个可见元素,但底层数组有 1 << 20 个 int s := make([]int, 0, 1<<20) // 8 MB 已到手 runtime.GC() time.Sleep(time.Second) // 用 top/taskmgr 可看到这 8 MB 仍在 _ = s // 保持引用,GC 不能回收 }把
cap改小或令s = nil后再GC,进程内存就会掉下去。(4)一句话结论 :
容量一旦分配,底层数组整块内存就归你"锁死"了,不管有没有索引到;想释放只能让切片脱离作用域或显式置 nil,等待 GC。
5.2.10 切片不能直接比较
切片之间是不能比较的 ,我们不能使用==操作符来判断两个切片是否含有全部相等元素。切片唯一合法的比较操作是和 nil 比较 。 一个 nil 值的切片并没有底层数组,一个 nil 值的切片的长度和容量都是 0。但是我们不能说一个长度和容量都是 0 的切片一定是 nil,例如:
Go
package main
import "fmt"
func main() {
// 三种方式创建空切片,用于存储不同的Web3.0数据
// 方式1: 仅声明,未初始化 - nil切片,表示"未分配内存的切片"
var transactionHashes []string // len(s1)=0; cap(s1)=0; s1==nil
// 方式2: 使用空字面量初始化 - 空切片,表示"已分配内存但没有任何元素的切片"
contractAddresses := []string{} // len(s2)=0; cap(s2)=0; s2!=nil
// 方式3: 使用make函数创建空切片 - 空切片,表示"已分配内存但没有任何元素的切片"
tokenBalances := make([]float64, 0) // len(s3)=0; cap(s3)=0; s3!=nil
// 打印各切片的长度和容量
fmt.Println("=== Web3.0 空切片比较 ===")
fmt.Printf("交易哈希切片 - 长度:%d, 容量:%d, 是否为nil:%v\n",
len(transactionHashes), cap(transactionHashes), transactionHashes == nil)
fmt.Printf("合约地址切片 - 长度:%d, 容量:%d, 是否为nil:%v\n",
len(contractAddresses), cap(contractAddresses), contractAddresses == nil)
fmt.Printf("代币余额切片 - 长度:%d, 容量:%d, 是否为nil:%v\n",
len(tokenBalances), cap(tokenBalances), tokenBalances == nil)
}注意: 要判断一个切片是否是空的,要是用len(s) == 0来判断,不应该使用 s == nil 来判断。
5.2.11 切片是引用数据类型--注意切片的赋值拷贝
下面的代码中演示了拷贝前后两个变量共享底层数组,对一个切片的修改会影响另一个切片的内容,这点需要特别注意。
Go
package main
import "fmt"
func main() {
// 创建一个切片,用于存储3个以太坊交易的Gas消耗(单位:Gwei)
originalGasCosts := make([]int64, 3) // 初始化为3个零值
// 将originalGasCosts赋值给另一个变量,两者共享同一个底层数组
modifiedGasCosts := originalGasCosts
// 通过modifiedGasCosts修改第一个交易的Gas消耗
modifiedGasCosts[0] = 100000 // 设置为100,000 Gwei
// 打印两个切片,显示它们共享底层数组
fmt.Println("原始Gas消耗:", originalGasCosts) // [100000 0 0]
fmt.Println("修改后的Gas消耗:", modifiedGasCosts) // [100000 0 0]
}5.2.12 append()方法为切片添加元素
Go 语言的内建函数**append()**可以为切片动态添加元素,每个切片会指向一个底层数组,这个数组的容量够用就添加新增元素。当底层数组不能容纳新增的元素时,切片就会自动按照一定的策略进行"扩容",此时该切片指向的底层数组就会更换。"扩容"操作往往发生在append()函数调用时,所以我们通常都需要用原变量接收 append 函数的返回值。
给切片追加元素的错误写法:
Go
package main
import "fmt"
func main() {
// 定义一个包含6个以太坊区块交易数量的切片
// 索引0-5分别对应区块1到区块6的交易数量
blockTransactionCounts := []int{100, 150, 200, 250, 300, 350}
// ❌ 错误:尝试访问索引6(超出切片范围)
// 切片长度为6,有效索引为0-5,索引6不存在
// blockTransactionCounts[6] = 400 // 这行代码会导致运行时错误
// 正确做法:先检查长度或使用append添加新元素
if len(blockTransactionCounts) > 6 {
blockTransactionCounts[6] = 400
} else {
fmt.Println("错误:索引6超出切片范围,切片长度为", len(blockTransactionCounts))
}
// 正确方式添加第7个区块的交易数量
blockTransactionCounts = append(blockTransactionCounts, 400)
fmt.Println("正确添加后:", blockTransactionCounts)
}append()方法为切片追加元素:
Go
package main
import "fmt"
func main() {
// 使用append()添加以太坊区块的交易数量,并观察切片扩容过程
var blockTransactionCounts []int // 创建一个空切片,用于存储区块交易数量
for blockNumber := 0; blockNumber < 10; blockNumber++ {
// 模拟每个区块的交易数量(实际可能是从区块链获取的)
// 这里简单使用区块号作为交易数量
transactionCount := blockNumber * 100 // 假设每个区块有递增的交易数量
// 使用append将新区块的交易数量添加到切片中
blockTransactionCounts = append(blockTransactionCounts, transactionCount)
// 打印每次添加后的切片状态
fmt.Printf("区块 %d: %v 长度:%d 容量:%d 底层数组指针:%p\n",
blockNumber, blockTransactionCounts, len(blockTransactionCounts),
cap(blockTransactionCounts), blockTransactionCounts)
}
}从上面的结果可以看出:
(1)append()函数将元素追加到切片的最后并返回该切片。
(2)切片 numSlice 的容量按照 1,2,4,8,16 这样的规则自动进行扩容,每次扩容后都是扩容前的 2 倍。
append()函数还支持一次性追加多个元素。 例如:
Go
package main
import "fmt"
func main() {
var blockchainNetworks []string // 声明一个空的区块链网络名称切片
// 追加一个元素 - 添加以太坊网络
blockchainNetworks = append(blockchainNetworks, "Ethereum")
// 追加多个元素 - 一次添加多个区块链网络
blockchainNetworks = append(blockchainNetworks, "Polygon", "BNB Chain", "Solana")
// 追加切片 - 将另一个切片的所有元素添加到当前切片
additionalNetworks := []string{"Avalanche", "Arbitrum"}
blockchainNetworks = append(blockchainNetworks, additionalNetworks...) // 注意...语法
fmt.Println(blockchainNetworks) // 输出: [Ethereum Polygon BNB Chain Solana Avalanche Arbitrum]
}通过 append() 完成两个切片的扩容。
Go
package main
import "fmt"
func main() {
s1 := []int{100, 200, 300}
s2 := []int{400, 500, 600}
s3 := append(s1, s2...)
fmt.Println(s3)
}问题:append()扩容的机制是怎么样?
append 的扩容规则一句话:"先按 2 倍扩,大到 1024 以后按 1.25 倍扩,但底层数组长度必须 ≥ 所需值,且最终向上对齐到内存分配器的 size class"。
下面把源码级别的流程拆开给你看(Go 1.20+ 仍沿用这套逻辑,位于
runtime/growslice)。(1)触发时机
Gos = append(s, x...)当
newLen = len(s)+len(x)超过cap(s)时,runtime 调用growslice重新申请一段更大的底层数组。(2)容量增长公式
Go// 伪代码,省略指针类型与溢出检查 oldCap := cap(s) newCap := oldCap doubleCap := newCap + newCap if newLen > doubleCap { // 要得太多,直接按需求给 newCap = newLen } else { // 常规倍增 const threshold = 256 if oldCap < threshold { newCap = doubleCap } else { // 0.25 倍渐进 newCap = oldCap + oldCap/4 // 计算 0.25 倍时可能进位不足,再补一次 if newCap < newLen { newCap = newLen } } }
小于 256(早期版本是 1024,后来调小)→ 2 倍。
大于等于 256 → 1.25 倍(即 5/4)。
如果算出来的 newCap 仍小于 "所需长度 newLen",就直接取 newLen。
(3)内存对齐
算完 newCap 还不算完,runtime 要把
newCap * 元素大小向上取整到内存分配器的 size class(8, 16, 32, 48, 64, 80...)。因此你最终拿到的 cap 往往 **≥ 理论计算值**,甚至看起来"多送"了几个槽位。
(4)例子实测
Gos := make([]int, 0) for i := 0; i < 2000; i++ { s = append(s, i) if i&(i-1) == 0 { // 2 的幂次打印 fmt.Printf("len=%d cap=%d\n", len(s), cap(s)) } }输出(64 位机器,Go1.20):
Golen=0 cap=0 len=1 cap=1 // 第一次 append,直接给 1 len=2 cap=2 // 2 倍 len=4 cap=4 len=8 cap=8 ... len=512 cap=512 len=1024 cap=1280 // 1.25 倍后对齐到 1280 len=2048 cap=2560可以看到 1024→1280 并不是严格 1.25 倍,而是对齐后的结果。
(5)一句话速记
"小切片 2 倍狂飙,大切片 1.25 倍慢跑,最后再对齐尺码";
只要记住最终 cap 一定 ≥ 新长度,且只会涨不会缩,想精确控制内存就用
make([]T, 0, 预估容量)一次性给足。
5.2.13 切片的扩容策略
可以通过查看$GOROOT/src/runtime/slice.go 源码,其中扩容相关代码如下:
Go
package main
import "fmt"
func main() {
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.len < 1024 {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop. for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}从上面的代码可以看出以下内容:
1、首先判断,如果新申请容量(cap)大于 2 倍的旧容量(old.cap),最终容量(newcap)就是新申请的容量(cap)。
2、否则判断,如果旧切片的长度小于 1024,则最终容量(newcap)就是旧容量(old.cap)的两倍,即(newcap=doublecap),
3、否则判断,如果旧切片长度大于等于 1024,则最终容量(newcap)从旧容量(old.cap)开始循环增加原来的 1/4,即(newcap=old.cap,for {newcap += newcap/4})直到最终容量(newcap)大于等于新申请的容量(cap),即(newcap >= cap)
4、如果最终容量(cap)计算值溢出,则最终容量(cap)就是新申请容量(cap)。
需要注意的是,切片扩容还会根据切片中元素的类型不同而做不同的处理,比如 int 和 string类型的处理方式就不一样。
5.2.14 使用 copy()函数复制切片
首先我们来看一个问题:
Go
package main
import "fmt"
func main() {
// 创建一个切片,表示5个以太坊交易的Gas消耗(单位:Gwei)
originalGasCosts := []int64{21000, 45000, 65000, 32000, 89000}
// 将originalGasCosts切片赋值给另一个变量
// 注意:这不是复制,而是两个变量共享同一个底层数组
copiedGasCosts := originalGasCosts
fmt.Println("原始Gas消耗:", originalGasCosts) // [21000 45000 65000 32000 89000]
fmt.Println("赋值后的Gas消耗:", copiedGasCosts) // [21000 45000 65000 32000 89000]
// 通过copiedGasCosts修改第一个交易的Gas消耗
copiedGasCosts[0] = 100000 // 将第一个Gas消耗改为100,000 Gwei
// 由于两个切片共享同一个底层数组,所以originalGasCosts也被修改了
fmt.Println("修改后原始Gas消耗:", originalGasCosts) // [100000 45000 65000 32000 89000]
fmt.Println("修改后赋值Gas消耗:", copiedGasCosts) // [100000 45000 65000 32000 89000]
}由于切片是引用类型 ,所以 a 和 b 其实都指向了同一块内存地址。修改 b 的同时 a 的值也会发生变化。
Go 语言内建的 copy()函数可以迅速地将一个切片的数据复制到另外一个切片空间中,copy()函数的使用格式如下:
Go
copy(destSlice, srcSlice []T)其中:
-
srcSlice: 数据来源切片
-
destSlice: 目标切片
举个例子:
Go
package main
import "fmt"
func main() {
// copy()复制切片
a := []int{1, 2, 3, 4, 5}
c := make([]int, 5, 5)
copy(c, a) // 使用copy()函数将切片a的元素复制到切片c
fmt.Println(a) // [1 2 3 4 5]
fmt.Println(c) // [1 2 3 4 5]
c[0] = 1000
fmt.Println(a) // [1 2 3 4 5]
fmt.Println(c) // [1000 2 3 4 5]
}5.2.15 从切片中删除元素
Go 语言中并没有删除切片元素的专用方法,我们可以使用切片本身的特性来删除元素。 代码如下:
Go
package main
import "fmt"
func main() {
// 假设这是一个NFT系列中的代币ID列表,代表该系列已发行的NFT代币ID
// 在Web3.0中,每个NFT都有一个唯一的代币ID
nftTokenIDs := []int{1001, 1002, 1003, 1004, 1005, 1006, 1007, 1008}
fmt.Println("原始NFT代币ID列表:", nftTokenIDs)
fmt.Println("假设我们要删除索引为2的代币ID:", nftTokenIDs[2])
// 要删除索引为2的NFT代币(第三个代币ID 1003)
// 使用append将索引2之前的元素和索引2之后的元素拼接起来
nftTokenIDs = append(nftTokenIDs[:2], nftTokenIDs[3:]...)
fmt.Println("删除后的NFT代币ID列表:", nftTokenIDs) // [1001 1002 1004 1005 1006 1007 1008]
}总结一下就是:要从切片 a 中删除索引为 index 的元素,操作方法是 a = append(a:index, aindex+1:...)
5.2.16 Golang 切片排序算法以及 sort 包
(1)选择排序:进行从小到大排序
概念: 通过比较,首先选出最小的数放在第一个位置上,然后在其余的数中选出次小数放在第二个位置上,依此类推,直到所有的数成为有序序列。
Go
package main
import "fmt"
func main() {
numArray := [...]int{2, 4, 9, 3, 30, 55, 6}
var min int
var max int
var min_cou int = 1
var max_cou int = 1
// 升序排序:从小到大
for i := 0; i < len(numArray); i++ {
for j := i + 1; j < len(numArray); j++ {
// 如果后面的元素小于前面的元素,则交换位置
if numArray[i] > numArray[j] {
min = numArray[i]
numArray[i] = numArray[j]
numArray[j] = min
}
fmt.Printf("第%d次排序结果:%v\n", min_cou, numArray)
min_cou++
}
}
fmt.Println("最后的结果:", numArray)
// 降序排序:从大到小
for i := 0; i < len(numArray); i++ {
for j := i + 1; j < len(numArray); j++ {
// 如果后面的元素小于前面的元素,则交换位置
if numArray[i] < numArray[j] {
max = numArray[i]
numArray[i] = numArray[j]
numArray[j] = max
}
fmt.Printf("第%d次排序结果:%v\n", max_cou, numArray)
max_cou++
}
}
fmt.Println("最后的结果:", numArray)
}(2)冒泡排序
概念:从头到尾,比较相邻的两个元素的大小,如果符合交换条件,交换两个元素的位置。
特点:每一轮比较中,都会选出一个最大的数,放在正确的位置。
Go
package main
import "fmt"
func main() {
// 冒泡排序
numArray := [...]int{2, 4, 9, 3, 30, 55, 6}
var max int
var cou int = 1
// 升序排序:从小到大
for i := 0; i < len(numArray); i++ {
for j := i + 1; j < len(numArray); j++ {
// 如果后面的元素小于前面的元素,则交换位置
if numArray[i] > numArray[j] {
max = numArray[i]
numArray[i] = numArray[j]
numArray[j] = max
}
fmt.Printf("第%d次排序结果:%v\n", cou, numArray)
cou++
}
}
fmt.Println("最后的结果:", numArray)
}(3)Golang 内置 Sort 包对切片进行排序
1)sort 包的文档:
2)sort 升序排序
对于 int 、 float64 和 string 数组或是切片的排序,go 分别提供了 sort.Ints() 、
sort.Float64s() 和 sort.Strings() 函数, 默认都是从小到大排序(升序)。
Go
package main
import (
"fmt"
"sort"
)
func main() {
// 升序
intList := []int{2, 4, 3, 5, 7, 6, 9, 8, 1, 0}
float8List := []float64{4.2, 5.9, 12.4, 10.2, 50.7, 99.9, 31.4, 27.81828, 3.14}
stringList := []string{"a", "c", "b", "z", "x", "w", "y", "d", "f", "i"}
sort.Ints(intList)
sort.Float64s(float8List)
sort.Strings(stringList)
fmt.Println(intList)
fmt.Println(float8List)
fmt.Println(stringList)
}3)sort 降序排序
Golang的sort包可以使用sort.Reverse(slice) 来调换 slice.Interface.Less ,也就是比较函数,所以,int、float64 和 string的逆序排序函数可以这么写。
Go
package main
import (
"fmt"
"sort"
)
func main() {
// 降序
intList1 := []int{2, 4, 3, 5, 7, 6, 9, 8, 1, 0}
float8List1 := []float64{4.2, 5.9, 12.4, 10.2, 50.7, 99.9, 31.4, 27.81828, 3.14}
stringList1 := []string{"a", "c", "b", "z", "x", "w", "y", "d", "f", "i"}
sort.Sort(sort.Reverse(sort.IntSlice(intList1)))
sort.Sort(sort.Reverse(sort.Float64Slice(float8List1)))
sort.Sort(sort.Reverse(sort.StringSlice(stringList1)))
fmt.Println(intList1)
fmt.Println(float8List1)
fmt.Println(stringList1)
}5.2.17 练习题
练习1:请写出下面代码的输出结果。
Go
package main
import "fmt"
func main() {
var a = make([]string, 5, 10) // 长度是5 ,容量是10的切片.
fmt.Println(a) // [ ]
for i := 0; i < 12; i++ {
a = append(a, fmt.Sprintf("%v", i)) // [ 0 1 2 3 4 5 6 7 8 9 10 11]
}
fmt.Println(a)
// fmt.Printf("a的长度是:%d --> a的容量为:%d", len(a), cap(a))
}练习2:请使用内置的 sort 包对数组 var a = ...int{3, 7, 8, 9, 1}进行排序()。
Go
package main
import (
"fmt"
"sort"
)
func main() {
a := [...]int{3, 7, 8, 9, 1} // 固定数组
fmt.Println(a)
sort.Ints(a[:]) // 切片化后原地排序(升序排序)
fmt.Println(a)
sort.Sort(sort.Reverse(sort.IntSlice(a[:]))) // 原地降序
fmt.Println(a)
}sort 是 Go 标准库里最常用也最精简的排序包,只暴露了几个函数 + 三个接口,却覆盖了 99 % 的排序场景。
核心思想:只要你的类型实现了 sort.Interface 的三个方法,就能就地排序。
(1)核心接口
Go
package sort
type Interface interface {
Len() int // 元素个数
Less(i, j int) bool // 决定升序/降序:返回 true 表示 i 应排在 j 前面
Swap(i, j int) // 交换两个元素
}sort.Sort(data Interface) 会 原地 对 data 做 不稳定排序(不保证相等元素原有相对次序)。
sort.Stable(data Interface) 则做 稳定排序(相等元素次序保持)。
(2)内置便捷函数
|----|----------------------------------------------------------------|-------------------------------|------------|-------|--------------------------------------|
| 序号 | 函数签名 | 功能 | 时间复杂度 | 稳定性 | 备注 / 易踩点 |
| 1 | sort.Ints(a []int) | 把 []int **原地**按升序排好 | O(n log n) | ❌ 不稳定 | 等价于 sort.Sort(sort.IntSlice(a)) |
| 2 | sort.Float64s(a []float64) | 把 []float64 **原地**按升序排好 | O(n log n) | ❌ 不稳定 | NaN 值会被扔到最**后**;+0 排在 −0 前面 |
| 3 | sort.Strings(a []string) | 按**字典序(UTF-8 字节序)**原地排序 | O(n log n) | ❌ 不稳定 | 大写 < 小写('A' < 'a');中文按字节码排,非拼音序 |
| 4 | sort.Slice(slice any, less func(i, j int) bool) | 无需写结构体,传匿名函数就能排 | O(n log n) | ❌ 不稳定 | 函数内如果捕获外部变量,注意并发安全;any=interface{} |
| 5 | sort.SliceStable(slice any, less func(i, j int) bool) | 同上,但稳定 | O(n log n) | ✅ 稳定 | 内部用归并排序,额外内存 O(n) |
| 6 | sort.SliceIsSorted(slice any, less func(i, j int) bool) bool | 判断切片已排好序 | O(n) | --- | 只扫一遍,满足 !less(i+1,i) 即返回 true |
(3)最简例子
Go
import "sort"
// 1) 基本类型
nums := []int{3, 1, 4}
sort.Ints(nums) // [1 3 4]
// 2) 结构体按字段排
type Person struct{ Name string; Age int }
people := []Person{{"Bob", 30}, {"Alice", 25}}
sort.Slice(people, func(i, j int) bool {
return people[i].Age < people[j].Age // 按年龄升序
})(4)高级玩法:自定义排序器
Go
import "sort"
// 1) 基本类型
nums := []int{3, 1, 4}
sort.Ints(nums) // [1 3 4]
// 2) 结构体按字段排
type Person struct{ Name string; Age int }
people := []Person{{"Bob", 30}, {"Alice", 25}}
sort.Slice(people, func(i, j int) bool {
return people[i].Age < people[j].Age // 按年龄升序
})(5)搜索函数
sort.Search 家族要求 升序已排好,返回 第一个满足条件的下标。
Go
// 在有序 []int 中找 ≥ 60 的最小下标
idx := sort.Search(len(nums), func(i int) bool {
return nums[i] >= 60
})
if idx < len(nums) && nums[idx] == 60 {
fmt.Println("找到 60,下标", idx)
} else {
fmt.Println("60 不存在,应插入位置", idx)
}还有 sort.SearchInts / SearchFloat64s / SearchStrings 直接返回插入点。
(6)性能 & 实现细节
- 内部用 快速排序 + 堆排序 的 introsort 变种:
先快排,递归深度超过 2*lg(len) 就转堆排,保证最坏 O(n log n)。
-
稳定排序用的是 **归并排序**。
-
所有接口调用都是 **原地**(in-place),额外空间 O(1)( introspect 时少量栈 + 堆排 O(1))。
(7)一句话总结
"写三个方法就能排任意类型;不想写结构体就用 sort.Slice 传匿名函数;排完直接搜用 sort.Search。"
记住 Interface 和 Slice 这两个入口,90 % 的排序需求就全搞定了。
5.3 map
5.3.1 map 的介绍
map 是一种无序的基于 key-value 的数据结构,Go 语言中的 map 是引用类型,必须初始化才能使用。
Go 语言中 map 的定义语法如下:
Go
map[KeyType] ValueType其中:
(1)KeyType:表示键的类型。
(2)ValueType:表示键对应的值的类型。
map 类型的变量默认初始值为 nil,需要使用 make()函数来分配内存。语法为:
make: 用于 slice,map,和 channel 的初始化。
Go
make(map[KeyType]ValueType, [cap])其中 cap 表示 map 的容量,该参数虽然不是必须的。
注意:获取 map 的容量不能使用 cap, cap 返回的是数组切片分配的空间大小, 根本不能用于map。要获取 map 的容量,可以用 len 函数。
5.3.2 map 基本使用
map 中的数据都是**成对(键值对)**出现的,map 的基本使用示例代码如下:
Go
package main
import (
"fmt"
)
func main() {
// 创建一个区块链账户余额映射表
// 使用 make 初始化,设置初始容量为 8 个账户
blockchainBalances := make(map[string]int, 8)
// 向区块链账户映射表中添加数据
blockchainBalances["0x742d35Cc6634C0532925a3b844Bc9e"] = 90 // 张三的以太坊地址
blockchainBalances["0x13f06f602a4b3b2c7c9c3c3c3c3c3c3c3c3c3c3c3"] = 100 // 小明的以太坊地址
// 打印整个区块链账户余额表
fmt.Println("区块链账户余额表:", blockchainBalances)
// 查询特定区块链地址的余额
fmt.Println("小明地址的余额:", blockchainBalances["0x13f06f602a4b3b2c7c9c3c3c3c3c3c3c3c3c3c3c3"])
// 显示映射表的数据类型
fmt.Printf("数据类型: %T\n", blockchainBalances)
}map 也支持在声明的时候填充元素,例如:
Go
package main
import (
"fmt"
)
func main() {
// 创建一个区块链账户信息映射表
// 键:以太坊地址,值:账户元数据(这里用JSON字符串表示)
blockchainAccountInfo := map[string]string{
"0xC8b3F7a4B0e1D29b9c1D5a5b8e6F8c2A3b4C5d6E7": `{"ens": "itcamp.eth", "role": "developer"}`, // 小王子的账户信息
"0xF2a1b8C3d4E5f6A7b8C9D0E1F2A3b4C5d6E7F8a9B": `{"ens": "miner001.eth", "role": "validator"}`, // 矿工账户信息
}
// 打印整个区块链账户信息表
fmt.Println(blockchainAccountInfo)
}5.3.3 判断某个键是否存在
Go 语言中有个判断 map 中键是否存在的特殊写法,格式如下:
Go
value, ok := map 对象[key]举个例子:
Go
package main
import (
"fmt"
)
func main() {
// 创建一个区块链钱包余额映射表
walletBalances := make(map[string]int)
walletBalances["Alice_Wallet"] = 90 // Alice的钱包余额
walletBalances["Bob_Wallet"] = 100 // Bob的钱包余额
// 查询特定钱包的余额,ok表示钱包是否存在
balance, ok := walletBalances["Alice_Wallet"] // ok是一个布尔类型的数据
// 根据钱包是否存在进行相应处理
if ok {
fmt.Println("Alice钱包余额:", balance)
} else {
fmt.Println("该钱包地址不存在")
}
}5.3.4 map 的遍历
Go 语言中使用 for range 遍历 map。
Go
package main
import (
"fmt"
)
func main() {
// 创建一个区块链交易记录映射表
// 键:交易ID,值:交易金额
transactionRecords := make(map[string]int)
transactionRecords["tx_001"] = 90 // 交易ID为tx_001的交易金额
transactionRecords["tx_002"] = 100 // 交易ID为tx_002的交易金额
transactionRecords["tx_003"] = 60 // 交易ID为tx_003的交易金额
// 遍历区块链交易记录,输出所有交易的ID和金额
for transactionId, amount := range transactionRecords {
fmt.Printf("交易ID: %s, 金额: %d\n", transactionId, amount)
}
}我们只想遍历 key 的时候,可以按下面的写法:
Go
package main
import (
"fmt"
)
func main() {
// 创建一个区块链节点列表映射表
// 键:节点ID,值:节点信誉度
nodeList := make(map[string]int)
nodeList["Node_A"] = 90 // 节点A的信誉度
nodeList["Node_B"] = 100 // 节点B的信誉度
nodeList["Node_C"] = 60 // 节点C的信誉度
// 遍历区块链网络中的所有节点ID
for nodeId := range nodeList {
fmt.Printf("节点ID: %s\n", nodeId)
}
}**注意:**遍历 map 时的元素顺序与添加键值对的顺序无关。
5.3.5 使用 delete()函数删除键值对
使用 delete()内建函数从 map 中删除一组键值对,delete()函数的格式如下:
delete(map 对象, key)
其中:
• map 对象:表示要删除键值对的 map 对象
• key:表示要删除的键值对的键
示例代码如下:
Go
package main
import (
"fmt"
)
func main() {
// 创建一个智能合约存储映射表
// 键:存储键(key),值:存储值(value)
contractStorage := make(map[string]int)
contractStorage["user_balance_Alice"] = 90 // Alice在合约中的余额
contractStorage["user_balance_Bob"] = 100 // Bob在合约中的余额
contractStorage["contract_total_supply"] = 60 // 合约代币总供应量
fmt.Println("智能合约存储(删除前):", contractStorage)
// 从智能合约存储中删除Bob的余额记录
// 这模拟了合约中某个键值对的删除操作(例如,用户提取全部余额)
delete(contractStorage, "user_balance_Bob")
fmt.Println("智能合约存储(删除后):", contractStorage)
}【案例】按照指定顺序遍历 map
Go
package main
import (
"fmt"
"math/rand"
"sort"
"time"
)
func main() {
// 初始化随机数种子,确保每次运行生成不同的随机数
// 在区块链应用中,随机性很重要,比如用于分配奖励、选择验证者等场景
/*
(1)Go 1.20+:程序启动时自动随机播种,不需要任何代码
(2)Go 1.19 及之前:仍然需要 rand.Seed 来获得真正的随机性
(3)向后兼容:即使保留 rand.Seed,代码仍然可以运行,只是会有警告
*/
rand.Seed(time.Now().UnixNano())
// 创建一个去中心化应用(DApp)用户活跃度映射表
// 使用 make 函数创建 map,初始容量设置为 200,优化内存分配
// 在Web3.0中,这种结构常用于记录用户地址与对应活动积分的映射关系
var dappUserActivity = make(map[string]int, 200)
// 生成模拟的DApp用户活跃度数据
// 循环生成100个模拟用户,模拟真实DApp中的用户活跃度分布
for i := 0; i < 100; i++ {
// 生成模拟钱包地址:格式为"0xWallet" + 三位数字编号
// 真实区块链地址通常是42位十六进制字符串(如以太坊地址)
walletAddress := fmt.Sprintf("0xWallet%03d", i)
// 生成0~99的随机活跃度积分,模拟不同用户的参与程度
// 在真实DApp中,这可能基于交易次数、持有代币时间、参与治理等计算
activityScore := rand.Intn(100)
// 将钱包地址与活跃度积分存入映射表
dappUserActivity[walletAddress] = activityScore
}
// 打印整个DApp用户活跃度数据映射表
// 注意:map的打印顺序是随机的,每次运行可能不同
fmt.Println("DApp用户活跃度数据(原始顺序):", dappUserActivity)
// 准备阶段:创建一个切片来存储所有钱包地址
// 初始容量设置为200,与map的初始容量一致,避免多次内存分配
var walletAddresses = make([]string, 0, 200)
// 遍历map,提取所有钱包地址到切片中
// 在区块链数据分析中,经常需要提取地址列表进行进一步处理
for walletAddress := range dappUserActivity {
walletAddresses = append(walletAddresses, walletAddress)
}
// 打印提取出的所有钱包地址(未排序)
fmt.Println("\n所有钱包地址(提取顺序随机):", walletAddresses)
// 对钱包地址切片进行排序(按字母顺序)
// 在区块链应用中,按地址排序常用于生成一致的报告或进行有序处理
sort.Strings(walletAddresses)
// 打印排序后的钱包地址
fmt.Println("\n排序后的钱包地址(字母顺序):", walletAddresses)
// 按照排序后的钱包地址输出用户活跃度报告
// 这种有序输出在区块链浏览器、治理报告等场景中很常见
fmt.Println("\n=== 按地址排序的用户活跃度报告 ===")
for _, walletAddress := range walletAddresses {
// 通过排序后的地址从map中查找对应的活跃度积分
// 这种方式可以确保输出结果的一致性
fmt.Printf("地址: %s, 活跃度积分: %d\n", walletAddress, dappUserActivity[walletAddress])
}
}5.3.6 元素为 map 类型的切片
下面的代码演示了切片中的元素为 map 类型时的操作:
Go
package main
import (
"fmt"
)
func main() {
// 创建一个包含智能合约存储映射表的切片
// 切片的长度为3,每个元素都是一个 map[string]string 类型的智能合约存储
// 这模拟了多链环境或多合约场景中的存储结构
var blockchainStorageSlice = make([]map[string]string, 3)
// 遍历切片并打印初始状态
// 初始化时每个map都是nil,表示合约存储尚未初始化
fmt.Println("初始化前的状态:")
for index, value := range blockchainStorageSlice {
fmt.Printf("链/合约索引:%d 存储状态:%v\n", index, value)
}
fmt.Println("\n========== 初始化智能合约存储 ==========")
// 初始化切片中的第一个智能合约存储(索引0)
// 这模拟了在第一条链或第一个合约中创建存储空间
blockchainStorageSlice[0] = make(map[string]string, 10)
// 向第一个智能合约存储中添加数据
// 这些键值对模拟了合约中的状态变量
blockchainStorageSlice[0]["contract_name"] = "ERC20_Token" // 合约名称
blockchainStorageSlice[0]["contract_symbol"] = "WEB3" // 代币符号
blockchainStorageSlice[0]["contract_owner"] = "0xOwnerWallet" // 合约所有者地址
blockchainStorageSlice[0]["total_supply"] = "1000000" // 代币总供应量
blockchainStorageSlice[0]["decimals"] = "18" // 代币小数位数
// 遍历切片并打印所有智能合约存储的状态
fmt.Println("\n初始化后的状态:")
for index, value := range blockchainStorageSlice {
fmt.Printf("链/合约索引:%d 存储内容:%v\n", index, value)
}
// 访问特定智能合约存储中的数据
fmt.Println("\n========== 查询智能合约存储数据 ==========")
if blockchainStorageSlice[0] != nil {
fmt.Printf("合约名称: %s\n", blockchainStorageSlice[0]["contract_name"])
fmt.Printf("代币符号: %s\n", blockchainStorageSlice[0]["contract_symbol"])
fmt.Printf("合约所有者: %s\n", blockchainStorageSlice[0]["contract_owner"])
fmt.Printf("总供应量: %s\n", blockchainStorageSlice[0]["total_supply"])
fmt.Printf("小数位数: %s\n", blockchainStorageSlice[0]["decimals"])
}
}5.3.7 值为切片类型的 map
下面的代码演示了 map 中值为切片类型的操作:
Go
package main
import "fmt"
func main() {
// 创建一个区块链网络地址映射表
// 键(string):区块链网络名称,例如 "以太坊主网"、"币安智能链" 等
// 值([]string):该网络上的节点地址切片,每个元素是一个节点的地址字符串
// 使用 make 初始化,设置初始容量为 3,表示预计会存储约3个不同的区块链网络信息
var blockchainNodes = make(map[string][]string, 3)
// 打印初始状态,此时映射表为空
fmt.Println("初始状态:", blockchainNodes)
// 提示信息,表示即将进行网络存在性检查和初始化操作
fmt.Println("初始化检查")
// 定义一个区块链网络名称,这里以 "以太坊主网" 为例
network := "以太坊主网"
// 检查区块链网络是否存在,并获取其对应的节点列表
// nodeList: 如果 network 存在,则为其节点列表;否则为 nil(或零值)
// exists: 布尔值,表示 network 是否存在于映射表中
nodeList, exists := blockchainNodes[network]
// 打印当前获取的节点列表以及网络是否存在的信息
fmt.Println("节点列表:", nodeList, "网络是否存在:", exists)
// 如果区块链网络不存在(即 exists 为 false),则初始化一个空的节点列表
if !exists {
// 使用 make 创建一个字符串切片,初始长度为 0,容量为 2
// 容量为2是为了优化内存分配,因为我们即将添加两个节点地址
nodeList = make([]string, 0, 2)
}
// 打印初始化后的节点列表内容(此时还未添加节点地址,所以为空)
fmt.Println("节点列表内容:", nodeList)
// 向节点列表中添加两个节点地址
// 这里使用示例地址,实际应用中可能是真实的节点地址(如IP:端口或公钥标识)
nodeList = append(nodeList, "0xNodeAddress1", "0xNodeAddress2")
// 将更新后的节点列表赋值回映射表中的对应网络
// 如果 network 已存在,则更新其节点列表;如果不存在,则创建新的键值对
blockchainNodes[network] = nodeList
// 打印最终状态,此时映射表中包含了一个网络及其节点列表
fmt.Println("最终状态:", blockchainNodes)
}5.3.8 练习题
写一个程序,统计一个字符串中每个单词出现的次数。比如:"how do you do"中 how=1 do=2 you=1。
Go
package main
import (
"fmt"
"strings"
)
func main() {
var wordMap = make(map[string]int) // 创建一个map变量
var str string = "how do you do"
var arrSlice = strings.Split(str, " ") // 将字符串切割
fmt.Println(arrSlice)
for _, word := range arrSlice {
wordMap[word]++ // 统计数量
}
fmt.Println(wordMap)
}5.4 指针
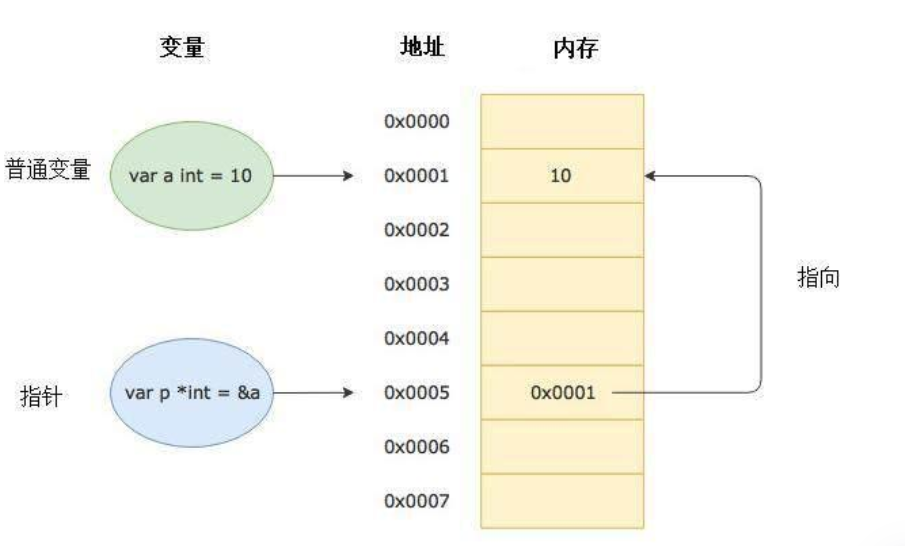
通过前面的教程我们知道变量是用来存储数据的,变量的本质是给存储数据的内存地址起了一个好记的别名。比如我们定义了一个变量 a := 10 ,这个时候可以直接通过 a 这个变量来读取内存中保存的 10 这个值。在计算机底层 a 这个变量其实对应了一个内存地址。
指针 也是一个变量,但它是一种特殊的变量,它存储的数据不是一个普通的值,而是另一个变量的内存地址。
要搞明白 Go 语言中的指针需要先知道 3 个概念:
(1)指针地址 :指针在内存中的位置,通常用十六进制数表示,可通过 **& 运算符**获取变量的地址。
(2)指针类型 :指针所指向的数据类型,例如 *int 表示指向整型数据的指针类型。
(3)指针取值 :通过指针获取其指向内存地址中存储的实际数据,使用 *** 运算符**对指针解引用。
Go 语言中的指针操作非常简单,我们只需要记住两个符号:&(取地址)和 *(根据地址取值)。
5.4.1 指针存在的意义
指针的存在意义可以概括为一句话:"让程序在运行时可以按地址直接读写内存,从而拥有灵活、高效、可控的间接操作能力"。
具体展开,有四大核心价值:
1、共享与修改------不用拷贝就能"多处同时改同一份数据"
Go
package main
import "fmt"
func addTokenBalance(x *int) {
*x++ // 等同于:*x = *x + 1,这里表示增加1个代币单位的余额
}
func main() {
// 模拟一个以太坊钱包的ETH余额(单位:ETH)
ethBalance := 10
fmt.Printf("原始ETH余额: %d ETH\n", ethBalance)
addTokenBalance(ðBalance) // 传入 ethBalance 的地址(指向钱包余额的指针)
// 执行过程:
// 1. x = ðBalance (x 指向 ethBalance 的内存地址)
// 2. *x = 10 (获取 x 指向的当前余额值)
// 3. *x + 1 = 11 (余额增加1个ETH)
// 4. 将 11 写回 x 指向的内存地址
// 结果:ethBalance 的值从 10 ETH 变为 11 ETH
fmt.Printf("增加后的ETH余额: %d ETH\n", ethBalance) // 输出:11
fmt.Println("\n=== Web3业务场景模拟 ===")
// 实际Web3业务中,余额通常以大整数形式存储(单位:wei)
// 1 ETH = 10^18 wei
var balanceInWei int = 10000000000000000000 // 10 ETH in wei
fmt.Printf("原始余额(wei): %d wei\n", balanceInWei)
fmt.Printf("原始余额(ETH): %.2f ETH\n", float64(balanceInWei)/1e18)
// 增加1 ETH(增加10^18 wei)
var amountToAdd int = 1000000000000000000 // 1 ETH in wei
balanceInWei += amountToAdd
fmt.Printf("增加1 ETH后的余额(wei): %d wei\n", balanceInWei)
fmt.Printf("增加1 ETH后的余额(ETH): %.2f ETH\n", float64(balanceInWei)/1e18)
// 使用函数处理交易(模拟实际转账)
processTransfer(&balanceInWei, 2000000000000000000) // 增加2 ETH
}
// 处理代币转账交易
func processTransfer(balance *int, amount int) {
fmt.Printf("\n=== 执行代币转账 ===")
fmt.Printf("\n当前余额(调用前): %.2f ETH\n", float64(*balance)/1e18)
fmt.Printf("转账金额: %.2f ETH\n", float64(amount)/1e18)
// 通过指针修改钱包余额
*balance += amount
fmt.Printf("转账后余额: %.2f ETH\n", float64(*balance)/1e18)
fmt.Println("交易确认成功!")
// 验证交易(模拟区块确认)
verifyTransaction(balance, amount)
}
// 验证交易(模拟区块链确认过程)
func verifyTransaction(finalBalance *int, transferredAmount int) {
fmt.Println("\n=== 交易验证 ===")
fmt.Println("正在等待区块确认...")
fmt.Println("✓ 交易已打包进区块")
fmt.Println("✓ 区块已上链")
fmt.Printf("✓ 最终余额已确认: %.2f ETH\n", float64(*finalBalance)/1e18)
fmt.Printf("✓ 已成功接收: %.2f ETH\n", float64(transferredAmount)/1e18)
}没有指针,就只能传值拷贝;大结构体、高频率调用会浪费 CPU 与内存。
2、动态大小------编译期大小未知的数据得以存在
数组长度在 Go 里固定,而切片底层必须搭配指针(指向底层数组)才能"运行时多大都行"。
同理,链节点、树节点、哈希桶、channel 等所有"引用类型"都靠指针把离散内存串起来。
3、可选与延迟------"有没有"和"何时有"可以分开决定
指针允许"先占坑,后填值",实现缺省、懒加载、对象池:
Go
var img *Image // 现在没有
if need {
img = loadFromDisk("bg.png") // 用时再真正申请
}空指针(nil)天然表达"暂无",避免用特殊魔数值。
4、底层抽象---操作系统、硬件、GC、运行时都依赖指针
-
栈帧局部变量地址、函数返回地址、寄存器值,本质都是指针。
-
垃圾回收靠扫描"根指针"标记存活对象。
-
cgo、syscall、手动内存对齐等场景必须拿到真实地址才能工作。
一句话总结:
指针是"地址+类型"的抽象,它让同一段内存可以被多人共享、动态生长、延迟创建,并且与硬件寻址模型保持一致------这是值拷贝无法替代的底层能力,也是 Go 既能高效又能自动管理内存的根基。
5.4.2 指针地址和指针类型
每个变量在运行时都拥有一个地址,这个地址代表变量在内存 中的位置。Go 语言中使用**&字符** 放在变量前面对变量进行取地址操作。 Go 语言中的值类型(int、float、bool、string、array、struct)都有对应的指针类型,如:*int、*int64、*string 等。
取变量指针的语法如下:
Go
ptr := &v // 比如 v 的类型为 T则其中:
**• v :**代表被取地址的变量,类型为 T。
• ptr : 用于接收地址的变量,ptr的类型就为*T,称做 T 的指针类型。*代表指针。
举个例子:
Go
package main
import "fmt"
func main() {
// 声明并初始化一个以太坊钱包的ETH余额,单位为ETH
var walletBalance int = 10 // 假设钱包有10个ETH
// 声明一个指向 int 类型的指针变量,指向钱包余额的地址
// 在Web3中,这可以表示一个钱包余额的访问器或引用
var balancePointer *int = &walletBalance // 这是一个指向钱包余额的指针
// 打印钱包余额的值和该变量在内存中的地址
// 在区块链中,地址很重要,但这里是内存地址,不是区块链地址
fmt.Printf("钱包余额:%d ETH 内存地址:%p\n", walletBalance, &walletBalance)
// 打印指针变量的值(即钱包余额的内存地址)和指针的类型
// 在Web3中,指针可以用来高效访问和修改区块链数据
fmt.Printf("余额指针的值(地址):%p 指针类型:%T\n", balancePointer, balancePointer)
// 打印指针变量本身的地址
// 指针本身也是一个变量,也有自己的内存地址
// 这可以类比为:在Web3中,你有一个指向余额的引用,这个引用本身也有一个位置
fmt.Printf("余额指针自身的地址:%p\n", &balancePointer) // 指针的地址
// Web3业务场景扩展
fmt.Println("\n=== Web3业务场景 ===")
// 通过指针修改钱包余额(模拟交易)
*balancePointer = 15 // 通过指针直接修改钱包余额
fmt.Printf("交易后钱包余额: %d ETH\n", walletBalance)
// 模拟Gas费用扣除
gasFee := 2 // 2 ETH的Gas费
*balancePointer -= gasFee
fmt.Printf("支付Gas费用后余额: %d ETH\n", walletBalance)
// 创建一个函数,通过指针处理交易
processTransaction(balancePointer, 3) // 再增加3 ETH
fmt.Printf("处理交易后余额: %d ETH\n", walletBalance)
}
// 处理交易函数,通过指针修改钱包余额
func processTransaction(balancePtr *int, amount int) {
fmt.Printf("\n处理交易中...\n")
fmt.Printf("交易金额: %d ETH\n", amount)
// 通过指针修改原始值
*balancePtr += amount
fmt.Printf("交易处理完成\n")
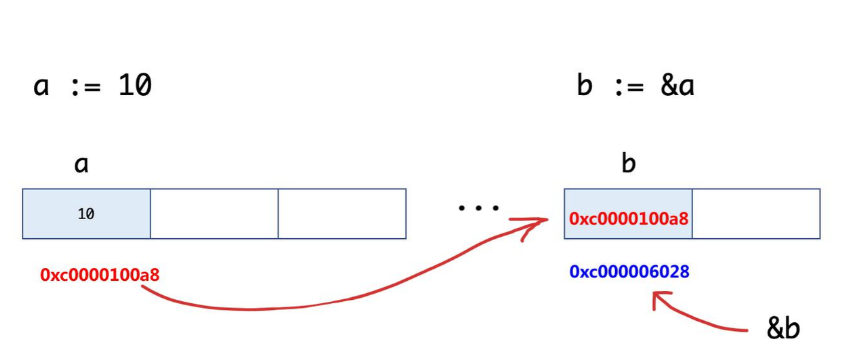
}我们来看一下 b := &a 的图示:
5.4.3 指针取值
在对普通变量使用&操作符取地址后会获得这个变量的指针,然后可以对指针使用*操作,也就是指针取值,代码如下。
Go
package main
import "fmt"
func main() {
// 创建一个以太坊钱包余额变量,就像创建一个区块链上的账户,里面有 10 个ETH
var walletBalance = 10 // 单位:ETH
// 创建指针变量 balanceRef,使用 & 操作符获取 walletBalance 的地址
// 这就像拿到了钱包余额的访问权限,balanceRef 现在是一个指向余额的引用(指针)
var balanceRef = &walletBalance // 这是一个指向钱包余额的指针
// 打印钱包余额的值和它在内存中的地址
// %d 显示余额的数值,%p 显示余额变量在内存中的地址(十六进制格式)
fmt.Printf("钱包余额:%d ETH 内存地址:%p\n", walletBalance, &walletBalance)
// 打印余额引用 balanceRef 的信息
// %p 显示引用存储的地址(即 walletBalance 的地址),%T 显示引用的类型(*int,即指向整数的引用类型)
fmt.Printf("余额引用:%p 引用类型:%T\n", balanceRef, balanceRef)
// 打印引用变量 balanceRef 本身的存放位置
// 就像问"这个余额引用本身存储在内存的哪个位置?"
// 注意:引用变量自己也有内存地址
fmt.Printf("引用自身的地址:%p\n", &balanceRef) // 引用变量自身的地址
// Web3业务场景扩展
fmt.Println("\n=== Web3实际业务操作 ===")
// 通过引用修改钱包余额(模拟接收到一笔转账)
*balanceRef = 15 // 通过引用直接修改钱包余额
fmt.Printf("接收到转账后的钱包余额: %d ETH\n", walletBalance)
// 再次模拟交易:支付Gas费用
gasFee := 2 // 2 ETH的Gas费
*balanceRef -= gasFee
fmt.Printf("支付Gas费用后的余额: %d ETH\n", walletBalance)
// 创建一个函数来安全地处理交易
processWeb3Transaction(balanceRef, 5) // 再增加5 ETH
fmt.Printf("完成交易后的余额: %d ETH\n", walletBalance)
// 演示多个引用指向同一个钱包(多个应用访问同一个钱包)
fmt.Println("\n=== 多应用访问同一钱包 ===")
var anotherRef = &walletBalance // 创建另一个引用指向同一个钱包
fmt.Printf("另一个引用存储的地址: %p\n", anotherRef)
fmt.Printf("通过另一个引用访问的余额: %d ETH\n", *anotherRef)
// 通过任意一个引用修改,都会影响原值
*anotherRef = 25
fmt.Printf("通过第二个引用修改后,钱包余额: %d ETH\n", walletBalance)
fmt.Printf("通过第一个引用访问的余额: %d ETH\n", *balanceRef)
}
// 安全处理Web3交易函数
func processWeb3Transaction(balancePtr *int, amount int) {
fmt.Printf("\n处理Web3交易中...\n")
fmt.Printf("交易金额: %d ETH\n", amount)
// 在实际Web3中,这里会有更多的验证逻辑
// 例如:验证签名、检查Gas费用、确认交易哈希等
if amount > 0 {
// 通过引用直接修改原始余额
*balancePtr += amount
fmt.Printf("交易成功!哈希: 0x1234567890abcdef\n")
} else {
fmt.Println("交易失败:金额必须大于0")
}
fmt.Printf("交易处理完成\n")
}**总结:**取地址操作符&和取值操作符*是一对互补操作符,&取出地址,*根据地址取出地址指向的值。
变量、指针地址、指针变量、取地址、取值的相互关系和特性如下:
• 对变量进行**取地址(&)**操作,可以获得这个变量的指针变量。
• 指针变量的值 是一个内存地址,我们通常称这个值为"指针地址 "。需注意:指针变量本身也是一个变量,它也有自己的内存地址(指针变量的地址 vs 指针变量存储的地址)。
• 对指针变量进行取值(*)操作,可以获得指针变量指向的原变量的值。
5.4.4 指针传值示例
Go
package main
import "fmt"
func modify1(x int) { // 系统把 a 的值 10 复制一份给 x
x = 100 // 改的是副本 x,main.a 完全不知道
}
func modify2(x *int) { // x 是一个指针变量,存的是 0xc000010210
*x = 100 // 解引用:把地址 0xc000010210 里的值改成 100
// 这一步直接改的就是 main 栈里的那块内存,所以 a 变成 100。
}
func main() {
a := 10 // main 栈帧里分配一块内存,名字是 a,值 10
modify1(a)
fmt.Println(a) // 执行完 modify1 栈帧被回收,main 里的 a 依旧是 10。
modify2(&a)
fmt.Println(a)
// modify1 拿到的是"值的复印件",改完就扔;
// modify2 拿到的是"原件的钥匙",进门随便改------这就是指针存在的最直观意义。
}5.4.5 new 和 make
我们先来看一个例子:
Go
package main
import "fmt"
// func main() {
// // 在Web3中,尝试创建一个未初始化的钱包余额映射
// var tokenBalances map[string]int // 声明一个映射,但未初始化
//
// // 尝试给未初始化的映射赋值(这会导致panic)
// tokenBalances["USDC"] = 1000 // panic: assignment to entry in nil map
// fmt.Println(tokenBalances)
// }
func main() {
// 在Web3中,尝试使用未初始化的智能合约指针
var contractPointer *int // 声明一个指针,但未指向任何有效的内存地址
// 尝试对空指针进行解引用并赋值(这会导致panic)
*contractPointer = 100 // panic: runtime error: invalid memory address or nil pointer dereference
fmt.Println(*contractPointer)
}执行上面的代码会引发 panic,为什么呢? **在 Go 语言中对于引用类型的变量,我们在使用的时候不仅要声明它,还要为它分配内存空间,否则我们的值就没办法存储。**而对于值类型的声明不需要分配内存空间,是因为它们在声明的时候已经默认分配好了内存空间。要分配内存,就引出来今天的 new 和 make。 Go 语言中 new 和 make 是内建的两个函数,主要用来分配内存。
(1)new 函数分配内存
new 是一个内置的函数,它的函数签名如下:
Go
func new(Type) *Type其中:
(1)Type 表示类型,new 函数只接受一个参数,这个参数是一个类型
(2)*Type 表示类型指针,new 函数返回一个指向该类型内存地址的指针。
实际开发中 new 函数不太常用,使用 new 函数得到的是一个类型的指针,并且该指针对应的值为该类型的零值。举个例子:
Go
package main
import "fmt"
func main() {
// 使用 new 函数为 int 类型分配内存,用于存储代币数量
// 在Web3中,代币数量通常使用大整数,但这里用int简化演示
// tokenBalance 是一个指针(*int),指向刚创建的内存空间
// 这个内存空间里的初始值是 int 类型的零值:0
tokenBalance := new(int)
// 使用 new 函数为 bool 类型分配内存,用于存储交易状态
// 在Web3中,布尔值常用于表示交易是否成功、合约调用是否通过等
// transactionStatus 是一个指针(*bool),指向刚创建的内存空间
// 这个内存空间里的初始值是 bool 类型的零值:false
transactionStatus := new(bool)
// 打印变量 tokenBalance 的类型
// %T 格式化输出变量类型
// tokenBalance 的类型是 *int(指向 int 的指针)
fmt.Printf("tokenBalance 类型: %T\n", tokenBalance) // *int
// 打印变量 transactionStatus 的类型
// transactionStatus 的类型是 *bool(指向 bool 的指针)
fmt.Printf("transactionStatus 类型: %T\n", transactionStatus) // *bool
// 对指针 tokenBalance 进行解引用,获取它指向的值
// 由于 tokenBalance 指向的 int 变量刚被 new 函数创建并初始化为零值
// 所以 *tokenBalance 的值为 0,表示初始代币余额为0
fmt.Printf("初始代币余额: %d\n", *tokenBalance) // 0
// 对指针 transactionStatus 进行解引用,获取它指向的值
// 由于 transactionStatus 指向的 bool 变量刚被 new 函数创建并初始化为零值
// 所以 *transactionStatus 的值为 false,表示初始交易状态为失败/未执行
fmt.Printf("初始交易状态: %v\n", *transactionStatus) // false
// Web3业务场景扩展
fmt.Println("\n=== Web3业务场景操作 ===")
// 模拟代币转账操作:更新代币余额
*tokenBalance = 1000 // 设置代币余额为1000
fmt.Printf("转账后代币余额: %d\n", *tokenBalance)
// 模拟交易执行:更新交易状态
*transactionStatus = true // 设置交易状态为成功
fmt.Printf("交易执行状态: %v\n", *transactionStatus)
// 模拟交易失败场景
fmt.Println("\n=== 交易失败场景 ===")
failedStatus := new(bool) // 创建新的交易状态指针
fmt.Printf("新交易状态初始值: %v\n", *failedStatus) // false,表示交易未开始或失败
// 尝试执行交易但失败
*failedStatus = false // 明确设置为false表示交易失败
fmt.Printf("交易执行结果: %v\n", *failedStatus)
// 使用函数处理更复杂的Web3业务
processSmartContract(tokenBalance, transactionStatus)
}
// 处理智能合约相关操作
func processSmartContract(balance *int, status *bool) {
fmt.Println("\n=== 智能合约处理 ===")
// 检查当前状态
if *status {
fmt.Println("交易状态: 已成功")
fmt.Printf("当前余额: %d\n", *balance)
// 模拟智能合约逻辑:如果交易成功,增加余额
*balance += 500
fmt.Printf("合约执行后余额: %d\n", *balance)
} else {
fmt.Println("交易状态: 失败或未执行")
fmt.Println("智能合约逻辑不会执行")
}
// 重置交易状态为未执行
*status = false
fmt.Printf("重置后的交易状态: %v\n", *status)
}本节开始的示例代码中 var a *int 只是声明了一个指针变量 a 但是没有初始化,指针作为引用类型需要初始化后才会拥有内存空间,才可以给它赋值。应该按照如下方式使用内置的new 函数对 a 进行初始化之后就可以正常对其赋值了:
Go
package main
import "fmt"
func main() {
// 声明一个指向 int 类型的指针变量 walletBalancePtr
// 此时 walletBalancePtr 还没有指向任何具体的内存空间,它的值是 nil(零值)
// 就像拿到一张"空白钱包地址",还没有分配具体的代币存储空间
var walletBalancePtr *int
// 使用 new 函数为 int 类型分配内存
// new(int) 在内存中创建一个 int 类型的"代币存储空间"
// 这个"存储空间"被初始化为 int 类型的零值:0
// 然后将这个"存储空间"的地址(钱包地址)赋值给指针 walletBalancePtr
// 现在 walletBalancePtr 指向一个值为 0 的代币余额
walletBalancePtr = new(int)
// 对指针 walletBalancePtr 进行解引用,访问它指向的内存空间
// 将 10 写入 walletBalancePtr 指向的内存位置
// 相当于将刚才分配的"代币存储空间"里的值从 0 改为 10 ETH
*walletBalancePtr = 10
// 打印指针变量 walletBalancePtr 自己的地址
// &walletBalancePtr 获取的是存储指针 walletBalancePtr 的内存地址
// 这就像问:"钱包地址指针本身存储在内存的哪个位置?"
fmt.Println(&walletBalancePtr) // 输出指针 walletBalancePtr 的地址(十六进制)
// 打印指针 walletBalancePtr 指向的值
// *walletBalancePtr 获取 walletBalancePtr 指向的内存位置中存储的值
// 这就像用"钱包地址"访问余额,看看里面有多少代币
fmt.Println(*walletBalancePtr) // 输出 10
// Web3业务场景扩展
fmt.Println("\n=== Web3业务场景操作 ===")
// 模拟更多的Web3操作
fmt.Printf("钱包余额指针指向的地址: %p\n", walletBalancePtr)
fmt.Printf("钱包余额指针自身的地址: %p\n", &walletBalancePtr)
fmt.Printf("钱包余额值: %d ETH\n", *walletBalancePtr)
// 模拟接收转账
receiveTransaction(walletBalancePtr, 5) // 接收5 ETH
fmt.Printf("接收转账后余额: %d ETH\n", *walletBalancePtr)
// 模拟发送转账
sendTransaction(walletBalancePtr, 3) // 发送3 ETH
fmt.Printf("发送转账后余额: %d ETH\n", *walletBalancePtr)
// 检查余额是否足够支付Gas
checkGasBalance(walletBalancePtr)
}
// 接收交易函数
func receiveTransaction(balancePtr *int, amount int) {
fmt.Printf("\n接收到 %d ETH 转账...\n", amount)
*balancePtr += amount
fmt.Printf("交易哈希: 0x1234567890abcdef\n")
fmt.Printf("区块确认: ✓ 已完成\n")
}
// 发送交易函数
func sendTransaction(balancePtr *int, amount int) bool {
fmt.Printf("\n尝试发送 %d ETH 转账...\n", amount)
// 检查余额是否足够
if *balancePtr >= amount {
gasFee := 1 // 假设Gas费为1 ETH
totalCost := amount + gasFee
if *balancePtr >= totalCost {
*balancePtr -= totalCost
fmt.Printf("转账成功! 发送: %d ETH, Gas费: %d ETH, 总计: %d ETH\n",
amount, gasFee, totalCost)
fmt.Printf("交易哈希: 0xfedcba0987654321\n")
return true
} else {
fmt.Printf("余额不足支付Gas费用! 需要: %d ETH, 当前: %d ETH\n",
totalCost, *balancePtr)
return false
}
} else {
fmt.Printf("余额不足! 需要: %d ETH, 当前: %d ETH\n", amount, *balancePtr)
return false
}
}
// 检查Gas余额函数
func checkGasBalance(balancePtr *int) {
fmt.Println("\n=== Gas余额检查 ===")
gasRequired := 2 // 假设需要2 ETH作为Gas
if *balancePtr >= gasRequired {
fmt.Printf("✅ 余额充足: %d ETH (需要 %d ETH Gas)\n", *balancePtr, gasRequired)
} else {
fmt.Printf("⚠️ 余额不足: %d ETH (需要 %d ETH Gas)\n", *balancePtr, gasRequired)
fmt.Println("建议: 充值ETH或降低交易Gas限制")
}
}(2)make 函数分配内存
make 也是用于内存分配的,区别于 new,它只用于slice、map 以及 chan 的内存创建,而且它返回的类型就是这三个类型本身,而不是它们的指针类型,因为这三种类型就是引用类型,所以就没有必要返回它们的指针了。make 函数的函数签名如下:
Go
func make(t Type, size ...IntegerType) Typemake 函数是无可替代的,我们在使用 slice、map 以及 channel 的时候,都需要使用 make 进行初始化,然后才可以对它们进行操作。这个我们在前面的教程中都有说明,关于 channel 我们会在后续的章节详细说明。
本节开始的示例中 var b mapstringint 只是声明变量 b 是一个 map 类型的变量,需要像下面的示例代码一样使用 make 函数进行初始化操作之后,才能对其进行键值对赋值:
Go
package main
import "fmt"
func main() {
// 声明一个映射,用于存储以太坊地址到ENS域名的映射
// 在Web3中,ENS(以太坊域名服务)允许将地址映射到易读的域名
var ensRegistry map[string]string
// 使用make函数初始化映射
// 在Web3中,我们需要先初始化映射才能安全地存储数据
ensRegistry = make(map[string]string)
// 将一个以太坊地址映射到ENS域名
// 这相当于注册一个ENS域名,将0x地址映射到易读的"zhangsan.eth"
ensRegistry["0x742d35Cc6634C0532925a3b844Bc9e2267c6f5B4"] = "zhangsan.eth"
// 打印整个ENS注册表
fmt.Println(ensRegistry)
// Web3业务场景扩展
fmt.Println("\n=== ENS域名解析服务 ===")
// 查询特定地址的ENS域名
address := "0x742d35Cc6634C0532925a3b844Bc9e2267c6f5B4"
if domain, exists := ensRegistry[address]; exists {
fmt.Printf("地址 %s 对应的ENS域名是: %s\n", address, domain)
} else {
fmt.Printf("地址 %s 没有注册ENS域名\n", address)
}
// 添加更多ENS映射
fmt.Println("\n=== 添加更多ENS映射 ===")
ensRegistry["0xAb5801a7D398351b8bE11C439e05C5B3259aeC9B"] = "vitalik.eth"
ensRegistry["0x1f9090aaE28b8a3dCeaDf281B0F12828e676c326"] = "coinbase.eth"
fmt.Println("更新后的ENS注册表:")
for address, domain := range ensRegistry {
fmt.Printf(" %s → %s\n", address, domain)
}
// 模拟ENS域名反向解析
fmt.Println("\n=== ENS反向解析 ===")
targetDomain := "vitalik.eth"
for addr, domain := range ensRegistry {
if domain == targetDomain {
fmt.Printf("ENS域名 %s 对应的地址是: %s\n", targetDomain, addr)
break
}
}
// 模拟ENS域名注册过程
fmt.Println("\n=== 注册新的ENS域名 ===")
registerENS(ensRegistry, "0x1234567890abcdef1234567890abcdef12345678", "newuser.eth")
// 检查映射大小
fmt.Printf("\n当前ENS注册表包含 %d 条记录\n", len(ensRegistry))
}
// 注册ENS域名的函数
func registerENS(registry map[string]string, address string, domain string) {
// 检查域名是否已存在
for _, existingDomain := range registry {
if existingDomain == domain {
fmt.Printf("域名 %s 已被注册\n", domain)
return
}
}
// 注册新域名
registry[address] = domain
fmt.Printf("成功注册: 地址 %s 绑定到域名 %s\n", address, domain)
// 模拟区块链交易
fmt.Printf("交易哈希: 0x%s\n", address[:16])
fmt.Println("等待区块确认...")
fmt.Println("✅ ENS域名注册完成")
}new 与 make 都是 Go 用来"申请内存 "的内建函数,但分配的对象、返回的类型、初始化程度完全不同。一句话记忆:
new 只管"零值"+"返回指针";
make 只用于"引用类型"+"返回初始化好的值本身"。
(1)函数原型对比
| 函数 | 签名 | 返回类型 | 适用类型 |
|---|---|---|---|
new |
func new(Type) *Type |
指针 | 任意类型(基本、结构、数组...) |
make |
func make(t Type, size ...int) t |
值本身(非指针) | 只能是 slice / map / channal |
(2)零值 vs 初始化
-
new把内存清零就完事(零值)。 -
make会完成内部初始化:-
slice:创建底层数组并设置 len/cap
-
map:创建哈希桶,可直接赋值
-
chan:建立环形队列,可立即收发
-
(3)代码对照
① slice --- 必须用 make 才能直接用
Go
// 错误:new 返回的是 *slice,且 len=0,不能 append
s1 := new([]int) // *[]int,nil 切片
(*s1) = append(*s1, 1) // 繁琐
// 正确:make 返回 []int,len=0 但已初始化
s2 := make([]int, 0, 4) // 可直接 append
s2 = append(s2, 1)② map --- 同理
Go
m1 := new(map[string]int) // *map[string]int,nil
(*m1)["a"] = 1 // panic: assignment to entry in nil map
m2 := make(map[string]int) // map[string]int,已初始化
m2["a"] = 1 // 正常③ chan
Go
ch1 := new(chan int) // *chan int,nil
*ch1 <- 1 // panic
ch2 := make(chan int) // chan int,已建好队列
ch2 <- 1 // 阻塞/正常④ 结构体 --- new 足够
Go
type Point struct{ X, Y int }
p := new(Point) // *Point,{0,0}
p.X = 3(4)口诀速记
"new 指针零值,make 初始化;slice、map、chan 三者只认 make,其余 new 搞定。"
(5)一张图总结

记住这条分界线,就不会再纠结"到底用谁"了。
(3)new 与 make 的区别
1)、二者都是用来做内存分配的。
2)、make 只用于 slice、map 以及 channel 的初始化,返回的还是这三个引用类型本身
3)、而 new 用于类型的内存分配,并且内存对应的值为类型零值,返回的是指向类型的指针。
5.5 接口(interface)
5.5.1 接口的介绍
(1)现实生活中的接口
现实生活中手机、相机、U 盘都可以和电脑的 USB 接口建立连接。我们不需要关注 USB 卡槽大小是否一样,因为所有的 USB 接口都是按照统一的标准来设计的。

(2)Golang 中的接口
Golang 中的接口(interface)是一种抽象数据类型,Golang 中接口定义了对象的行为规范,只定义规范不实现。接口中定义的规范由具体的对象来实现。
通俗的讲接口就一个标准,它是对一个对象的行为和规范进行约定,约定实现接口的对象必须得按照接口的规范。
5.5.2 Golang 接口的定义
在 Golang 中接口(interface)是一种类型,一种抽象的类型。接口(interface)是一组函数 method 的集合,Golang 中的接口不能包含任何变量。
在 Golang 中接口中的所有方法都没有方法体,接口定义了一个对象的行为规范,只定义规范不实现。接口体现了程序设计的多态 和高内聚低耦合的思想
Golang 中的接口也是一种数据类型,不需要显示实现。只需要一个变量含有接口类型中的所有方法,那么这个变量就实现了这个接口。
Golang 中每个接口由数个方法组成,接口的定义格式如下:
Go
type 接口名 interface{
方法名 1( 参数列表 1 ) 返回值列表 1
方法名 2( 参数列表 2 ) 返回值列表 2
...
}其中:
• 接口名:使用 type 将接口定义为自定义的类型名。Go 语言的接口在命名时,一般会在单词后面添加 er,如有写操作的接口叫 Writer,有字符串功能的接口叫 Stringer 等。接口名最好要能突出该接口的类型含义。
• 方法名:当方法名首字母是大写且这个接口类型名首字母也是大写时,这个方法可以被接口所在的包(package)之外的代码访问。
• 参数列表、返回值列表:参数列表和返回值列表中的参数变量名可以省略。
演示:定义一个 Usber 接口让 Phone 和 Camera 结构体实现这个接口。
Go
package main
import "fmt"
// 定义一个名为 BlockchainOperator 的接口
// 接口定义了一组方法签名,任何实现了这些方法的类型都隐式实现了该接口
// 在Web3中,这表示智能合约的基本操作接口
type BlockchainOperator interface {
Deploy() // 部署智能合约的方法
Execute() // 执行合约函数的方法
}
// 定义一个 ERC20Token 结构体
// 结构体是自定义的数据类型,表示以太坊上的ERC20代币合约
type ERC20Token struct {
Name string // 代币的名称字段
Symbol string // 代币的符号字段
}
// 为 ERC20Token 结构体实现 Deploy 方法
// 这是值接收器方法,接收的是 ERC20Token 的副本
// 实现了 BlockchainOperator 接口的 Deploy 方法
func (token ERC20Token) Deploy() {
// 访问 ERC20Token 的 Name 和 Symbol 字段并打印
fmt.Printf("部署 %s (%s) ERC20代币合约...\n", token.Name, token.Symbol)
}
// 为 ERC20Token 结构体实现 Execute 方法
// 同样使用值接收器,实现了 BlockchainOperator 接口的 Execute 方法
func (token ERC20Token) Execute() {
// 执行代币合约的转账操作
fmt.Printf("执行 %s (%s) 代币转账操作...\n", token.Name, token.Symbol)
}
// 定义 NFTContract 结构体
// 这个结构体表示以太坊上的非同质化代币合约
type NFTContract struct {
// 这里可以为NFT合约添加字段,如集合名称、创建者等
Collection string // NFT集合名称
}
// 为 NFTContract 结构体实现 Deploy 方法
// 实现了 BlockchainOperator 接口的 Deploy 方法
func (nft NFTContract) Deploy() {
fmt.Printf("部署 %s NFT集合合约...\n", nft.Collection)
}
// 为 NFTContract 结构体实现 Execute 方法
// 实现了 BlockchainOperator 接口的 Execute 方法
func (nft NFTContract) Execute() {
fmt.Printf("执行 %s NFT铸造或转移操作...\n", nft.Collection)
}
func main() {
// 创建 ERC20Token 结构体的实例(对象)
// 使用结构体字面量初始化,为 Name 字段赋值为"USD Coin",Symbol字段赋值为"USDC"
usdcToken := ERC20Token{
Name: "USD Coin",
Symbol: "USDC",
}
// 创建一个 BlockchainOperator 接口类型的变量 p
// 将 usdcToken 赋值给 p,这自动发生了类型转换
// 因为 ERC20Token 实现了 BlockchainOperator 接口的所有方法,所以 ERC20Token 可以赋值给 BlockchainOperator 接口变量
// 这是 Go 接口的"鸭子类型"特性:只要一个类型实现了接口的所有方法,它就实现了该接口
var p BlockchainOperator = usdcToken // usdcToken 实现了 BlockchainOperator 接口
// 通过接口变量调用 Deploy 方法
// 实际执行的是 ERC20Token 类型的 Deploy 方法
p.Deploy()
// 注意:也可以通过 usdcToken.Deploy() 直接调用,但这里演示了接口的用法
// 创建 NFTContract 结构体的实例
baycNFT := NFTContract{
Collection: "Bored Ape Yacht Club",
}
// 创建一个 BlockchainOperator 接口类型的变量 c
// 将 baycNFT 赋值给 c,同样因为 NFTContract 实现了 BlockchainOperator 接口
var c BlockchainOperator = baycNFT // baycNFT 实现了 BlockchainOperator 接口
// 通过接口变量调用 Deploy 方法
// 实际执行的是 NFTContract 类型的 Deploy 方法
c.Deploy()
// 可以继续调用 Execute 方法
p.Execute()
c.Execute()
}演示:Computer 结构体中的 Work 方法必须传入一个 Usb 的接口
Go
package main
import (
"fmt"
"strings"
)
// BlockchainOperator 区块链操作接口,定义智能合约的基本操作
type BlockchainOperator interface {
Deploy() // 部署智能合约
Execute() // 执行合约函数
}
// ERC20Token ERC20代币合约结构体
type ERC20Token struct {
Name string // 代币名称
Symbol string // 代币符号
}
// Deploy 实现ERC20代币的部署方法
func (token ERC20Token) Deploy() {
fmt.Printf("部署 %s (%s) ERC20代币合约...\n", token.Name, token.Symbol)
}
// Execute 实现ERC20代币的执行方法
func (token ERC20Token) Execute() {
fmt.Printf("执行 %s (%s) 代币转账操作...\n", token.Name, token.Symbol)
}
// NFTContract NFT代币合约结构体
type NFTContract struct {
Collection string // NFT系列名称
}
// Deploy 实现NFT合约的部署方法
func (nft NFTContract) Deploy() {
fmt.Printf("部署 %s NFT集合合约...\n", nft.Collection)
}
// Execute 实现NFT合约的执行方法
func (nft NFTContract) Execute() {
fmt.Printf("执行 %s NFT铸造或转移操作...\n", nft.Collection)
}
// BlockchainClient 区块链客户端结构体
type BlockchainClient struct {
Network string // 区块链网络名称
}
// Work 区块链客户端的执行方法,要求必须传入 BlockchainOperator接口类型数据
func (client BlockchainClient) Work(contract BlockchainOperator) {
fmt.Printf("\n[%s网络] 开始处理智能合约:\n", client.Network)
contract.Deploy() // 调用合约的部署方法
contract.Execute() // 调用合约的执行方法
fmt.Println("合约操作完成")
}
func main() {
// 创建ERC20代币实例
usdcToken := ERC20Token{
Name: "USD Coin",
Symbol: "USDC",
}
// 创建NFT合约实例
baycNFT := NFTContract{
Collection: "Bored Ape Yacht Club",
}
// 创建区块链客户端实例
ethereumClient := BlockchainClient{
Network: "Ethereum Mainnet",
}
// 把ERC20代币合约发送到区块链客户端执行
ethereumClient.Work(usdcToken)
// 把NFT合约发送到区块链客户端执行
ethereumClient.Work(baycNFT)
// 创建Polygon网络客户端实例
polygonClient := BlockchainClient{
Network: "Polygon",
}
// 在Polygon网络上执行USDC代币合约
fmt.Println("\n" + strings.Repeat("=", 50))
polygonClient.Work(usdcToken)
}5.5.3 空接口
Golang 中的接口可以不定义任何方法,没有定义任何方法的接口就是空接口。空接口表示没有任何约束,因此任何类型变量都可以实现空接口。
空接口在实际项目中用的是非常多的,用空接口可以表示任意数据类型。
课程案例:
Go
package main
import (
"fmt"
"math/big"
)
func main() {
// 定义了一个空接口x,x变量可以接受任意的Web3数据类型
var x interface{}
// 第一个赋值:以太坊地址(字符串类型)
address := "0x742d35Cc6634C0532925a3b844Bc9e2267c6f5B4"
x = address
fmt.Printf("type:%T value:%v\n", x, x)
// 第二个赋值:代币数量(大整数类型)
amount := big.NewInt(1500000000000000000) // 1.5 ETH,单位wei
x = amount
fmt.Printf("type:%T value:%v\n", x, x)
// 第三个赋值:交易状态(布尔类型)
txStatus := true
x = txStatus
fmt.Printf("type:%T value:%v\n", x, x)
// 添加第四个赋值:交易手续费(浮点数类型)
gasFee := 0.0032 // ETH
x = gasFee
fmt.Printf("type:%T value:%v\n", x, x)
}(1)空接口作为函数的参数
使用空接口实现可以接收任意类型的函数参数。
Go
package main
import (
"fmt"
"math/big"
)
// 显示Web3数据详情 - 通用函数处理所有区块链数据类型
func showWeb3Data(data interface{}) {
// 打印数据的类型和原始值
fmt.Printf("type:%T value:%v\n", data, data)
// 添加Web3业务解释
switch v := data.(type) {
case string:
if len(v) == 42 && v[:2] == "0x" {
fmt.Println("解释: 这是一个以太坊地址")
} else if len(v) == 66 && v[:2] == "0x" {
fmt.Println("解释: 这是一个交易哈希")
} else {
fmt.Println("解释: 这是一个字符串")
}
case *big.Int:
// 转换为ETH单位
ethValue := new(big.Float).Quo(new(big.Float).SetInt(v), big.NewFloat(1e18))
fmt.Printf("解释: 代币数量 %s ETH\n", ethValue.Text('f', 4))
case bool:
if v {
fmt.Println("解释: 交易状态为成功")
} else {
fmt.Println("解释: 交易状态为失败")
}
case float64:
fmt.Printf("解释: Gas费用 %v ETH\n", v)
case int, int32, int64:
fmt.Println("解释: 可能表示区块高度或交易数量")
case map[string]interface{}:
fmt.Println("解释: 这是一个包含多种类型数据的资产映射表")
case []interface{}:
fmt.Println("解释: 这是一个包含多种类型数据的数组")
default:
fmt.Println("解释: 区块链数据类型")
}
}
func main() {
// 测试不同类型的Web3数据
fmt.Println("=== 测试Web3数据类型 ===")
// 测试以太坊地址
address := "0x742d35Cc6634C0532925a3b844Bc9e2267c6f5B4"
fmt.Println("\n1. 以太坊地址:")
showWeb3Data(address)
// 测试代币数量
amount := big.NewInt(1500000000000000000) // 1.5 ETH
fmt.Println("\n2. 代币数量:")
showWeb3Data(amount)
// 测试交易状态
status := true
fmt.Println("\n3. 交易状态:")
showWeb3Data(status)
// 测试Gas费用
gasFee := 0.0032
fmt.Println("\n4. Gas费用:")
showWeb3Data(gasFee)
// 测试区块高度
blockNumber := 17823456
fmt.Println("\n5. 区块高度:")
showWeb3Data(blockNumber)
// 测试资产映射表
assetMap := map[string]interface{}{
"address": address,
"balance": amount,
"status": status,
}
fmt.Println("\n6. 资产映射表:")
showWeb3Data(assetMap)
// 测试数据数组
dataArray := []interface{}{address, amount, status}
fmt.Println("\n7. 数据数组:")
showWeb3Data(dataArray)
}(2)map 的值实现空接口
使用空接口实现可以保存任意值的字典。
Go
package main
import (
"fmt"
"math/big"
)
func main() {
// 创建区块链资产信息映射表
// 在Web3中,一个钱包地址通常关联多种不同类型的资产和数据
// map的键是资产标识符,值可以是任意类型的区块链数据(空接口)
var walletAssets = make(map[string]interface{})
// 添加不同类型的数据到钱包资产表中
walletAssets["address"] = "0x742d35Cc6634C0532925a3b844Bc9e2267c6f5B4" // 钱包地址 - 字符串类型
walletAssets["eth_balance"] = big.NewInt(3500000000000000000) // ETH余额 - 大整数类型 (3.5 ETH)
walletAssets["is_verified"] = true // 是否已验证 - 布尔类型
walletAssets["transaction_count"] = 142 // 交易数量 - 整数类型
walletAssets["last_active"] = "2024-01-15 14:30:00" // 最后活跃时间 - 字符串类型
walletAssets["gas_price_preference"] = 45.7 // Gas价格偏好 - 浮点数类型 (Gwei)
// 添加代币余额信息(嵌套map)
walletAssets["token_balances"] = map[string]*big.Int{
"USDT": big.NewInt(5000000000), // 5000 USDT (6 decimals)
"DAI": big.NewInt(2000000000000000000), // 2 DAI (18 decimals)
"UNI": big.NewInt(1500000000000000000), // 1.5 UNI (18 decimals)
}
// 添加NFT资产信息(结构体切片)
type NFT struct {
Collection string
TokenID int
Name string
}
walletAssets["nfts"] = []NFT{
{"Bored Ape Yacht Club", 1234, "Ape #1234"},
{"CryptoPunks", 5678, "Punk #5678"},
{"Art Blocks", 9012, "Fidenza #9012"},
}
// 打印原始资产数据
fmt.Println("=== 钱包资产信息(原始数据)===")
for key, value := range walletAssets {
fmt.Printf("%s: %v\n", key, value)
}
fmt.Println("\n" + "="*50 + "\n")
// 使用类型断言安全地处理不同类型的数据
fmt.Println("=== 类型安全解析钱包资产 ===")
// 解析钱包地址
if address, ok := walletAssets["address"].(string); ok {
fmt.Printf("钱包地址: %s\n", address)
fmt.Printf("地址类型: %T\n", address)
}
// 解析ETH余额
if ethBalance, ok := walletAssets["eth_balance"].(*big.Int); ok {
ethValue := new(big.Float).Quo(new(big.Float).SetInt(ethBalance), big.NewFloat(1e18))
fmt.Printf("\nETH余额: %s ETH\n", ethValue.Text('f', 4))
fmt.Printf("原始数据 (wei): %s\n", ethBalance.String())
fmt.Printf("数据类型: %T\n", ethBalance)
}
// 解析验证状态
if isVerified, ok := walletAssets["is_verified"].(bool); ok {
fmt.Printf("\n钱包验证状态: %v\n", isVerified)
verificationStatus := "未验证"
if isVerified {
verificationStatus = "已验证"
}
fmt.Printf("状态说明: %s\n", verificationStatus)
}
// 解析代币余额
fmt.Println("\n=== 代币余额详情 ===")
if tokenBalances, ok := walletAssets["token_balances"].(map[string]*big.Int); ok {
for token, balance := range tokenBalances {
// 根据代币精度确定除数
divisor := big.NewFloat(1e18) // 默认18位小数
if token == "USDT" {
divisor = big.NewFloat(1e6) // USDT 6位小数
}
// 计算代币数量
tokenValue := new(big.Float).Quo(new(big.Float).SetInt(balance), divisor)
fmt.Printf("%s: %s\n", token, tokenValue.Text('f', 2))
}
}
// 解析NFT资产
fmt.Println("\n=== NFT资产详情 ===")
if nfts, ok := walletAssets["nfts"].([]NFT); ok {
for i, nft := range nfts {
fmt.Printf("NFT %d:\n", i+1)
fmt.Printf(" 系列: %s\n", nft.Collection)
fmt.Printf(" 代币ID: %d\n", nft.TokenID)
fmt.Printf(" 名称: %s\n", nft.Name)
}
fmt.Printf("总计: %d 个NFT\n", len(nfts))
}
fmt.Println("\n" + "="*50 + "\n")
// 实际应用:计算总资产价值(简化版)
fmt.Println("=== 资产价值估算 ===")
var totalUSDValue float64 = 0
// 估算ETH价值(假设1 ETH = $2000)
if ethBalance, ok := walletAssets["eth_balance"].(*big.Int); ok {
ethValue := new(big.Float).Quo(new(big.Float).SetInt(ethBalance), big.NewFloat(1e18))
ethFloat, _ := ethValue.Float64()
ethUSDValue := ethFloat * 2000
fmt.Printf("ETH价值: $%.2f (%.4f ETH × $2000)\n", ethUSDValue, ethFloat)
totalUSDValue += ethUSDValue
}
// 估算代币价值(简化)
if tokenBalances, ok := walletAssets["token_balances"].(map[string]*big.Int); ok {
tokenPrices := map[string]float64{
"USDT": 1.0,
"DAI": 1.0,
"UNI": 6.5,
}
for token, balance := range tokenBalances {
divisor := 1e18
if token == "USDT" {
divisor = 1e6
}
tokenAmount := new(big.Float).Quo(new(big.Float).SetInt(balance), big.NewFloat(divisor))
tokenFloat, _ := tokenAmount.Float64()
tokenValue := tokenFloat * tokenPrices[token]
fmt.Printf("%s价值: $%.2f (%.2f × $%.2f)\n", token, tokenValue, tokenFloat, tokenPrices[token])
totalUSDValue += tokenValue
}
}
// 估算NFT价值(简化)
if nfts, ok := walletAssets["nfts"].([]NFT); ok {
nftValue := float64(len(nfts)) * 1000 // 假设每个NFT价值$1000
fmt.Printf("NFT总价值: $%.2f (%d个NFT × $1000)\n", nftValue, len(nfts))
totalUSDValue += nftValue
}
fmt.Printf("\n💰 总资产价值估算: $%.2f\n", totalUSDValue)
fmt.Println("\n" + "="*50 + "\n")
// 模拟钱包操作:检查是否满足交易条件
fmt.Println("=== 交易条件检查 ===")
requiredGas := big.NewInt(21000) // 基础Gas费用
gasPrice := big.NewInt(20000000000) // 20 Gwei
if ethBalance, ok := walletAssets["eth_balance"].(*big.Int); ok {
gasCost := new(big.Int).Mul(requiredGas, gasPrice)
fmt.Printf("当前ETH余额: %s wei\n", ethBalance.String())
fmt.Printf("Gas费用估计: %s wei\n", gasCost.String())
if ethBalance.Cmp(gasCost) > 0 {
fmt.Println("✅ Gas费用检查: 通过")
remaining := new(big.Int).Sub(ethBalance, gasCost)
fmt.Printf("交易后余额: %s wei\n", remaining.String())
} else {
fmt.Println("❌ Gas费用检查: 失败")
fmt.Println("余额不足支付Gas费用")
}
}
}(3)切片实现空接口
Go
package main
import (
"fmt"
"math/big"
)
func main() {
// 创建一个空接口切片,模拟区块链交易或事件中的多种数据类型
// 在Web3中,一个交易或事件可能包含多种类型的数据
// 例如:发送者地址(字符串)、交易数量(大整数)、交易状态(布尔值)、手续费(浮点数)
var blockchainData = []interface{}{
"0x742d35Cc6634C0532925a3b844Bc9e2267c6f5B4", // 发送者地址 - 以太坊地址字符串
big.NewInt(1000000000000000000), // 交易数量 - 1 ETH (以wei为单位的大整数)
true, // 交易状态 - 是否成功
0.005, // 手续费 - ETH (Gas费用)
}
fmt.Println("=== 区块链交易数据解析 ===")
fmt.Printf("原始数据: %v\n\n", blockchainData)
// 遍历切片并解析每个元素的类型和值
for i, data := range blockchainData {
fmt.Printf("元素 %d:\n", i+1)
// 使用类型断言解析不同类型的区块链数据
switch v := data.(type) {
case string:
// 字符串类型 - 可能是钱包地址、交易哈希、智能合约地址等
if len(v) == 42 && v[:2] == "0x" {
fmt.Printf(" 类型: 以太坊地址\n")
fmt.Printf(" 值: %s\n", v)
fmt.Printf(" 用途: 发送者/接收者钱包地址\n")
} else {
fmt.Printf(" 类型: 字符串\n")
fmt.Printf(" 值: %s\n", v)
}
case *big.Int:
// 大整数类型 - 通常是代币数量,单位是wei
fmt.Printf(" 类型: 代币数量 (big.Int)\n")
fmt.Printf(" 原始值 (wei): %s\n", v.String())
// 转换为ETH单位显示 (1 ETH = 10^18 wei)
ethValue := new(big.Float).Quo(new(big.Float).SetInt(v), big.NewFloat(1e18))
fmt.Printf(" 转换为ETH: %s\n", ethValue.Text('f', 6))
case bool:
// 布尔类型 - 表示交易状态、条件判断等
fmt.Printf(" 类型: 布尔值\n")
fmt.Printf(" 值: %v\n", v)
if v {
fmt.Printf(" 含义: 交易成功\n")
} else {
fmt.Printf(" 含义: 交易失败\n")
}
case float64:
// 浮点数类型 - 可能表示手续费、代币价格等
fmt.Printf(" 类型: 浮点数 (手续费)\n")
fmt.Printf(" 值: %v ETH\n", v)
fmt.Printf(" 实际价值: 约 $%.2f (以$2000/ETH计算)\n", v*2000)
case int, int32, int64:
// 整数类型 - 可能表示区块高度、交易nonce等
fmt.Printf(" 类型: 整数\n")
fmt.Printf(" 值: %v\n", v)
default:
// 其他类型 - 比如智能合约字节码、复杂数据结构等
fmt.Printf(" 类型: %T\n", v)
fmt.Printf(" 值: %v\n", v)
}
fmt.Println()
}
// 实际应用示例:模拟交易验证
fmt.Println("=== 交易验证示例 ===")
if len(blockchainData) >= 4 {
sender, ok1 := blockchainData[0].(string)
amount, ok2 := blockchainData[1].(*big.Int)
status, ok3 := blockchainData[2].(bool)
fee, ok4 := blockchainData[3].(float64)
if ok1 && ok2 && ok3 && ok4 {
fmt.Printf("发送者: %s\n", sender)
ethAmount := new(big.Float).Quo(new(big.Float).SetInt(amount), big.NewFloat(1e18))
fmt.Printf("发送金额: %s ETH\n", ethAmount.Text('f', 4))
fmt.Printf("交易状态: %v\n", status)
fmt.Printf("手续费: %v ETH\n", fee)
// 简单验证
if status {
totalCost := new(big.Float).Add(ethAmount, big.NewFloat(fee))
fmt.Printf("总支出: %s ETH\n", totalCost.Text('f', 6))
fmt.Println("✅ 交易验证通过")
} else {
fmt.Println("❌ 交易失败")
}
} else {
fmt.Println("❌ 交易数据格式错误")
}
}
}5.5.4 类型断言
一个接口的值(简称接口值)是由一个具体类型和具体类型的值两部分组成的。这两部分分别称为接口的动态类型 和动态值。如果我们想要判断空接口中值的类型,那么这个时候就可以使用类型断言,其语法格式:
Go
x.(T)其中:
• x : 表示类型为 interface{} 的变量。
• T : 表示断言 x 可能是的类型。
该语法返回两个参数,第一个参数是 x 转化为 T 类型后的变量,第二个值是一个布尔值,若为 true 则表示断言成功,为 false 则表示断言失败。
举个例子:
Go
package main
import "fmt"
func main() {
// 声明一个空接口变量 x
// 空接口 interface{} 可以存储任何类型的值
// 在Web3中,这可以表示一个未确定类型的区块链数据容器
// 可以存储地址、交易哈希、区块号、代币数量等任意类型的区块链数据
var x interface{}
// 将一个以太坊钱包地址字符串赋值给空接口变量 x
// 在以太坊中,地址是0x开头的42个字符的十六进制字符串
// 此时 x 存储的是一个钱包地址字符串,但静态类型是 interface{}
x = "0x742d35Cc6634C0532925a3b844Bc9e2267c6f5B4"
// 使用类型断言(type assertion)
// x.(string) 尝试将 x 中存储的值转换为 string 类型
// 这里使用了两个返回值的形式(安全类型断言):
// v: 转换成功后的钱包地址字符串
// ok: 一个布尔值,表示地址转换是否成功(即x中存储的是否确实是字符串类型的地址)
v, ok := x.(string)
// 检查类型断言是否成功
if ok {
// 如果成功,打印转换后的钱包地址值
// 在Web3中,我们可以进一步处理这个地址,比如查询余额、发送交易等
fmt.Println("成功获取到钱包地址:", v)
fmt.Println("地址长度:", len(v), "字符")
fmt.Println("这是一个有效的以太坊地址格式")
} else {
// 如果失败,打印错误信息
// 在Web3中,这意味着我们期望的是地址字符串,但实际得到了其他类型的数据
// 比如可能是交易哈希、智能合约字节码、数字余额等其他区块链数据
fmt.Println("类型断言失败:期望的是钱包地址字符串,但实际类型不是string")
}
// 补充示例:展示类型断言失败的情况
fmt.Println("\n=== 类型断言失败示例 ===")
// 重新赋值x为一个数字(例如代币数量)
// 在Web3中,这可能是某个代币的数量(以wei为单位的大整数)
x = 1000000000000000000
// 再次尝试断言为string类型
v2, ok2 := x.(string)
if ok2 {
fmt.Println("成功获取到钱包地址:", v2)
} else {
fmt.Println("类型断言失败:期望的是钱包地址字符串,但实际类型是", fmt.Sprintf("%T", x))
fmt.Println("实际值:", x, "(这可能是代币数量,单位: wei)")
fmt.Println("注:1 ETH = 10^18 wei")
}
}上面的示例中如果要断言多次就需要写多个 if 判断,这个时候我们可以使用 switch 语句来实现:
注意:类型.(type)只能结合 switch 语句使用
Go
package main
import "fmt"
// ERC20Token 结构体 - 以太坊同质化代币标准
type ERC20Token struct {
name string // 代币名称
symbol string // 代币符号
balance string // 代币余额
}
// NFTToken 结构体 - 以太坊非同质化代币标准
type NFTToken struct {
name string // NFT 名称
tokenID int // 唯一的代币ID
collection string // 所属集合
}
// LPToken 结构体 - 去中心化交易所流动性代币
type LPToken struct {
poolName string // 流动性池名称
pair string // 交易对
share string // 份额比例
}
// justType 函数 - 对应 Web3 中的多链资产类型识别
// 根据不同的区块链资产类型执行不同的处理逻辑
func justType(x interface{}) {
// 类型开关(type switch) - 对应 Web3 中识别不同类型的区块链资产
// v := x.(type) 获取接口值的实际类型
switch v := x.(type) {
case ERC20Token:
// ERC20Token 类型 - 对应以太坊上的同质化代币标准
// 如 USDT、USDC、DAI 等,每个代币可分割,且价值相同
// 这是最常见的代币类型,用于支付、交易和价值存储
fmt.Printf("x 是一个 ERC20 代币,代币信息: %v\n", v)
case NFTToken:
// NFTToken 类型 - 对应以太坊上的非同质化代币
// 如 CryptoPunks、BAYC 等,每个代币独一无二,不可分割
// 用于数字艺术品、收藏品、游戏资产等
fmt.Printf("x 是一个 NFT 代币,NFT 信息: %v\n", v)
case LPToken:
// LPToken 类型 - 对应去中心化交易所的流动性提供者代币
// 如 Uniswap LP 代币,代表用户在流动性池中的份额
// 用户可以通过提供流动性获得交易手续费分成
fmt.Printf("x 是一个 LP 代币,流动性池信息: %v\n", v)
default:
// 默认分支 - 对应不支持的区块链资产类型
// 例如 Solana 链的代币、Cosmos 生态代币等不在此函数支持范围内
fmt.Println("不支持的区块链资产类型!")
}
}
func main() {
// 创建不同类型的 Web3 资产实例
// ERC20 代币示例 - USDC 稳定币
usdc := ERC20Token{
name: "USD Coin",
symbol: "USDC",
balance: "1000.00",
}
// NFT 代币示例 - Bored Ape Yacht Club 中的一个 NFT
baycNFT := NFTToken{
name: "Bored Ape Yacht Club",
tokenID: 1234,
collection: "BAYC",
}
// LP 代币示例 - Uniswap 的 ETH/USDC 流动性池代币
uniLP := LPToken{
poolName: "Uniswap V3",
pair: "ETH/USDC",
share: "0.5%",
}
// 测试类型识别函数
fmt.Println("=== 测试区块链资产类型识别 ===")
justType(usdc) // 识别 ERC20 代币
justType(baycNFT) // 识别 NFT
justType(uniLP) // 识别 LP 代币
// 测试不支持的类型
fmt.Println("\n=== 测试不支持的类型 ===")
justType(123) // 整数 - 不是 Web3 资产类型
justType("Ethereum") // 字符串 - 不是 Web3 资产类型
justType(true) // 布尔值 - 不是 Web3 资产类型
}因为空接口可以存储任意类型值的特点,所以空接口在 Go 语言中的使用十分广泛。
关于接口需要注意的是: 只有当有两个或两个以上的具体类型必须以相同的方式进行处理时才需要定义接口。不要为了接口而写接口,那样只会增加不必要的抽象,导致不必要的运行时损耗。
5.5.5 接口嵌套
接口与接口间可以通过嵌套创造出新的接口。
Go
package main
import "fmt"
// WalletInterface 钱包接口 - 对应 Web3 中的钱包账户功能
// 包含查询余额等钱包基本操作
type WalletInterface interface {
getBalance() // 查询钱包余额 - 在 Web3 中对应查询账户代币余额
}
// TransactionInterface 交易接口 - 对应 Web3 中的交易功能
// 包含转账等交易操作
type TransactionInterface interface {
transfer() // 执行转账 - 在 Web3 中对应发送代币交易
}
// TokenInterface 代币接口 - 对应 Web3 中的代币合约
// 通过接口嵌套,一个代币合约需要同时实现钱包和交易功能
type TokenInterface interface {
WalletInterface // 代币需要钱包功能(查询余额)
TransactionInterface // 代币需要交易功能(执行转账)
}
// ERC20Token 结构体 - 对应 Web3 中的 ERC20 标准代币
// 如 USDT、USDC、DAI 等常见的 ERC20 代币
type ERC20Token struct {
name string // 代币名称 - 如 "USD Coin"
symbol string // 代币符号 - 如 "USDC"
decimals uint8 // 代币精度 - 如 6 (USDC) 或 18 (大多数代币)
}
// 实现 WalletInterface 接口的 getBalance 方法
// 对应查询 ERC20 代币余额的功能
func (token ERC20Token) getBalance() {
fmt.Printf("查询 %s (%s) 代币余额...\n", token.name, token.symbol)
fmt.Println("当前余额: 1000.00", token.symbol) // 模拟查询结果
}
// 实现 TransactionInterface 接口的 transfer 方法
// 对应 ERC20 代币的 transfer 函数调用
func (token ERC20Token) transfer() {
fmt.Printf("执行 %s (%s) 代币转账...\n", token.name, token.symbol)
fmt.Println("转账成功: 从 0x123... 向 0x456... 转账 100", token.symbol) // 模拟交易成功
}
// LiquidityPoolInterface 流动性池接口 - 对应 Web3 中的 AMM 流动性池
// 如 Uniswap、SushiSwap 等 DeFi 协议中的流动性池
type LiquidityPoolInterface interface {
addLiquidity() // 添加流动性 - 对应向流动性池存入代币
removeLiquidity() // 移除流动性 - 对应从流动性池提取代币
}
// UniswapPool 结构体 - 对应 Uniswap V2/V3 流动性池
// 用户可以添加/移除流动性以获得交易费用分成
type UniswapPool struct {
pair string // 交易对 - 如 "ETH/USDC"
feeTier string // 手续费等级 - 如 "0.3%"
isV3 bool // 是否为 V3 版本
}
// 实现 WalletInterface 接口的 getBalance 方法
// 对应查询流动性池中 LP 代币的余额
func (pool UniswapPool) getBalance() {
fmt.Printf("查询 %s 流动性池 LP 代币余额...\n", pool.pair)
fmt.Println("LP 代币余额: 50.25") // 模拟查询结果
}
// 实现 TransactionInterface 接口的 transfer 方法
// 对应转移 LP 代币的功能
func (pool UniswapPool) transfer() {
fmt.Printf("转移 %s 流动性池的 LP 代币...\n", pool.pair)
fmt.Println("LP 代币转移成功")
}
// 实现 LiquidityPoolInterface 接口的 addLiquidity 方法
// 对应向流动性池添加流动性的操作
func (pool UniswapPool) addLiquidity() {
fmt.Printf("向 %s 流动性池添加流动性...\n", pool.pair)
if pool.isV3 {
fmt.Println("V3 版本: 需要选择价格区间")
}
fmt.Println("流动性添加成功")
}
// 实现 LiquidityPoolInterface 接口的 removeLiquidity 方法
// 对应从流动性池移除流动性的操作
func (pool UniswapPool) removeLiquidity() {
fmt.Printf("从 %s 流动性池移除流动性...\n", pool.pair)
fmt.Println("流动性移除成功,收到 ETH 和 USDC")
}
// AdvancedDeFiInterface 高级 DeFi 接口 - 对应复杂的 DeFi 协议
// 通过接口嵌套组合基础代币功能和流动性池功能
type AdvancedDeFiInterface interface {
TokenInterface // 包含代币的基本功能
LiquidityPoolInterface // 包含流动性池的功能
}
func main() {
// 创建一个 ERC20 代币实例 - 对应 Web3 中的 USDC 稳定币
usdcToken := ERC20Token{
name: "USD Coin",
symbol: "USDC",
decimals: 6, // USDC 的精度是 6 位小数
}
// 将 USDC 代币赋值给 TokenInterface 接口
// 因为 ERC20Token 实现了 TokenInterface 的所有方法
// 这对应在 Web3 中,我们可以使用统一的接口调用不同代币的方法
var token TokenInterface = usdcToken
// 通过代币接口调用方法
token.getBalance() // 查询代币余额
token.transfer() // 执行代币转账
fmt.Println("\n" + "==================================================" + "\n")
// 创建一个 Uniswap 流动性池实例 - 对应 ETH/USDC 交易对
// Uniswap 是以太坊上最流行的去中心化交易所
ethUsdcPool := UniswapPool{
pair: "ETH/USDC",
feeTier: "0.3%",
isV3: true, // 使用 Uniswap V3
}
// 将 Uniswap 流动性池赋值给 AdvancedDeFiInterface 接口
// 因为 UniswapPool 实现了所有必需的方法
// 这展示了接口嵌套的强大之处:一个类型可以实现多个接口
var defiProtocol AdvancedDeFiInterface = ethUsdcPool
// 通过高级 DeFi 接口调用所有方法
// 由于接口嵌套,我们可以通过一个接口访问所有功能
defiProtocol.getBalance() // 查询 LP 代币余额
defiProtocol.transfer() // 转移 LP 代币
defiProtocol.addLiquidity() // 添加流动性
defiProtocol.removeLiquidity() // 移除流动性
fmt.Println("\n" + "==================================================" + "\n")
// 演示接口的多态性 - 对应 Web3 中处理多种类型资产的能力
// 我们可以统一处理不同类型的代币和协议
fmt.Println("所有支持的 Web3 资产:")
web3Assets := []TokenInterface{
usdcToken,
ERC20Token{
name: "Wrapped Ether",
symbol: "WETH",
decimals: 18, // WETH 的精度是 18 位小数
},
ethUsdcPool, // 注意:这里也能添加,因为 UniswapPool 也实现了 TokenInterface
}
for i, asset := range web3Assets {
fmt.Printf("\n资产 %d:\n", i+1)
asset.getBalance() // 统一调用查询余额方法
asset.transfer() // 统一调用转账方法
}
}5.6 结构体
5.6.1 关于Golang 结构体
Golang 中没有"类"的概念,Golang 中的结构体和其他语言中的类有点相似。和其他面向对象语言中的类相比,Golang 中的结构体具有更高的扩展性和灵活性。
Golang 中的基础数据类型可以表示一些事物的基本属性,但是当我们想表达一个事物的全部或部分属性时(类比数据库中的一张表,有字段和字段对应的数据类型) ,这时候再用单一的基本数据类型就无法满足需求了,Golang 提供了一种自定义数据类型,可以封装多个基本数据类型,这种数据类型叫结构体,英文名称 struct。也就是我们可以通过 struct 来定义自己的类型了。
5.6.2 Golang type 关键词自定义类型和类型别名
Golang 中通过 type 关键词定义一个结构体,在讲解结构体之前,我们首先给大家看看通过 type 自定义类型以及定义类型别名。
(1)自定义类型
在 Go 语言中有一些基本的数据类型,如 字符串、整型、浮点型、布尔等数据类型, Go 语言中可以使用 type 关键字来定义自定义类型。
Go
type myInt int上面代码表示:将 myInt 定义为 int 类型,通过 type 关键字的定义,myInt 就是一种新的类型,它具有 int 的特性。
(2)类型别名
Golang1.9 版本以后添加的新功能。
类型别名规定:TypeAlias 只是 Type 的别名,本质上 TypeAlias 与 Type 是同一个类型。就像一个孩子小时候有大名、小名、英文名,但这些名字都指的是他本人。
Go
type TypeAlias = Type我们之前见过的 rune 和 byte 就是类型别名,它们的底层定义如下:
Go
type byte = uint8
type rune = int32(3)自定义类型和类型别名的区别
类型别名与自定义类型表面上看只有一个等号的差异,我们通过下面的这段代码来理解它们之间的区别。
Go
package main
import "fmt"
// 类型定义,得到一个新的类型
type newInt int
// 类型别名:还是以前的类型
type myInt = int
func main() {
var a newInt
var b myInt
fmt.Printf("type of a:%T\n", a) // main.newInt
fmt.Printf("type of b:%T\n", b) // int
}结果显示 a 的类型是 main.newInt,表示 main 包下定义的 newInt 类型。b 的类型是 int 类型。
5.6.3 结构体定义初始化的几种方法
(1)结构体的定义
使用 type 和 struct 关键字来定义结构体,具体代码格式如下:
Go
type 类型名 struct{
字段名1 字段类型
字段名2 字段类型
...
}其中:
• 类型名:表示自定义结构体的名称,在同一个包内不能重复。
• 字段名:表示结构体字段名。结构体中的字段名必须唯一。
• 字段类型:表示结构体字段的具体类型。
举个例子,我们定义一个 person(人)结构体,代码如下:
Go
type person struct{
name string
city string
age int8
}同样类型的字段也可以写在一行,
Go
type person struct{
name,city string
age int8
}注意:结构体的大小写具有不同的含义。
结构体首字母可以大写也可以小写,大写表示这个结构体是公有的 ,在其他的包里面可以使用。小写表示这个结构体是私有的,只有这个包里面才能使用。
(2)结构体实例化(第一种方法)
只有当结构体实例化时,才会真正地分配内存。也就是必须实例化后才能使用结构体的字段。结构体本身也是一种类型,我们可以像声明内置类型一样使用 var 关键字声明结构体类型。
Go
var 结构体实例 结构体类型
Go
package main
import "fmt"
// 定义区块链节点信息结构体
type blockchainNode struct {
nodeName string // 节点名称
network string // 网络类型
uptime int // 在线时长(天)
}
func main() {
// 实例化区块链节点结构体
var node1 blockchainNode
node1.nodeName = "验证节点01"
node1.network = "以太坊主网"
node1.uptime = 45
// 打印节点1的类型和值
fmt.Printf("node1的类型: %T\n", node1) // main.blockchainNode
fmt.Printf("node1的值: %v\n", node1) // node1={验证节点01 以太坊主网 45}
// %#v : 按可直接复制回源码的形式输出结构体
fmt.Printf("node1的详细结构: %#v\n", node1) // node1=main.blockchainNode{nodeName:"验证节点01", network:"以太坊主网", uptime:45}
// 输出格式对比:%%v %+v %#v
// 创建一个区块链交易结构体用于对比
type Transaction struct{ From, To string; Amount int }
tx := Transaction{"0xWalletA", "0xWalletB", 100}
// 打印格式说明
fmt.Printf("\n格式对比: %%v %%+v %%#v\n")
// 实际输出不同格式的结果
fmt.Printf("%v %+v %#v\n", tx, tx, tx)
}(3)结构体实例化(第二种方法)
我们还可以通过使用 new 关键字对结构体进行实例化,得到的是结构体的地址。 格式如下:
Go
package main
import "fmt"
// 定义区块链节点结构体
type blockchainNode struct {
nodeName string // 节点名称
network string // 网络类型
uptime int // 在线时长(天)
}
func main() {
// 使用new函数创建blockchainNode结构体的指针
var node2 = new(blockchainNode)
// 通过指针设置结构体字段的值
node2.nodeName = "验证节点02"
node2.uptime = 60
node2.network = "以太坊主网"
// 打印指针的类型
fmt.Printf("node2的类型: %T\n", node2) // *main.blockchainNode
// 使用%#v格式打印指针指向的结构体的详细内容
fmt.Printf("node2的详细内容: %#v\n", node2) // node2=&main.blockchainNode{nodeName:"验证节点02", network:"以太坊主网", uptime:60}
}从打印的结果中我们可以看出 node2是一个结构体指针。
注意 :在 Golang 中支持对结构体指针直接使用.来访问结构体的成员。p2.name = "张三" ,其实在底层是(*p2).name = "张三"
(4)结构体实例化(第三种方法)
使用**&对结构体进行取地址操作**相当于对该结构体类型进行了一次 new 实例化操作。
Go
package main
import "fmt"
// 定义区块链节点结构体
type blockchainNode struct {
nodeName string // 节点名称
network string // 网络类型
uptime int // 在线时长(天)
}
func main() {
// 使用取地址操作符&创建结构体指针
// &blockchainNode{} 创建并初始化一个结构体,然后返回其指针
node3 := &blockchainNode{} // 实例化区块链节点结构体
// 打印指针类型和初始值
fmt.Printf("node3的类型: %T\n", node3) // *main.blockchainNode
fmt.Printf("node3的初始值: %#v\n", node3) // node3=&main.blockchainNode{nodeName:"", network:"", uptime:0}
// 通过指针设置结构体字段值
node3.nodeName = "验证节点03"
node3.uptime = 90
node3.network = "Polygon网络"
// 使用指针解引用方式也可以访问和修改字段
(*node3).uptime = 100 // 这样也是可以的,通过解引用指针访问字段
// 打印修改后的值
fmt.Printf("node3修改后: %#v\n", node3) // node3=&main.blockchainNode{nodeName:"验证节点03", network:"Polygon网络", uptime:100}
}(5)结构体实例化(第四种方法) 键值对初始化
Go
package main
import "fmt"
// 定义区块链节点结构体
type blockchainNode struct {
nodeName string // 节点名称
network string // 网络类型
uptime int // 在线时长(天)
}
func main() {
// 使用字段名初始化结构体(推荐方式,清晰明了)
node4 := blockchainNode{
nodeName: "验证节点04",
network: "以太坊主网",
uptime: 75,
}
// 打印结构体的详细Go语法表示
fmt.Printf("node4=%#v\n", node4) // node4=main.blockchainNode{nodeName:"验证节点04", network:"以太坊主网", uptime:75}
}注意 :最后一个属性的**","**要加上。
(6)结构体实例化(第五种方法) 结构体指针 进行键值对初始化
Go
package main
import "fmt"
// 定义区块链节点结构体
type blockchainNode struct {
nodeName string // 节点名称
network string // 网络类型
uptime int // 在线时长(天)
}
func main() {
// 直接创建并初始化区块链节点的指针
// 使用取地址操作符&配合初始化列表创建结构体指针
node5 := &blockchainNode{
nodeName: "验证节点05",
network: "以太坊主网",
uptime: 120,
}
// 打印指针的类型
fmt.Printf("node5的类型: %T\n", node5) // *main.blockchainNode
// 打印指针的详细Go语法表示
fmt.Printf("node5=%#v\n", node5) // node5=&main.blockchainNode{nodeName:"验证节点05", network:"以太坊主网", uptime:120}
}当某些字段没有初始值的时候,这个字段可以不写。如下案例没有指定初始值的字段的。
Go
package main
import "fmt"
// 定义区块链节点结构体
type blockchainNode struct {
nodeName string // 节点名称
network string // 网络类型
uptime int // 在线时长(天)
}
func main() {
// 创建并初始化区块链节点指针,只指定部分字段
// 未指定的字段将使用零值:字符串为空字符串,整数为0
node6 := &blockchainNode{
network: "以太坊主网",
}
// 打印结构体指针的详细Go语法表示
// 注意:nodeName为空字符串,uptime为0
fmt.Printf("node6=%#v\n", node6) // 输出:node6=&main.blockchainNode{nodeName:"", network:"以太坊主网", uptime:0}
}(7)结构体实例化(第六种方法) 使用值的列表初始化
Go
package main
import "fmt"
// 定义区块链节点结构体
type blockchainNode struct {
nodeName string // 节点名称
network string // 网络类型
uptime int // 在线时长(天)
}
func main() {
// 初始化结构体的时候可以简写,不写字段名,直接按字段顺序写值
// 注意:这种方式要求值的顺序必须与结构体字段定义的顺序完全一致
node7 := &blockchainNode{
"验证节点07",
"以太坊主网",
90,
}
// 打印结构体指针的详细Go语法表示
fmt.Printf("node7=%#v\n", node7) // 输出:node7=&main.blockchainNode{nodeName:"验证节点07", network:"以太坊主网", uptime:90}
}使用这种格式初始化时,需要注意:
(1)必须初始化结构体的所有字段。
(2)初始值的填充顺序必须与字段在结构体中的声明顺序一致。
(3)该方式不能和键值初始化方式混用。
5.6.4 结构体方法和接收者
(1)什么是结构体方法
在 Go 语言中,结构体方法是定义在接收者上的函数,接收者将方法与结构体绑定。接收者有两种:值接收者 操作结构体副本,方法内修改不影响原对象;指针接收者操作结构体指针,可直接修改原对象。无论用值还是指针调用方法,Go 都会自动转换,但接收者类型决定了方法能否修改原数据。
Go
package main
import "fmt"
// 定义一个区块链节点结构体
type BlockchainNode struct {
NodeName string // 节点名称或地址
Uptime int // 节点在线时长(天)
}
// 为BlockchainNode结构体定义一个方法
func (n BlockchainNode) DisplayInfo() {
fmt.Printf("节点信息:名称/地址 %s,已在线运行 %d 天\n", n.NodeName, n.Uptime)
}
func main() {
// 创建一个区块链节点实例
node := BlockchainNode{NodeName: "0x742d35Cc6634C0532925a3b844Bc9e", Uptime: 120}
node.DisplayInfo() // 调用方法
}(2)接收者类型
值 接收者 (Value Receiver)
接收者是一个结构体的副本
方法内对接收者的修改不会影响原始结构体
Go
package main
import "fmt"
// 定义区块链节点结构体
// 该结构体表示一个区块链网络中的节点状态信息
type BlockchainNode struct {
BlockHeight int64 // 当前区块高度 - 表示节点已同步到的区块编号
IsOnline bool // 节点是否在线 - 表示节点当前是否可连接和正常工作
}
// 值接收者方法:UpdateBlockHeight
// 参数:
// node BlockchainNode - 结构体的值接收器(接收的是结构体的副本)
// height int64 - 要设置的新区块高度
// 功能:
// 尝试更新节点的区块高度,但由于使用值接收器,修改的是副本,不会影响原始结构体
// 注意:
// 值接收器方法适用于不修改原始结构体的场景,如计算、查询等操作
func (node BlockchainNode) UpdateBlockHeight(height int64) {
// 修改结构体副本的BlockHeight字段
node.BlockHeight = height
// 打印更新后的区块高度,注意这是副本的值
fmt.Printf("区块高度更新为: %d (副本)\n", node.BlockHeight)
}
func main() {
// 创建并初始化一个区块链节点实例
// BlockHeight: 1000000 - 节点当前区块高度为100万
// IsOnline: true - 节点在线
node := BlockchainNode{BlockHeight: 1000000, IsOnline: true}
// 打印调用UpdateBlockHeight方法前的区块高度
fmt.Println("调用前:", node.BlockHeight) // 输出: 1000000
// 调用值接收器方法UpdateBlockHeight
// 注意:由于UpdateBlockHeight使用值接收器,这里传递的是node的副本
// 方法内部对副本的修改不会影响原始的node结构体
node.UpdateBlockHeight(1000100) // 输出: 区块高度更新为: 1000100 (副本)
// 打印调用UpdateBlockHeight方法后的区块高度
// 由于值接收器修改的是副本,原始结构体的BlockHeight字段保持不变
fmt.Println("调用后:", node.BlockHeight) // 输出: 仍然是1000000
// 额外说明:为了展示指针接收器的不同效果,可以添加以下注释
fmt.Println("\n说明:")
fmt.Println("由于UpdateBlockHeight方法使用值接收器,方法内部修改的是结构体的副本")
fmt.Println("原始结构体的字段值保持不变,这是值接收器的典型行为")
}指针 接收者 (Pointer Receiver)
接收者是一个指向结构体的指针
方法内对接收者的修改会影响原始结构体
Go
package main
import "fmt"
// 定义区块链节点结构体
// 该结构体用于表示区块链网络中的一个节点状态
type BlockchainNode struct {
BlockHeight int64 // 当前区块高度 - 节点已同步到的区块链最新区块编号
IsOnline bool // 节点是否在线 - 表示节点当前是否可以正常连接和通信
}
// 指针接收者方法:UpdateBlockHeightPtr
// 参数:
// node *BlockchainNode - 结构体的指针接收器(接收的是结构体的内存地址)
// height int64 - 要设置的新区块高度
// 功能:
// 更新节点的区块高度。由于使用指针接收器,方法内部可以直接修改原始结构体的字段
// 注意:
// 指针接收器方法适用于需要修改原始结构体字段的场景,如状态更新、配置变更等
func (node *BlockchainNode) UpdateBlockHeightPtr(height int64) {
// 直接修改指针指向的结构体的BlockHeight字段
// 由于node是指针,这里的修改会影响原始的BlockchainNode实例
node.BlockHeight = height
// 打印更新后的区块高度,这是原始结构体的实际值
fmt.Printf("区块高度更新为: %d (指针)\n", node.BlockHeight)
}
func main() {
// 创建并初始化一个区块链节点实例
// BlockHeight: 1000000 - 节点当前同步到第100万个区块
// IsOnline: true - 节点当前在线,可以正常参与网络活动
node := BlockchainNode{BlockHeight: 1000000, IsOnline: true}
// 打印调用UpdateBlockHeightPtr方法前的区块高度
// 输出节点当前的区块高度,应为初始化的值1000000
fmt.Println("调用前:", node.BlockHeight) // 输出: 1000000
// 调用指针接收器方法UpdateBlockHeightPtr
// 注意:由于UpdateBlockHeightPtr使用指针接收器,Go会自动取node的地址传递给方法
// 方法内部通过指针直接修改原始node结构体的BlockHeight字段
node.UpdateBlockHeightPtr(1000100) // 输出: 区块高度更新为: 1000100 (指针)
// 打印调用UpdateBlockHeightPtr方法后的区块高度
// 由于指针接收器修改的是原始结构体,这里的值已经变为1000100
fmt.Println("调用后:", node.BlockHeight) // 输出: 1000100
// 额外说明:展示指针接收器与值接收器的区别
fmt.Println("\n====== 指针接收器特点说明 ======")
fmt.Println("1. 指针接收器接收的是结构体的内存地址,可以直接修改原始结构体")
fmt.Println("2. 当结构体较大时,使用指针接收器可以避免值复制,提高性能")
fmt.Println("3. 指针接收器方法可以通过值类型变量调用,Go会自动进行取地址转换")
fmt.Println("4. 适合用于需要修改接收器状态的场景,如状态更新、配置变更等")
}区块链系统示例
Go
package main
import "fmt"
// 定义区块链节点结构体
// BlockchainNode 表示一个区块链网络中的节点,包含节点的基本属性和状态
type BlockchainNode struct {
NodeName string // 节点名称或唯一标识符
IsActive bool // true: 在线, false: 离线 - 表示节点当前是否正在运行
Network string // 节点所在的区块链网络,如"以太坊主网"、"币安智能链"等
}
// 值接收者方法 - 获取节点状态
// GetStatus 返回节点当前状态的字符串描述
// 使用值接收器意味着方法不会修改原始结构体,适用于查询操作
func (n BlockchainNode) GetStatus() string {
if n.IsActive {
return "在线"
}
return "离线"
}
// 指针接收者方法 - 启动节点
// StartNode 将节点的IsActive状态设置为true,表示节点开始运行
// 使用指针接收器可以修改原始结构体的字段值
func (n *BlockchainNode) StartNode() {
n.IsActive = true
fmt.Printf("%s 节点已启动\n", n.NodeName)
}
// 指针接收者方法 - 停止节点
// StopNode 将节点的IsActive状态设置为false,表示节点停止运行
// 使用指针接收器确保可以修改原始结构体的状态
func (n *BlockchainNode) StopNode() {
n.IsActive = false
fmt.Printf("%s 节点已停止\n", n.NodeName)
}
// 值接收者方法 - 显示节点信息(不修改状态)
// DisplayInfo 展示节点的详细信息,包括名称、网络和状态
// 使用值接收器确保不会意外修改节点状态,适合展示信息的场景
func (n BlockchainNode) DisplayInfo() {
fmt.Printf("节点名称: %s\n", n.NodeName)
fmt.Printf("所属网络: %s\n", n.Network)
fmt.Printf("当前状态: %s\n", n.GetStatus())
fmt.Println("------------------")
}
// 定义验证节点结构体(嵌套结构体)
// ValidatorNode 是一个特殊的区块链节点,除了基本节点属性外,还包含质押信息和角色
// 通过嵌套BlockchainNode结构体,ValidatorNode继承了所有基本节点属性和方法
type ValidatorNode struct {
BlockchainNode // 嵌套BlockchainNode结构体,继承其所有字段和方法
StakedAmount float64 // 质押金额(单位:代币)- 验证节点需要质押代币以参与共识
Role string // "validator", "miner", "delegator" - 节点在共识机制中的角色
}
// 验证节点专属方法 - 设置质押金额
// SetStakeAmount 设置验证节点的质押代币数量
// 质押金额通常决定验证节点在共识中的权重和收益
func (vn *ValidatorNode) SetStakeAmount(amount float64) {
vn.StakedAmount = amount
fmt.Printf("验证节点质押金额已设置为: %.2f 代币\n", amount)
}
// 验证节点专属方法 - 设置节点角色
// SetRole 设置验证节点在共识机制中的角色
// 不同区块链网络可能有不同的角色定义和职责
func (vn *ValidatorNode) SetRole(role string) {
vn.Role = role
fmt.Printf("节点角色已设置为: %s\n", role)
}
// 接口定义
// NodeController 定义了区块链节点的基本控制接口
// 接口允许我们以统一的方式处理不同类型的节点,实现多态
type NodeController interface {
StartNode() // 启动节点
StopNode() // 停止节点
GetStatus() string // 获取节点状态
}
func main() {
// 创建普通区块链节点
// fullNode 是一个完整的区块链节点,可以同步整个区块链数据
fullNode := BlockchainNode{
NodeName: "全节点-001",
IsActive: false, // 初始状态为离线
Network: "以太坊主网",
}
// 创建验证节点(包含嵌套的BlockchainNode)
// validator 是一个验证节点,参与区块链共识机制,需要质押代币
validator := ValidatorNode{
BlockchainNode: BlockchainNode{
NodeName: "验证节点-Alpha",
IsActive: false, // 初始状态为离线
Network: "以太坊权益证明网络", // 使用权益证明共识机制的以太坊网络
},
StakedAmount: 1000.0, // 初始质押1000个代币
Role: "validator", // 初始角色为验证者
}
fmt.Println("=== 区块链节点管理系统 ===")
// 使用值接收者方法(不会修改原始对象)
// DisplayInfo方法使用值接收器,仅展示信息,不会修改节点状态
fullNode.DisplayInfo()
// 使用指针接收者方法(会修改原始对象)
// StartNode方法使用指针接收器,会修改fullNode的IsActive字段为true
fullNode.StartNode()
// 再次显示节点信息,确认状态已更新
fullNode.DisplayInfo()
fmt.Println("\n=== 验证节点控制 ===")
// 验证节点继承了BlockchainNode的所有方法
validator.DisplayInfo()
validator.StartNode()
validator.SetStakeAmount(1500.5) // 更新质押金额
validator.SetRole("miner") // 更改节点角色
// 显示验证节点的详细信息
// 通过嵌套结构体,我们可以直接访问BlockchainNode的字段
fmt.Println("\n验证节点详细信息:")
fmt.Printf("节点名称: %s\n", validator.NodeName) // 继承自BlockchainNode
fmt.Printf("所属网络: %s\n", validator.Network) // 继承自BlockchainNode
fmt.Printf("当前状态: %s\n", validator.GetStatus()) // 调用继承的方法
fmt.Printf("质押金额: %.2f 代币\n", validator.StakedAmount) // ValidatorNode特有字段
fmt.Printf("节点角色: %s\n", validator.Role) // ValidatorNode特有字段
fmt.Println("------------------")
// 使用接口
fmt.Println("\n=== 通过接口控制 ===")
// 将fullNode的地址赋值给NodeController接口
// 接口可以持有任何实现了其所有方法的类型的值
var controller NodeController = &fullNode
// 通过接口调用方法
controller.StopNode()
fmt.Println("节点状态:", controller.GetStatus())
// 验证节点也可以通过接口控制
fmt.Println("\n=== 验证节点接口控制 ===")
// 验证节点也实现了NodeController接口(通过继承BlockchainNode的方法)
var validatorController NodeController = &validator
fmt.Printf("验证节点状态: %s\n", validatorController.GetStatus())
}(4)接收者选择原则
何时使用 值 接收者
(1)不修改结构体数据的方法
(2)结构体很小(复制成本低)
(3)需要不可变性保证
(4)方法被频繁调用,避免指针解引用开销
Go
// 适合使用值接收者的场景
type BlockchainPosition struct {
X, Y float64 // X: 区块高度,Y: 交易在区块中的位置索引
}
// 计算位置哈希值(不修改位置信息)
// 在区块链中,位置信息可用于计算唯一标识符
func (p BlockchainPosition) Hash() float64 {
return math.Sqrt(p.X*p.X + p.Y*p.Y)
}
// 创建新位置(返回新对象,不修改原始位置)
// 将两个位置相加,可用于计算新的区块位置或交易位置
func (p BlockchainPosition) Add(other BlockchainPosition) BlockchainPosition {
return BlockchainPosition{X: p.X + other.X, Y: p.Y + other.Y}
}何时使用 指针 接收者:
(1)需要修改结构体数据的方法。
(2)结构体很大(避免复制开销)。
(3)包含互斥锁或其他需要同步的字段。
(4)实现接口时,接口方法可能会修改接收者。
Go
// 适合使用指针接收者的场景
type BlockchainNetwork struct {
mu sync.Mutex // 互斥锁,用于保护并发访问,防止数据竞争
Nodes []BlockchainNode // 区块链网络中的节点列表,存储所有已连接的节点
Settings map[string]interface{} // 网络配置参数,如区块大小、共识算法等
}
// 添加节点到网络(修改切片)需要指针接收器
// 因为需要修改Nodes切片,并且需要加锁确保并发安全
func (bn *BlockchainNetwork) AddNode(node BlockchainNode) {
bn.mu.Lock() // 加锁,防止其他goroutine同时修改Nodes
defer bn.mu.Unlock() // 函数返回时自动解锁
bn.Nodes = append(bn.Nodes, node) // 将新节点添加到节点列表中
}
// 更新网络配置(修改map)需要指针接收器
// 因为需要修改Settings映射,并且需要加锁确保并发安全
func (bn *BlockchainNetwork) UpdateSetting(key string, value interface{}) {
bn.mu.Lock() // 加锁,防止其他goroutine同时修改Settings
defer bn.mu.Unlock() // 函数返回时自动解锁
bn.Settings[key] = value // 更新或添加配置项
}(5)高级特性
方法集 (Method Sets)
-
值类型 T 的方法集包含所有值接收者声明的方法。
-
指针类型 T 的方法集包含所有 值接收者 和 指针接收者 声明的方法。
Go
type BlockchainNode struct {
Name string
}
func (n BlockchainNode) ValueMethod() {
fmt.Println("值方法 - 操作节点副本")
}
func (n *BlockchainNode) PointerMethod() {
fmt.Println("指针方法 - 操作原始节点")
}
func main() {
var node1 BlockchainNode
var node2 *BlockchainNode = &BlockchainNode{}
fmt.Println("=== 值类型节点调用方法 ===")
// 值类型可以调用值方法
node1.ValueMethod()
// 值类型也可以调用指针方法(Go会自动取地址)
node1.PointerMethod()
fmt.Println("\n=== 指针类型节点调用方法 ===")
// 指针类型可以调用所有方法
node2.ValueMethod()
node2.PointerMethod()
fmt.Println("\n=== 总结 ===")
fmt.Println("Go语言允许:")
fmt.Println("1. 值类型可以调用值方法和指针方法")
fmt.Println("2. 指针类型可以调用值方法和指针方法")
fmt.Println("3. 编译器会自动处理值和指针之间的转换")
}嵌套结构体方法
Go
package main
import "fmt"
// BaseBlockchainNode 定义基础区块链节点结构体
// 该结构体包含了所有区块链节点共有的基本属性和方法
type BaseBlockchainNode struct {
ID string // 节点唯一标识符,通常为字符串格式的节点地址或名称
Status bool // 节点状态:true表示节点在线/活跃,false表示节点离线/非活跃
}
// GetID 方法返回节点的ID
// 使用指针接收器,允许通过节点指针调用此方法
func (bd *BaseBlockchainNode) GetID() string {
return bd.ID
}
// ValidatorNode 定义验证节点结构体
// 验证节点是区块链网络中的特殊节点,参与共识过程
// 通过嵌入BaseBlockchainNode,ValidatorNode继承了其所有字段和方法
type ValidatorNode struct {
BaseBlockchainNode // 嵌入BaseBlockchainNode,实现继承效果
ConsensusType string // 共识类型:表示节点参与的共识算法类型,如"PoW"(工作量证明)、"PoS"(权益证明)、"DPoS"(委托权益证明)等
}
func main() {
// 创建验证节点实例
// 通过结构体字面量初始化ValidatorNode
validator := ValidatorNode{
// 初始化嵌入的BaseBlockchainNode
BaseBlockchainNode: BaseBlockchainNode{
ID: "node001", // 节点ID为"node001"
Status: true, // 节点状态为在线
},
// 设置ValidatorNode特有的字段
ConsensusType: "PoS", // 共识类型为权益证明
}
// 演示如何调用嵌入结构体的方法
// 方式1:直接调用(Go语言会自动查找嵌入结构体的方法)
fmt.Println("节点ID (直接调用):", validator.GetID())
// 方式2:通过嵌入结构体名称显式调用
fmt.Println("节点ID (显式调用):", validator.BaseBlockchainNode.GetID())
// 访问嵌入结构体的字段
// 可以直接访问嵌入结构体的字段,就像它们是ValidatorNode的一部分
fmt.Println("节点状态:", validator.Status)
// 也可以显式指定嵌入结构体名称来访问
fmt.Println("节点状态 (显式访问):", validator.BaseBlockchainNode.Status)
// 访问ValidatorNode特有的字段
fmt.Println("共识类型:", validator.ConsensusType)
}方法与函数的区别
在 Go 语言中,函数是一段独立的、可通过名称直接调用的代码块,不依赖于特定类型;而方法是一种特殊的函数,它必须关联到一个具体的接收者类型(如结构体),并通过该类型的实例进行调用。本质上,方法是绑定在类型上的函数,它隐含地以接收者作为第一个操作参数,从而能够访问和操作该类型的数据。
Go
package main
// 区块链节点结构体
type BlockchainNode struct {
Name string
Status bool // true: 在线, false: 离线
}
// 函数 - 独立,需要显式传递参数
func AdjustNodeStatus(node *BlockchainNode, status bool) {
node.Status = status
}
// 方法 - 与类型关联,隐式传递接收者
func (n *BlockchainNode) SetStatus(status bool) {
n.Status = status
}
func main() {
node := &BlockchainNode{Name: "验证节点-A"}
// 函数调用
AdjustNodeStatus(node, true)
// 方法调用(更简洁)
node.SetStatus(false)
}(6)最佳实践:一致性原则
一致性原则 是 Go 语言中的一项重要设计规则,它规定:一个类型的方法集合中,要么全部使用值接收者,要么全部使用指针接收者,避免混合使用。这样做的主要目的是保证代码行为的可预测性和一致性------如果某些方法能修改接收者(指针接收者),而另一些不能(值接收者),会使得类型的操作行为变得混乱,增加理解和维护的难度。遵循一致性原则有助于维护清晰的语义:要么类型是不可变的(全部值接收者),要么是可变的(全部指针接收者),从而提升代码的可靠性和可读性。
Go
// 不好的实践:混合使用值和指针接收者
type Inconsistent struct {
data int
}
func (i Inconsistent) Get() int { return i.data } // 值接收者
func (i *Inconsistent) Set(x int) { i.data = x } // 指针接收者
// 好的实践:保持一致性
type Consistent struct {
data int
}
// 如果有一个方法需要指针接收者,所有方法都用指针接收者
func (c *Consistent) Get() int { return c.data }
func (c *Consistent) Set(x int) { c.data = x }实用的 智能家居系统 示例
Go
package main
import (
"fmt"
"time"
)
// 智能家居主控系统
type SmartHomeSystem struct {
Temperature float64
Humidity float64
SecurityEnabled bool
Devices map[string]bool
lastUpdated time.Time
}
// 初始化方法(指针接收者)
func (shs *SmartHomeSystem) Initialize() {
shs.Devices = make(map[string]bool)
shs.SecurityEnabled = true
shs.lastUpdated = time.Now()
}
// 更新环境数据(指针接收者)
func (shs *SmartHomeSystem) UpdateEnvironment(temp, humidity float64) {
shs.Temperature = temp
shs.Humidity = humidity
shs.lastUpdated = time.Now()
shs.log("环境数据更新")
}
// 控制设备(指针接收者)
func (shs *SmartHomeSystem) ControlDevice(device string, status bool) {
if shs.Devices == nil {
shs.Initialize()
}
shs.Devices[device] = status
action := "关闭"
if status {
action = "开启"
}
fmt.Printf("%s %s\n", device, action)
shs.log("设备控制")
}
// 获取系统状态(值接收者,只读)
func (shs SmartHomeSystem) GetStatus() string {
deviceCount := len(shs.Devices)
activeDevices := 0
for _, status := range shs.Devices {
if status {
activeDevices++
}
}
return fmt.Sprintf(
"温度: %.1f°C, 湿度: %.1f%%, 设备: %d/%d 运行, 安防: %v",
shs.Temperature,
shs.Humidity,
activeDevices,
deviceCount,
shs.SecurityEnabled,
)
}
// 私有方法(指针接收者)
func (shs *SmartHomeSystem) log(action string) {
fmt.Printf("[%s] %s\n", shs.lastUpdated.Format("15:04:05"), action)
}
// 模拟自动调节(指针接收者)
func (shs *SmartHomeSystem) AutoAdjust() {
if shs.Temperature > 28 {
shs.ControlDevice("空调", true)
} else if shs.Temperature < 18 {
shs.ControlDevice("暖气", true)
}
if shs.Humidity > 80 {
shs.ControlDevice("除湿器", true)
}
}
func main() {
// 创建智能家居系统
home := SmartHomeSystem{}
home.Initialize()
// 更新环境数据
home.UpdateEnvironment(29.5, 75.0)
// 控制设备
home.ControlDevice("客厅灯光", true)
home.ControlDevice("窗帘", true)
// 自动调节
home.AutoAdjust()
// 获取状态(值接收者方法)
fmt.Println("\n当前系统状态:")
fmt.Println(home.GetStatus())
// 再次更新环境
home.UpdateEnvironment(25.0, 65.0)
fmt.Println("\n调节后状态:")
fmt.Println(home.GetStatus())
}(7)总结
关键点:
(1)值接收者:适用于不修改数据或结构体很小的场景。
(2)指针接收者:适用于需要修改数据或结构体很大的场景。
(3)一致性:尽可能保持接收者类型的一致性。
(4)方法集:指针类型的方法集包含值类型的方法集。
(5)接口实现:指针接收者方法既能被值类型也能被指针类型调用。
选择指南:
-
如果需要修改接收者 → 指针接收者
-
如果结构体很大 → 指针接收者
-
如果方法需要实现接口,且接口方法可能修改接收者 → 指针接收者
-
如果只是读取数据,且结构体很小 → 值接收者
-
如果追求线程安全(不可变) → 值接收者
理解并正确使用结构体方法和接收者是编写高效、可维护Go代码的关键。
5.6.5 给任意类型添加方法
在 Go 语言中,接收者的类型可以是任何类型,不仅仅是结构体,任何类型都可以拥有方法。 举个例子,我们基于内置的 int 类型使用 type 关键字可以定义新的自定义类型,然后为我们的自定义类型添加方法。
Go
package main
import "fmt"
type myInt int
func (m myInt) SayHello() {
fmt.Printf("Hello,我是一个int。\n")
}
func main() {
var m1 myInt
m1.SayHello()
m1 = 100
fmt.Printf("%#v %T\n", m1, m1) // 输出:100 main.myInt
}**注意事项:**非本地类型不能定义方法,也就是说我们不能给别的包的类型定义方法。
5.6.6 结构体的匿名字段
结构体允许其成员字段在声明时没有字段名而只有类型,这种没有名字的字段就称为匿名字段。
Go
package main
import "fmt"
type Person struct {
string
int
}
func main() {
p1 := Person{
"小王子",
18,
}
fmt.Printf("%#v\n", p1) // main.Person{string:"小王子", int:18}
fmt.Println(p1.string, p1.int) // 小王子 18
}结构体匿名字段是Go语言中强大的特性,主要应用场景包括:
(1)模拟继承实现代码复用:通过嵌入类型实现自动委托,使子结构体直接复用父结构体的字段和方法,模拟传统面向对象的继承关系。
(2)组合优于继承的面向接口设计:将多个小型的、职责单一的结构体组合成复杂类型,利用其方法集合来实现行为复用,践行"组合优于继承"的设计思想。
(3)扩展已有类型的功能:通过嵌入已有类型并为其添加新方法,从而在不修改原类型定义的前提下扩展其功能。
(4)接口组合构建复杂接口:通过嵌入多个接口类型,将它们的全部方法要求合并,从而快速定义出一个新的、更复杂的接口。
(5)Mixin模式实现功能混入:通过嵌入多个提供特定功能的结构体,将它们的实现"混合"进新类型,实现代码的横向复用。
(6)领域模型构建:通过逐层嵌入基础领域实体(如ID、时间戳)来构建富领域模型,实现领域概念的清晰表达与复用。
(7)框架开发中的控制器设计:通过将核心框架的控制器结构体匿名嵌入用户自定义控制器,使用户结构体自动继承框架提供的所有基础方法。
5.6.7 嵌套结构体
一个结构体中可以嵌套包含另一个结构体或结构体指针。
Go
package main
import "fmt"
// Address 地址结构体
type Address struct {
Province string
City string
}
// User用户结构体
type User struct {
Name string
Gender string
Address Address
}
func main() {
user1 := User{
Name: "张三",
Gender: "男",
Address: Address{
Province: "广东",
City: "深圳",
},
}
fmt.Printf("user1=%#v\n", user1) // user1=main.User{Name:"张三", Gender:"男", Address:main.Address{Province:"广东", City:"深圳"}}
}5.6.8 嵌套匿名结构体
Go
package main
import "fmt"
// Address 地址结构体
type Address struct {
Province string
City string
}
// User用户结构体
type User struct {
Name string
Gender string
Address // 匿名结构体
}
func main() {
var user2 User
user2.Name = "张三"
user2.Gender = "男"
user2.Address.Province = "广东" // 通过匿名结构体.字段名访问
user2.City = "深圳" // 直接访问匿名结构体的字段名
fmt.Printf("user2=%#v\n", user2) // user2=main.User{Name:"张三", Gender:"男", Address:main.Address{Province:"广东", City:"深圳"}}
}注意:当访问结构体成员时会先在结构体中查找该字段,找不到再去匿名结构体中查找。
5.6.9 关于嵌套结构体的字段名冲突
嵌套结构体内部可能存在相同的字段名。这个时候为了避免歧义需要指定具体的内嵌结构体的字段。
Go
package main
import "fmt"
// Address 地址结构体
type Address struct {
Province string
City string
CreateTime string
}
// Email 邮箱结构体
type Email struct {
Account string
CreateTime string
}
// User 用户结构体
type User struct {
Name string
Gender string
Address
Email
}
func main() {
var user3 User
user3.Name = "张三"
user3.Gender = "男"
// user3.CreateTime = "2025" // ambiguous selector user3.CreateTimecompiler
user3.Address.CreateTime = "2025" // 指定Address结构体中的CreateTime
user3.Email.CreateTime = "2026" // 指定Email结构体中的CreateTime
fmt.Printf("user3=%#v\n", user3) // user3=main.User{Name:"张三", Gender:"男", Address:main.Address{Province:"", City:"", CreateTime:"2025"}, Email:main.Email{Account:"", CreateTime:"2026"}}
}5.6.10 结构体的继承
Go 语言中使用结构体也可以实现其他编程语言中的继承。通过匿名字段实现结构体"继承":子结构体嵌入父结构体后,自动获得其全部字段和方法,可直接调用,如同属于自己的功能;但这并非真正的继承,而是将父结构体作为子结构体的内部组成部分,本质是组合,从而更灵活安全地复用代码。
Go
package main
import "fmt"
// Animal 动物
type Animal struct {
name string
}
func (a *Animal) run() {
fmt.Printf("%s会运动!\n", a.name)
}
// Dog 狗
type Dog struct {
Age int8
*Animal // 通过嵌套匿名结构体实现继承
}
func (d *Dog) wang() {
fmt.Printf("%s会汪汪汪~\n", d.name)
}
func main() {
d1 := &Dog{
Age: 4,
Animal: &Animal{ // 注意嵌套的是结构体指针
name: "阿奇",
},
}
d1.wang() // 阿奇会汪汪汪~
d1.run() // 阿奇会动!
}5.6.11 Go结构体和 JSON 相互转换 序列化 反序列化
(1)关于 JSON 数据
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。易于人阅读和编写。同时也易于机器解析和生成。RESTfull Api 接口中返回的数据都是 json 数据。
Json 的基本格式如下:
Go
{
"a": "Hello",
"b": "World"
}稍微复杂点的 JSON
Go
{
"result": [{
"_id": "59f6ef443ce1fb0fb02c7a43",
"title": "笔记本电脑","status": "1",
"pic": "public\\upload\\UObZahqPYzFvx_C9CQjU8KiX.png",
"url": "12"
}, {
"_id": "5a012efb93ec4d199c18d1b4",
"title": "第二个轮播图",
"status": "1",
"pic": "public\\upload\\f3OtH11ZaPX5AA4Ov95Q7DEM.png"
}, {
"_id": "5a012f2433574208841e0820",
"title": "第三个轮播图",
"status": "1",
"pic": "public\\upload\\s5ujmYBQVRcLuvBHvWFMJHzS.jpg"
}, {
"_id": "5a688a0ca6dcba0ff4861a3d",
"title": "教程",
"status": "1",
"pic": "public\\upload\\Zh8EP9HOasV28ynDSp8TaGwd.png"
}]
}(2)结构体与 JSON 序列化
比如我们 Golang 要给 App 或者小程序提供 API 接口数据,这个时候就需要涉及到结构体和JSON 之间的相互转换。
Golang JSON 序列化: 是指把结构体数据转化成 JSON 格式的字符串。**Golang JSON 的反序列化:**是指把 JSON 数据转化成 Golang 中的结构体对象 Golang 中 的 序 列 化 和 反 序 列 化 主 要 通 过 "encoding/json" 包 中 的 json.Marshal() 和 json.Unmarshal()方法实现。
结构体对象 -> JSON 字符串
Go
package main
import (
"encoding/json"
"fmt"
)
// WalletAccount 定义了一个Web3钱包账户的结构体
// 结构体字段的可见性决定了JSON序列化时是否包含该字段
// 字段首字母大写表示公开(public),小写表示私有(private)
type WalletAccount struct {
Address string // 公开的区块链地址,可以被JSON序列化
Balance float64 // 账户余额(ETH单位),可以被JSON序列化
chainID int // 私有属性:链ID,不能被json包访问(小写开头)
PrivateKey string // 私钥,实际应用中绝不应公开暴露
}
func main() {
// 创建一个钱包账户实例,初始化所有字段
var account1 = WalletAccount{
Address: "0x742d35Cc6634C0532925a3b844Bc9e90F1fE2f5A", // 以太坊地址示例
Balance: 3.75, // 账户余额,单位ETH
chainID: 1, // 1代表以太坊主网,这是私有字段,不会被JSON序列化
PrivateKey: "0x...", // 私钥占位符,实际应用中应该安全存储
}
// 使用%#v格式化动词打印结构体的详细表示,包含字段名和值
fmt.Printf("完整结构体内容:%#v\n", account1)
// 将结构体序列化为JSON字节切片
// json.Marshal函数只能序列化公开字段(首字母大写的字段)
// jsonData是序列化后的JSON字节切片,err是可能发生的错误
var jsonData, err = json.Marshal(account1)
// 打印序列化结果和错误信息
// jsonData是字节切片,所以显示为数字序列
// 如果序列化成功,err将为nil
fmt.Printf("JSON字节数据:%v 错误信息:%v\n", jsonData, err)
// 将字节切片转换为可读的字符串
jsonStr := string(jsonData)
// 输出格式化后的JSON字符串
// 注意:私有字段chainID不会出现在输出中
fmt.Printf("JSON字符串:%s\n", jsonStr)
// 输出结果说明:
// 只有Address、Balance和PrivateKey这三个公开字段被序列化
// chainID由于是私有字段,不会出现在JSON输出中
// 实际Web3应用中,PrivateKey字段绝不应该被序列化传输或暴露
}(3)结构体与 JSON 反序列化
Json 字符串 -> 结构体对象
Go
package main
import (
"encoding/json" // 导入JSON编解码包,提供Marshal和Unmarshal函数
"fmt" // 导入格式化I/O包,提供打印输出功能
)
// NFTAsset 代表一个非同质化代币(NFT)资产的结构体
// NFT是Web3和区块链中的核心概念之一,每个NFT都有唯一标识
// 结构体字段必须首字母大写才能被JSON包访问(公开可见)
type NFTAsset struct {
TokenID int // 代币ID:NFT在智能合约中的唯一编号,用于区分同一集合中的不同资产
Category string // 资产类别:描述NFT的类型,如"Art"(艺术)、"Collectible"(收藏品)、"Game"(游戏道具)等
Name string // 资产名称:NFT的具体名称,如"CryptoPunk #1234"、"Bored Ape #5678"等
OwnerAddr string // 所有者地址:当前持有该NFT的区块链钱包地址(以太坊地址格式)
}
func main() {
// 定义JSON字符串,模拟从区块链API、智能合约事件或数据库中获取的NFT数据
// JSON格式是Web3 API中最常用的数据交换格式
var jsonStr = `{"TokenID":12345,"Category":"Art","Name":"CryptoPunk #1234","OwnerAddr":"0x742d35Cc6634C0532925a3b844Bc9e90F1fE2f5A"}`
// 声明一个NFTAsset类型的变量nft,用于接收反序列化后的数据
// 此时nft的所有字段都是零值:TokenID=0, Category="", Name="", OwnerAddr=""
var nft NFTAsset
// 将JSON字符串反序列化为NFTAsset结构体
// json.Unmarshal()接收两个参数:
// 1. []byte(jsonStr): 将字符串转换为字节切片
// 2. &nft: 传入结构体指针,这样函数才能修改原始结构体内容
// 返回值err用于检查反序列化过程中是否发生错误
err := json.Unmarshal([]byte(jsonStr), &nft)
// 异常处理:检查反序列化是否成功
// 常见的错误原因包括:JSON格式错误、字段类型不匹配、缺少必填字段等
if err != nil {
fmt.Printf("反序列化错误 = %v\n", err)
return // 发生错误时提前退出,避免继续执行可能引发的问题
}
// 打印反序列化后的结果
// %#v 格式化动词:显示结构体的完整类型和字段信息,包括字段名和值
// nft.Name:直接访问结构体的Name字段,显示NFT的具体名称
fmt.Printf("反序列化后 nft=%#v nft.Name = %v\n", nft, nft.Name)
// 实际应用场景说明:
// 1. 在DApp(去中心化应用)中从区块链后端API获取NFT数据
// 2. 处理智能合约事件返回的NFT转移信息
// 3. 构建NFT市场或钱包应用时显示用户资产列表
// 4. 将链下数据库中的NFT元数据解析为可操作的结构体
// 补充说明:如果JSON键名与结构体字段名不匹配,可以使用结构体标签(tag):
// type NFTAsset struct {
// TokenID int `json:"token_id"`
// Category string `json:"category"`
// Name string `json:"asset_name"`
// OwnerAddr string `json:"owner_address"`
// }
// 这样即使JSON使用不同的命名约定,也能正确映射到结构体字段
}json.Unmarshal 是 json.Marshal 的逆操作:
把 JSON 文本( []byte )反序列化成 Go 值。
记住"公开字段、类型匹配、标签对应、nil 可写"四句话,就能 cover 99 % 的踩坑场景。
函数原型
Go
func Unmarshal(data []byte, v interface{}) errorfunc Unmarshal(data []byte, v interface{}) error
-
data:UTF-8 JSON 文本 -
v:必须传指针,否则无法写入(常见 panic:nil pointer) -
返回:解析失败时
*SyntaxError/*UnmarshalTypeError等
最简例子
Go
jsonStr := `{"id":1,"name":"Alice"}`
type User struct {
ID int `json:"id"`
Name string `json:"name"`
}
var u User
err := json.Unmarshal([]byte(jsonStr), &u) // 传指针!
// u = {ID:1, Name:"Alice"}字段匹配规则
| JSON 键 | 能否写到 struct | 说明 |
|---|---|---|
| 存在且导出字段同名/同标签 | ✅ | 直接填 |
| 多出的键 | ➖ | 静默忽略 |
| 缺失的键 | ➖ | 保持零值 |
| 小写/private 字段 | ❌ | 无法写入(不会被匹配) |
常用标签
同 Marshal,只是反向填值:
Go
type T struct {
A int `json:"a,string"` // 把 JSON 字符串 `"123"` 转 int
B int `json:"b,omitempty"`
C string `json:"-"` // 永远不解析
}任意 JSON → 万能容器
若结构未知,可解析到空接口:
Go
var m map[string]interface{}
json.Unmarshal(data, &m)
// 数字 → float64
// 字符串 → string
// true/false → bool
// null → nil或直接用 json.RawMessage 延迟二次解析。
自定义反序列化
实现接口:
Go
UnmarshalJSON([]byte) error例:把毫秒时间戳转成 time.Time
Go
type MilliTime time.Time
func (mt *MilliTime) UnmarshalJSON(b []byte) error {
ms, _ := strconv.ParseInt(string(b), 10, 64)
*mt = MilliTime(time.UnixMilli(ms))
return nil
}典型错误
-
忘传指针:
json.Unmarshal(b, u)→ 编译期 panic -
JSON 数字超过 Go 类型范围 →
UnmarshalTypeError -
null给非指针字段 → 零值;想区分可声明成指针类型*int/*string -
字符串
"123"直接写进int→ 类型不匹配错误(若用了,string标签则合法)
性能小贴士
-
高频场景可复用
json.Decoder流式解析 -
只取部分字段可先
json.RawMessage或定义"子结构体"再解析,避免全量反射
一句话总结
json.Unmarshal = JSON 文本 → Go 值的翻译器:
必须传指针 ,字段公开才能写;标签可改名、可忽略、可自定义;结构未知就用 map[string]interface{} 当万能容器。
(4)结构体标签 Tag
Tag 是结构体的元信息,可以在运行的时候通过反射的机制读取出来。 Tag 在结构体字段的后方定义,由一对反引号 包裹起来,具体的格式如下: key1:"value1" key2:"value2"
结构体 tag 由一个或多个键值对组成。键与值使用冒号分隔,值用双引号括起来。同一个结构体字段可以设置多个键值对 tag,不同的键值对之间使用空格分隔。
**注意事项:**为结构体编写 Tag 时,必须严格遵守键值对的规则。结构体标签的解析代码的容错能力很差,一旦格式写错,编译和运行时都不会提示任何错误,通过反射也无法正确取值。例如不要在 key 和 value 之间添加空格。
Go
package main
import (
"encoding/json"
"fmt"
)
type Student struct {
ID int `json:"id"` // 通过指定tag实现json序列化该字段时的key
Gender string `json:"gender"`
Name string
Sno string
}
func main() {
var s1 = Student{
ID: 1,
Gender: "男",
Name: "李四",
Sno: "s0001",
}
fmt.Printf("%#v\n", s1) // main.Student{ID:1, Gender:"男", Name:"李四", Sno:"s0001"}
// 结构体数据转化成 JSON 格式的字符串
var s, _ = json.Marshal(s1)
jsonStr := string(s)
fmt.Printf(jsonStr) // {"id":1,"gender":"男","Name":"李四","Sno":"s0001"}
}
Go
package main
import (
"encoding/json"
"fmt"
)
type Student struct {
ID int `json:"id"` // 通过指定tag实现json序列化该字段时的key
Gender string `json:"gender"`
Name string
Sno string
}
func main() {
var s2 Student
fmt.Println(s2) // {0 }
var str = "{\"id\":1,\"gender\":\"男\",\"Name\":\"李四\",\"Sno\":\"s0001\"}"
err := json.Unmarshal([]byte(str), &s2)
if err != nil {
fmt.Println(err)
}
fmt.Printf("%#v\n", s2) // main.Student{ID:1, Gender:"男", Name:"李四", Sno:"s0001"}
fmt.Printf("s2=%v s2的类型为:%T\n", s2, s2) // {1 男 李四 s0001}
}(4)嵌套结构体和 JSON 序列化反序列化
Go
package main
import (
"encoding/json"
"fmt"
)
// NFTAsset 代表一个非同质化代币资产
type NFTAsset struct {
TokenID int
Category string
Name string
}
// NFTCollection 代表一个NFT集合
type NFTCollection struct {
ContractAddress string
Assets []NFTAsset // 切片存储多个NFT资产
}
func main() {
// 初始化NFT集合结构体
c := &NFTCollection{
ContractAddress: "0x06012c8cf97BEaD5deAe237070F9587f8E7A266d", // CryptoKitties合约地址
Assets: make([]NFTAsset, 0, 200), // 创建容量为200的切片
}
fmt.Println(c) // 输出集合信息:&{0x06012c8cf97BEaD5deAe237070F9587f8E7A266d []}
fmt.Println(c.Assets) // 输出空的资产切片:[]
// 循环生成NFT资产并添加到集合中
// 在实际Web3应用中,这些数据通常从区块链或API获取
for i := 0; i < 10; i++ {
asset := NFTAsset{
Name: fmt.Sprintf("CryptoKitty #%03d", i), // 格式化NFT名称,例如"CryptoKitty #009"
Category: "Collectible", // NFT类别:收藏品
TokenID: i + 1000, // TokenID通常从1000开始
}
c.Assets = append(c.Assets, asset)
fmt.Println(c.Assets)
}
// JSON序列化:将NFT集合结构体转换为JSON格式字符串
// 这在Web3开发中常用于API响应、数据存储或前后端通信
data, err := json.Marshal(c)
// 处理异常:JSON序列化可能因字段类型问题或循环引用而失败
if err != nil {
fmt.Println("JSON序列化失败!!")
return
}
// 输出格式化后的JSON字符串
// 在实际DApp中,这个JSON可能被发送到前端界面或存储到数据库
fmt.Printf("NFT集合JSON数据:%s\n", data)
}
Go
package main
import (
"encoding/json"
"fmt"
)
// NFTAsset 代表一个非同质化代币资产
type NFTAsset struct {
TokenID int
Category string
Name string
}
// NFTCollection 代表一个NFT集合
type NFTCollection struct {
ContractAddress string
Assets []NFTAsset // 切片存储多个NFT资产
}
func main() {
// 定义JSON字符串,模拟从区块链API获取的NFT集合数据
str := `{"ContractAddress":"0x06012c8cf97BEaD5deAe237070F9587f8E7A266d",
"Assets":[{"TokenID":1000,"Category":"Collectible","Name":"CryptoKitty #000"},
{"TokenID":1001,"Category":"Collectible","Name":"CryptoKitty #001"},
{"TokenID":1002,"Category":"Collectible","Name":"CryptoKitty #002"},
{"TokenID":1003,"Category":"Collectible","Name":"CryptoKitty #003"},
{"TokenID":1004,"Category":"Collectible","Name":"CryptoKitty #004"},
{"TokenID":1005,"Category":"Collectible","Name":"CryptoKitty #005"},
{"TokenID":1006,"Category":"Collectible","Name":"CryptoKitty #006"},
{"TokenID":1007,"Category":"Collectible","Name":"CryptoKitty #007"},
{"TokenID":1008,"Category":"Collectible","Name":"CryptoKitty #008"},
{"TokenID":1009,"Category":"Collectible","Name":"CryptoKitty #009"}]
}`
// 创建一个空的NFTCollection指针实例
c1 := &NFTCollection{}
// 将JSON字符串反序列化到NFTCollection结构体
err := json.Unmarshal([]byte(str), c1)
// 处理反序列化过程中可能出现的错误
if err != nil {
fmt.Println("JSON反序列化失败!")
return
}
// 使用%#v格式化打印反序列化后的结构体
fmt.Printf("%#v\n", c1)
}(5)关于 Map、切片的序列化和反序列化
Map 和切片也可以进行序列化和反序列化,这个我们讲完接口后再去给大家详细讲解。
5.6.12 结构体值接收者和指针接收者实现接口的区别
值接收者: 如果结构体中的方法是值接收者 ,那么实例化后的结构体值类型 和结构体指针类型都可以赋值给接口变量。
**解释:**想象一下,你有一台电视机(结构体)和一个通用遥控器(接口)。电视机内置了接收信号的功能(值接收者方法)。神奇的是,无论你是直接用电视机机身上的按钮(结构体值类型),还是用遥控器对准电视机(结构体指针类型),都能成功控制它。这是因为电视机本身和遥控器发送的信号都会被电视机接收并响应,所以两种方式都能正常操作电视。
Go
package main
import "fmt"
type Usb interface {
Start()
Stop()
}
type Phone struct {
Name string
}
func (p Phone) Start() {
fmt.Println(p.Name, "开始工作")
}
func (p Phone) Stop() {
fmt.Println("phone 停止")
}
func main() {
phone1 := Phone{
Name: "小米手机",
}
var p1 Usb = phone1 // phone1 实现了Usb接口 phone1是 Phone类型
p1.Start() // 小米手机 开始工作
phone2 := &Phone{
Name: "苹果手机",
}
var p2 Usb = phone2 // phone2 实现了Usb接口 phone2是 *Phone类型
p2.Start() // 苹果手机 开始工作
}指针接收者:
如果结构体中的方法是指针接收者,那么实例化后结构体指针类型都可以赋值给接口变量,结构体值类型没法赋值给接口变量。
解释:想象你有一辆共享单车(结构体)。这辆单车有一个扫码开锁 的功能,但这个功能设计得比较特殊:它必须扫描到单车上的二维码标签(指针)才能解锁。
现在,有一个手机App(接口),它可以调用"开锁"功能:
情况一:直接扫描单车上的二维码标签(指针接收者)
- 你用手机App扫描车上的二维码,系统识别到这是单车的"身份标签",允许开锁。 → ✅ 成功(结构体指针可以赋值给接口变量)
情况二:只记得单车的车牌号,但没扫描二维码(值类型)
- 你只是口头告诉App:"我要开编号123的单车",但App无法通过这个数字直接找到单车的身份标签,因此无法开锁。 → ❌ 失败(结构体值无法赋值给接口变量)
为什么?
因为指针接收者方法需要直接"触摸"到结构体在内存中的真实位置(就像必须扫到二维码标签),而值类型只是复制品(就像只知道车牌号),无法提供这个真实位置,所以不能调用这个方法,也就无法满足接口的要求。
总结: 如果结构体的方法是指针接收者,那只有真实的地址(指针)才能被接口识别,而值的副本不行。
Go
package main
import "fmt"
type Usb interface {
Start()
Stop()
}
type Phone struct {
Name string
}
func (p *Phone) Start() {
fmt.Println(p.Name, "开始工作")
}
func (p *Phone) Stop() {
fmt.Println("phone 停止")
}
func main() {
/*
// 错误写法
phone1 := Phone{
Name: "小明手机",
}
var p1 Usb = phone1
p1.Start()
*/
// 正确写法
phone2 := &Phone{
Name: "苹果手机",
}
var p2 Usb = phone2 // phone2 实现了 Usb接口,phone2是*Phone类型
p2.Start() // 苹果手机 开始工作
}5.6.13 一个结构体实现多个接口
Golang 中一个结构体也可以实现多个接口
Go
package main
import "fmt"
// AccountInfoGetter 定义了获取账户信息的接口
type AccountInfoGetter interface {
GetAccountInfo() string
}
// AccountInfoSetter 定义了设置账户信息的接口
type AccountInfoSetter interface {
SetAccountInfo(string, int)
}
// BlockchainAccount 代表一个区块链账户
type BlockchainAccount struct {
Address string // 账户地址
Balance int // 账户余额(单位:wei)
}
// GetAccountInfo 实现获取账户信息的方法(值接收者)
func (account BlockchainAccount) GetAccountInfo() string {
return fmt.Sprintf("地址:%v 余额:%d wei", account.Address, account.Balance)
}
// SetAccountInfo 实现设置账户信息的方法(指针接收者)
func (account *BlockchainAccount) SetAccountInfo(address string, balance int) {
account.Address = address
account.Balance = balance
}
func main() {
// 创建一个区块链账户指针实例
var account = &BlockchainAccount{
Address: "0x742d35Cc6634C0532925a3b844Bc9e90F1fE2f5A",
Balance: 1000000000000000000, // 1 ETH = 10^18 wei
}
// BlockchainAccount同时实现了AccountInfoGetter和AccountInfoSetter接口
var infoGetter AccountInfoGetter = account
var infoSetter AccountInfoSetter = account
// 获取并打印账户信息
fmt.Println(infoGetter.GetAccountInfo())
// 设置新的账户信息(模拟转账或账户更新)
infoSetter.SetAccountInfo("0xAb5801a7D398351b8bE11C439e05C5B3259aeC9B", 2000000000000000000)
// 再次获取并打印更新后的账户信息
fmt.Println(infoGetter.GetAccountInfo())
}